from Practical Perspectives Haruka Kiyohara, Kosuke Kawakami Haruka Kiyohara, Tokyo Institute of Technology https://sites.google.com/view/harukakiyohara September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 1
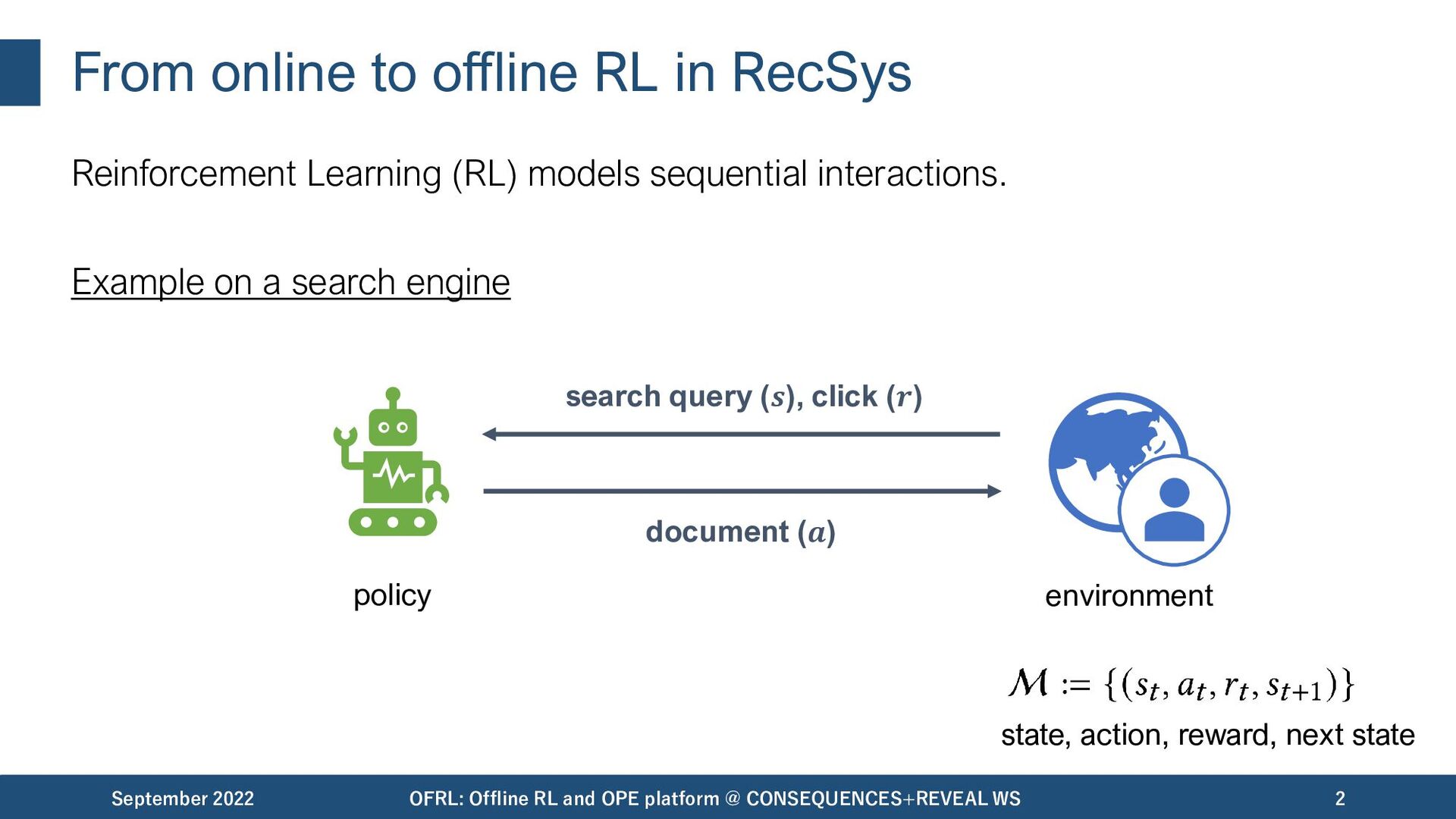
models sequential interactions. Example on a search engine September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 2 search query (𝒔), click (𝒓) document (𝒂) environment policy state, action, reward, next state
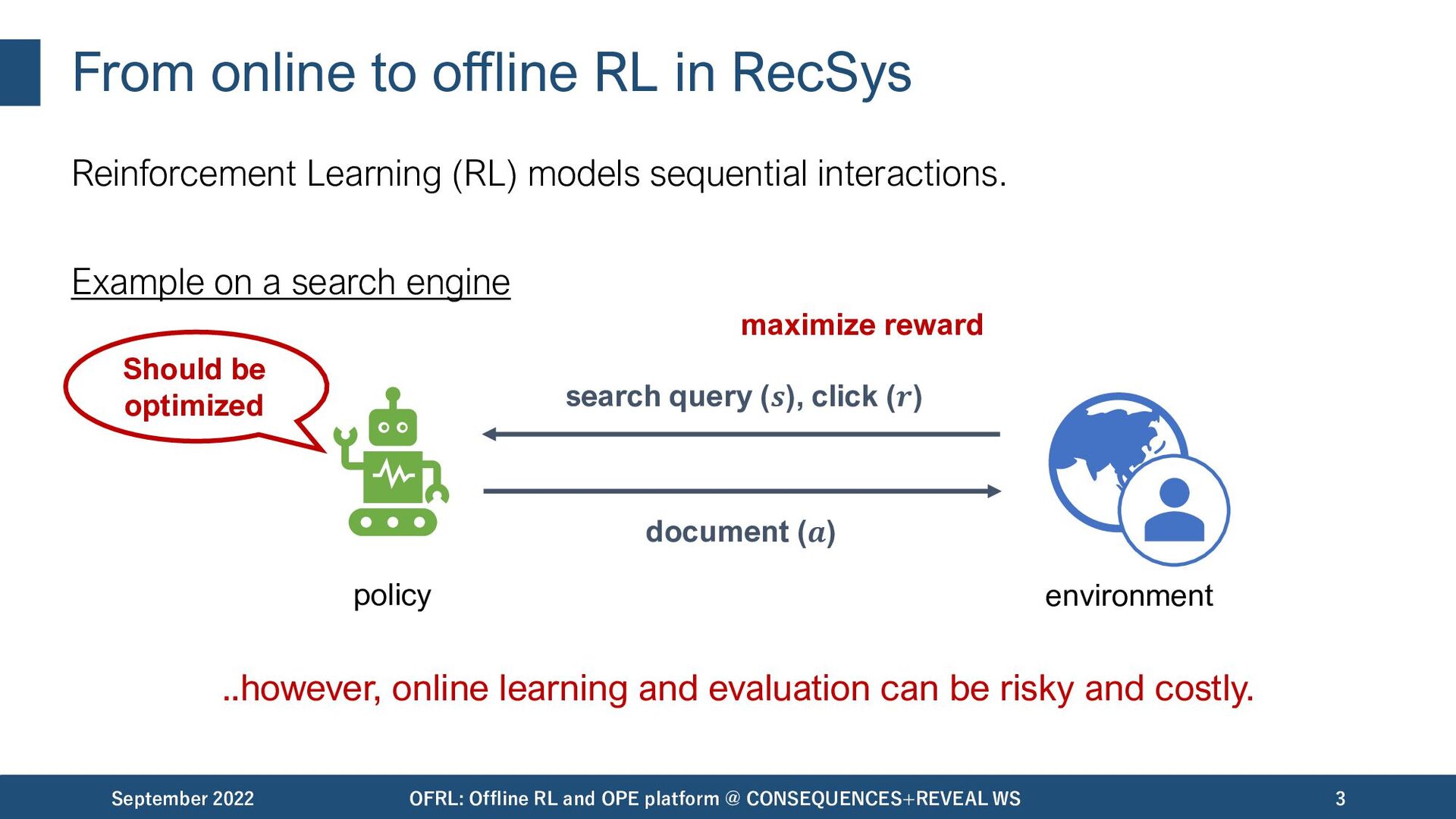
models sequential interactions. Example on a search engine ..however, online learning and evaluation can be risky and costly. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 3 environment policy Should be optimized search query (𝒔), click (𝒓) document (𝒂) maximize reward
growing as a safe and cost-effective substitute for online counterpart. We’ve implemented a new offline RL platform to facilitate its practical application. (especially focusing on the policy evaluation part) September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 4 online logged data policy
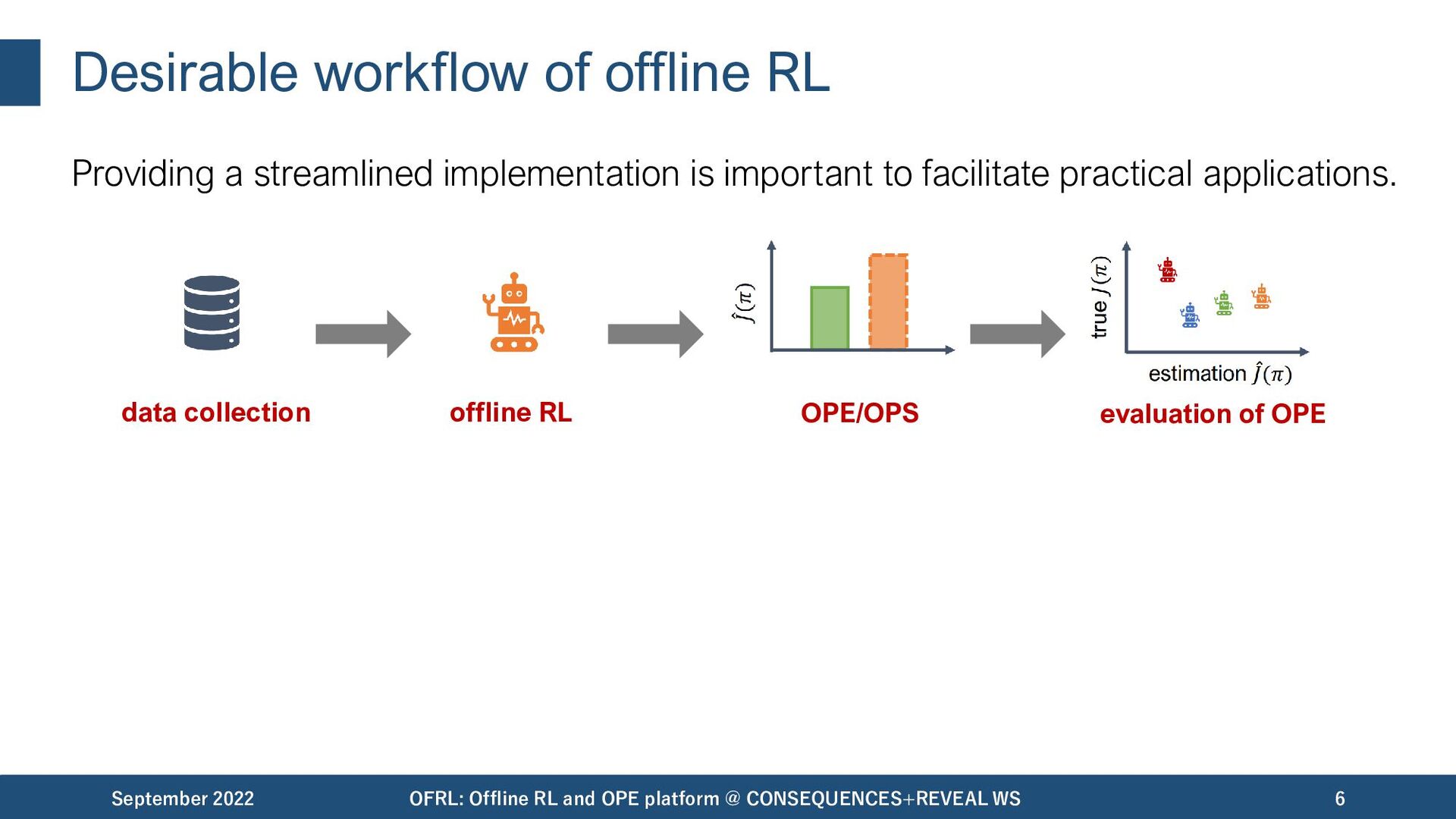
important to facilitate practical applications. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 6 data collection offline RL OPE/OPS evaluation of OPE
