Summary We have been experimenting on possible implementations of a cloud-based storage service for supporting scienti c research experiments Here we present what we have done and learnt so far and what our plans are 2
Who we are • Affiliated to computer centers supporting high energy physics experiments IN2P3/CNRS computing centre (Lyon, France) IHEP computing centre (Beijing, China) • Users of these centers are both virtual organizations and individual users 4
Objective • What it takes to provide a cloud-based storage service to our users? • Use-cases: experiments (a.k.a. virtual organizations) as a whole and individuals • Cloud-based always on, online storage no in nite elasticity users are not directly charged for their usage easy of use and easy to integrate with our user’s working environment 6
S3 protocol • Amazon’s S3: Simple Storage Service • De facto standard protocol for object storage well documented, works on top of HTTP(S) several client-side tools support it, both CLI- and GUI-based several service providers and implementors (Amazon, Google, Eucalyptus, Rackspace, ...) • How S3 works objects (i.e. les) stored within containers called buckets limits: 100 buckets per user, in nite number of les per bucket, 5TB per le, bucket namespace shared among all users of a single provider at object namespace within buckets: no hierarchy, no directories no POSIX semantics: partial reading, no partial writing, le versioning per-bucket and per- le access control based on ACLs authentication based on secret shared between the user and the server user is provided with credentials of type: access key and secret key le sharing mechanism via standard URL 8 Bucket with objects
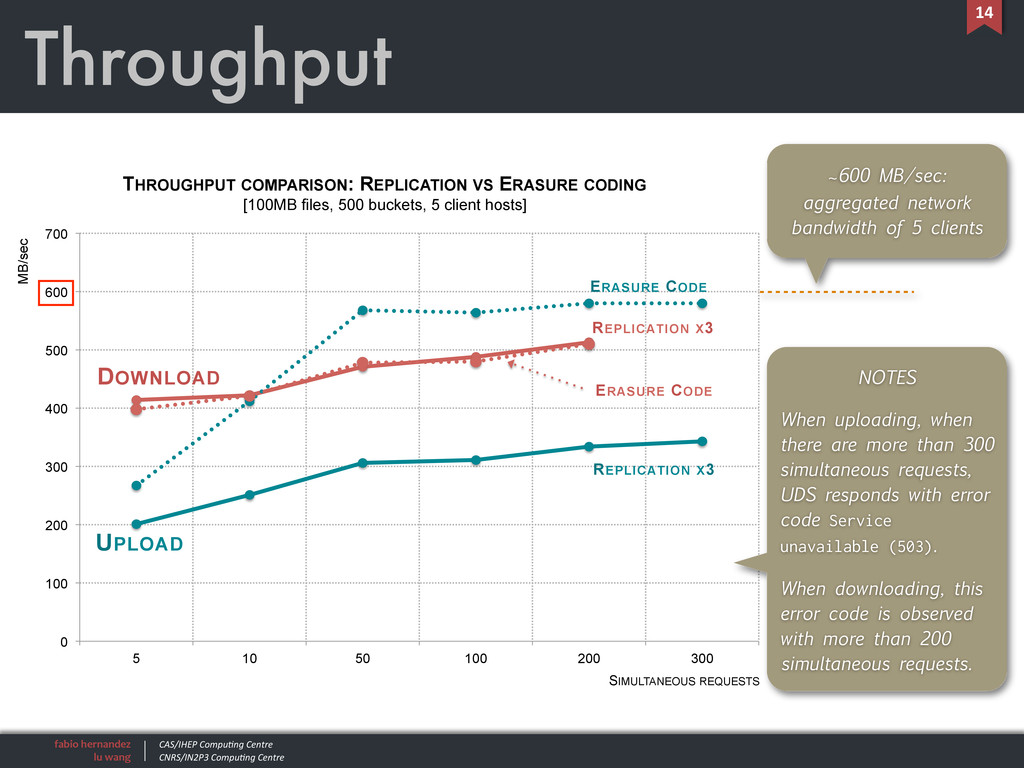
Performance tests • Type of tests upload and download of 4KB les upload and download of 100MB les • Adjustable parameters number of accounts number of buckets number of simultaneous requests redundancy: erasure coding or 3 replicas • Fixed parameters all tests performed in the context of IHEP’s local area network 5 client hosts, same con guration, both hardware and software • Software UDS software version: V100R001C00SPC101 client hosts OS: Scienti c Linux 5, 1 Gbps, 16 GB RAM S3 client: Python program based on AWS SDK (Boto) 11
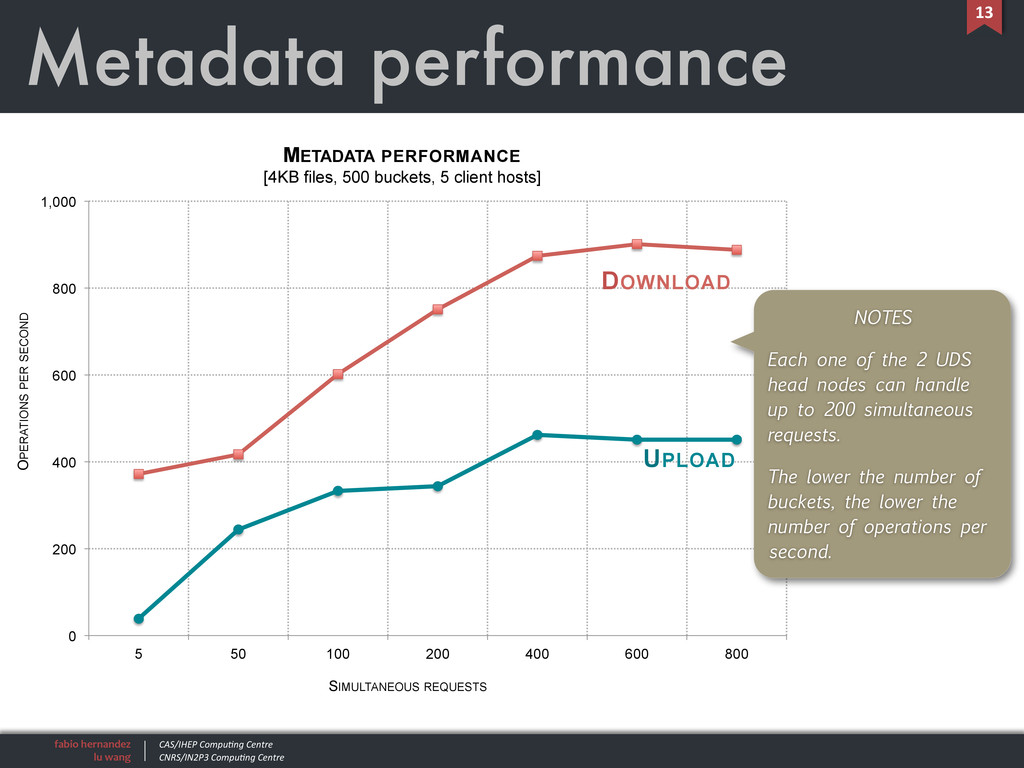
0 200 400 600 800 1,000 5 50 100 200 400 600 800 OPERATIONS PER SECOND SIMULTANEOUS REQUESTS METADATA PERFORMANCE [4KB files, 500 buckets, 5 client hosts] DOWNLOAD UPLOAD Metadata performance 13 NOTES Each one of the 2 UDS head nodes can handle up to 200 simultaneous requests. The lower the number of buckets, the lower the number of operations per second.
