Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Accelerate inference of BNN over TFHE
Search
Zume
March 04, 2022
Technology
280
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Accelerate inference of BNN over TFHE
IPSJ第84回全国大会5ZC-04
Zume
March 04, 2022
Other Decks in Technology
See All in Technology
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.7k
人手不足への挑戦:車両保全を支えるIoTとクラウド内製化の道【SORACOM Discovery 2026】
soracom
PRO
0
160
AI エージェント時代のデジタルアイデンティティ
fujie
1
1.2k
自己解決や回答速度を上げる、サポート業務へのAIの組み込み方【SORACOM Discovery 2026】
soracom
PRO
0
100
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
4
1.1k
plamo-3-translateの開発
pfn
PRO
0
140
『モンスターストライク』 の運営に伴走する! データ民主化への 解析グループの3つのアプローチ
mixi_engineers
PRO
0
170
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
1
270
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
310
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
31
21k
NetBoxを利用した作業効率化の試み_NetDevNight4
tnoha
0
330
カメラ×AIで挑む「ホワイト物流」― 車両管理、自動化の壁と突破口【SORACOM Discovery 2026】
soracom
PRO
0
180
Featured
See All Featured
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
230
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Paper Plane (Part 1)
katiecoart
PRO
1
9.9k
So, you think you're a good person
axbom
PRO
2
2.1k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Rails Girls Zürich Keynote
gr2m
96
14k
GitHub's CSS Performance
jonrohan
1033
470k
WENDY [Excerpt]
tessaabrams
11
39k
The Spectacular Lies of Maps
axbom
PRO
1
880
GraphQLとの向き合い方2022年版
quramy
50
15k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
640
Transcript
1 レイアウトがダサい 第84回 情報処理学会全国大会 5ZC-04 完全準同型暗号における BNNを用いた高速な秘匿推論手法の実装と評価 橋詰 陽太 京都大学
古川 修平 放送大学 松本 直樹 京都大学 伴野 良太郎 京都大学 松岡 航太郎 京都大学 佐藤 高史 京都大学
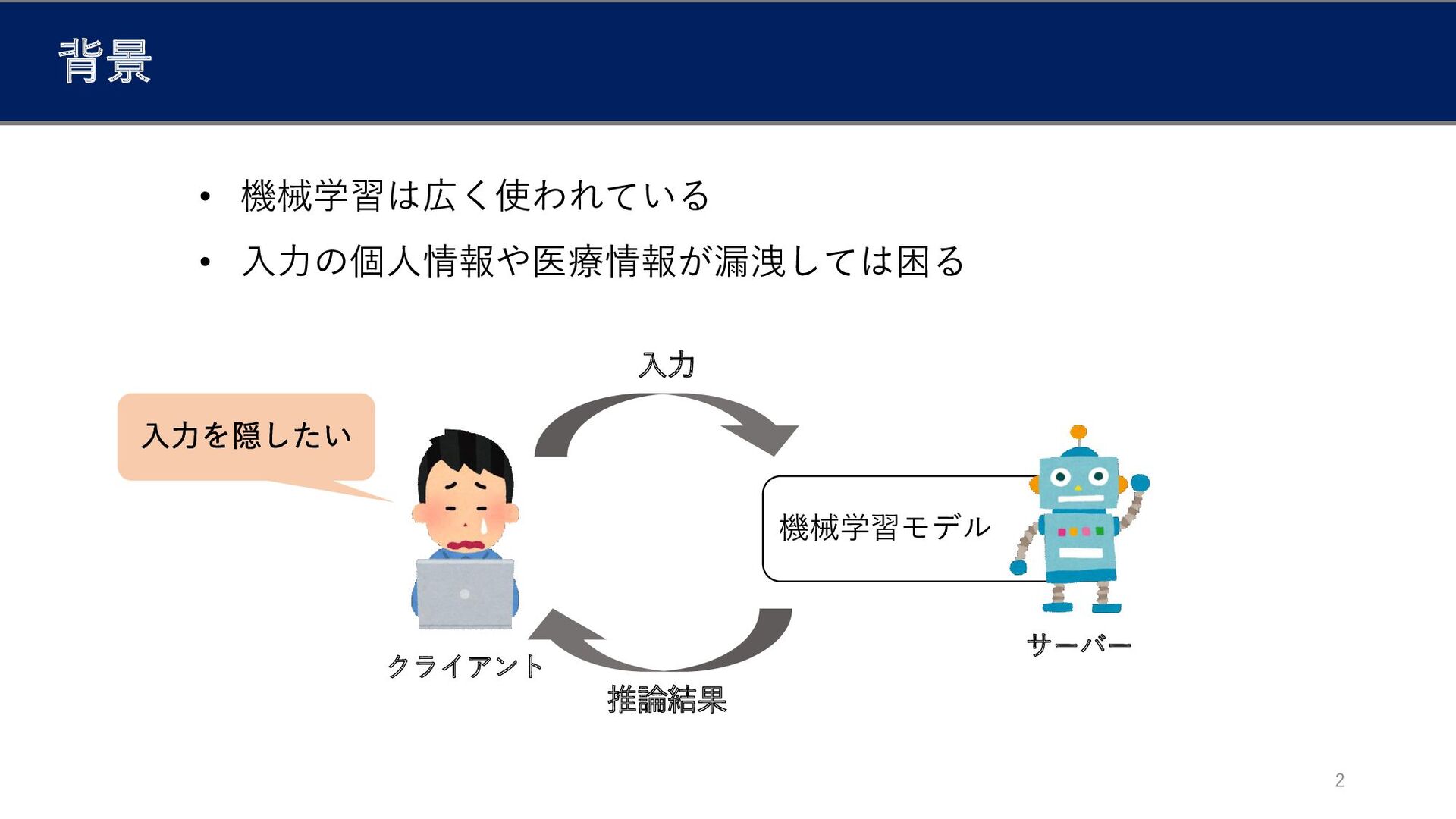
背景 2 • 機械学習は広く使われている • 入力の個人情報や医療情報が漏洩しては困る 機械学習モデル 推論結果 入力 クライアント
サーバー
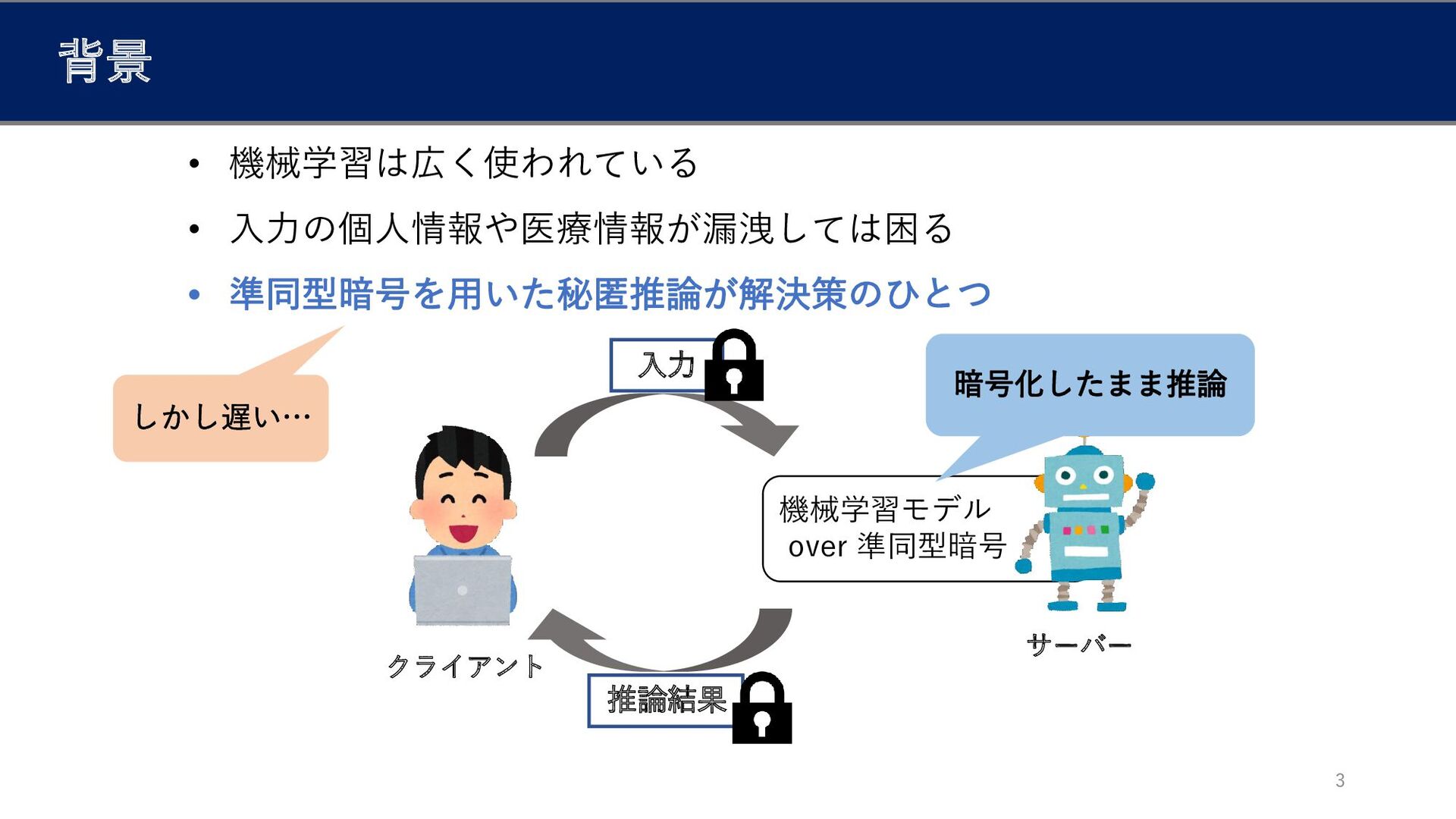
入力 背景 3 • 機械学習は広く使われている • 入力の個人情報や医療情報が漏洩しては困る 機械学習モデル over 準同型暗号
推論結果 クライアント サーバー
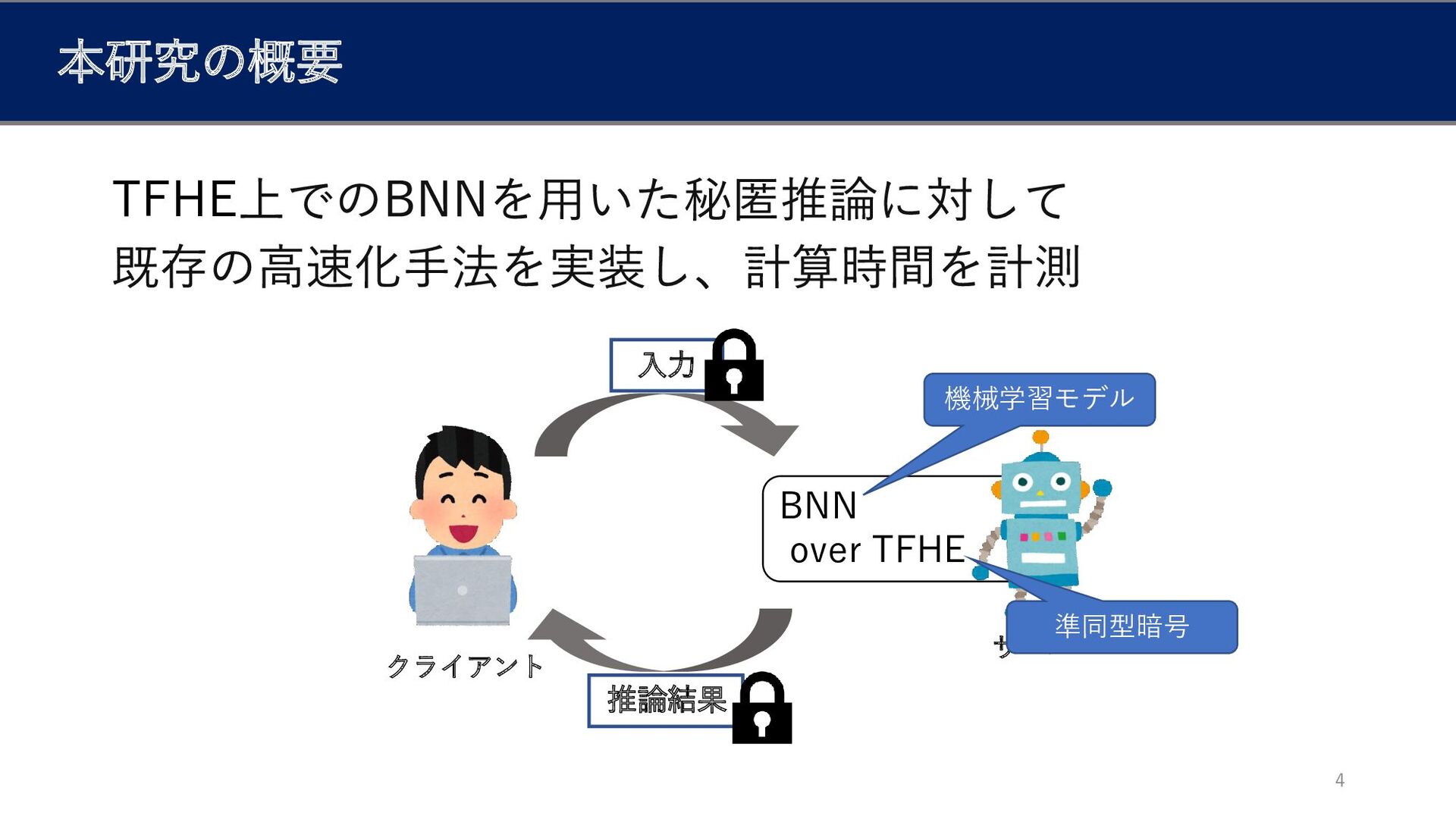
入力 本研究の概要 4 BNN over TFHE 推論結果 TFHE クライアント サーバー
機械学習モデル 準同型暗号
