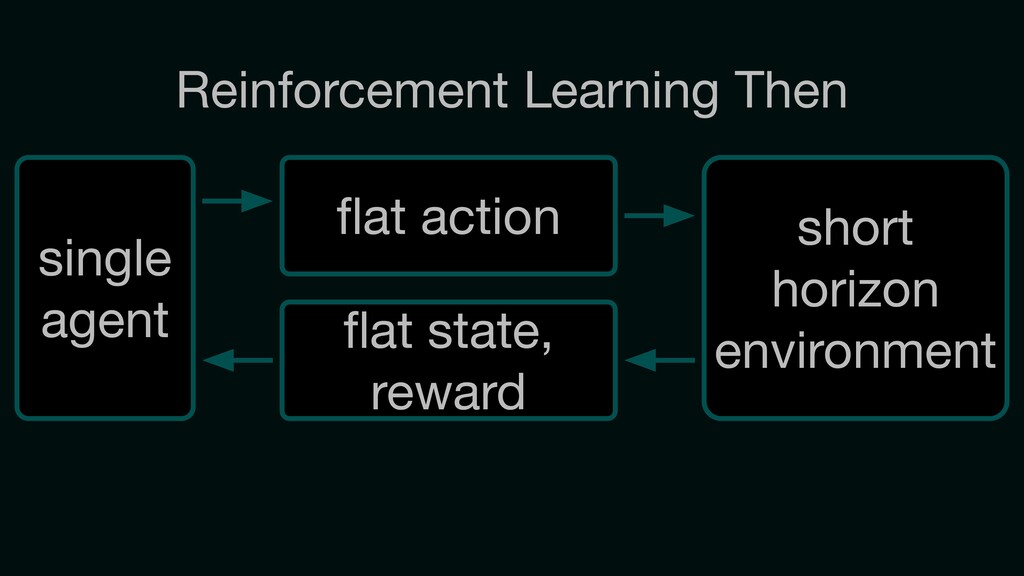
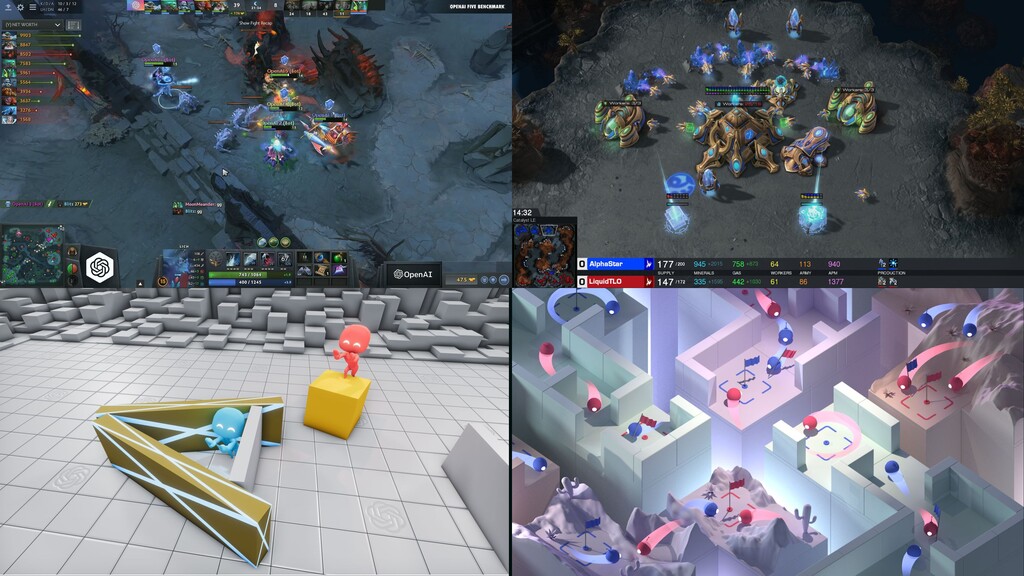
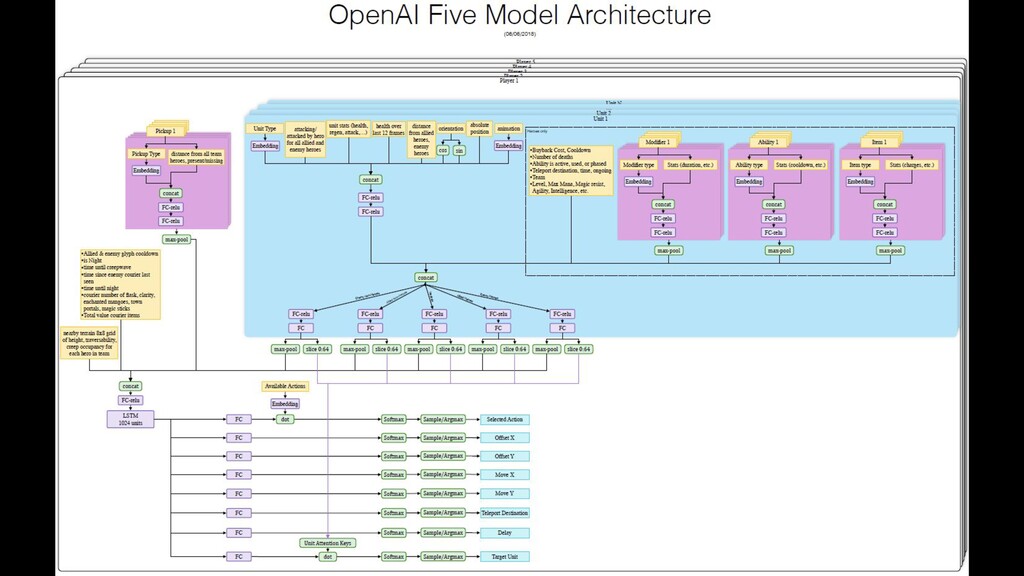
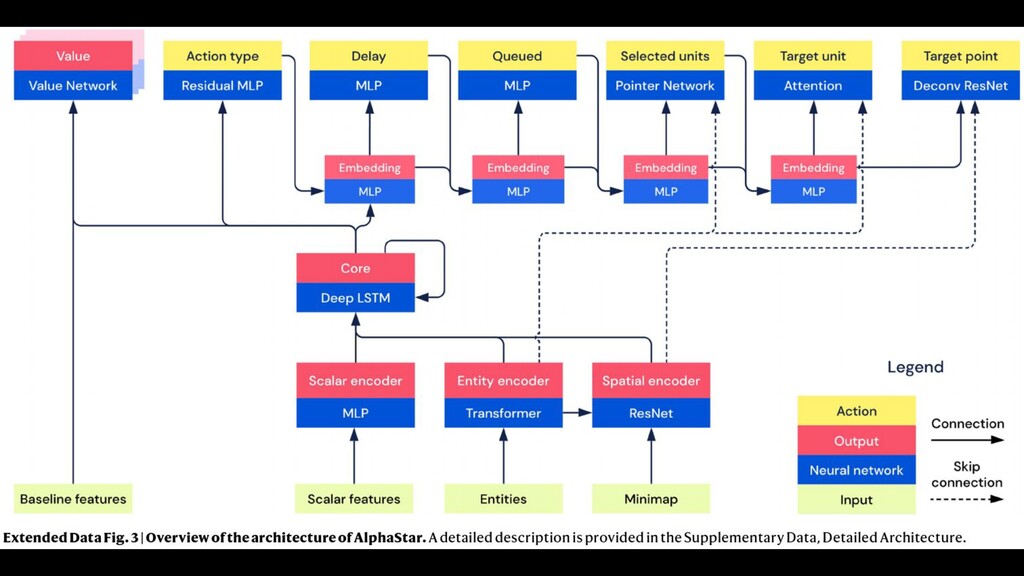
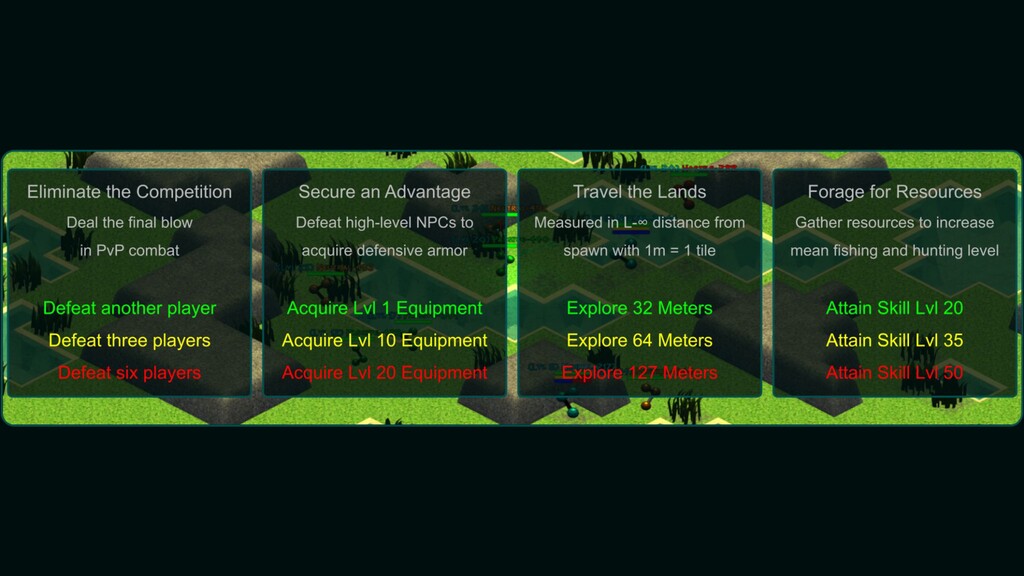
