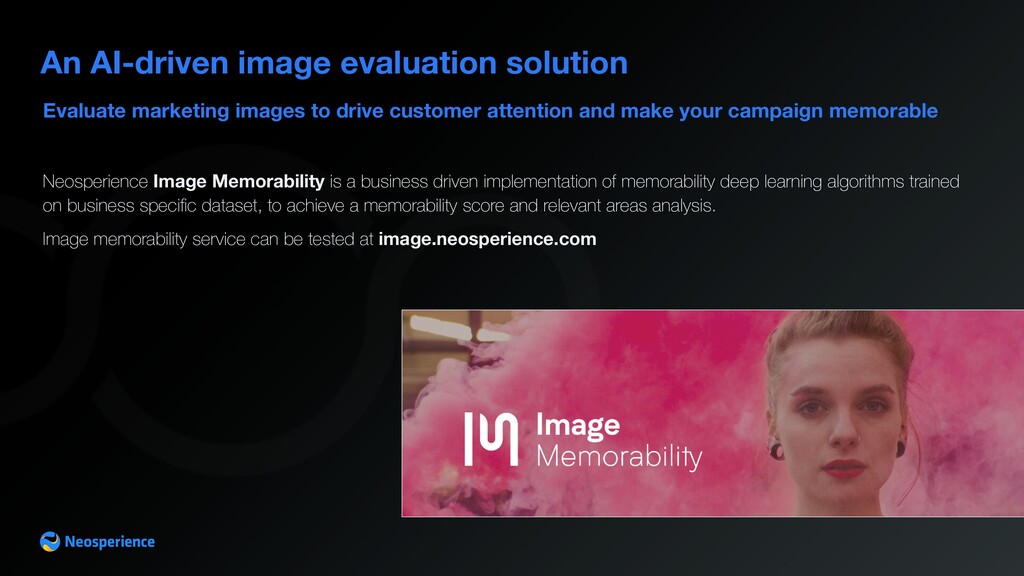
campaign memorable An AI-driven image evaluation solution Neosperience Image Memorability is a business driven implementation of memorability deep learning algorithms trained on business specific dataset, to achieve a memorability score and relevant areas analysis. Image memorability service can be tested at image.neosperience.com
is good for marketing How it works? Great authored images are can be misleading when you analyze their memorability map score 9.32 / 10 these areas are the most relevant of the image (red color), so they have the highest stickiness in viewer’s brain this is probably the most interesting part from a brand perspective, but the image does not focus attention on it (cold color)
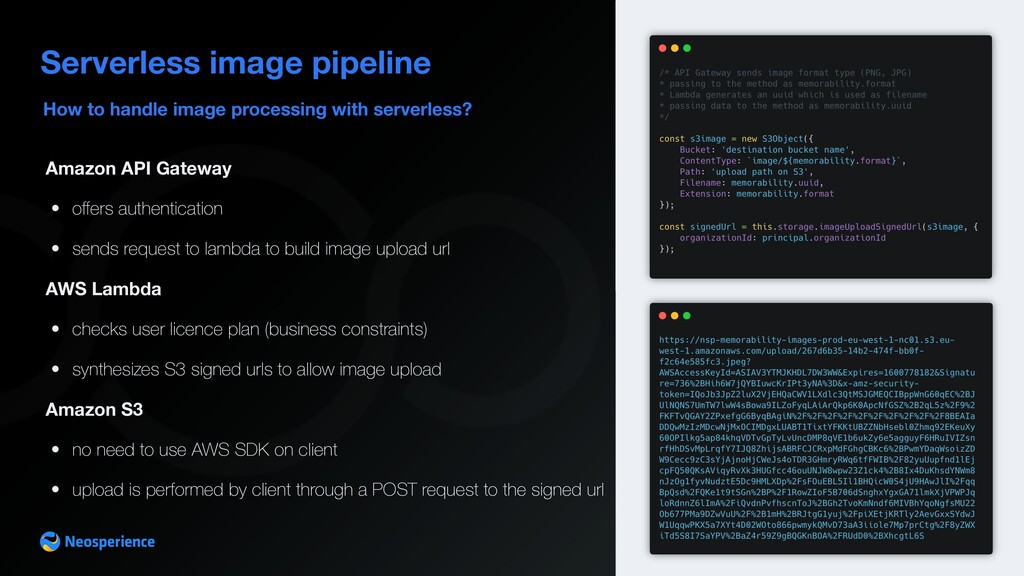
easy task Start from service requirements - easy to build - easy to deploy and operate - easy to integrate - implement memorability algorithm (score, heatmap) - serverless (never pay for idle, scalability) - cost-effective - response time within seconds
