Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介「二値符号予測と誤り訂正を用いたニューラル翻訳モデル」
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Ayumu
March 05, 2019
Technology
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介「二値符号予測と誤り訂正を用いたニューラル翻訳モデル」
2019/03/05
長岡技術科学大学 自然言語処理研究室
学部4年 守谷 歩
Ayumu
March 05, 2019
More Decks by Ayumu
See All by Ayumu
B3ゼミ_03_28_マルチモーダル学習_.pdf
ayumum
0
200
マルチモーダル学習
ayumum
0
190
B3ゼミ 自然言語処理におけるCNN
ayumum
0
140
言語処理年次大会報告
ayumum
0
130
ニューラルネット4
ayumum
0
140
ニューラルネット3 誤差伝搬法,CNN,word2vec
ayumum
0
210
ニューラルネット実践
ayumum
0
150
文献紹介[Zero-Shot Dialog Generation with Cross-Domain Latent Action]
ayumum
0
230
パーセプトロンとニューラルネット1
ayumum
0
120
Other Decks in Technology
See All in Technology
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
グローバルチームと挑むプロダクト開発
sansantech
PRO
1
160
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.5k
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
180
最近評価が難しくなった
maroon8021
0
250
“ID沼入口” - 基本とセキュリティから始める、考え続けるためのID管理技術勉強会 告知&イントロ
ritou
0
440
