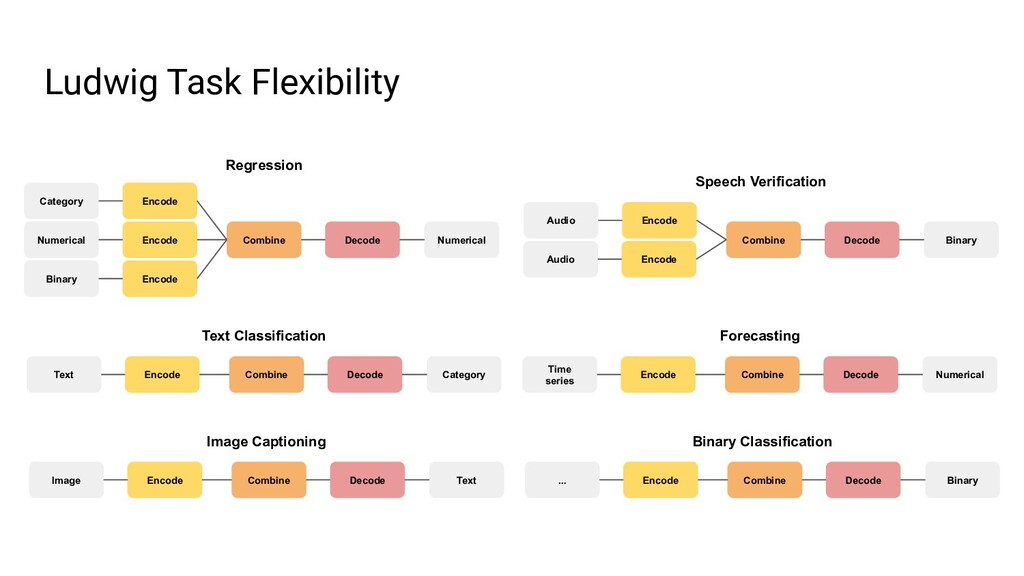
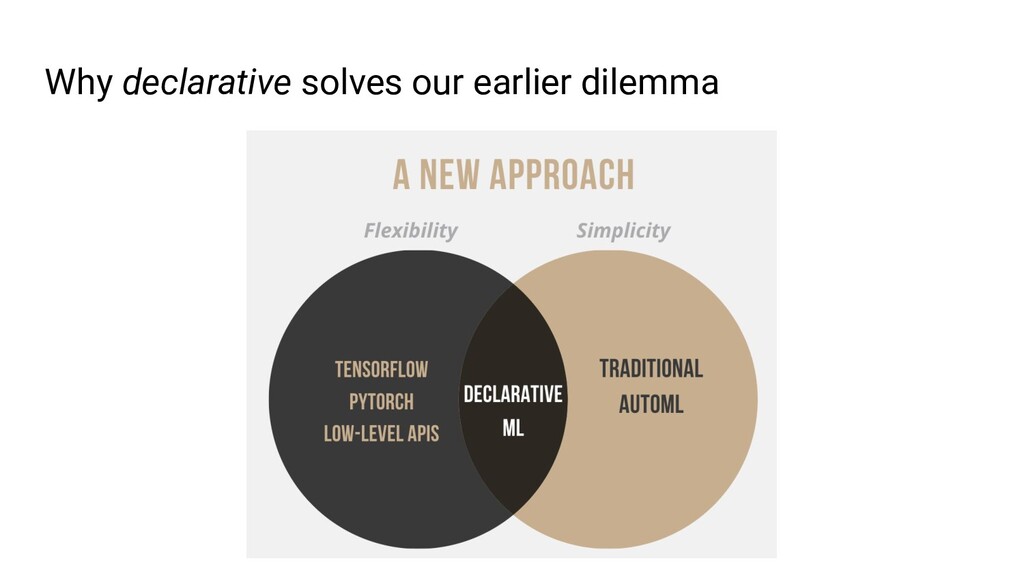
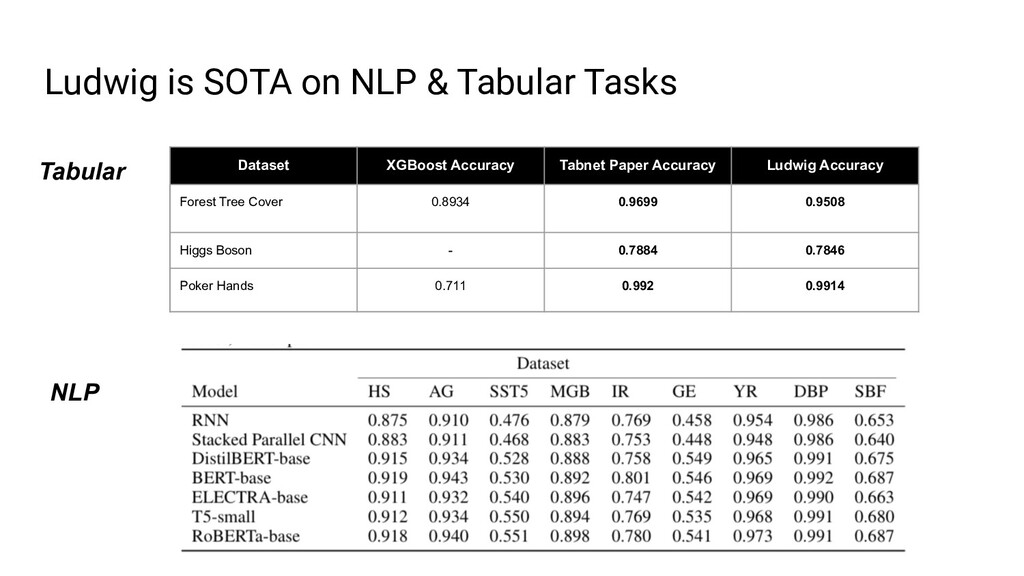
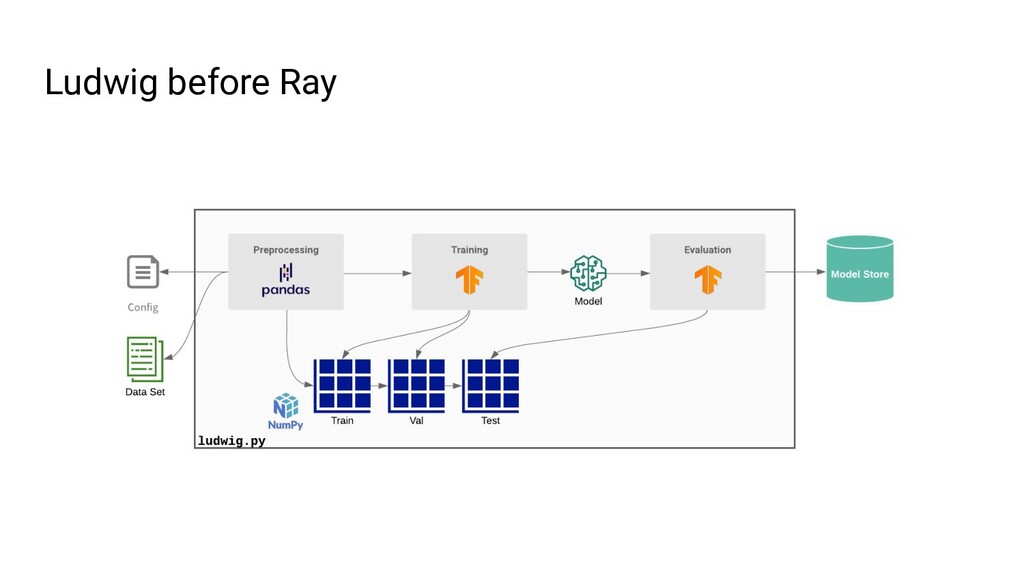
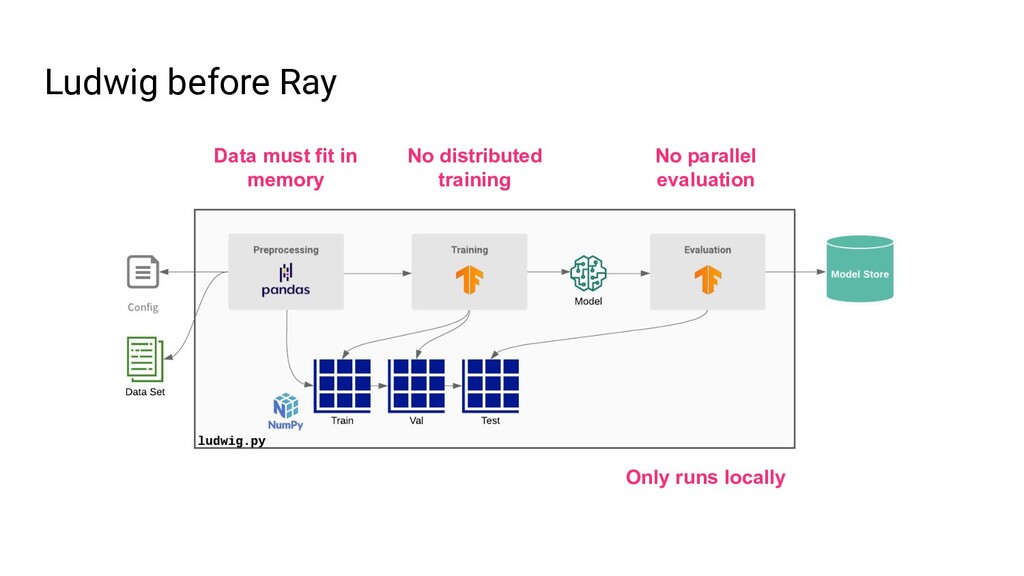
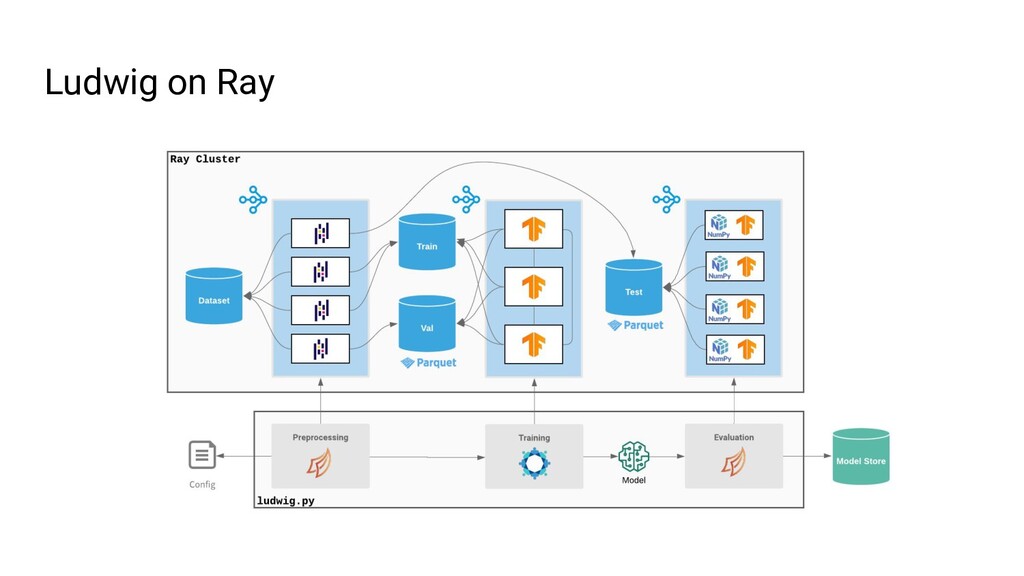
