This talk is about JAX, a system for high-performance machine learning research and numerical computing. JAX offers the familiarity of Python+NumPy together with hardware acceleration. JAX combines these features with user-wielded function transformations, including automatic differentiation, automatic vectorized batching, end-to-end compilation (via XLA), parallelizing over multiple accelerators, and more. Composing these transformations is the key to JAX's power and simplicity. It’s used by researchers for a wide range of advanced applications, from large-scale neural net training, to probabilistic programming, to scientific applications in physics and biology.
![JAX: accelerating ML with composable transformations Matthew Johnson ([email protected]) on](https://files.speakerdeck.com/presentations/fea34aac8c26481480f3424cb9d8498e/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
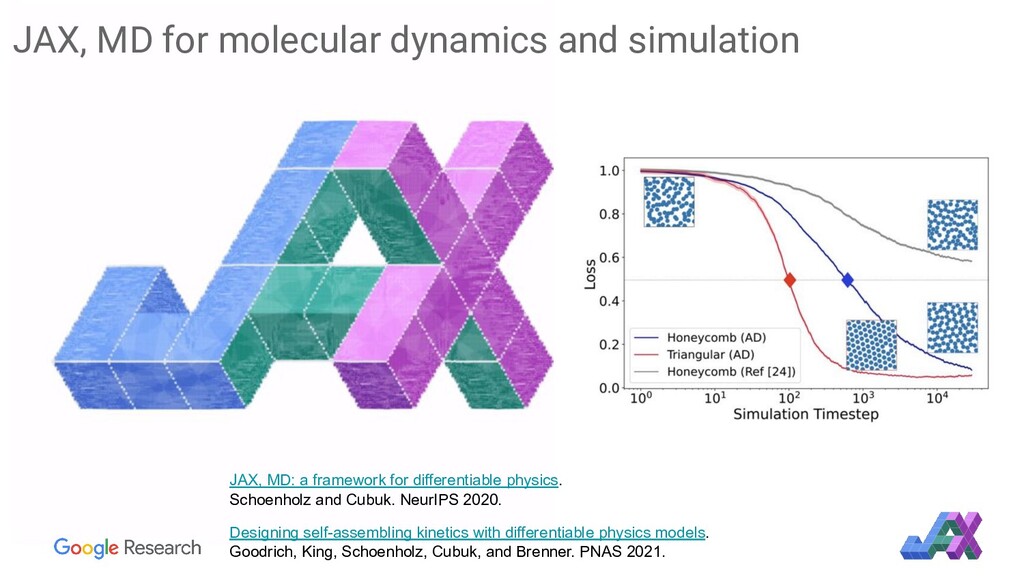{kind=link}
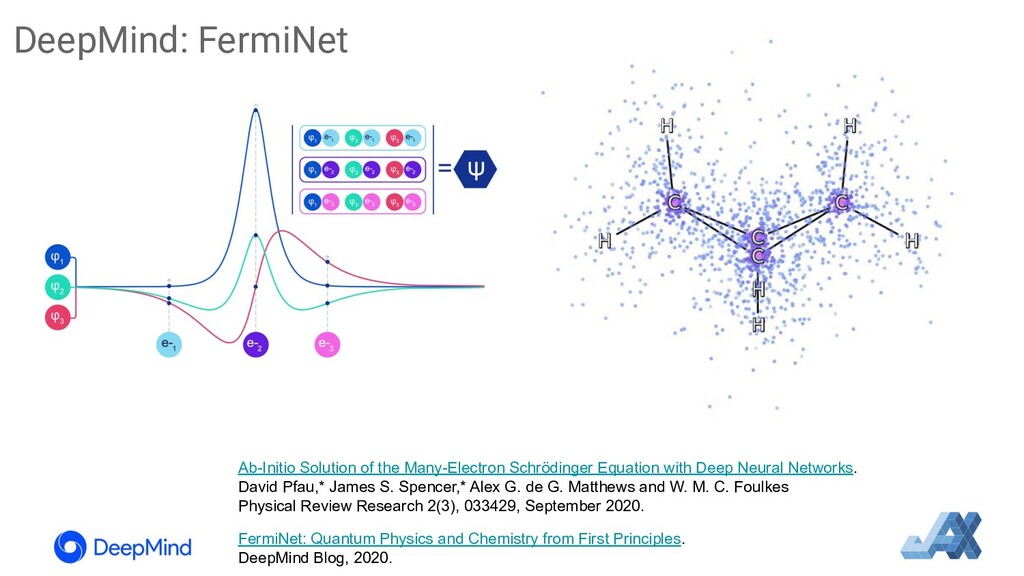{kind=link}
