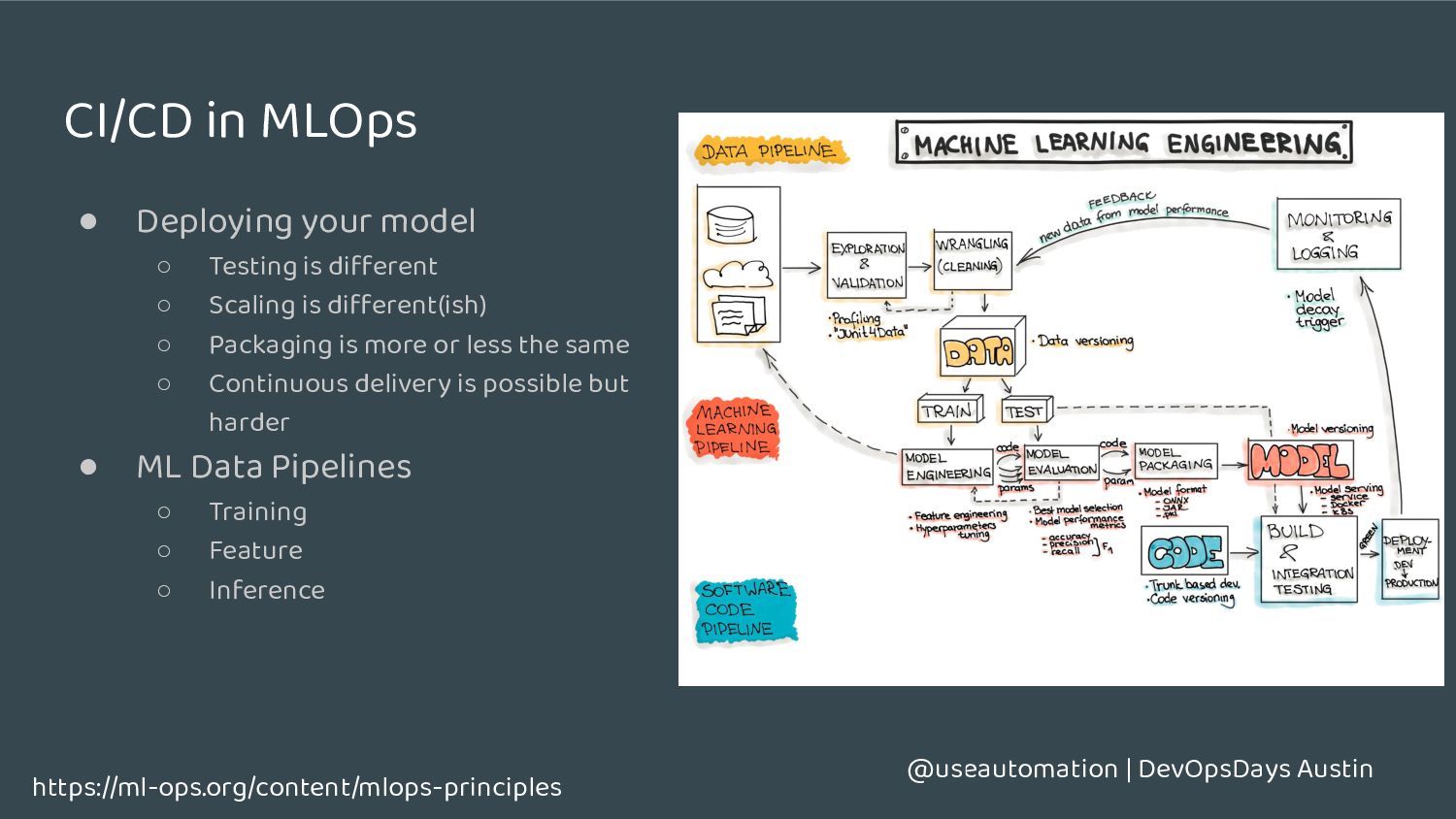
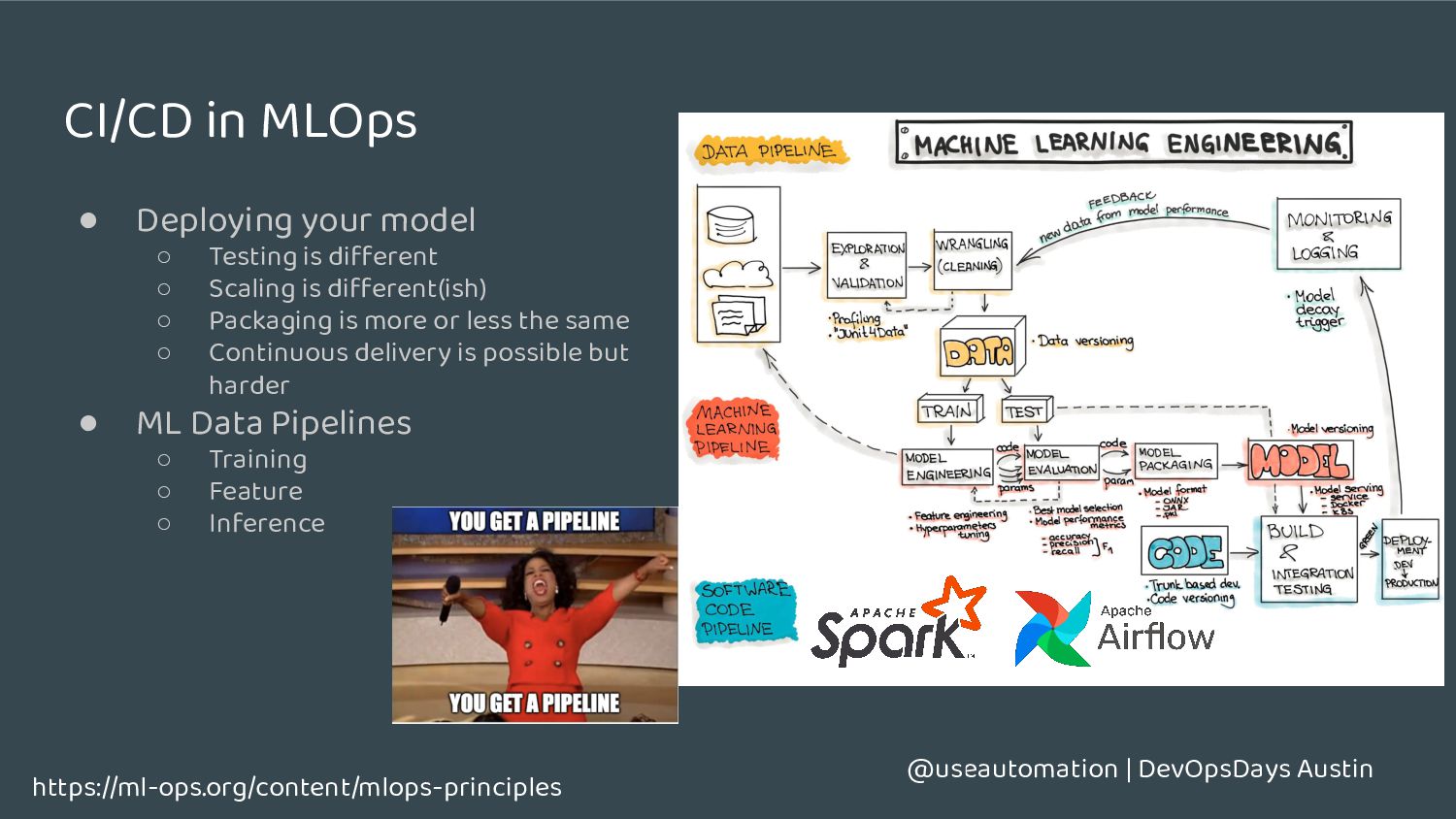
model ◦ Testing is different ◦ Scaling is different(ish) ◦ Packaging is more or less the same ◦ Continuous delivery is possible but harder • ML Data Pipelines ◦ Training ◦ Feature ◦ Inference https://ml-ops.org/content/mlops-principles
