Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
階層的クラスタリングをRubyで表現する / Implement Hierarchical...
Search
Ayumi Tamai
December 14, 2019
Technology
2.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
階層的クラスタリングをRubyで表現する / Implement Hierarchical Clustering Analysis Using Ruby
Ayumi Tamai
December 14, 2019
Other Decks in Technology
See All in Technology
reFACToring
moznion
1
1.1k
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
150
Pavlokで始める電撃駆動開発
sgrsn
0
130
LLMリーダーボードアップデートに向けたAgentic Math_SWEのトレースについて
nejumi
0
170
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
780
AIがAPIを書く時代に、私たちは何を設計すべきか
nagix
0
170
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
190
もう一度考える SRE チームの作り方・育て方 / Rethinking SRE #1: Building and Growing SRE Teams
rrreeeyyy
1
170
AI工学特論: MLOps・継続的評価
asei
11
3.1k
システム監視入門
grimoh
5
770
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
570
NetBoxを利用した作業効率化の試み_NetDevNight4
tnoha
0
410
Featured
See All Featured
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
410
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
260
The browser strikes back
jonoalderson
0
1.4k
Test your architecture with Archunit
thirion
1
2.3k
Navigating Weather and Climate Data
rabernat
0
430
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
From π to Pie charts
rasagy
0
240
The Language of Interfaces
destraynor
162
27k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Designing Experiences People Love
moore
143
24k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
The Limits of Empathy - UXLibs8
cassininazir
1
570
Transcript
平成 会議 階層的クラスタリングを で表現する
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
玉井あゆみ 平成 年生まれ カンファレンスでの発表は初 自己紹介
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
• せっかくの機会なので登壇してみたい ◦ しかし、 や に関する新しい知見は提供できそうにな い ◦ 加えて、語られるべきキャリアもない •
普段 を使わないことに敢えて を使って発表してみ ようか • そうだ、階層的クラスタ分析を実装してみよう ◦ のあるソフトウェアでこの分析を行ったことがある ◦ 階層的クラスタ分析ができる は調べた限り無さそう 発表の経緯