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
1.4k
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
Why is RC4 still being used?
tamaiyutaro
0
310
Claude Code 珍プレー好プレー
shinyasaita
0
280
初めてのDatabricks勉強会
taka_aki
2
240
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
140
Featured
See All Featured
Accessibility Awareness
sabderemane
1
150
WCS-LA-2024
lcolladotor
0
670
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
380
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Thoughts on Productivity
jonyablonski
76
5.2k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
180
Crafting Experiences
bethany
1
210
We Have a Design System, Now What?
morganepeng
55
8.2k
Transcript
二値符号予測と誤り訂正を 用いたニューラル翻訳モデル 2019/03/05 長岡技術科学大学 自然言語処理研究室 学部4年 守谷 歩 1
文献 ⚫「二値符号予測と誤り訂正を用いたニューラル翻訳モデル」 ⚫小田 悠介, Philip Arthur, Graham Neubig, 吉野 幸一郎,
中村 哲 ⚫二値符号予測と誤り訂正を用いたニューラル翻訳モデル, 自然言 語処理, 2018, 25 巻, 2 号, p. 167-199, 公開日 2018/06/15, Online ISSN 2185-8314, Print ISSN 1340- 7619, https://doi.org/10.5715/jnlp.25.167, https://www.jstage.jst.go .jp/article/jnlp/25/2/25_167/_article/-char/ja, 抄録: 2