Use case 1: experimental data storage • Use cases storage of experimental data to be processed by batch jobs executing in the local farm storage of experimental data to be shared with remote sites: download the whole le or access only the required chunks of data storage element for collecting, in a central repository, simulation data produced by remote grid sites • Required tools command line tools for downloading and uploading les: to be used by batch jobs (local or grid) data access libraries that understand S3 protocol, e.g. CERN’s ROOT framework 17
Experimental data storage (cont.) • Improvements of S3 support in CERN’s ROOT data analysis framework experiments can efficiently read remote les using the S3 protocol as easy as if the les were stored in a local le system — no experiment-speci c software needs to be modi ed TFile* f = TFile::Open(“s3://uds.ihep.ac.cn/myBucket/path/to/myDataFile.root”) features: partial reads, vector read (provided the S3 server supports it), web proxy handling, HTTP and HTTPS works with Amazon, Google, Huawei, … available in the current production release of ROOT 18
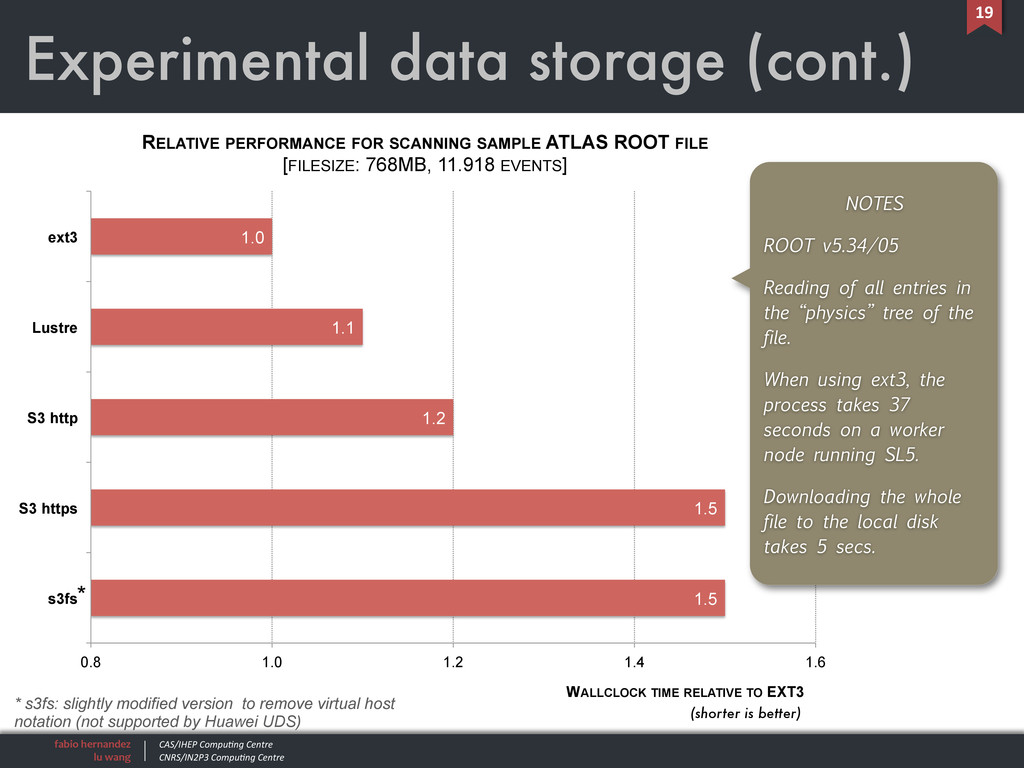
Experimental data storage (cont.) 19 1.5 1.5 1.2 1.1 1.0 0.8 1.0 1.2 1.4 1.6 s3fs S3 https S3 http Lustre ext3 WALLCLOCK TIME RELATIVE TO EXT3 RELATIVE PERFORMANCE FOR SCANNING SAMPLE ATLAS ROOT FILE [FILESIZE: 768MB, 11.918 EVENTS] NOTES ROOT v5.34/05 Reading of all entries in the “physics” tree of the file. When using ext3, the process takes 37 seconds on a worker node running SL5. Downloading the whole file to the local disk takes 5 secs. (shorter is better) * * s3fs: slightly modified version to remove virtual host notation (not supported by Huawei UDS)
Experimental data storage (cont.) • Tests successfully performed at IHEP scanning ATLAS sample les in ROOT format • Ongoing tests with BES-III experiment’ data les also in ROOT format needs upgrading the version of ROOT used by the experiment • Integrating a S3-based storage element in experiment’s computing infrastructure several experiments already use URLs for identifying entries in their le catalogues: S3 URLs use an additional scheme (e.g. “s3://”) how to handle credentials for accessing non-public S3 les is a separate problem (more on this later) experiment needs to adopt conventions to handle the limitations due to the naming schema imposed by S3 20
Use case 2: personal file storage • Goal: provide a storage area for individual users controlled and managed by its owner signi cant but limited capacity usage convenience is more important than raw performance kind of personal storage element: accessible from the user’s desktop computer and readable and writable by the user’s (local and grid) batch jobs individual user can share his own les with other individuals • What tools can we provide or recommend so that individuals can interact with their own storage area? both from their desktop environment and from their jobs GUI and command-line le system emulation 21