• 背景 • TFHE • BNN • BNN over TFHE
• 適用した高速化手法 1. 3値化による精度向上と高速化 2. BATによる線形層の高速化 3. SBNの前計算による精度向上 • 実験 本発表の流れ 5
• 背景 • TFHE • BNN • BNN over TFHE
本発表の流れ 6
TFHE:概要 • TFHEとは? • Torus Fully Homomorphic Encryption[1] • データを暗号化したまま計算を行える
完全準同型暗号(FHE)の一種 7 入力 入力 出力 出力 計算 計算 [1] Chillotti, I., Gama, N., Georgieva, M. and Izabach`ene, M.: TFHE: Fast Fully Homomorphic Encryption Over the Torus,J. Cryptol., Vol. 33, No. 1, pp. 34–91 (2020) 暗号化 復号
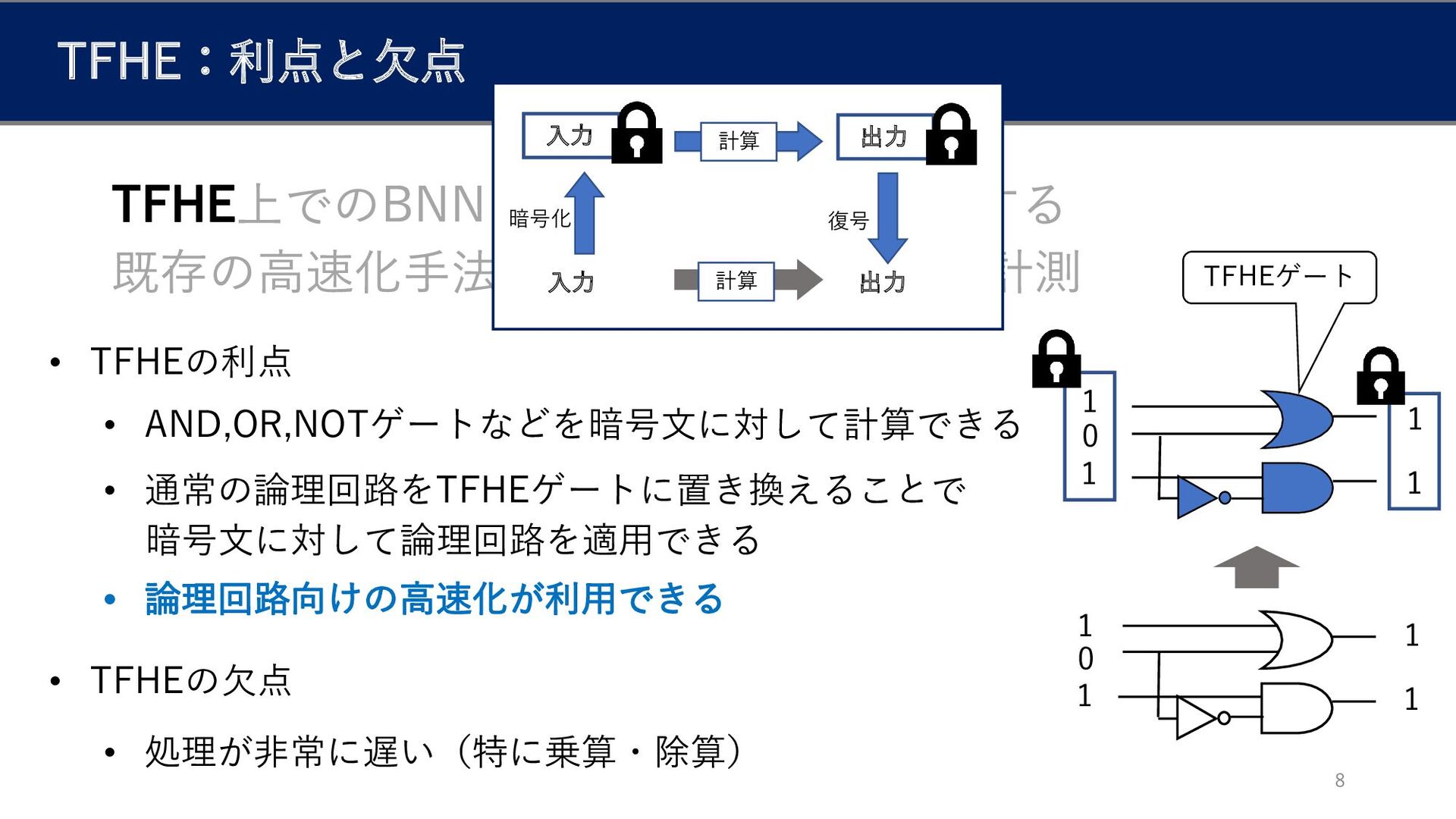
TFHE:利点と欠点 8 • TFHEの利点 • AND,OR,NOTゲートなどを暗号文に対して計算できる • 通常の論理回路をTFHEゲートに置き換えることで 暗号文に対して論理回路を適用できる •
TFHEの欠点 • 処理が非常に遅い(特に乗算・除算) 0 1 1 1 1 0 1 1 1 1 TFHEゲート 入力 入力 出力 出力 計算 計算 暗号化 復号
BNN:概要 • BNNとは? • Binarized Neural Network[2] • 通常のNNを低ビット幅で表現 今回は特に1ビット、2ビットで扱う
9 −0.5 1.3 +1 −1 2値化 [2] Courbariaux, M. and Bengio, Y.: BinaryNet: Training DeepNeural Networks with Weights and Activations Constrained to+1 or−1,CoRR, Vol. abs/1602.02830 (2016)
BNN:低ビット幅表現による利点と欠点 • BNNの利点 • 論理回路として簡潔に表現できる • 低ビット幅のため推論が高速 • BNNの欠点 •
浮動小数点数を低ビット幅で近似するため精度が悪くなる 10
