Small LLMs at the edge are the engine for open‑source, scalable AI agents. Luca Bianchi, PhD Chief Technology & Innovation Officer @ Overnet / MESA / LIDIA
50 THESIS The 2026 enterprise AI architecture is a specialized open ‑ weight model , running on edge hardware, reasoning over a standard protocol , while proprietary data never leaves the perimeter. OPEN WEIGHTS ON ‑ PREMISE MCP ‑ NATIVE AUDITABLE
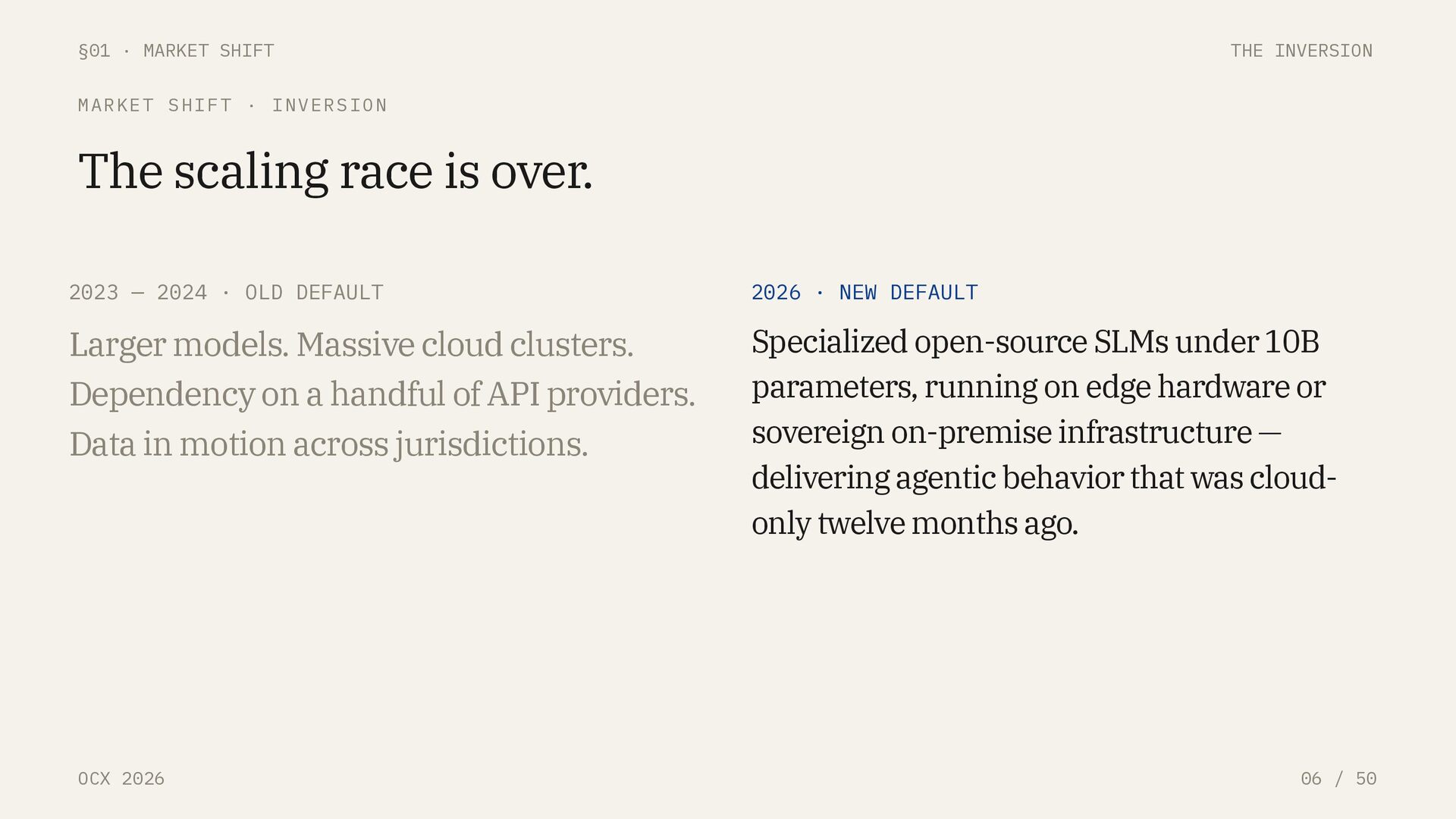
50 MARKET SHIFT · INVERSION The scaling race is over. 2023 — 2024 · OLD DEFAULT Larger models. Massive cloud clusters. Dependency on a handful of API providers. Data in motion across jurisdictions. 2026 · NEW DEFAULT Specialized open-source SLMs under 10B parameters, running on edge hardware or sovereign on-premise infrastructure — delivering agentic behavior that was cloud- only twelve months ago.
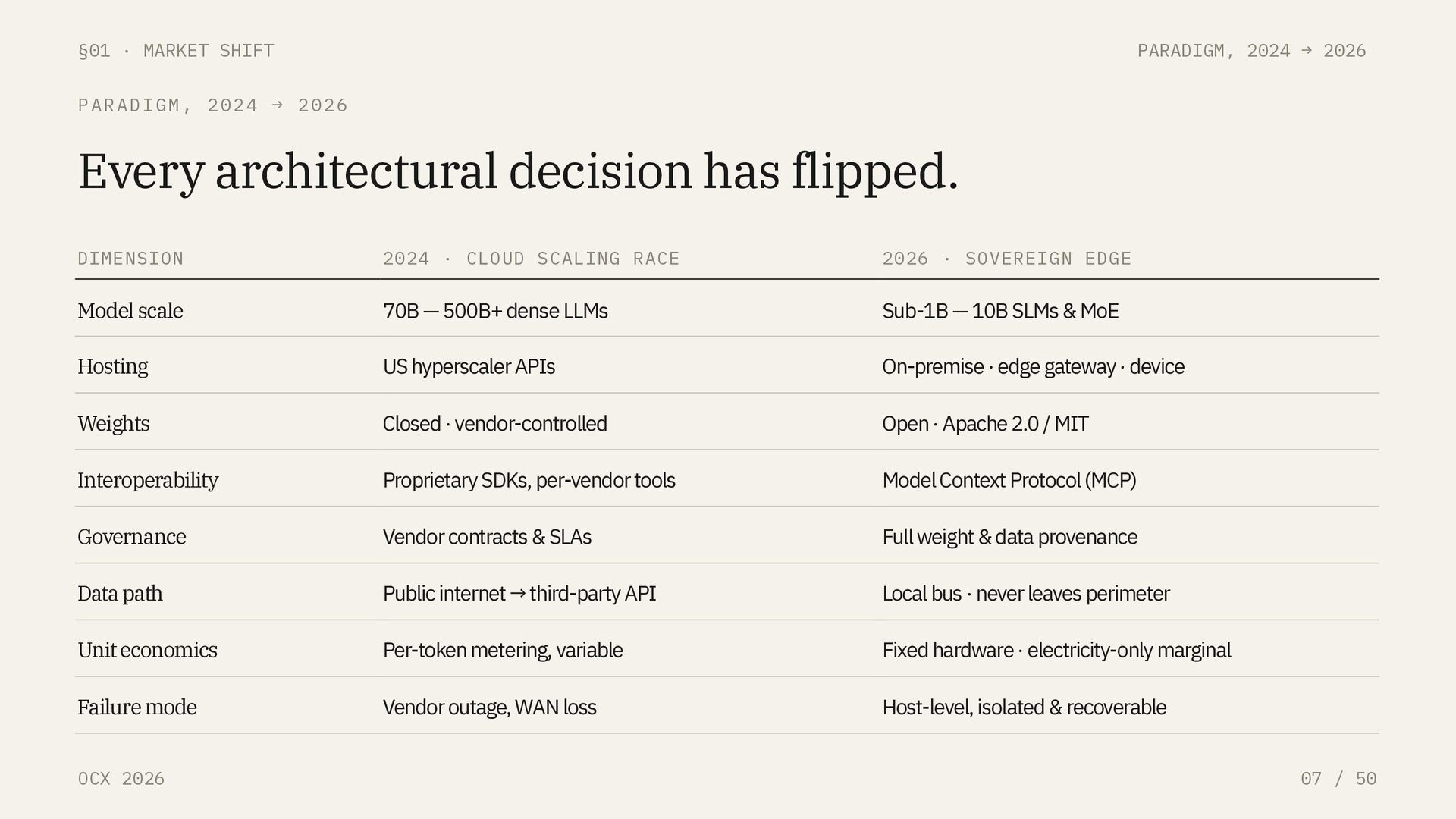
DRIVERS Three forces, pushing the same direction. 01 / CAPABILITY Parity at 1/20th the scale. A 3B model with test-time compute now outperforms a 70B dense model on MATH-500. Reasoning ability is no longer a function of parameter count alone. 02 / REGULATION Enforcement is 120 days away. EU AI Act high-risk obligations become fully enforceable August 2026. US CLOUD Act continues to collide with GDPR Article 48 on cross-border data transfers. 03 / ECONOMICS $250 buys 67 TOPS. A Jetson Orin Nano Super runs a quantized 4B model at sub-second latency, indefinitely, for the price of electricity. Per-token cloud economics no longer compete.
DEFINITION Under 10B parameters now matches frontier behavior. Sub ‑ 1B to ~10B parameters, defined not by size, but by deployability in resource ‑ constrained environments. Three capability unlocks have closed the gap with frontier LLMs. 01 · DISTILLATION Learn from frontier models. Compress reasoning behavior from 100B+ teachers into sub-10B students. 02 · SYNTHETIC DATA Reasoning ‑ dense training. Curated chain-of-thought corpora replace quantity with density. 03 · POST-TRAINING RL Verifier ‑ aligned output. Process reward models and RLHF align step-by-step reasoning to ground truth.