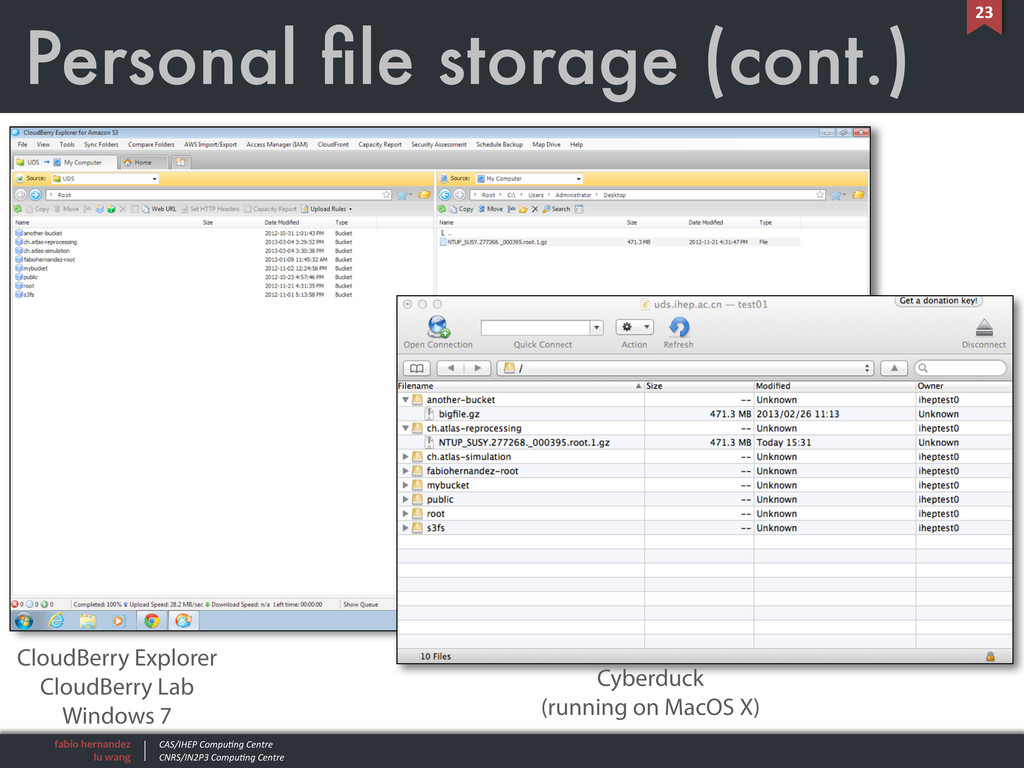
Personal file storage (cont.) • GUI MacOS: Cyberduck (open source, free) - Transmit and ExpandDrive (commercial) only work with Amazon servers Windows: CloudBerry Explorer (free) Linux: Cyberduck • Command line tools several tools available: s3curl, s3cmd we are developing our own (more on this later) • File system emulation s3fs: does not have all the features we want not really satisfactory solution found yet 22
Personal file storage (cont.) Command-line interface we are developing a CLI-based S3 client compatible with Amazon, Google, Huawei, … GO programming language exploit built-in concurrency stand-alone executable small size, so to avoid pre- installation and be downloadable 24 $ mucura --help Usage: mucura [--version] <command> [opts...] args... Accepted commands: lb list existing buckets mb make a new bucket ls list bucket contents rb remove a bucket up upload a file to an existing bucket dl download a file rm remove a file Use 'mucura help <command>' for getting more information on a specific command $ mucura dl http://s3.amazonaws.com/mucura/path/to/myFile /tmp
Integration with computing centre • Storage backend not exposed to the world we used nginx, con gured as a reverse proxy, exposing only HTTPS endpoint to the world nginx handles persistent connections, validation of client certi cates, load balancing in our testing environment, local clients (i.e. local jobs or individuals connected to the LAN) can directly interact with the S3 backend using either HTTP or HTTPS • Integration with grid infrastructure grid jobs need to have user credentials to interact with S3 backend avoid embedding the credentials int the job’s input sandbox how to provide grid jobs with credentials so that they can upload and download les? 26
Integration with computing centre (cont.) • Credential delivery service we prototyped of a web service for storing and delivering S3 credentials, based on the requester’s grid proxy (or X509 personal certi cate) uses PyGSI, the same component used by DIRAC servers for validating user proxies principle of operation: at execution time, the grid job uses this service to retrieve the credentials necessary to interact with the user’s S3 backend — once per job • Ideal solution on-demand creation of volatile credentials (pair of keys) to be used only by a single grid job, based on the user’s grid proxy credentials expire when the proxy certi cate expires currently not possible to implement with Huawei UDS because of limitation of 2 key pairs per existing account for implementing this mechanism one needs to control the storage backend 27