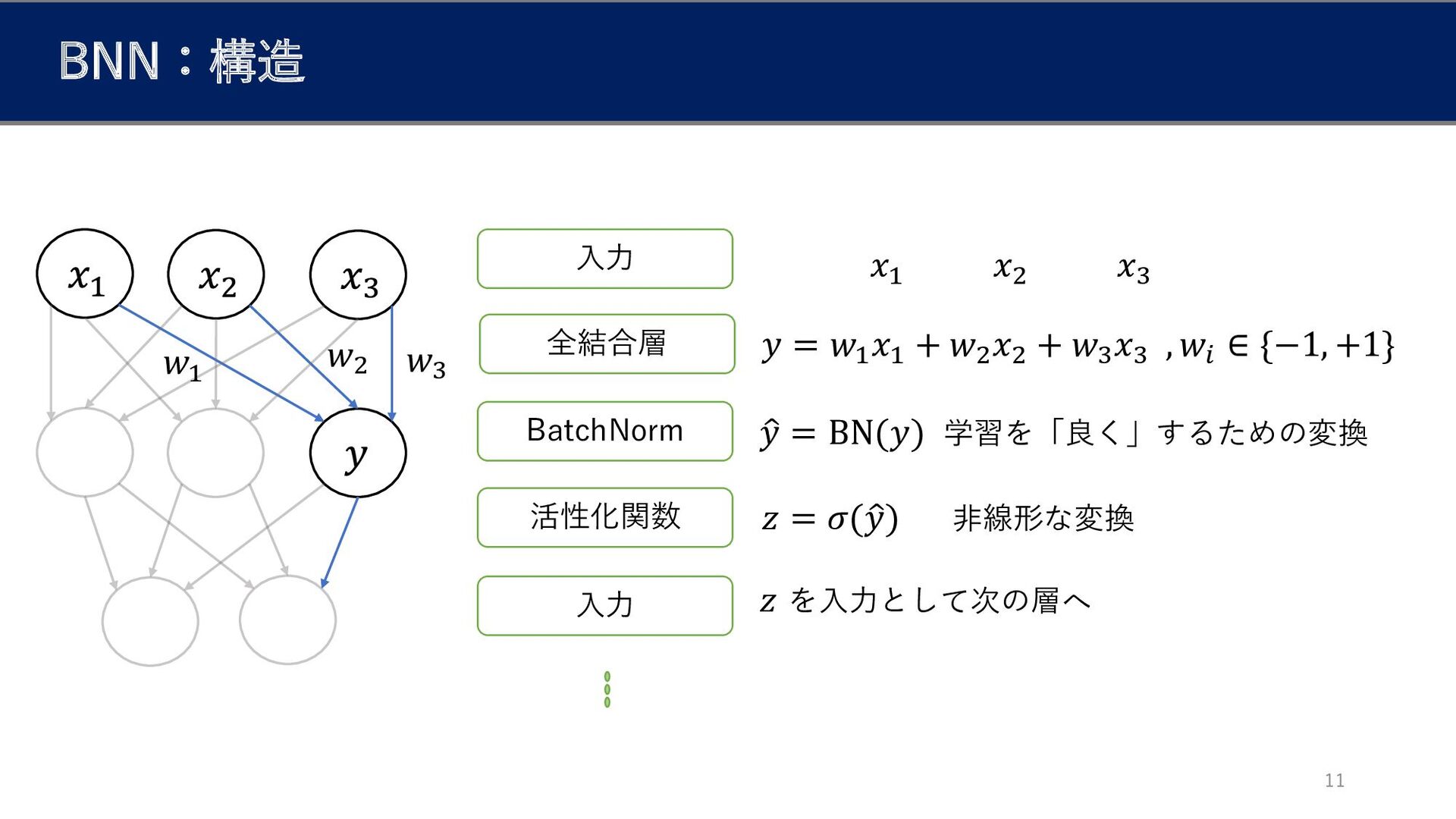
BNN:構造 𝑤1 𝑤2 𝑤3 入力 全結合層 BatchNorm 活性化関数 入力 𝑦
= 𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝑤3 𝑥3 , 𝑤𝑖 ∈ {−1, +1} 𝑥1 𝑥2 𝑥3 ො 𝑦 = BN(𝑦) 学習を「良く」するための変換 𝑧 = 𝜎(ො 𝑦) 非線形な変換 𝑧 を入力として次の層へ 11
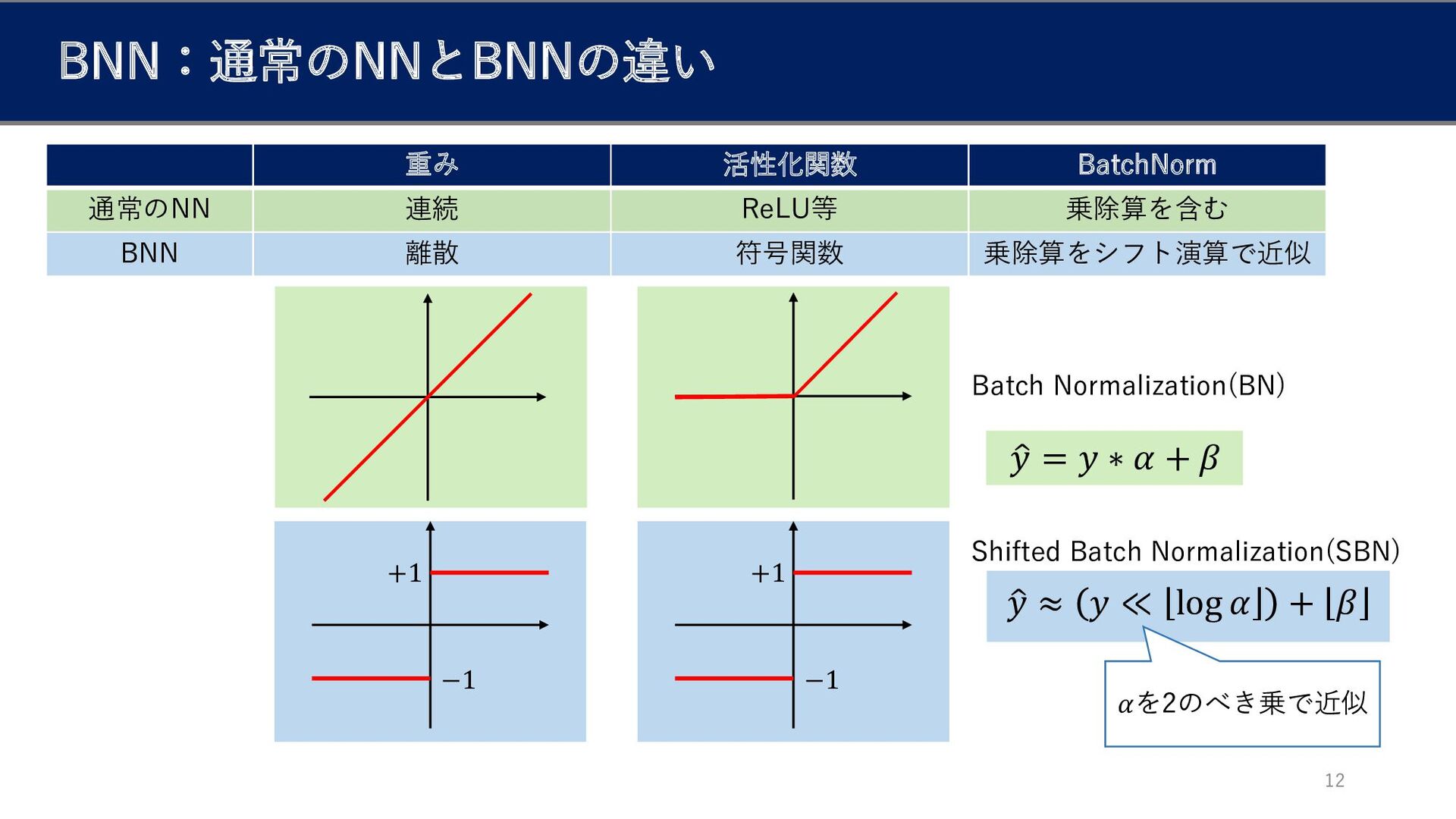
b BNN:通常のNNとBNNの違い 重み 活性化関数 BatchNorm 通常のNN 連続 ReLU等 乗除算を含む BNN
離散 符号関数 乗除算をシフト演算で近似 +1 −1 12 ො 𝑦 = 𝑦 ∗ 𝛼 + 𝛽 ො 𝑦 ≈ 𝑦 ≪ ہ ۂ log 𝛼 + ہ ۂ 𝛽 Batch Normalization(BN) Shifted Batch Normalization(SBN) 𝛼を2のべき乗で近似 +1 −1
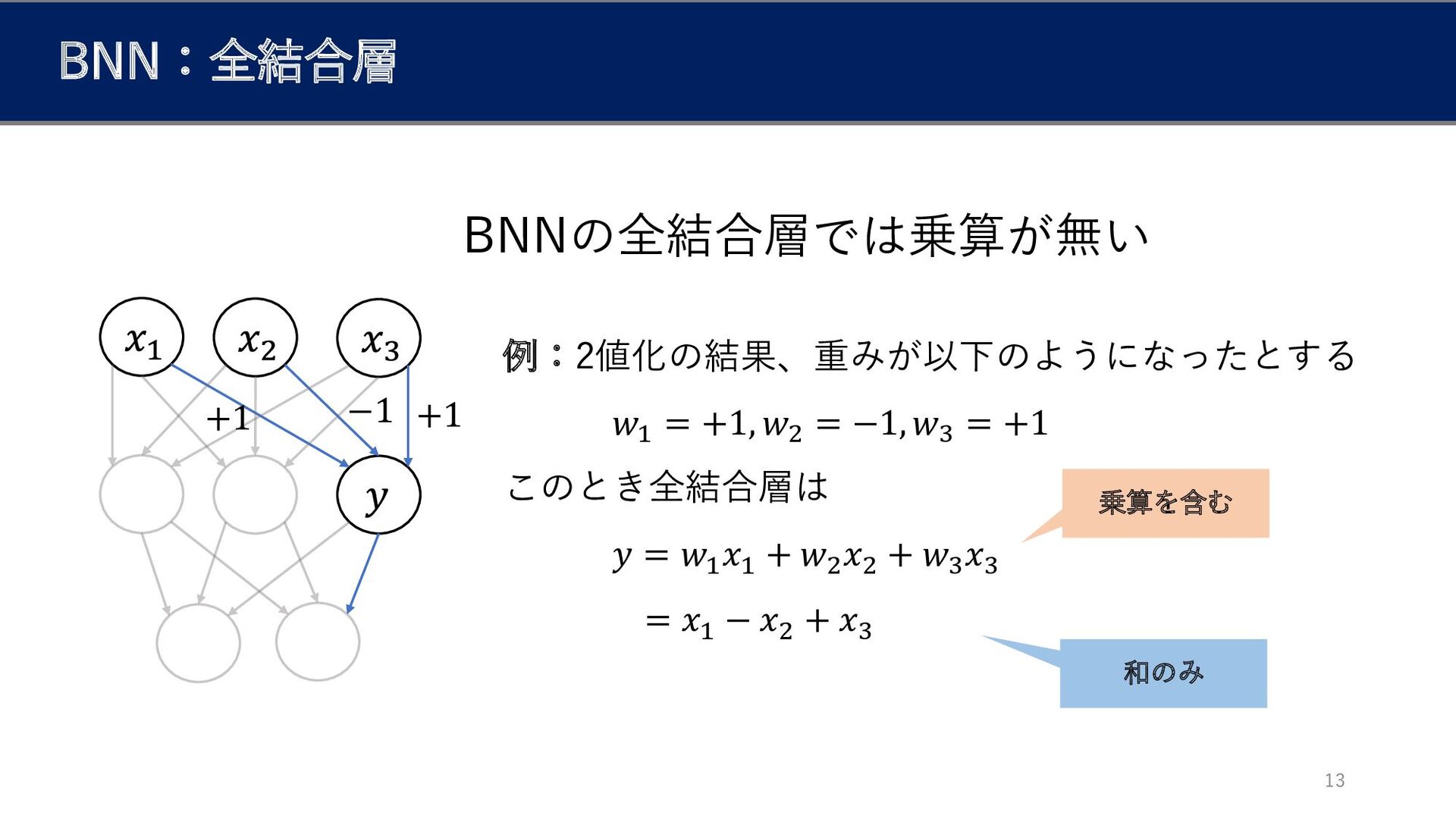
BNN:全結合層 +1 −1 +1 13 例:2値化の結果、重みが以下のようになったとする 𝑤1 = +1, 𝑤2
= −1, 𝑤3 = +1 このとき全結合層は 𝑦 = 𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝑤3 𝑥3 = 𝑥1 − 𝑥2 + 𝑥3 乗算を含む 和のみ BNNの全結合層では乗算が無い
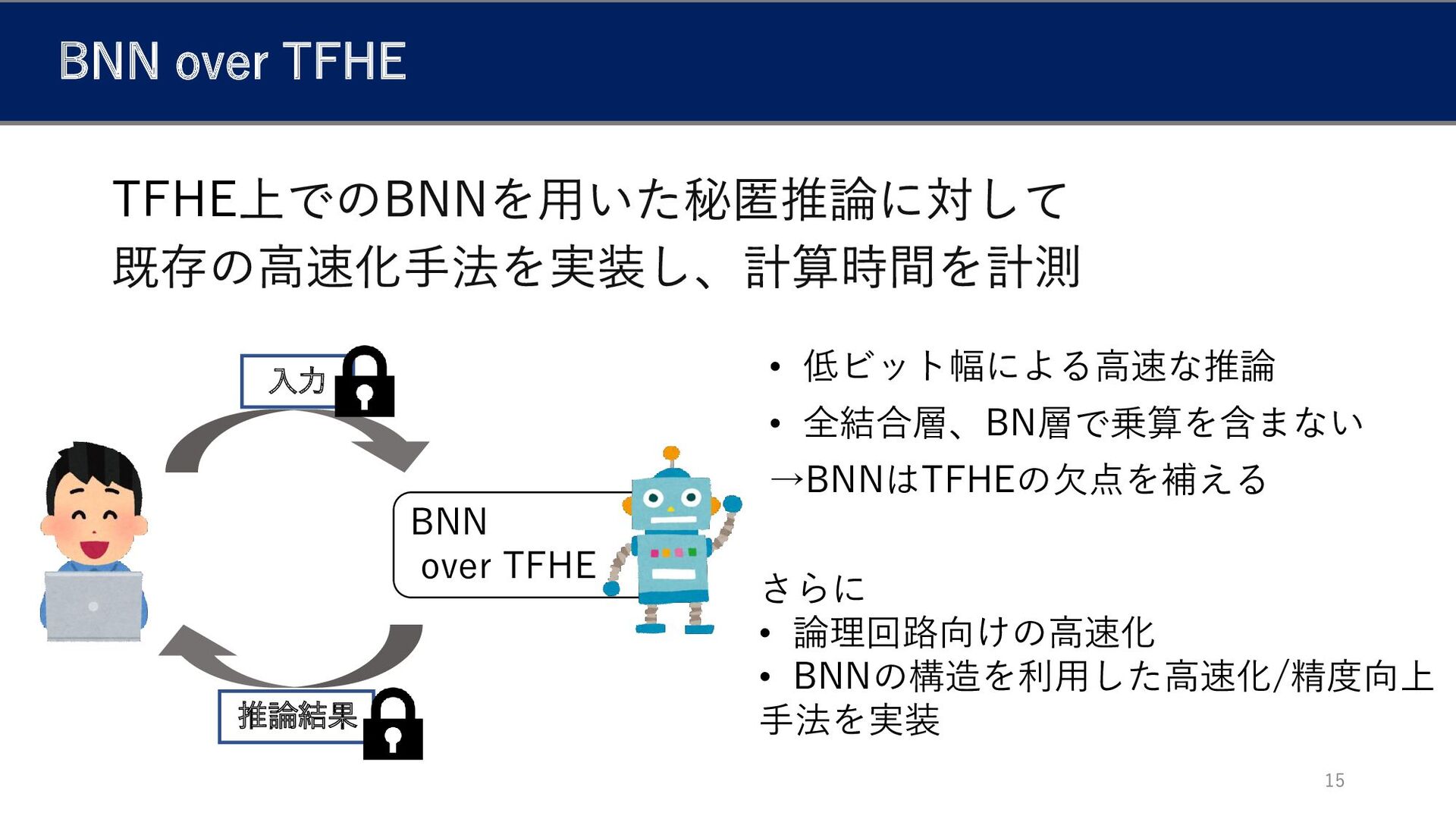
入力 BNN over TFHE:実現方法 14 BNN over TFHE 推論結果 TFHE
入力 BNN over TFHE 15 BNN over TFHE 推論結果 TFHE
• 低ビット幅による高速な推論 • 全結合層、BN層で乗算を含まない →BNNはTFHEの欠点を補える さらに • 論理回路向けの高速化 • BNNの構造を利用した高速化/精度向上 手法を実装
• 適用した高速化手法 1. 3値化による精度向上と高速化 2. BATによる線形層の高速化 3. SBNの前計算による精度向上 本発表の流れ 16