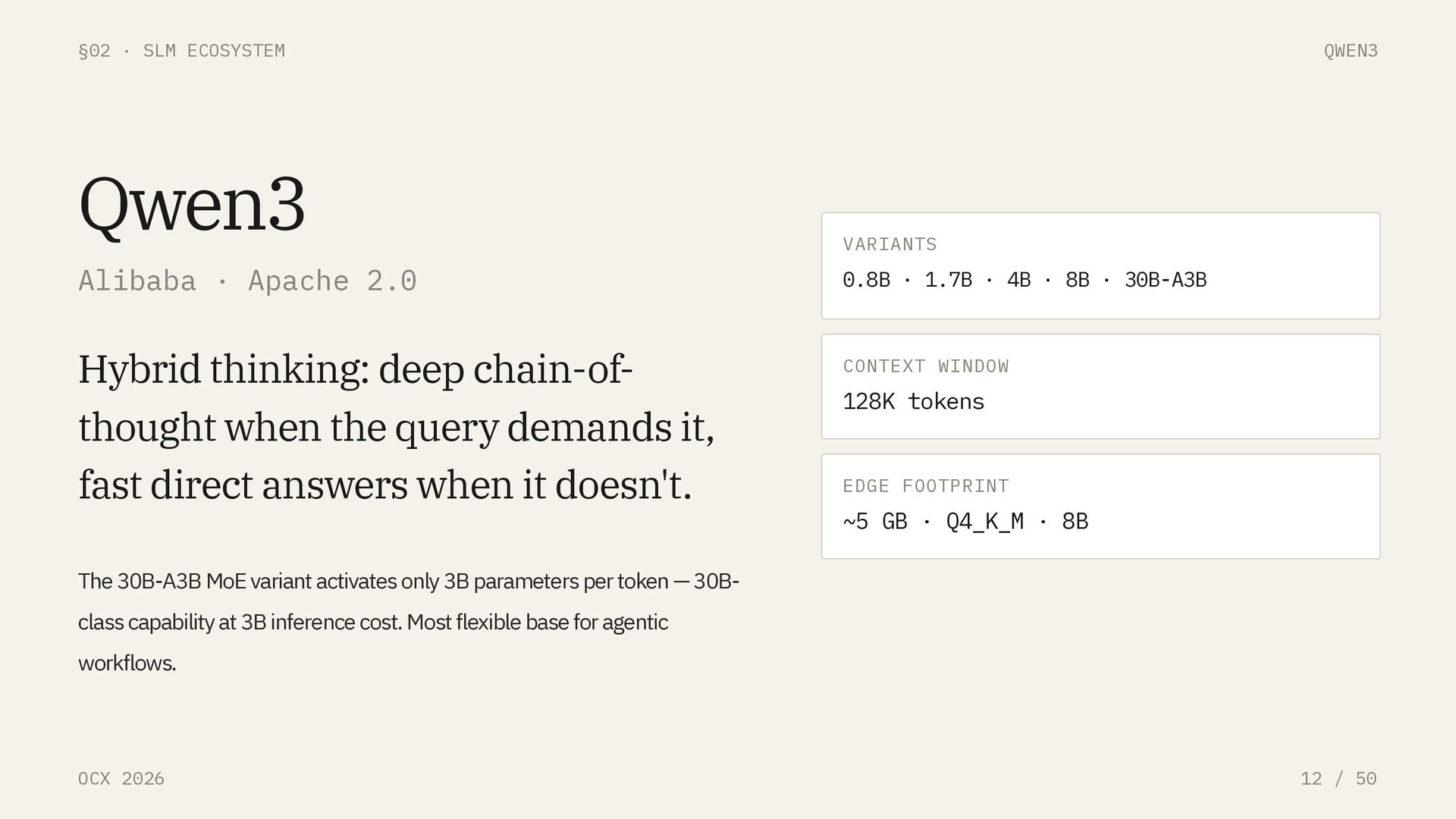
Qwen3 Alibaba · Apache 2.0 Hybrid thinking: deep chain-of- thought when the query demands it, fast direct answers when it doesn't. The 30B-A3B MoE variant activates only 3B parameters per token — 30B- class capability at 3B inference cost. Most flexible base for agentic workflows. VARIANTS 0.8B · 1.7B · 4B · 8B · 30B-A3B CONTEXT WINDOW 128K tokens EDGE FOOTPRINT ~5 GB · Q4_K_M · 8B
50 Gemma 4 Google DeepMind · Apache 2.0 Mobile-first multimodal — text, image, audio and video on a phone, offline, with near-zero latency. VARIANTS E2B (eff. 2B) · E4B TARGET HARDWARE Snapdragon Hexagon · Apple Neural Engine · Pi 5 MODALITIES text · image · audio · video First SLM family engineered specifically for NPU-class silicon. E2B runs inside 1.5 GB of phone RAM with LiteRT acceleration.
Phi-4 Microsoft · MIT Reasoning-dense synthetic training — a 3.8B model that matches 7 — 9B peers on reasoning benchmarks. VARIANTS Mini 3.8B · Multimodal 5.6B CONTEXT WINDOW 128K tokens COMMERCIAL TERMS MIT · zero restrictions MIT license gives maximum commercial flexibility: no field-of-use clauses, no use-case restrictions, no vendor contract.
50 DeepSeek-R1 DeepSeek · MIT · Distilled o1-class reasoning, math, code, and logic, distilled into 7 and 8B forms that run on consumer hardware. VARIANTS Distill-Qwen-7B · Distill-Llama-8B STRENGTHS Math · code · logic · long-horizon reasoning HARDWARE FLOOR Consumer GPU · RTX 4090 If your agents need to actually think, plan, verify, and backtrack, not just retrieve, these are the defaults for on-device reasoning.
50 Arcee AI Arcee.ai · Apache 2.0 A specialist shop — small models engineered for tool calling, merged from strong open bases. THE LINEUP ARCEE-AGENT 7B Purpose-built for function calling & tool use. Qwen2-7B base + agentic SFT. The flagship. SUPERNOVA-MEDIUS 14B Cross-architecture distillation from Qwen2.5-72B & Llama-3.1-405B into a single 14B student. VIRTUOSO-SMALL / LITE 14B · 7B General-purpose SLMs with strong reasoning for their size class. AGENT-FIRST DESIGN Trained on agentic traces — Thought → Action → Action-Input — not general chat. OPEN RECIPES MergeKit & DistillKit release weights, datasets and merge configs. SOVEREIGN POSTURE On-prem deploy · no telemetry · no gated API. ENTERPRISE FIT Drop-in replacement for GPT-4 tool calling at a fraction of the cost. Known for MergeKit and DistillKit — their open-source toolchain for composing expert SLMs by merging, distilling and spectrum-tuning Qwen, Llama and Mistral bases. Every release ships as a buildable recipe, not a black box.
