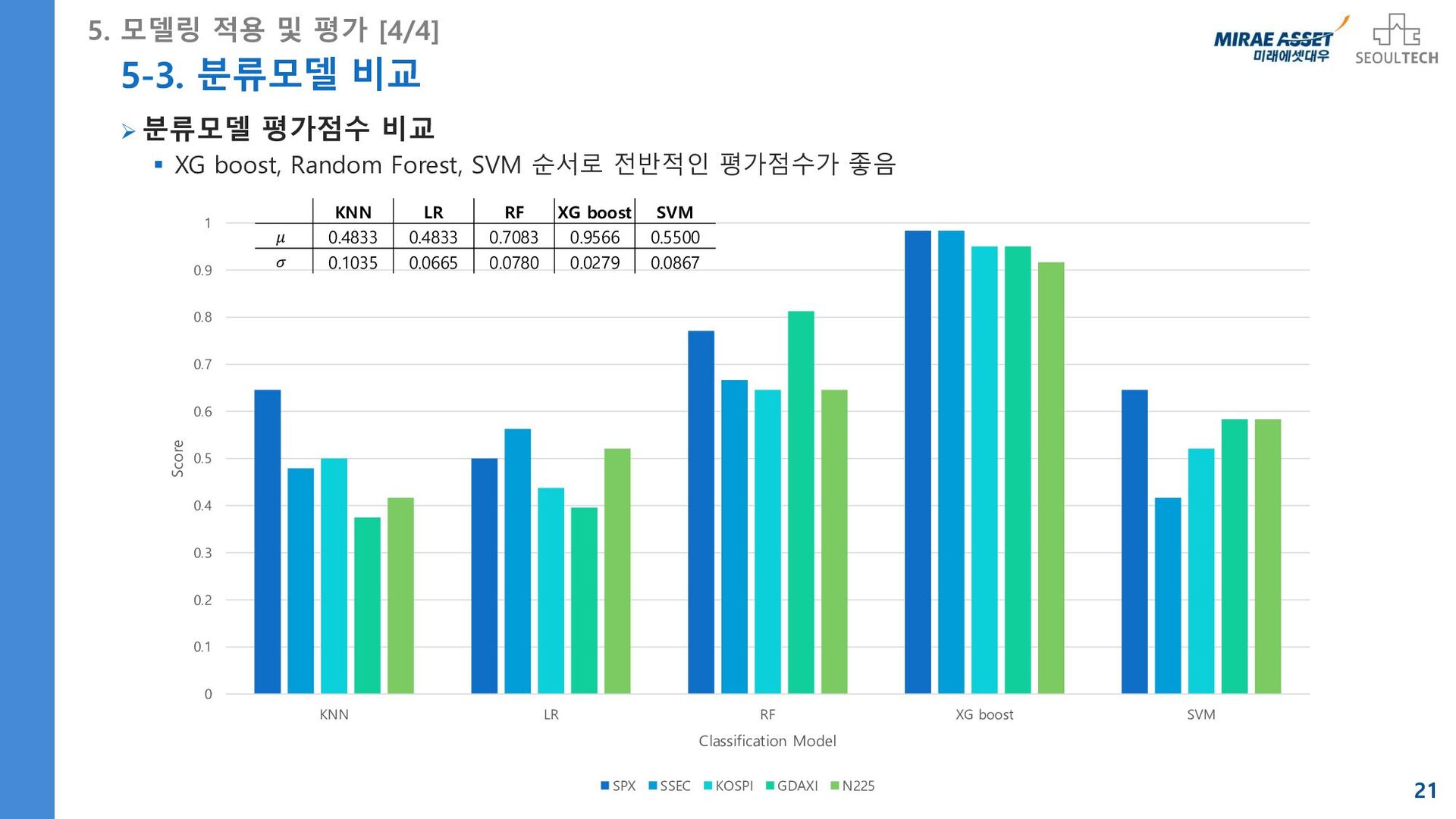
SVM Classifier ▪ 𝐶 = 10−2, 10−1, 1, 10, 102 , 𝛾 = {10−2, 10−1, 1, 10, 102} 20 5. 모델링 적용 및 평가 [3/4] * 매개변수 조합 생략, 최종 매개변수 튜닝 결과 {SVM} SPX SSEC KOSPI GDAXI N225 Score 0.6458 0.4166 0.5208 0.5833 0.5833 Params {'C': 0.01, 'gamma': 0.01} {'C': 0.01, 'gamma': 0.01} {'C': 0.01, 'gamma': 0.01} {'C': 0.01, 'gamma': 0.01} {'C': 0.01, 'gamma': 0.01} {XG boost} SPX SSEC KOSPI GDAXI N225 Score 0.9833 0.9833 0.9500 0.9500 0.9166 Params {'n_estimators':160, 'learning_rate': 0.1, 'reg_alpha':0, 'subsample': 0.76, 