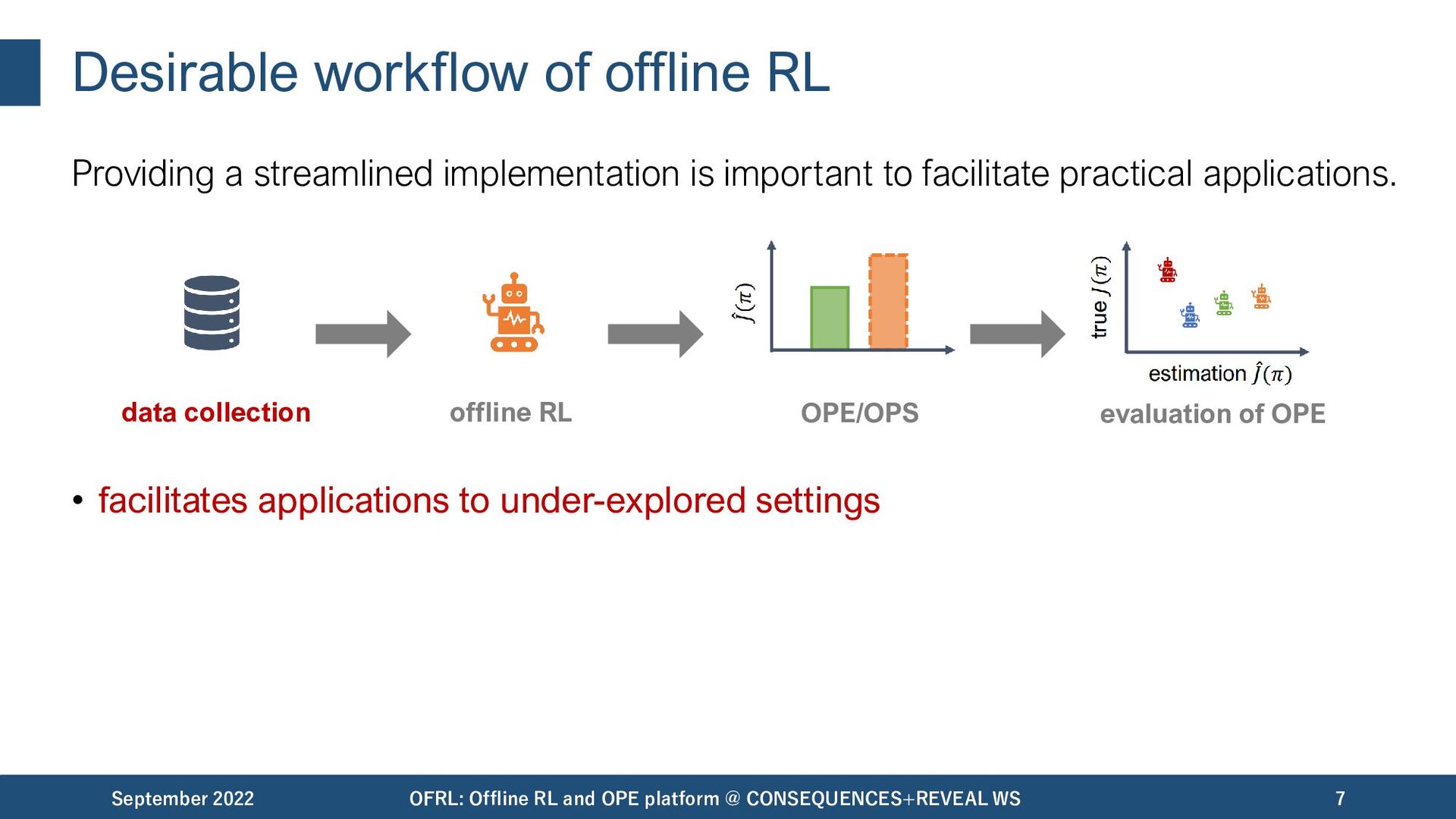
important to facilitate practical applications. • facilitates applications to under-explored settings September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 7 data collection offline RL OPE/OPS evaluation of OPE
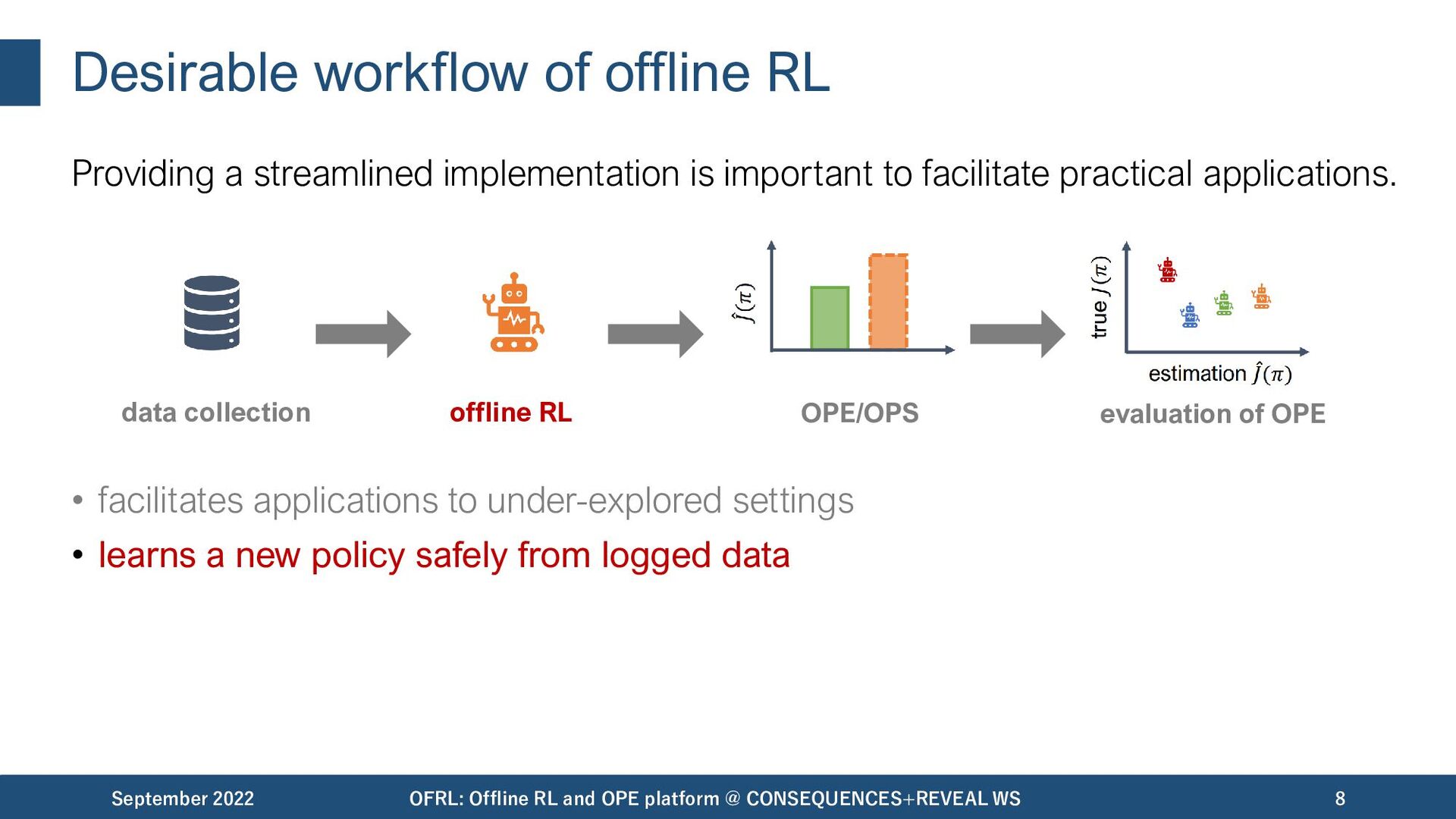
important to facilitate practical applications. • facilitates applications to under-explored settings • learns a new policy safely from logged data September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 8 data collection offline RL OPE/OPS evaluation of OPE