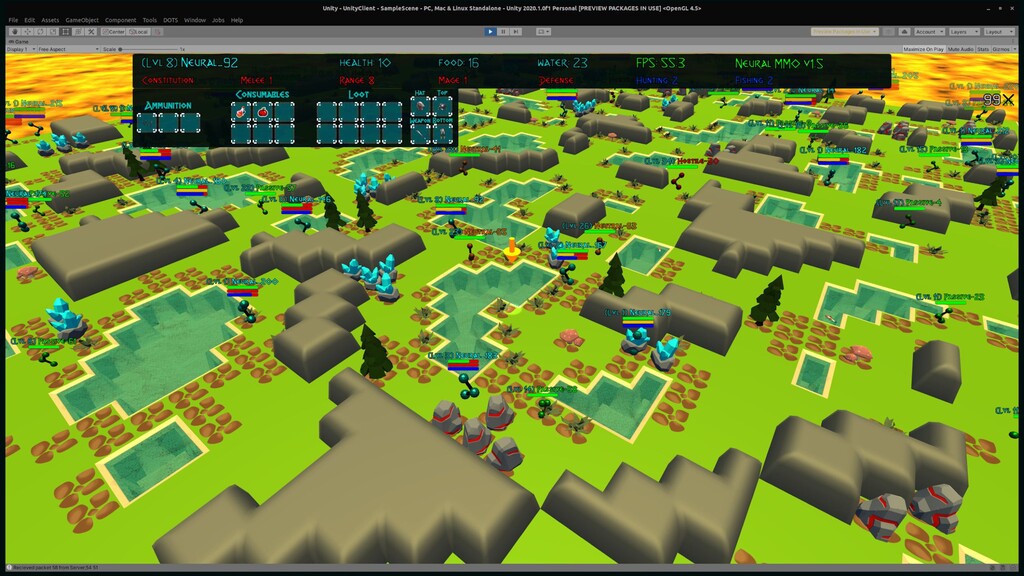
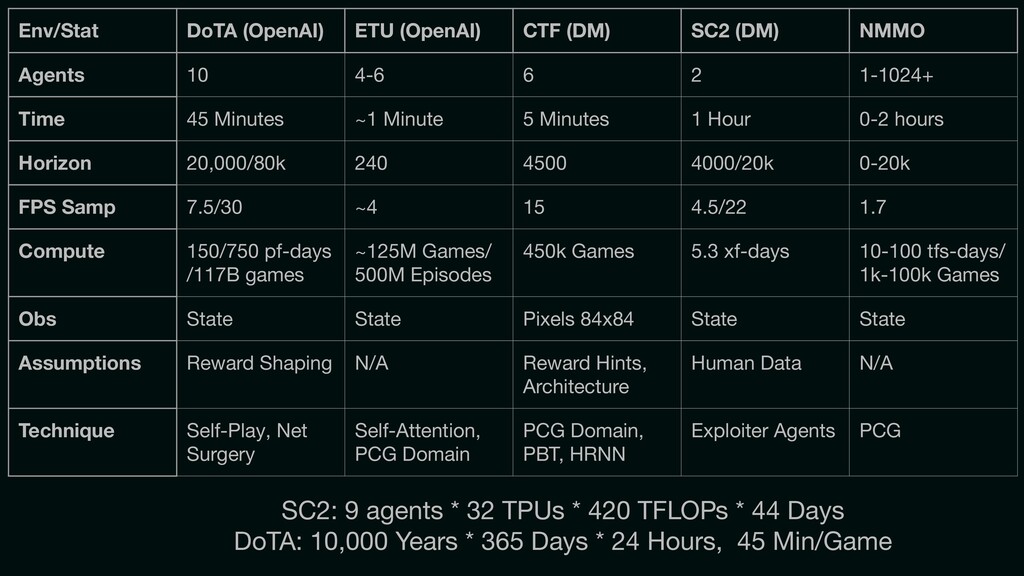
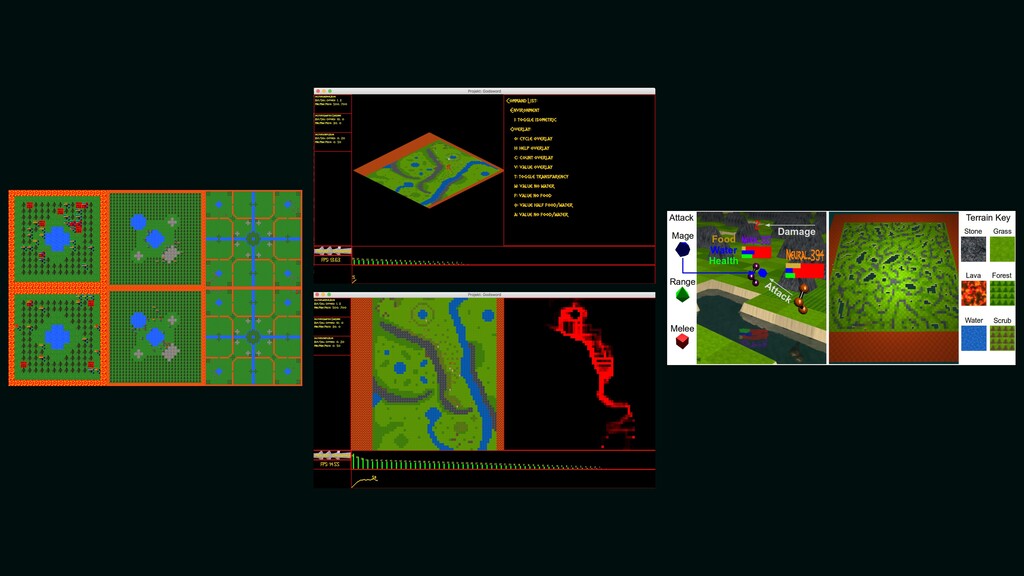
Reinforcement learning has solved Go, DoTA, Starcraft -- some of the hardest, most strategy-intensive