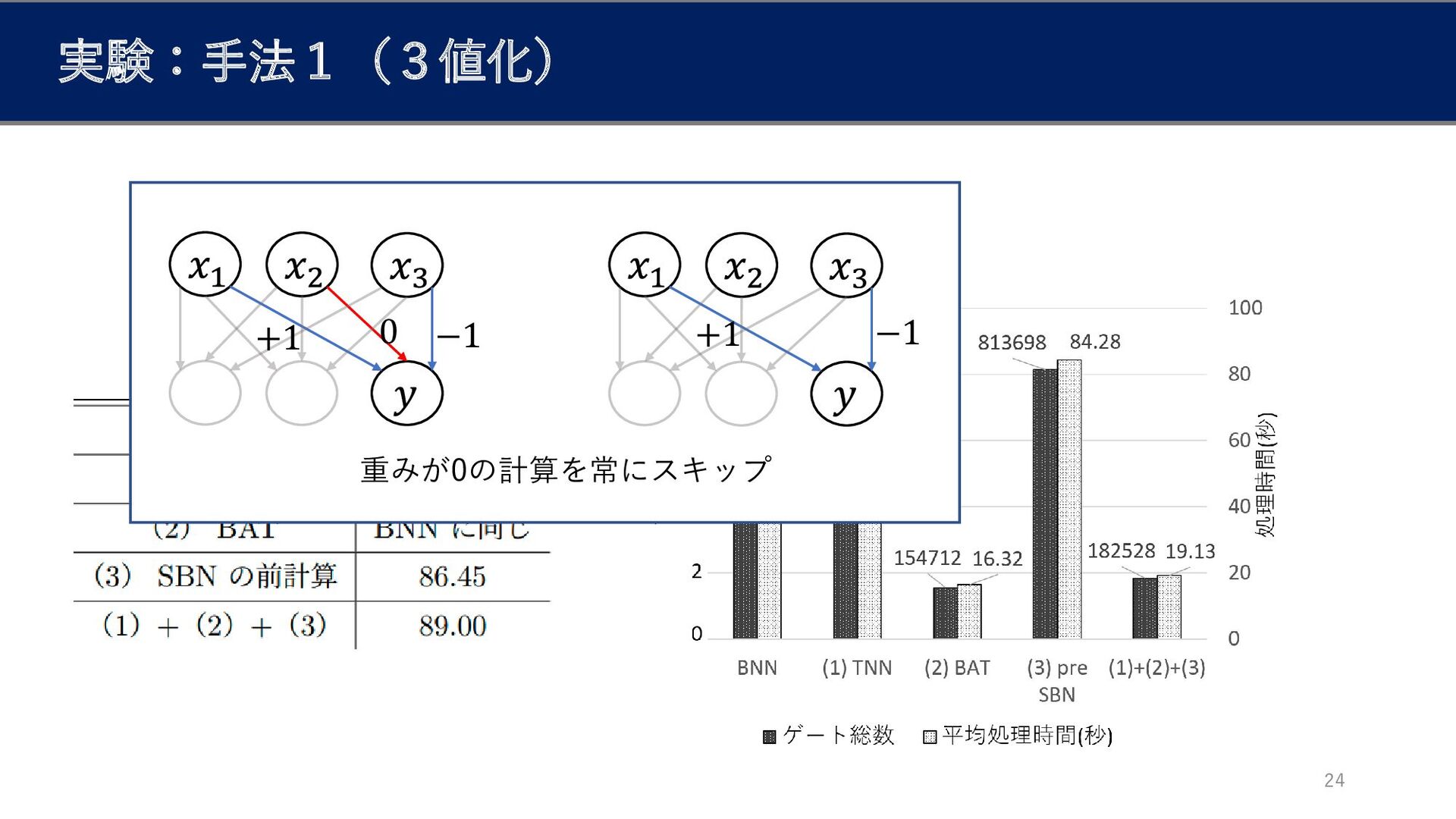
手法1:3値化による精度向上・高速化[3] 17 +1 0 −1 +1 −1 重みが0の計算を常にスキップ 一般に、ビット数を増やすと精度は向上するが計算時間とトレードオフ [3]
Li, F. and Liu, B.: Ternary Weight Networks,CoRR,Vol. abs/1605.04711 (2016)
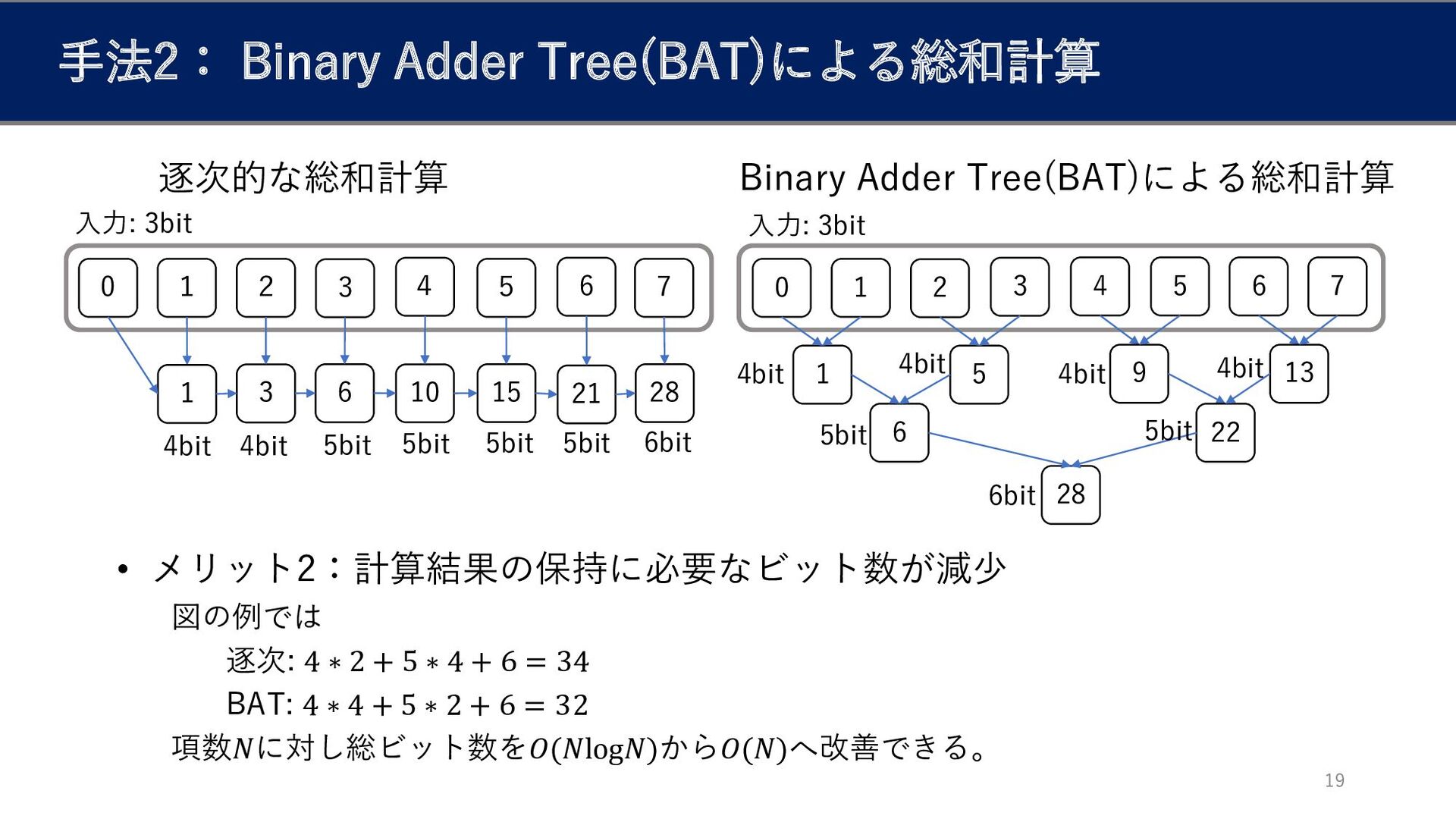
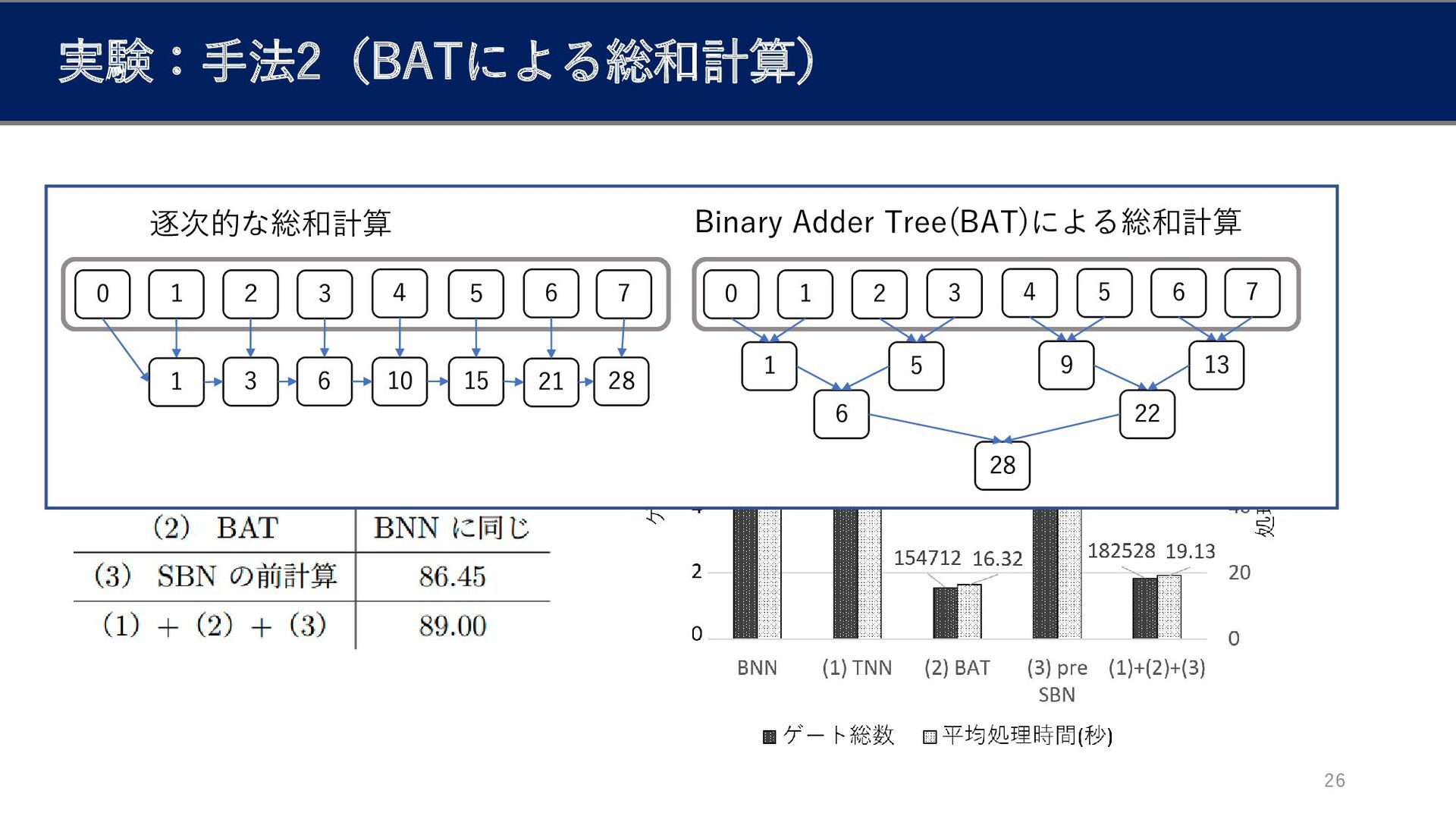
手法2:Binary Adder Tree(BAT)による総和計算[4] 18 1 2 3 4 5 3
6 10 15 0 1 2 3 4 1 5 6 28 • メリット1:並列な実行の余地 同じ層の加算を完全に並列に実行できると仮定すると、 計算時間を項数𝑁に対し𝑂(𝑁)から𝑂(log 𝑁)へ改善できると期待される 5 9 6 21 6 22 7 28 7 13 0 1 逐次的な総和計算 Binary Adder Tree(BAT)による総和計算 全結合層の総和計算を高速化 [4] Fu, C., Huang, H., Chen, X. and Zhao, J.: GateNet: Bridg-ing the gap between Binarized Neural Network and FHE eval-uation,ICLR Workshop on Security and Safety in MachineLearning Systems(2021)
手法2: Binary Adder Tree(BAT)による総和計算 19 入力: 3bit 4bit 5bit 5bit
5bit 入力: 3bit 5bit 4bit 6bit 1 2 3 4 5 3 6 10 15 0 1 2 3 4 1 5 6 28 5 9 6 21 6 22 7 28 7 13 0 1 逐次的な総和計算 Binary Adder Tree(BAT)による総和計算 4bit 5bit • メリット2:計算結果の保持に必要なビット数が減少 図の例では 逐次: 4 ∗ 2 + 5 ∗ 4 + 6 = 34 BAT: 4 ∗ 4 + 5 ∗ 2 + 6 = 32 項数𝑁に対し総ビット数を𝑂(𝑁log𝑁)から𝑂(𝑁)へ改善できる。 4bit 4bit 4bit 5bit 6bit
