長岡技術科学大学
自然言語処理研究室 守谷歩
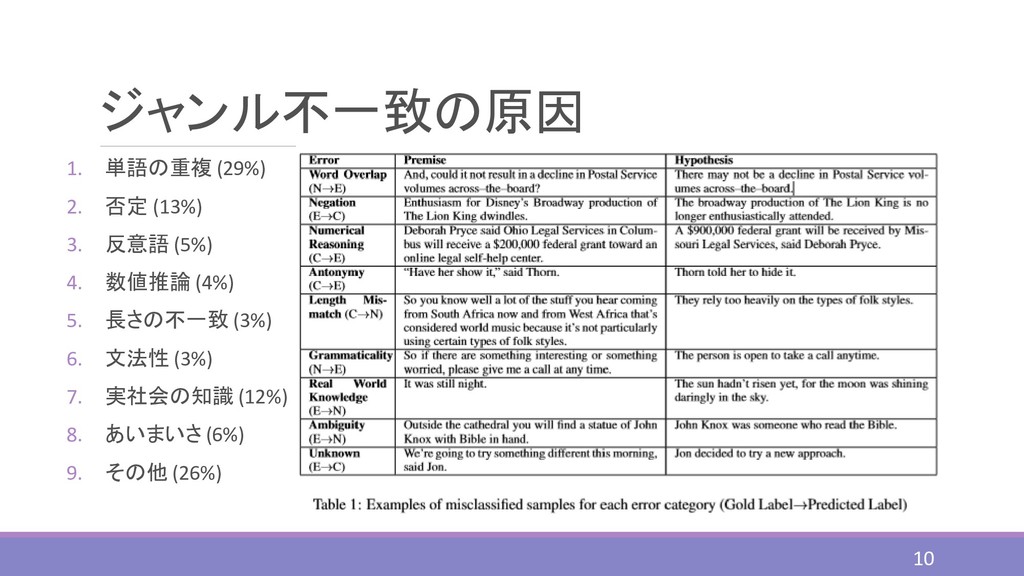
Stress Test Evaluation for Natural Language Inference 文献紹介
文献発表後に表現がおかしい、誤字があったので以下に示します。
p.13 誤「名前付きで実態を含まない文」
正「固有名詞」
p.15 誤 ストレス精度の式
正 " } "が抜けてました(literatureを参考に してください)
p.23以降のページ番号が小さい
p.24 誤「制度が大幅に低下」
正「精度が大幅に低下」
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}