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
クラスタリングとは ※距離が近いほど似ているとする
クラスタリングとは ※距離が近いほど似ているとする
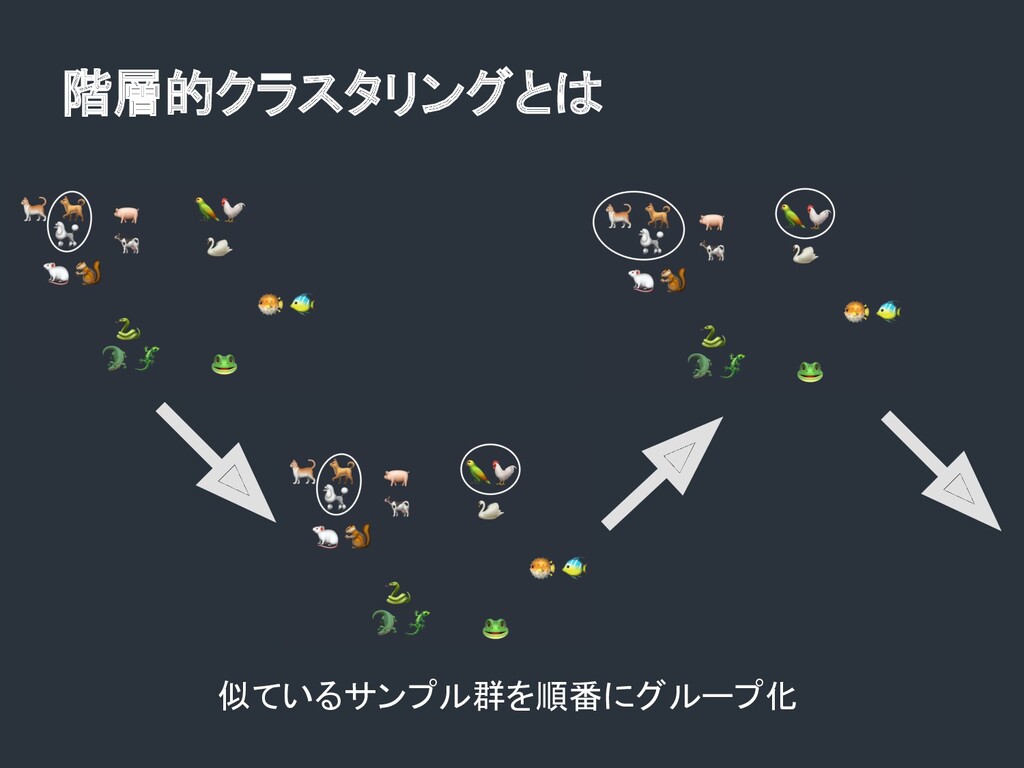
階層的クラスタリングとは 似ているサンプル群を順番にグループ化
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
平成の邦楽ヒット曲の歌詞 • 楽曲リスト: サイト「年代流行」の邦楽ヒット曲 ランキングを使用 ◦ 年のヒット曲上位 曲 ◦ アルバム名しかない場合は最初の曲を採用
• 歌詞: サイト「歌詞検索 」を使用 分析対象
形態素の出現回数により楽曲をベクトル化 • 形態素解析器: ( ) • 辞書: • 品詞大分類「記号」「助詞」「助動詞」と固有名詞は除く 恣意性
前処理
分析方法 階層的クラスタ分析 • クラスタの併合方法:ウォード法 ◦ 似ている つのサンプル 群 を順に繋げてクラスタにしていく •
クラスタ間の距離:ユークリッド距離 ◦ 日常会話で使う「距離」と同じ
分析対象の楽曲(一部) アーティスト名 楽曲名 AKB48 Teacher Teacher AKB48 センチメンタルトレイン 乃木坂46 シンクロニシティ
AKB48 願いごとの持ち腐れ AKB48 #好きなんだ AKB48 11月のアンクレット AKB48 翼はいらない AKB48 LOVE TRIP/しあわせを分けなさい AKB48 君はメロディー AKB48 僕たちは戦わない AKB48 ハロウィン・ナイト AKB48 Green Flash
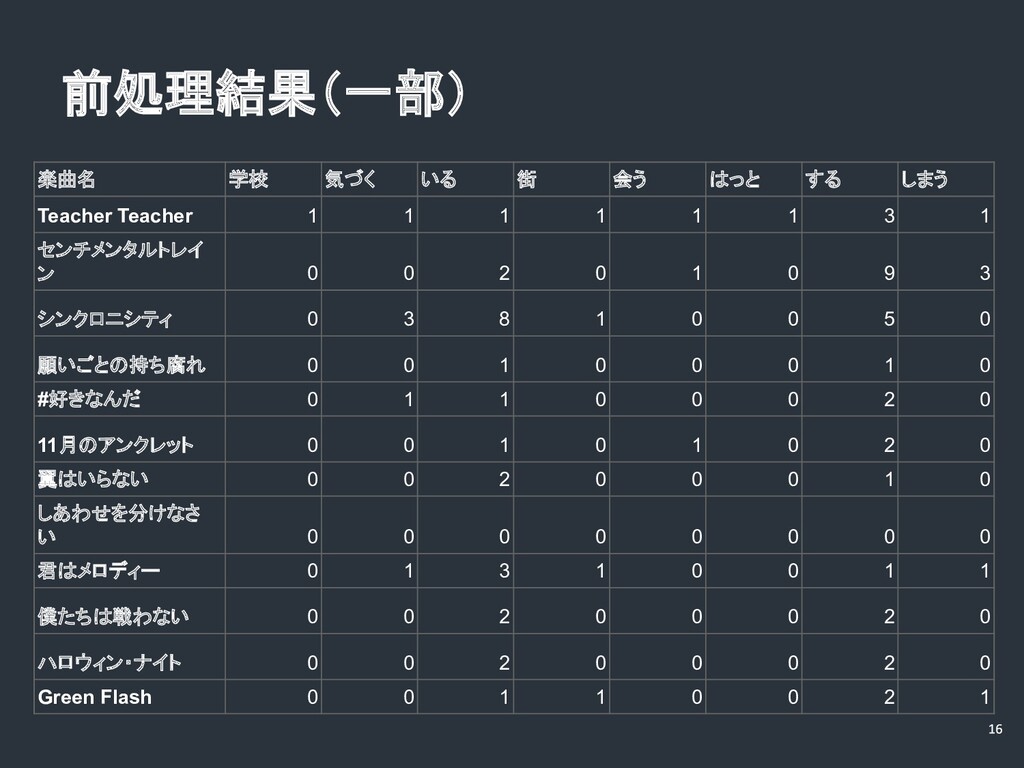
前処理結果(一部) 楽曲名 学校 気づく いる 街 会う はっと する しまう