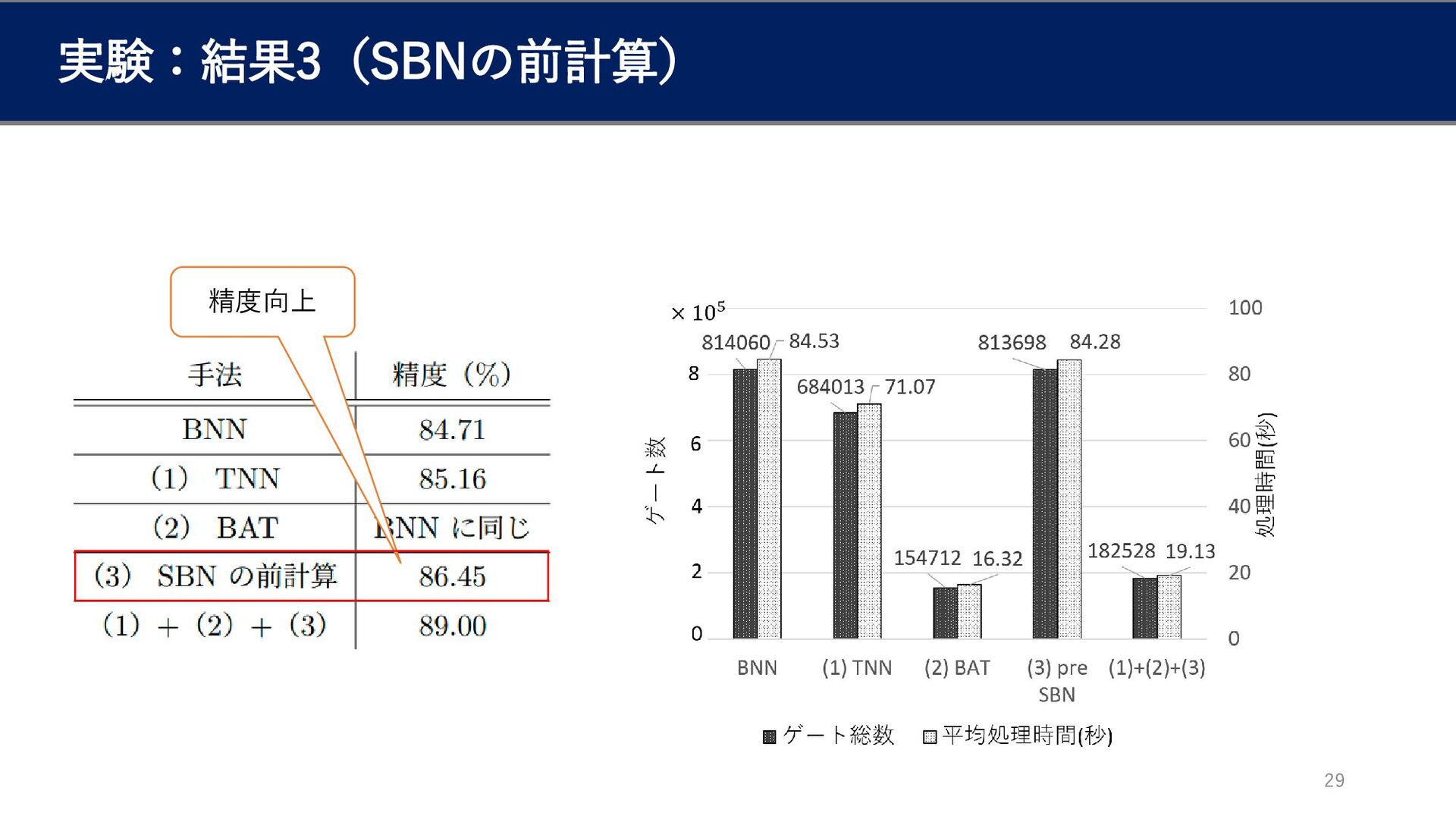
手法3:Shifted BatchNorm(SBN)の前計算[5] 20 BN: ො 𝑦 = 𝛼𝑦 + 𝛽
SBN: ො 𝑦 ≈ 𝑦 ≪ ہ ۂ log 𝛼 + ہ ۂ 𝛽 BatchNorm(BN)層の近似を改善 BatchNorm 活性化関数 ො 𝑦 = 𝛼𝑦 + 𝛽 𝑧 = 𝜎(ො 𝑦) 𝛼を2のべき乗で近似しているのでもとの𝛼から大きく離れる恐れ →精度が低下する原因になる 𝑧 = sign(𝛼𝑦 + 𝛽) = sign(𝑦 + 𝛽/𝛼) − 𝛽/𝛼 を閾値として前計算しておき、閾値以上ならば + 1、未満ならば−1とする [5] Yonekawa, H. and Nakahara, H.: On-Chip Memory Based Bina-rized Convolutional Deep Neural Network Applying Batch Nor-malization Free Technique on an FPGA,IEEE InternationalParallel and Distributed Processing Symposium Workshops,May 29 - June 2, 2017, pp. 98–105 (2017)
• 実験 本発表の流れ 21
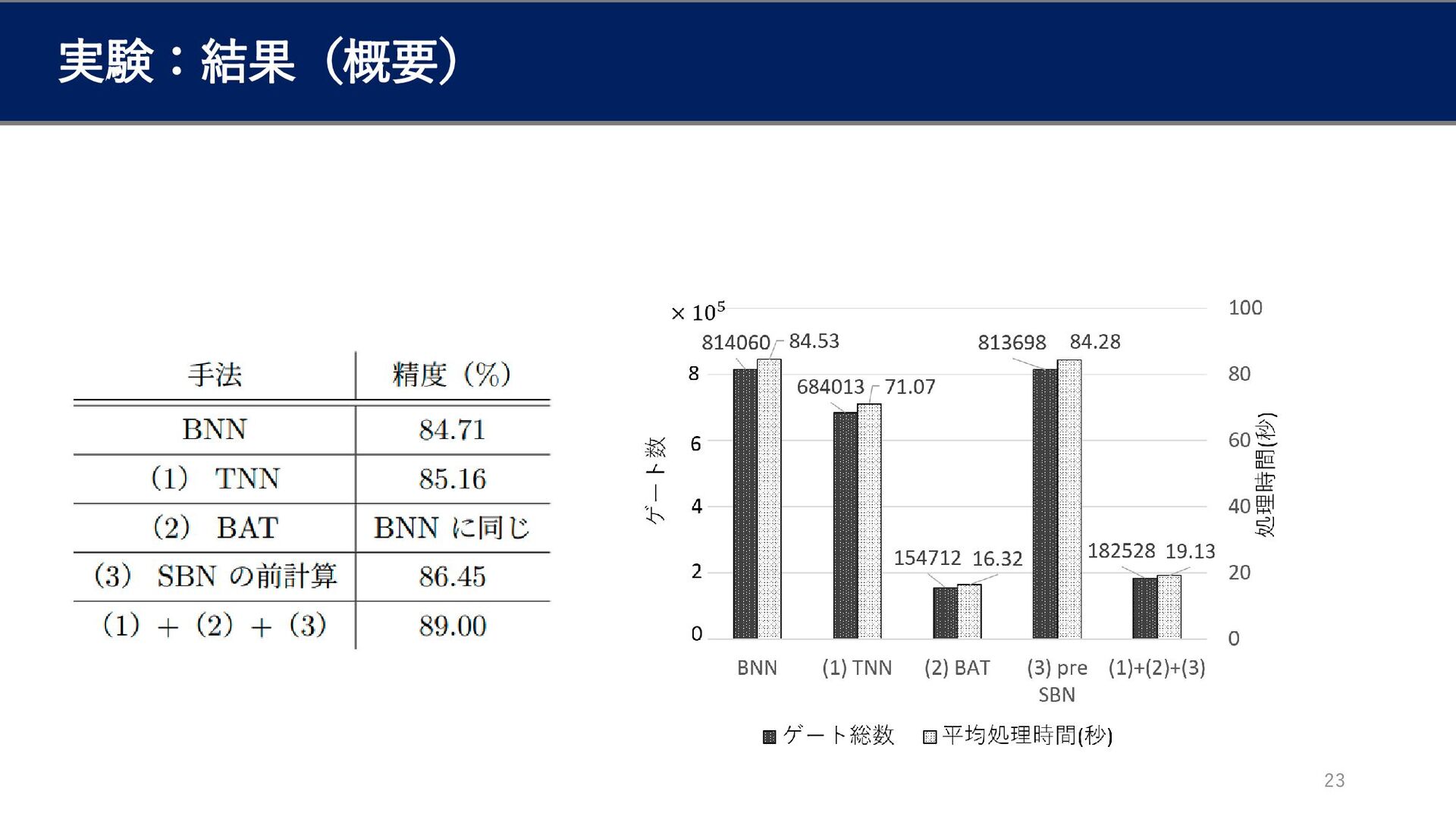
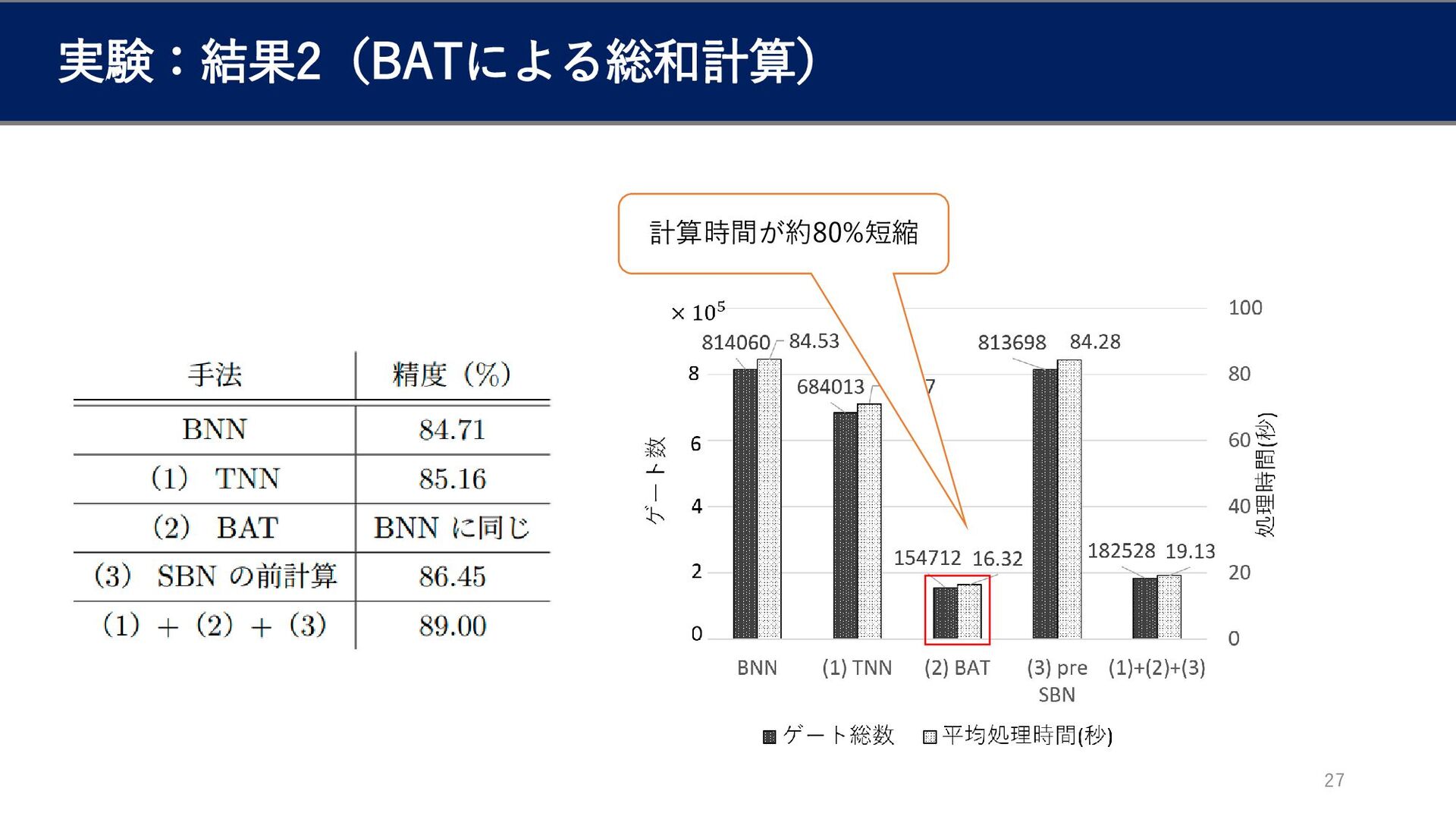
実験:設定 22 モデルの構成: タスク: MNIST • 3手法をどれも用いないもの(ベースライン) • それぞれの手法を一つ用いたもの •
3手法全てを用いたもの で精度と推論時間を計測 実験環境: Intel Xeon Silver 4216(16C32T) 2基 NVIDIA A100 2基 128GB CPU GPU メモリ
実験:結果(概要) 23
実験:手法1(3値化) 24 +1 0 −1 +1 −1 重みが0の計算を常にスキップ
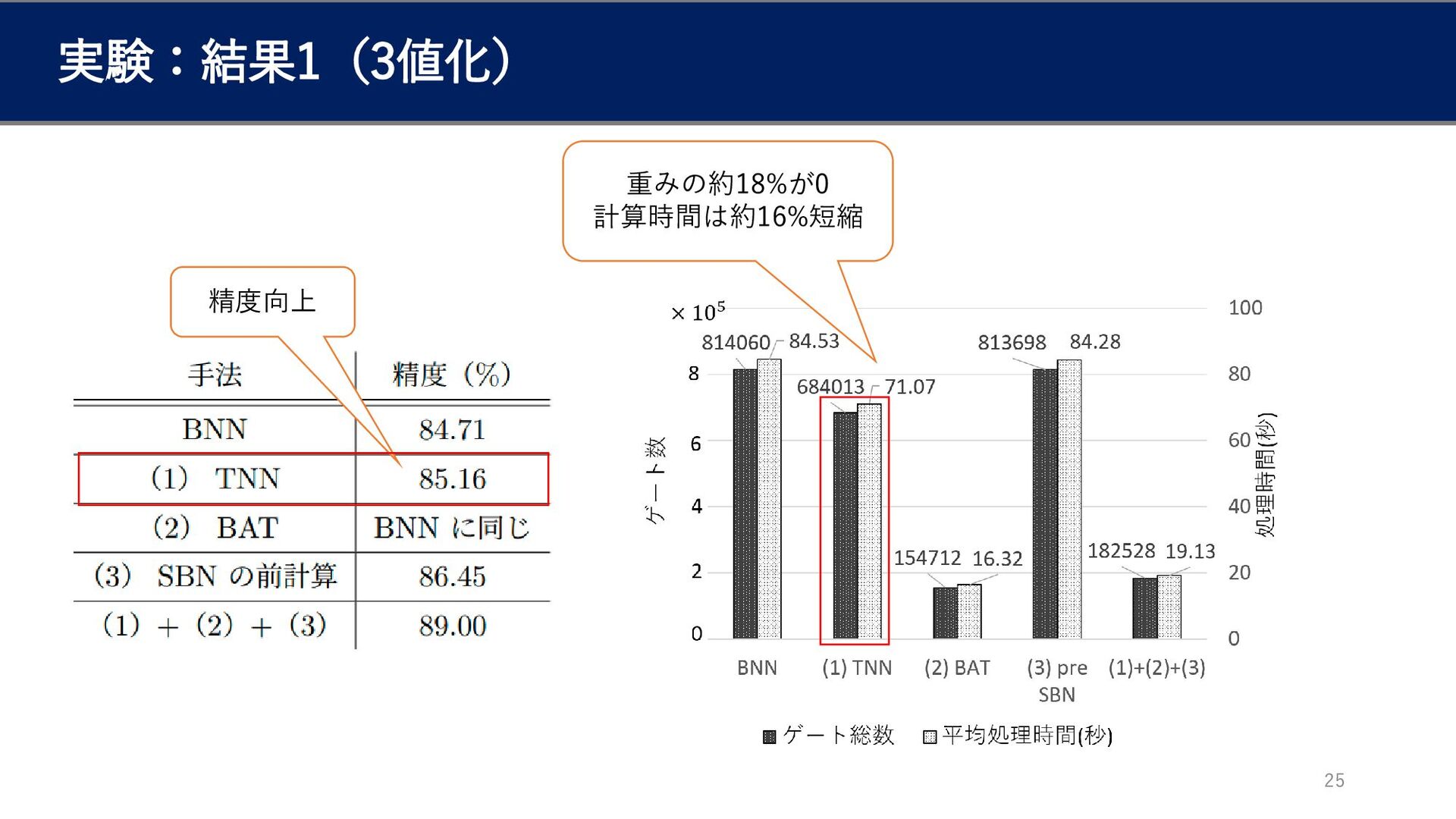
実験:結果1(3値化) 25 重みの約18%が0 計算時間は約16%短縮 精度向上