'max_depth': 3, 'colsample_bytree': 0.8, 'min_child_weight': 4, 'objective' :'binary:lo gistic', 'scale_pos_weight':1, 'max_delta_step':0, 'gamma' : 0.1} {'n_estimators':160, 'learning_rate': 0.005, 'reg_alpha':0, 'subsample': 0.59, 'max_depth': 3, 'colsample_bytree': 0.4 'min_child_weight': 4, 'objective' : 'binary:logistic', 'scale_pos_weight':1, 'max_delta_step':0, 'gamma' :0.1} {'n_estimators':160, 'learning_rate': 0.1, 'reg_alpha':0, 'subsample': 0.78, 'max_depth': 3, 'colsample_bytree': 0.59, 'min_child_weight': 5, 'objective' :'binary:lo gistic', 'scale_pos_weight':1, 'max_delta_step':0, 'gamma' : 0.1} {'n_estimators':160, 'learning_rate':0.1, 'reg_alpha':0, 'subsample': 0.68, 'max_depth': 3, 'colsample_bytree': 0.51, 'min_child_weight': 2, 'objective' :'binary:lo gistic', 'scale_pos_weight':1, 'max_delta_step':0, 'gamma' :0.1} {'n_estimators':160, 'learning_rate': 0.1, 'reg_alpha':0, 'subsample': 0.44, 'max_depth':4, 'colsample_bytree': 0.64, 'min_child_weight': 0, 'objective' :'binary:lo gistic', 'scale_pos_weight':1, 'max_delta_step':0, 'gamma' : 0.1}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1. 