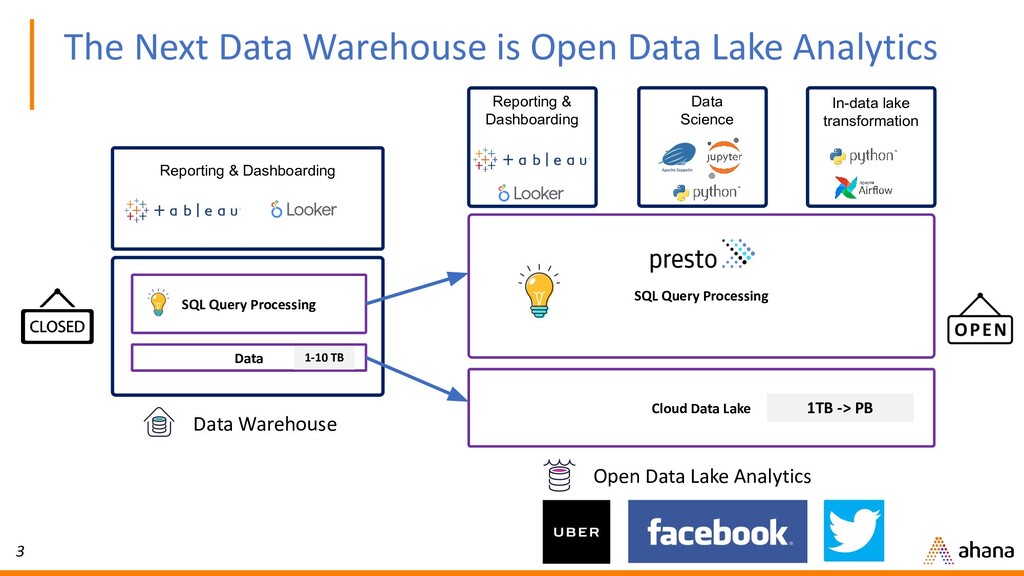
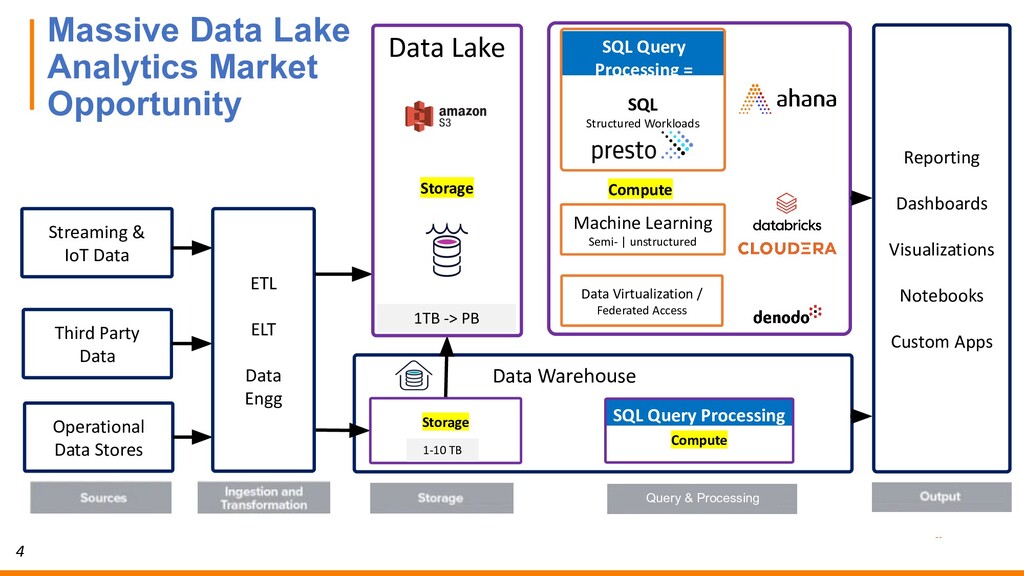
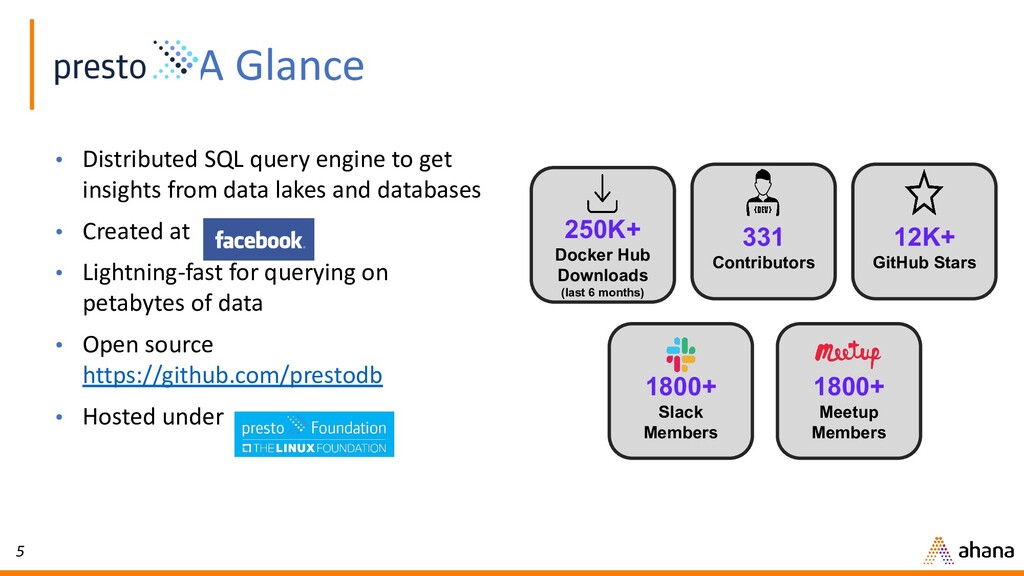
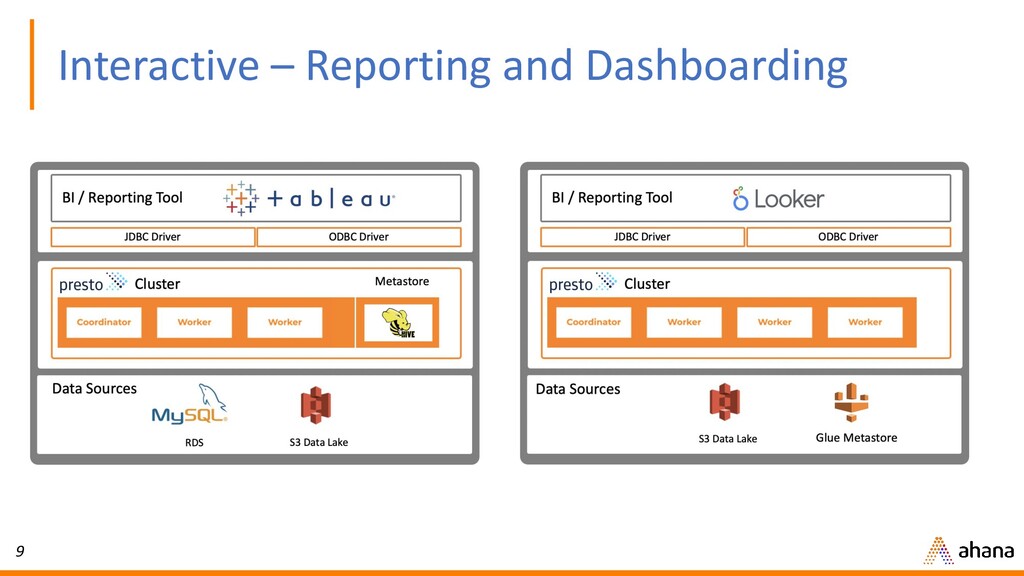
