со-авторов Что такое Apache Flink? 2014 в Apache Incubator. В 2016 1.0 версия < 100ms задержка (latency) Кластерное приложение для обработки потоковых данных в реальном времени Режимы: streaming и batch Часто используется вместе с Kafka Быстрее чем “Мощнее*” чем Kafka Streams (Flink App vs. KS app) 4
(CDC), Потоковый Lakehouse Аналитика данных в реальном времени Stream/Batch SQL, BI отчеты, Mat. Views Сложная событийная обработка (CEP*) фин. мониторинг, обр. транзакций, кибербезопасность (EDR), сенсоры на конвейерах ( IoT) AI и ML Обучение моделей, генерация рекомендаций, ML feature store *Complex Event Processing 5
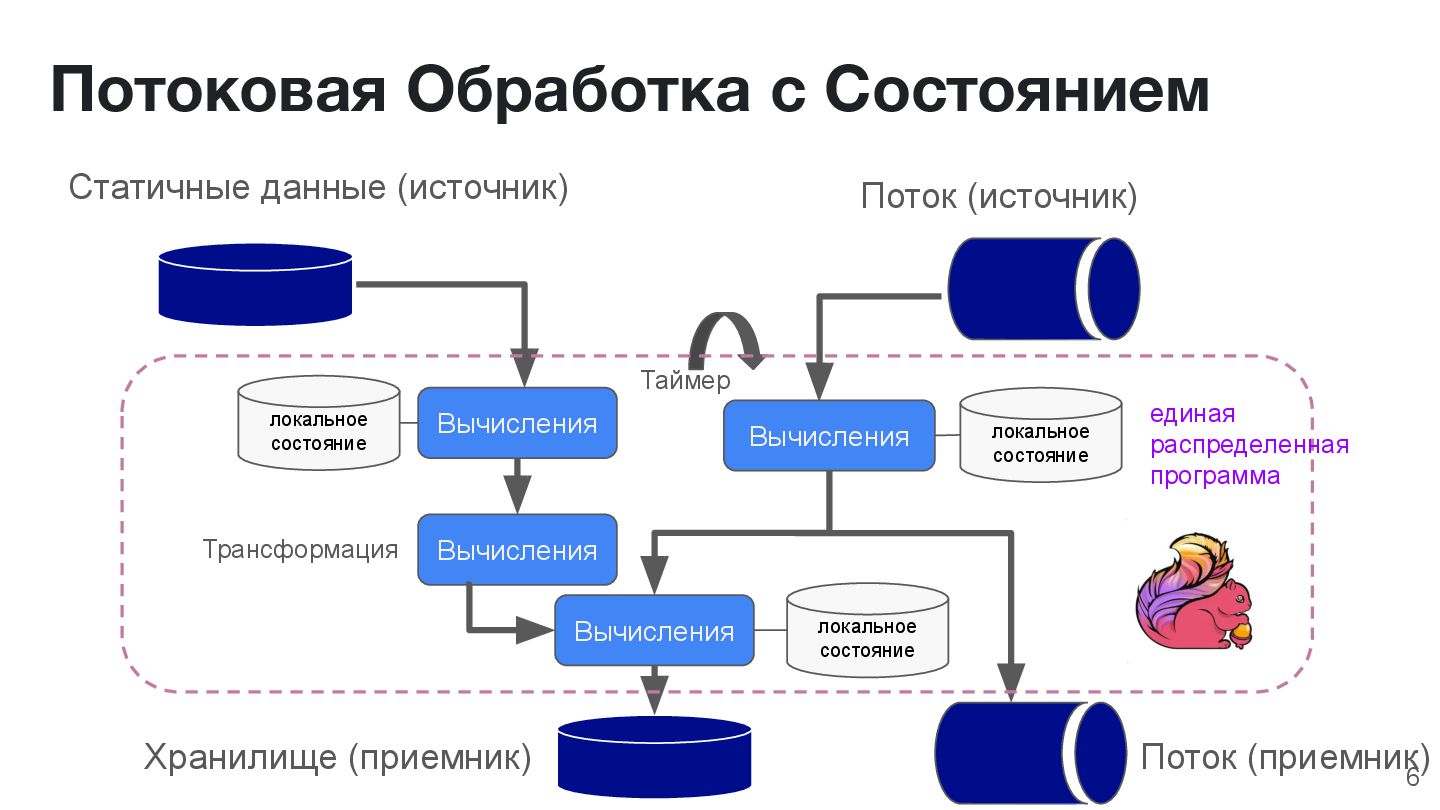
(источник) локальное состояние локальное состояние Вычисления Вычисления локальное состояние Хранилище (приемник) Поток (приемник) Трансформация Таймер единая распределенная программа 6