model ◦ Testing is different ◦ Scaling is different(ish) ◦ Packaging is more or less the same ◦ Continuous delivery is possible but harder • ML Data Pipelines ◦ Training ◦ Feature ◦ Inference https://ml-ops.org/content/mlops-principles
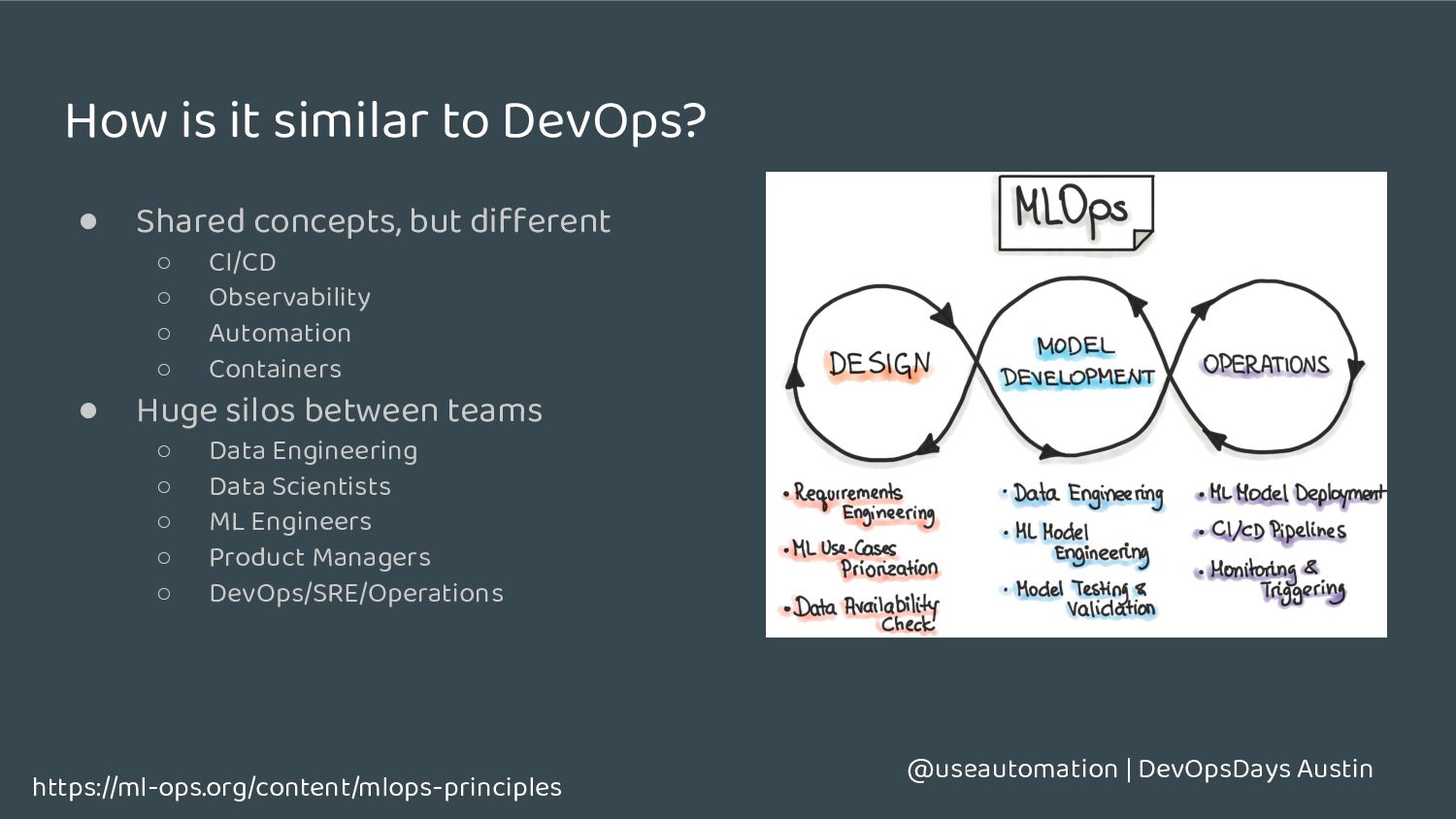
