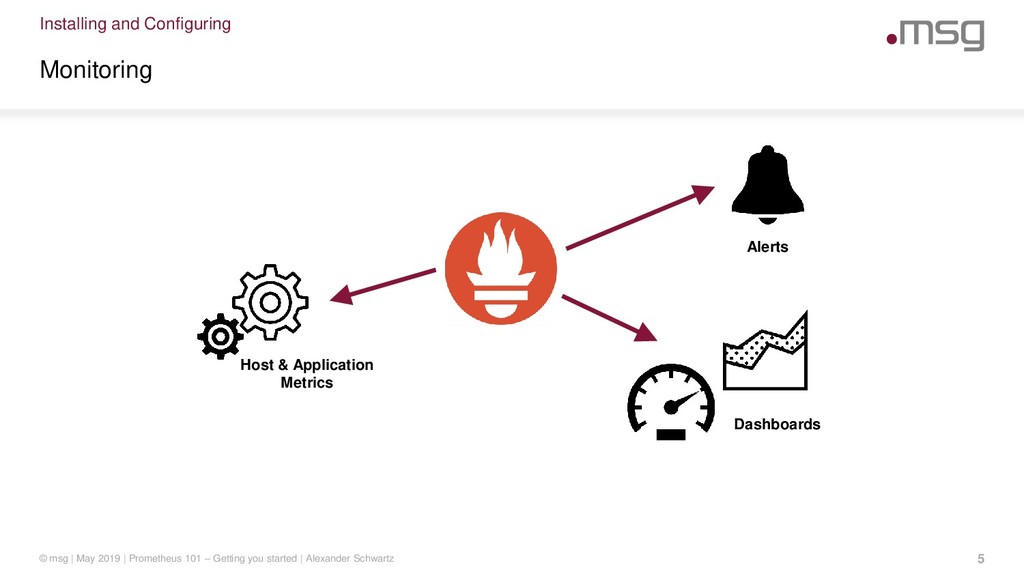
Monitoring the “up” status of your services is not enough if you want to know how your users experience them: you need to track response times, error rates, and throughput of your services. During incident investigation you want to correlate monitoring information from infrastructure and application level. For your business owners you want to create reports and dashboards to show the key performance indicators that matter.
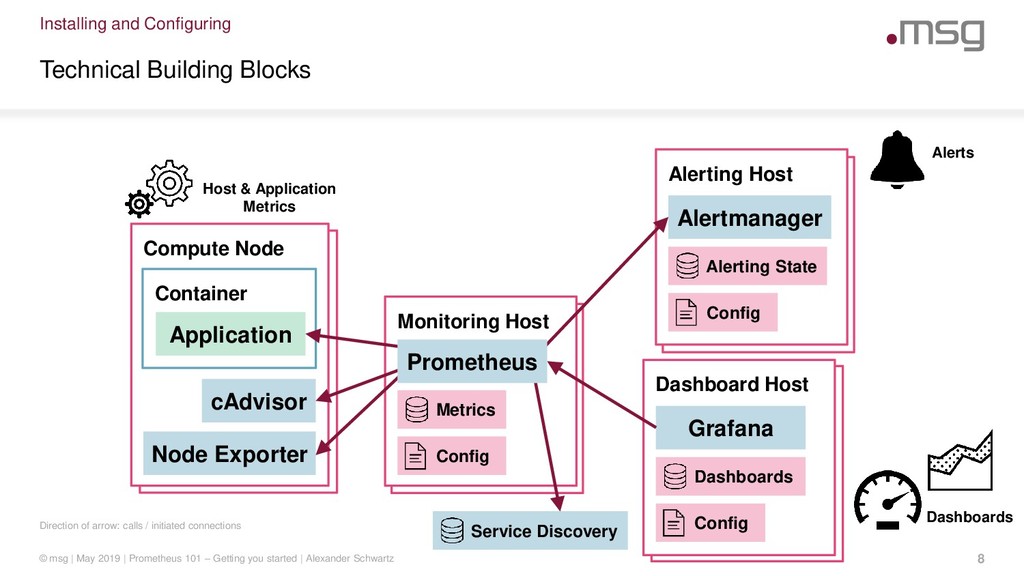
Prometheus has been designed to process metrics to deliver the alerts and dashboards you need in your day-to-day work. Over the last releases it matured, gained a broad adoption in cloud computing and is now a graduated project in the Cloud Native Computing Foundation. Its design focuses on simple and reliable operations.
Join this talk to learn about the basics of Prometheus, integrating it with your existing infrastructure, leveraging metrics at work, and to hear about its ecosystem and roadmap.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![route: receiver: 'alertmanager-bot' group_by: [alertname, datacenter, app] group_wait: 10s group_interval:](https://files.speakerdeck.com/presentations/55191fb258214ab496b5075056b4026b/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}