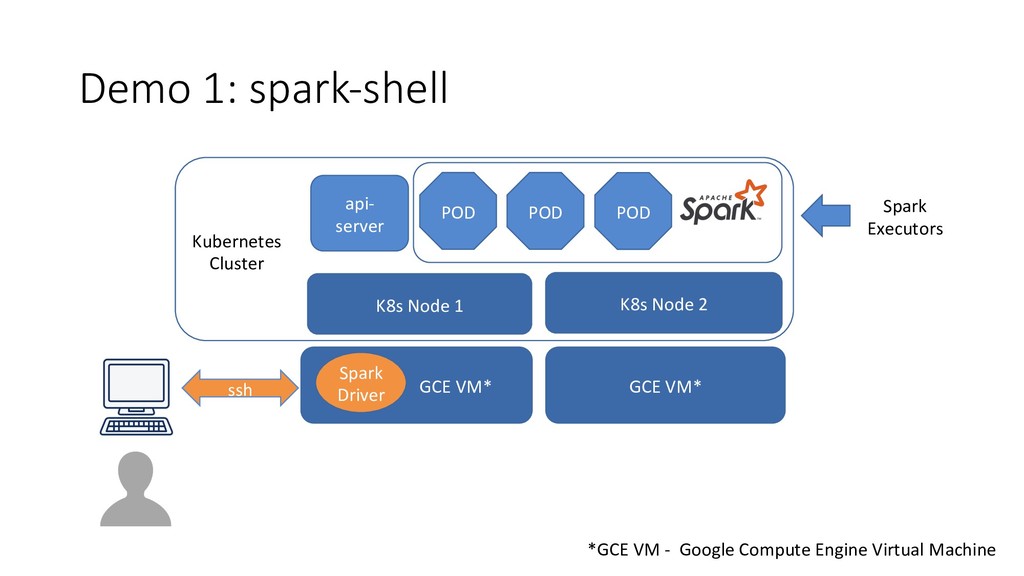
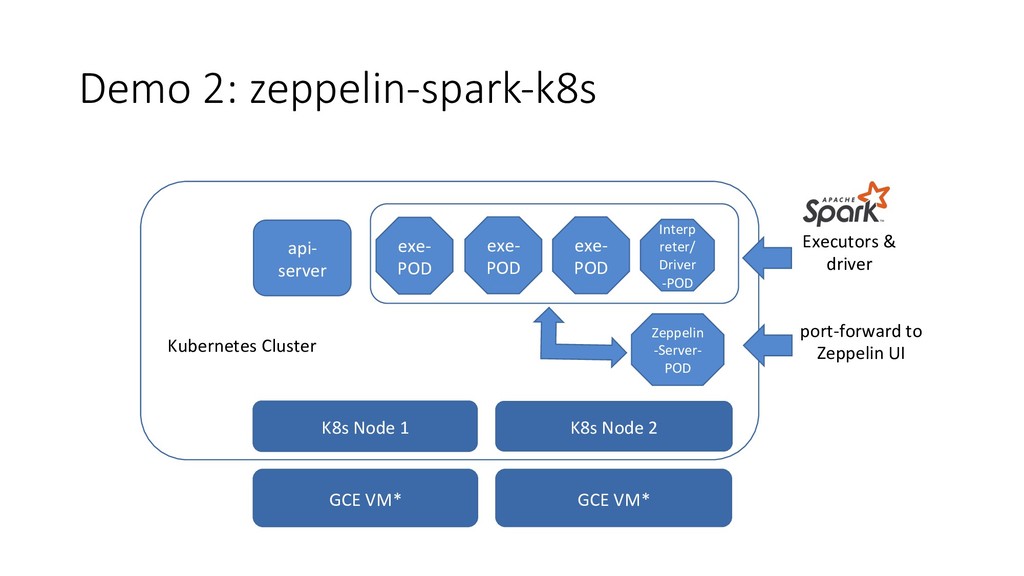
New Spark version is getting closer to use all possible native Kubernetes scheduler features. Latest Spark comes with support of client-mode in Kubernetes, which enables us to use Spark Notebooks and work in interactive mode. In this talk we will learn how Spark is using Kubernetes to spin up Spark executors and coordinate Spark jobs with a driver process. It will be a short demo having Spark Job running in Google Kubernetes Engine and