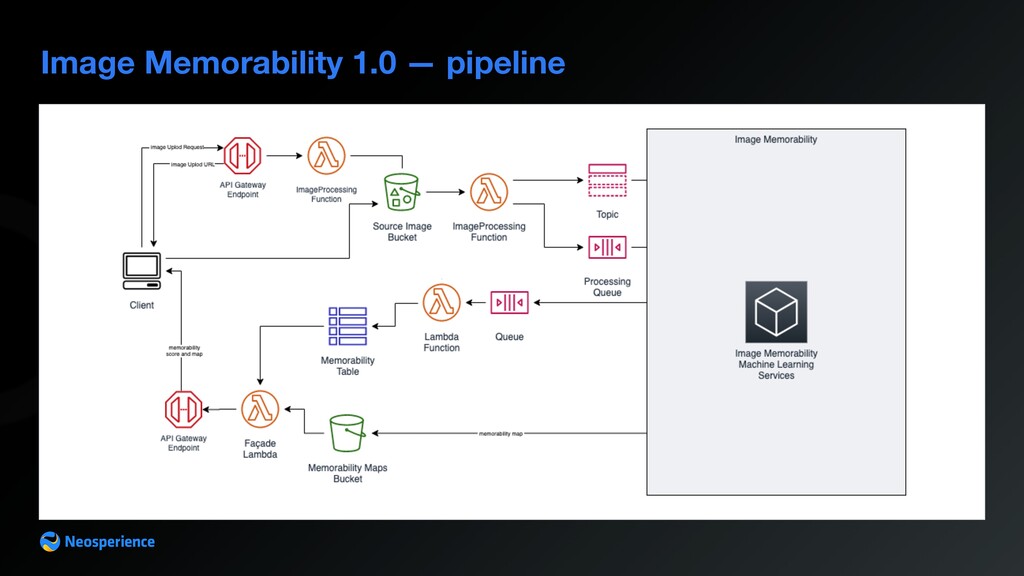
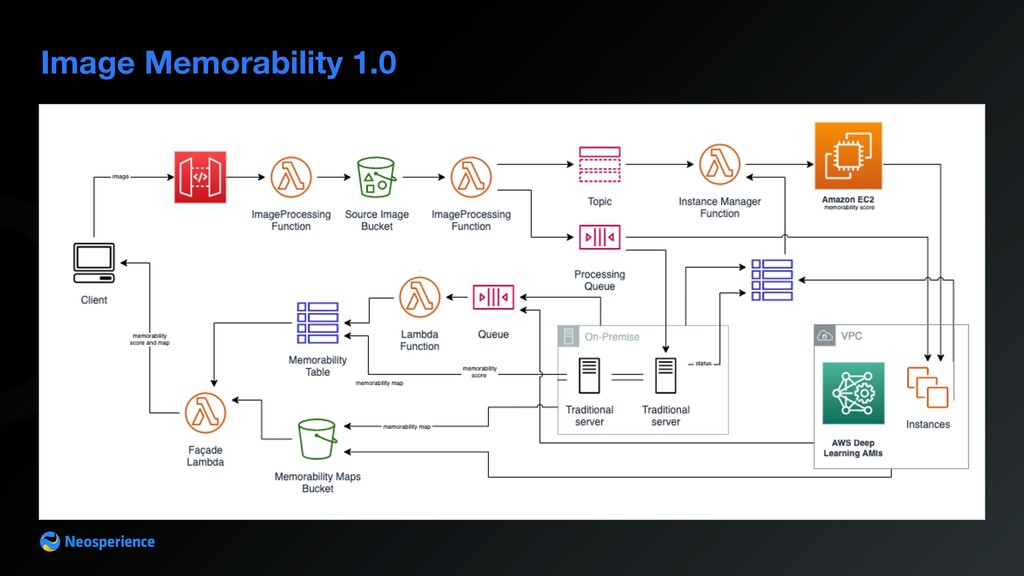
Amazon S3 • no need to use AWS SDK on client • upload is performed by client through a POST request to the signed url AWS Lambda • checks user licence plan (business constraints) • synthesizes S3 signed urls to allow image upload Amazon API Gateway • offers authentication • sends request to lambda to build image upload url
Rekognition • automated AI service with available with pre-trained state-of-the-art deep learning models • ready to analyze images for classification, object detection and labelling • additional feature such as logo and celebrity recognition • support for face detection, analysis and identification How to leverage? • upload your image to S3 and pass the reference to the Rekognition API, or send a base64 encoded image directly from your client to the API.