概要 ⚫近年の機械翻訳ではエンコーダ、デコーダ、注釈機構からなる ニューラル翻訳モデルが研究されている。 ⚫既存の方法で表現力の高いニューラル翻訳モデルの出力層では ソフトマックス演算を行っており、これは、語彙に含まれる全単語の スコアを隠れ層の一次結合として計算するため、計算量が語彙サ イズに比例するため軽量化したい。 ⚫また、単純に二値符号のみを用いる方法だと翻訳精度が従来の 手法と比べて大幅に低下してしまう。 3
概要 ⚫従来の方法でも以下の4つの観点が計算量を軽量化するために 需要だと考えられる。 ⚫翻訳精度 ⚫空間効率(使用メモリ量) ⚫時間効率(実行速度) ⚫並列計算との親和性 ⚫軽量化をするために従来のソフトマックスモデルを部分的に導入 し、高頻度語と低頻度語を分離し、学習させる手法を提案。また、 二値符号の頑健性を向上させるため、誤り訂正符号、畳み込み符
号による冗長化を施す。 4
単純なソフトマックスモデルの定式化 ⚫語彙サイズV、同じ数の次元の連続空間ℝ ⚫単語ID ∈ { ∈ ℕ|1 ≤ ≤ }に対応する次元を1、それ以外の次元を
0とする単位ベクトル () ∈ ℝを単語の表現とみなす ⚫部分空間 ℝ = ∈ ℝ ∧ ∀. 0 ≤ < 1 ∧ σ =1 = 1 ⚫損失関数の計算 , = , = − + log =1 = σ =1 = ℎ ℎ + 5
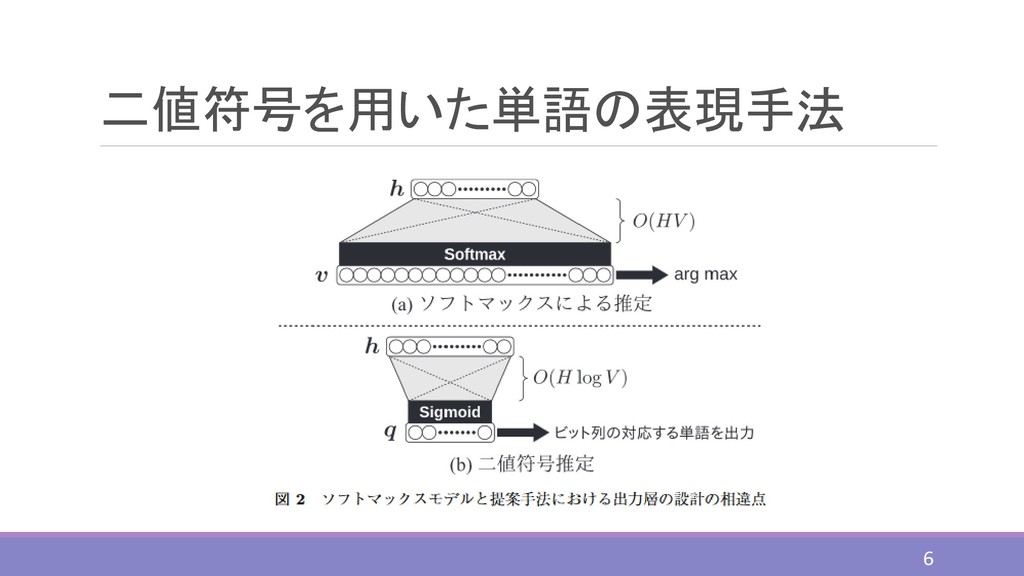
二値符号を用いた単語の表現手法 6
二値符号を用いた単語の表現手法 ⚫単語に対応するビット列 = b1 w , b2 w , …
, bB w V = 0,1 B ⚫各ビットが1となる確率 ℎ = 1 ℎ , 2 ℎ , … , ℎ ∈ 0,1 ⚫ロジスティック回帰モデル ℎ = ℎ ℎ + , = 1 1 + exp(−) ⚫確率q(h)における各ビットごとの確率の積 Pr ℎ = ෑ =1 ℎ + 1 − 1 − ℎ 7
二値符号モデルの損失関数、計算量 ⚫損失関数 損失関数の満たすべき条件 , ቊ =∈ = ≥∈ ℎ 損失関数は、先行研究より二乗誤差を用いるほうが精度が向上
, = =1 B − 2 ⚫計算量 8
ソフトマックスと二値符号予測の 混合モデル ⚫生成確率 Pr ℎ = ቊ , < ∗