50 Scale inference, not parameters. Don’t scale parameters, scale inference. Multiple reasoning paths, verify each step, and prune the bad ones. PROCESS REWARD MODEL (PRM) Scores each step of the reasoning chain, not just the final answer. TREE SEARCH (BEAM · DVTS) Generates multiple partial answers per step, prunes the bad paths, focuses compute on promising branches.
50 CAPABILITY PARITY · MATH-500 3B beats 70B A 3B-parameter Llama with test-time compute scaling outperforms a 70B dense model on MATH-500. Hugging Face · Dec 2024 MATH-500 benchmark · inference-time scaling ~23× smaller
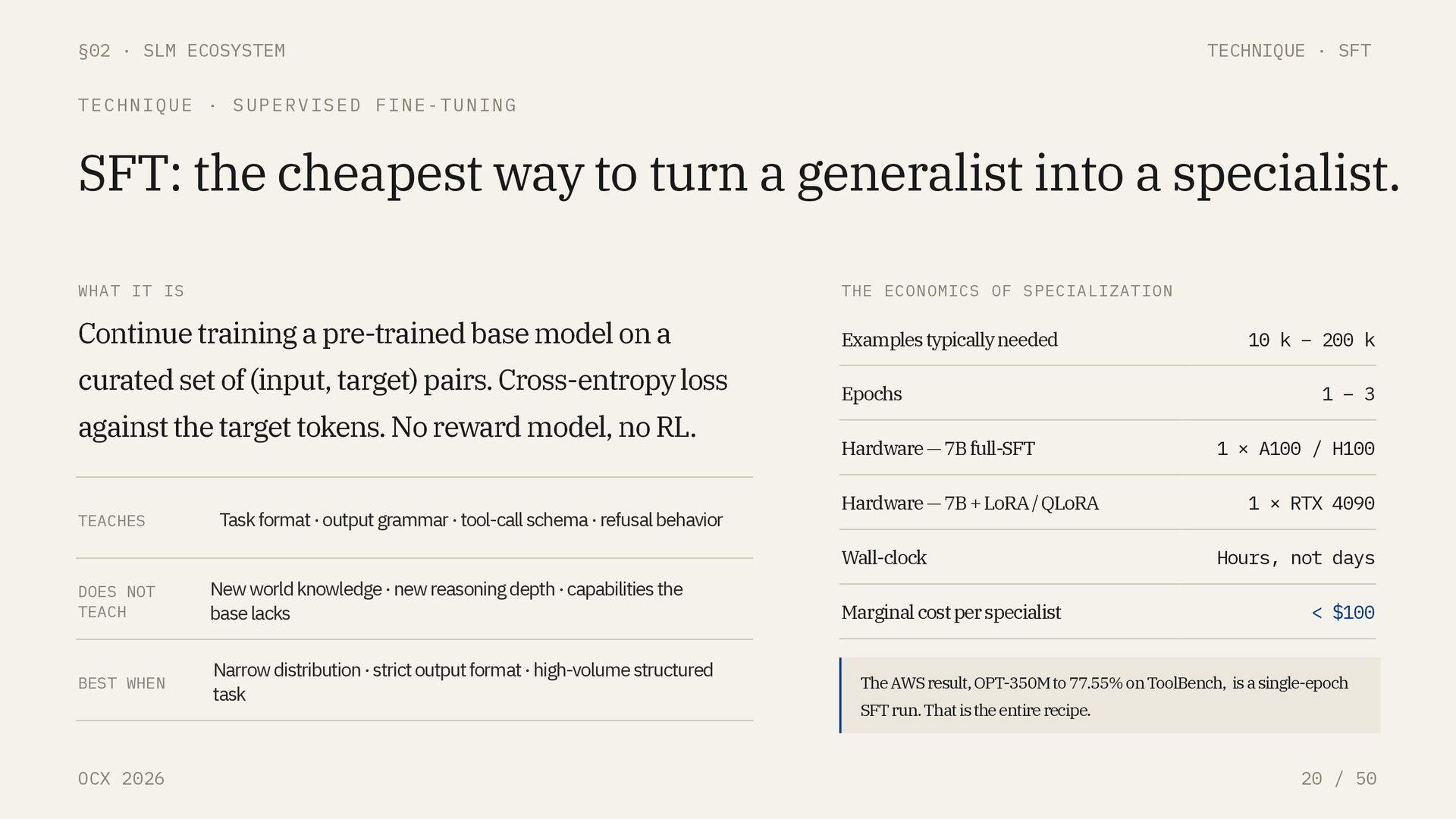
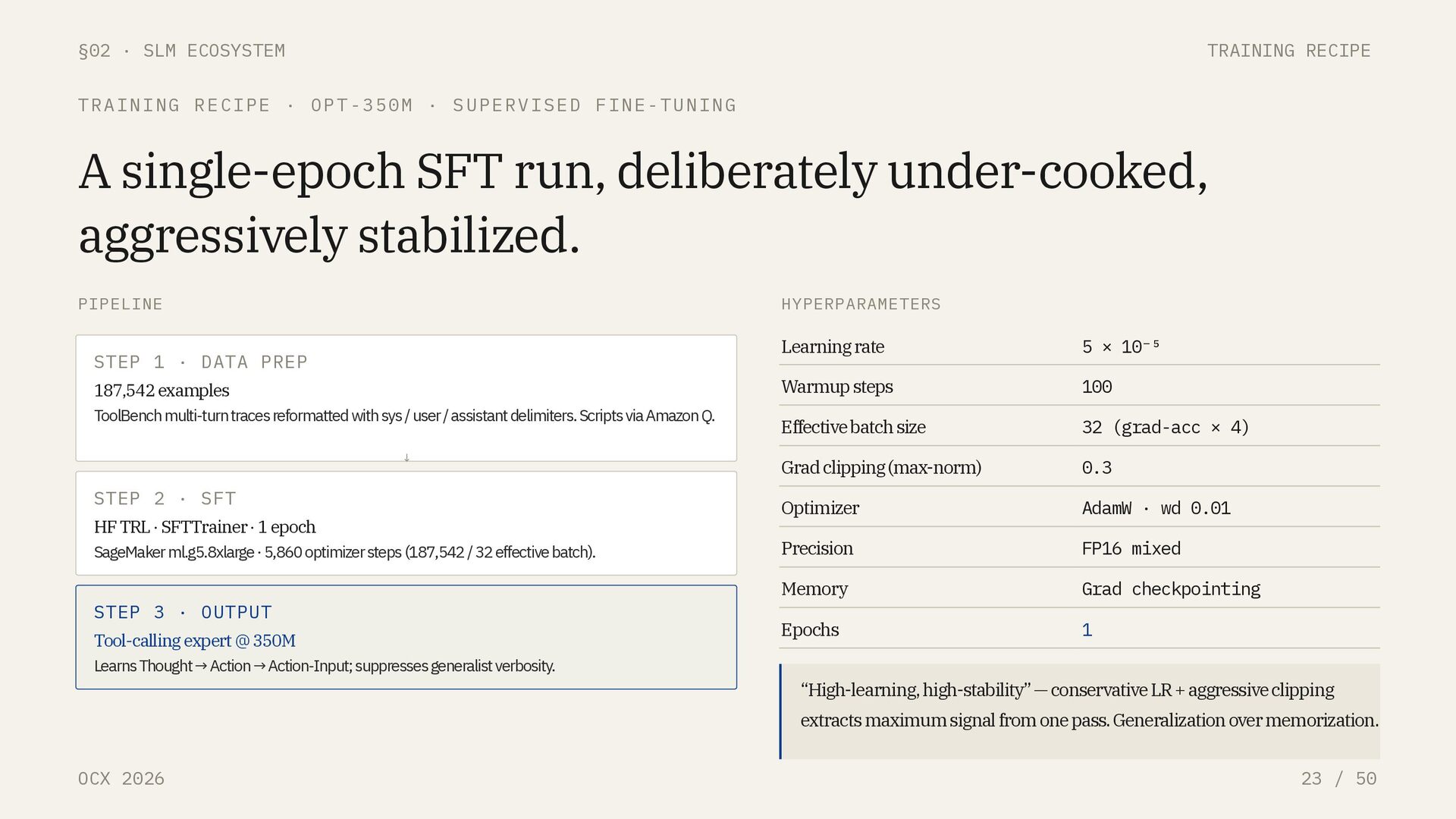
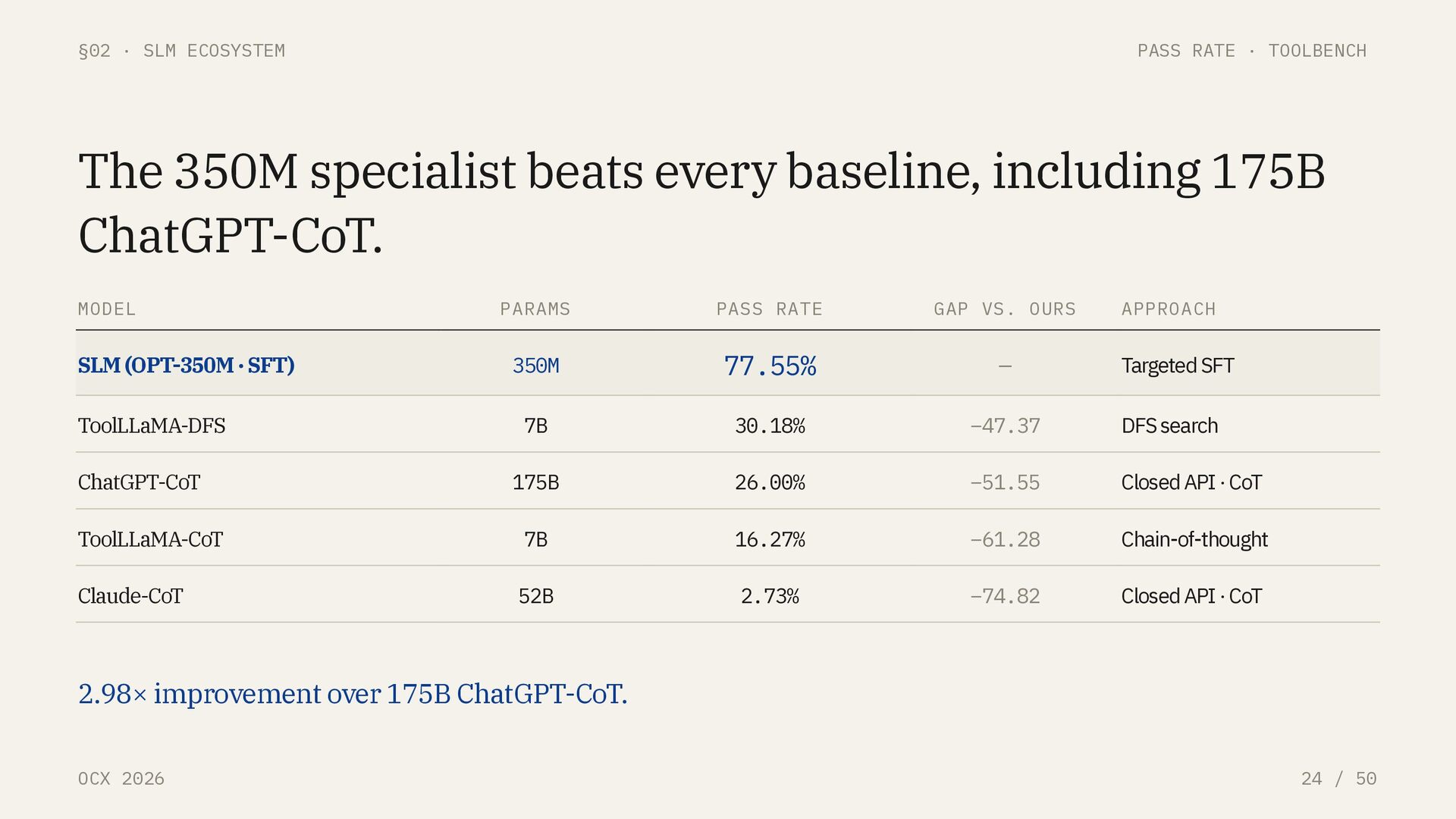
/ 50 TECHNIQUE · SUPERVISED FINE-TUNING SFT: the cheapest way to turn a generalist into a specialist. WHAT IT IS Continue training a pre-trained base model on a curated set of (input, target) pairs. Cross-entropy loss against the target tokens. No reward model, no RL. TEACHES Task format · output grammar · tool-call schema · refusal behavior DOES NOT TEACH New world knowledge · new reasoning depth · capabilities the base lacks BEST WHEN Narrow distribution · strict output format · high-volume structured task THE ECONOMICS OF SPECIALIZATION Examples typically needed 10 k – 200 k Epochs 1 – 3 Hardware — 7B full-SFT 1 × A100 / H100 Hardware — 7B + LoRA / QLoRA 1 × RTX 4090 Wall-clock Hours, not days Marginal cost per specialist < $100 The AWS result, OPT-350M to 77.55% on ToolBench, is a single-epoch SFT run. That is the entire recipe.
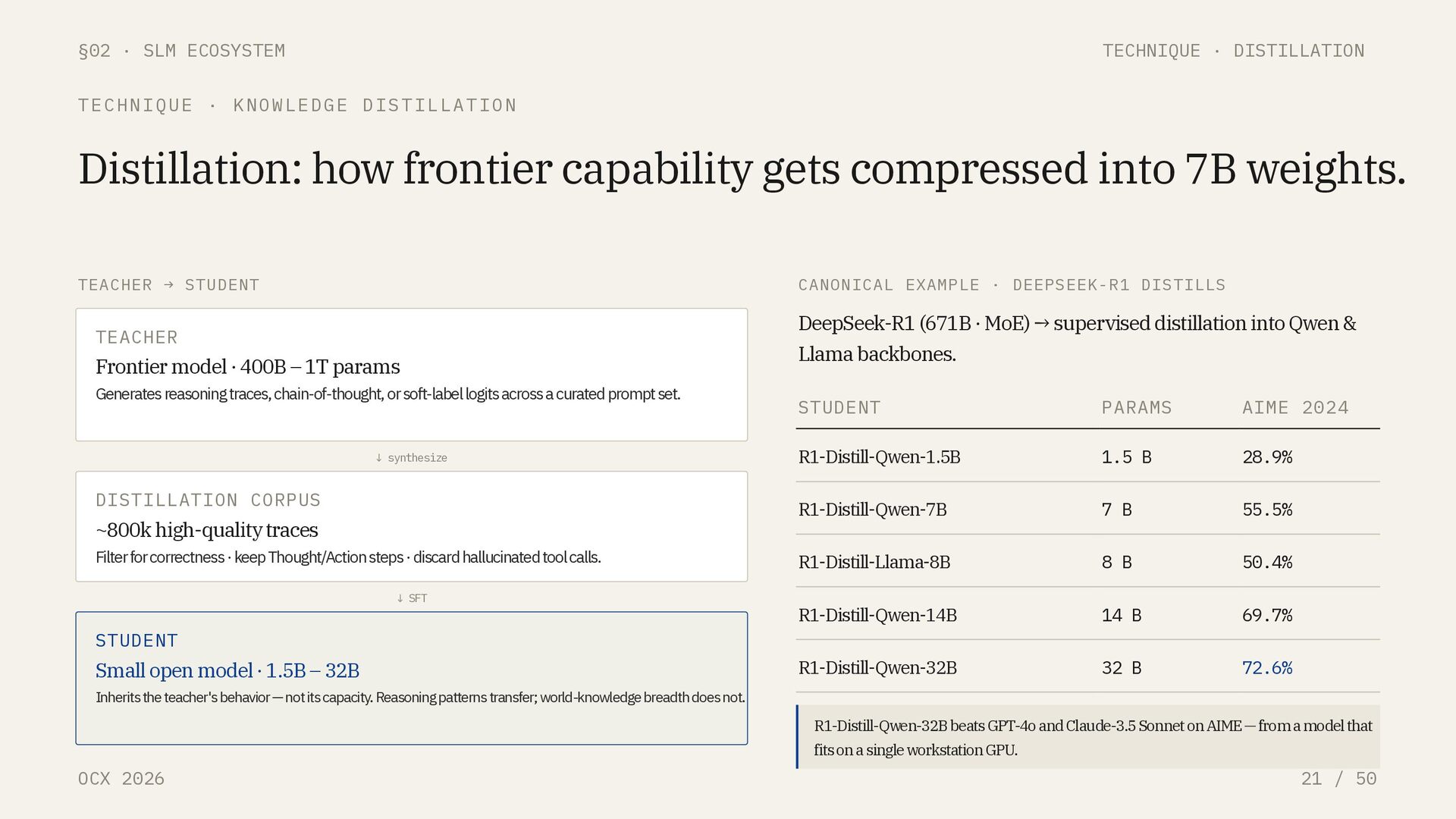
/ 50 TECHNIQUE · KNOWLEDGE DISTILLATION Distillation: how frontier capability gets compressed into 7B weights. TEACHER → STUDENT TEACHER Frontier model · 400B – 1T params Generates reasoning traces, chain-of-thought, or soft-label logits across a curated prompt set. ↓ synthesize DISTILLATION CORPUS ~800k high-quality traces Filter for correctness · keep Thought/Action steps · discard hallucinated tool calls. ↓ SFT STUDENT Small open model · 1.5B – 32B Inherits the teacher's behavior — not its capacity. Reasoning patterns transfer; world-knowledge breadth does not. CANONICAL EXAMPLE · DEEPSEEK-R1 DISTILLS DeepSeek-R1 (671B · MoE) → supervised distillation into Qwen & Llama backbones. STUDENT PARAMS AIME 2024 R1-Distill-Qwen-1.5B 1.5 B 28.9% R1-Distill-Qwen-7B 7 B 55.5% R1-Distill-Llama-8B 8 B 50.4% R1-Distill-Qwen-14B 14 B 69.7% R1-Distill-Qwen-32B 32 B 72.6% R1-Distill-Qwen-32B beats GPT-4o and Claude-3.5 Sonnet on AIME — from a model that fits on a single workstation GPU.