Teacher Teacher 1 1 1 1 1 1 3 1 センチメンタルトレイ ン 0 0 2 0 1 0 9 3 シンクロニシティ 0 3 8 1 0 0 5 0 願いごとの持ち腐れ 0 0 1 0 0 0 1 0 #好きなんだ 0 1 1 0 0 0 2 0 11月のアンクレット 0 0 1 0 1 0 2 0 翼はいらない 0 0 2 0 0 0 1 0 しあわせを分けなさ い 0 0 0 0 0 0 0 0 君はメロディー 0 1 3 1 0 0 1 1 僕たちは戦わない 0 0 2 0 0 0 2 0 ハロウィン・ナイト 0 0 2 0 0 0 2 0 Green Flash 0 0 1 1 0 0 2 1
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
• 併合水準により適切そうなクラスタ数を指定したもの 分析結果
• クラスタ数を多めに指定したもの 分析結果
おもしろい結果は出なかった... 20
分析結果 • 都道府県別人口・人口密度による都道府県のクラスタリ ングの分析結果 ◦ クラスタ数: ◦ データ出典:都道府県・市区町村別統計表(国勢調査)(男女別人 口,年齢3区分・割合,就業者,昼間人口など) 都道府県・市区町
村別統計表(一覧表)平成 年
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
ウォード法の実装 23 ※簡略化・説明のため、実際のコードとは異なる箇所があります
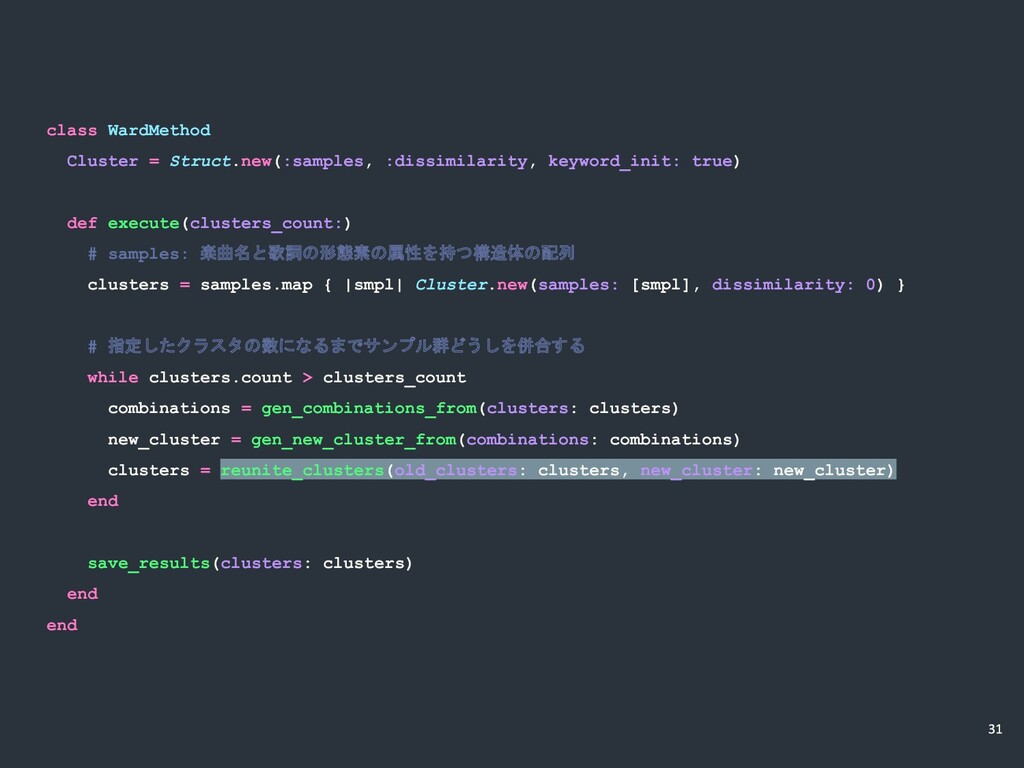
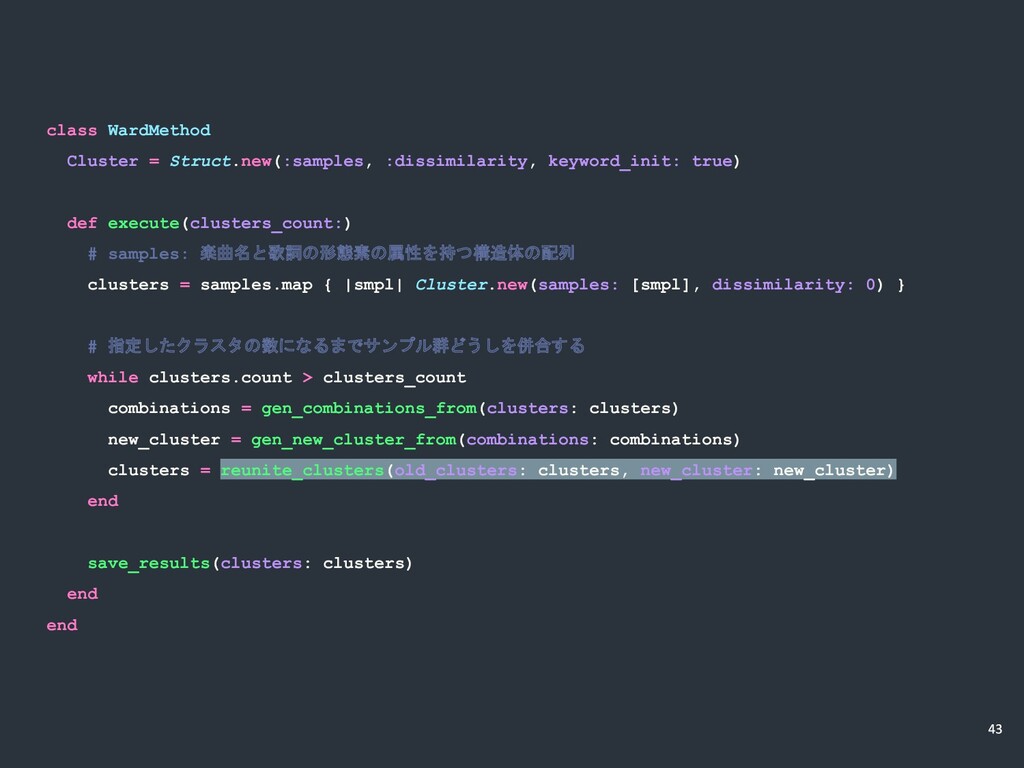
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
def gen_combinations_from(clusters:) provisional_clusters = [] # いくつかのサンプル群(仮置きクラスター)から2つとって併合 clusters.combination(2) do |c1,
c2| # 併合前のサンプル群の重心を求める cg_of_c1 = Calc.cg(array: c1.samples, name: 'C1の重心', member_variable_names: member_variable_names) cg_of_c2 = Calc.cg(array: c2.samples, name: 