custom labels Amazon Rekognition with custom labels • provide a set of labelled images to fine tune your training • images can be uploaded in batches using Amazon SageMaker manifest format • it solves a classification problem, we need a regression number (score) with something else deeply related to how network performs
easy to deploy and operate ✓ easy to integrate ✗ implement memorability algorithm (score, heatmap) ✓ serverless (never pay for idle, scalability) ✓ cost-effective ✓ response time within seconds
instances for deep learning • GPU instances (p2, p3 instance type) • model training and inference on the same cluster • bring your own deep learning framework (PyTorch, Keras) • can implement any ML model on this architecture How to leverage? • needs an image processing pipeline to handle images • needs a scheduling logic to process data • needs S3 bridge to store and retrieve data EC2 p3 instance Deep Learning AMI
instance type) • model training and inference on the same cluster • bring your own deep learning framework (PyTorch, Keras) • can implement any ML model on this architecture A GPU powered EC2 instance Amazon Deep Learning Instances EC2 instances for deep learning • cost effective GPU instances (any instance type) • model training and inference on different cluster • bring your own deep learning framework (PyTorch, Keras) • can implement any ML model on this architecture How to leverage? • needs an image processing pipeline to handle images • needs a scheduling logic to process data • needs S3 bridge to store and retrieve data EC2 Deep Learning AMI Elastic Inference
easy to deploy and operate - easy to integrate ✓ implement memorability algorithm (score, heatmap) ✗ serverless (never pay for idle, scalability) ✗ cost-effective ✓ response time within seconds EC2 Deep Learning AMI Elastic Inference
Instances, training and inference platform • Jupyter Notebooks managed in the cloud • scales up and down training across multiple instances • support to inference endpoint creation and model hosting • testing, debugging, and fine-tuning through SageMaker Studio • allow building custom ML models such as AMNet How to leverage? • needs an image processing pipeline to handle images • needs S3 bridge to store and retrieve data Amazon SageMaker
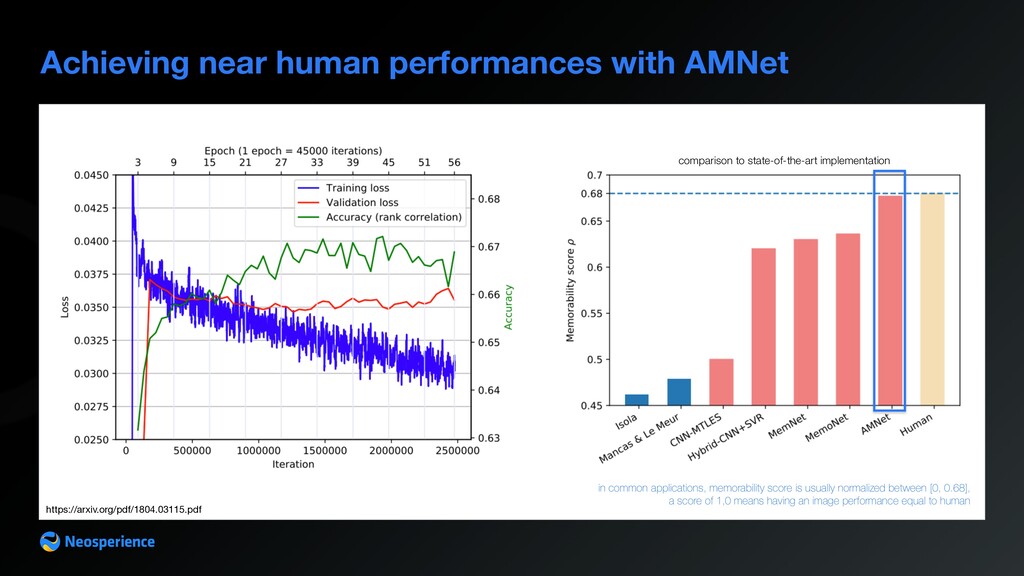
score is usually normalized between [0, 0.68], a score of 1,0 means having an image performance equal to human comparison to state-of-the-art implementation https://arxiv.org/pdf/1804.03115.pdf