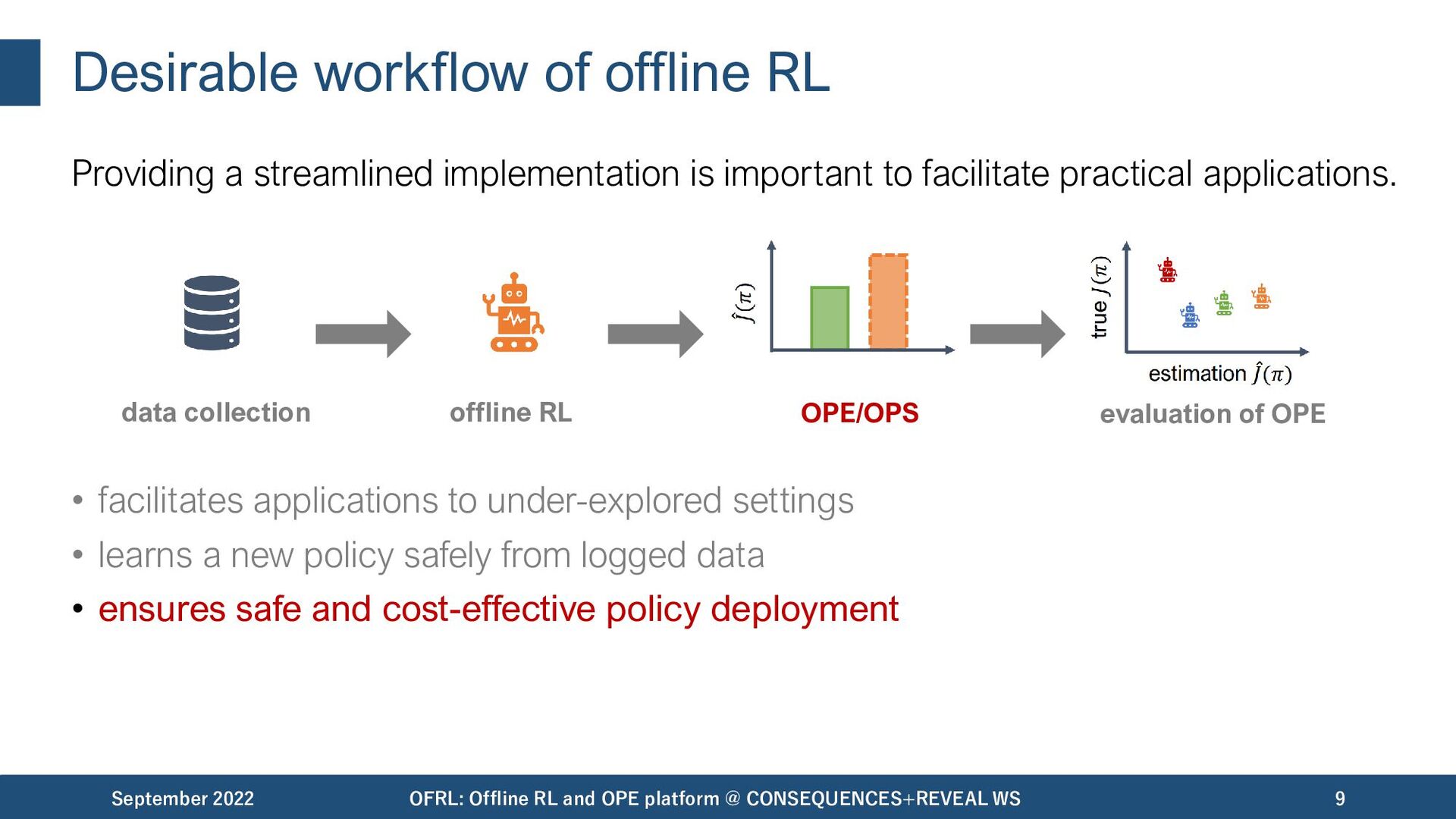
important to facilitate practical applications. • facilitates applications to under-explored settings • learns a new policy safely from logged data • ensures safe and cost-effective policy deployment September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 9 data collection offline RL OPE/OPS evaluation of OPE
important to facilitate practical applications. • facilitates applications to under-explored settings • learns a new policy safely from logged data • ensures safe and cost-effective policy deployment • validates the reliability of OPE/OPS