残念ながら現代のクラウドサービスでは障害が発生します。
一般向けに公開されたパブリッククラウドは多くの場合、特定の一社が保有するデータセンターよりもはるかに規模が大きく、また社会的な影響も大きいため、その障害はニュースとして大きく取りざたされます。ただクラウドは魔法でも未来の技術でもなく、基礎となる技術は皆様が所有する IT 設備と何ら変わりがないのです。障害は不可避なものと考えましょう。
またクラウドはオンプレミスとは異なりメンテナンスもその利用料金に含まれ、利用者の手を煩わせないようになっています。ただ利用者から見ればその影響は無視できるものではないでしょう。障害もメンテナンスも、サービスの停止に繋がりうるという意味では同じかもしれません。
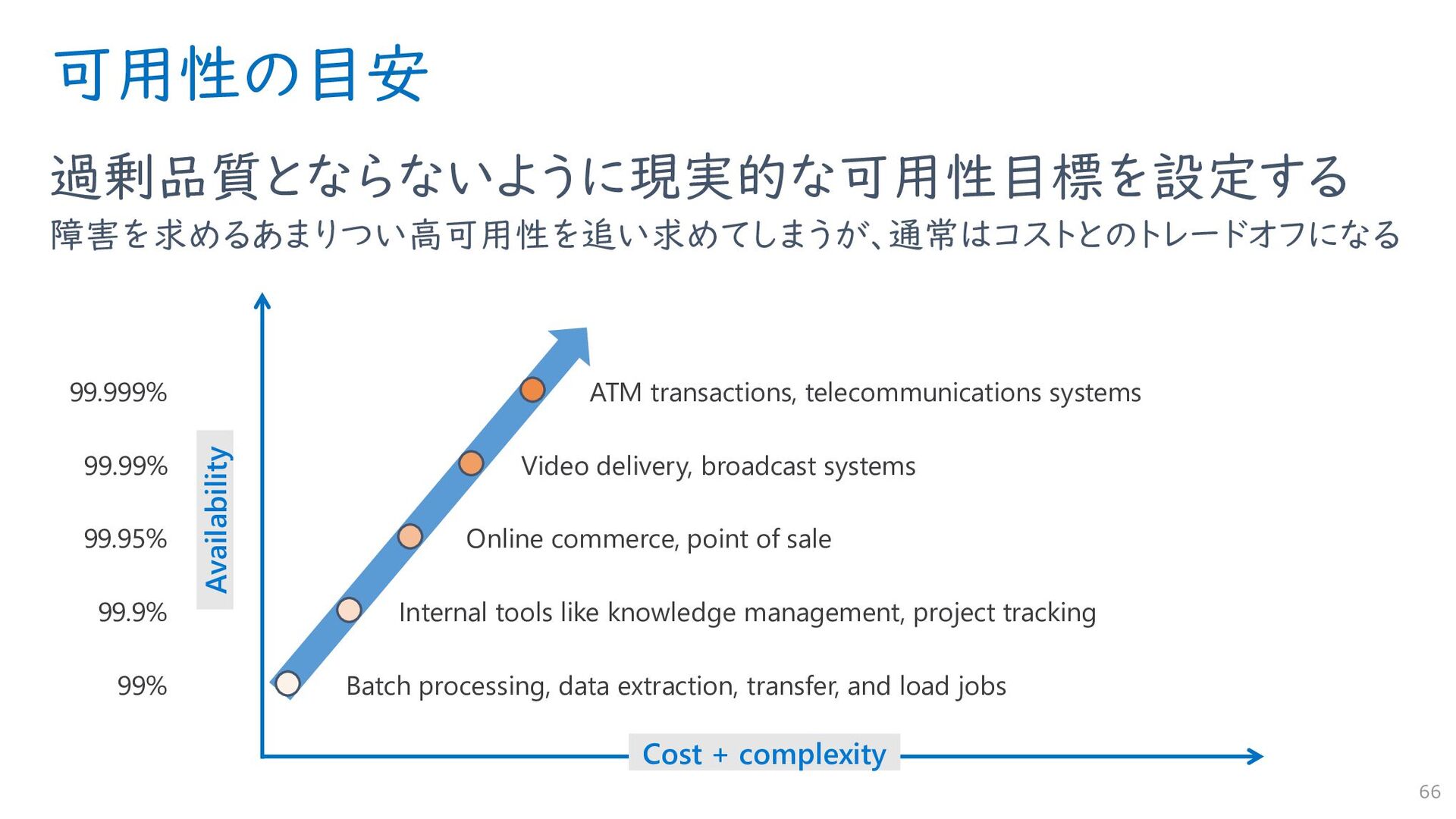
Azure のような IaaS や PaaS は利用者のアプリケーションが搭載され、初めてエンドユーザーに対して「サービス」が提供されます。Azure の「利用者」は「サービスの事業者」でもあります。