⚫[機械学習]パラメータの重みの初期値:https://qiita.com/m-hayashi/items/02065a2e2ec3e2269e0b ⚫ChainerとRNNと機械翻訳:https://qiita.com/odashi_t/items/a1be7c4964fbea6a116e ⚫[機械学習]Google翻訳(みたいなもの)を自作してみた。:https://qiita.com/R- Yoshi/items/9a809c0a03e02874fabb ⚫Xavierの初期値 Heの初期値の考察:http://murayama.hatenablog.com/entry/2017/11/25/231609 ⚫Dual Learning for Machine Translation ⚫Seq2Seq+Attentionのその先へ:https://qiita.com/ymym3412/items/c84e6254de89c9952c55 ⚫Attention Is All You Need
{kind=link}
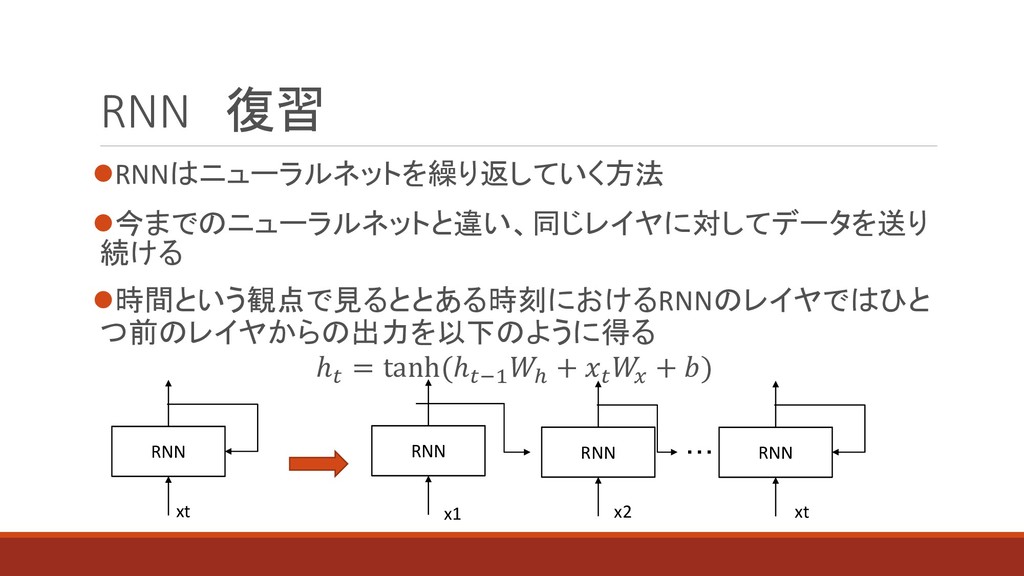{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}