methods September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 10 data collection offline RL OPE/OPS evaluation of OPE
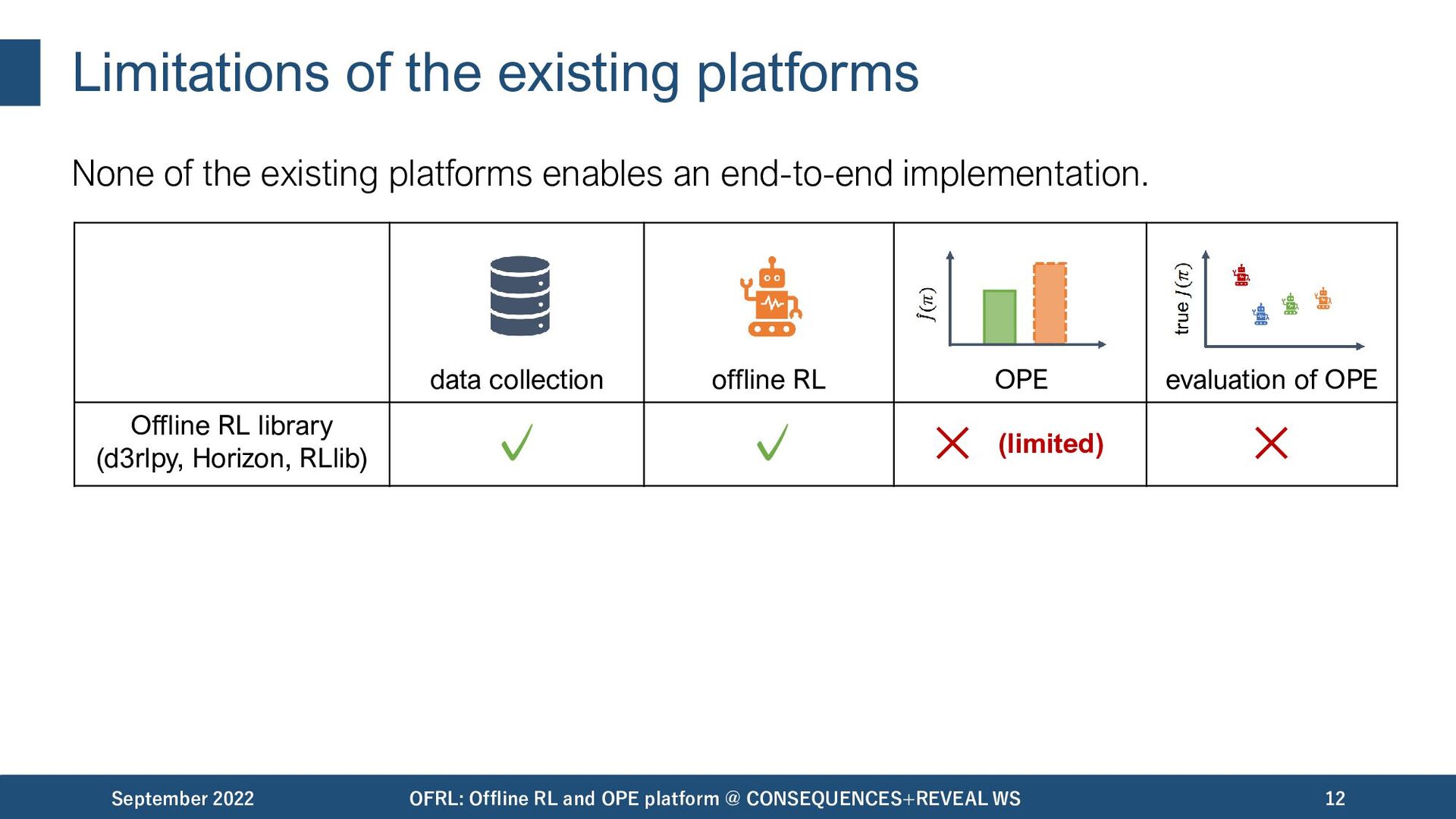
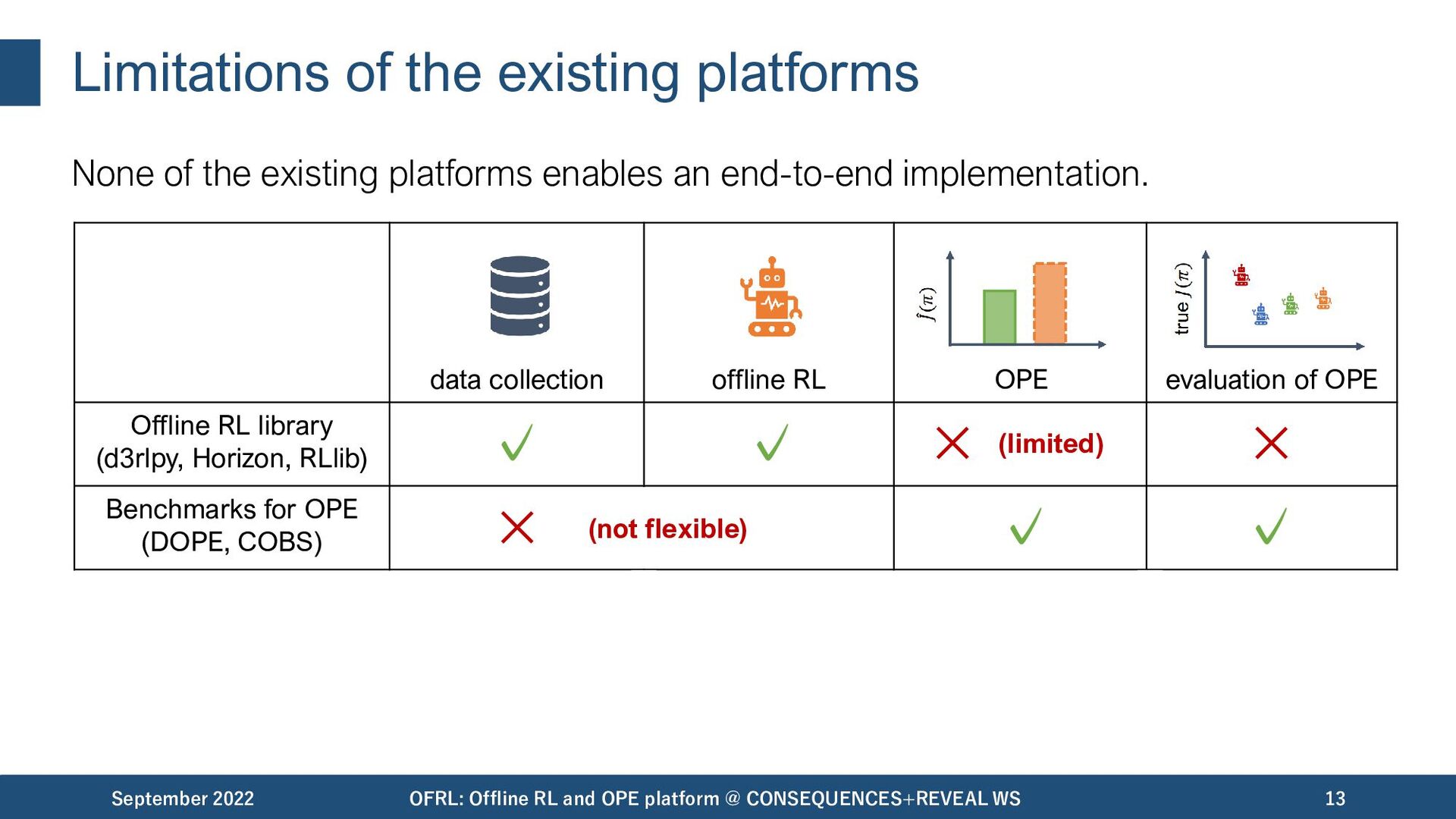
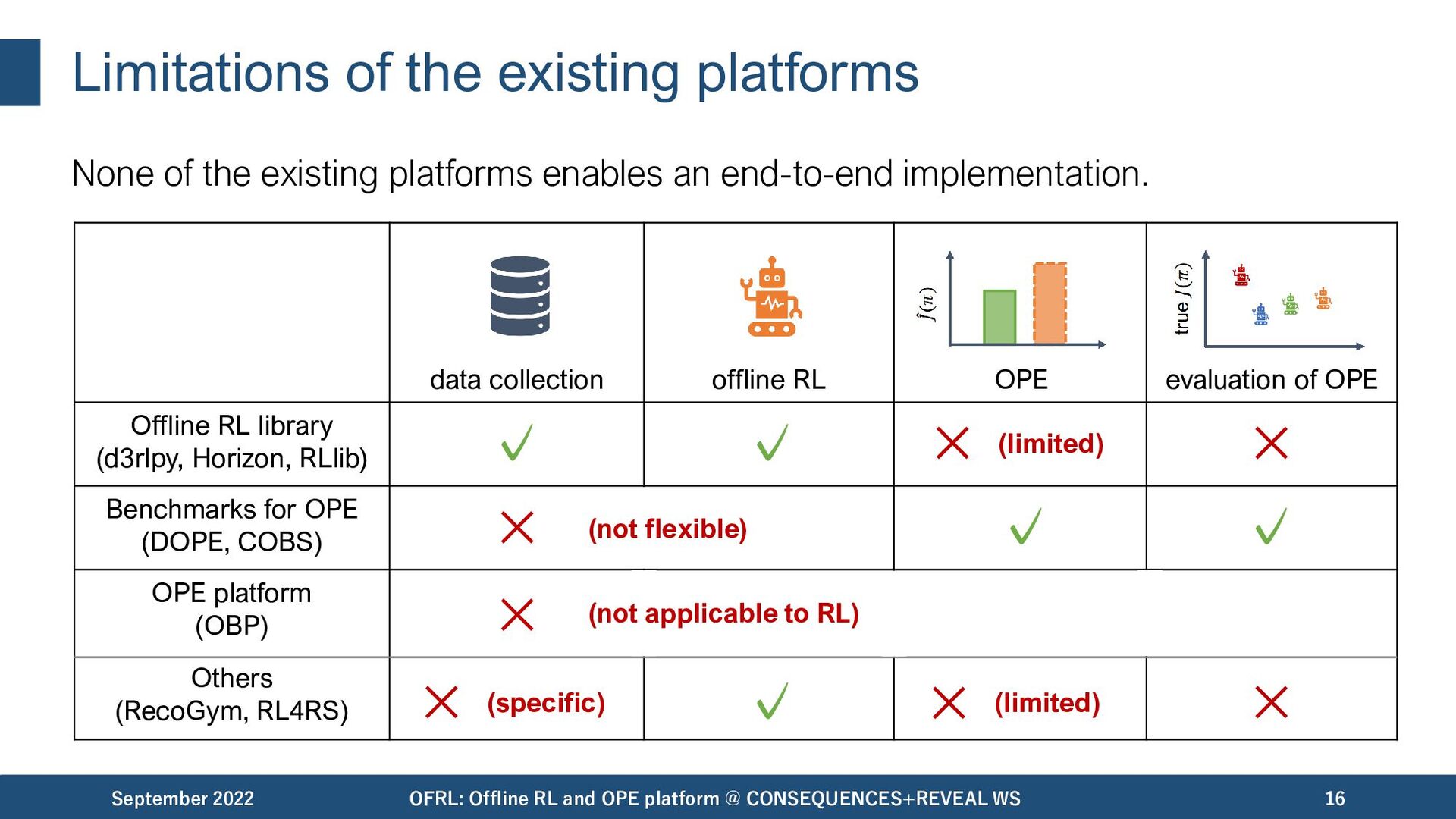
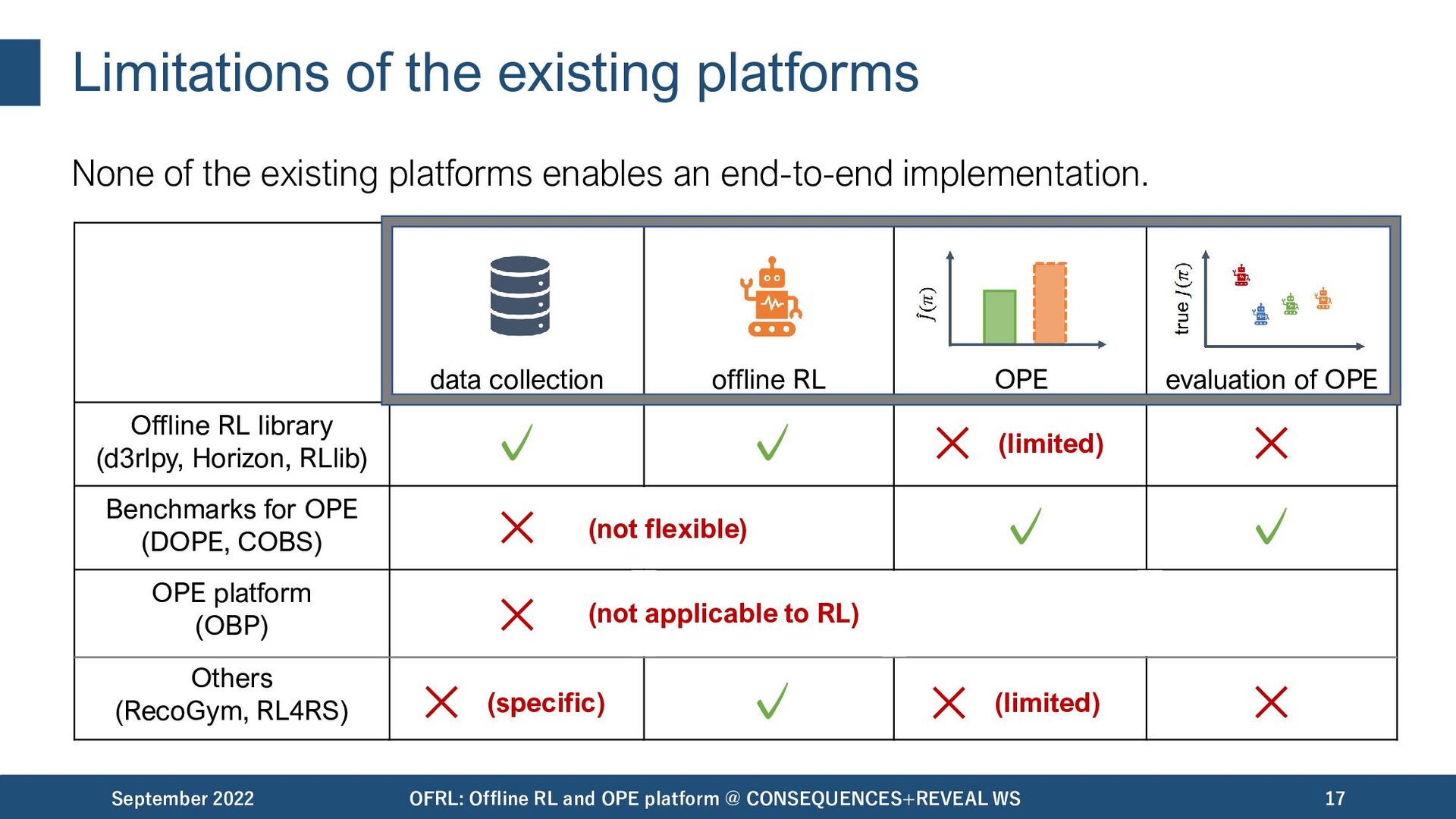
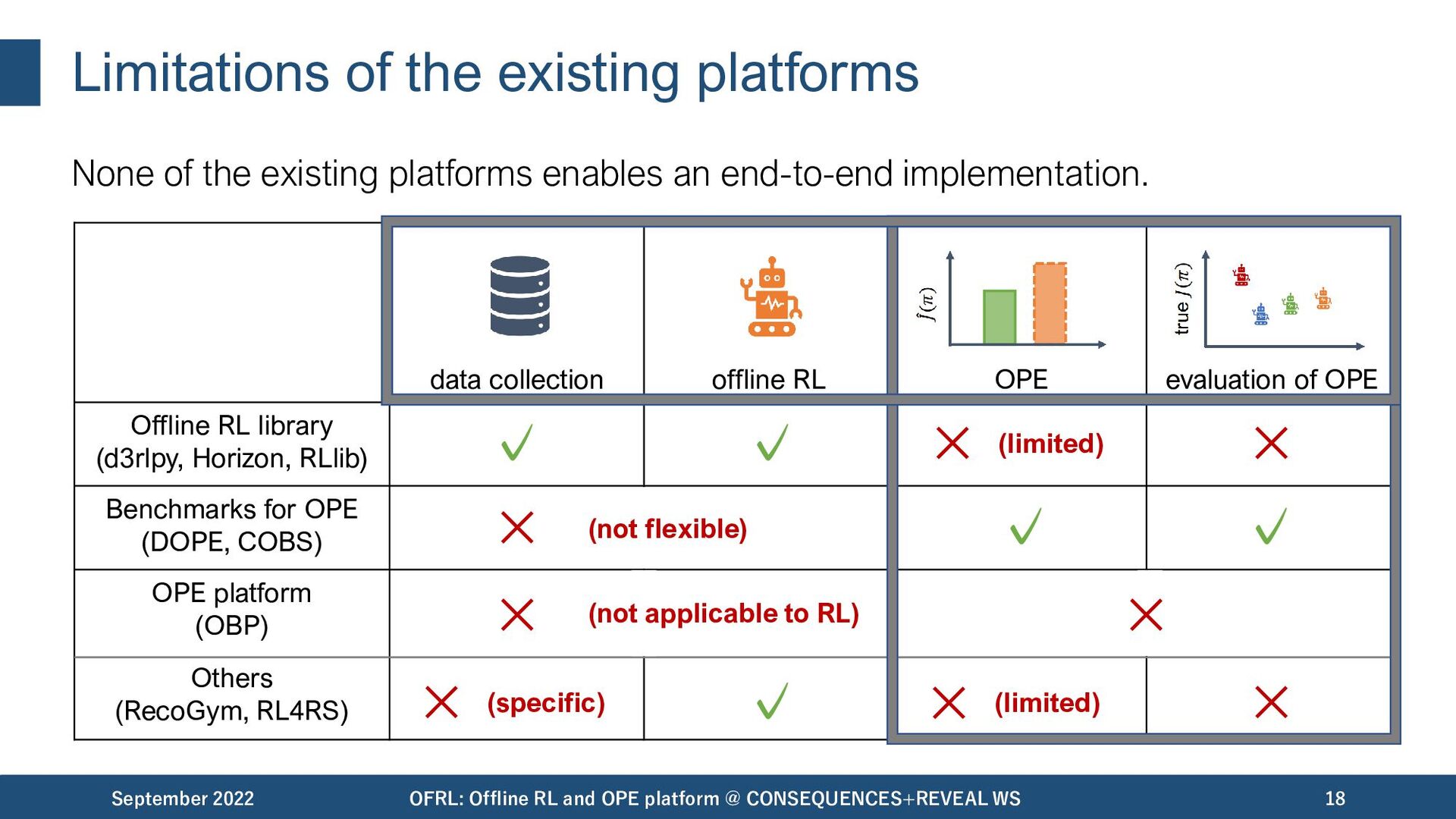
important to facilitate practical applications. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 11 data collection offline RL OPE/OPS evaluation of OPE Unfortunately, most of the existing platforms / benchmark suites are insufficient to enable an end-to-end implementation..