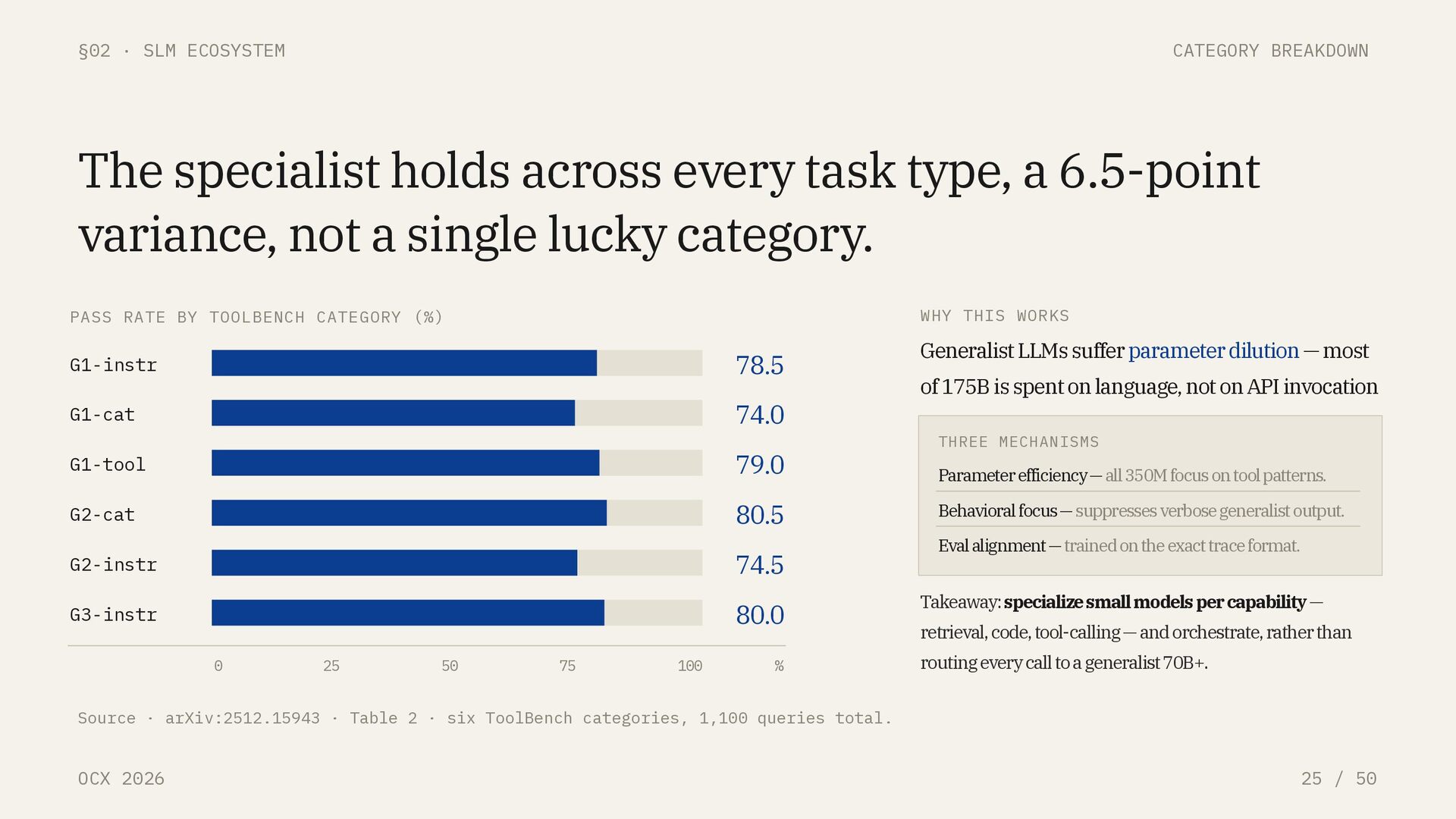
50 PASS RATE BY TOOLBENCH CATEGORY (%) G1-instr 78.5 G1-cat 74.0 G1-tool 79.0 G2-cat 80.5 G2-instr 74.5 G3-instr 80.0 0 25 50 75 100 % WHY THIS WORKS Generalist LLMs suffer parameter dilution — most of 175B is spent on language, not on API invocation THREE MECHANISMS Parameter efficiency — all 350M focus on tool patterns. Behavioral focus — suppresses verbose generalist output. Eval alignment — trained on the exact trace format. Takeaway: specialize small models per capability — retrieval, code, tool-calling — and orchestrate, rather than routing every call to a generalist 70B+. Source · arXiv:2512.15943 · Table 2 · six ToolBench categories, 1,100 queries total. The specialist holds across every task type, a 6.5-point variance, not a single lucky category.
/ 50 § 03 Technical Architecture. Quantization, parameter-efficient fine-tuning, and the Model Context Protocol: the three layers that make sovereign edge work.
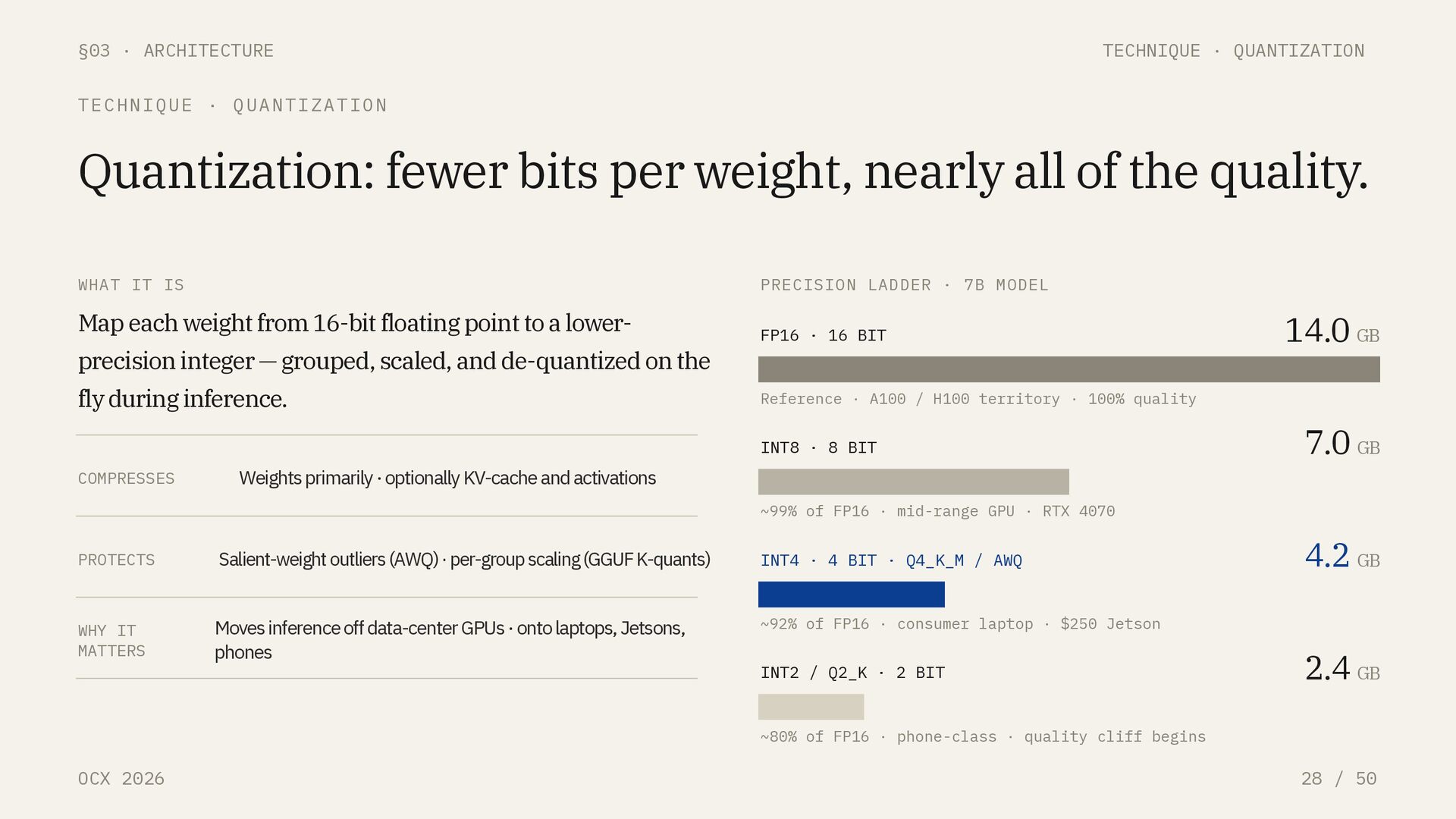
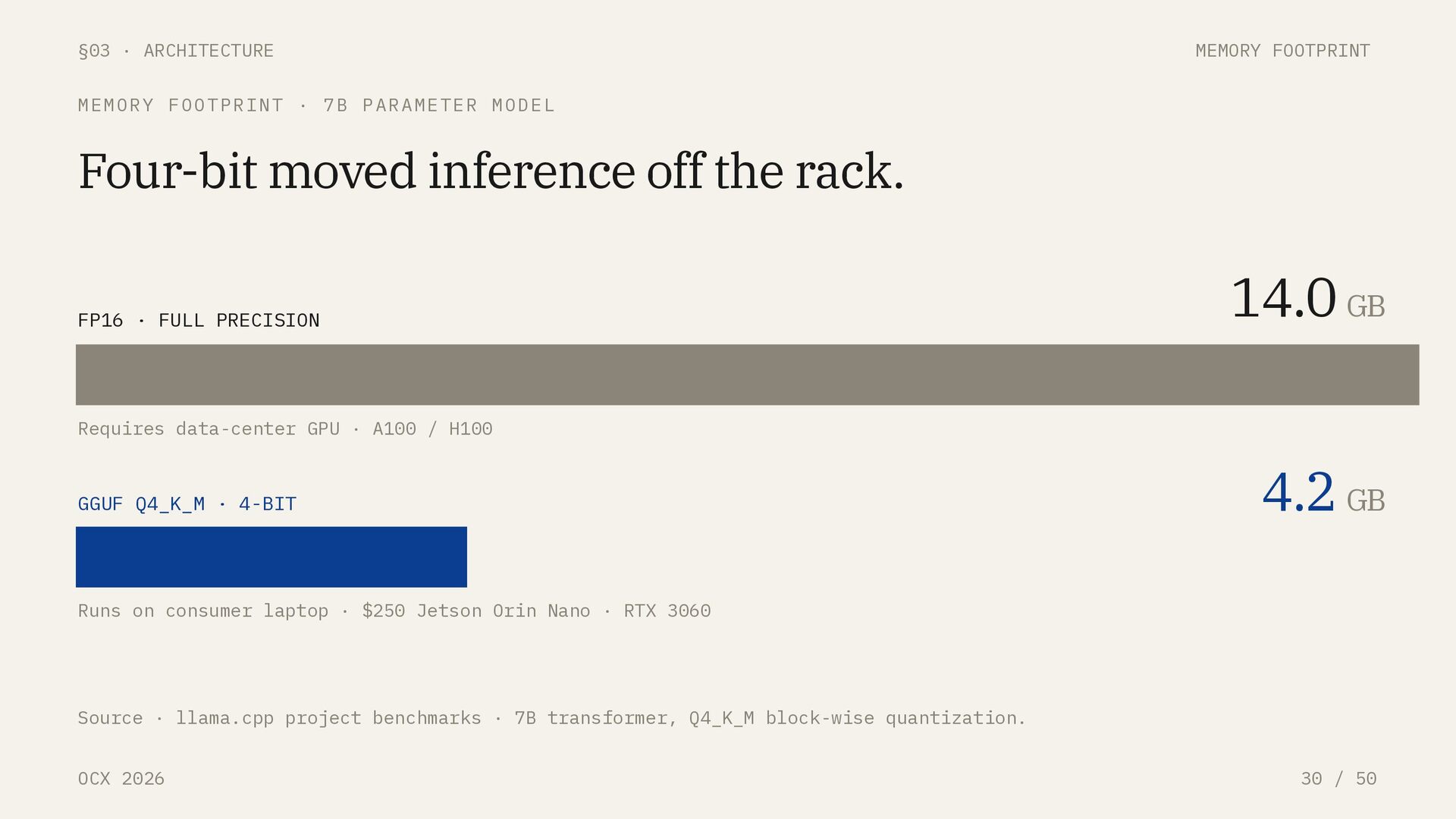
QUANTIZATION FORMATS Pick quantization by target silicon. FORMAT TARGET QUALITY @ Q4 THROUGHPUT ECOSYSTEM GGUF CPU · cross- platform · hybrid CPU/GPU ~92% of FP16 Baseline llama.cpp, Ollama, LM Studio MLX Apple Silicon · unified memory ~93% of FP16 +20–40% vs GGUF on M-series mlx-lm, LM Studio (MLX backend) AWQ NVIDIA & AMD GPU Highest (salient-weight aware) 741 tok/s vLLM + Marlin kernels GPTQ NVIDIA & AMD GPU ~90% of FP16 Mature, ~-10% vs AWQ Widest toolchain support A 7B model that needs 14 GB VRAM in FP16 runs under 5 GB in 4-bit, a 75% reduction, with ~92% of full-precision quality. On Apple Silicon, MLX’s unified-memory path typically edges GGUF by 20–40% in tokens/second.