분석 개요 [1/2] ➢ 글로벌 주가지수의 매 월 종가변동을](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_4.jpg){kind=link}
![1. 분석 개요 [2/2] ➢ 알고리즘 학습데이터 구조 ▪ 매달](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_5.jpg){kind=link}
![2-1. 대회제공 데이터 구조화 [1/2] ➢ 메타데이터 생성 및 DB](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_6.jpg){kind=link}
![2-1. 대회제공 데이터 구조화 [2/2] ➢ 데이터그룹과 목적변수의 대응(mapping) ▪](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![3-2. 내생변수 수집 및 전처리 [1/2] ➢ (Step 1) 수집](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_11.jpg){kind=link}
![3-2. 내생변수 수집 및 전처리 [2/2] ➢ 결측 데이터 1차](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
![4-2. 외생변수 수집 및 전처리 [1/2] ➢ CNN 주요 뉴스기사](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_15.jpg){kind=link}
![4-2. 외생변수 수집 및 전처리 [2/2] ➢ 특정 시점의 감정](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_16.jpg){kind=link}
{kind=link}
![5-2. 최적 매개변수 탐색 [1/2] ➢ KNN Classifier ▪ 𝑘](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_18.jpg){kind=link}
![5-2. 최적 매개변수 탐색 [2/2] ➢ XG boost Classifier ➢](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
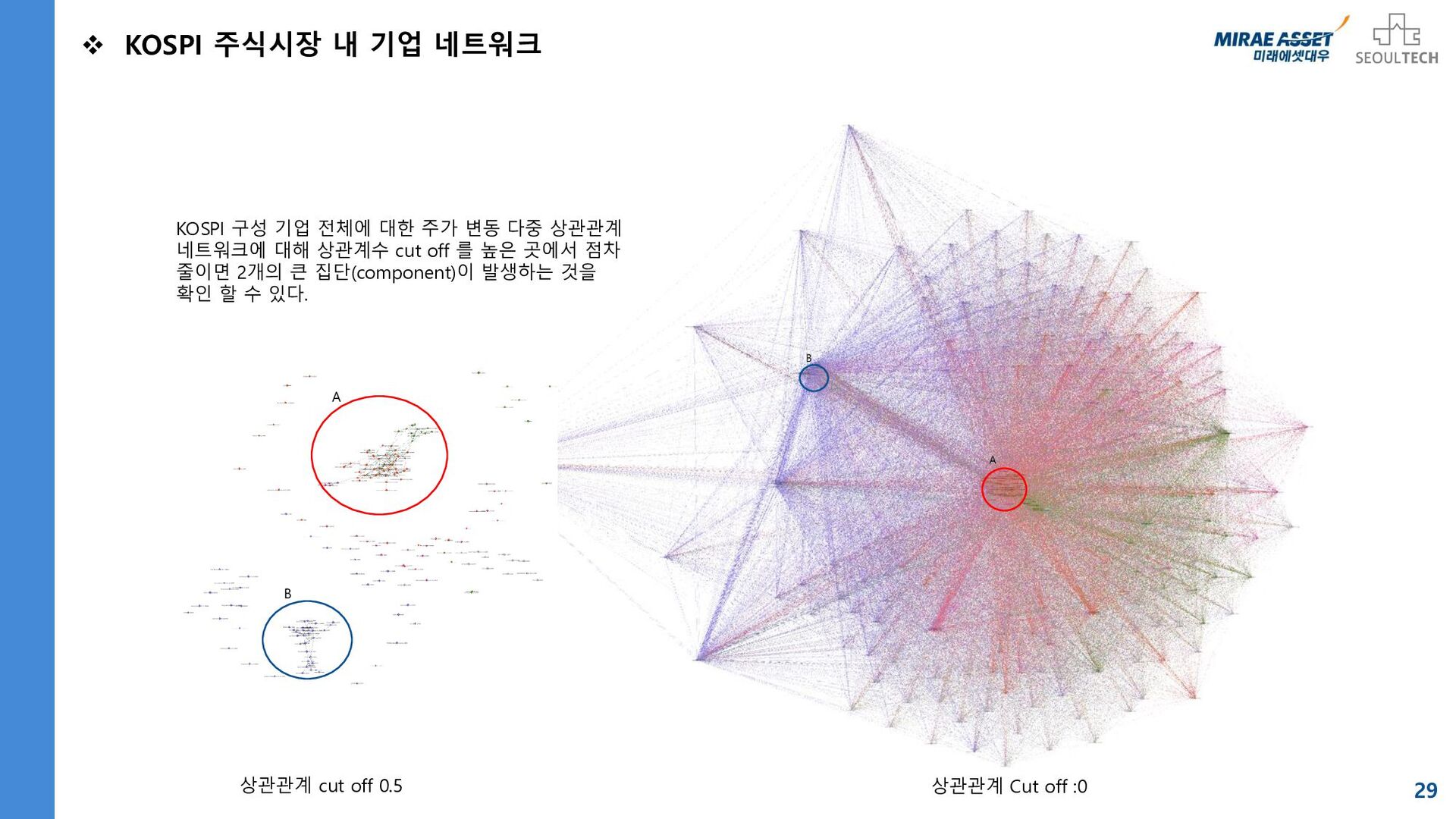
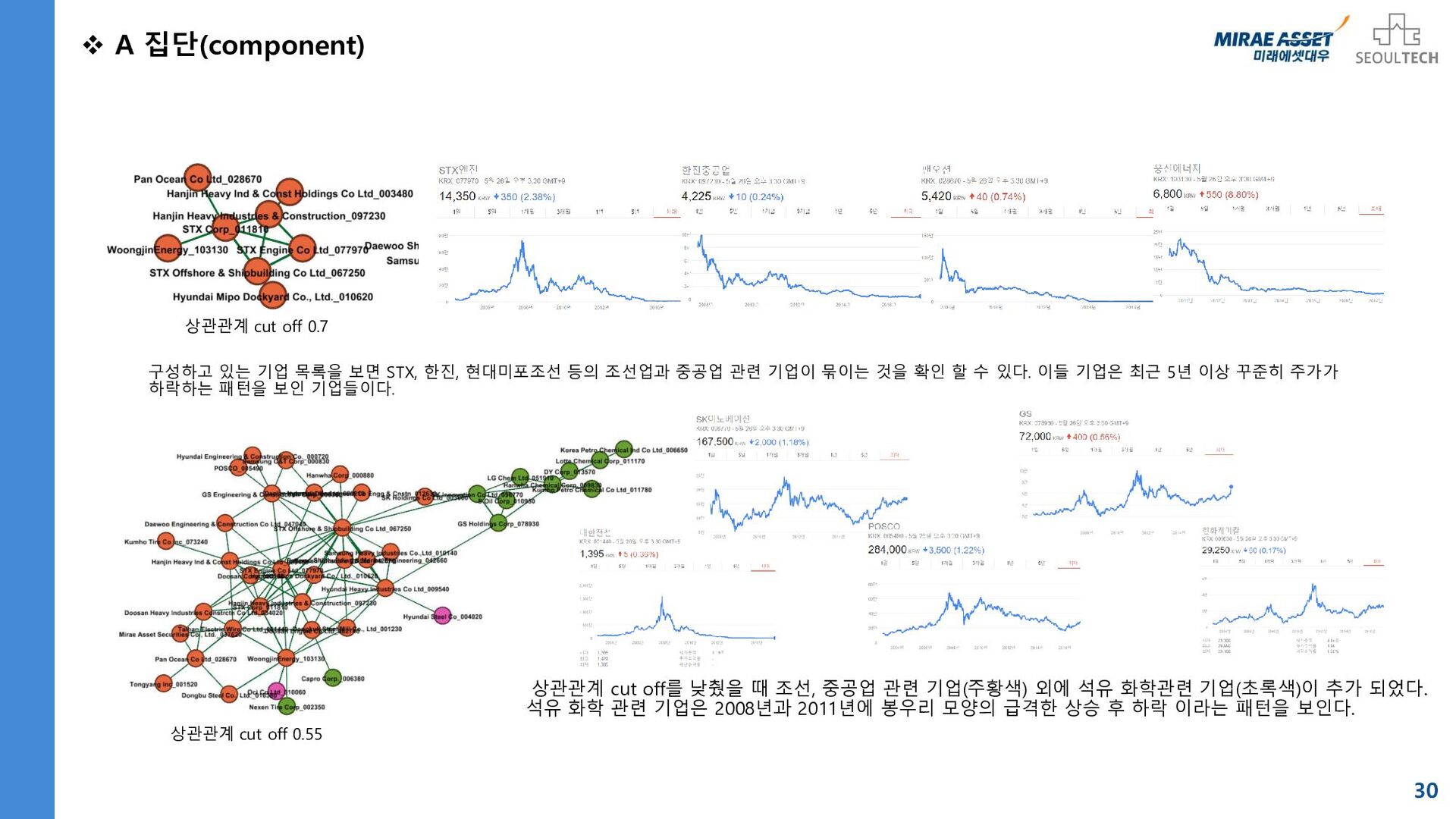
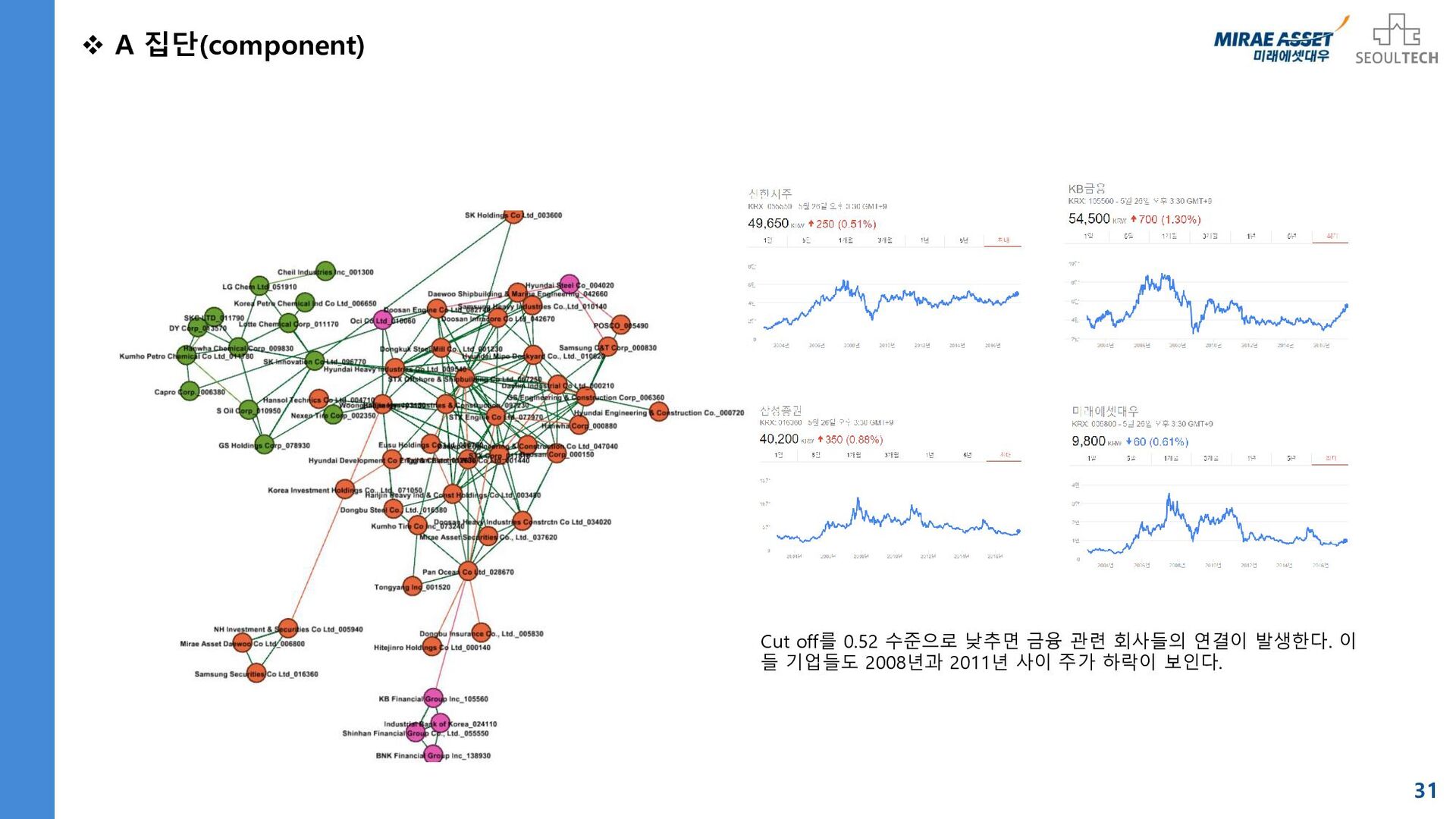
![별첨 목차 23 1. 국가별 경제지표 네트워크 1-1. [한국경제] KOSPI,](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_22.jpg){kind=link}
![24 ❖ [한국경제] KOSPI, KR_INDEX 경제지표 네트워크 한국경제와 관련된 경제지표](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_23.jpg){kind=link}
![25 ❖ [미국경제] SPX, US_INDEX 경제지표 네트워크 미국 경제지표 네트워크는](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_24.jpg){kind=link}