easy to deploy and operate - easy to integrate ✓ implement memorability algorithm (score, heatmap) ✓ serverless (never pay for idle, scalability) - cost-effective ✓ response time within seconds EC2 Deep Learning AMI Elastic Inference
results Image inference with a regression model • memorability score is built with a single evaluation of the network • shrinking down the CNN used has a minimum impact on accuracy (from 0.677 to 0.64) but a huge impact on performances • shrinking the network means being able to adopt on a more cost-effective approach Backpropagation to compute image heatmap • is built back propagating network weights and checking activations • is computationally intensive even on GPU (15s on an nVidia Tesla V100)
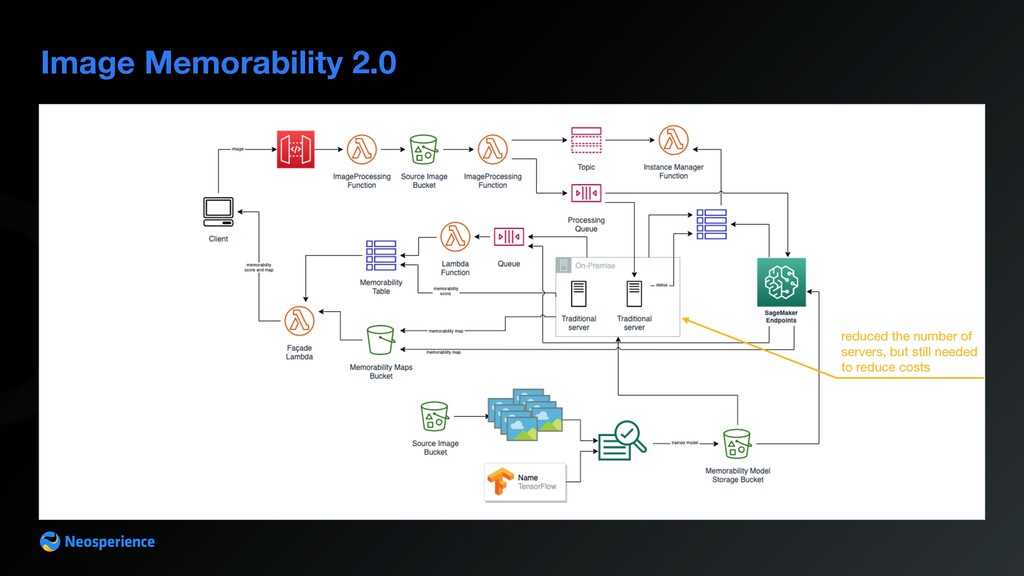
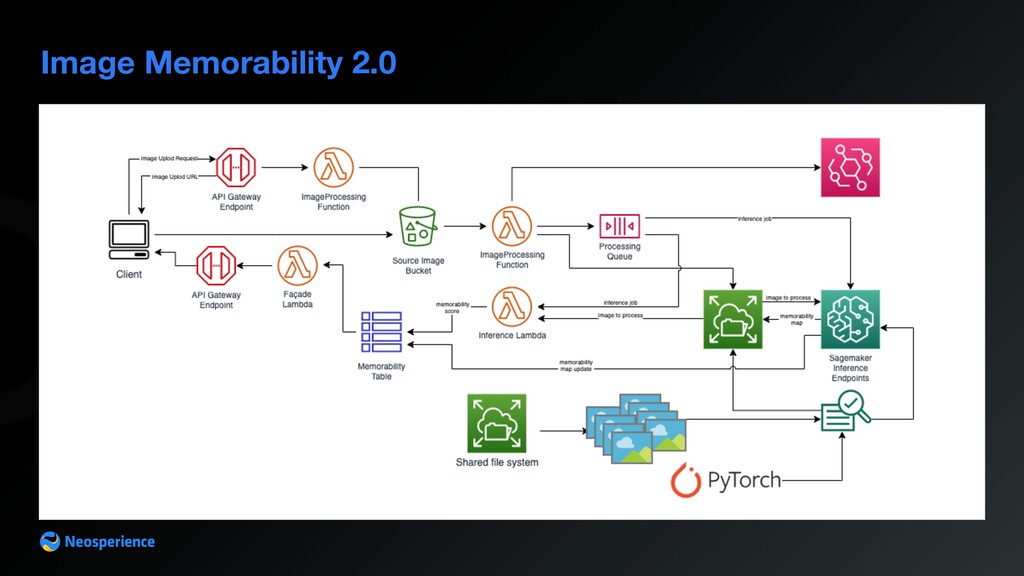
source images are shared between Lambdas with no need to upload/download from S3 • S3 interface is maintained to ease image upload • still need Amazon SageMaker to process image heatmap • using Lambda made execution time for score compute rise from 5 seconds to 12 seconds • overall image scoring is improved from an average of 90 seconds to 12 seconds (queue jobs are processed in parallel by Lambdas) • no costs for idle endpoints • costs reduced by an order of magnitude (reduced load on SageMaker endpoints) • could remove on premise servers (SageMaker endpoints + Inference on Lambda is cost effective)
pipeline for a custom ML model Wrap up • custom ML models can be implemented on AWS Lambda (if no GPU is required or the slow down is acceptable) • Amazon SageMaker is a great alternative, but more expensive (you pay for idle at least one instance) • model training is performed on Amazon SageMaker (consider using spot instances for training) • choose the right computing for your machine learning model requirements • Amazon EFS is a game changer in many applications • be aware of AWS Lambda dependency size when using ML libraries
![www.neosperience.com | blog.neosperience.com | [email protected] Neosperience Empathy in Technology Serving](https://files.speakerdeck.com/presentations/e6e62dee77f14cedbf74353af67a7be7/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.neosperience.com | blog.neosperience.com | [email protected]](https://files.speakerdeck.com/presentations/e6e62dee77f14cedbf74353af67a7be7/slide_37.jpg){kind=link}