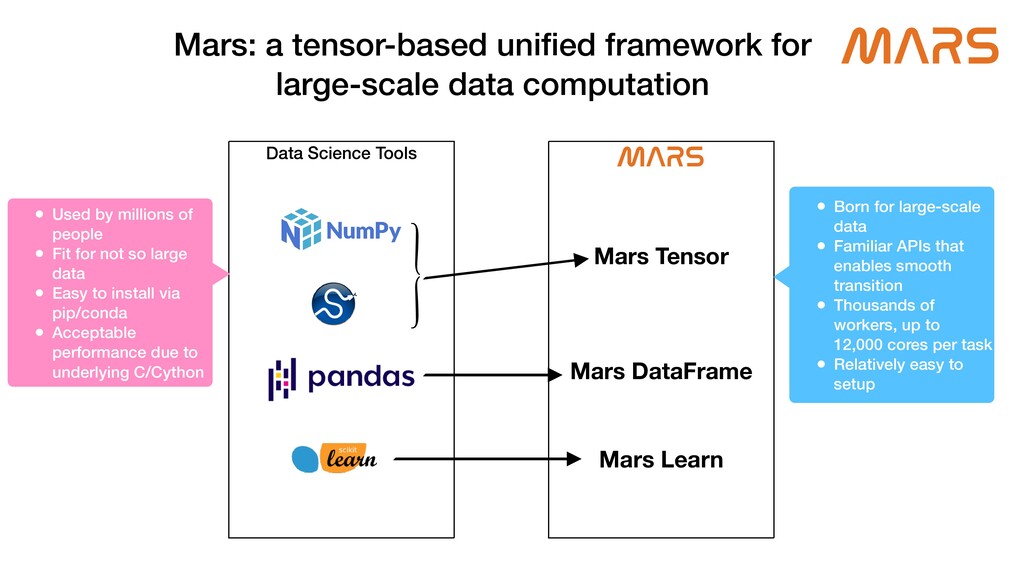
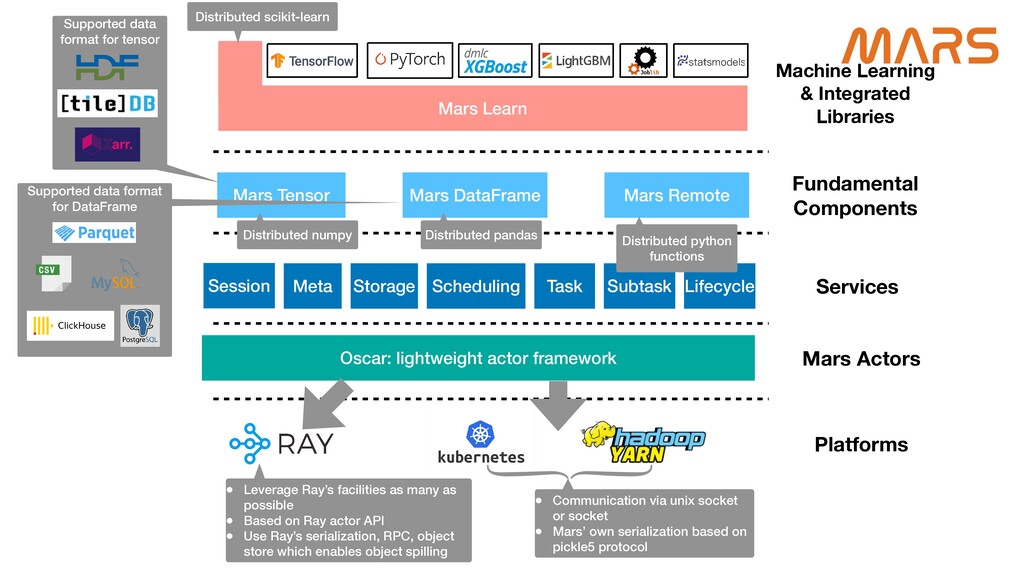
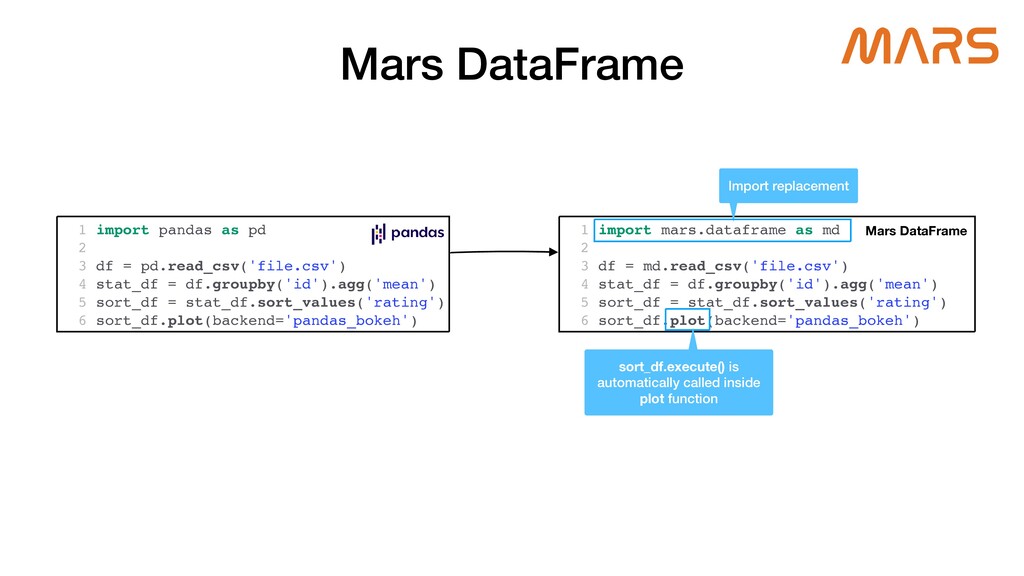
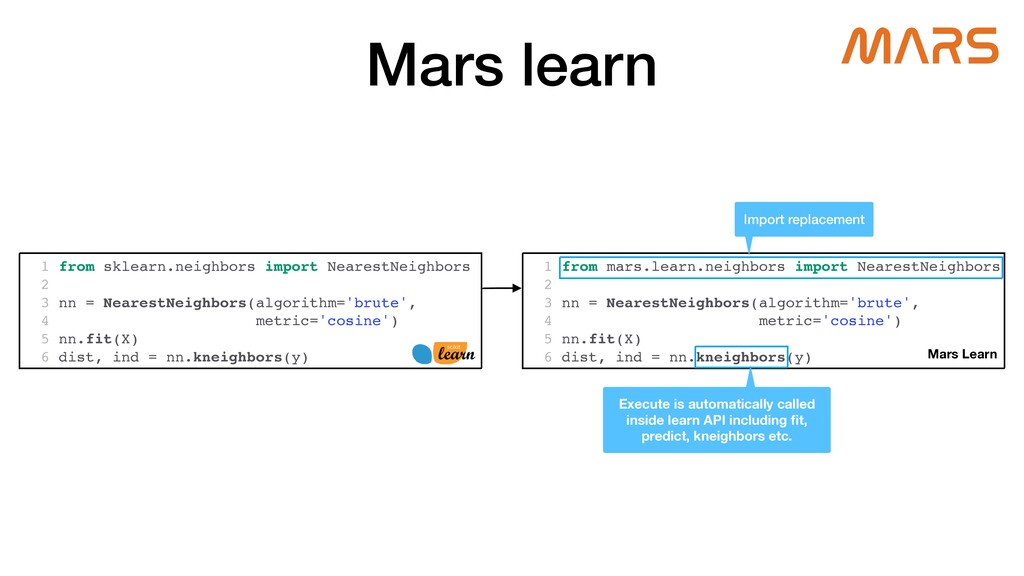
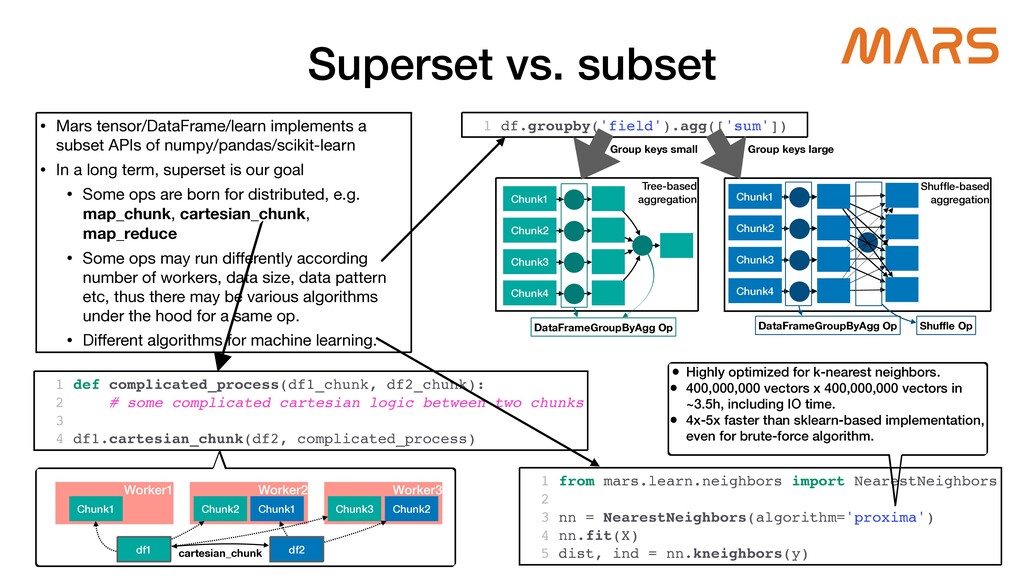
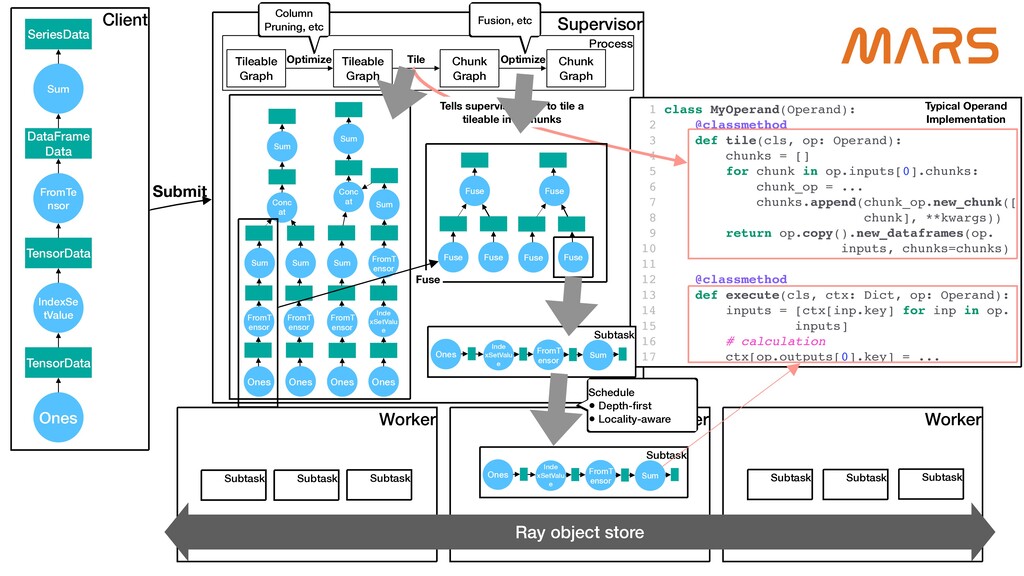
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and Python functions. Ray, which provides a general purpose task and actor API, is extremely expressive, and guarantees high