games for humans. Nonetheless, these games are missing fundamental aspects of real-world intelligence: large agent populations, ad-hoc collaboration vs. competition, and extremely long time horizons, among others. Neural MMO is an environment modeled off of Massively Multiplayer Online games -- a genre supporting hundreds to thousands of concurrent players, realistic social incentives, and persistent play. I will discuss the current state of the project, key enabling features of Ray + RLlib, and infrastructure required for continued expansion.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
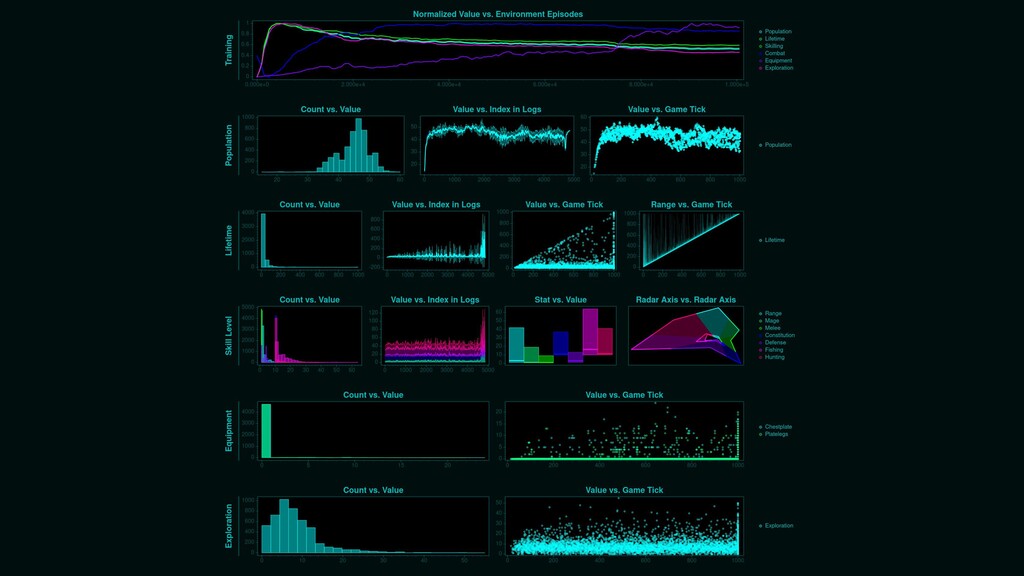{kind=link}