{kind=link}
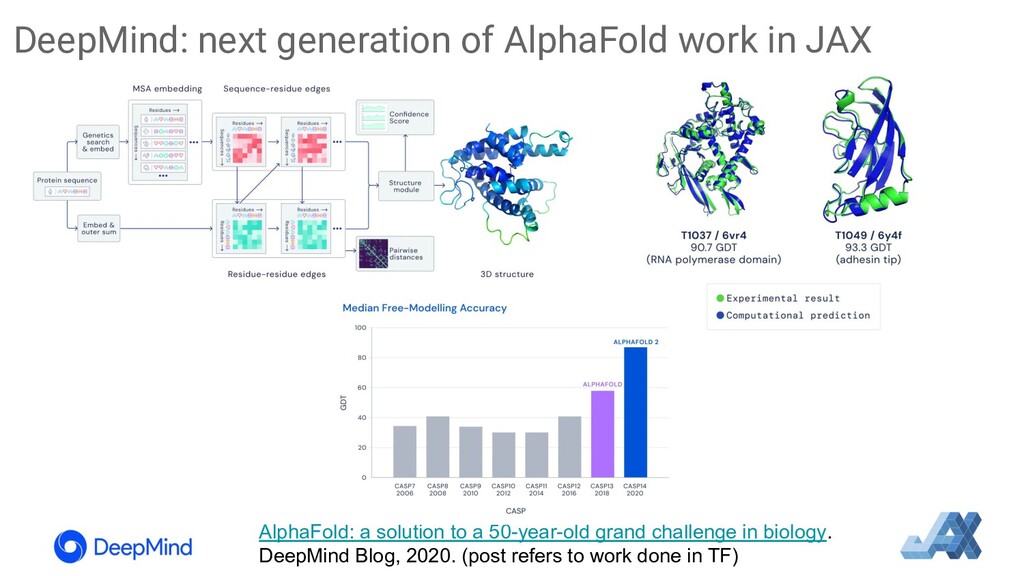{kind=link}
{kind=link}
{kind=link}
{kind=link}
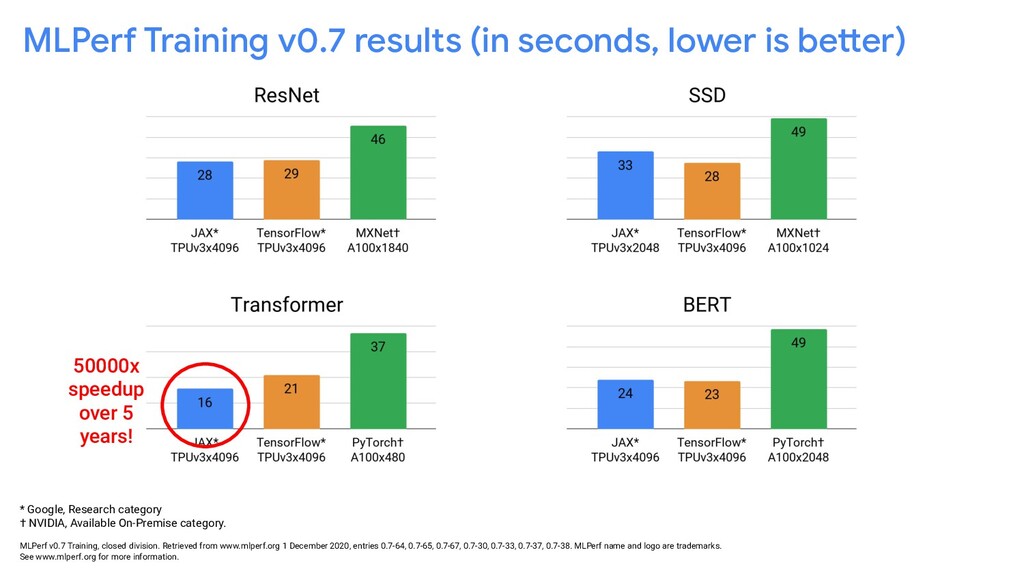{kind=link}
{kind=link}
{kind=link}
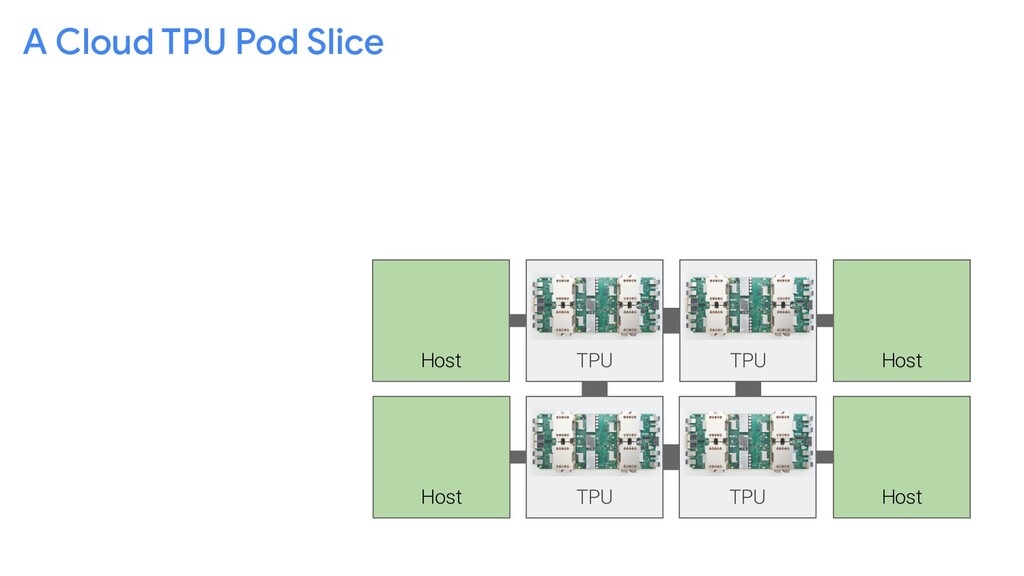{kind=link}
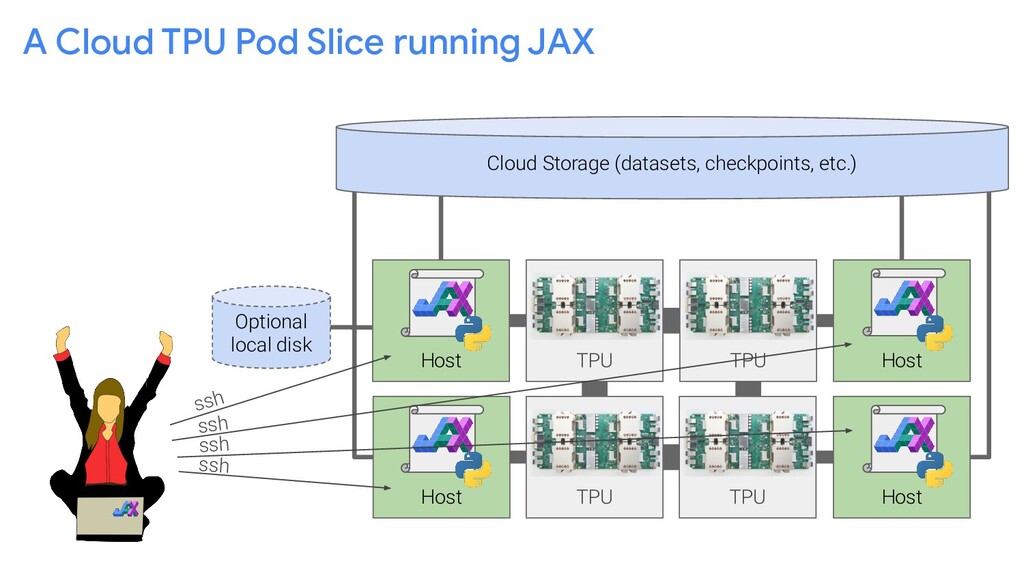{kind=link}
{kind=link}
![JAX: accelerating ML with composable transformations Matthew Johnson ([email protected]) on](https://files.speakerdeck.com/presentations/fea34aac8c26481480f3424cb9d8498e/slide_22.jpg){kind=link}
{kind=link}