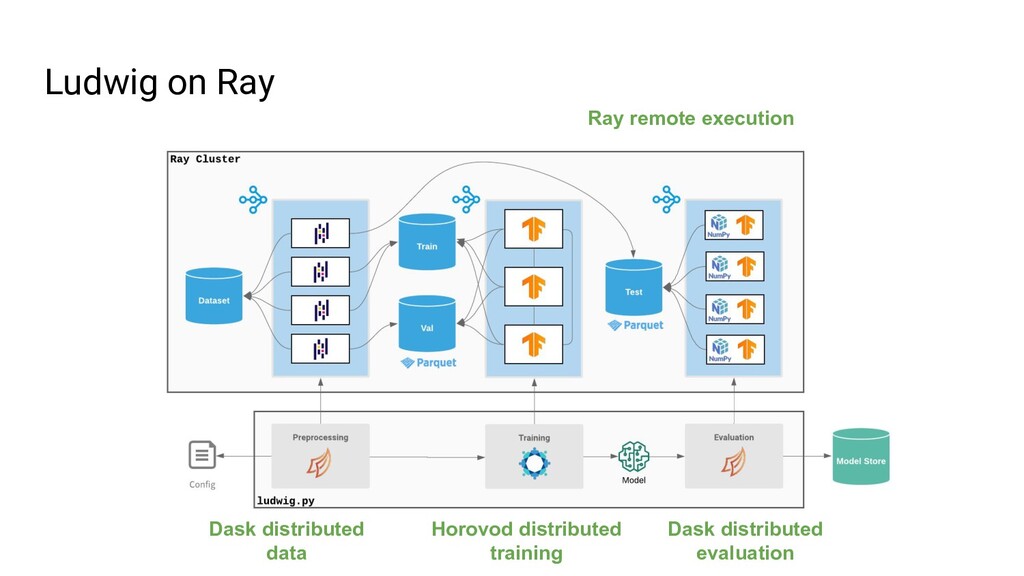
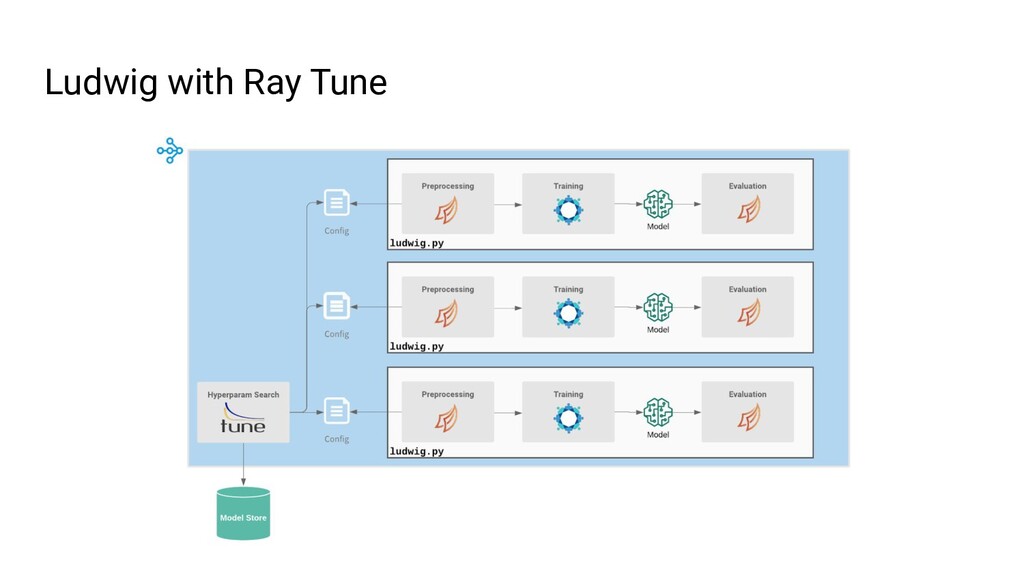
Ludwig is an open source AutoML framework that allows you to train and deploy state-of-the-art deep learning models with no code required. With a single parameter on the command line, the same Ludwig configuration used to train models on your local machine can be scaled to train on massive datasets across hundreds of machines in parallel using Ray. In this talk, we'll show you how Ludwig combines Dask on Ray for distributed out-of-memory data preprocessing, Horovod on Ray for distributed training, and Ray Tune for hyperparameter optimization together into a single end-to-end solution you can run on your existing Ray cluster.