Платформа обработка потоковых данных: https://smartdataconf.ru/archive/2024/talks/da48c7cc0108449c89ad36cefa64777d/ Lyft такси-сервис: определение времени подбора клиента, динамическая цена, генерация ML св-ва для обнаружения мошенничества. https://www.alibabacloud.com/blog/lyfts-large-scale-flink-based-near-real-time-data-analytics-pla tform_596674 Netflix: персонализация, рекомендации, мониторинг качества видеопотока и доставки контента, мониторинг сервисов Alibaba: электронная коммерция, интеграция данных, аналитика в реальном времени. 10
Scala изначально созданный в Findify (спасибо - Роман Г.) - поддерживает Scala 2.13 и 3.x Как мигрировать: // оригинальный API import import org.apache.flink.streaming.api.scala.* // flink-scapa-api imports import org.apache.flinkx.api.* import org.apache.flinkx.api.serializers.* Было: Стало: 15
импорт): a. базовые типы Scala b. ADT во время компиляции 2. Сериализация без использования Java Reflection во время исполнения (Magnolia) 3. Без скрытого переключения на Kryo сериализаторы (ошибка компиляции) 4. Расширяемость сериализаторов для глубоко- вложенных типов через Type Classes Почему Scala? преимущества в сериализации: 18
copy(x = x + a) // явное определение для кэширования // если не определено, тогда выводится автоматически given fooTypeInfo: TypeInformation[Foo] = deriveTypeInformation[Foo] env .fromElements(Foo( 1),Foo(2),Foo(3)) .map(x => x.inc( 1)) // передано как given .map(x => x.inc( 2)) // снова, без повторного выведения Выведение Сериализаторов 20
почти всегда (var) env.getConfig.enableObjectReuse - > меньше времени на передачу данных - Также актуально для HashMapStateBackend case class Transaction( accountId: Long, timestamp: Long, amount: Double, loc: String = "" ) 21
Mill - Для новой версией Scala, заменить flink-scala*.jar в flink/lib на: - scala-library-2.13.x.jar - scala-library_3-3.y.z.jar (опционально) - flink-scala-api-2_3-a.b.c.jar (из flinkextended) - Для моделей данных используй Case Classes / Enums / ADTs Отличия от Java или Python 25