'C2の重心', member_variable_names: member_variable_names) # サンプル群を併合後してできた仮置きクラスターの重心を求める cu_samples = c1.samples | c2.samples cg_of_cu = Calc.cg(array: cu_samples, name: 'C1とC2を連結した仮クラスターの重心', member_variable_names: member_variable_names) # 次スライドへ続く
# 併合前後で、「仮置きクラスターの重心」と各「サンプル」との # ユークリッド距離の二乗和 ‘sum of squared differences’ を求める sum_of_sqd_between_c1_cg_and_sample
= Calc.sum_of_sqds(samples: c1.samples, cg: cg_of_c1, member_variable_names: member_variable_names) sum_of_sqd_between_c2_cg_and_sample = Calc.sum_of_sqds(samples: c2.samples, cg: cg_of_c2, member_variable_names: member_variable_names) sum_of_sqd_between_cu_cg_and_sample = Calc.sum_of_sqds(samples: cu_samples, cg: cg_of_cu, member_variable_names: member_variable_names) # 次スライドへ続く
# 併合してできた仮置きクラスターのサンプルとメタ情報をメモしておく # 併合後の 重心–各サンプル 間距離の二乗和から併合前の 重心–各サンプル 間距離の二乗和を引く # `diff_between_sqds`:
クラスタの重心と各サンプルとの距離の二乗和の差(後で使う) provisional_clusters << ProvisionalCluster.new( diff_between_sqds: sum_of_sqd_between_cu_cg_and_sample - sum_of_sqd_between_c1_cg_and_sample - sum_of_sqd_between_c2_cg_and_sample, c1: c1, c2: c2, ) end provisional_clusters end