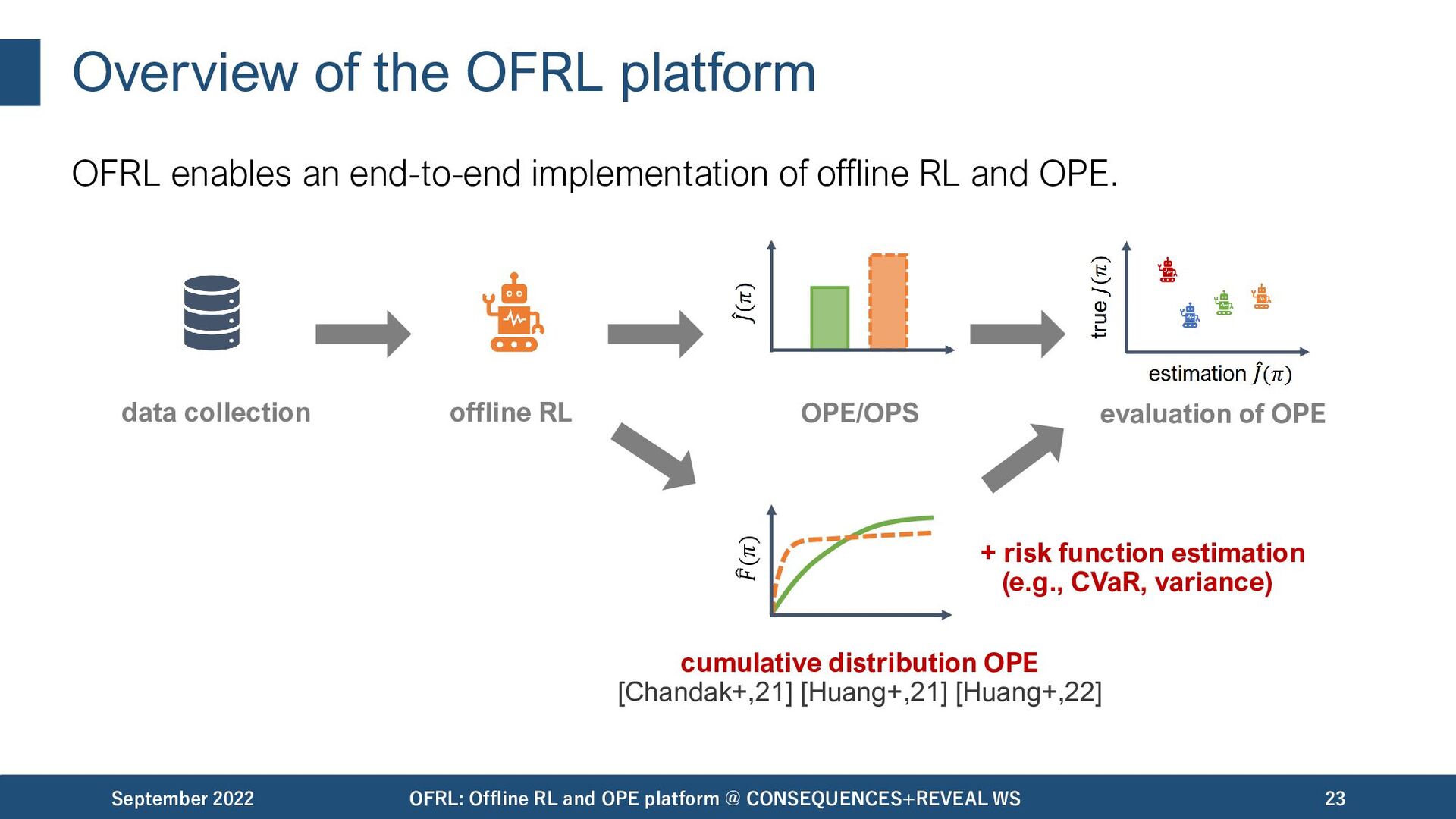
of offline RL and OPE. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 20 data collection offline RL OPE/OPS evaluation of OPE
of offline RL and OPE. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 21 data collection offline RL OPE/OPS evaluation of OPE focus of many existing platforms
of offline RL and OPE. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 22 data collection offline RL OPE/OPS evaluation of OPE focus of many existing platforms our focus
of offline RL and OPE. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 23 data collection offline RL OPE/OPS evaluation of OPE 𝐹(𝜋) cumulative distribution OPE [Chandak+,21] [Huang+,21] [Huang+,22] + risk function estimation (e.g., CVaR, variance)
code. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 25 Quick demo with RTBGym offline RL OPE/OPS evaluation of OPE data collection
code. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 26 Quick demo with RTBGym offline RL OPE/OPS evaluation of OPE data collection
code. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 27 Quick demo with RTBGym offline RL OPE/OPS evaluation of OPE data collection
code. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 28 Quick demo with RTBGym data collection offline RL OPE/OPS evaluation of OPE
code. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 29 Quick demo with RTBGym offline RL OPE/OPS evaluation of OPE data collection
d3rlpy for the offline RL part. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 30 data collection offline RL OPE/OPS evaluation of OPE
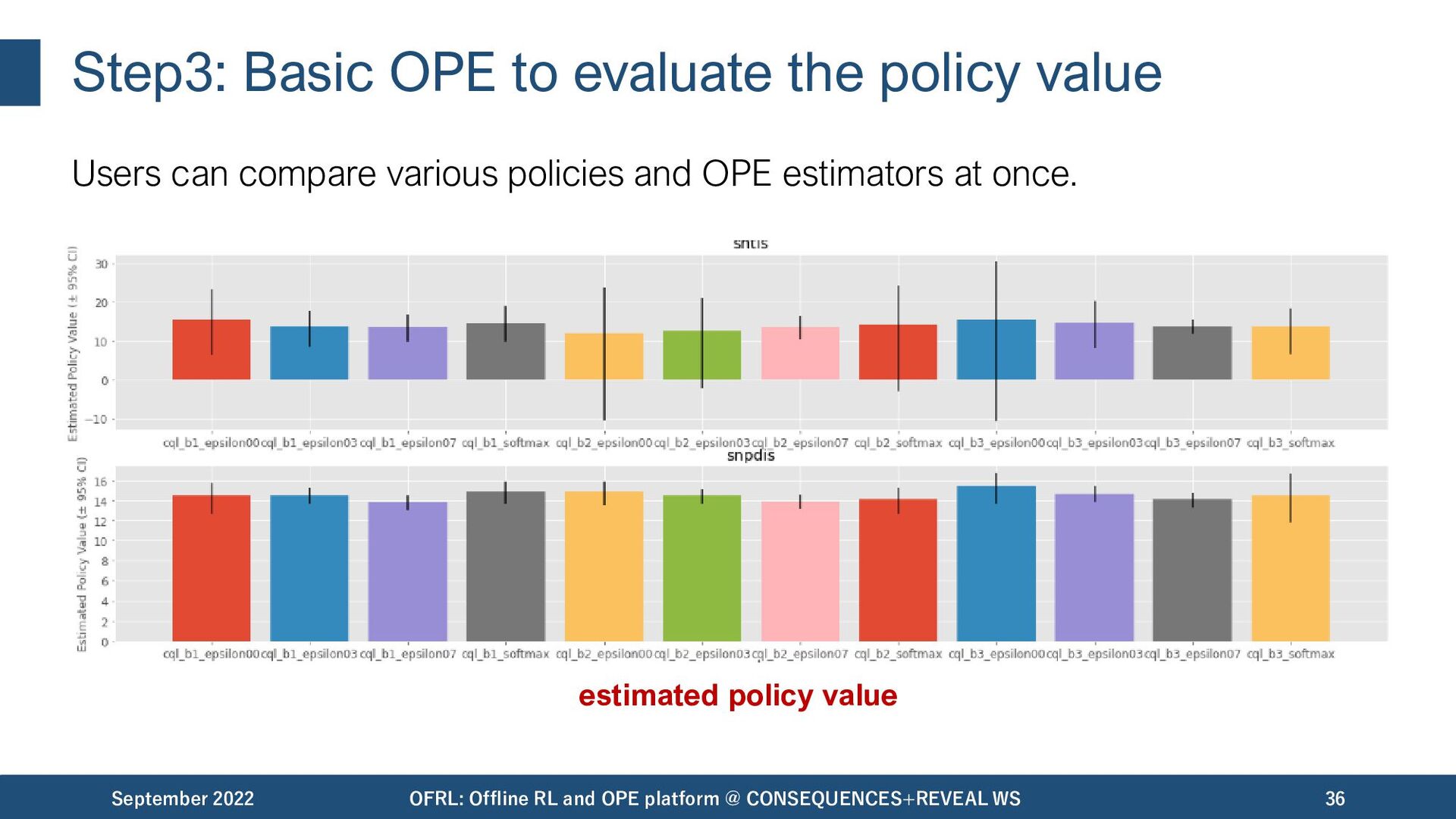
compare various policies and OPE estimators at once. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 31 data collection offline RL OPE/OPS evaluation of OPE
compare various policies and OPE estimators at once. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 32 data collection offline RL OPE/OPS evaluation of OPE
compare various policies and OPE estimators at once. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 33 data collection offline RL OPE/OPS evaluation of OPE
compare various policies and OPE estimators at once. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 34 data collection offline RL OPE/OPS evaluation of OPE
compare various policies and OPE estimators at once. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 35 data collection offline RL OPE/OPS evaluation of OPE
compare various policies and OPE estimators at once. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 36 estimated policy value
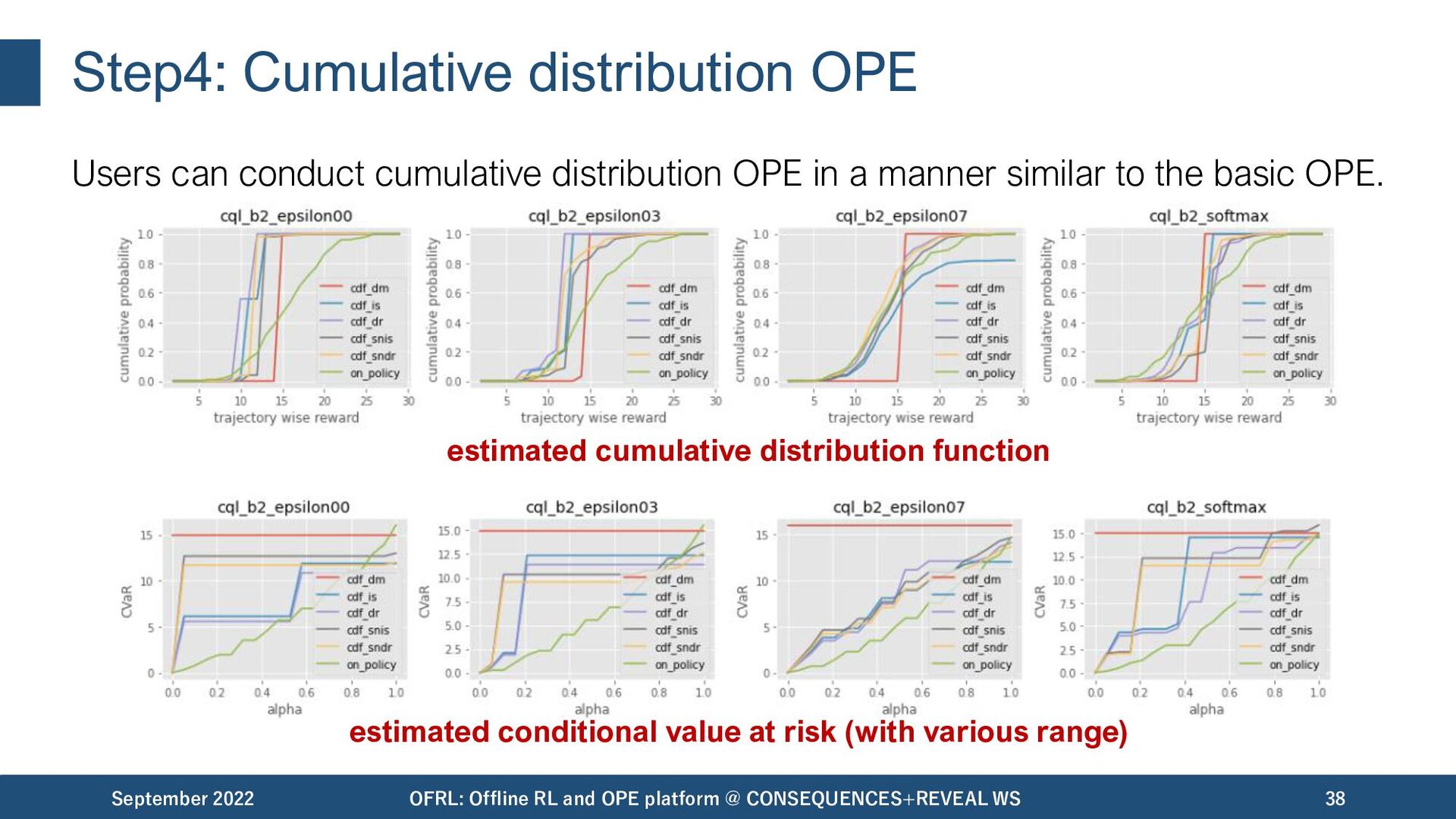
OPE platform @ CONSEQUENCES+REVEAL WS 37 Users can conduct cumulative distribution OPE in a manner similar to the basic OPE. data collection offline RL OPE/OPS evaluation of OPE
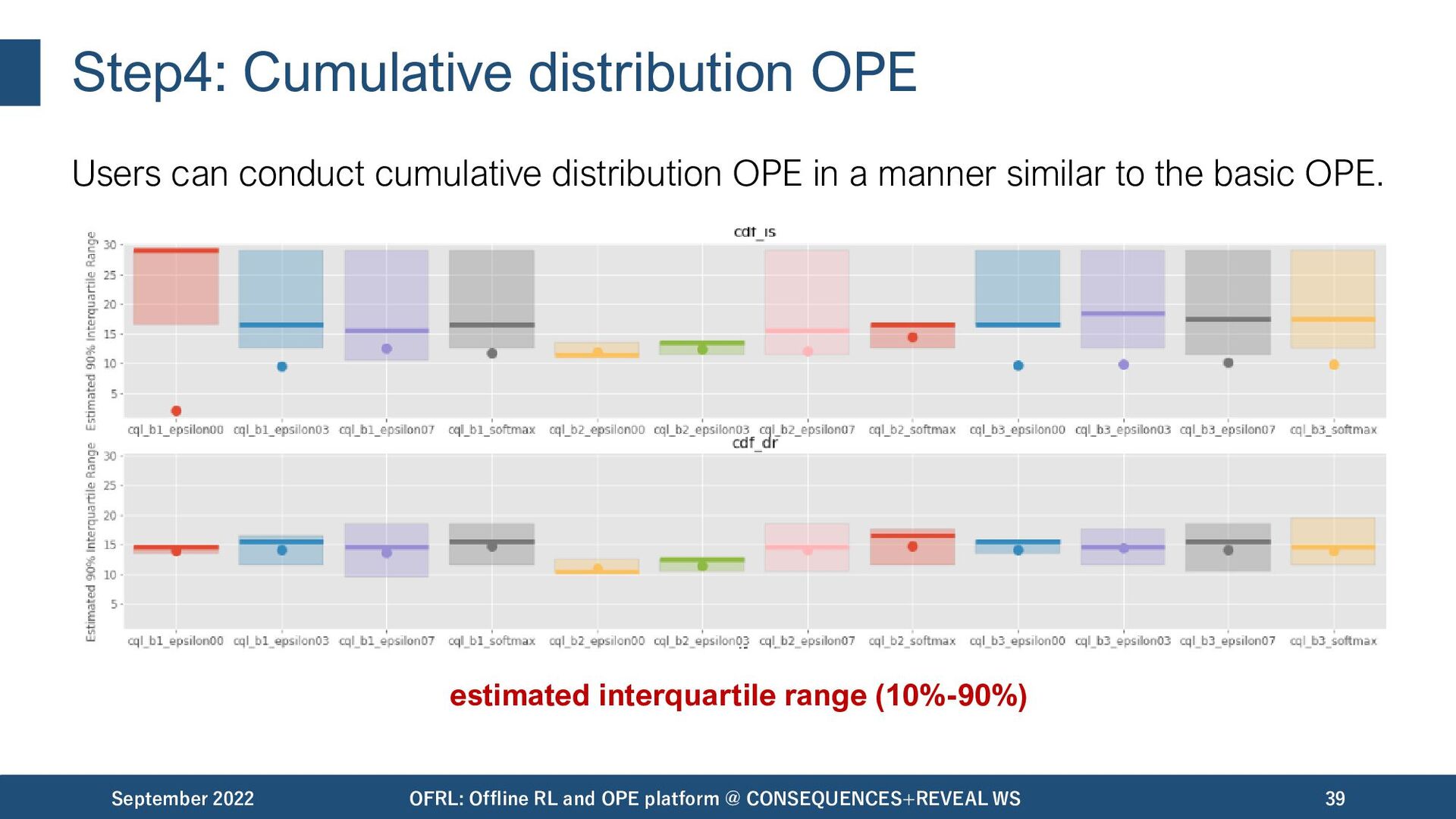
in a manner similar to the basic OPE. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 38 estimated cumulative distribution function estimated conditional value at risk (with various range)