- Прекрасно подходит для управлениями Flink приложениями в продакшене - Позволяет настроить и развернуть Flink дистрибутив через - K8s CRDs - Docker образ для Flink JM & TM apiVersion: flink.apache.org/v1beta1 kind: FlinkDeployment spec: ………… job: jarURI: local:///opt/flink/usrlib/word-count-job.jar entryClass: WordCount 29
паковать в fat JAR ADD --chown=flink --chmod=644 scala3-library_3-3.7.1.jar $FLINK_HOME/lib/ ADD --chown=flink --chmod=644 scala-library-2.13.16.jar $FLINK_HOME/lib/ ADD --chown=flink --chmod=644 flink-scala-api-2_3-1.2.8.jar $FLINK_HOME/lib/ Как развернуть Scala 3 Job через Flink Operator FROM flink:2.0.0 # удаляем старый Scala модуль RUN rm $FLINK_HOME/lib/flink-scala*.jar - Собираем свой Docker Job образ # добавляем свой Job JAR COPY word-count-job.jar /opt/flink/usrlib/ 30
инструментарий - Более “функциональный” и менее “развесистый” код - Сериализация без головной боли (auto-derivation) - Доступ к самым новым возможностям Scala 3 Попробуй реализовать свой следующий Flink job на flink-scala-api! Пример конвертации Scala Savepoint: 32 Релиз 1.15 о Scala-free Extended Flink Scala API
о Scala-free - :https://flink.apache.org/2022/02/22/scala-free-in-one-fifteen/ - https://github.com/flink-extended/flink-scala-api Extended Flink Scala API
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Пример на DataStream API val lines = env.fromSource(KafkaSource.builder[String]()....) val events](https://files.speakerdeck.com/presentations/cd7dfef9ae9b45059f8a96724d238206/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
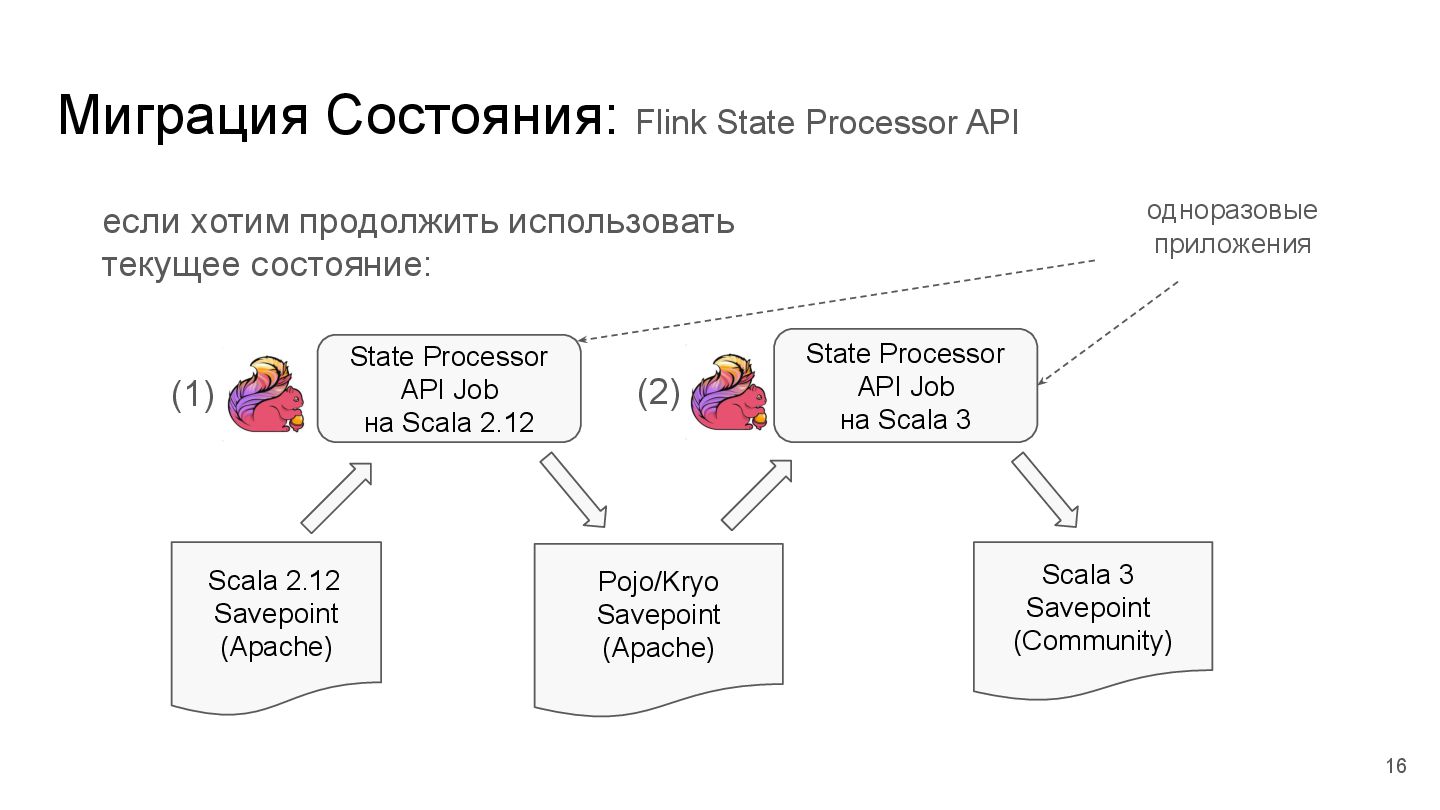{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
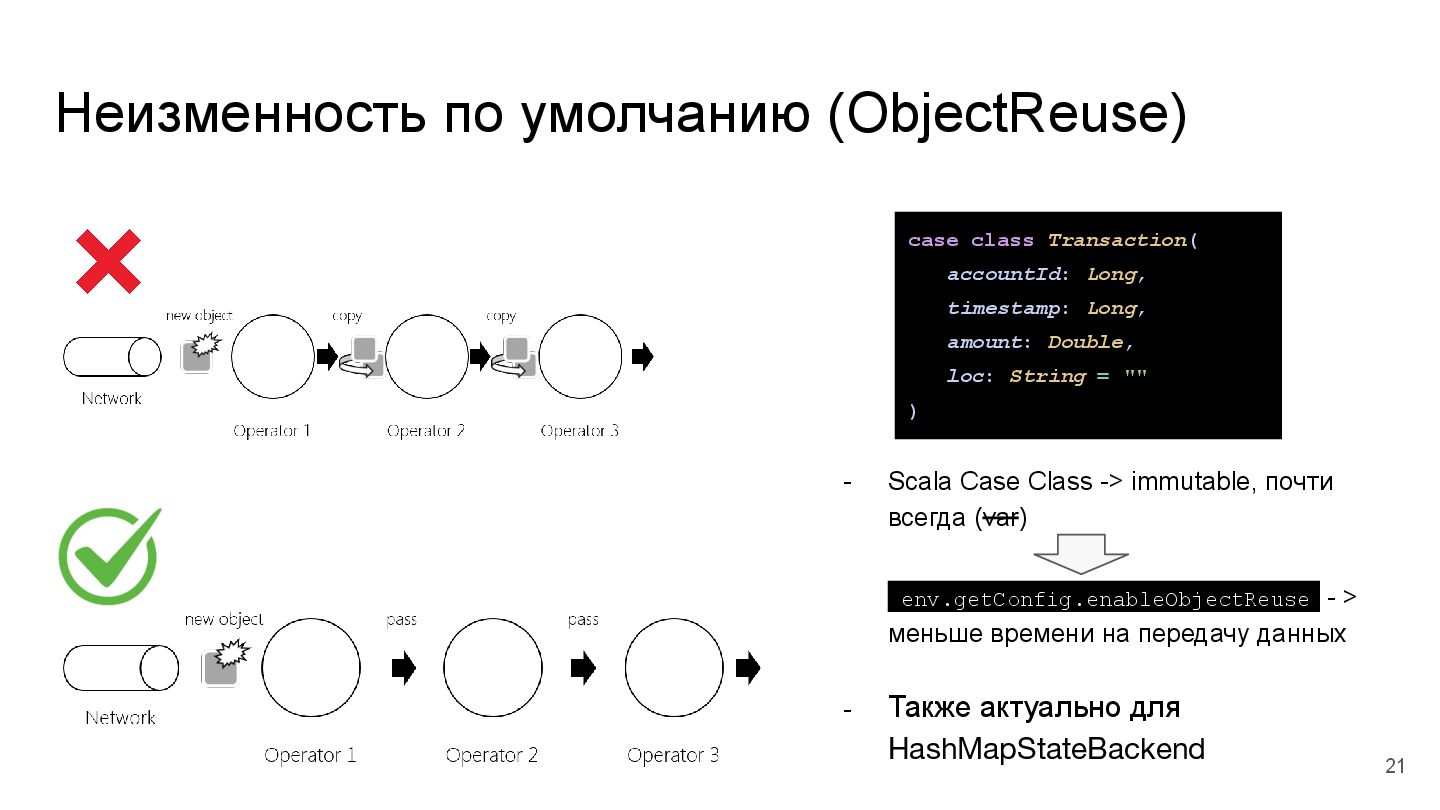{kind=link}
{kind=link}
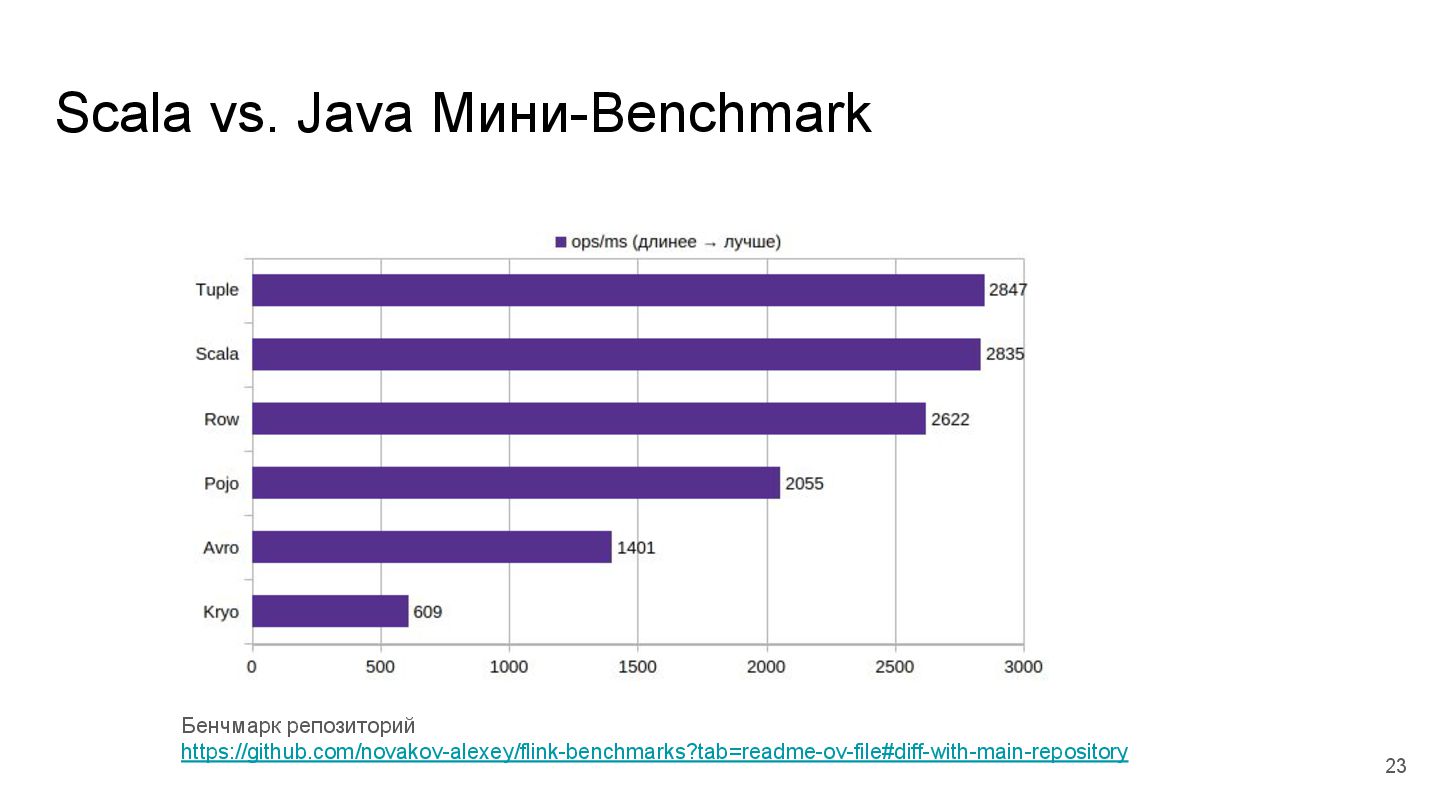{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}