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
def gen_new_cluster_from(combinations:) # 含まれるサンプルがもっとも似ているクラスタを選ぶ # ※「含まれるサンプルがもっとも似ているクラスタ」:複数ある仮置きクラスタの中で、 # クラスタの重心と各サンプルとの距離の二乗和の差(`diff_between_sqds`)が最も小さいもの new_cluster_prov =
combinations .min { |a, b| a.diff_between_sqds <=> b.diff_between_sqds } #構造体クラス Cluster の構造体として返す new_cluster = Cluster.new( samples: new_cluster_prov.c1.samples | new_cluster_prov.c2.samples, dissimilarity: dissimilarity(new_cluster_provision: new_cluster_prov) ) end
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
def reunite_clusters(old_clusters:, new_cluster:) # 新しく作ったクラスタとサンプルを共有する古いクラスタを削除 # 理論上、2つのクラスタ(Cluster構造体)を配列から除くことになっているはず old_clusters.delete_if { |cl|
(new_cluster.samples & cl.samples).count > 0 } # 除いた古いクラスタを併合して新しく作ったクラスタ(Cluster構造体)を配列に追加 old_clusters.push new_cluster end
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
次元データでの例 34
併合 段階目 35
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
None
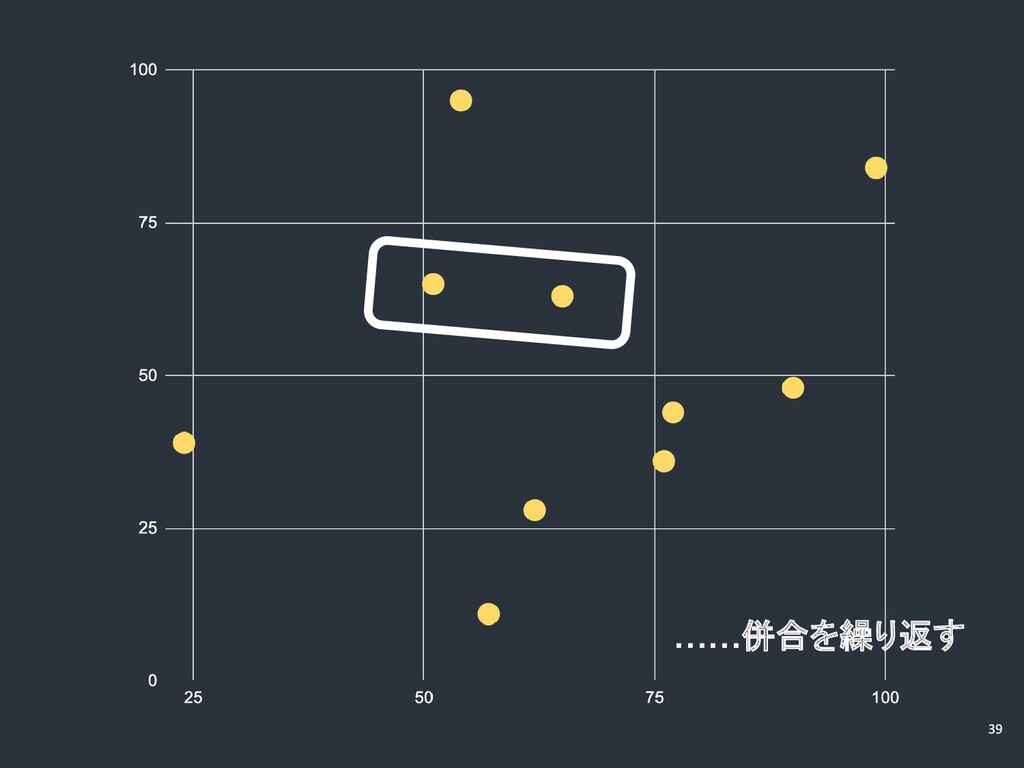
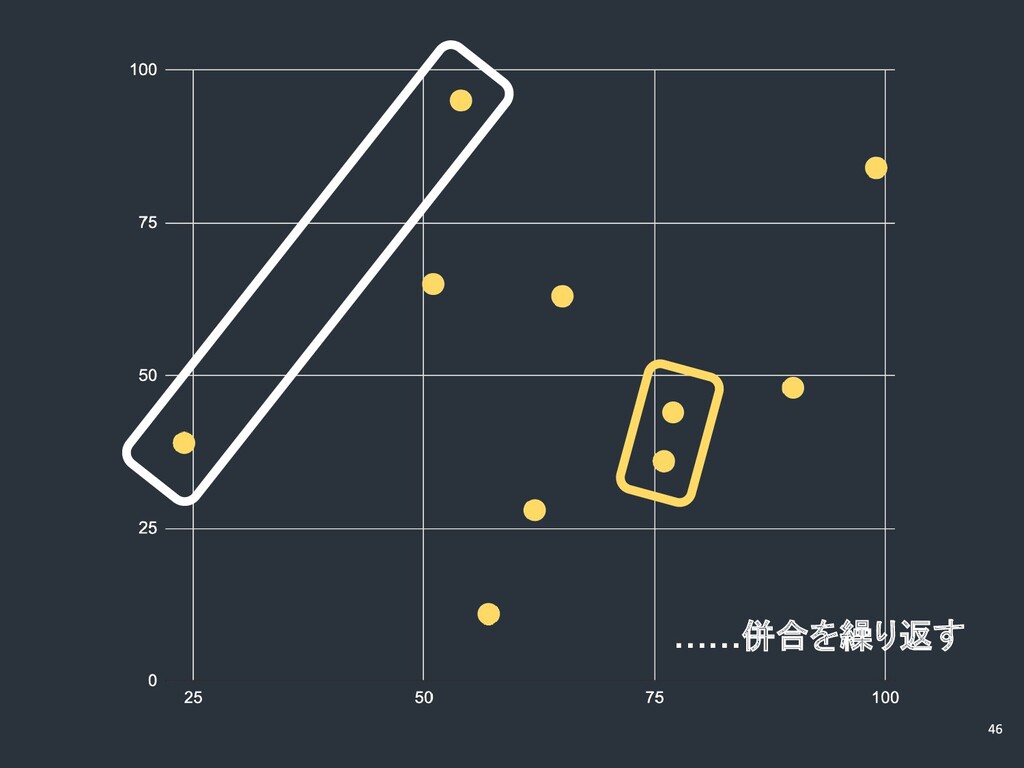
……併合を繰り返す
……併合を繰り返す
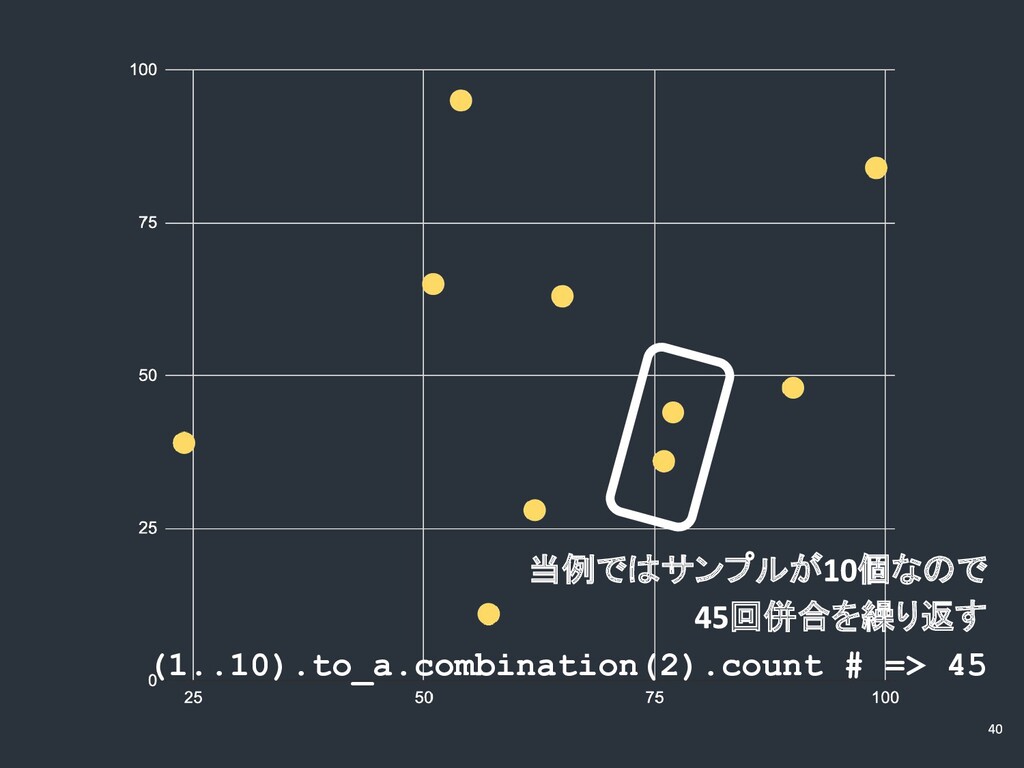
当例ではサンプルが 個なので 回併合を繰り返す (1..10).to_a.combination(2).count # => 45
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
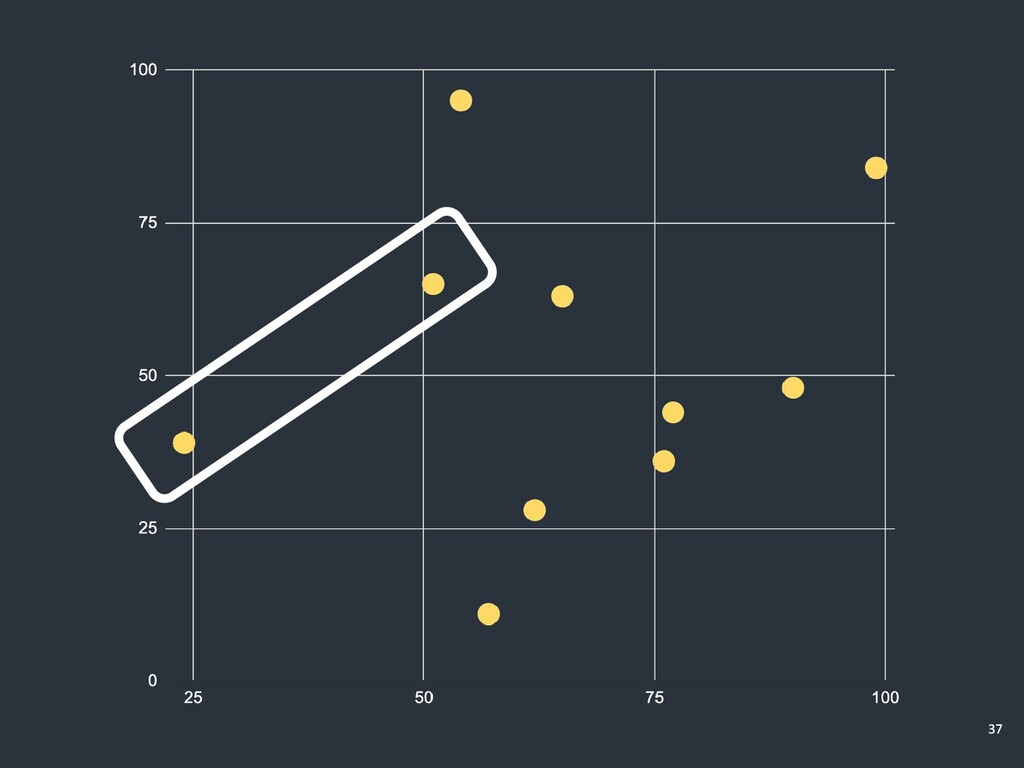
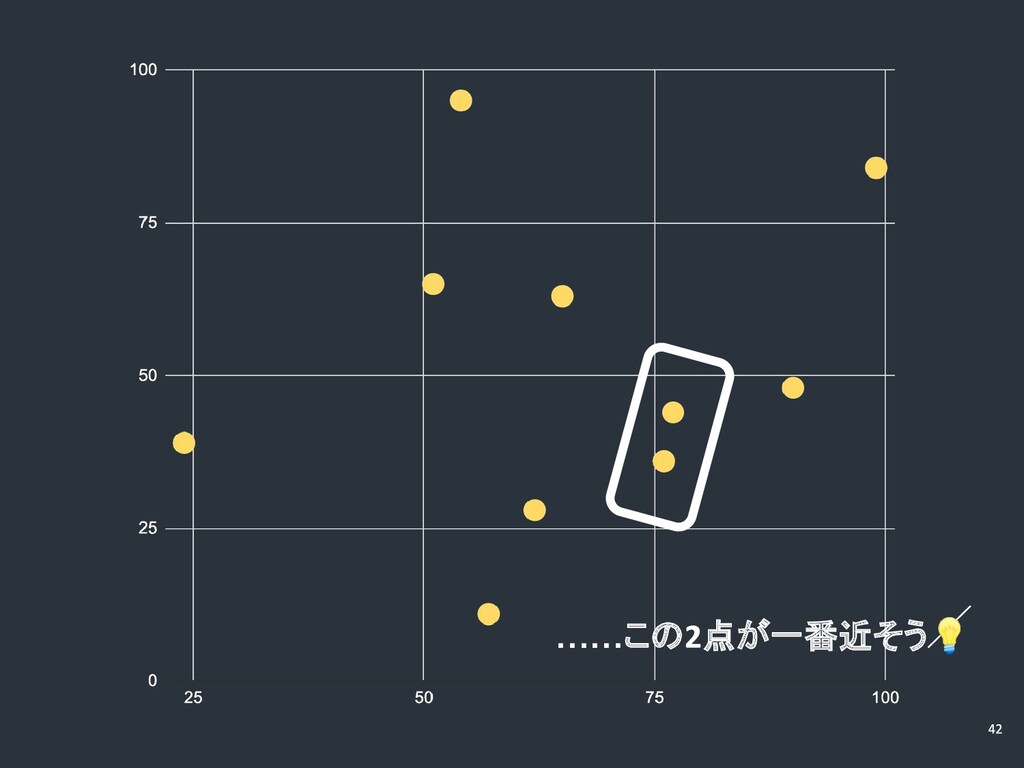
……この 点が一番近そう
class WardMethod Cluster = Struct.new(:samples, :dissimilarity, keyword_init: true) def execute(clusters_count:)
# samples: 楽曲名と歌詞の形態素の属性を持つ構造体の配列 clusters = samples.map { |smpl| Cluster.new(samples: [smpl], dissimilarity: 0) } # 指定したクラスタの数になるまでサンプル群どうしを併合する while clusters.count > clusters_count combinations = gen_combinations_from(clusters: clusters) new_cluster = gen_new_cluster_from(combinations: combinations) clusters = reunite_clusters(old_clusters: clusters, new_cluster: new_cluster) end save_results(clusters: clusters) end end
None