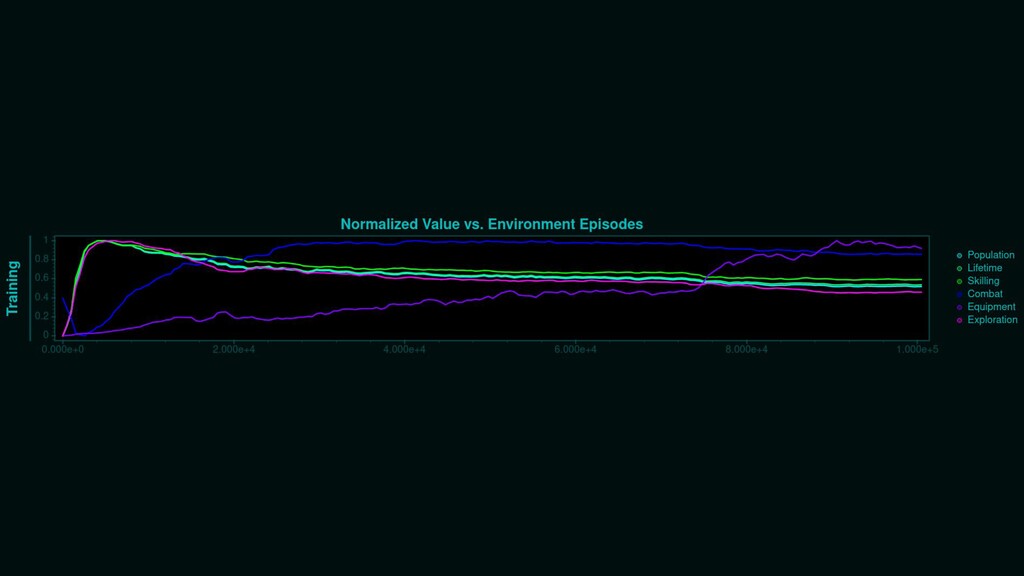{kind=link}
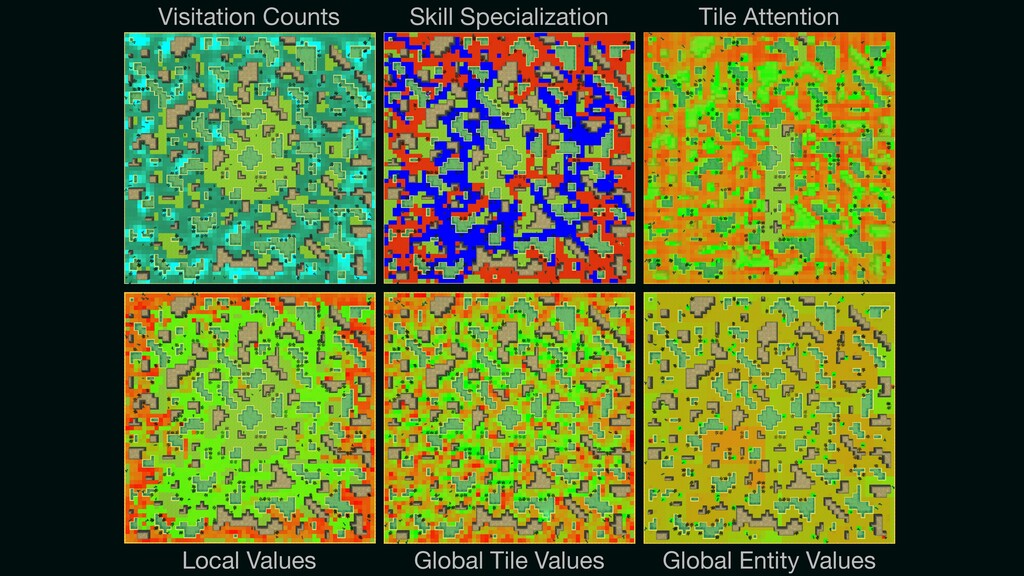{kind=link}
{kind=link}
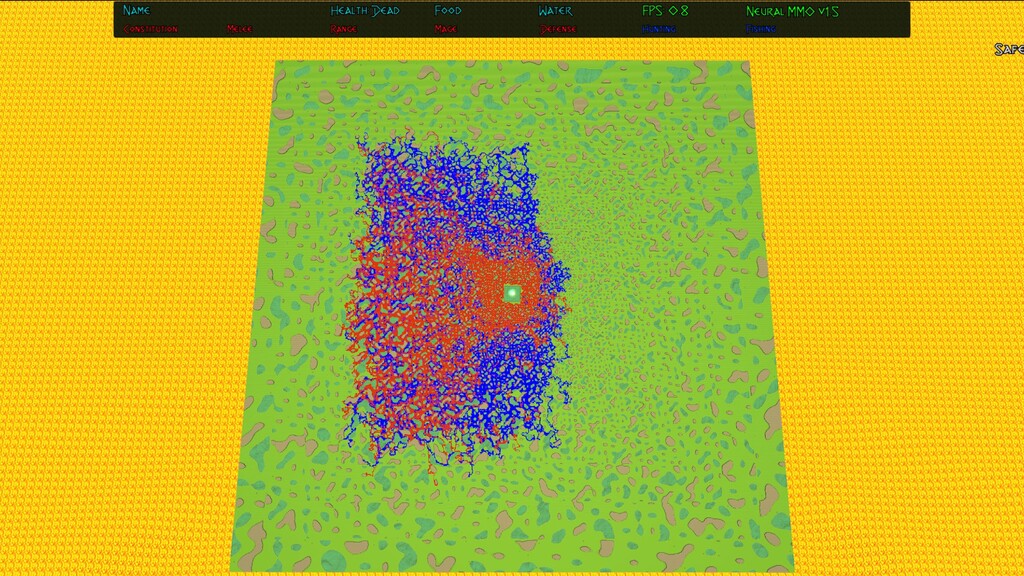{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}