![Travis Addair // [email protected] Making ML at scale simple &](https://files.speakerdeck.com/presentations/522f6b1d8f9849b39b7a2fb616d4871a/slide_0.jpg){kind=link}
{kind=link}
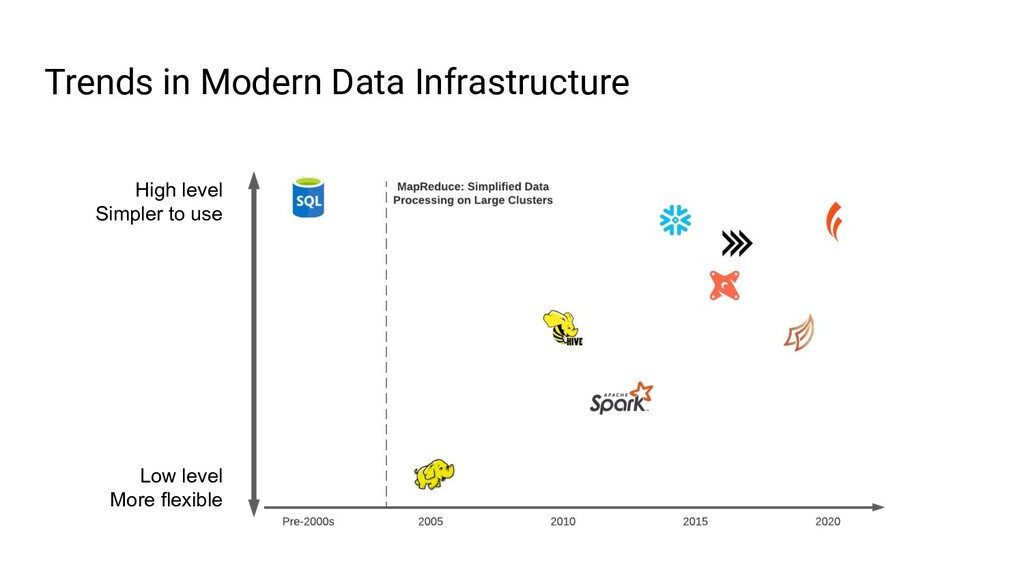{kind=link}