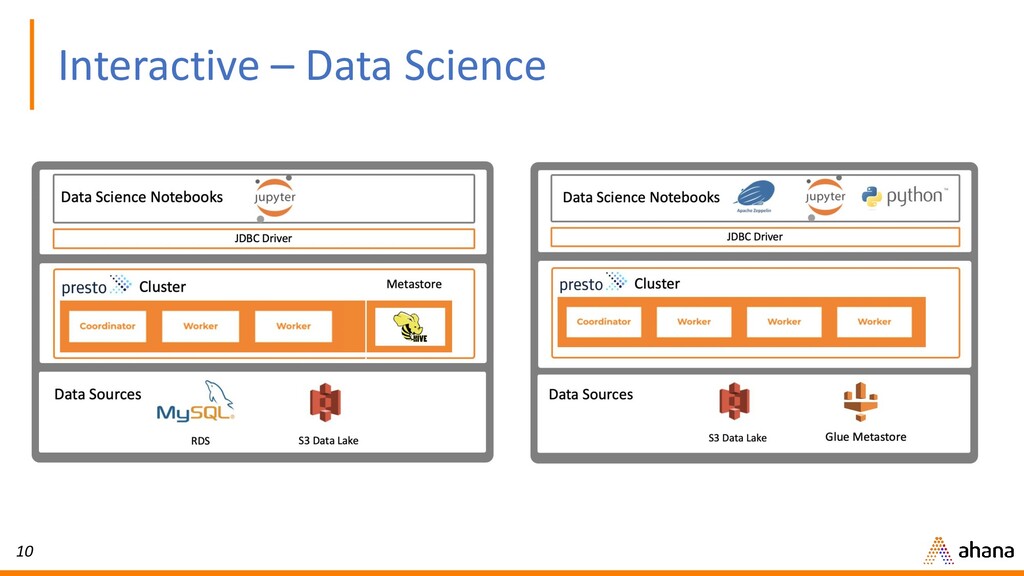
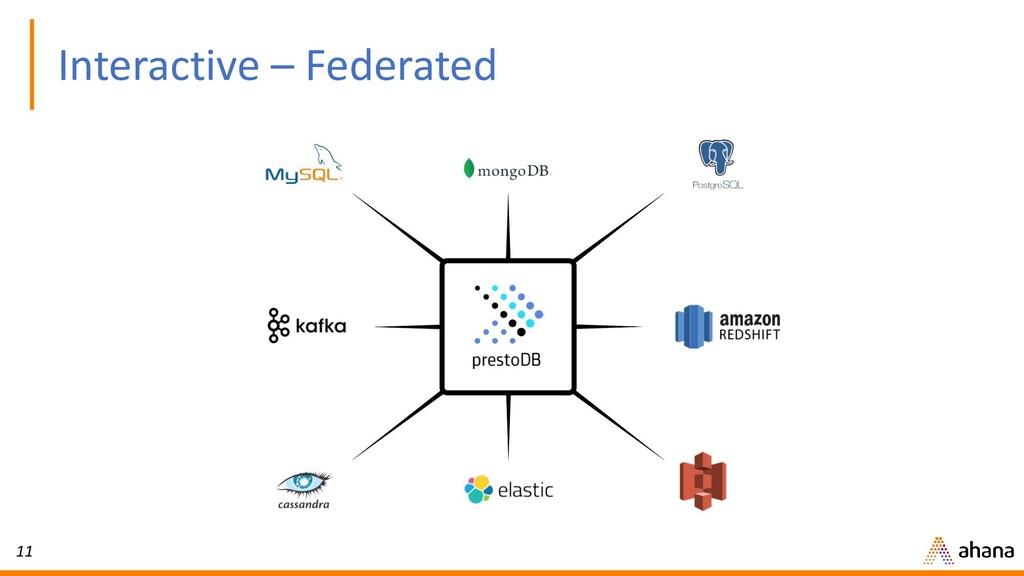
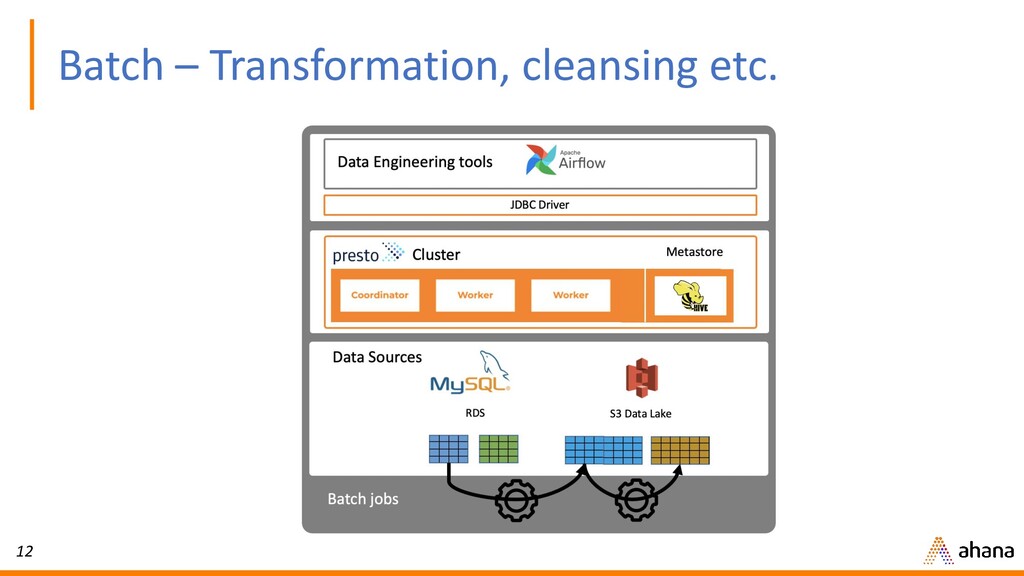
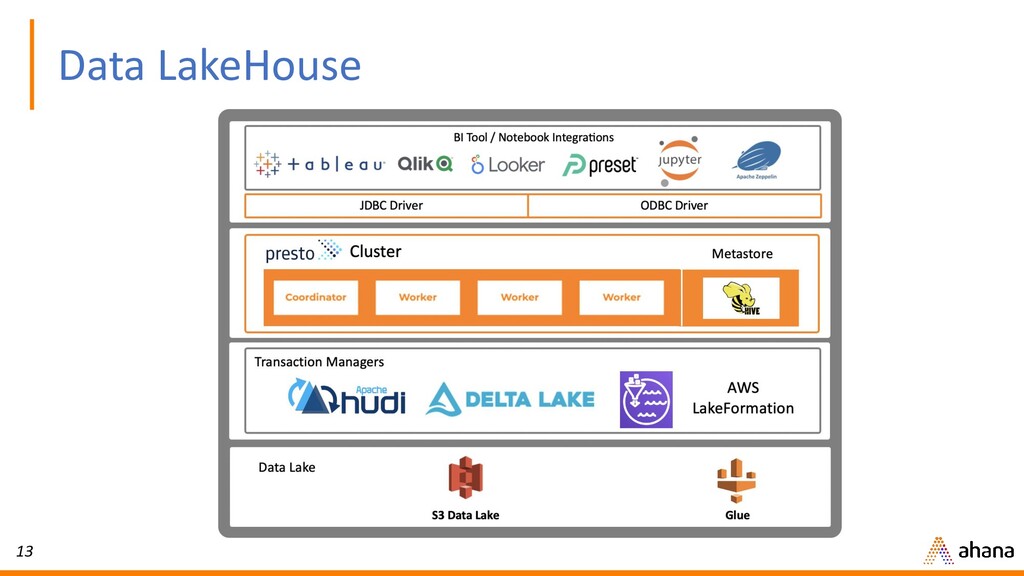
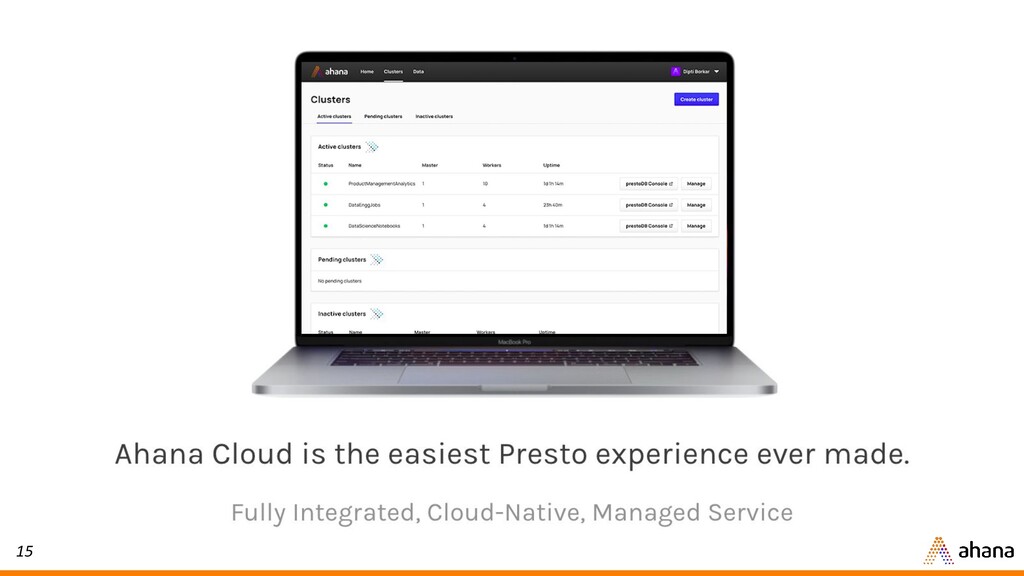
In this webinar, Dipti will discuss why open source Presto has quickly become the de-facto query engine for the data lake. Presto enables ad hoc data discovery where you can use SQL to run queries whenever you want, wherever your data resides. With Presto, you can unlock the value of your data lake.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}