in a manner similar to the basic OPE. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 39 estimated interquartile range (10%-90%)
implement both OPS and evaluation of OPE/OPS. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 40 data collection offline RL OPE/OPS evaluation of OPE
implement both OPS and evaluation of OPE/OPS. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 41 comparing the true (x) and estimated (y) variance evaluating the quality of OPS results
they are safe and cost-effective substitutes of the online counterparts. • To facilitate their practical application, we are building a new software (OFRL). • OFRL is the first end-to-end platform for offline RL and OPE. • OFRL provides informative insights on policy performance using cumulative distribution OPE. OFRL enables quick and flexible prototyping of offline RL and OPE, facilitating practical applications in a range of problem settings. September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 42
OPE enables to estimate the cumulative distribution function (CDF) and some risk functions, which is of great practical relevance. [Chandak+,21] [Huang+,21] [Huang+,22] September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 44 cumulative distribution OPE 𝐹(𝜋) cumulative probability calculate various risk function based on CDF
An Offline Deep Reinforcement Learning Library.” 2021. https://arxiv.org/abs/2111.03788 [Gauci+,18 (Horizon)] Jason Gauci, Edoardo Conti, Yitao Liang, Kittipat Virochsiri, Yuchen He, Zachary Kaden, Vivek Narayanan, Xiaohui Ye, Zhengxing Chen, and Scott Fujimoto. “Horizon: Facebook's Open Source Applied Reinforcement Learning Platform.” 2018. https://arxiv.org/abs/1811.00260 [Liang+,18 (RLlib)] Eric Liang, Richard Liaw, Philipp Moritz, Robert Nishihara, Roy Fox, Ken Goldberg, Joseph E. Gonzalez, Michael I. Jordan, and Ion Stoica. “RLlib: Abstractions for Distributed Reinforcement Learning.” ICML, 2018. https://arxiv.org/abs/1712.09381 September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 46
George Tucker, Ziyu Wang, Alexander Novikov, Mengjiao Yang, Michael R. Zhang, Yutian Chen, Aviral Kumar, Cosmin Paduraru, Sergey Levine, and Tom Le Paine. “Benchmarks for Deep Off-Policy Evaluation.” ICLR, 2021. https://arxiv.org/abs/2103.16596 [Voloshin+,21 (COBS)] Cameron Voloshin, Hoang M. Le, Nan Jiang, and Yisong Yue. “Empirical Study of Off-Policy Policy Evaluation for Reinforcement Learning.” NeurIPS dataset&benchmark, 2021. https://arxiv.org/abs/1911.06854 [Rohde+,18 (RecoGym)] David Rohde, Stephen Bonner, Travis Dunlop, Flavian Vasile, and Alexandros Karatzoglou “RecoGym: A Reinforcement Learning Environment for the problem of Product Recommendation in Online Advertising.” 2018. https://arxiv.org/abs/1808.00720 September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 47
