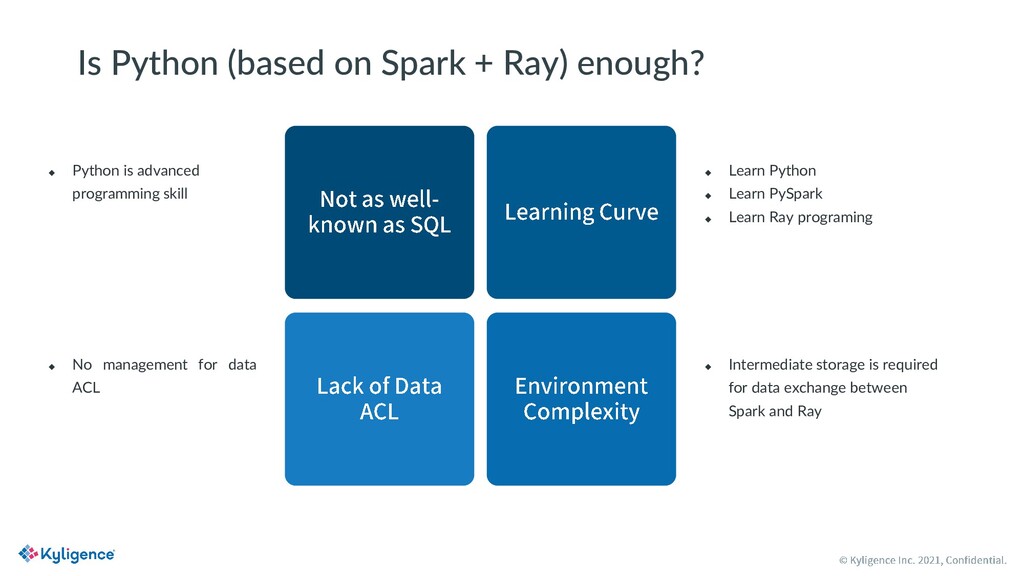
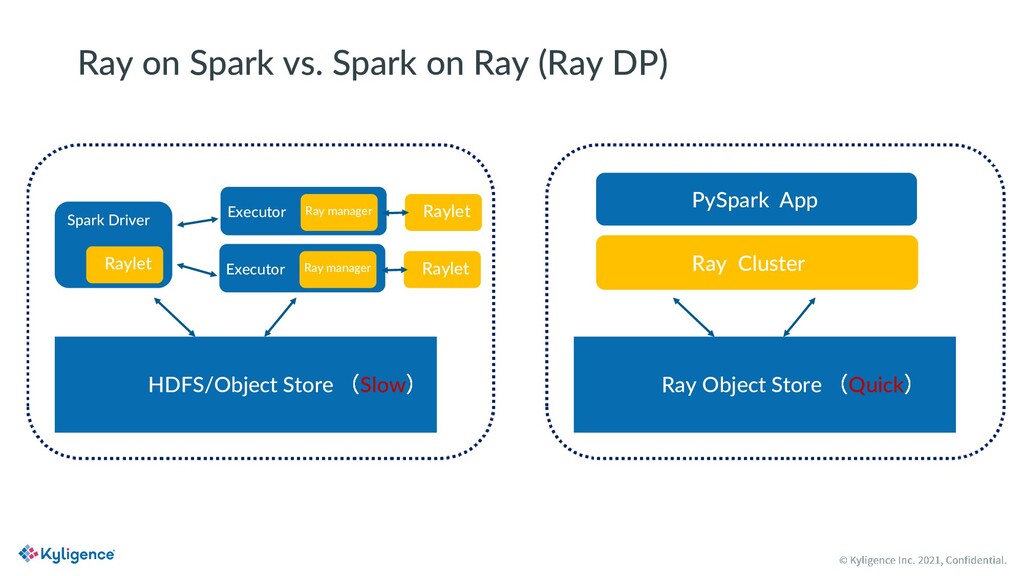
Most organizations prefer Python for AI and machine learning, but the JVM-based distributed system is also popular for big data processing. Many Ray users are willing to incorporate parallel data processing directly into Python applications but suffer from the complexity and low efficiency of existing solutions.