実験:手法2(BATによる総和計算) 26 1 2 3 4 5 3 6 10
15 0 1 2 3 4 1 5 6 28 5 9 6 21 6 22 7 28 7 13 0 1 逐次的な総和計算 Binary Adder Tree(BAT)による総和計算
実験:結果2(BATによる総和計算) 27 計算時間が約80%短縮
実験:手法3(SBNの前計算) 28 z ො 𝑦 ≈ 𝑦 ≪ ہ ۂ
log 𝛼 + ہ ۂ 𝛽 𝑧 = sign(ො 𝑦) 𝑧 = sign(𝑦 + 𝛽/𝛼 ) SBN:
実験:結果3(SBNの前計算) 29 精度向上
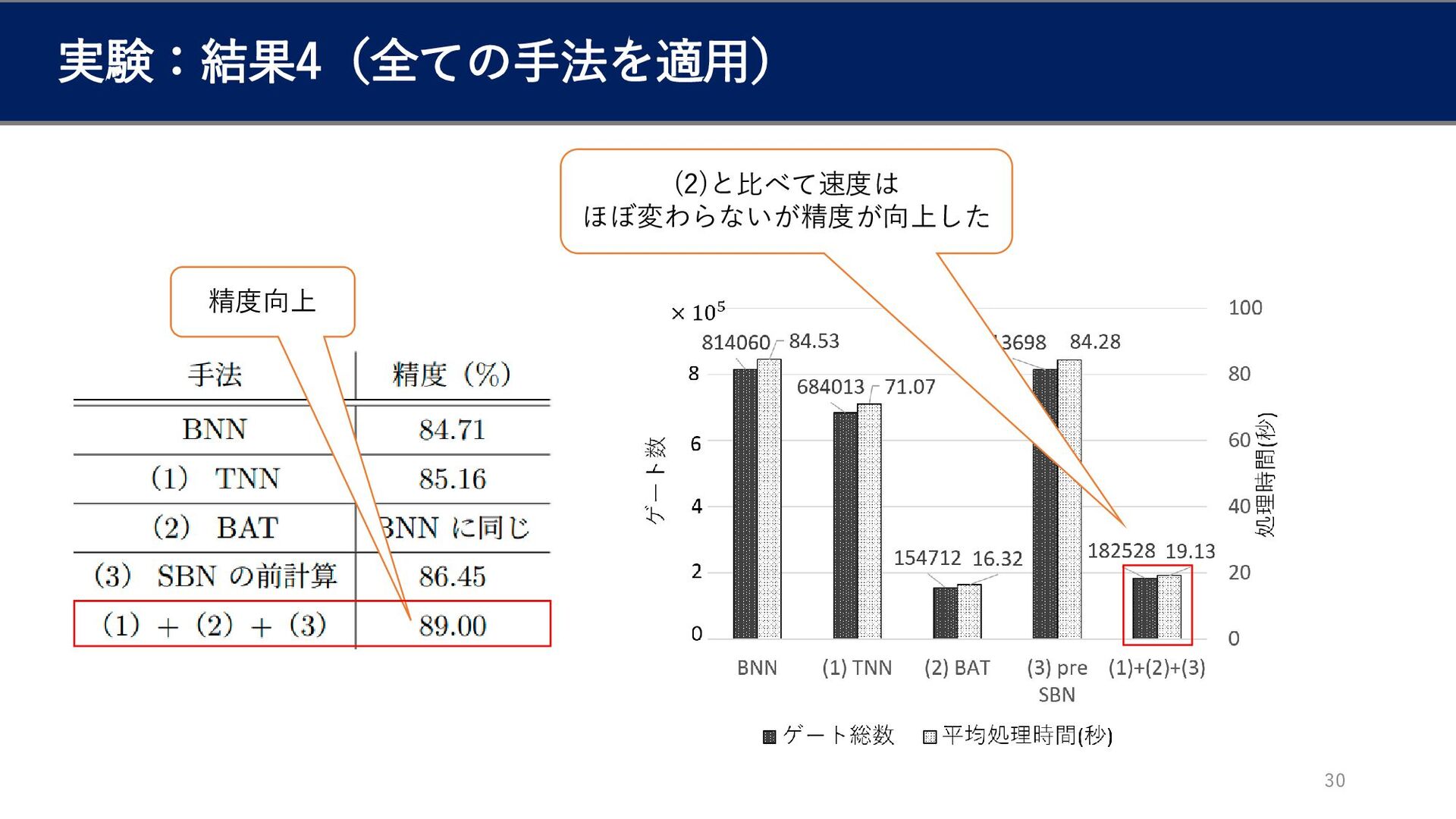
実験:結果4(全ての手法を適用) 30 精度向上 (2)と比べて速度は ほぼ変わらないが精度が向上した
まとめ 31 本研究では • BNN over TFHE の枠組みで 1. 論理回路に対する高速化
2. BNNの構造を利用した高速化、精度向上 手法を実装し、計測した • 精度・計算時間ともに改善することを確認した
32
バックアップ:TFHEの安全性 33 TFHEの安全性はLearning With Errors(LWE)の安全性から推定される セキュリティパラメータは128bitセキュリティが担保されている 古典コンピュータの攻撃に対して LWEでは量子コンピュータの攻撃に対する安全性も推定することができる
バックアップ:BNNの学習方法 34 +1 −1 +1 −1 このままではほとんど至るところ微分が0となり 学習ができない 左のように近似することで学習が可能となる Straight
Through Estimatorという手法
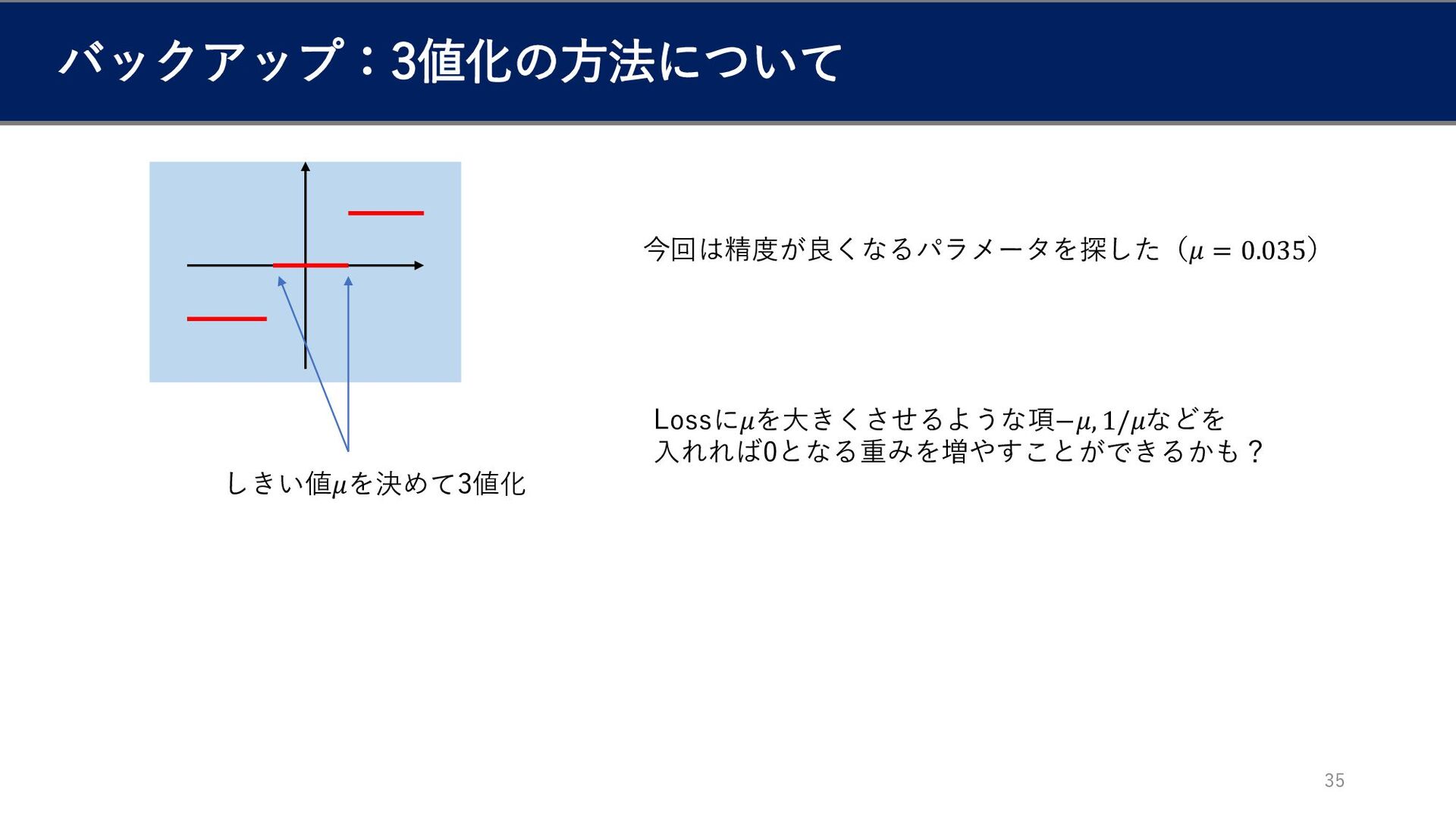
バックアップ:3値化の方法について 35 しきい値𝜇を決めて3値化 今回は精度が良くなるパラメータを探した(𝜇 = 0.035) Lossに𝜇を大きくさせるような項−𝜇, 1/𝜇などを 入れれば0となる重みを増やすことができるかも?
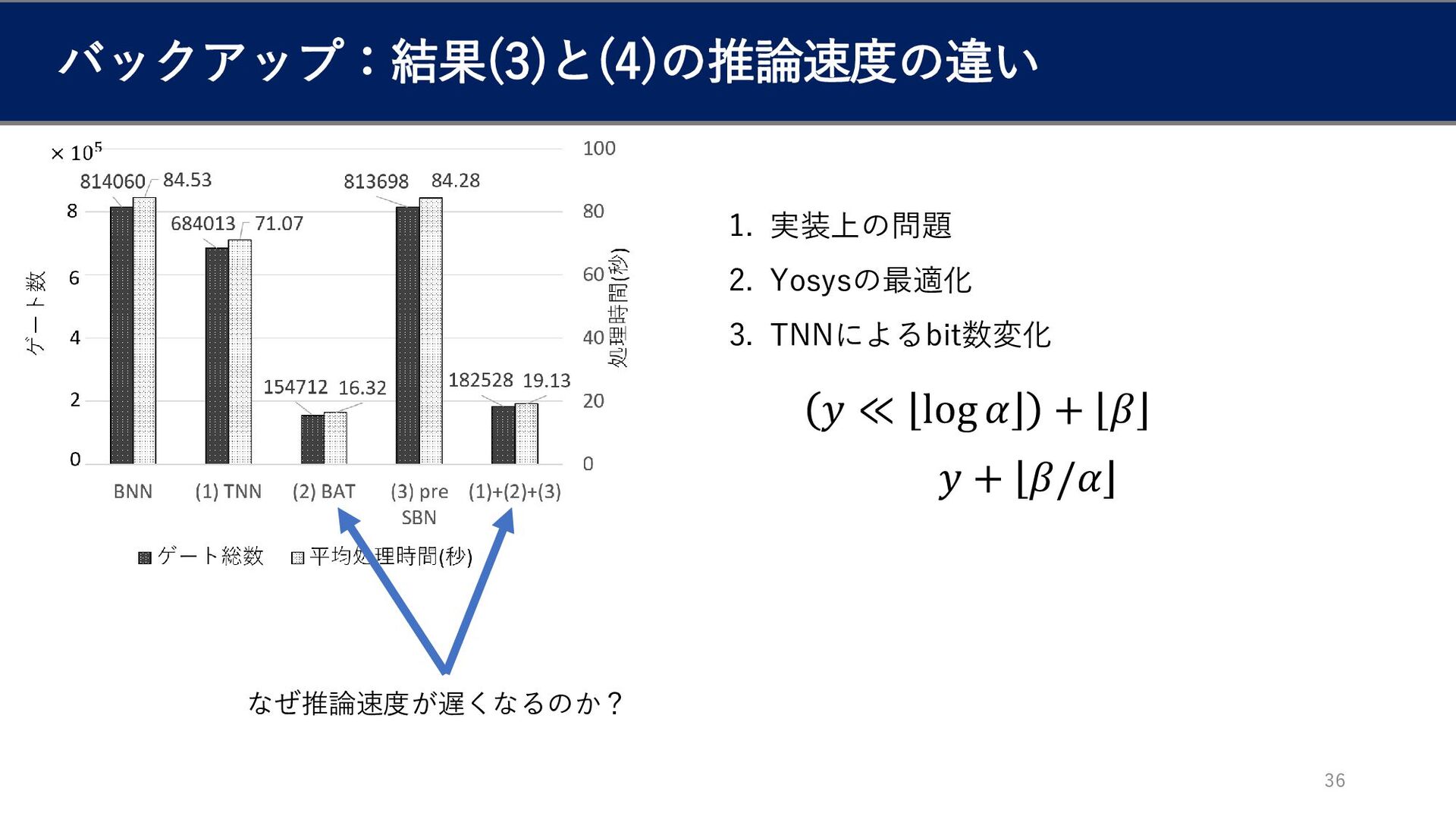
バックアップ:結果(3)と(4)の推論速度の違い 36 なぜ推論速度が遅くなるのか? 𝑦 ≪ ہ ۂ log 𝛼 +