Integration with computing centre (cont.) • Service operations requirements interactive and scriptable con guration, storage accounting, network bandwidth usage, monitoring, generation of data for analytics purposes • Huawei UDS comes with a web-based GUI for operations: we didn’t explore it in depth 28
Issues with Huawei UDS • Metadata inconsistencies listing the contents of reportedly existing buckets gives ‘bucket does not exist’ error ‘internal error’ retrieved (even after several retries) when listing bucket contents successfully deleted objects may “reappear” when the contents of the bucket is retrieved some of these issues can be reproduced, others cannot: detailed trace information provided to Huawei representatives • Management interface impossible to retrieve the list of existing users in the system: need of a separate database to keep this information cannot create more than 2 pair of credentials (access key, secret key) per user: impossible to create “volatile” credentials cannot reuse a recently deleted user account before an expiration period (not documented) email addresses of users need to be unique, so cannot have more than one pair of credentials per individual, unless using fake email addresses • Operational issues time skewing of the head nodes: checks can be administratively bypassed but then les get a wrong creation date 31
Perspectives • Transcontinental le replication tests between CERN (Geneva) / CCIN2P3 (Lyon) and IHEP (Beijing) exploration of self-subscription of les among sites using S3: how to orchestrate the transfers to avoid overloading sites? • Prototype a client to expose a le system interface in front of a S3 backend users want to navigate the le system with their familiar tools a better s3fs, emphasis on usage by humans and good integration with personal computers environment • Perform the same tests using a software-based solution, such as OpenStack Swift, Riak CS or other S3- or CDMI- compliant backend • Explore value added services in top of raw le storage through S3 client-side encryption, le synchronization (à la Dropbox), client-side S3 endpoint aggregation, … 33
Conclusions • We have made progress understanding what is needed to integrate cloud-based storage for supporting high energy physics research both for experiment-wide data and for individual les • Prospects look promising • More work needs to be done to reach production readiness larger scale testing involve end-users, both experiments and individuals 34
Your feedback is very welcome • As an individual, would you be interested in using such a service? • As a data center operator, are you interested in operating such kind of storage service? what features would you like to see in it to make it more operator-friendly 35
![ISGC 2013 — Taipei, March 21st 2013 Fabio Hernandez [email protected]](https://files.speakerdeck.com/presentations/a0cb2aa0abee0130cde802481b2a3015/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}