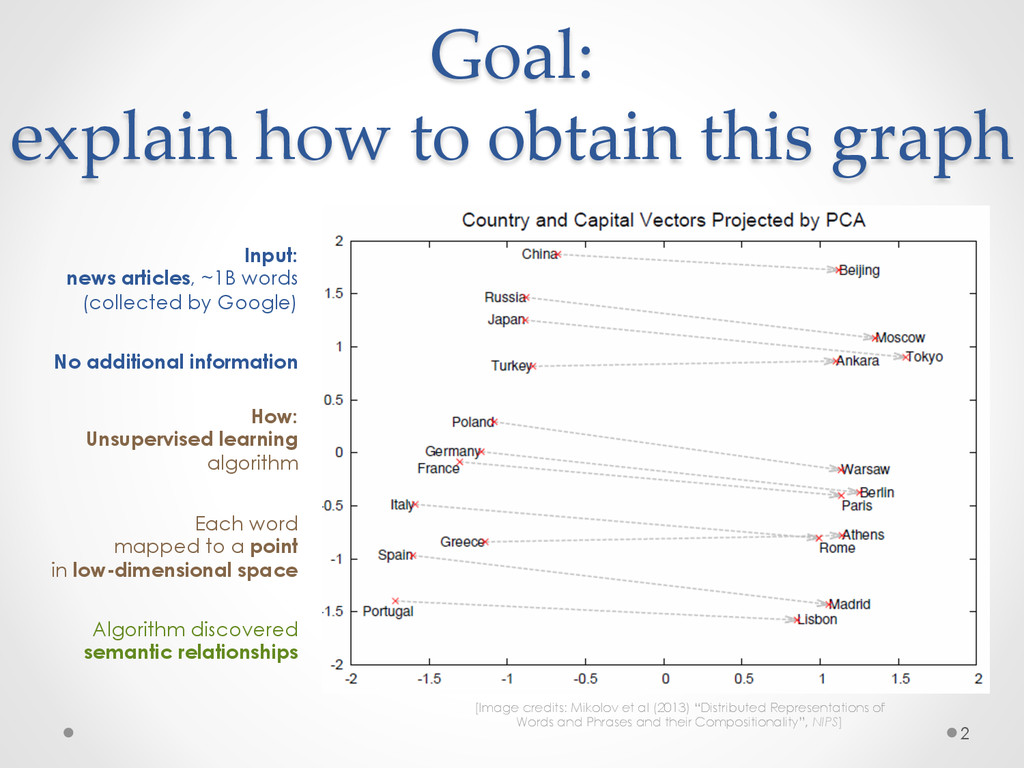
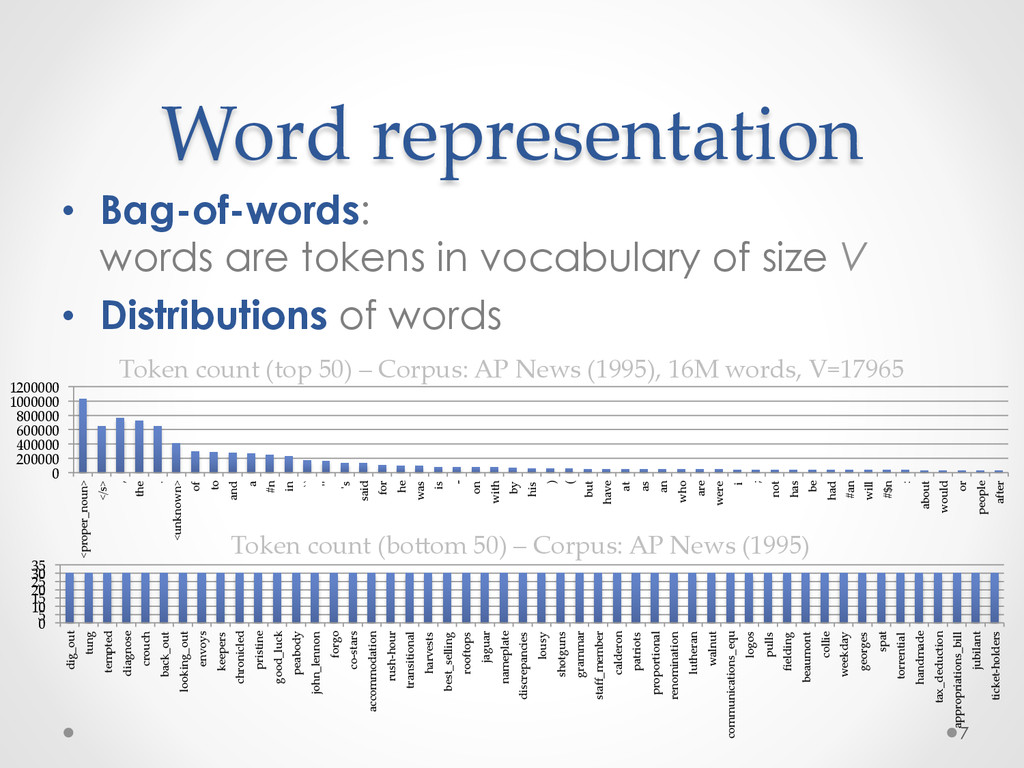
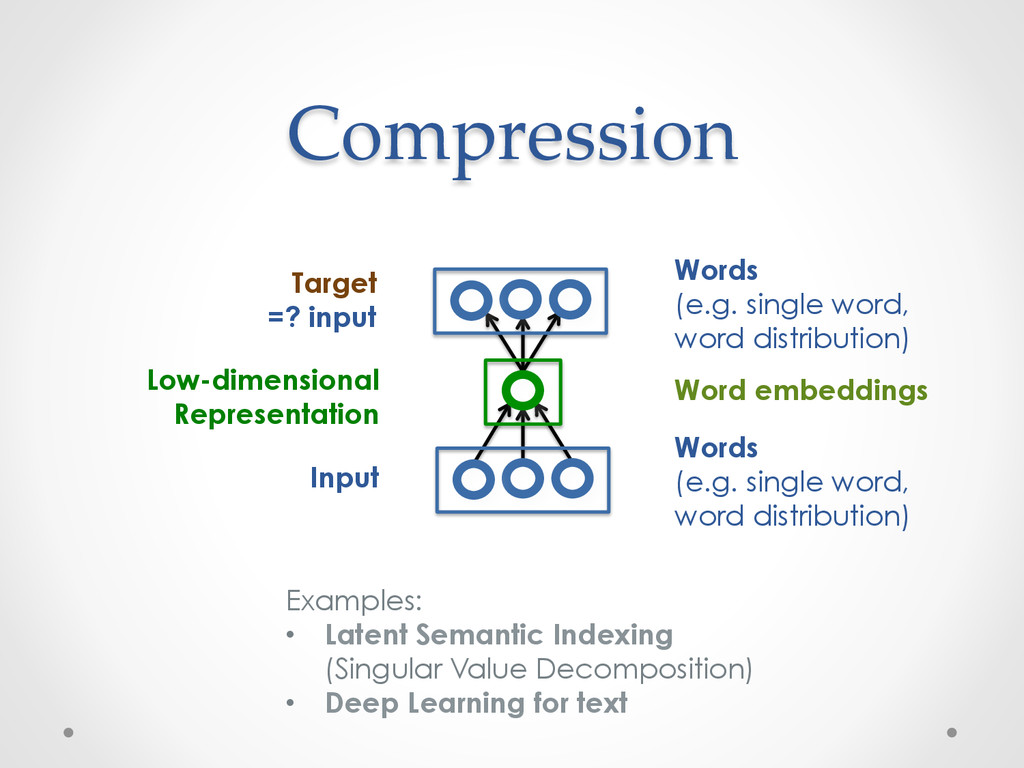
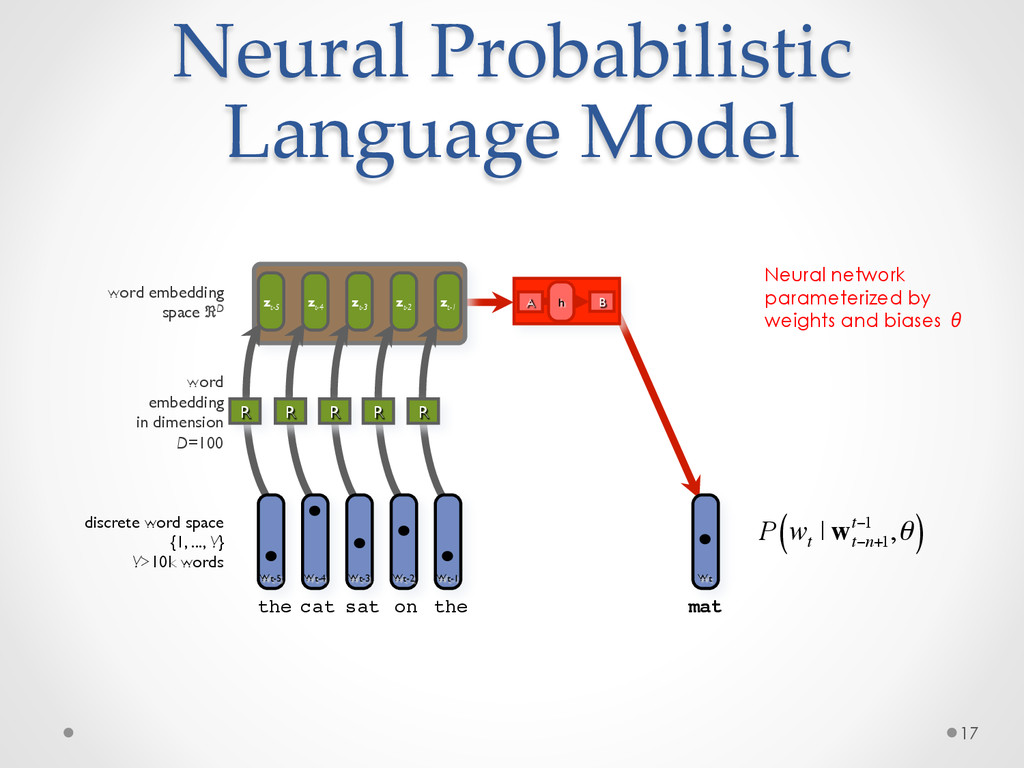
