to calculate fines • We also need to look at the whole history of the state to fully understand the fines • Customer also wants business analytics based on history
override val gebyrId: GebyrId, val principalRole: ActionRole, val klagesakId: KlagesakId, val reference: Long, val body: String, val attachments: List<AttachmentReference>, val email: String?, override val commandId: UUID = UUID.randomUUID() ) : • An intent to do something • Not guaranteed to succeed
contained inside this boundary, does not care about what the rest of the world does) • The “root” of your data • Example: Your vehicle. All the fines related to your vehicle are contained inside this boundary and do not interact with fines on other vehicles.
translate to commands and GraphQL queries translate to queries • Authentication • Flexibility: multiple views share same endpoint while customising the data received
translate to commands and GraphQL queries translate to queries • Authentication • Flexibility: multiple views share same endpoint while customising the data received • Direct mapping from domain objects to API responses
existing data • Easy to formalise write rules for your data without relying on database triggers (and therefore not worrying about consistency across different database tables)
existing data • Easy to formalise write rules for your data without relying on database triggers (and therefore not worrying about consistency across different database tables) • Major performance gains possible
existing data • Easy to formalise write rules for your data without relying on database triggers (and therefore not worrying about consistency across different database tables) • Major performance gains possible • Not a single table join (okay, just a few here and there)
existing data • Easy to formalise write rules for your data without relying on database triggers (and therefore not worrying about consistency across different database tables) • Major performance gains possible • Not a single table join (okay, just a few here and there) • Authentication can be made super simple
stuff in production is not so viable (still possible) • Complexity is much higher than in a regular CRUD system ⚠ • Slightly niche way of doing this, which makes googling harder
across simultaneous writes • Projections (central to search capabilities) • Details of authentication • Database structure (application is database agnostic)
across simultaneous writes • Projections (central to search capabilities) • Details of authentication • Database structure (application is database agnostic) • Choice of language (it matters)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
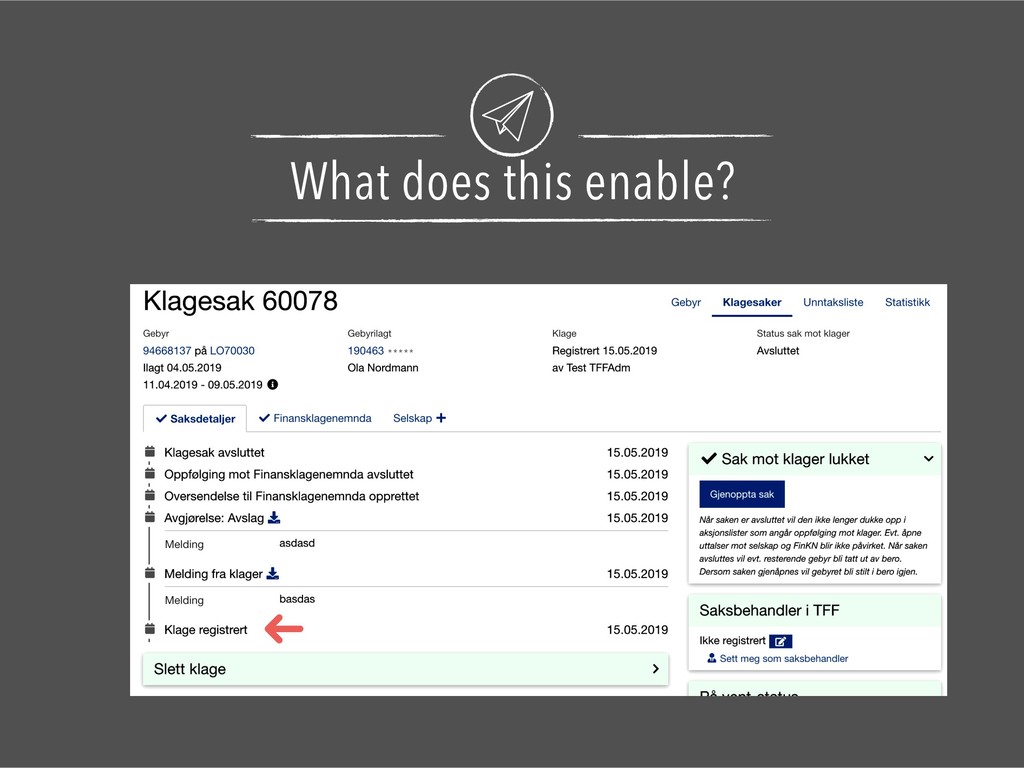{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}