Saito. “Accelerating Offline Reinforcement Learning Application in Real-Time Bidding and Recommendation: Potential Use of Simulation.” 2021. https://arxiv.org/abs/2109.08331 [Chandak+,21 (cumulative distribution OPE)] Yash Chandak, Scott Niekum, Bruno Castro da Silva, Erik Learned-Miller, Emma Brunskill, and Philip S. Thomas. “Universal Off-Policy Evaluation.” NeurIPS, 2021. https://arxiv.org/abs/2104.12820 [Huang+,21 (cumulative distribution OPE)] Audrey Huang, Liu Leqi, Zachary C. Lipton, and Kamyar Azizzadenesheli. “Off-Policy Risk Assessment in Contextual Bandits.” NeurIPS, 2021. https://arxiv.org/abs/2104.12820 September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 49
Zachary C. Lipton, and Kamyar Azizzadenesheli. “Off-Policy Risk Assessment for Markov Decision Processes.” AISTATS, 2022. https://proceedings.mlr.press/v151/huang22b.html [Hasselt+,16 (DDQN)] Hado van Hasselt, Arthur Guez, and David Silver. “Deep Reinforcement Learning with Double Q-learning.” AAAI, 2016. https://arxiv.org/abs/1509.06461 [Kumar+,20 (CQL)] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. “Conservative Q-Learning for Offline Reinforcement Learning.” NeurIPS, 2020. https://arxiv.org/abs/2006.04779 [Le+,19 (DM)] Hoang M. Le, Cameron Voloshin, and Yisong Yue. “Batch Policy Learning under Constraints.” ICML, 2019. https://arxiv.org/abs/1903.08738 September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 50
Satinder P. Singh. “Eligibility Traces for Off-Policy Policy Evaluation.” ICML, 2000. https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=1079&context=cs_facult y_pubs [Jiang&Li,16 (DR)] Nan Jiang and Lihong Li. “Doubly Robust Off-policy Value Evaluation for Reinforcement Learning.” ICML, 2016. https://arxiv.org/abs/1511.03722 [Thomas&Brunskill,16 (DR)] Philip S. Thomas and Emma Brunskill. “Data-Efficient Off-Policy Policy Evaluation for Reinforcement Learning.” ICML, 2016. https://arxiv.org/abs/1604.00923 September 2022 OFRL: Offline RL and OPE platform @ CONSEQUENCES+REVEAL WS 51
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References (1/6) [Seno+,21 (d3rlpy)] Takuma Seno and Michita Imai. “d3rlpy:](https://files.speakerdeck.com/presentations/e2fbf57fcb4f42f194769bed9619e9a1/slide_45.jpg){kind=link}
![References (2/6) [Fu+,21 (DOPE)] Justin Fu, Mohammad Norouzi, Ofir Nachum,](https://files.speakerdeck.com/presentations/e2fbf57fcb4f42f194769bed9619e9a1/slide_46.jpg){kind=link}
![References (3/6) [Wang+,21 (RL4RS)] Kai Wang, Zhene Zou, Yue Shang,](https://files.speakerdeck.com/presentations/e2fbf57fcb4f42f194769bed9619e9a1/slide_47.jpg){kind=link}
![References (4/6) [Kiyohara+,21 (RTBGym)] Haruka Kiyohara, Kosuke Kawakami, and Yuta](https://files.speakerdeck.com/presentations/e2fbf57fcb4f42f194769bed9619e9a1/slide_48.jpg){kind=link}
![References (5/6) [Huang+,22 (cumulative distribution OPE)] Audrey Huang, Liu Leqi,](https://files.speakerdeck.com/presentations/e2fbf57fcb4f42f194769bed9619e9a1/slide_49.jpg){kind=link}
![References (6/6) [Precup+,00 (IPS)] Doina Precup, Richard S. Sutton, and](https://files.speakerdeck.com/presentations/e2fbf57fcb4f42f194769bed9619e9a1/slide_50.jpg){kind=link}