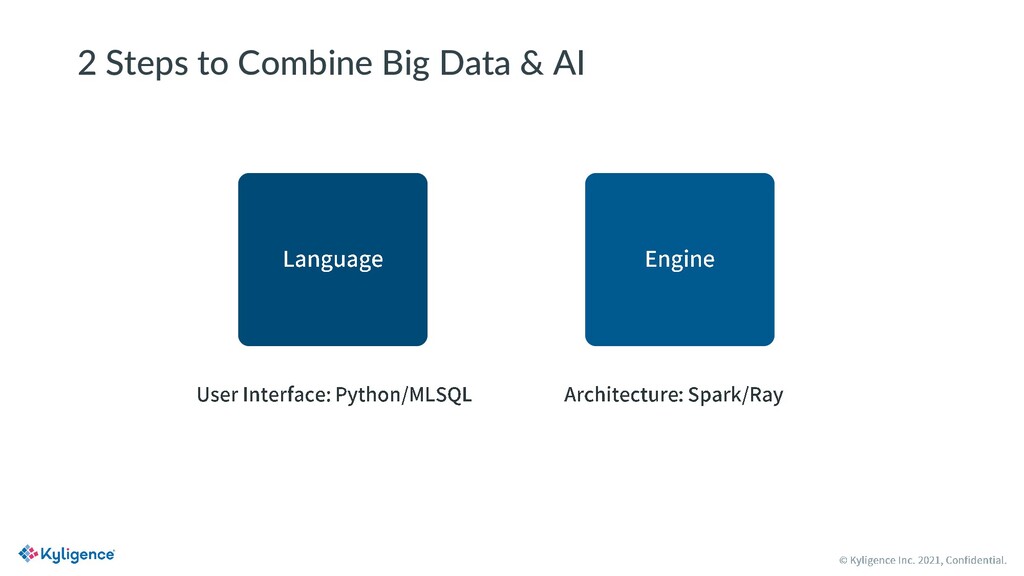
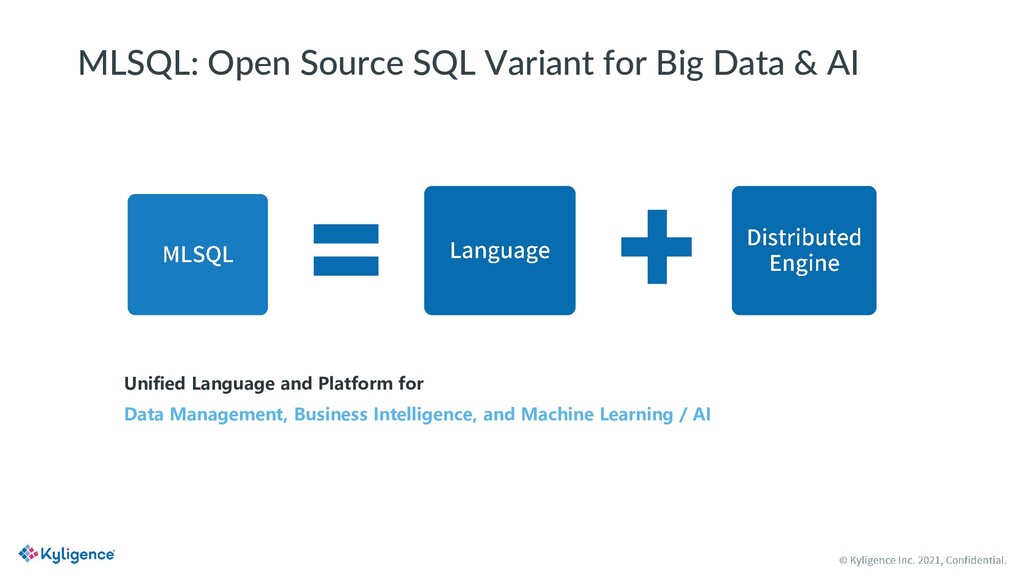
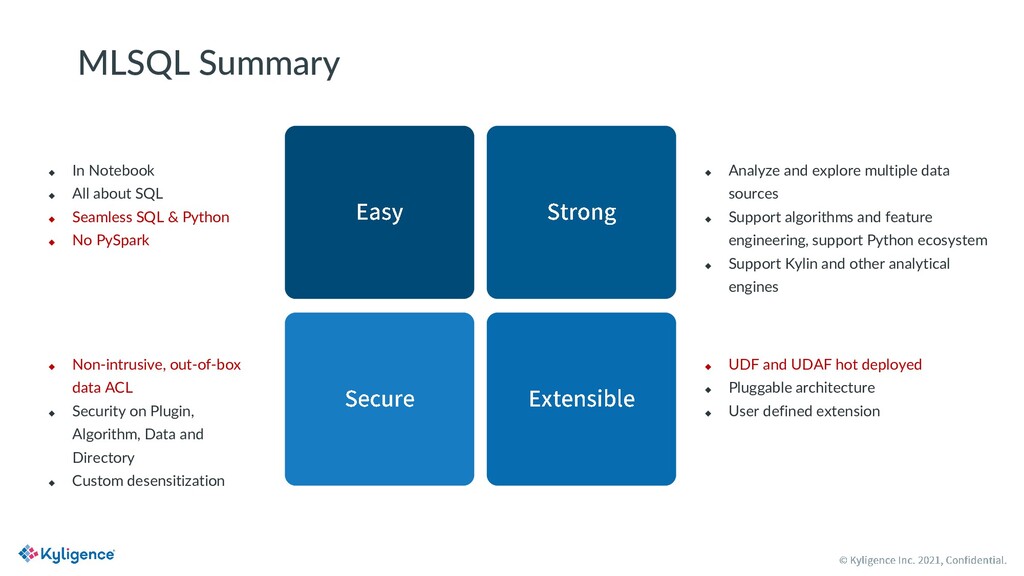
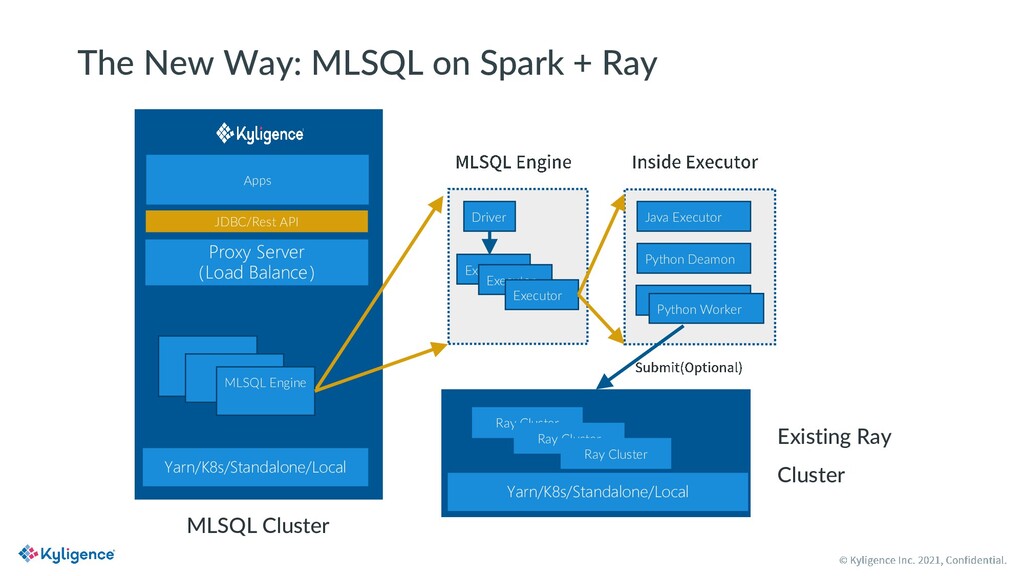
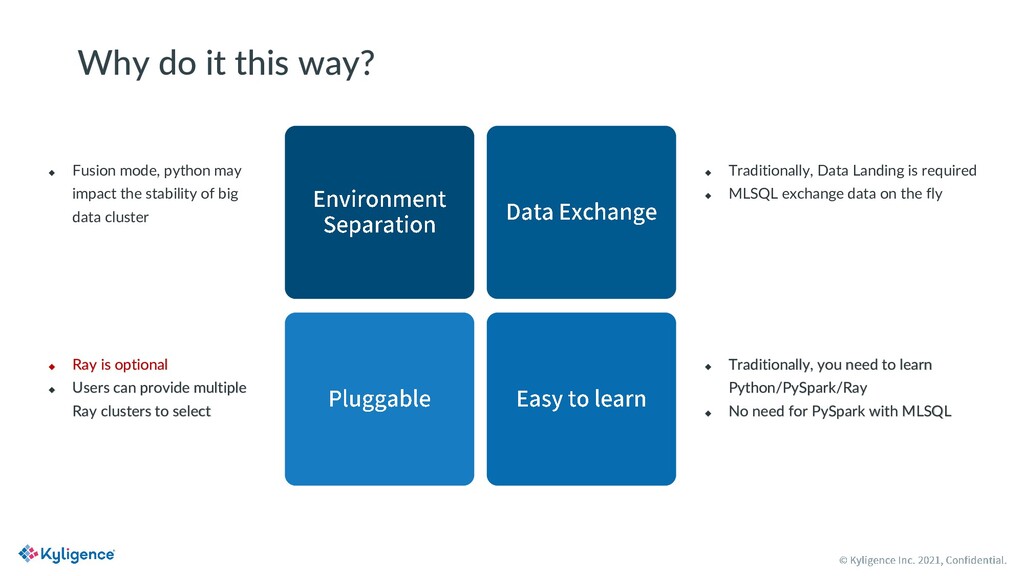
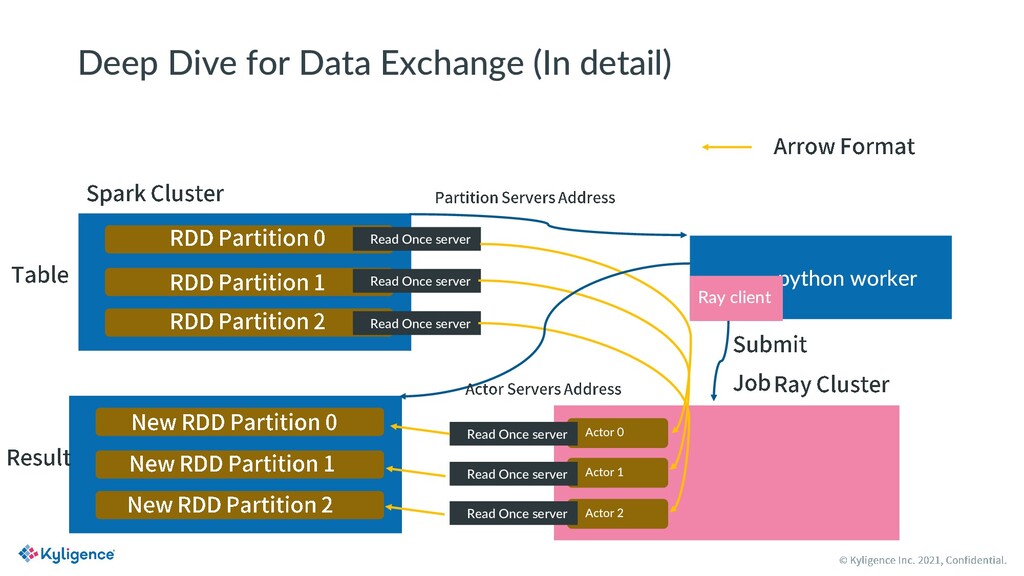
MLSQL is a new SQL variant designed for big data and AI scenarios. It is open source with Apache License V2.0. With MLSQL, users can perform self-service machine learning and AI tasks on large scale datasets on top of Ray and Spark, without caring about the different programming paradigms between PySpark and Ray, simply by writing a few lines of SQL statements. MLSQL optimized its distributed engine by combining Spark and Ray and improving the underlying data exchanging efficiency between them. Also, users can run the same piece of code on any Ray cluster of their choice.
In this presentation, Dong Li will outline the basics of MLSQL with a live demo and a deep-dive into how MLSQL implements Spark+Ray on the engine side to build an efficient and single substrate for big data and AI.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact Us Kyligence Inc ◆ http://kyligence.io ◆ [email protected] ◆ Twitter:](https://files.speakerdeck.com/presentations/6479149252ad40e7921d99bca31ded31/slide_14.jpg){kind=link}
{kind=link}