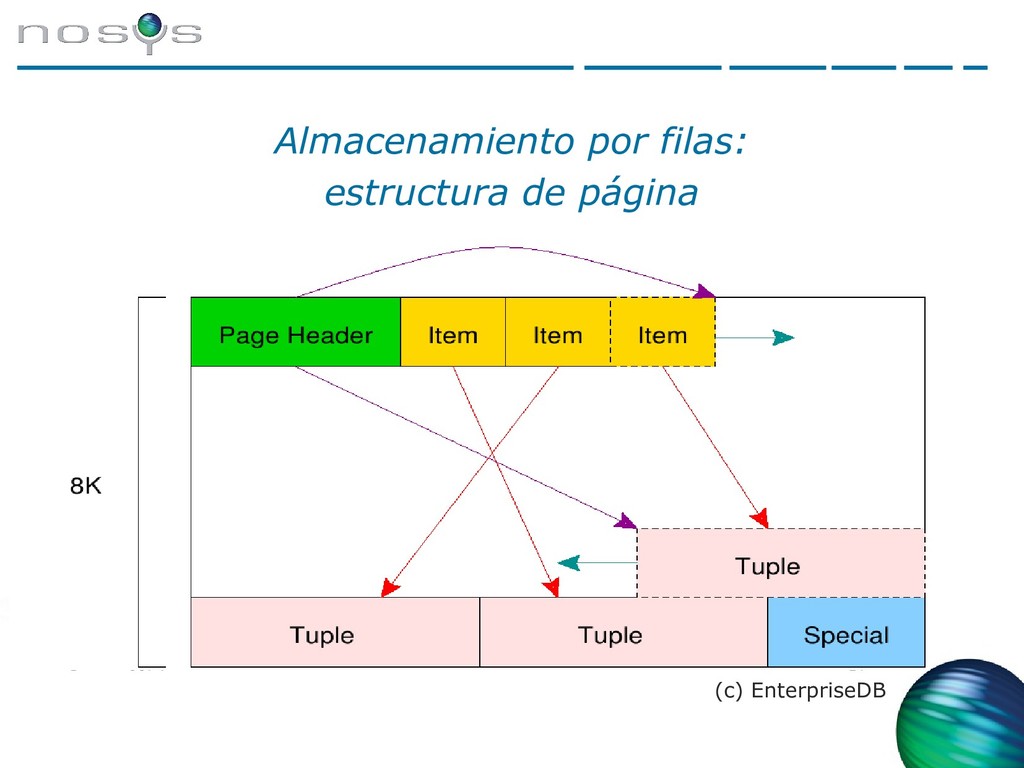
PostgreSQL y Big Data, Big Data y PostgreSQL. PostgreSQL y almacenamiento por columnas (columnar store). Las bases de datos relacionales orientan su procesado, por lo general, a registros, con todas las columnas que contienen. Sin embargo, para procesado de grandes volúmenes de información hay otras técnicas de almacenamiento, como las orientadas a columnas, que permiten una eficiencia muy superior para determinadas operaciones y habilitan compresión transparente para reducir los requisitos de almacenamiento.
![PostgreSQL Big Data Álvaro Hernández Tortosa <[email protected]>](https://files.speakerdeck.com/presentations/2f3ac518ebc7475bada662c5316aadfd/slide_0.jpg){kind=link}
![Acerca de mí • Álvaro Hernández Tortosa <[email protected]> • Fundador](https://files.speakerdeck.com/presentations/2f3ac518ebc7475bada662c5316aadfd/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PostgreSQL Big Data Álvaro Hernández Tortosa <[email protected]>](https://files.speakerdeck.com/presentations/2f3ac518ebc7475bada662c5316aadfd/slide_27.jpg){kind=link}