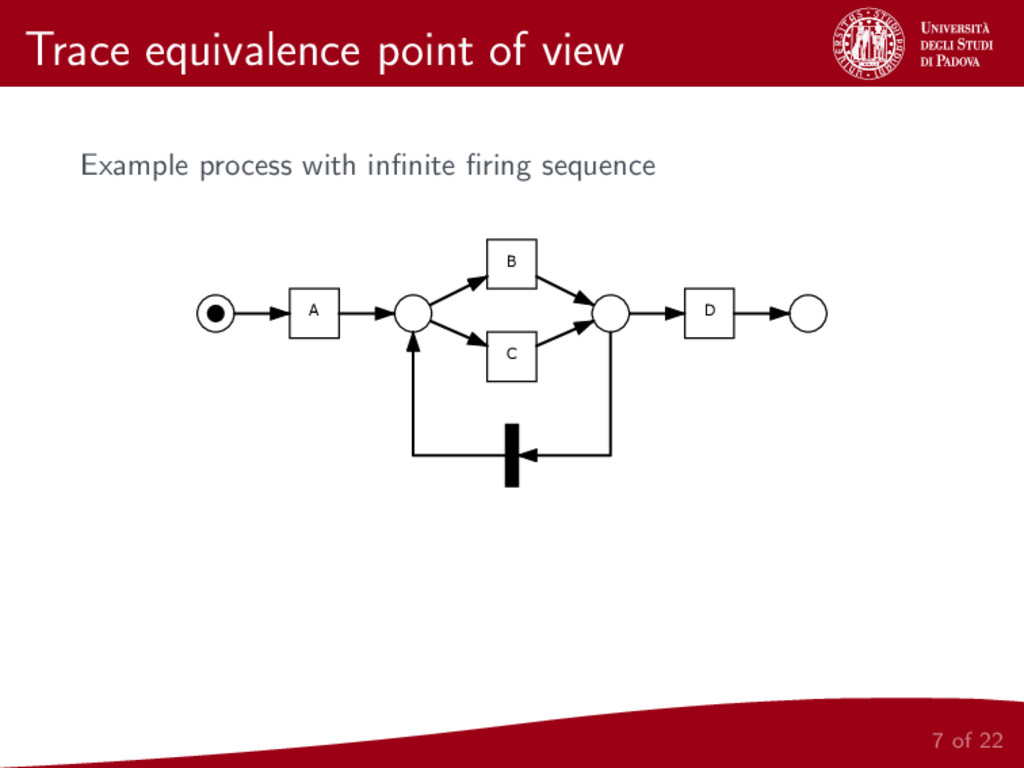
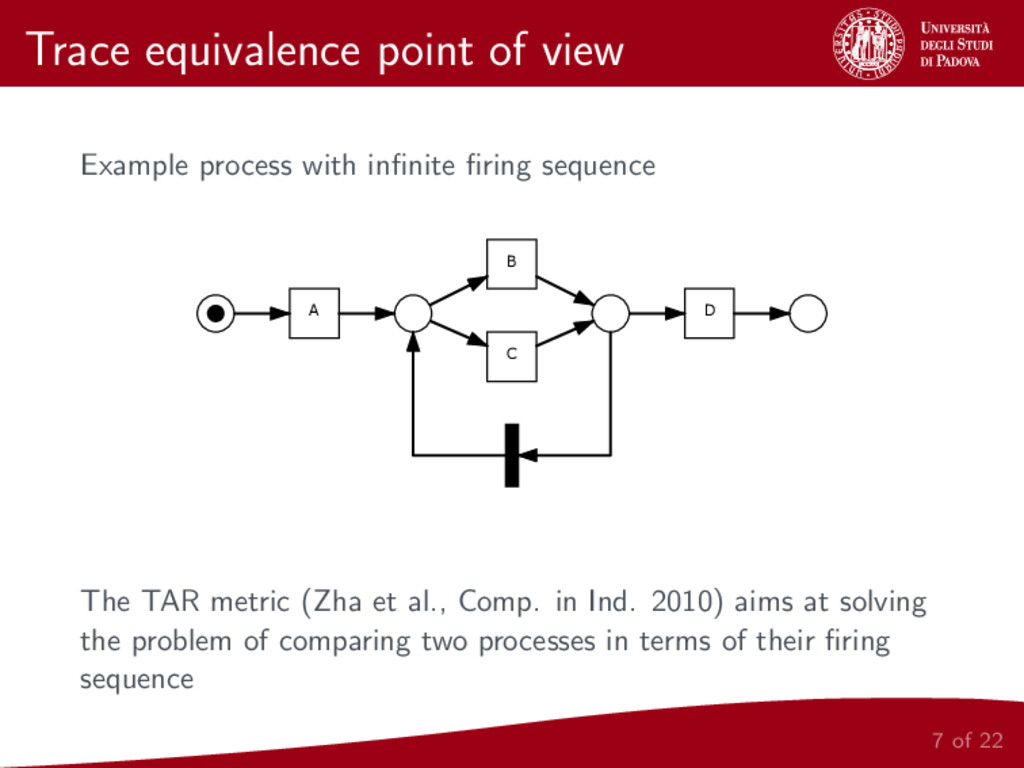
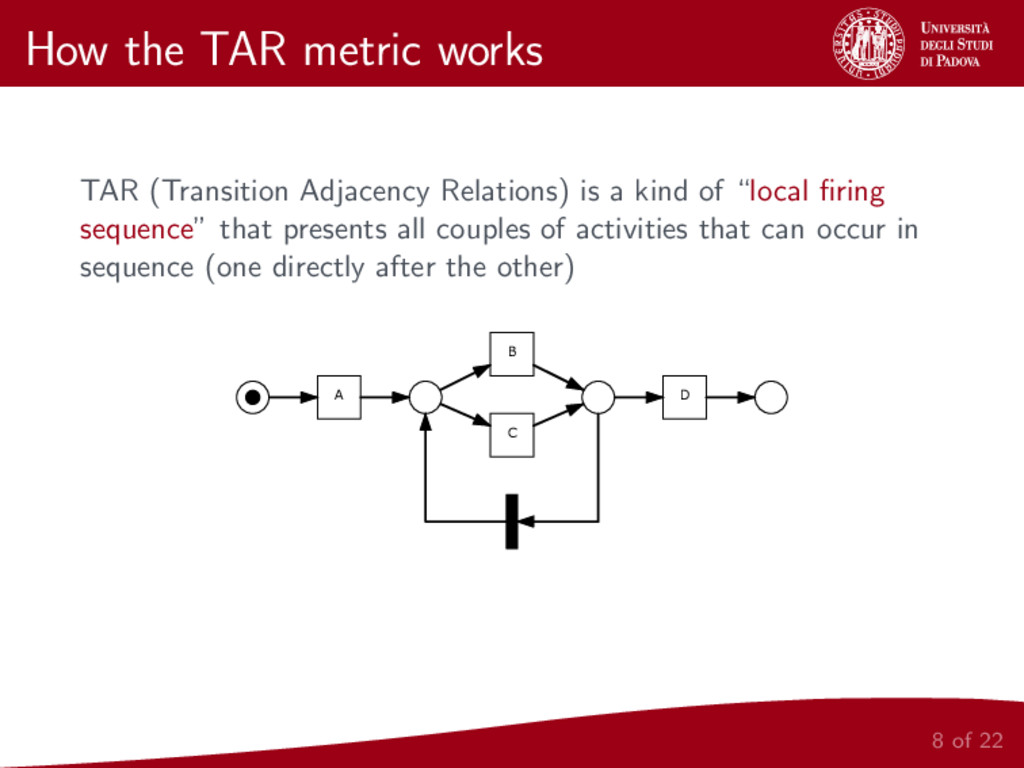
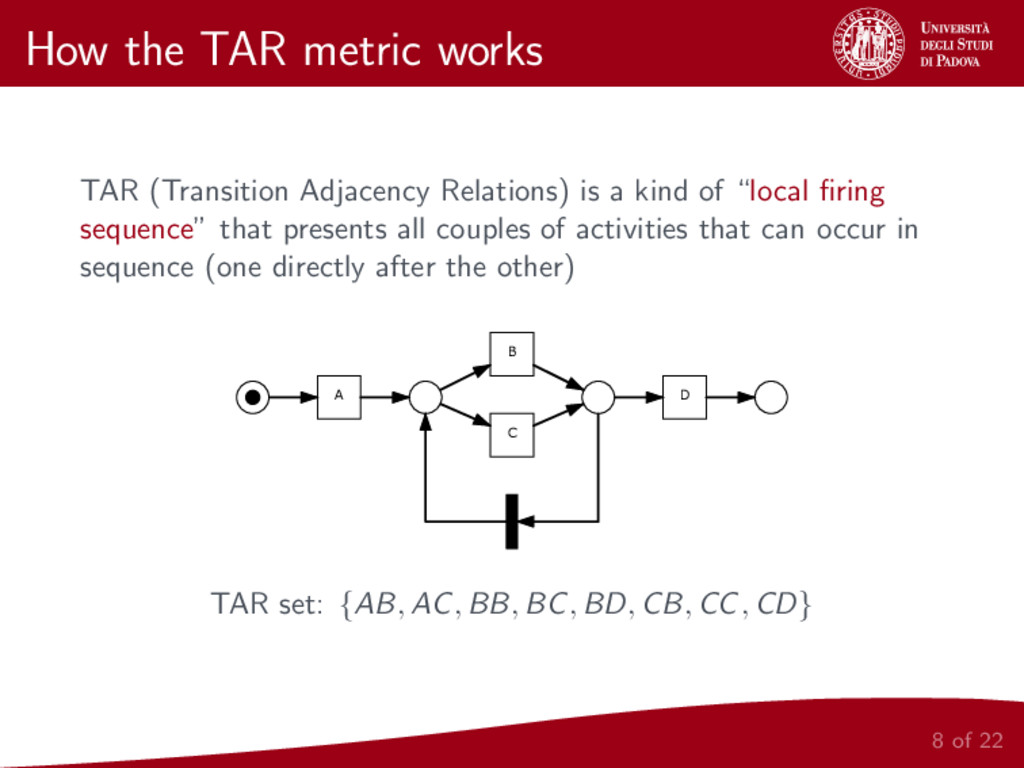
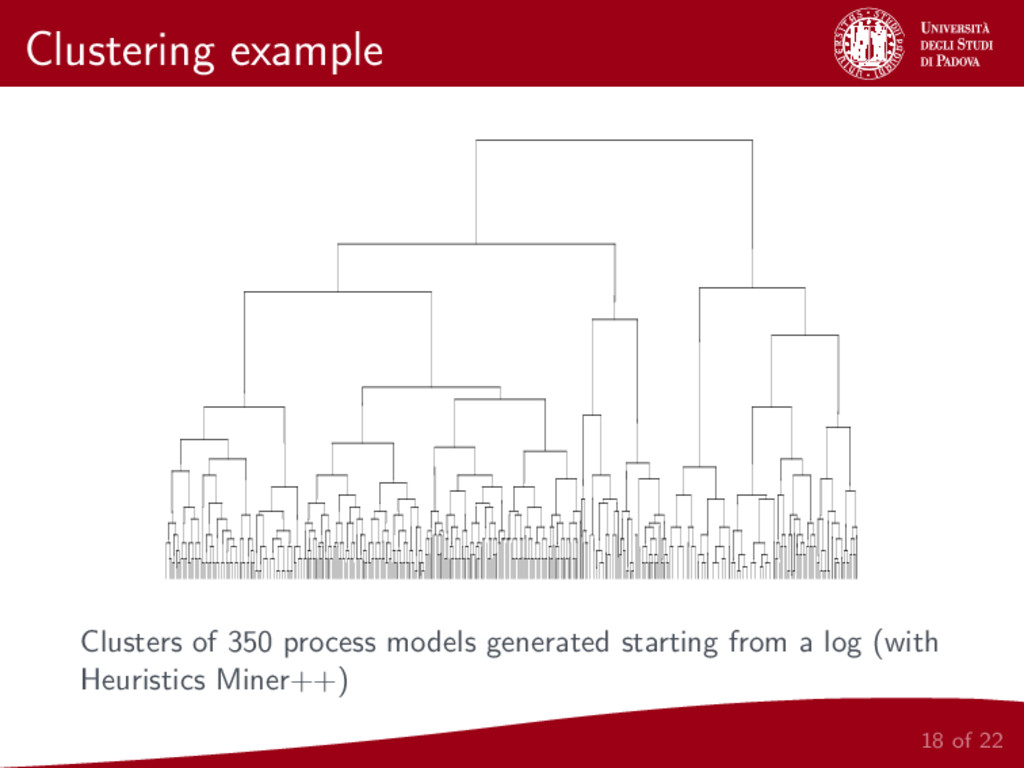
We present a metric for the comparison of business process models. This new metric is based on a representation of a given model as two sets of local relations between pairs of activities in the model. In order to build this two sets, the same relations defined for the Alpha Algorithm [2] are considered. The proposed metric is then applied to hierarchical clustering of business process models and the whole procedure is implemented and made publicly available.
More info: http://andrea.burattin.net/publications/2011-bpi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}