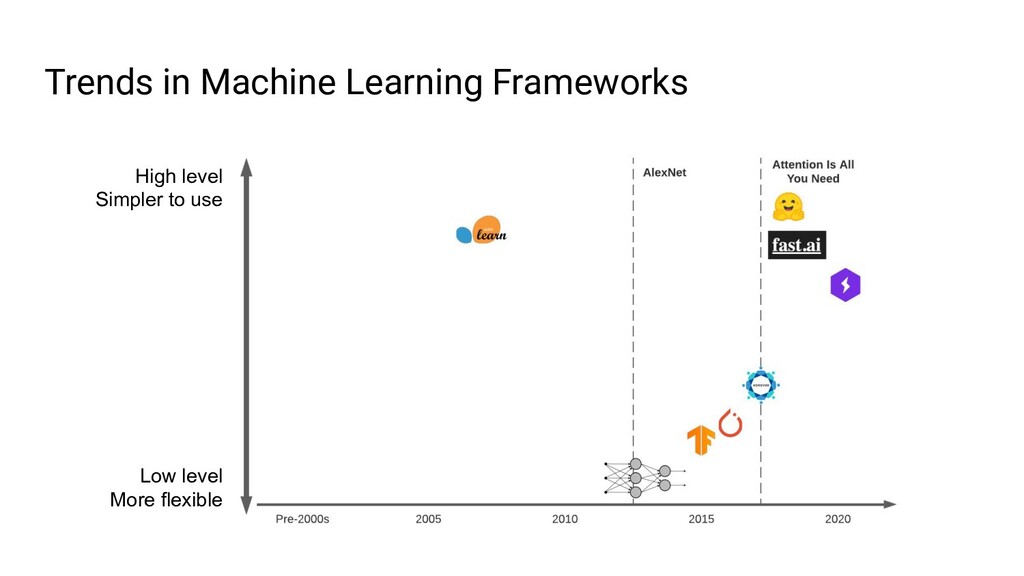{kind=link}
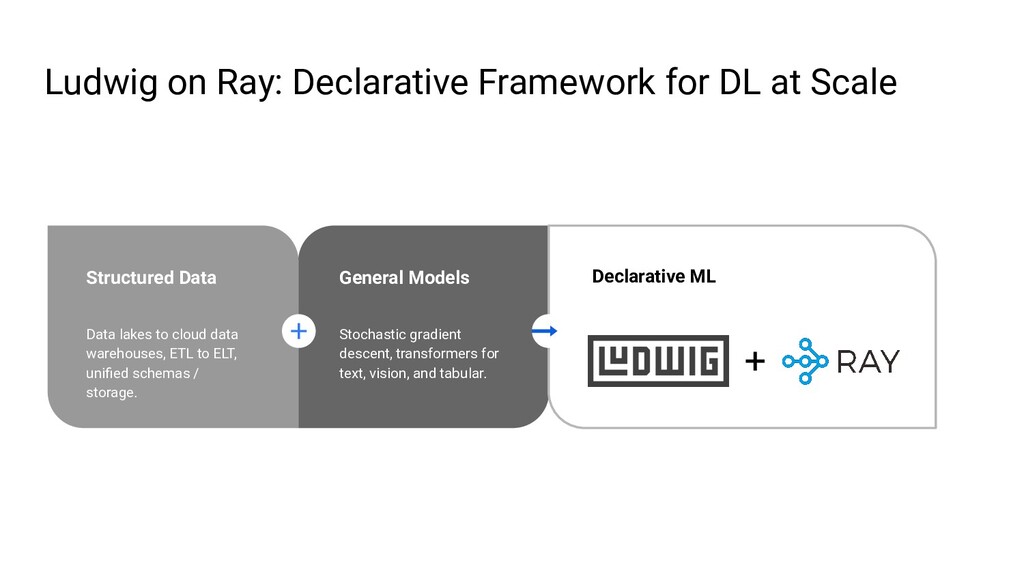{kind=link}
{kind=link}
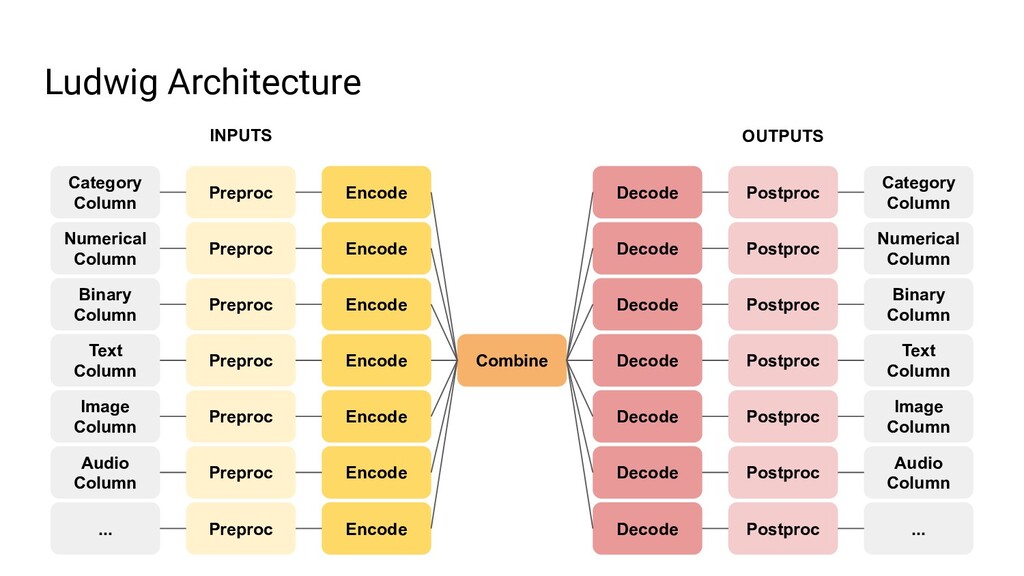{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}