THROUGHPUT · AWQ VS FP16 741 tok/s AWQ quantization + Marlin kernels. 60% more throughput than FP16 at a quarter of the memory. FP16 BASELINE 461 tok/s AWQ + MARLIN 741 tok/s Single GPU · 7B model vLLM runtime · 2026 benchmark
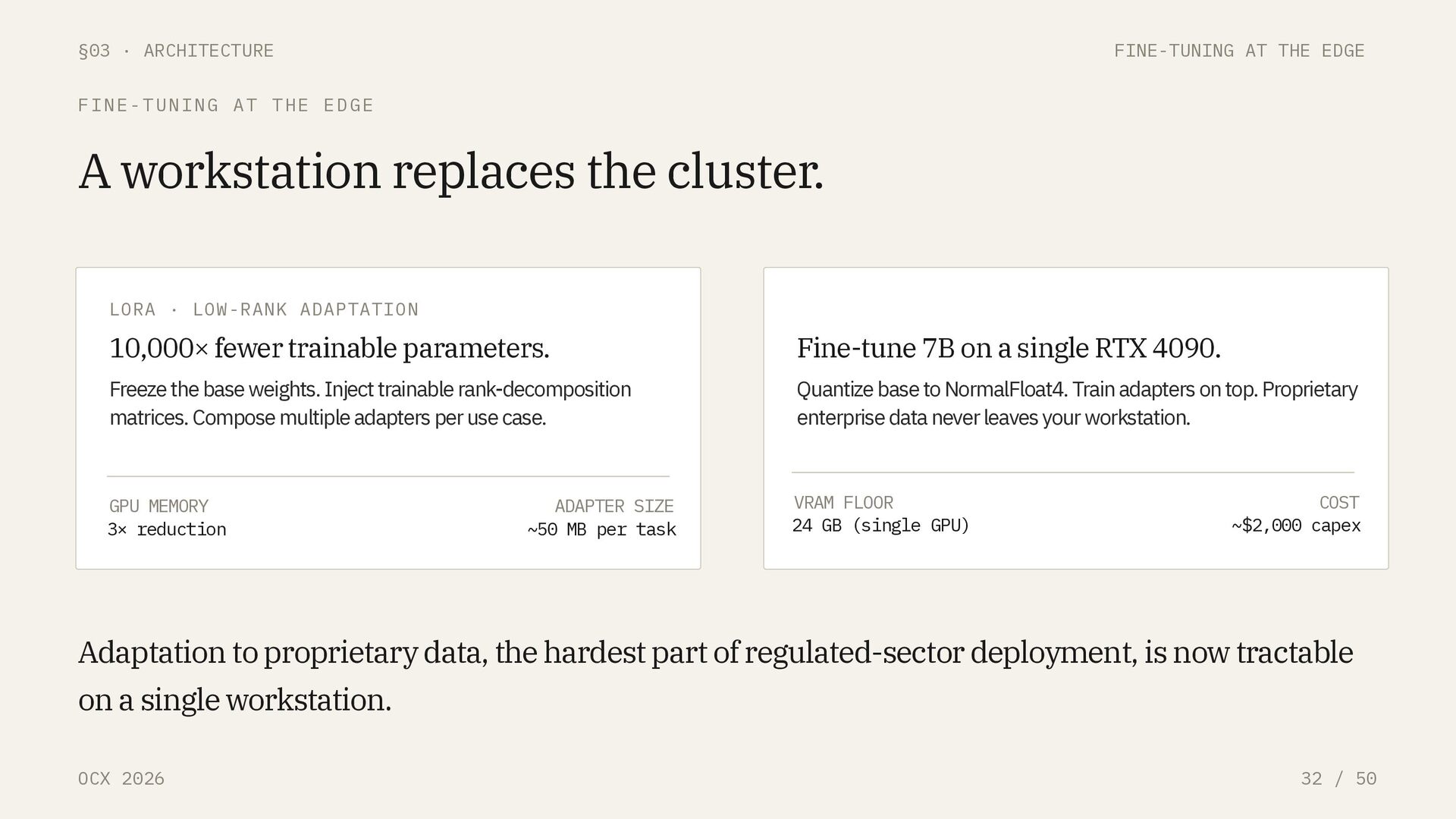
/ 50 FINE-TUNING AT THE EDGE A workstation replaces the cluster. LORA · LOW-RANK ADAPTATION 10,000× fewer trainable parameters. Freeze the base weights. Inject trainable rank-decomposition matrices. Compose multiple adapters per use case. GPU MEMORY 3× reduction ADAPTER SIZE ~50 MB per task QLORA · 4-BIT BASE + LORA ADAPTERS Fine-tune 7B on a single RTX 4090. Quantize base to NormalFloat4. Train adapters on top. Proprietary enterprise data never leaves your workstation. VRAM FLOOR 24 GB (single GPU) COST ~$2,000 capex Adaptation to proprietary data, the hardest part of regulated-sector deployment, is now tractable on a single workstation.
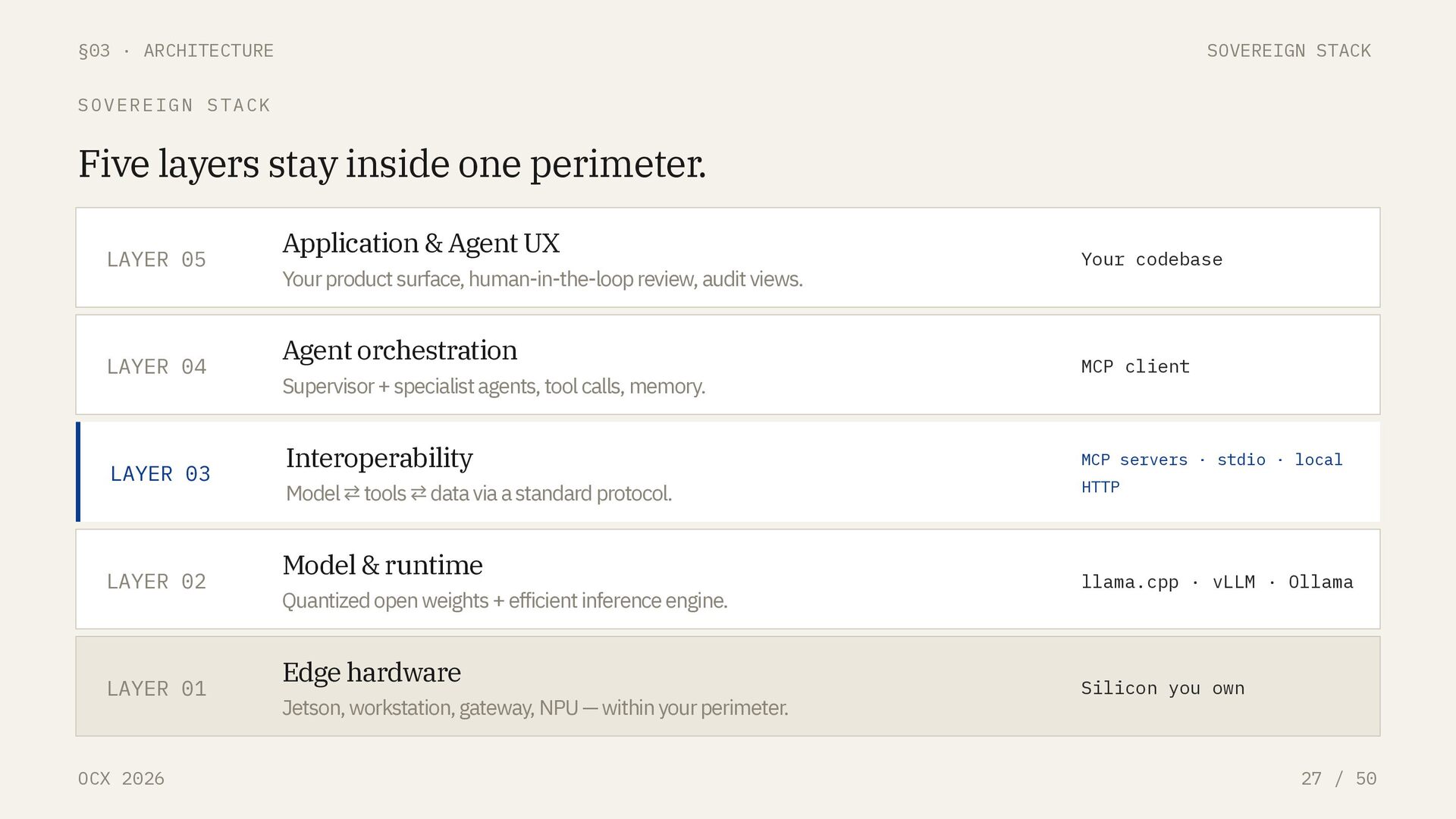
50 INTEROPERABILITY LAYER MCP is the USB-C for AI agents. The USB-C for AI agents, a standard interface between any model and any tool, data source, or environment. GOVERNANCE Linux Foundation. Vendor-neutral stewardship. Long-term viability as a standard, not a proprietary SDK. TRANSPORT stdio · HTTP. Local or remote. Your MCP servers can expose files, databases, APIs without ever touching the public internet. DECOUPLING Model ⇄ tools. Swap the inference engine without rewriting integrations. Swap tools without retraining the model.
COMPOSITION PATTERN Open protocol replaces proprietary glue. No proprietary orchestration middleware. No per-vendor tool adapters. MCP is the glue, and it is open. 01 Supervisor agent decomposes the task, delegates to specialists, maintains shared state. 02 Librarian. Retrieves from local vector stores via RAG over proprietary corpora. 03 Analyst. Runs Python, SQL, numerical work in a sandboxed MCP server. 04 Vision. Inspects images, diagrams, camera feeds on-device. 05 Data sovereignty. Inference, MCP servers, tools, storage: all inside the same host.