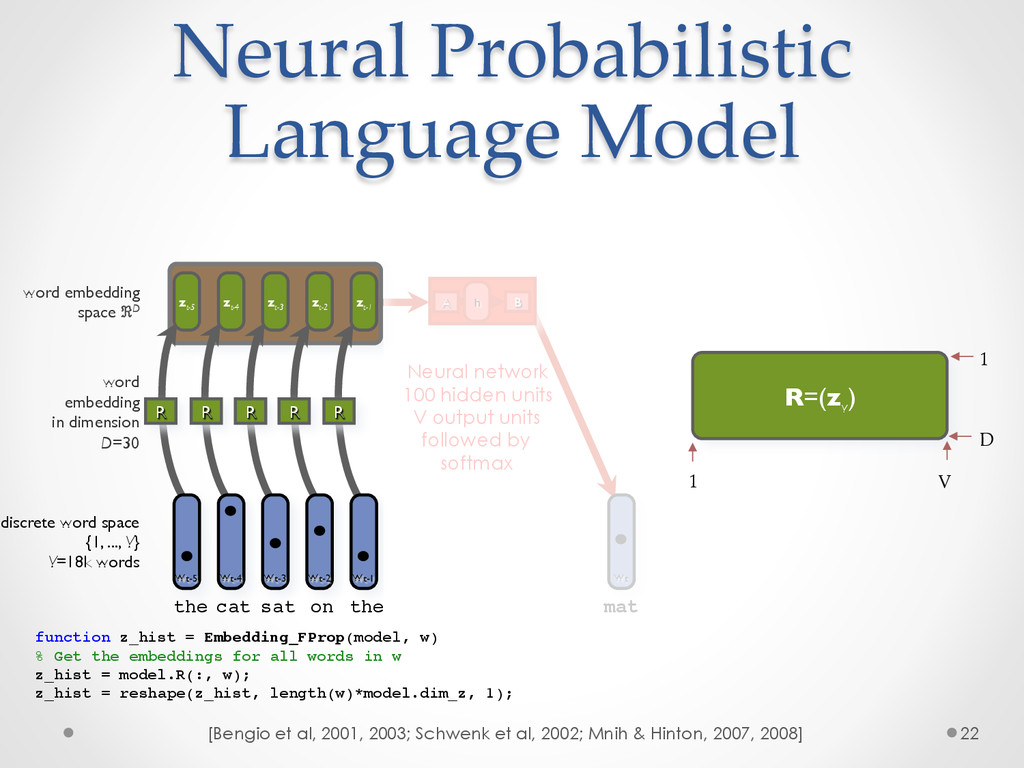
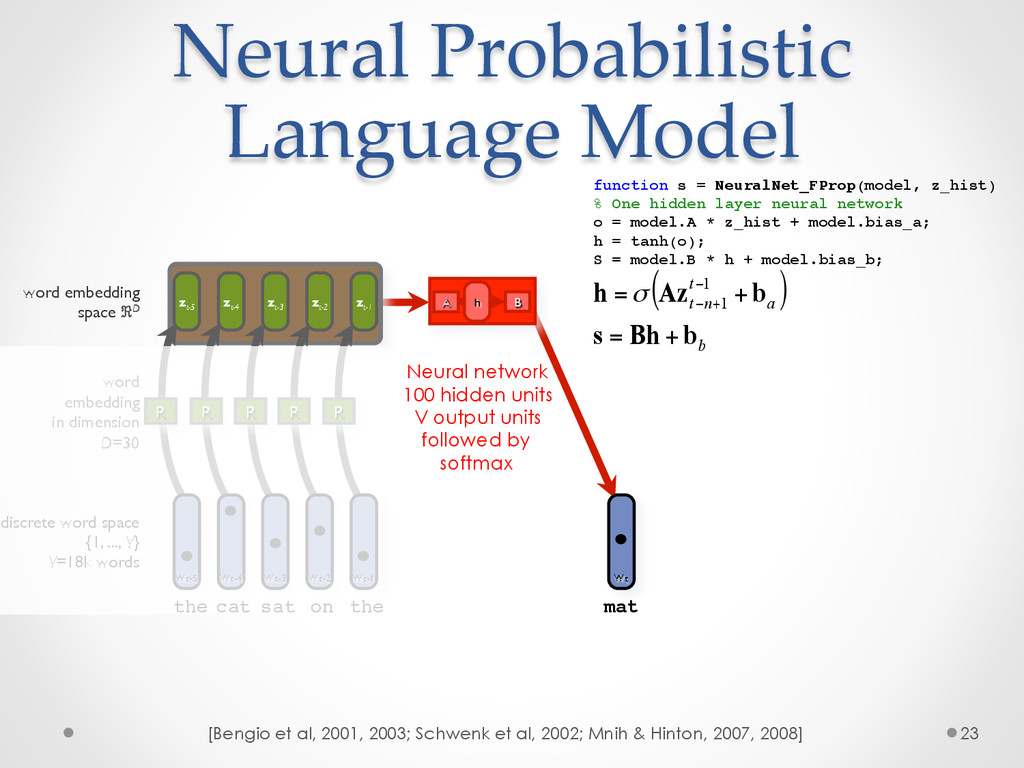
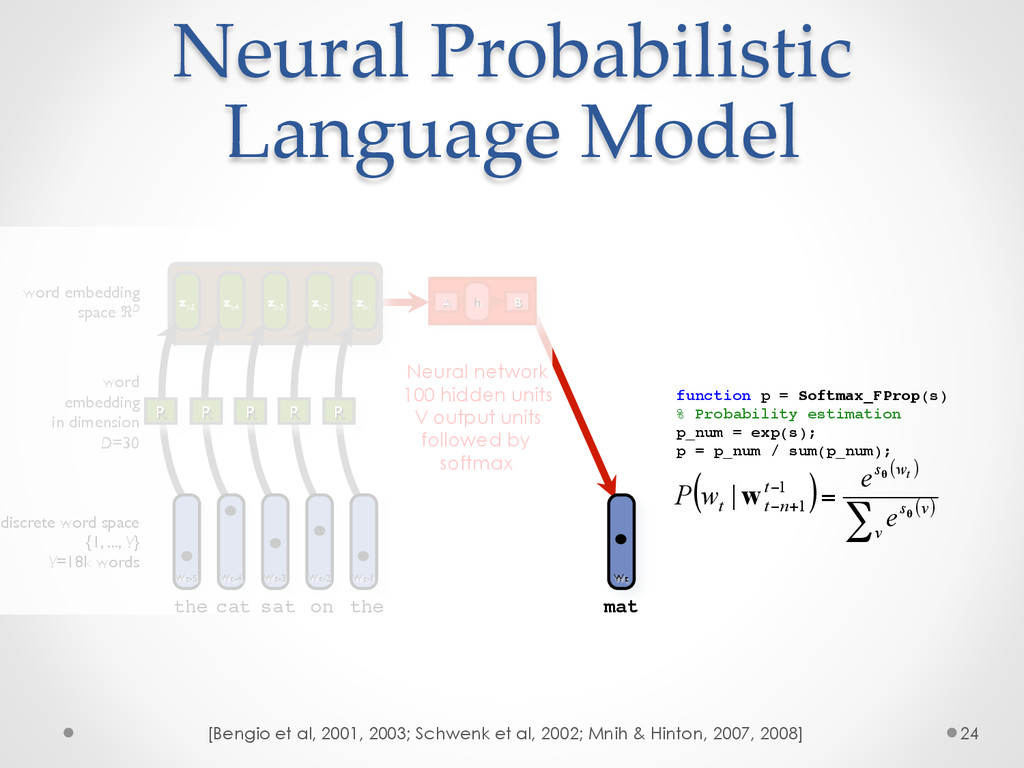
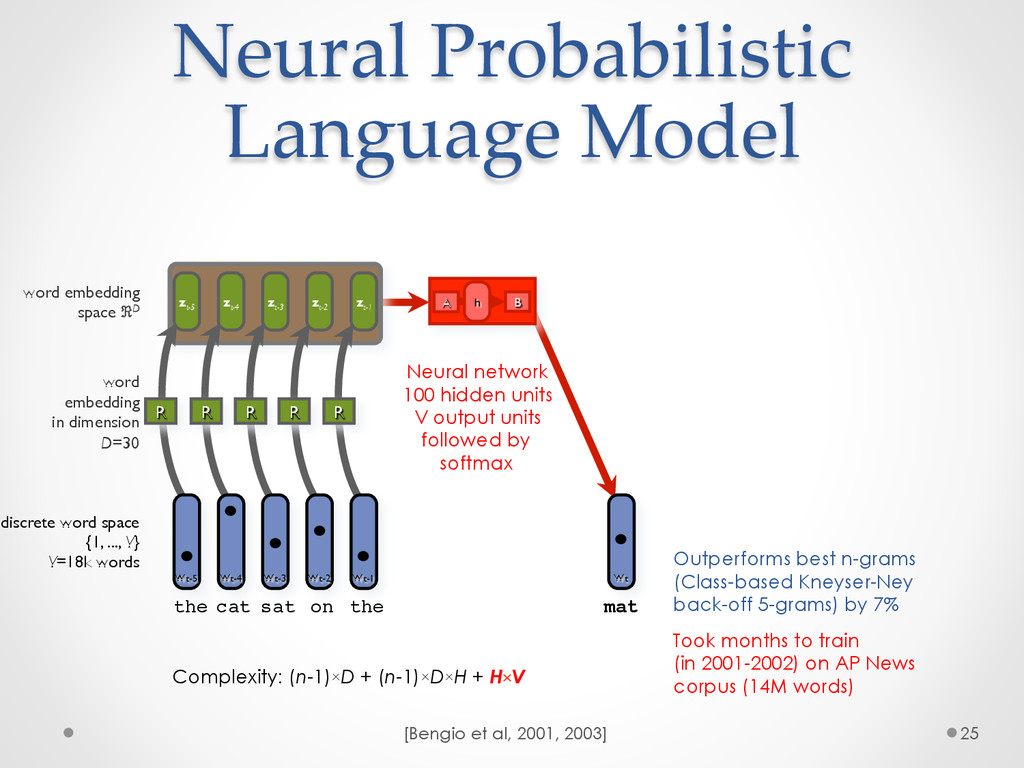
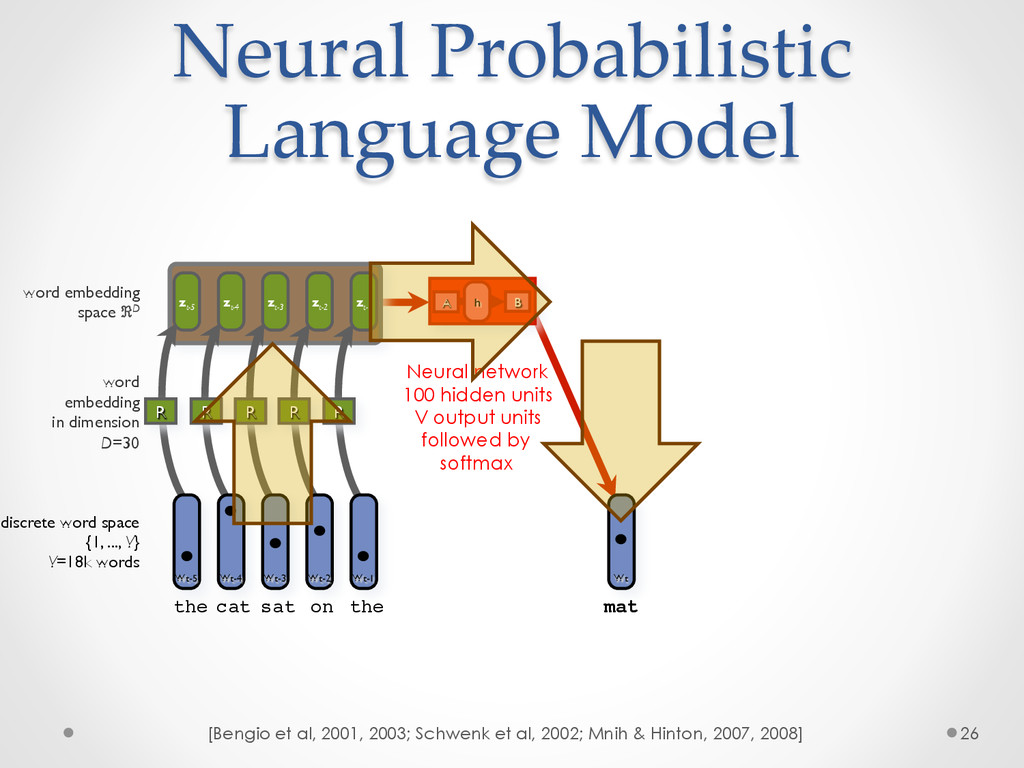