Apache Zeppelin notebook in the client-mode. We will look at two scenarios: driver inside the K8s cluster, a driver outside the cluster. We will also talk about new K8s-Spark integration features and future plans of Spark community with regards to K8s.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
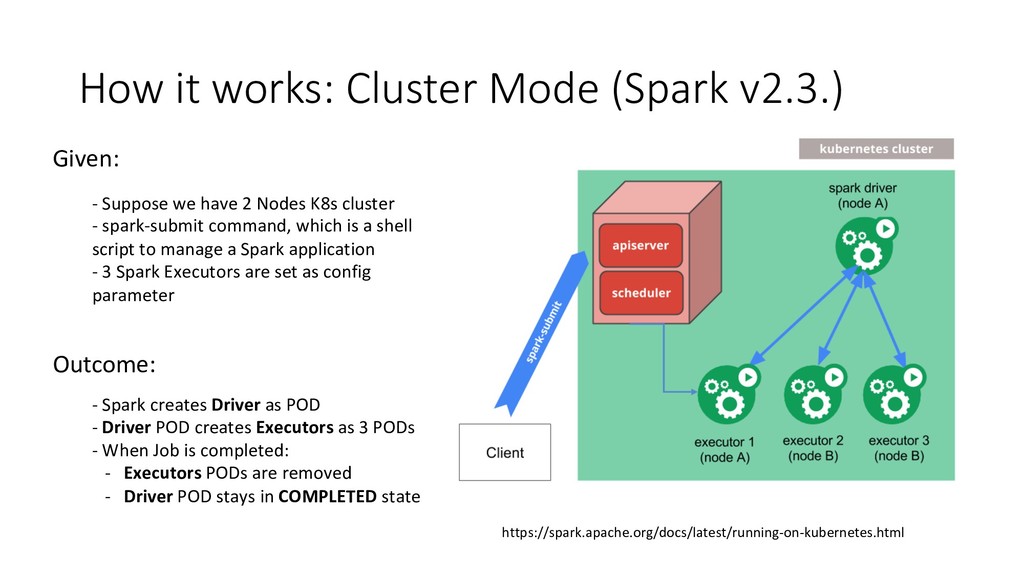{kind=link}
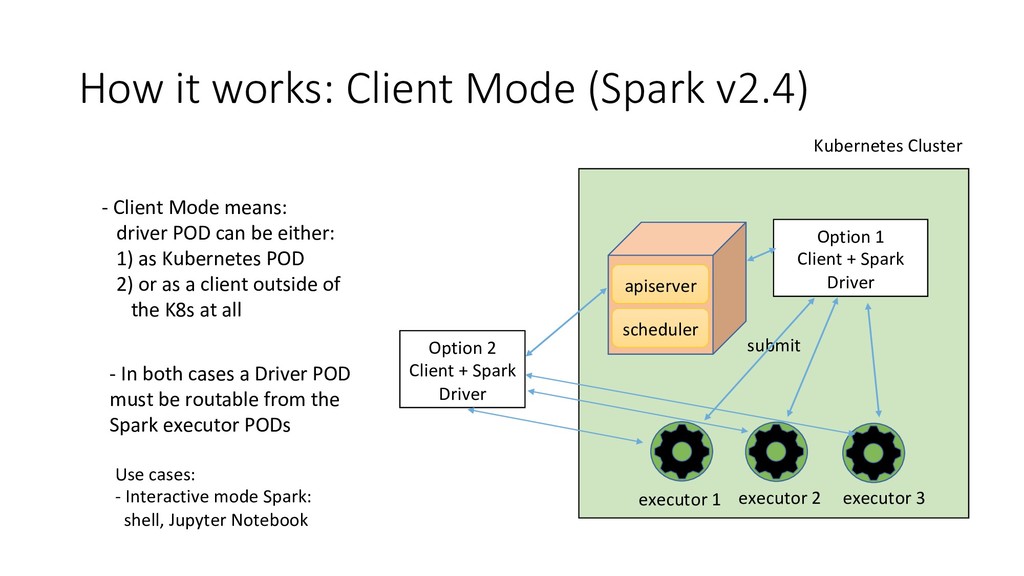{kind=link}
{kind=link}
{kind=link}
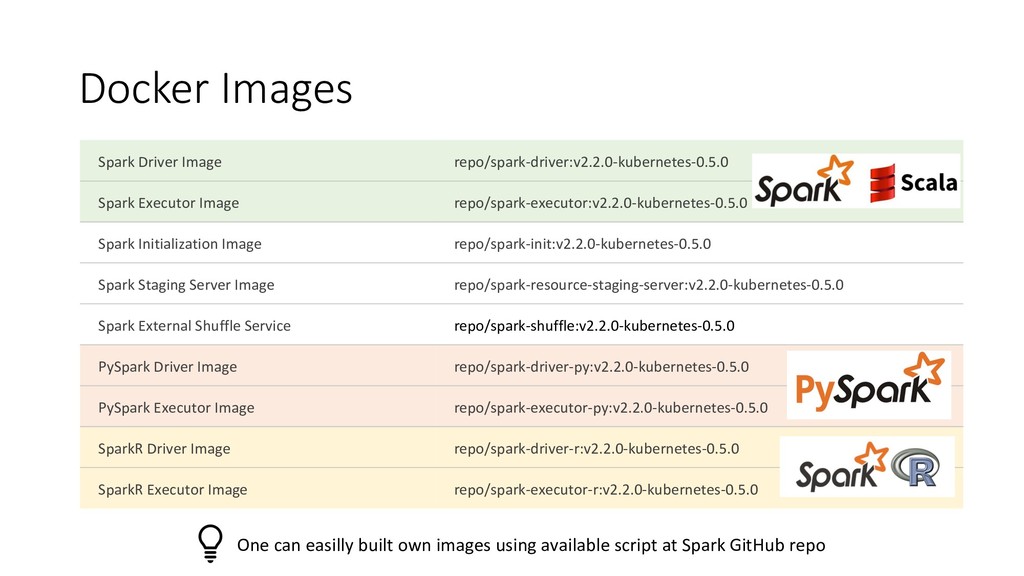{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}