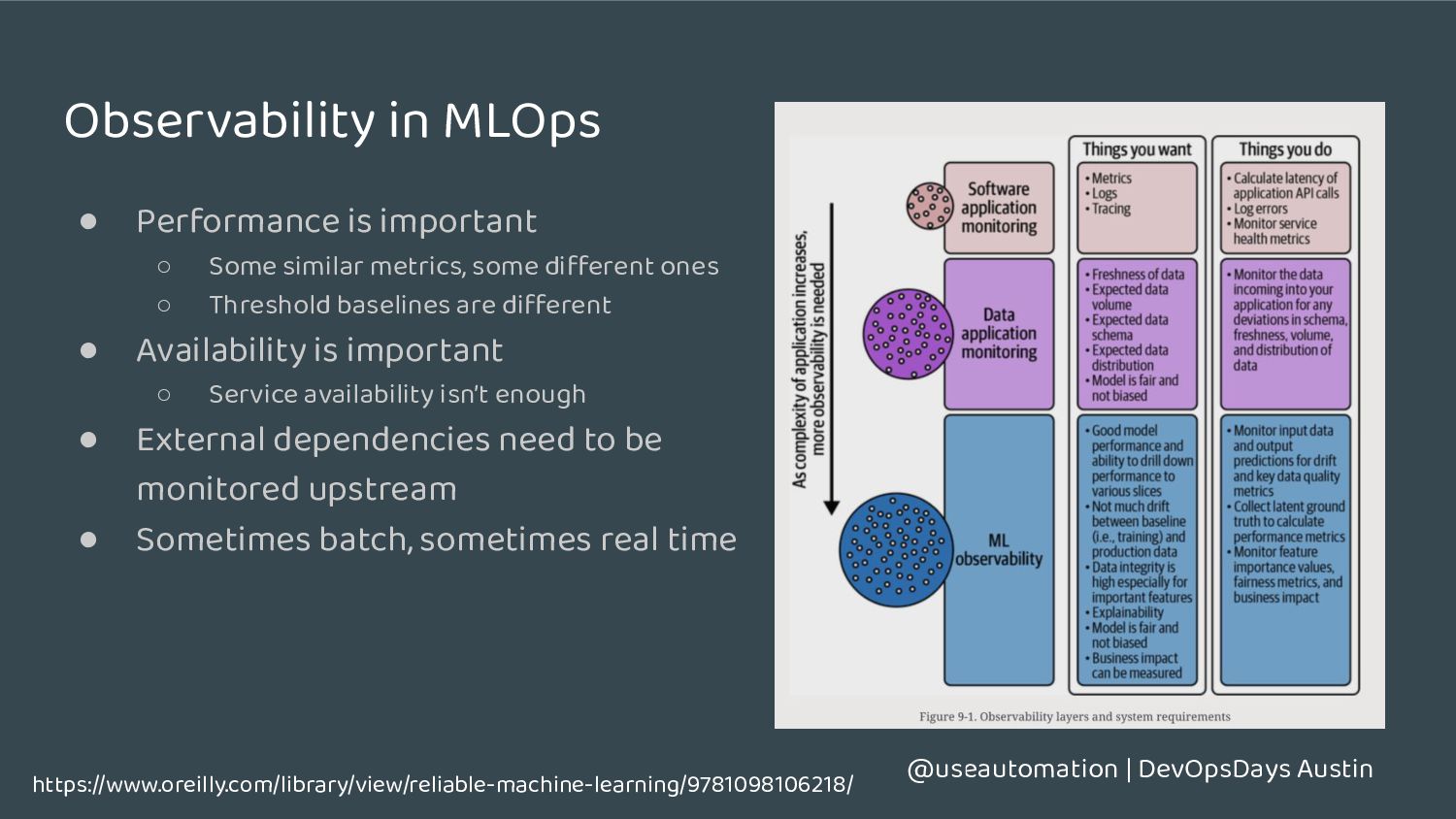
important ◦ Some similar metrics, some different ones ◦ Threshold baselines are different • Availability is important ◦ Service availability isn’t enough • External dependencies need to be monitored upstream • Sometimes batch, sometimes real time