performance for distributed Python applications. Mars-on-Ray takes advantage of both Mars and Ray; Mars provides familiar data science APIs, and highly optimized, locality-aware, fine-grained task scheduling, and now Mars-on-Ray allows Mars workloads to run on Ray with the same scheduling strategy, but has an extensive ability to scale on Ray clusters.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Lazy evaluation vs. eager vs ?? In [1]: import mars.tensor](https://files.speakerdeck.com/presentations/91789a83a0f14625bf32f14d5ddd4ba2/slide_10.jpg){kind=link}
![Client How Mars tensor/DataFrame scales In [1]: import mars.tensor as](https://files.speakerdeck.com/presentations/91789a83a0f14625bf32f14d5ddd4ba2/slide_11.jpg){kind=link}
{kind=link}
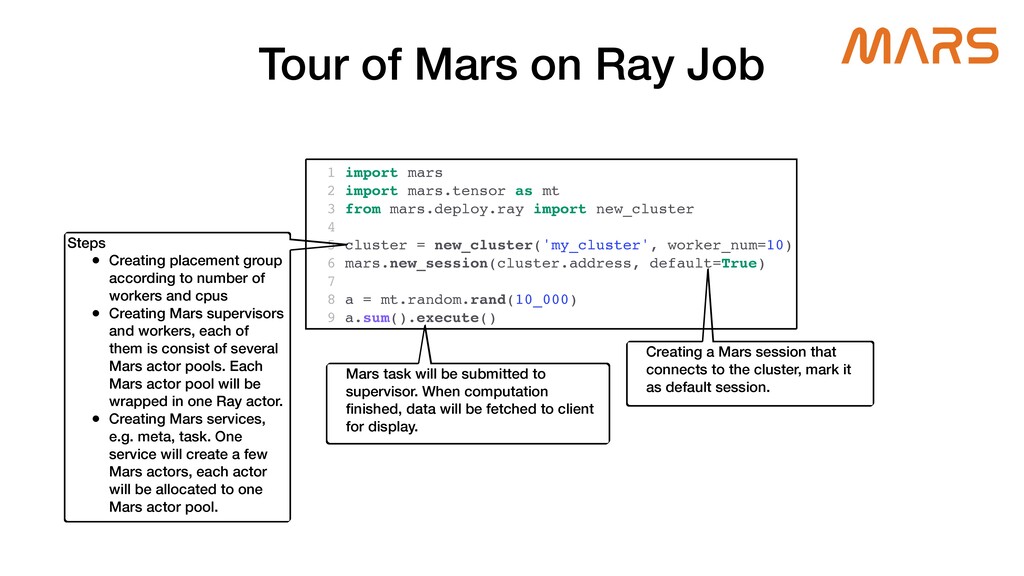{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}