その「サービス」によって品質要求はまちまちです。可用性は突き詰めればキリがありませんので、どこかで妥協が必要です。絶対に落ちてはならないサービスもあれば、多少落ちてもいいからとにかく安ければいいというサービスもあるでしょうから、サービス特性に合わせた必要十分な障害とメンテナンス対策が必要です。それを決定するのはクラウドサービスの利用者であり、クラウドそのものに対する理解が重要です。
本資料がこれから Azure を利用する方に、あるいは既にご利用いただいている方の参考になれば幸いです。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
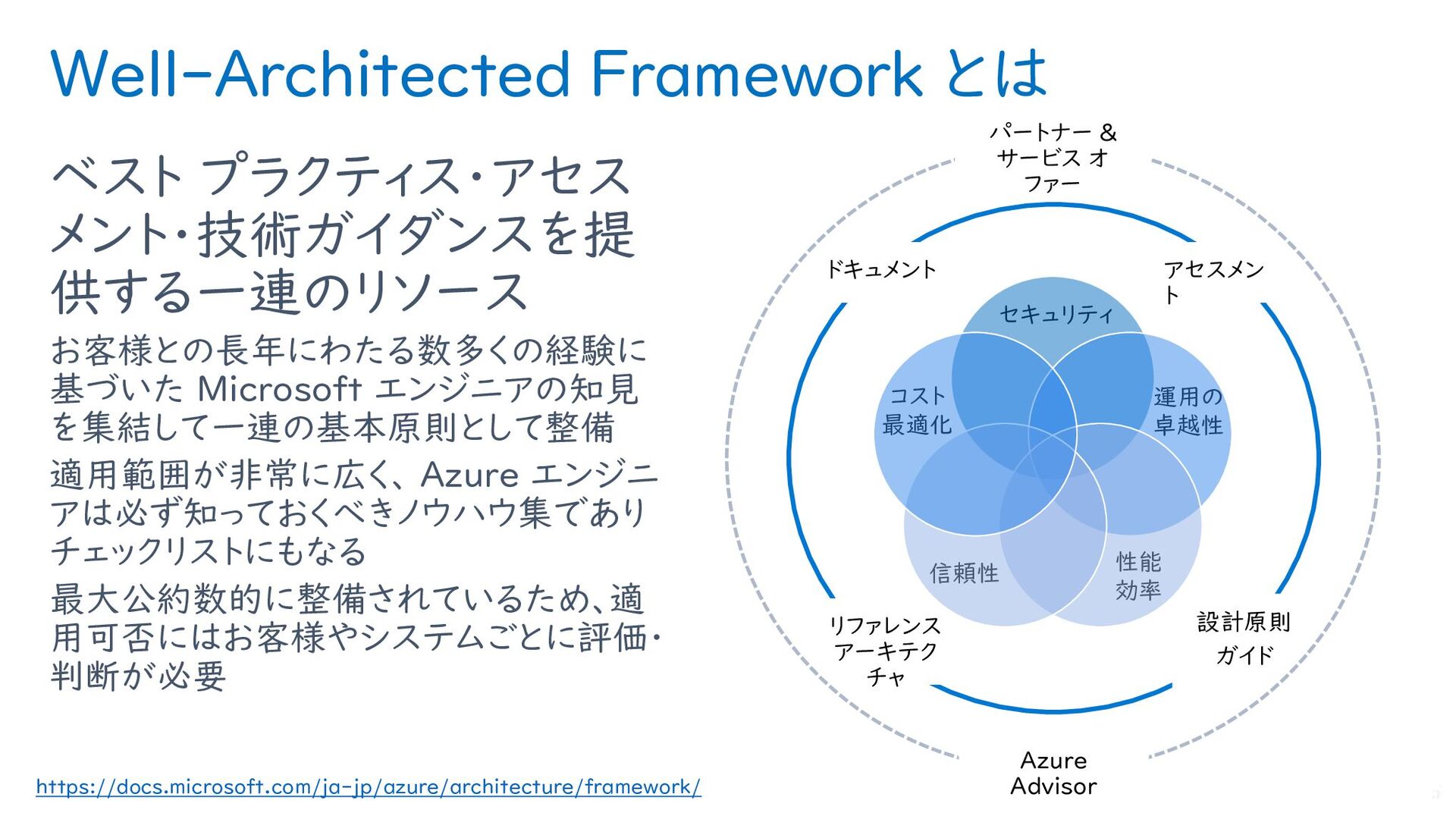{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
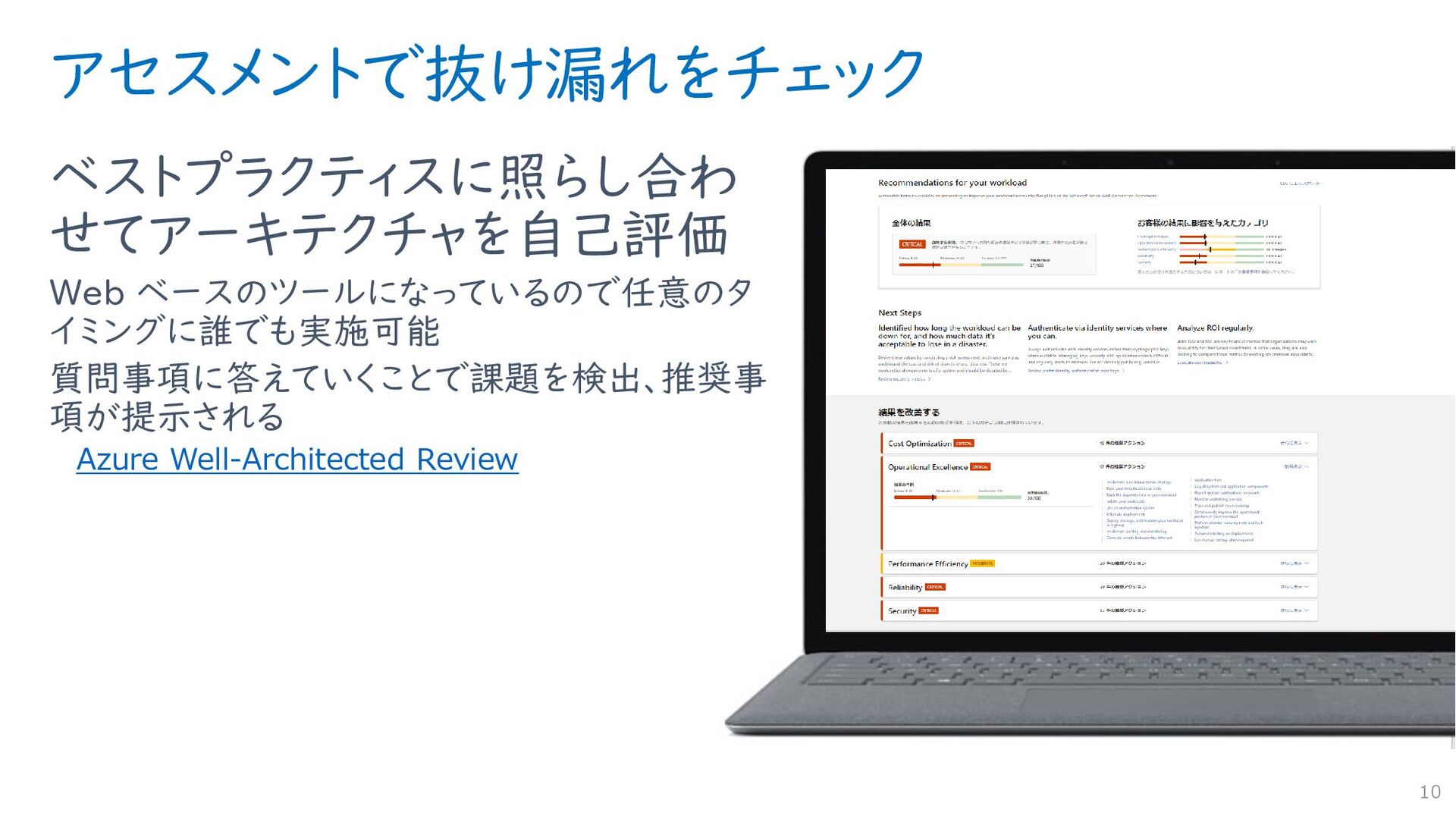{kind=link}