併合 段階目 45
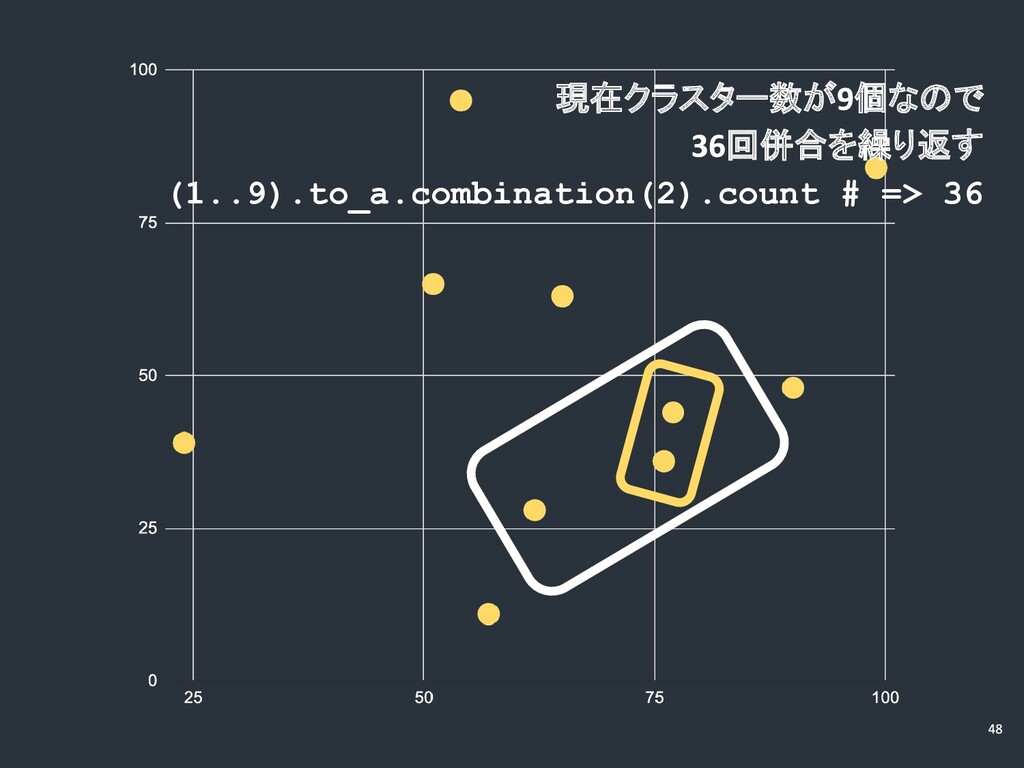
……併合を繰り返す
……併合を繰り返す
現在クラスター数が 個なので 回併合を繰り返す (1..9).to_a.combination(2).count # => 36
クラスタ数指定の基準 49
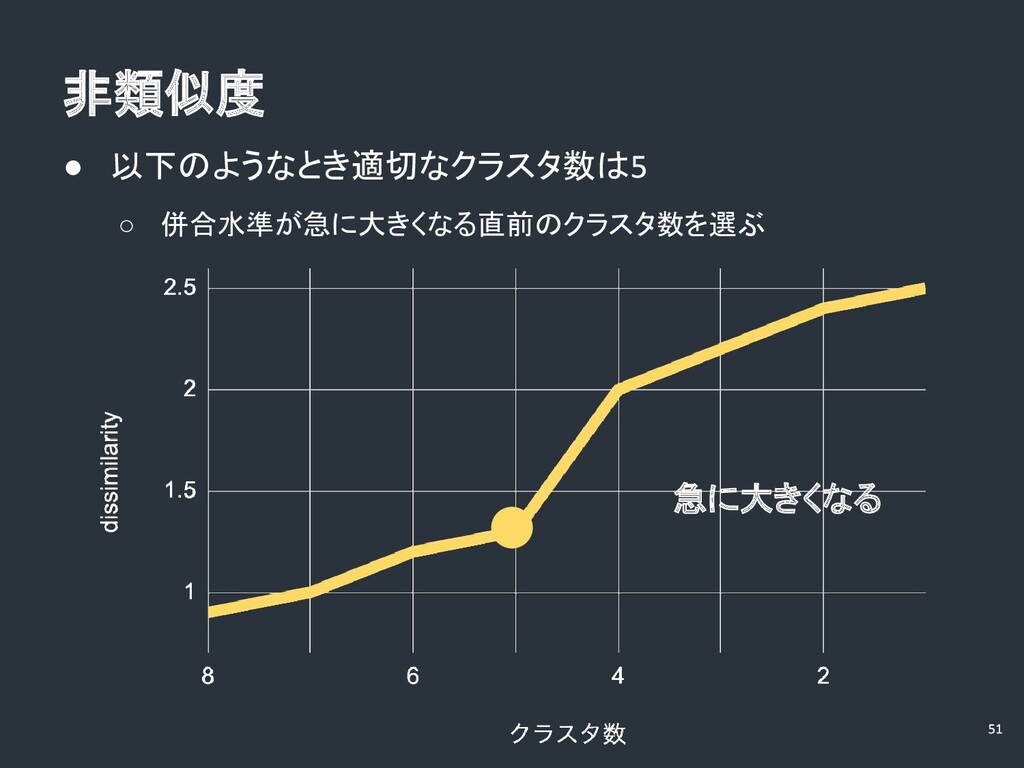
• 非類似度 併合水準 • クラスタどうしが似ていないほど数値が高い • 今回は、距離の二乗和の差(前述)の常用対数( を底と する対数)をとったものを非類似度とする 非類似度
非類似度 • 以下のようなとき適切なクラスタ数は ◦ 併合水準が急に大きくなる直前のクラスタ数を選ぶ 急に大きくなる
話すこと • 自己紹介 • 発表の経緯 • 階層的クラスタリングの説明 • 分析対象・方法 •
分析結果 • 実装の紹介 • まとめ
階層的クラスタリングをなんとか で表現できた
• 階層的クラスタリングをなんとか で表現できた • 非文章(歌詞や詩)をこの方法で分析するのは難しい ◦ を使用した前処理 ◦ 語のスコアによる重み付きユークリッド距離 •
併合水準のグラフ デンドログラムの描画には手をつけら れなかった まとめ
今回の分析に使用したコード •
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def gen_combinations_from(clusters:) provisional_clusters = [] # いくつかのサンプル群(仮置きクラスター)から2つとって併合 clusters.combination(2) do |c1,](https://files.speakerdeck.com/presentations/28ca00ac9244419a8688a5584815598c/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}