50 THE SOVEREIGNTY GAP “Putting your servers in Frankfurt does not make your data sovereign . Physical location is irrelevant, corporate domicile governs.” — The architect's fallacy, 2020 — 2025
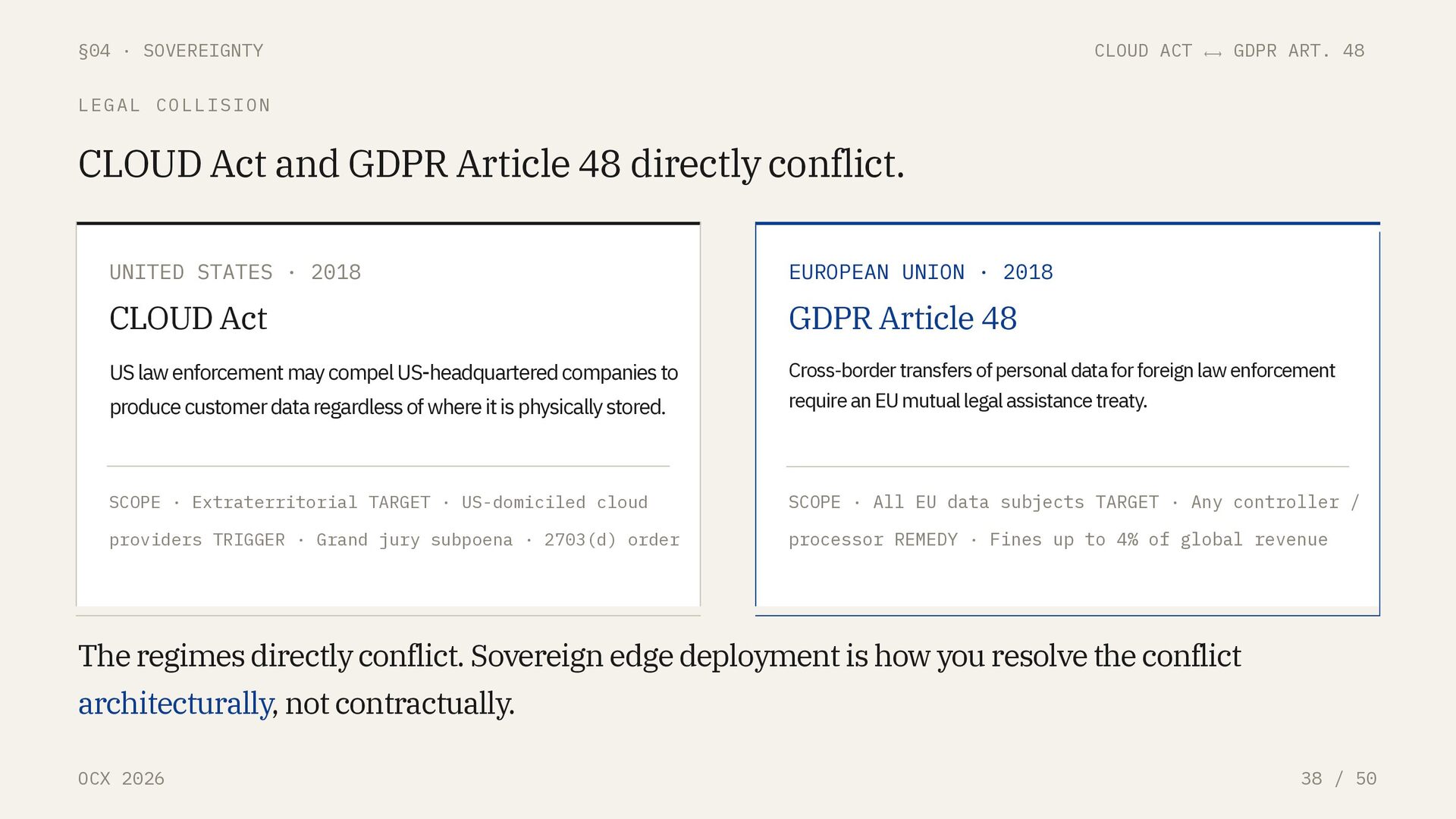
2026 38 / 50 LEGAL COLLISION CLOUD Act and GDPR Article 48 directly conflict. UNITED STATES · 2018 CLOUD Act US law enforcement may compel US-headquartered companies to produce customer data regardless of where it is physically stored. SCOPE · Extraterritorial TARGET · US-domiciled cloud providers TRIGGER · Grand jury subpoena · 2703(d) order EUROPEAN UNION · 2018 GDPR Article 48 Cross-border transfers of personal data for foreign law enforcement require an EU mutual legal assistance treaty. SCOPE · All EU data subjects TARGET · Any controller / processor REMEDY · Fines up to 4% of global revenue The regimes directly conflict. Sovereign edge deployment is how you resolve the conflict architecturally, not contractually.
50 EU AI ACT · HIGH-RISK OBLIGATIONS Five obligations become binding in August. “High-risk” is defined broadly: critical infrastructure, healthcare, credit, employment, and education. If your AI touches any of these sectors, five obligations become binding. Sovereign deployment is the lightest path to meeting all five. EU AI ACT ART. 9 — 15 Fully enforceable · 02 AUG 2026 Fines up to €35M or 7% global revenue 01 Data governance Art. 10 02 Technical documentation Art. 11 03 Record-keeping & logging Art. 12 04 Transparency Art. 13 05 Human oversight Art. 14
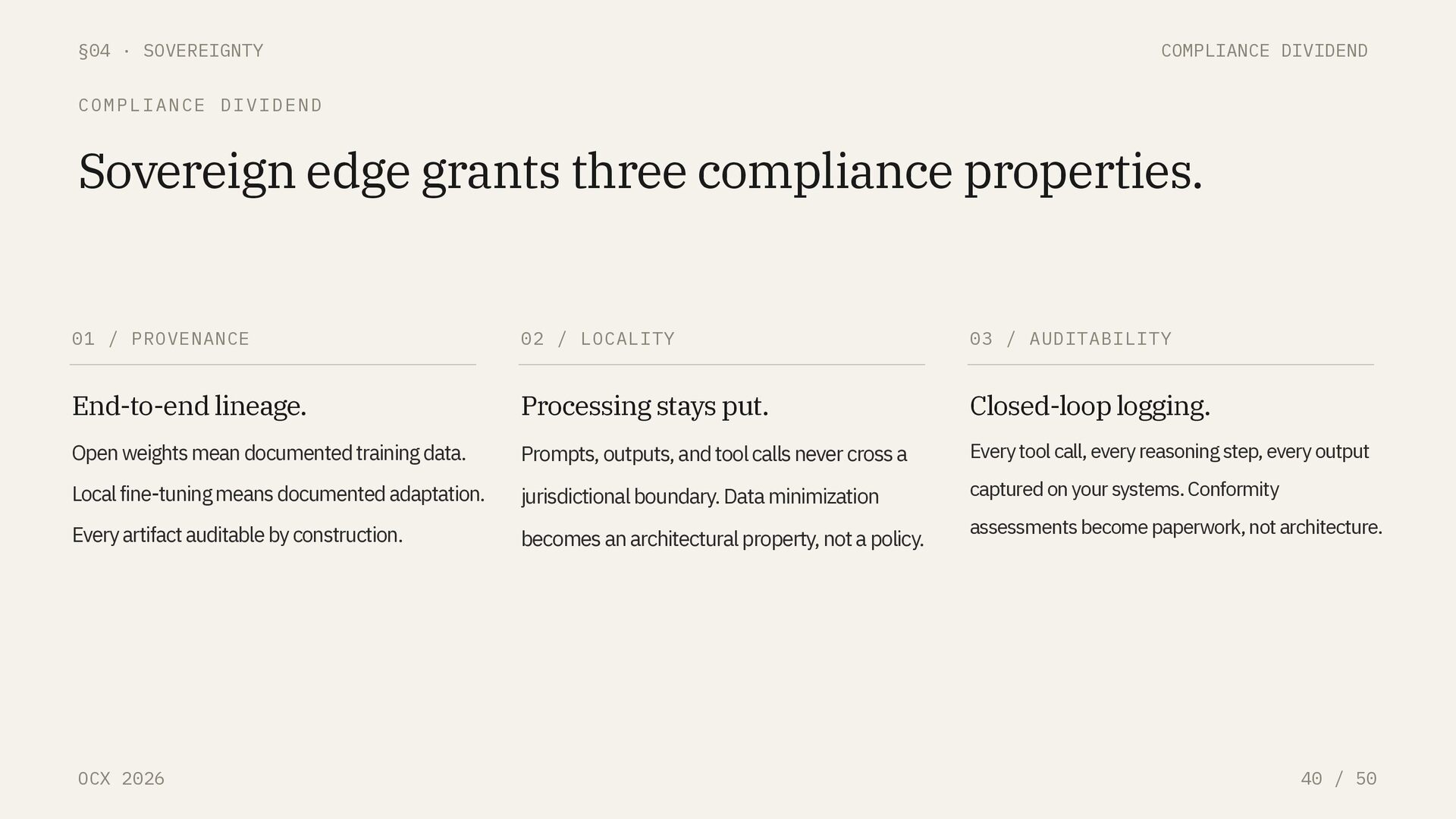
COMPLIANCE DIVIDEND Sovereign edge grants three compliance properties. 01 / PROVENANCE End-to-end lineage. Open weights mean documented training data. Local fine-tuning means documented adaptation. Every artifact auditable by construction. 02 / LOCALITY Processing stays put. Prompts, outputs, and tool calls never cross a jurisdictional boundary. Data minimization becomes an architectural property, not a policy. 03 / AUDITABILITY Closed-loop logging. Every tool call, every reasoning step, every output captured on your systems. Conformity assessments become paperwork, not architecture.