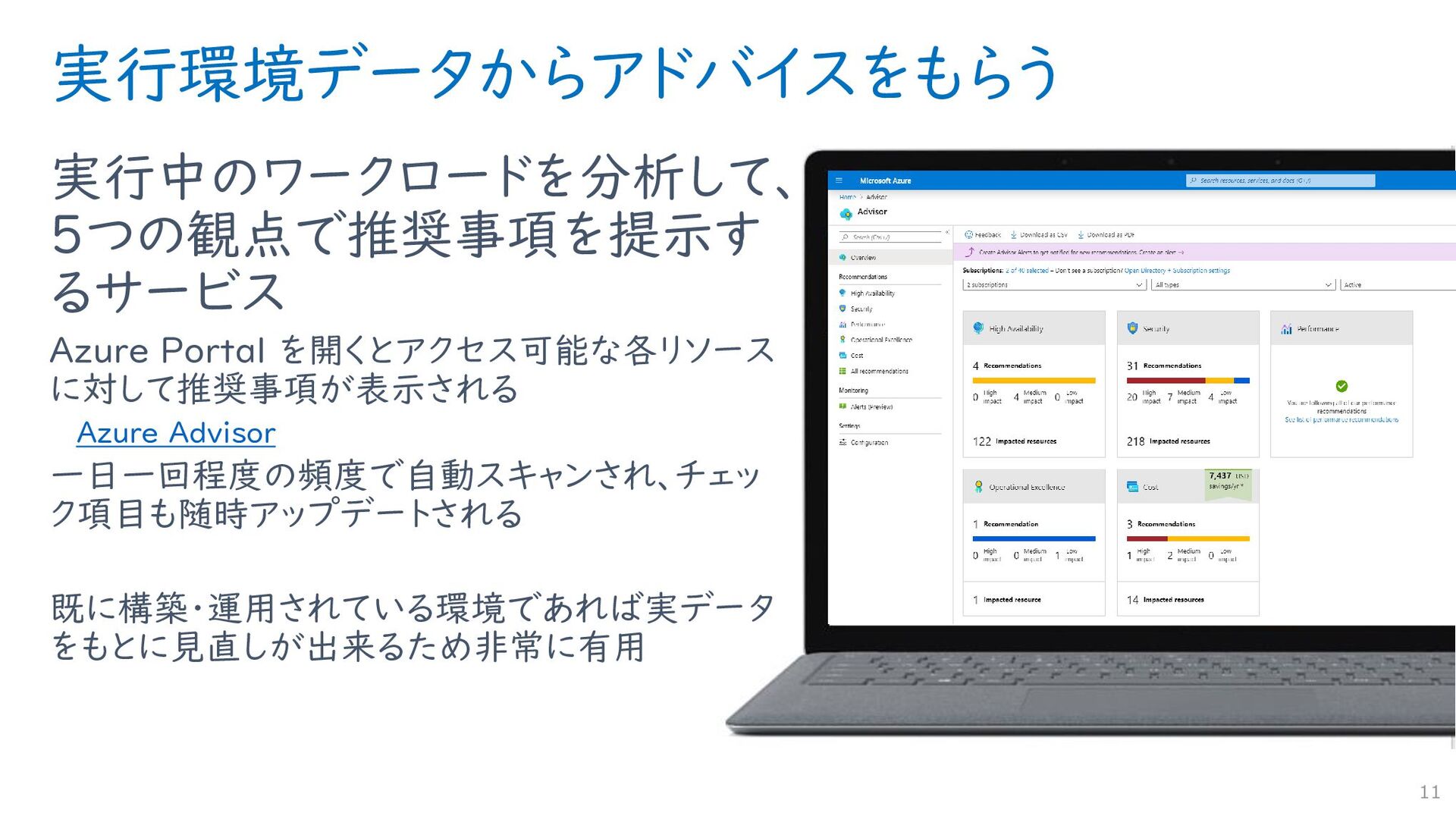{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
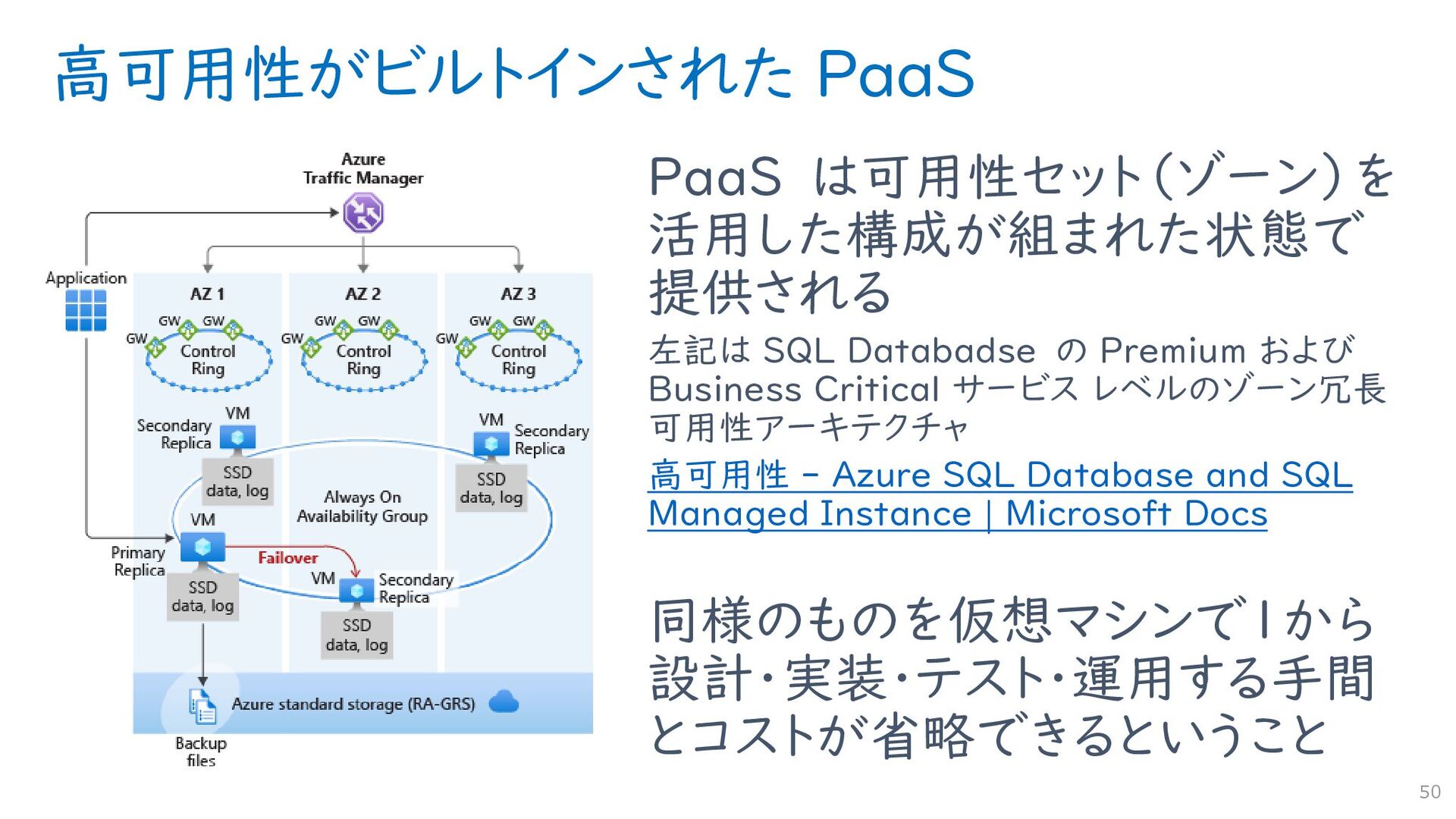{kind=link}
{kind=link}
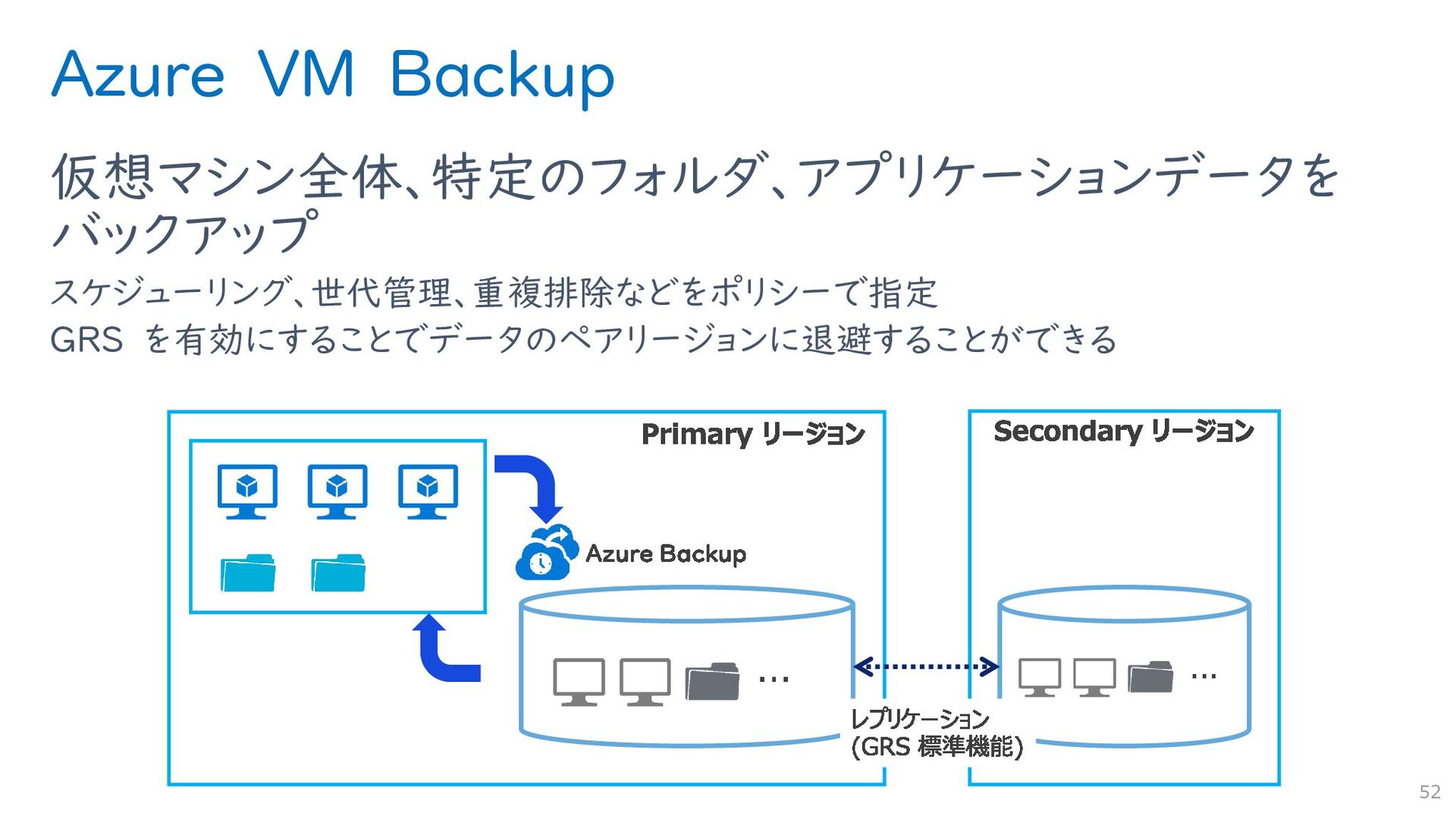{kind=link}
