Presentation of the paper "Autoscaling Tiered Cloud Storage in Anna", presented at the Massive Data Processing discipline's seminar at DCC/UFMG 2022/01.
Presentation (PT-BR): https://www.youtube.com/watch?v=gzspGRsFVEs
Original paper published by VLDB 19: https://dsf.berkeley.edu/jmh/papers/anna_vldb_19.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
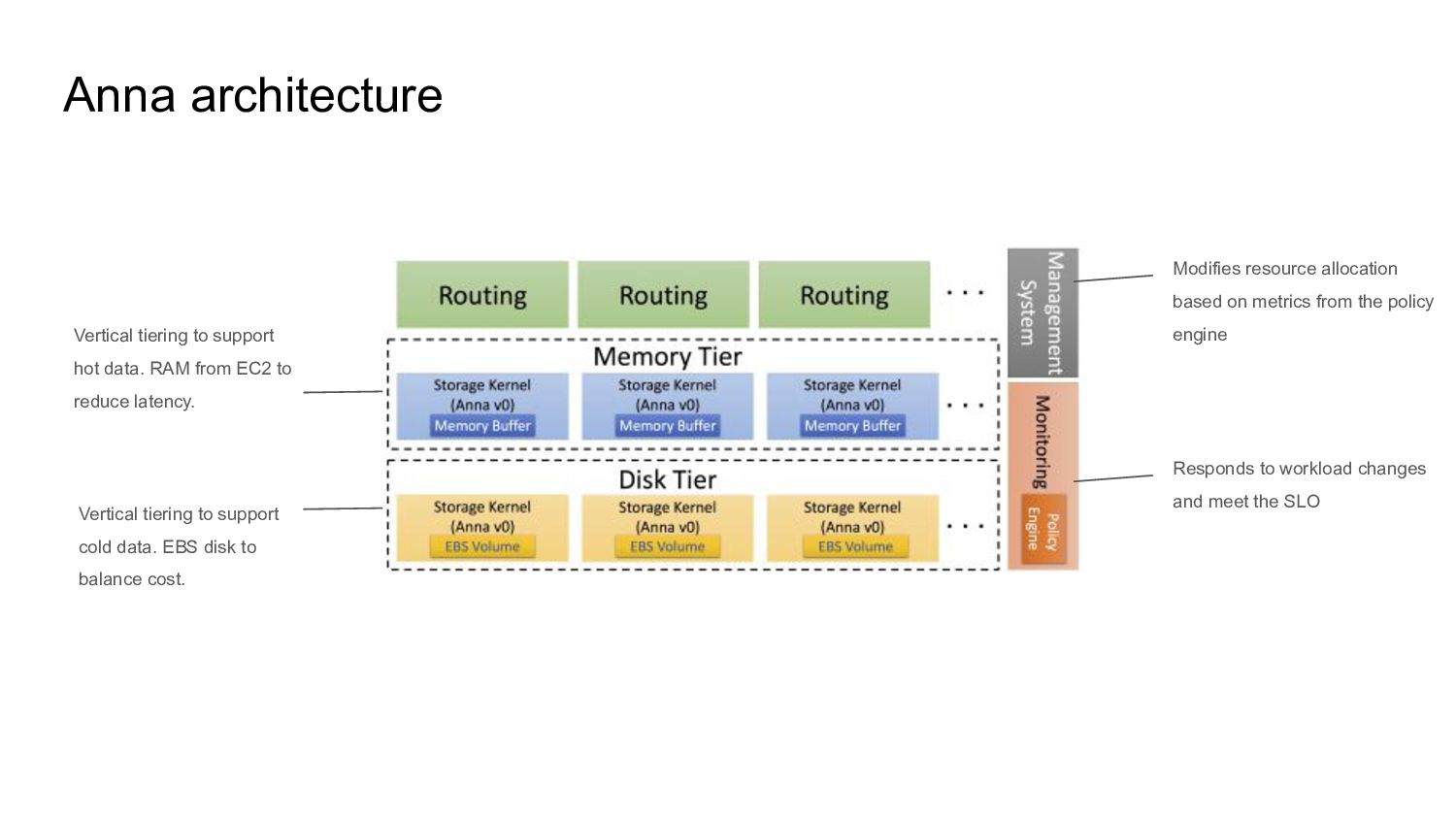{kind=link}