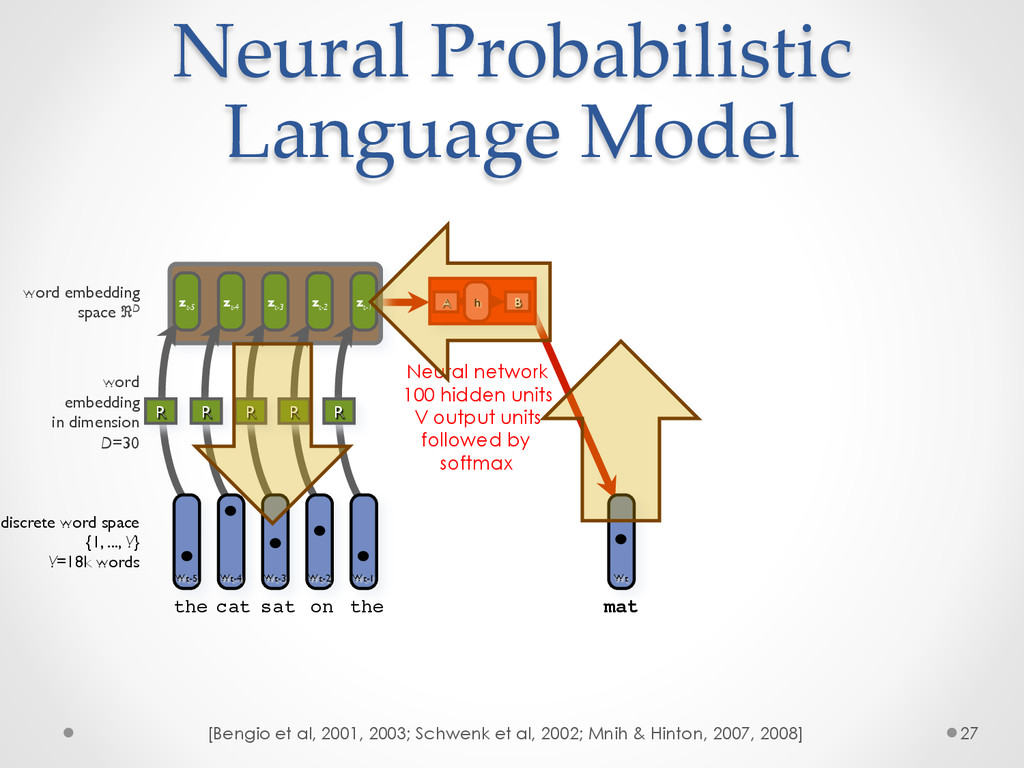
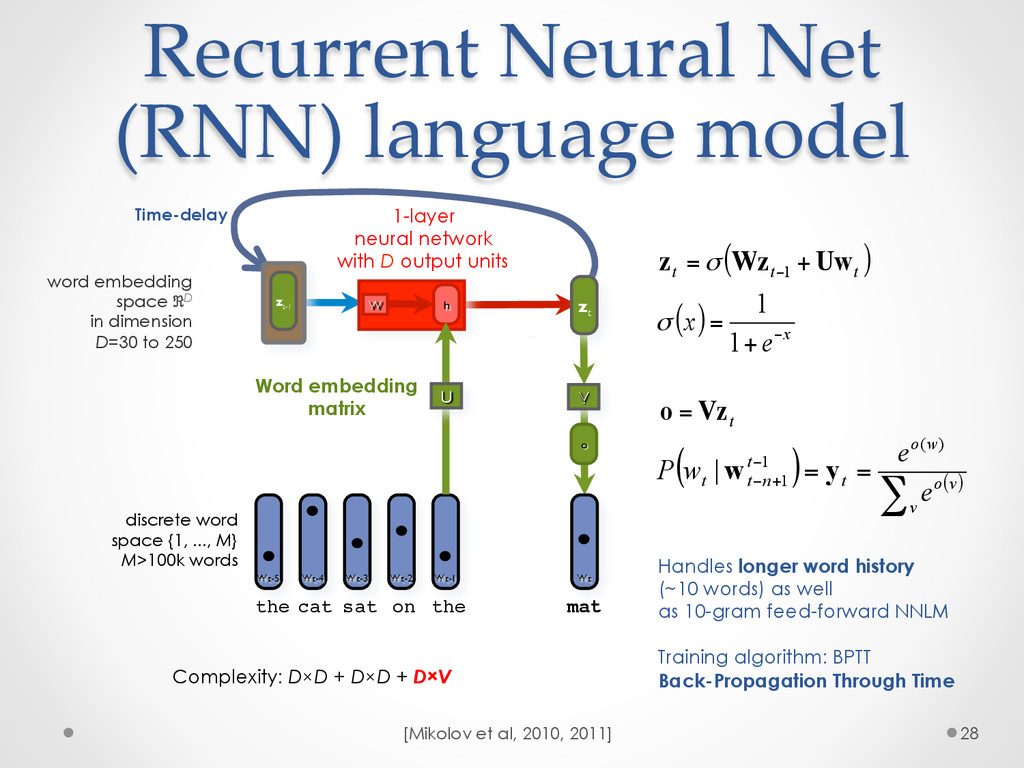
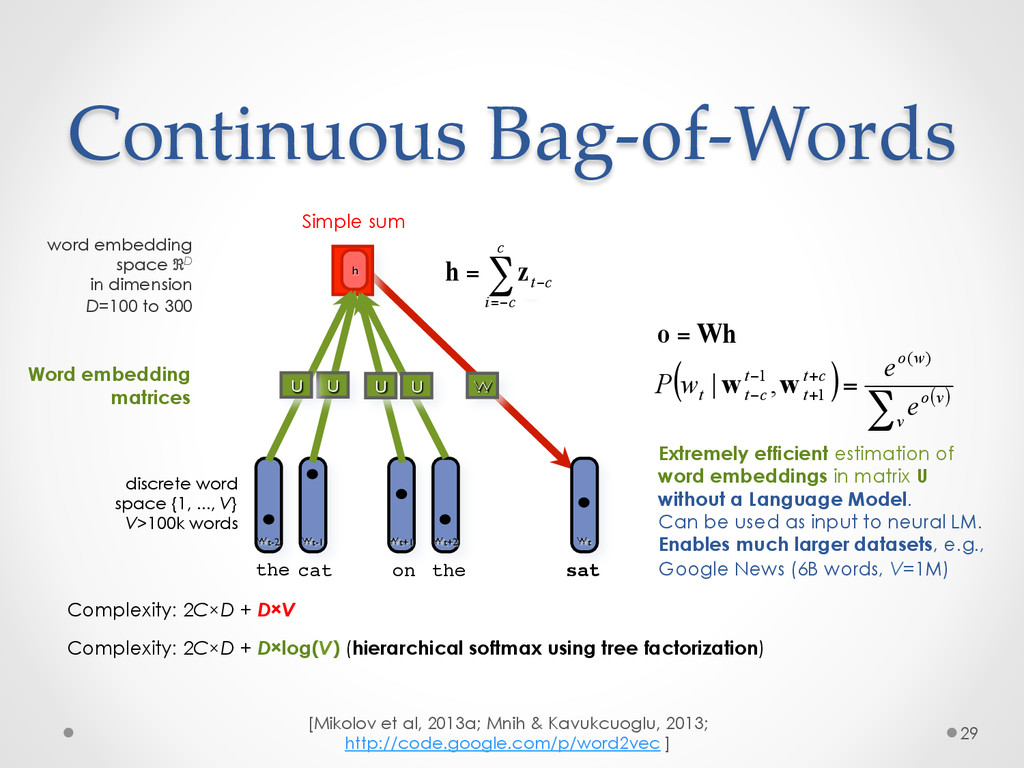
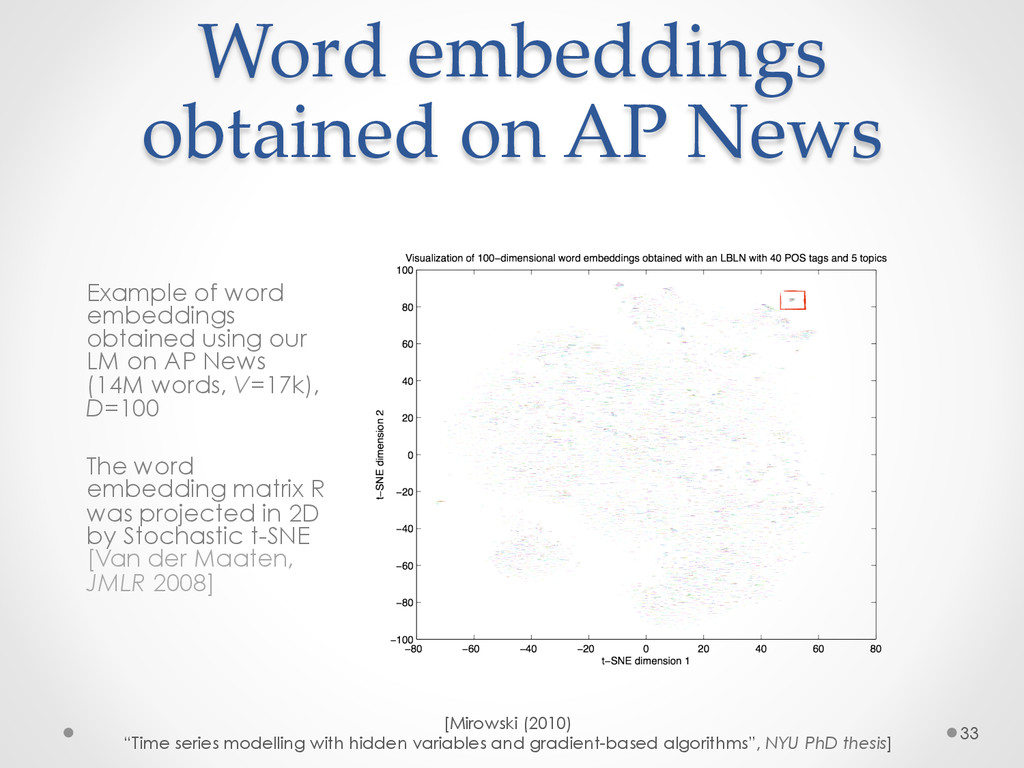