![[参考] Azure Backup と Site Recovery Azure 東日本リージョン Recovery Service](https://files.speakerdeck.com/presentations/a14e2057abac4a9b8eac5802e78fd573/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
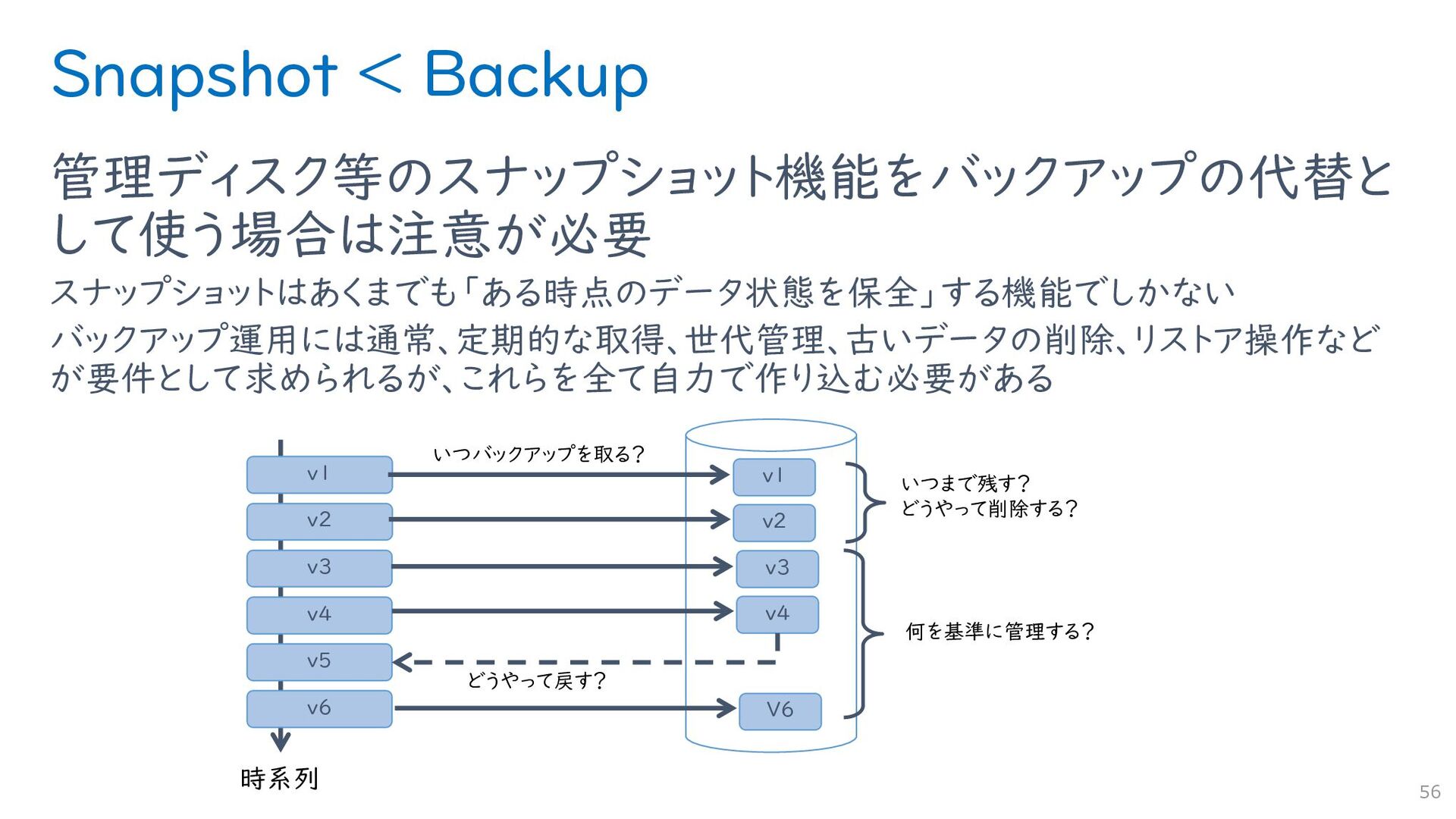{kind=link}