{kind=link}
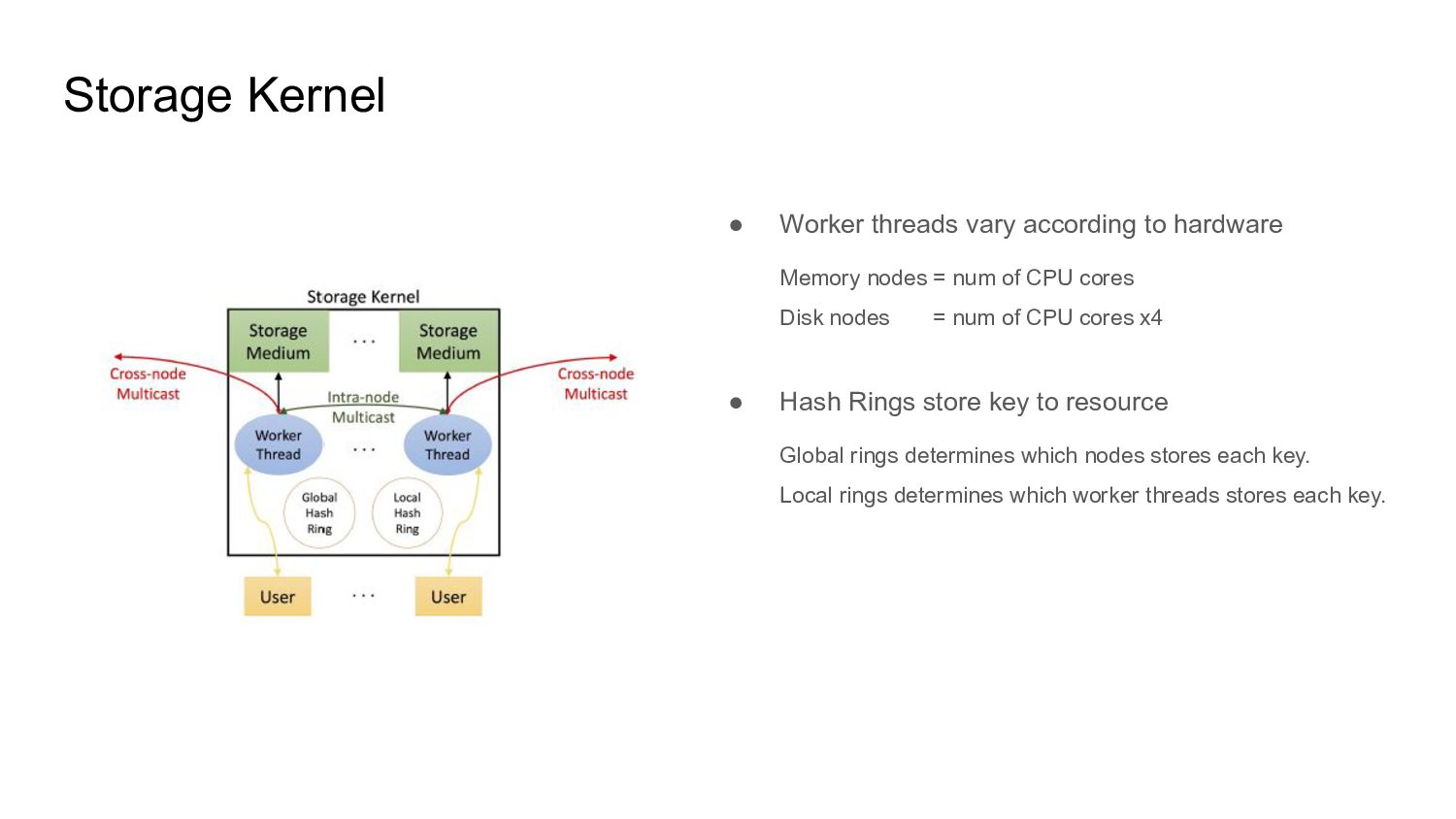{kind=link}
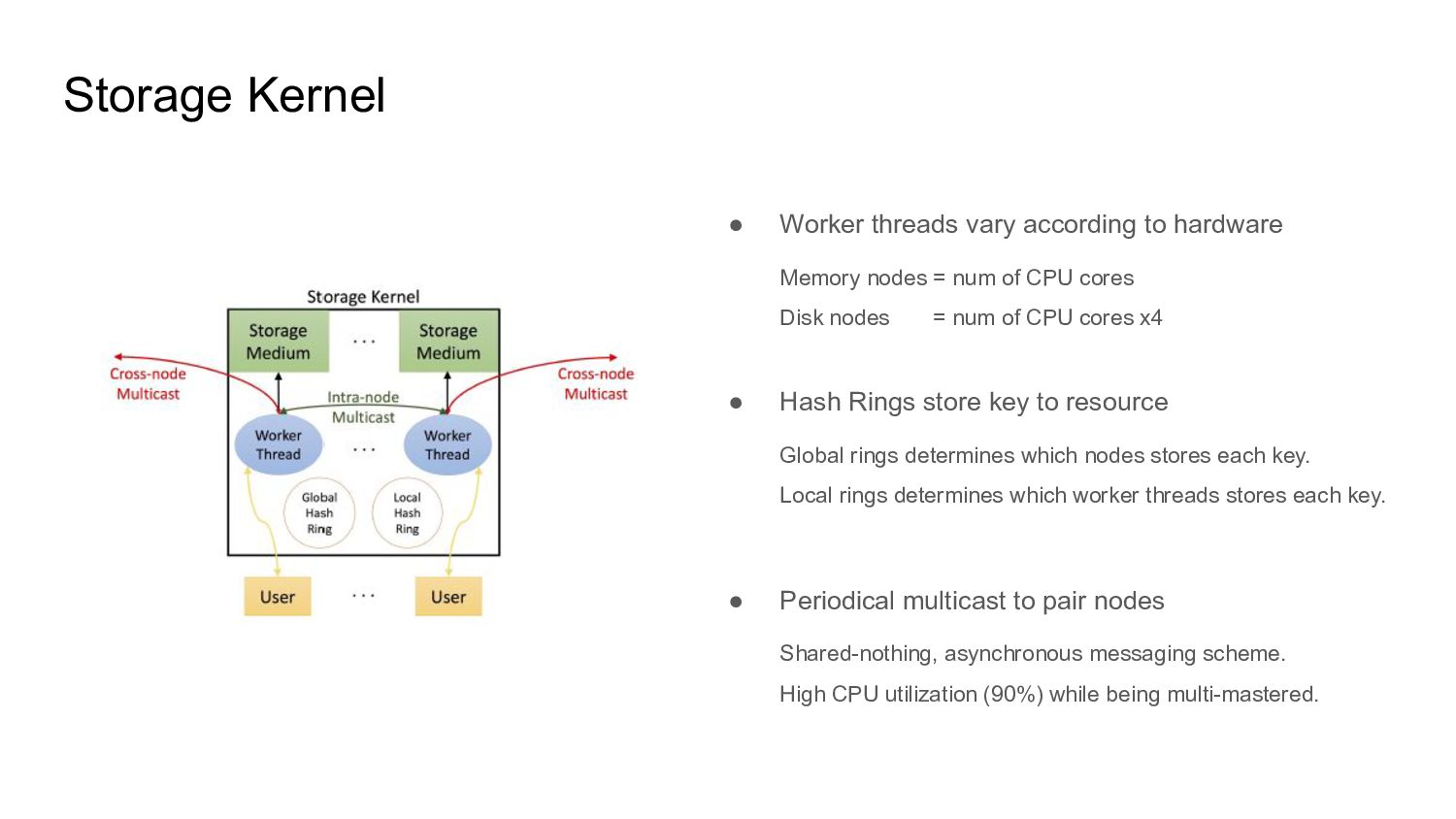{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
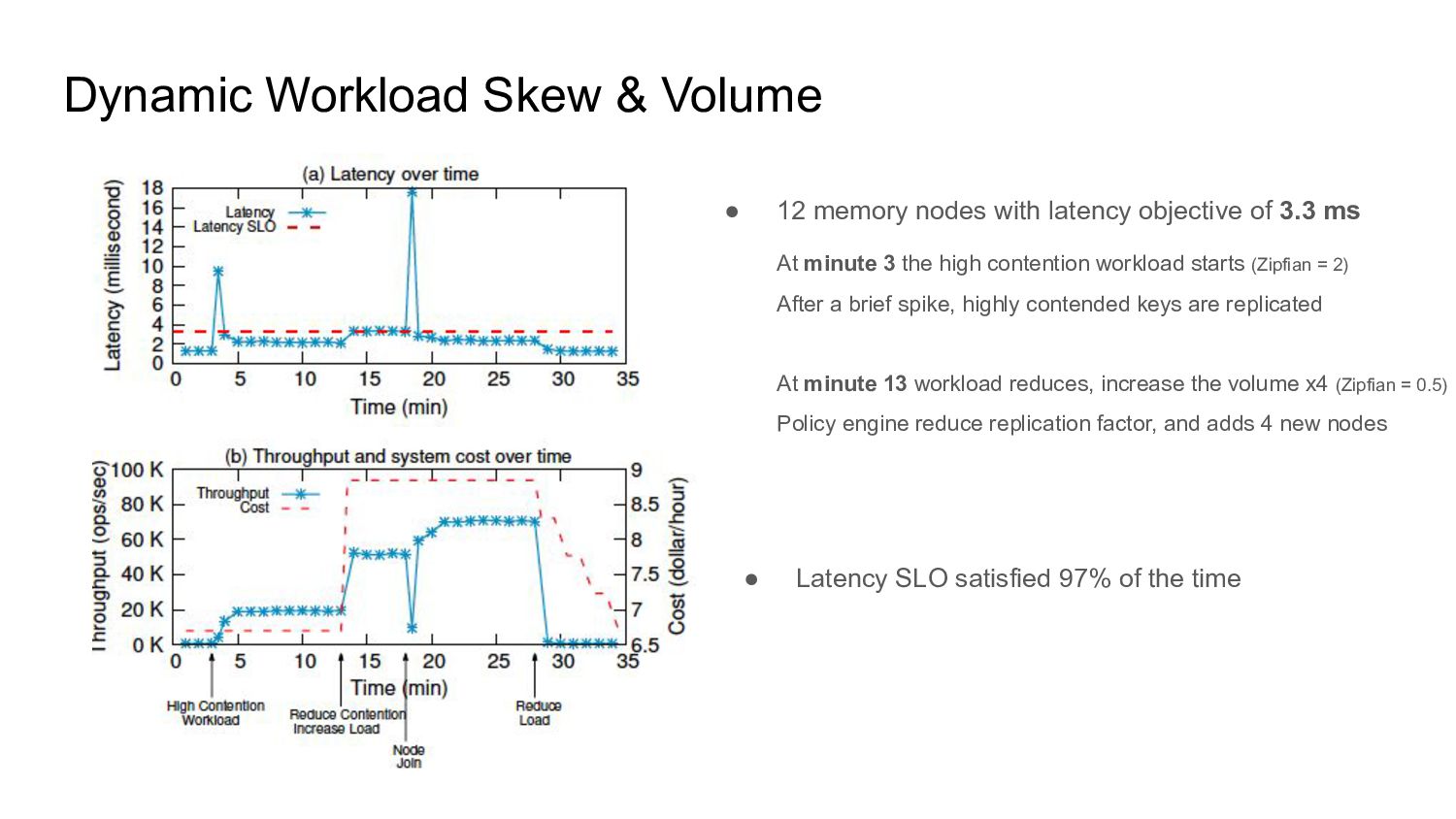{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! https://speakerdeck.com/andreybleme Lucas Bleme [email protected]](https://files.speakerdeck.com/presentations/22760c0580394a049bc6bd28ad2c4bf2/slide_21.jpg){kind=link}