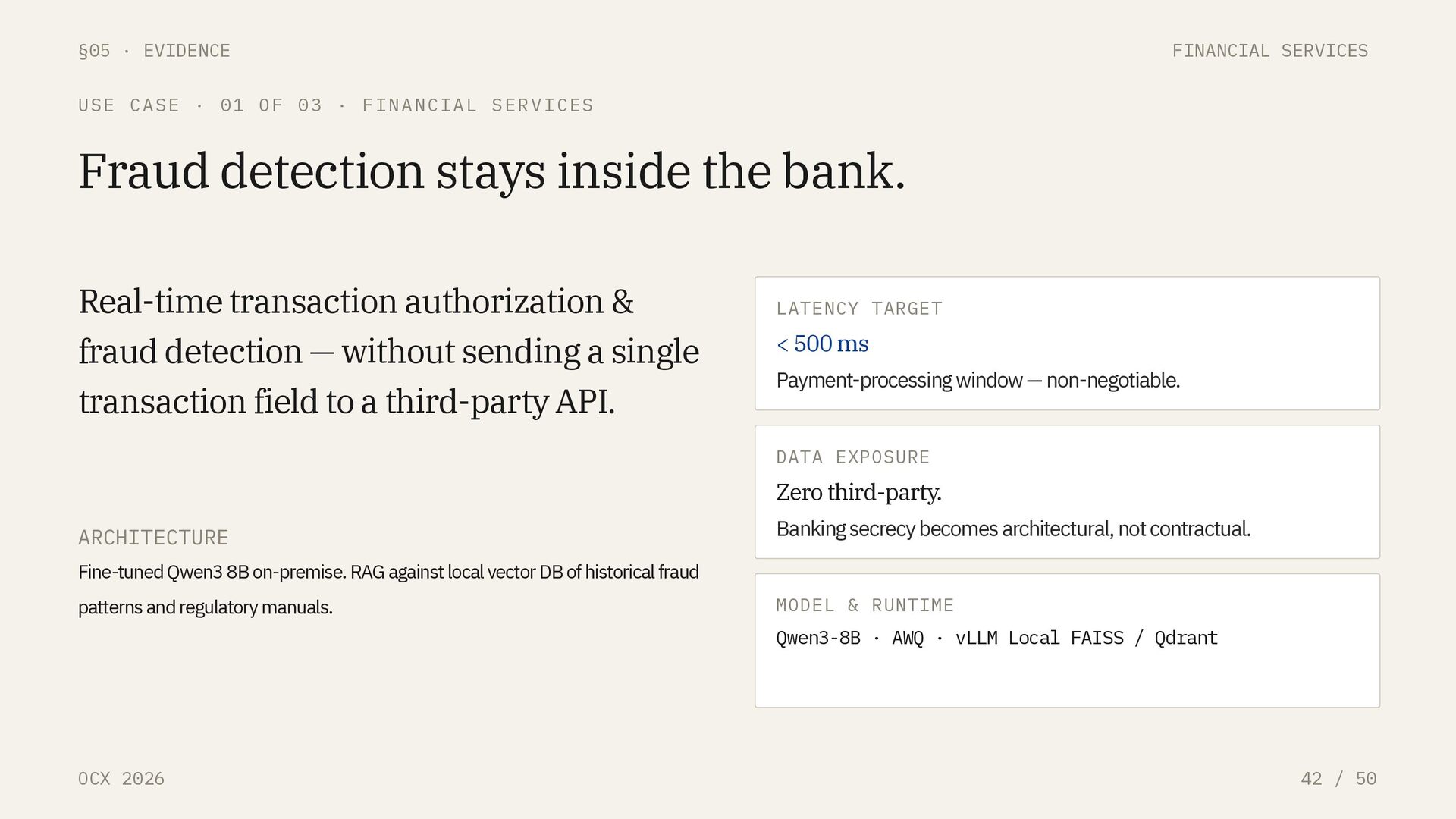
USE CASE · 01 OF 03 · FINANCIAL SERVICES Fraud detection stays inside the bank. Real-time transaction authorization & fraud detection — without sending a single transaction field to a third-party API. ARCHITECTURE Fine-tuned Qwen3 8B on-premise. RAG against local vector DB of historical fraud patterns and regulatory manuals. LATENCY TARGET < 500 ms Payment-processing window — non-negotiable. DATA EXPOSURE Zero third-party. Banking secrecy becomes architectural, not contractual. MODEL & RUNTIME Qwen3-8B · AWQ · vLLM Local FAISS / Qdrant
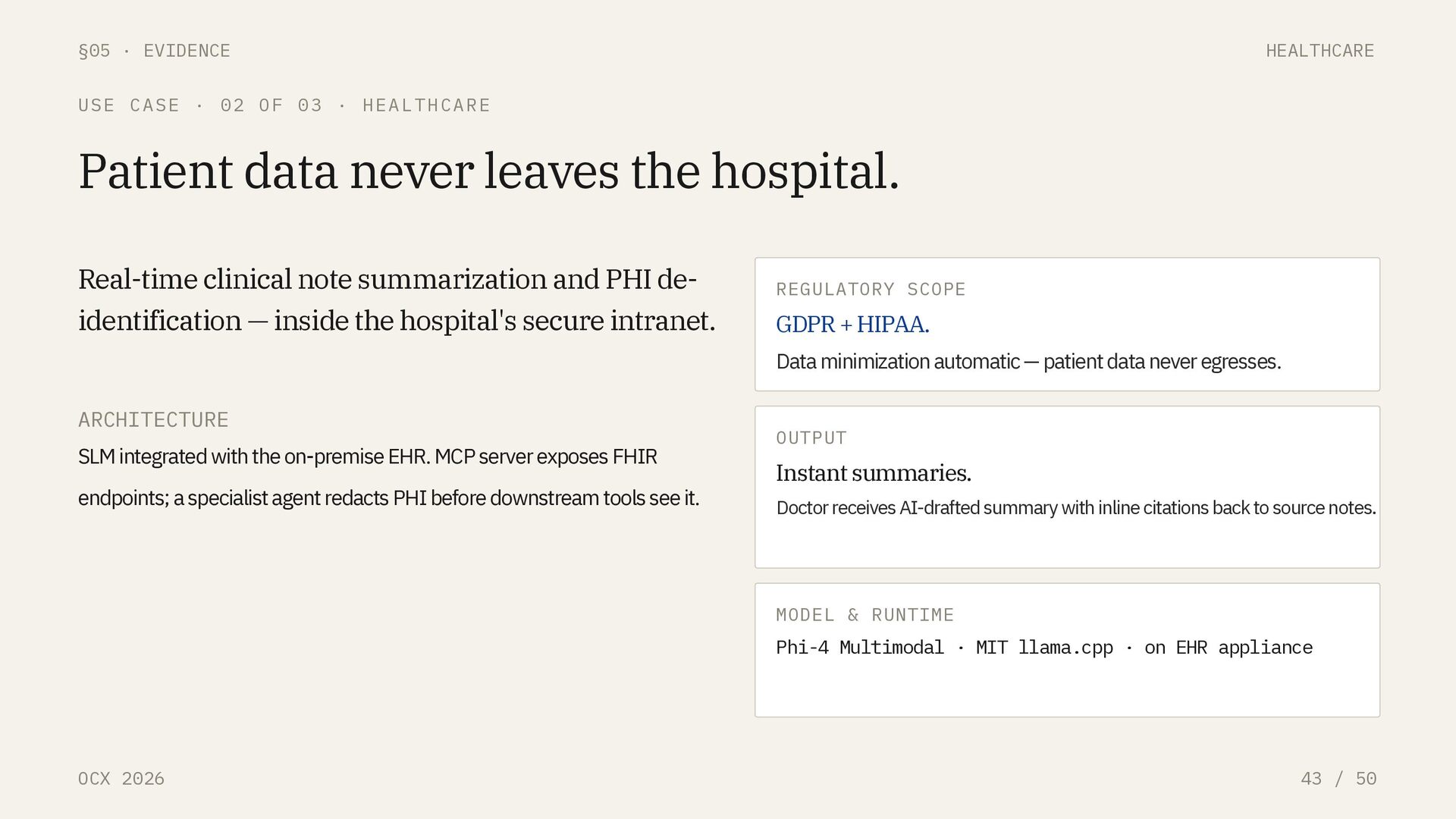
CASE · 02 OF 03 · HEALTHCARE Patient data never leaves the hospital. Real-time clinical note summarization and PHI de- identification — inside the hospital's secure intranet. ARCHITECTURE SLM integrated with the on-premise EHR. MCP server exposes FHIR endpoints; a specialist agent redacts PHI before downstream tools see it. REGULATORY SCOPE GDPR + HIPAA. Data minimization automatic — patient data never egresses. OUTPUT Instant summaries. Doctor receives AI-drafted summary with inline citations back to source notes. MODEL & RUNTIME Phi-4 Multimodal · MIT llama.cpp · on EHR appliance
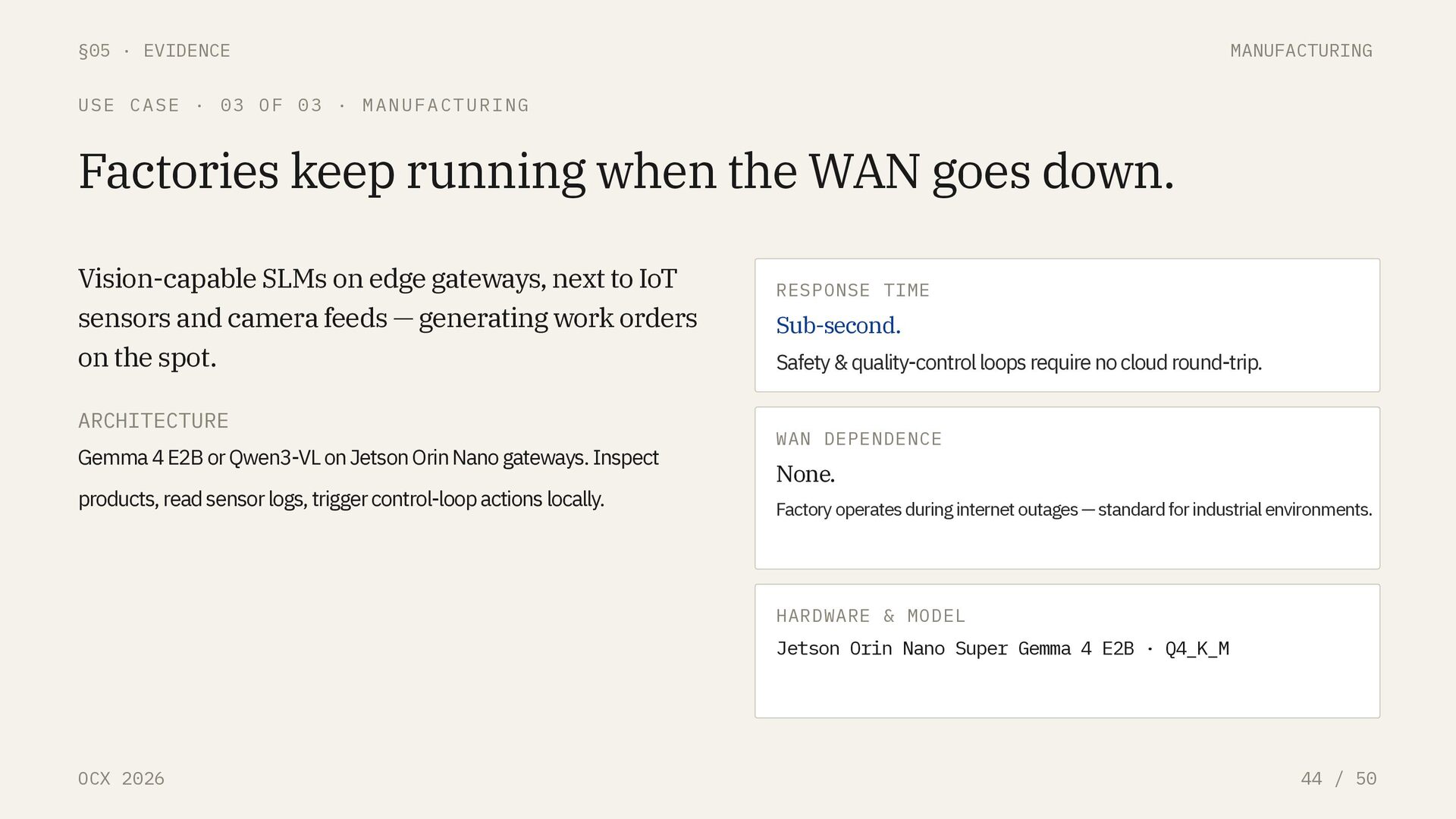
CASE · 03 OF 03 · MANUFACTURING Factories keep running when the WAN goes down. Vision-capable SLMs on edge gateways, next to IoT sensors and camera feeds — generating work orders on the spot. ARCHITECTURE Gemma 4 E2B or Qwen3-VL on Jetson Orin Nano gateways. Inspect products, read sensor logs, trigger control-loop actions locally. RESPONSE TIME Sub-second. Safety & quality-control loops require no cloud round-trip. WAN DEPENDENCE None. Factory operates during internet outages — standard for industrial environments. HARDWARE & MODEL Jetson Orin Nano Super Gemma 4 E2B · Q4_K_M