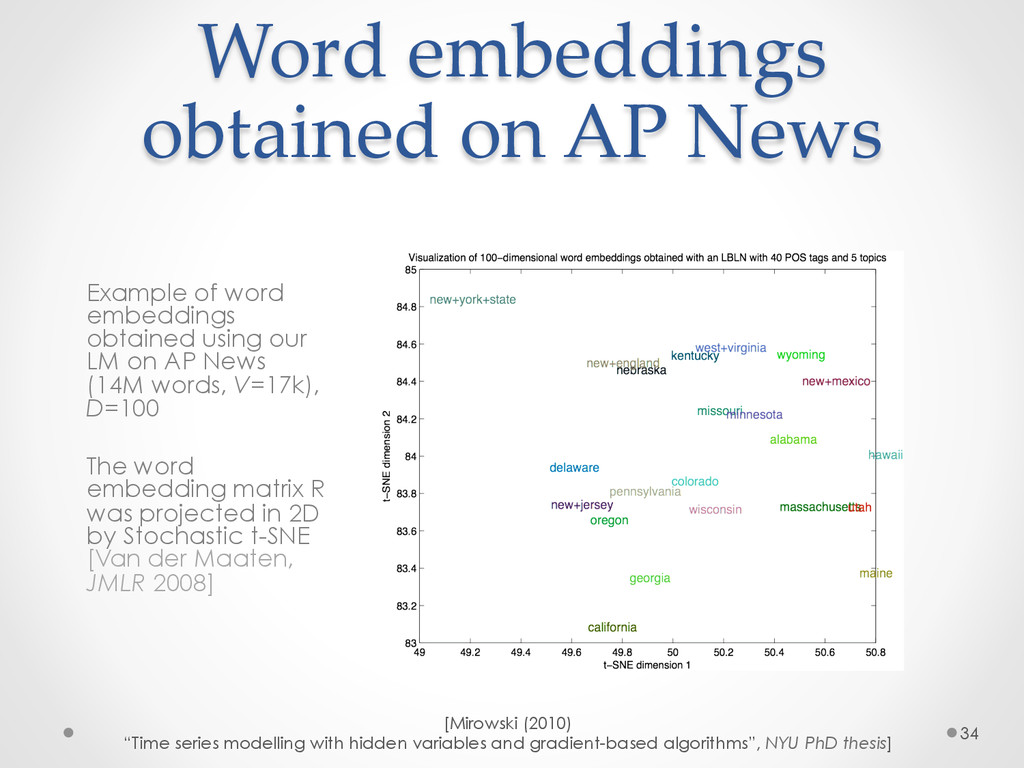
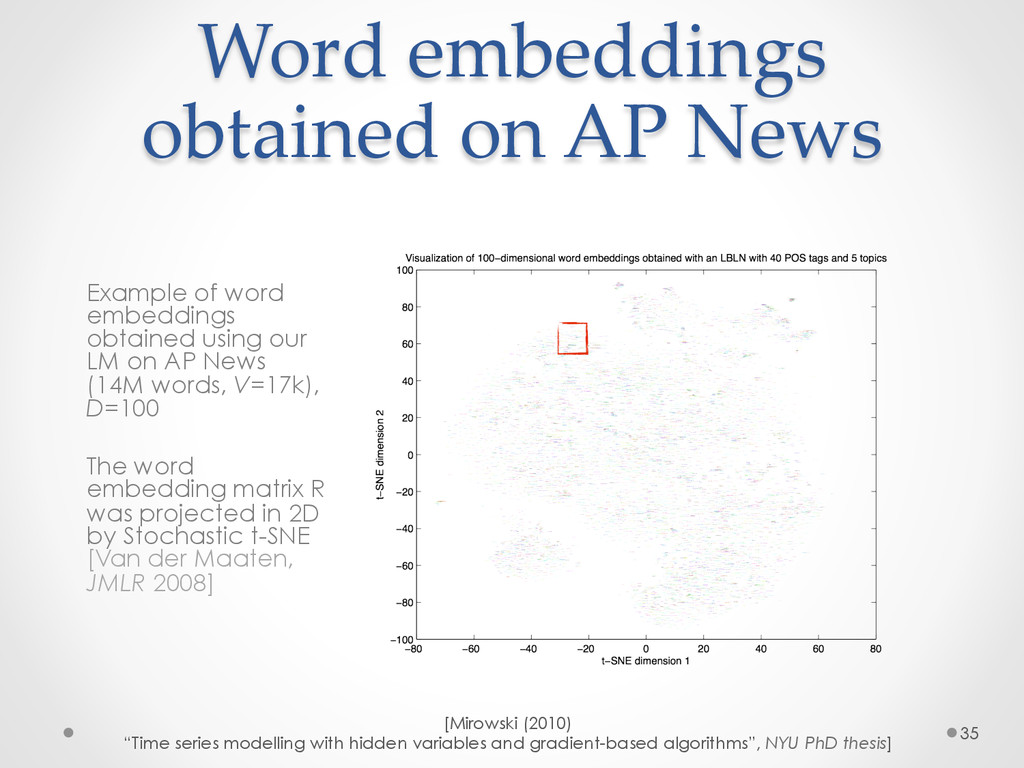
A recent development in statistical language modelling happened when distributional semantics (the idea of defining words in relation to other words) met neural networks. Neural language models further try to "embed" each word into a low-dimensional vector-space representation that can be learned as the language model is trained. When they are trained on very large corpora, these models can not only achieve state-of-the-art performance in many applications such as speech recognition, but also help visualising graphs of word relationships or even two-dimensional maps of word meanings.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! • Contact: [email protected] • Further references: following this](https://files.speakerdeck.com/presentations/e1457ce048d60132f4145e2d20eae4a4/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}