https://www.oreilly.com/library/view/reliable-machine-learning/9781098106218/
• Yes, it’s still kubernetes. ◦ With all of it’s usual complaints. • Sometimes controlled directly, most times through a platform ◦ Kubeflow ◦ Sagemaker ◦ AzureML ◦ Vertex • Scaled for model serving, training, and pipelines
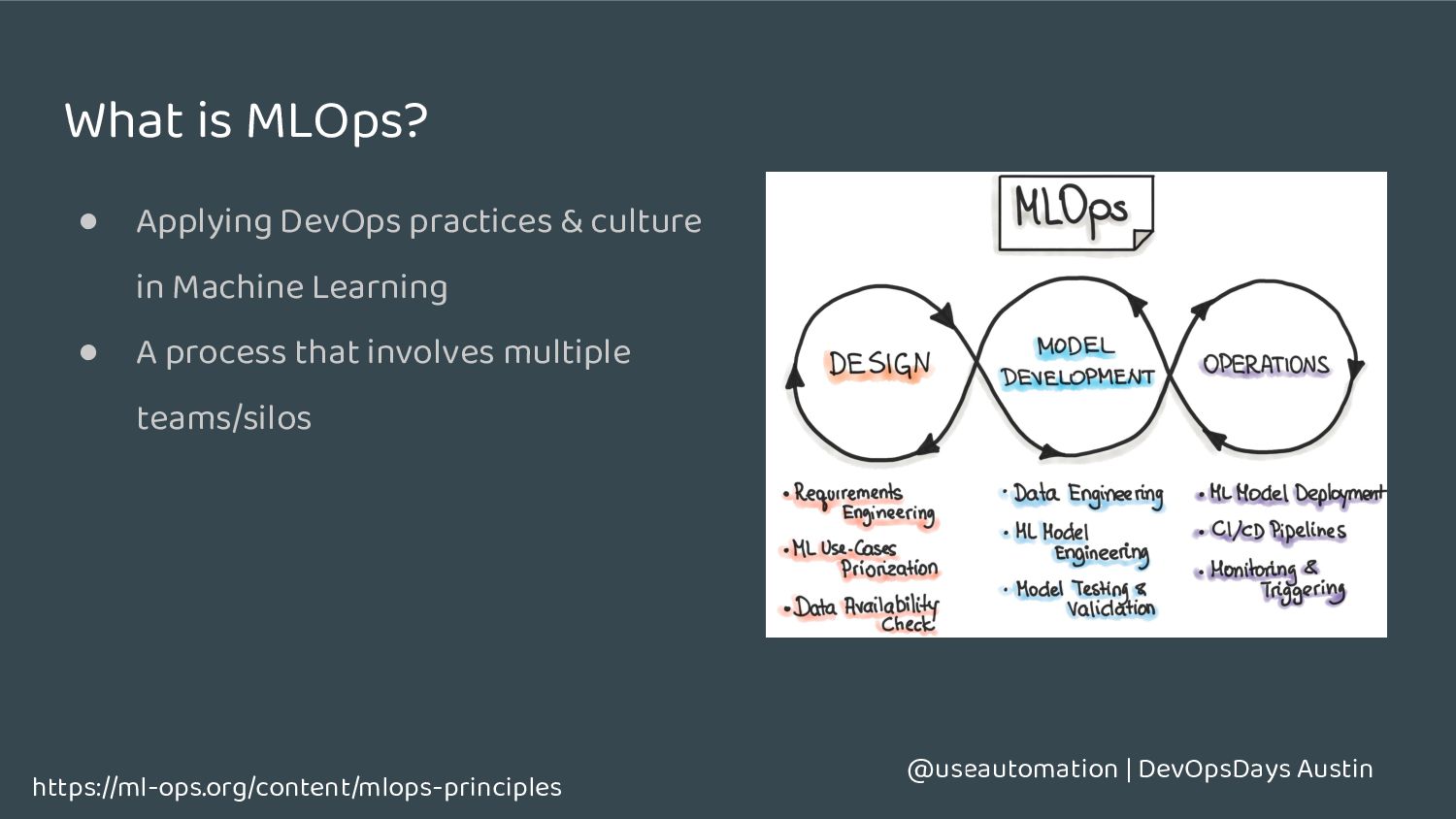
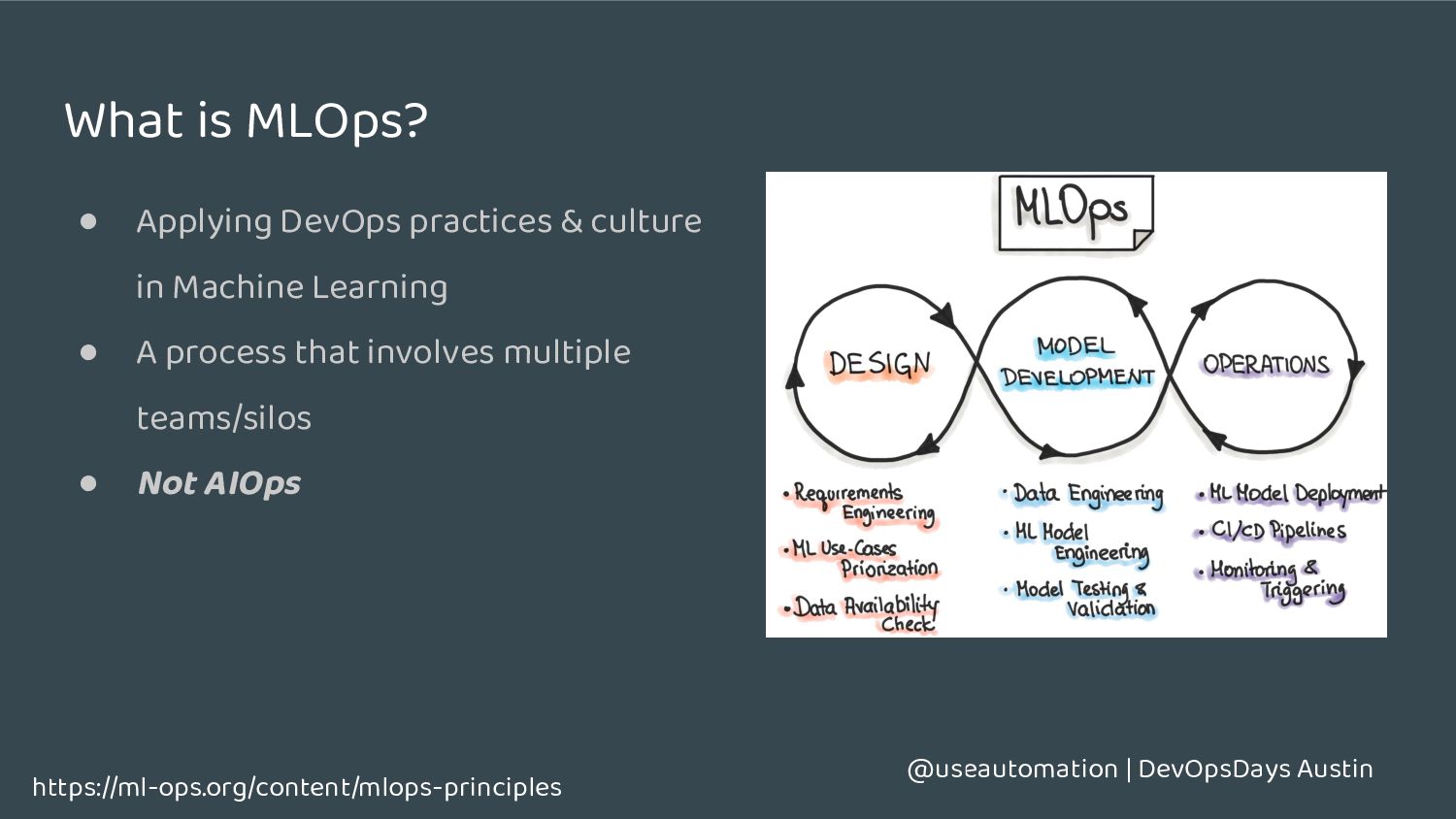
Machine learning systems tend to be: ◦ Fragile to changes in data ◦ Harder to test ◦ Harder to scale • Complex to measure ◦ What is good vs what is bad? ◦ You may not know if something is good or bad for a while • Models get