![26 ❖ [중국경제] SSEC, CN_INDEX 경제지표 네트워크 중국 경제지표 네트워크는](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_25.jpg){kind=link}
![27 ❖ [일본경제] N225, JP_INDEX 경제지표 네트워크](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_26.jpg){kind=link}
![28 ❖ [독일경제] GDAXI, DE_INDEX 경제지표 네트워크](https://files.speakerdeck.com/presentations/ff052ac0fcff4f5ea413a0aaa4b24d45/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
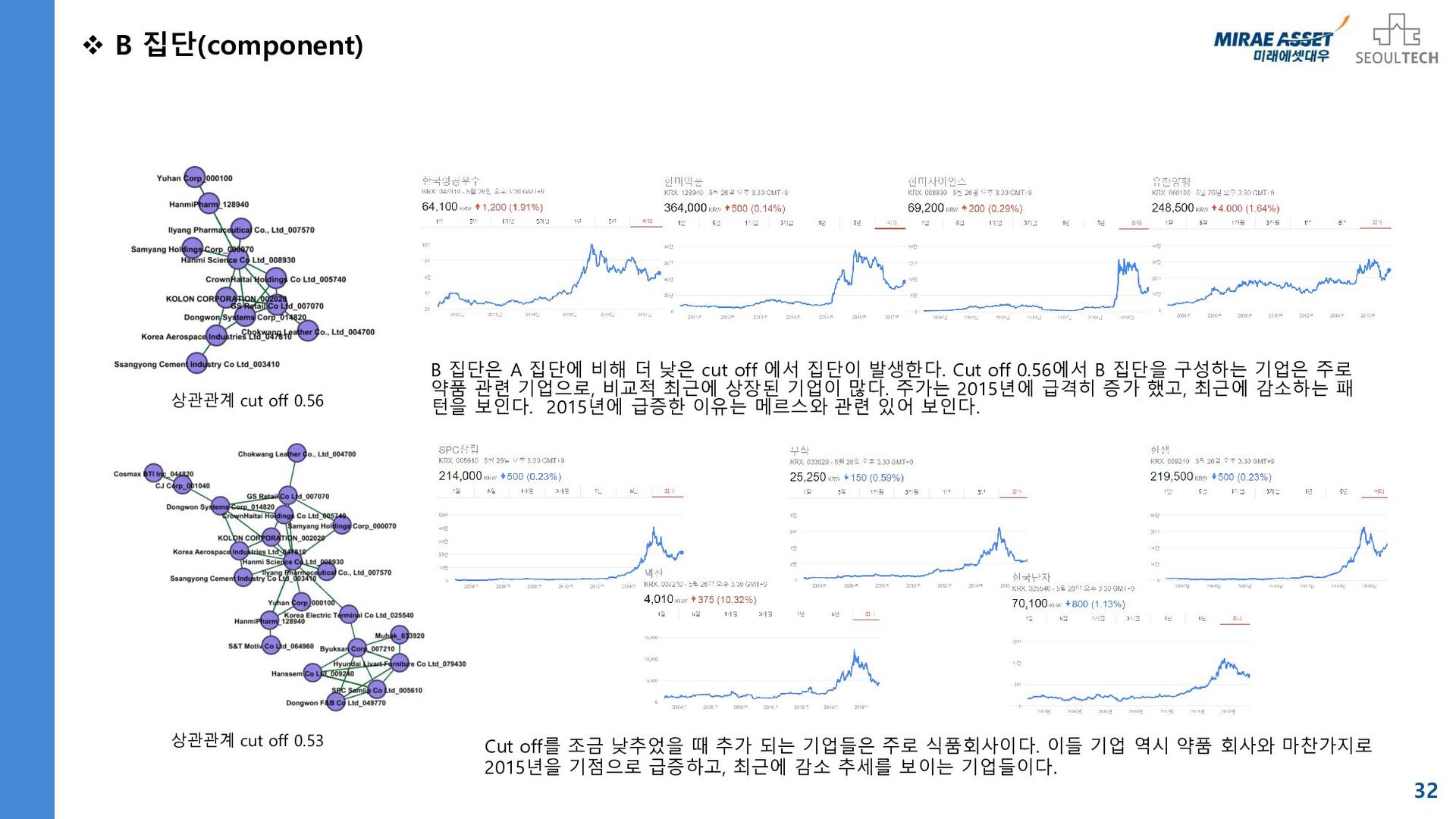{kind=link}
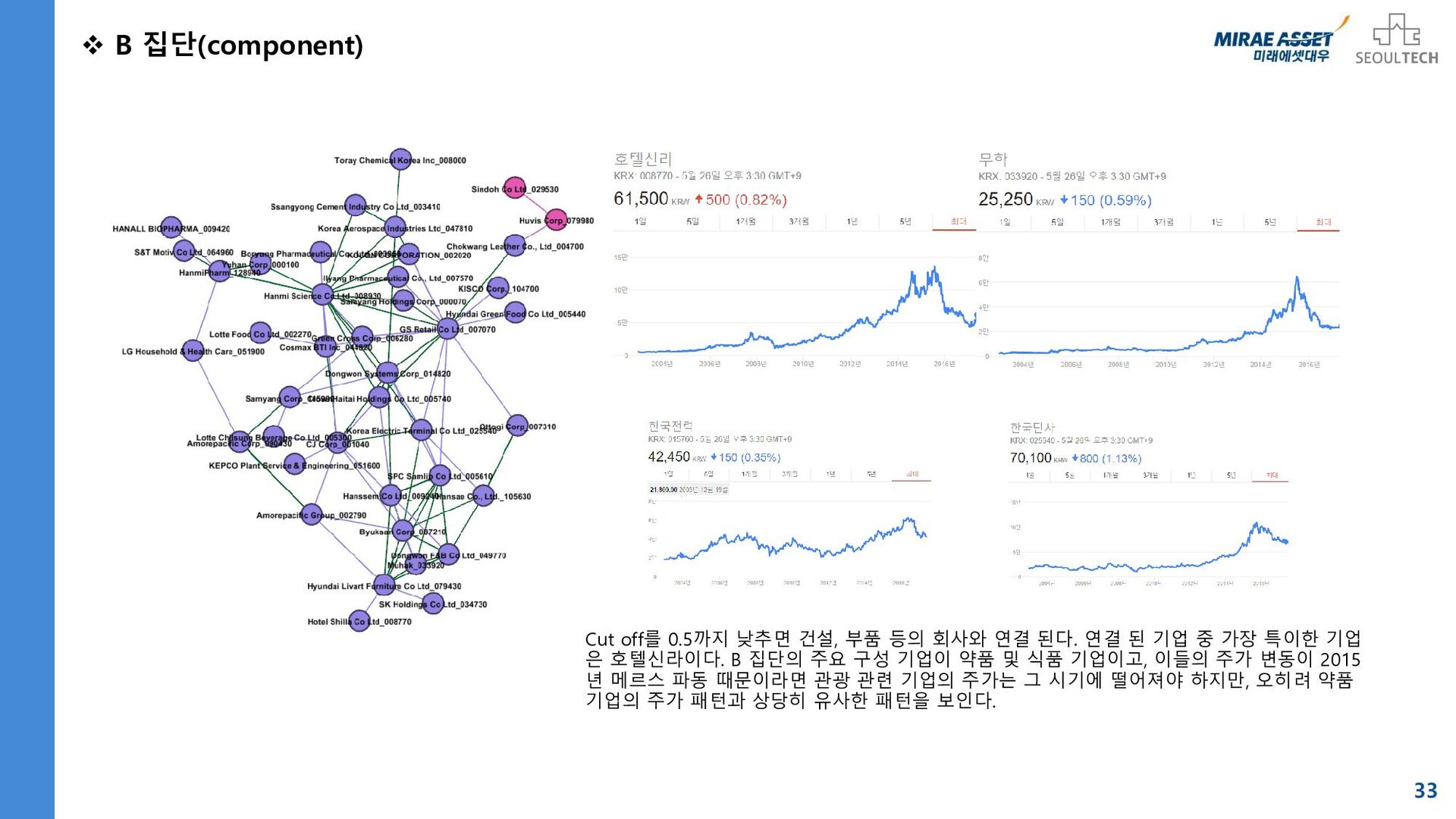{kind=link}
{kind=link}