, ℎ ℎ = exp σ =1 exp , = ℎ ℎ + , ℎ = ෑ =1 ( + 1 − 1 − ) ⚫損失関数 = ൝ , < + , ℎ = , , = , 9
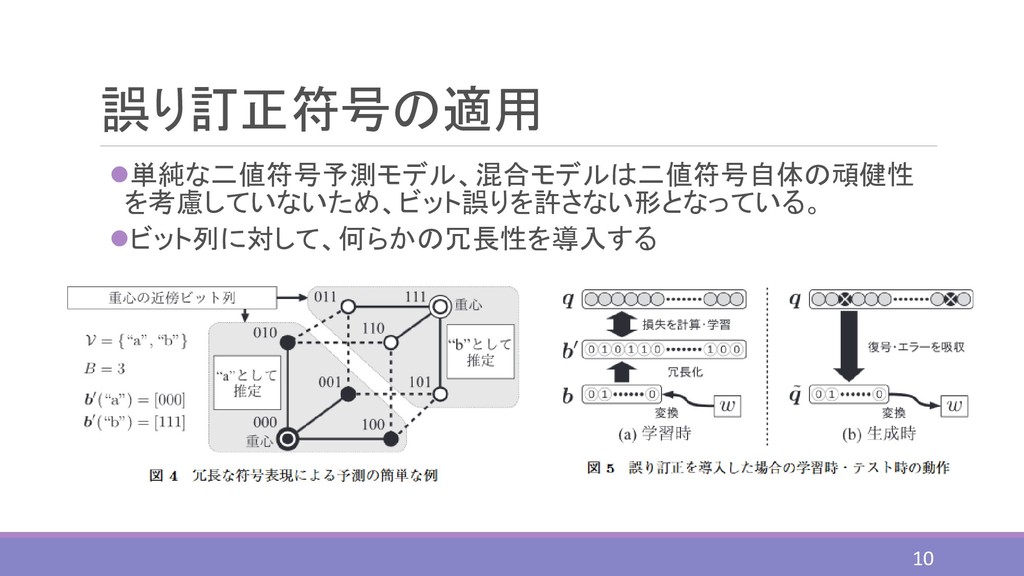
誤り訂正符号の適用 ⚫単純な二値符号予測モデル、混合モデルは二値符号自体の頑健性 を考慮していないため、ビット誤りを許さない形となっている。 ⚫ビット列に対して、何らかの冗長性を導入する 10
実験設定 ⚫コーパスはASPECとBTECを使用 ⚫英語のトークン化にはMoses、日本語のトークン化に はKyTeaを使用した。 ⚫ニューラルネットワークの構築にはDyNetを使用した。 ⚫すべてのモデルは1つのGPUを用いて学習した。また、 実行時間を検証するためにGPU上とCPU上の両方で 行った。 ⚫翻訳モデルのエンコーダには双方向RNN、注意機構 及びデコーダはConcat
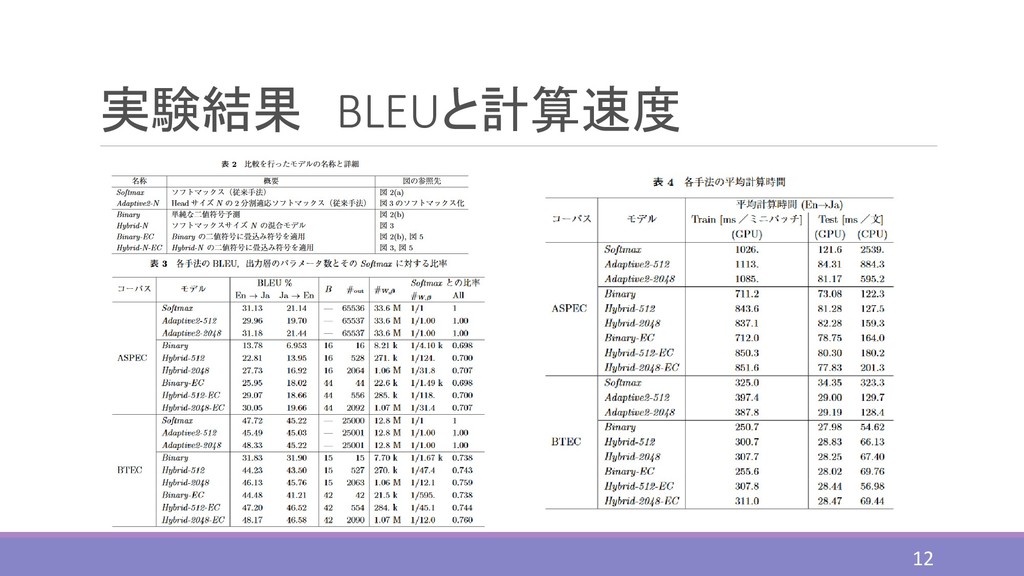
Global Attention モデルを使 用した。また、RNNには入力、忘却、出力ゲートを含 む1層のLSTMを使用した。 ⚫ニューラルネットワークの学習にはAdam最適化機を 使用し、そのハイパーパラメータは = 0.001, 1 = 0.9, 2 = 0.999, = 10−8 ⚫モデルの評価にはBLUEを使用 11
実験結果 BLEUと計算速度 12
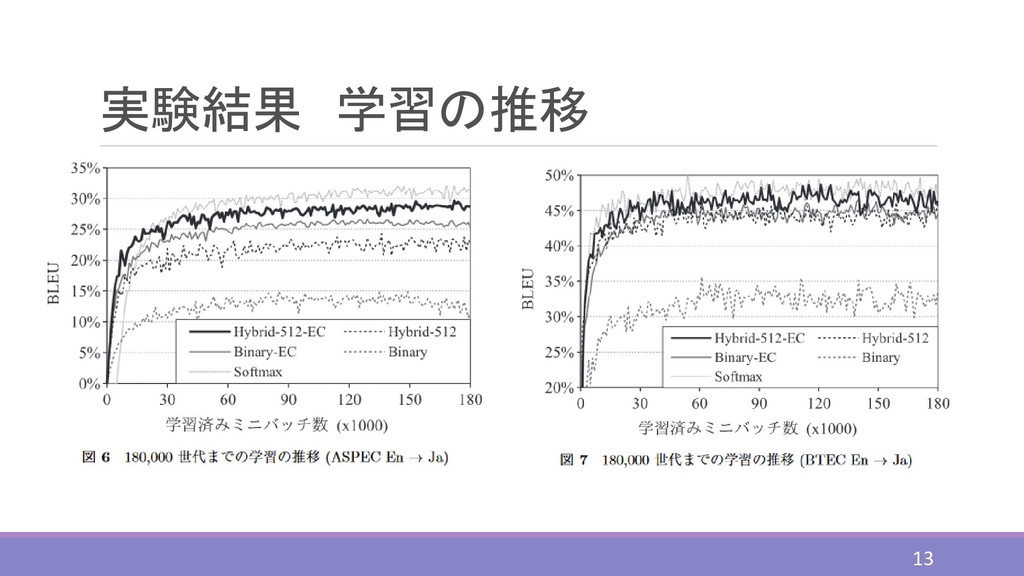
実験結果 学習の推移 13
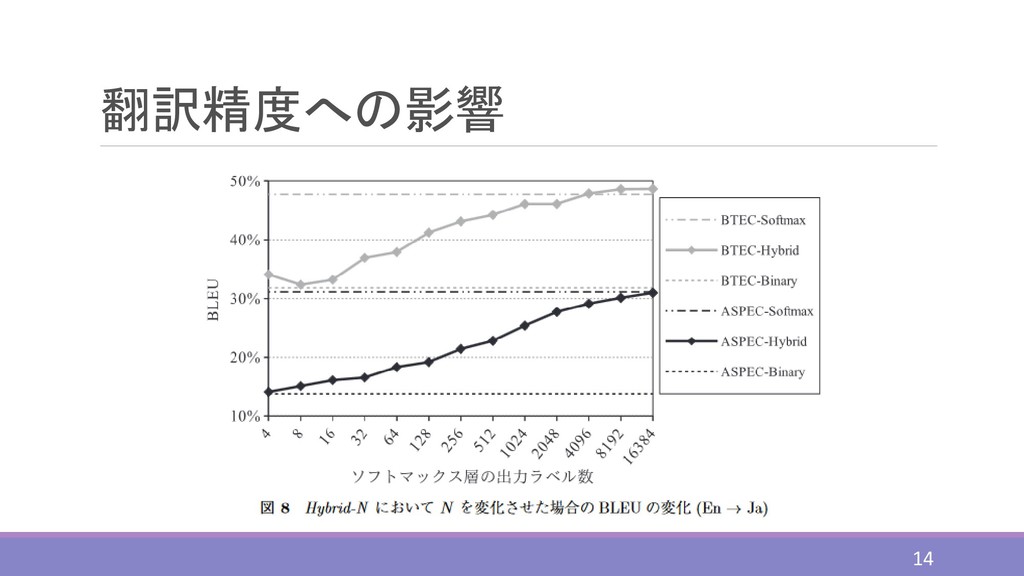
翻訳精度への影響 14
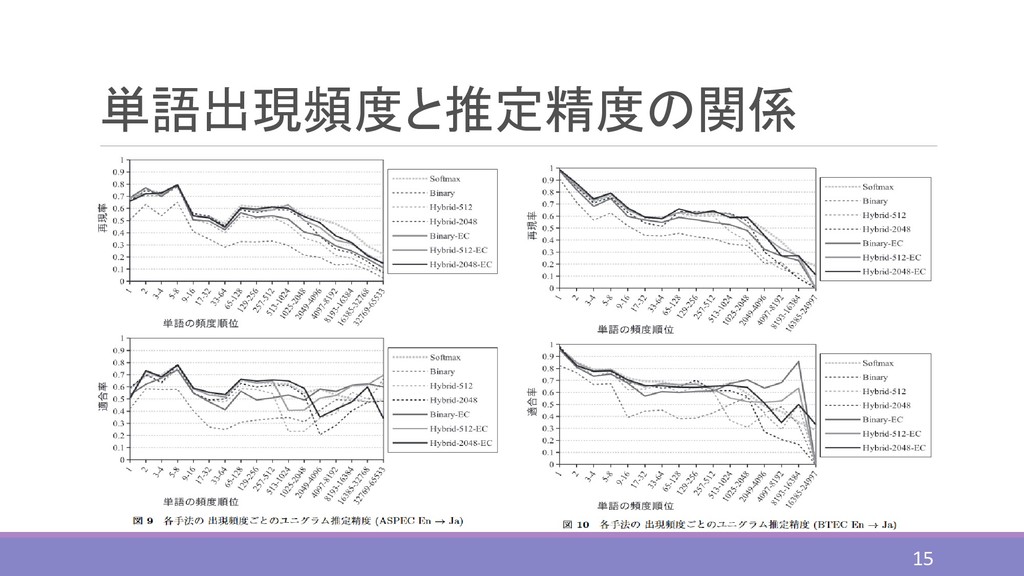
単語出現頻度と推定精度の関係 15
今後への展開 ⚫翻訳モデルにより適した単語のビット列への割り当て手法 ⚫ニューラル翻訳モデルの学習により適した形の誤り訂正手法の 開発 ⚫入力装側の単語ベクトルも二値符号に制約し、モデルのパラメー タを削った場合の翻訳精度は同様に達成できるのか ⚫翻訳モデルの内部状態やパラメータが獲得した表現に関する調 査 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}