worse over time, not better • Data Scientists <3 Jupyter notebooks https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
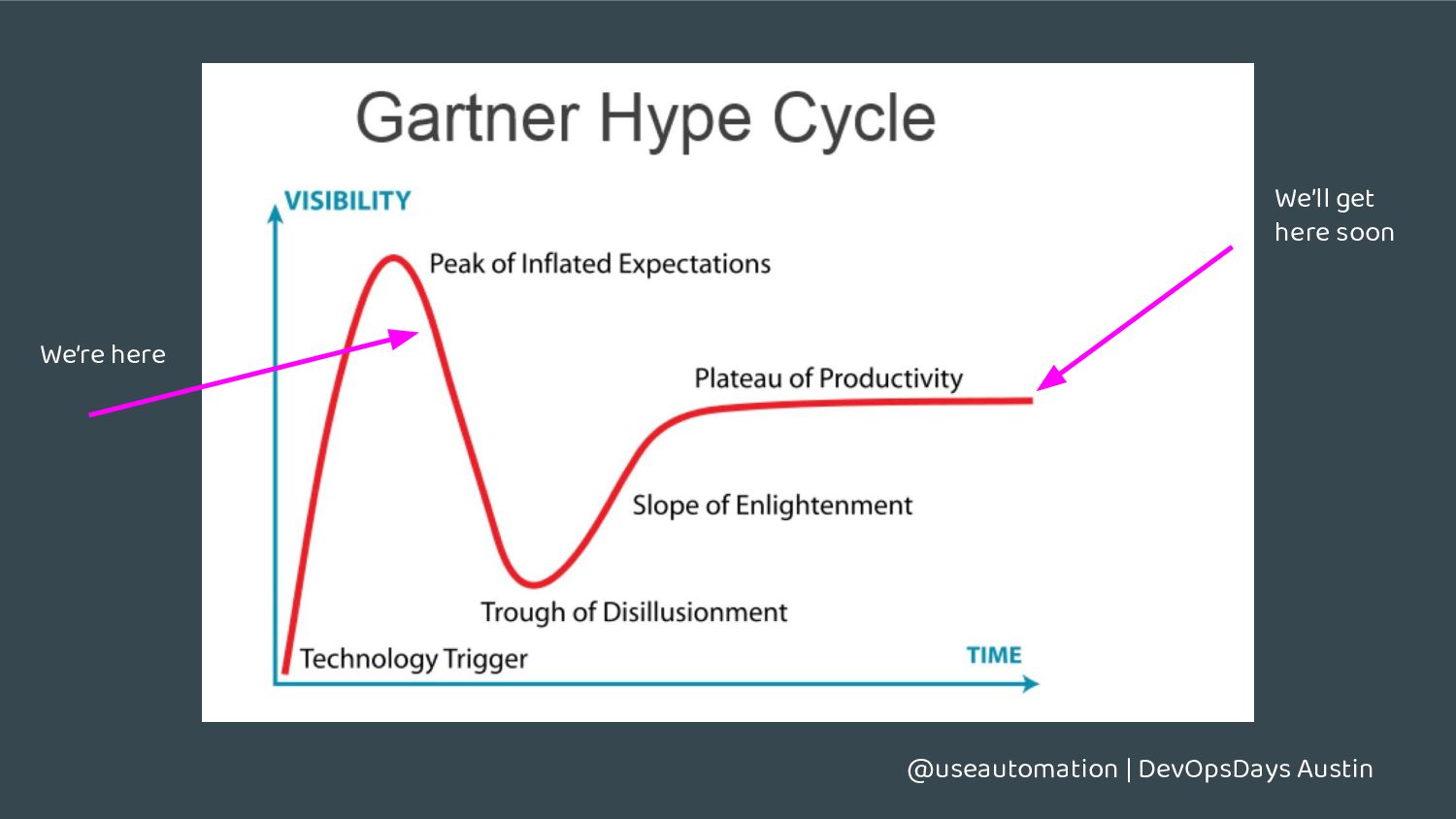
MLOps? • There’s a TON of new innovation happening • There is a desperate need for operating experience • MLOps is where DevOps was ~8-10 years ago • Open source development is happening fast • ML is here to stay
out what models you’re running (or planning to run) in production • Get involved, share knowledge and experiences • Start experimenting with open source models & examples • Talk about this with your team and think about how you can avoid surprises
{kind=link}
{kind=link}
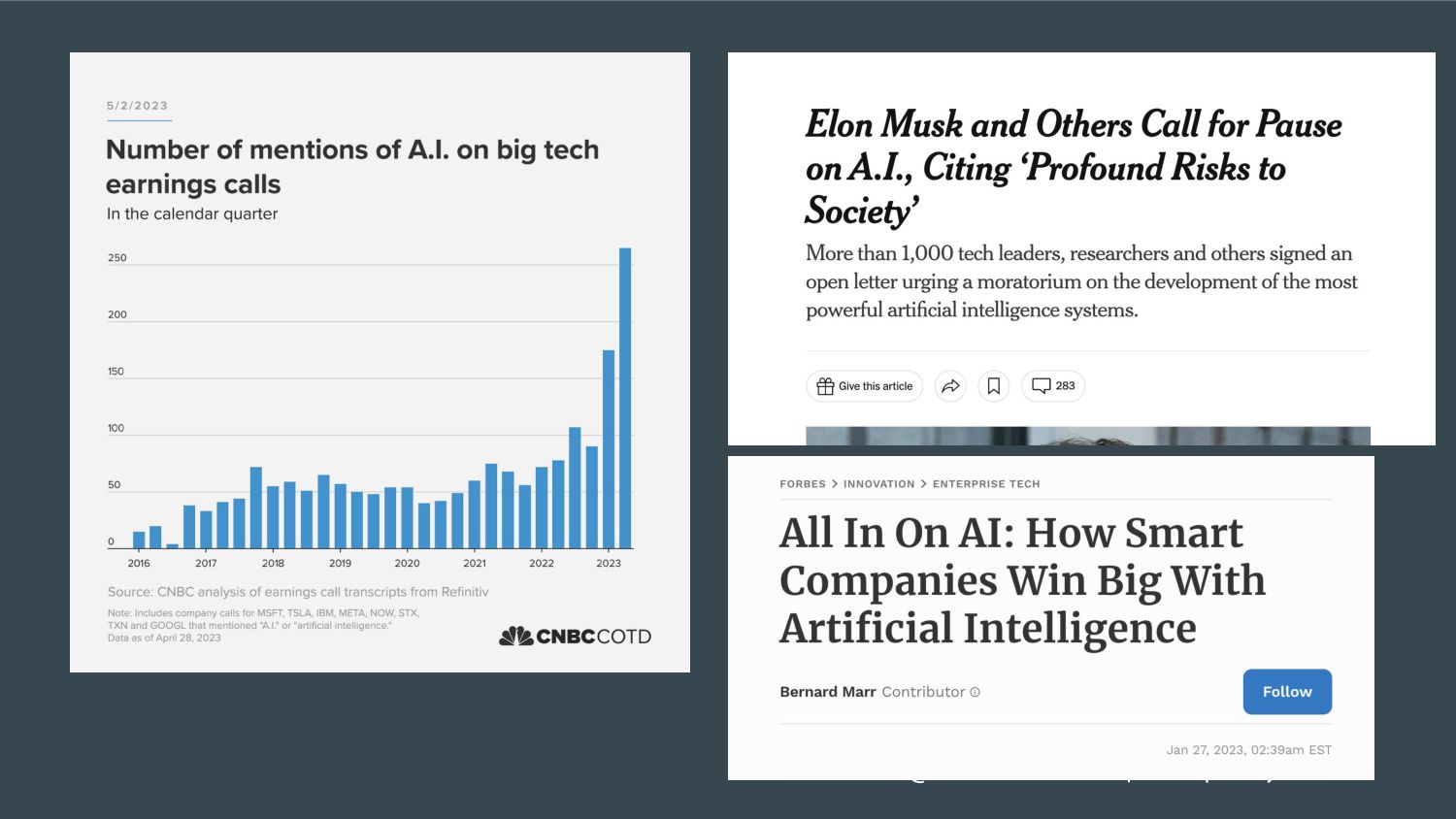{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
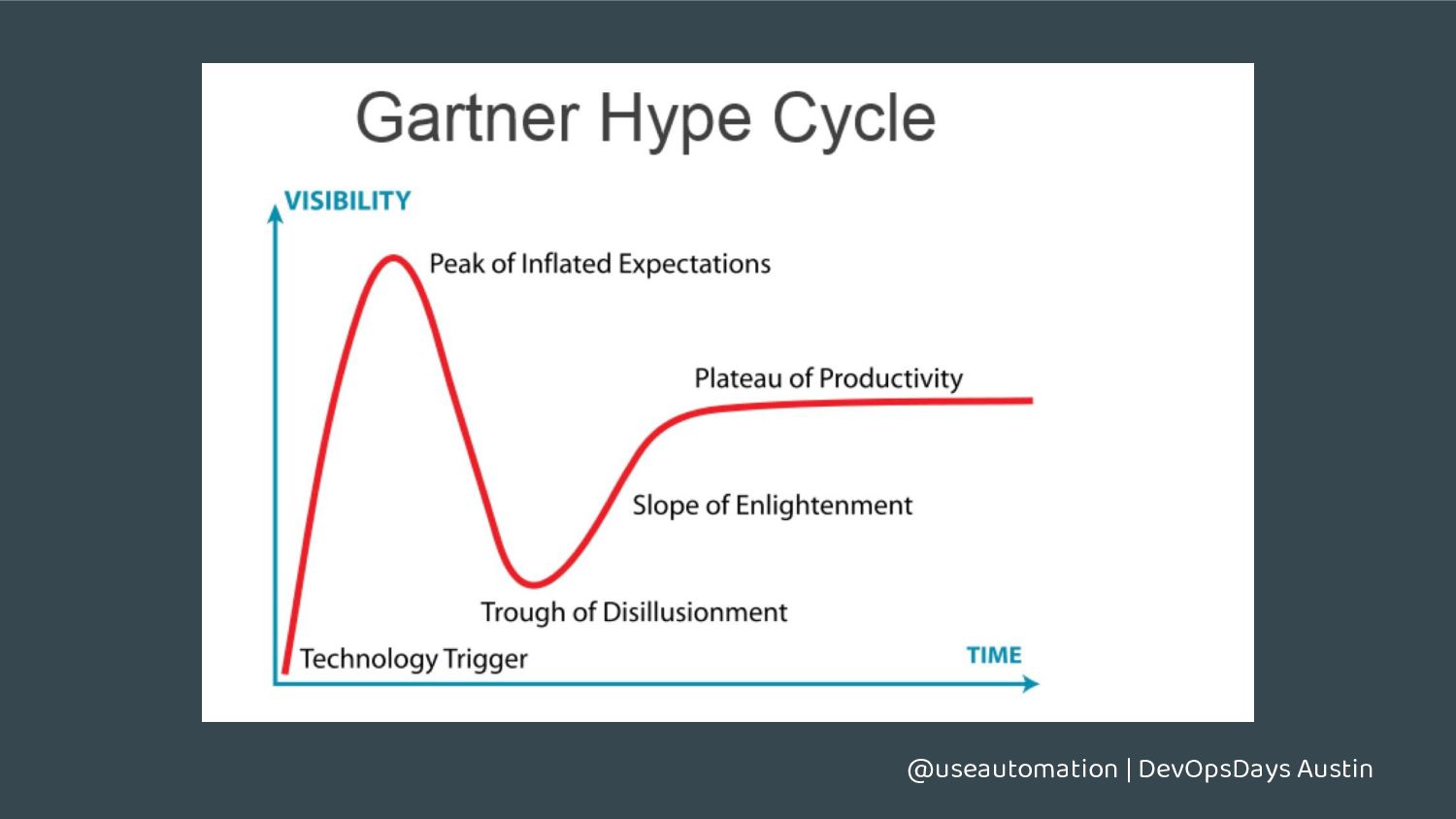{kind=link}
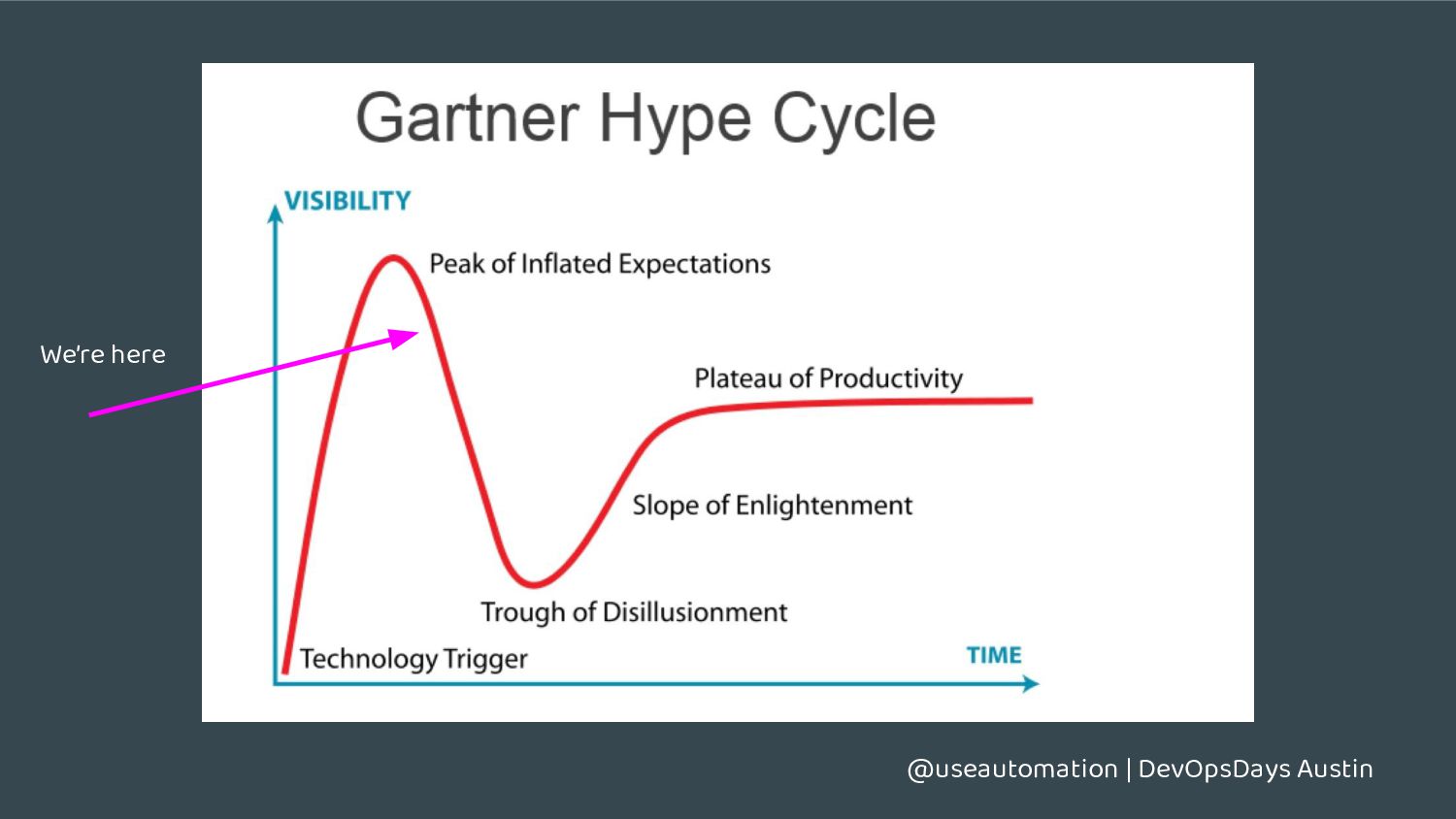{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}