ہ ۂ 𝛽 𝑦 + 𝛽/𝛼 1. 実装上の問題 2. Yosysの最適化 3. TNNによるbit数変化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TFHE:概要 • TFHEとは? • Torus Fully Homomorphic Encryption[1] • データを暗号化したまま計算を行える](https://files.speakerdeck.com/presentations/753f0187cc3840a0b93aecfb75ddfd7a/slide_6.jpg){kind=link}
{kind=link}
![BNN:概要 • BNNとは? • Binarized Neural Network[2] • 通常のNNを低ビット幅で表現 今回は特に1ビット、2ビットで扱う](https://files.speakerdeck.com/presentations/753f0187cc3840a0b93aecfb75ddfd7a/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![手法1:3値化による精度向上・高速化[3] 17 +1 0 −1 +1 −1 重みが0の計算を常にスキップ 一般に、ビット数を増やすと精度は向上するが計算時間とトレードオフ [3]](https://files.speakerdeck.com/presentations/753f0187cc3840a0b93aecfb75ddfd7a/slide_16.jpg){kind=link}
![手法2:Binary Adder Tree(BAT)による総和計算[4] 18 1 2 3 4 5 3](https://files.speakerdeck.com/presentations/753f0187cc3840a0b93aecfb75ddfd7a/slide_17.jpg){kind=link}
{kind=link}
![手法3:Shifted BatchNorm(SBN)の前計算[5] 20 BN: ො 𝑦 = 𝛼𝑦 + 𝛽](https://files.speakerdeck.com/presentations/753f0187cc3840a0b93aecfb75ddfd7a/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}