{kind=link}
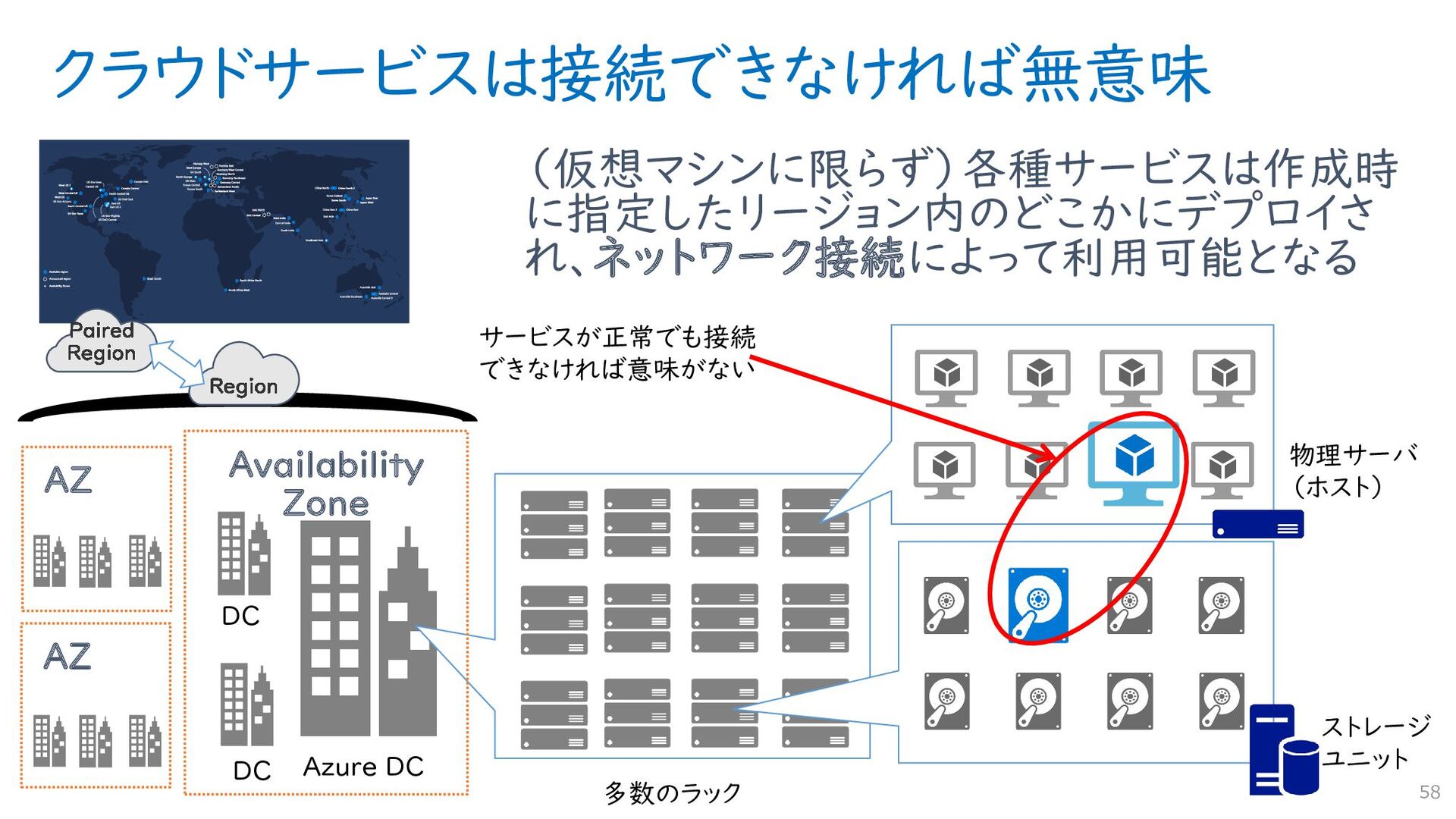{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[参考] 災害対策例の RPO/RTO の目安 種別 方式 RPO/RTO 備考 Web サーバー](https://files.speakerdeck.com/presentations/a14e2057abac4a9b8eac5802e78fd573/slide_66.jpg){kind=link}
{kind=link}
![[参考] 3rd Party Solution 69 Partner Product Solution Key Workloads](https://files.speakerdeck.com/presentations/a14e2057abac4a9b8eac5802e78fd573/slide_68.jpg){kind=link}
{kind=link}