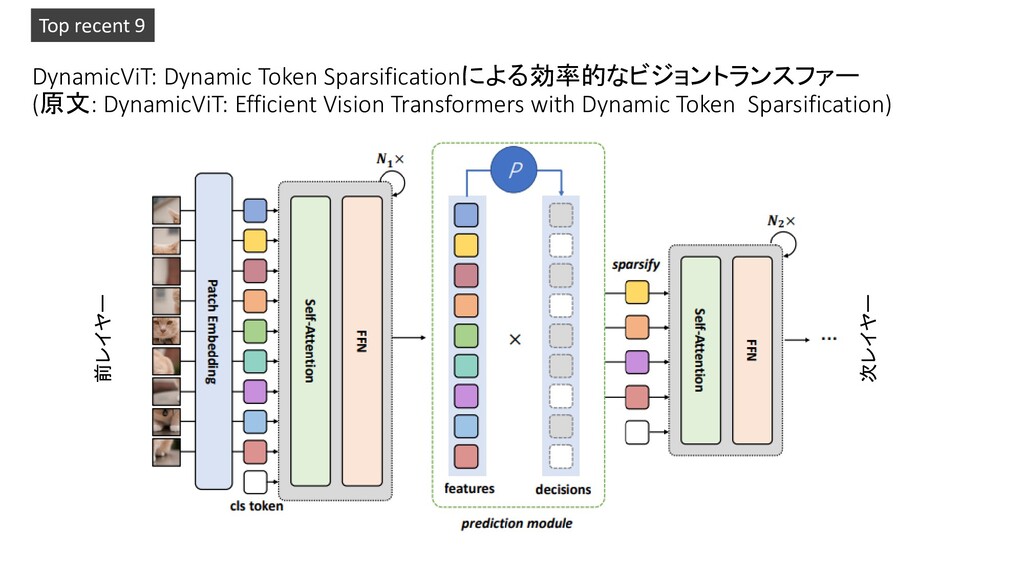
Dynamic Vision Transformers with Adaptive Sequence Length 2. Decision Transformer: Reinforcement Learning via Sequence Modeling 3. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers 4. When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations 5. Reinforcement Learning as One Big Sequence Modeling Problem 6. You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection 7. Towards Long-Form Video Understanding 8. NeRF in detail: Learning to sample for view synthesis 9. DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification 10. Rethinking InfoNCE: How Many Negative Samples Do You Need? Pickup!
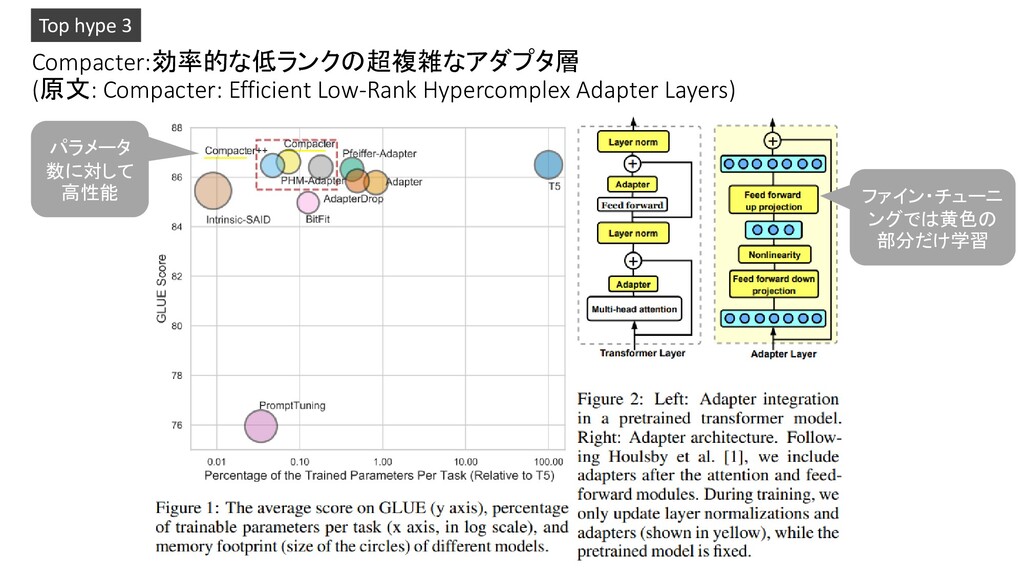
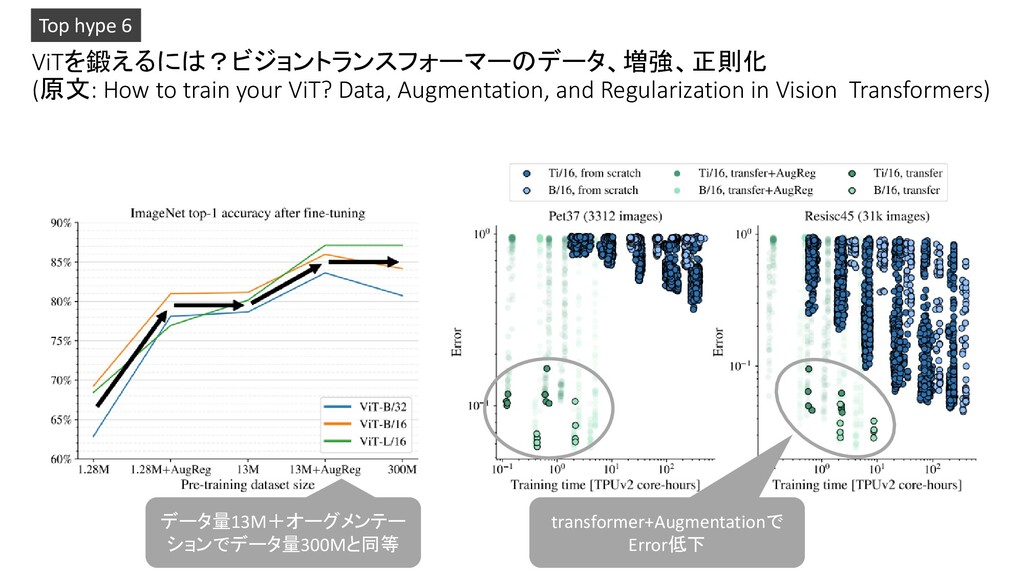
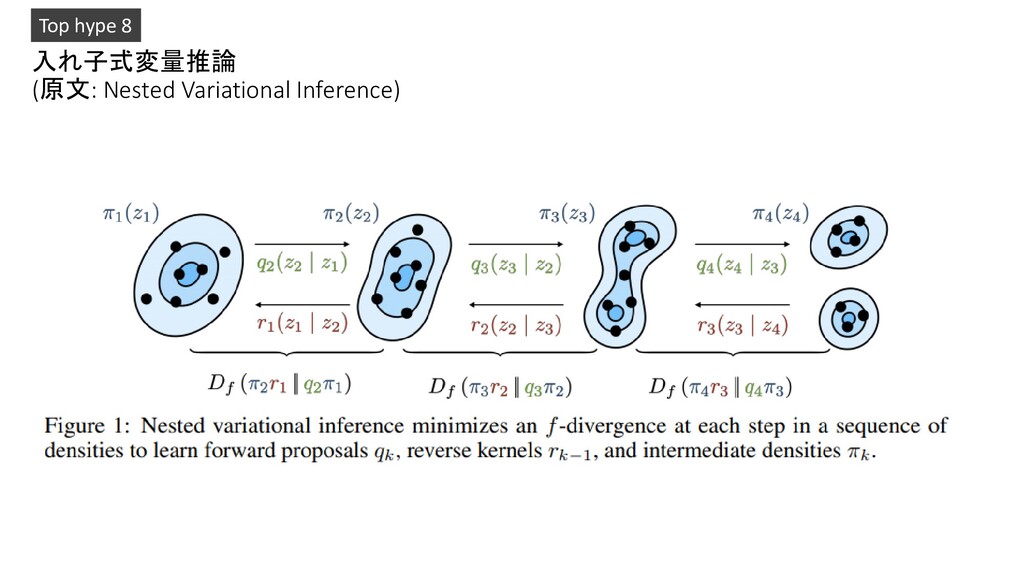
by artificial intelligence and image processing 2. The Modern Mathematics of Deep Learning 3. Compacter: Efficient Low-Rank Hypercomplex Adapter Layers 4. Applications of Deep Neural Networks 5. Scalable Marginal Likelihood Estimation for Model Selection in Deep Learning 6. How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers 7. Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks 8. Nested Variational Inference 9. Regularization is all you Need: Simple Neural Nets can Excel on Tabular Data 10. DeepLab2: A TensorFlow Library for Deep Labeling Pickup!
at One Sequence: Rethinking Transformer in Vision through Object Detection) http://arxiv.org/abs/2106.00666v2 Transformerは、純粋なシーケンスの観点から、2Dの空間構造に関する最小限の知識で、2Dのオブジェクトレベルの認識を行うことがで きるのでしょうか?この疑問に答えるために、私たちはYou Only Look at One Sequence (YOLOS)を発表しました。これは、可能な限り最小 限の修正と帰納的バイアスを加えたVision Transformerに基づく一連のオブジェクト検出モデルです。中規模のImageNet-1kデータセット のみで事前学習したYOLOSは、COCOでも競争力のある物体検出性能を達成できることがわかりました。また、BERT-Baseから直接採用し たYOLOS-Baseは、42.0 box APを達成することができました。また、Transformerが物体検出を通じた視覚において、現在のプレトレーニン グスキームとモデルスケーリング戦略の影響と限界についても議論します。コードとモデルの重みは、https://github.com/hustvl/YOLOS で利用可能です。 Top recent 6 目的: オブジェクト検出 方法: Vision Transformerを使ったオブジェクト検出モデルの開発 著者所属: 華中科技大学、ホライゾン・ロボティクス
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}