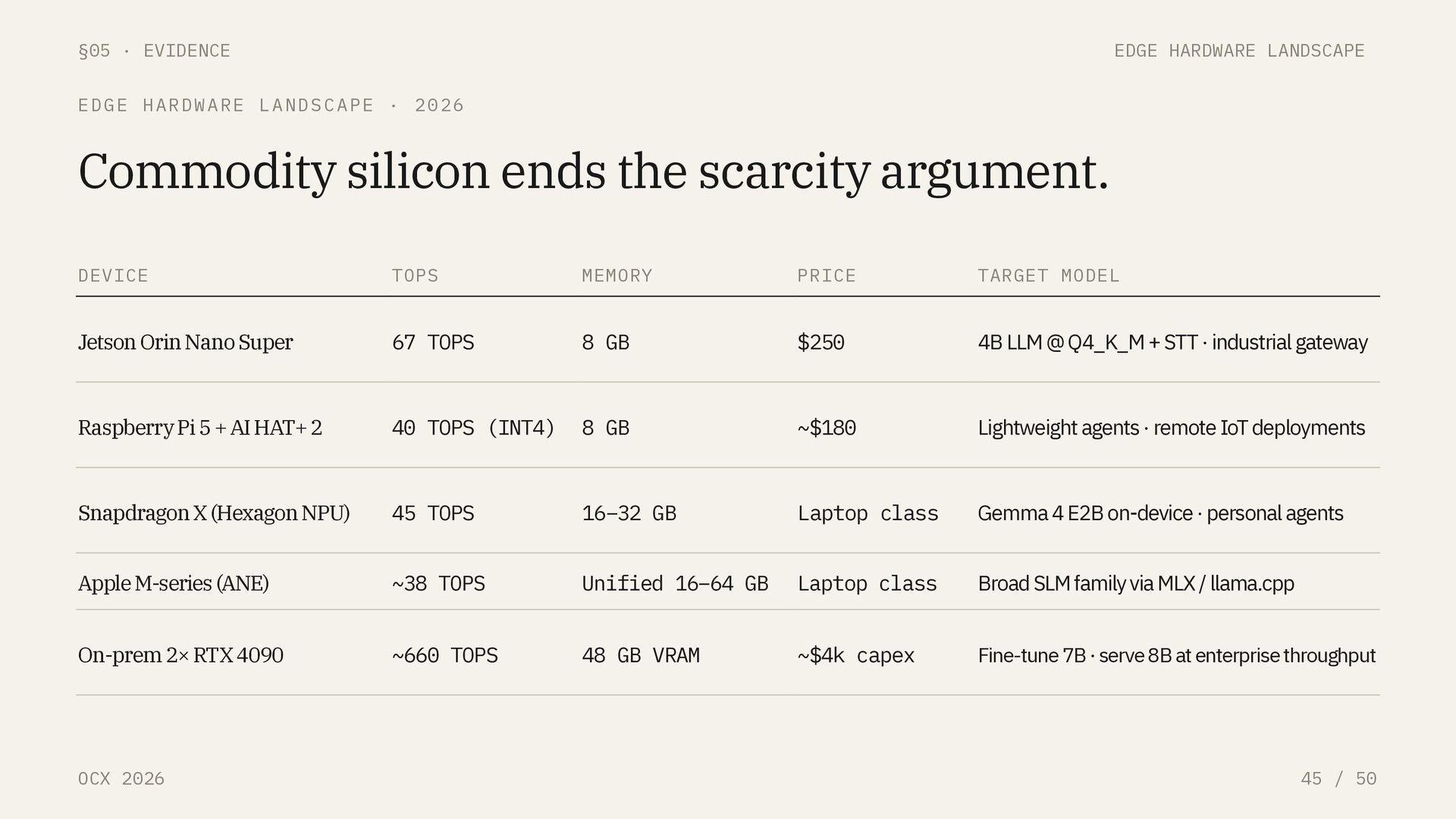
/ 50 REFERENCE POINT · JETSON ORIN NANO SUPER $250/ 67 TOPS Enough headroom for a 4B LLM at Q4_K_M, speech-to-text, and an MCP server, all in 8 GB. Marginal cost is electricity. NVIDIA Jetson Orin Nano Super · list price · 2026 Reference: Gemma 4 E4B · llama.cpp · Q4_K_M
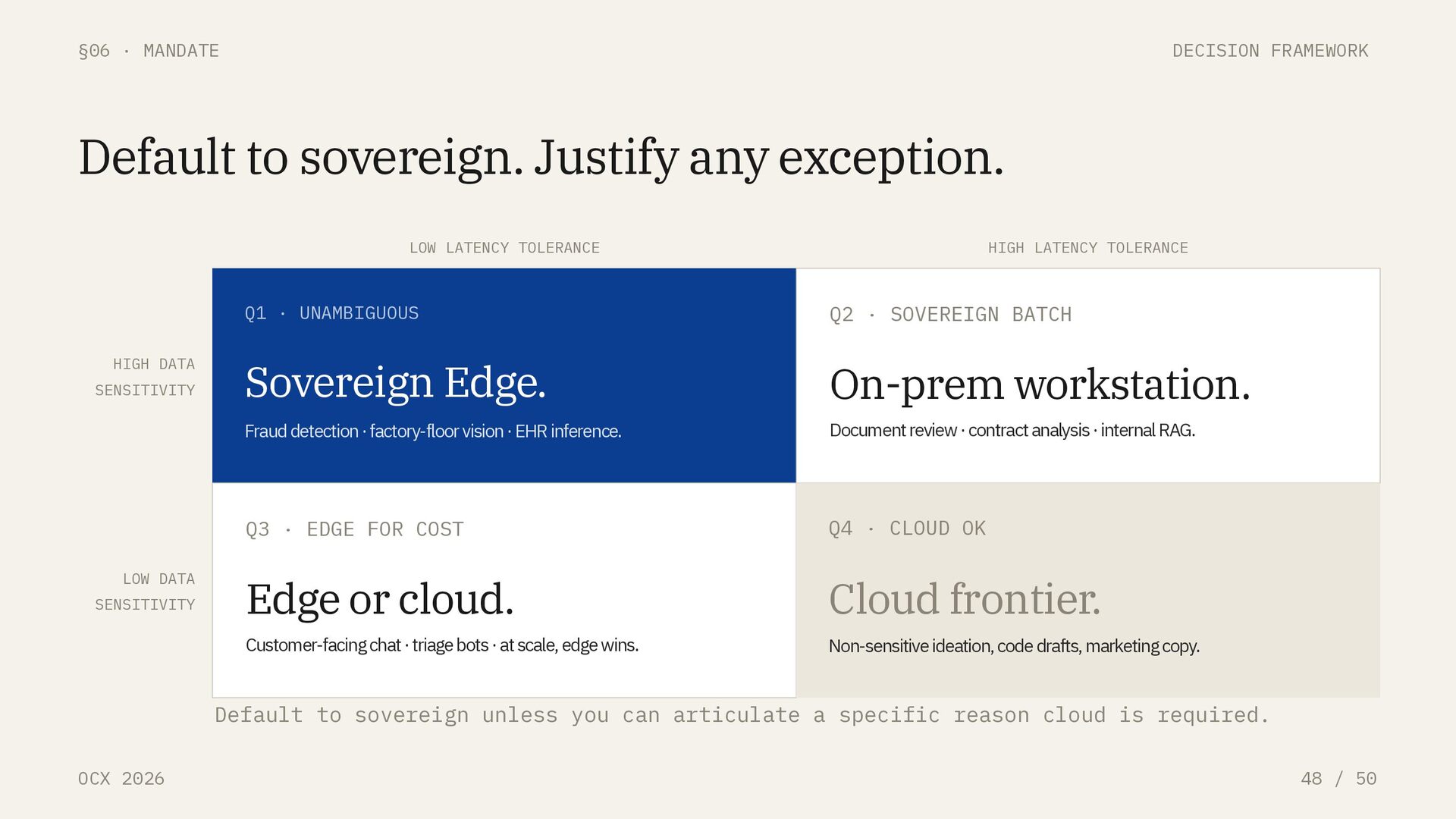
Default to sovereign. Justify any exception. HIGH DATA SENSITIVITY LOW DATA SENSITIVITY LOW LATENCY TOLERANCE HIGH LATENCY TOLERANCE Q1 · UNAMBIGUOUS Sovereign Edge. Fraud detection · factory-floor vision · EHR inference. Q2 · SOVEREIGN BATCH On-prem workstation. Document review · contract analysis · internal RAG. Q3 · EDGE FOR COST Edge or cloud. Customer-facing chat · triage bots · at scale, edge wins. Q4 · CLOUD OK Cloud frontier. Non-sensitive ideation, code drafts, marketing copy. Default to sovereign unless you can articulate a specific reason cloud is required.
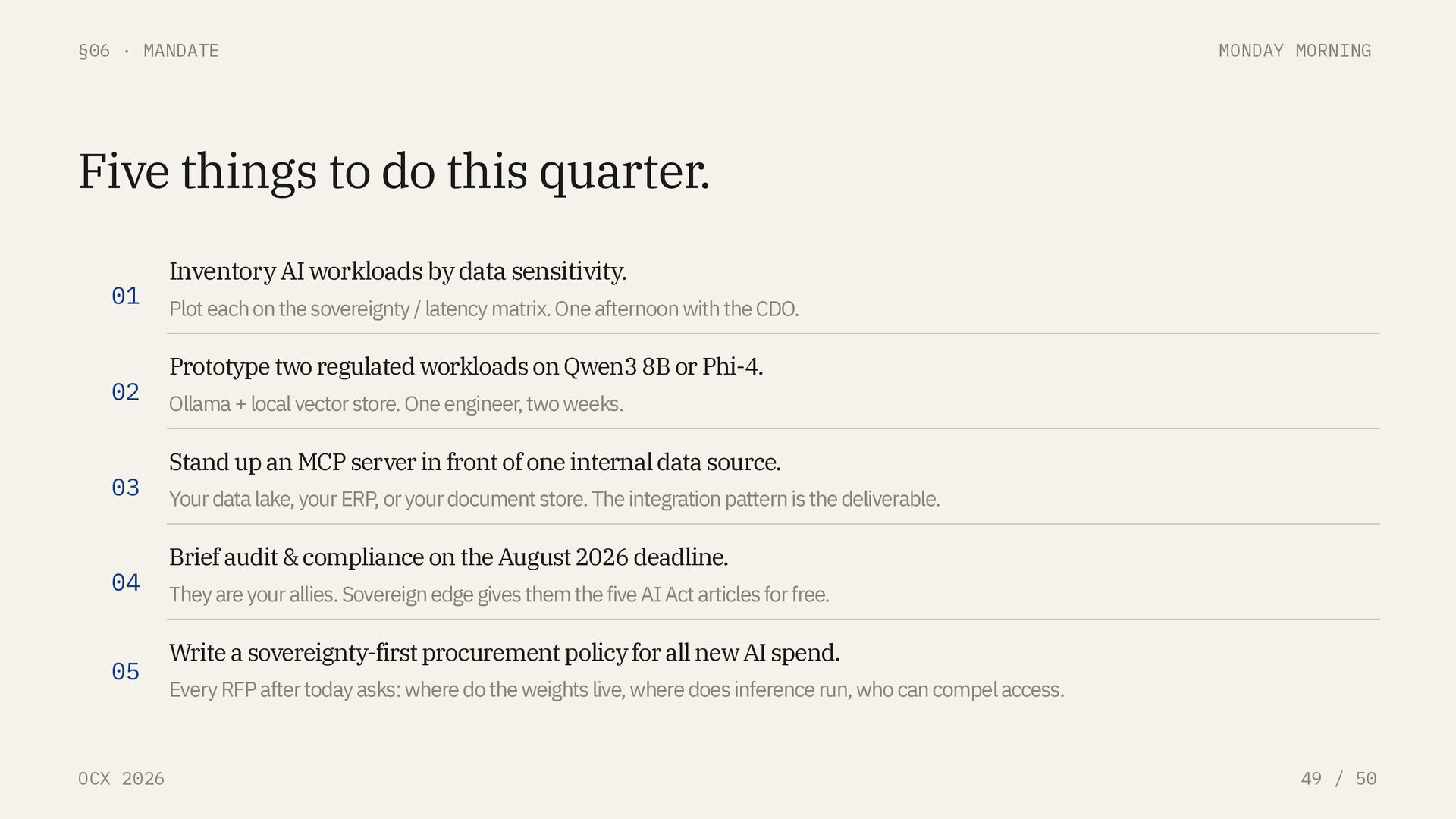
Five things to do this quarter. 01 Inventory AI workloads by data sensitivity. Plot each on the sovereignty / latency matrix. One afternoon with the CDO. 02 Prototype two regulated workloads on Qwen3 8B or Phi-4. Ollama + local vector store. One engineer, two weeks. 03 Stand up an MCP server in front of one internal data source. Your data lake, your ERP, or your document store. The integration pattern is the deliverable. 04 Brief audit & compliance on the August 2026 deadline. They are your allies. Sovereign edge gives them the five AI Act articles for free. 05 Write a sovereignty-first procurement policy for all new AI spend. Every RFP after today asks: where do the weights live, where does inference run, who can compel access.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}