Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ニューラルネット3 誤差伝搬法,CNN,word2vec
Search
Ayumu
February 28, 2019
Technology
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ニューラルネット3 誤差伝搬法,CNN,word2vec
2019/02/28
長岡技術科学大学 自然言語処理研究室
学部3年 守谷 歩
Ayumu
February 28, 2019
More Decks by Ayumu
See All by Ayumu
B3ゼミ_03_28_マルチモーダル学習_.pdf
ayumum
0
200
マルチモーダル学習
ayumum
0
190
B3ゼミ 自然言語処理におけるCNN
ayumum
0
140
言語処理年次大会報告
ayumum
0
130
ニューラルネット4
ayumum
0
140
文献紹介「二値符号予測と誤り訂正を用いたニューラル翻訳モデル」
ayumum
0
210
ニューラルネット実践
ayumum
0
150
文献紹介[Zero-Shot Dialog Generation with Cross-Domain Latent Action]
ayumum
0
230
パーセプトロンとニューラルネット1
ayumum
0
120
Other Decks in Technology
See All in Technology
ゼロをイチにする仕事が終わったあと
smasato
0
310
Claude Codeとハーネスについて考えてみる
oikon48
18
8.7k
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
550
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
260
Zoom2Youtube.Claude
kawaguti
PRO
2
460
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
140
“ID沼入口” - 基本とセキュリティから始める、考え続けるためのID管理技術勉強会 告知&イントロ
ritou
0
440
初めてのDatabricks勉強会
taka_aki
2
240
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
1
220
どうして今サーバーサイドKotlinを選択したのか
nealle
0
210
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
12
1.7k
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
150
Featured
See All Featured
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Building Adaptive Systems
keathley
44
3.1k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
180
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
From π to Pie charts
rasagy
0
230
Designing Experiences People Love
moore
143
24k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
270
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Claude Code のすすめ
schroneko
67
230k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
XXLCSS - How to scale CSS and keep your sanity
sugarenia
250
1.3M
Transcript
ニューラルネット 2019/02/28 長岡技術科学大学 自然言語処理研究室 学部3年 守谷 歩 誤差逆伝搬法,CNN,word2vec
誤差逆伝搬法 ⚫逆伝搬は順方向とは逆向きに局所的な微分をする + **2 = 2(x+y)*1 = 1 = 1
∗ 2 = 2(x+y)
ReLUの逆伝搬 ⚫ReLU関数はy = ቊ ( > 0) 0 ( ≤
0) より、その微分の形はy = ቊ 1 ( > 0) 0 ( ≤ 0) で表すことができる。 relu relu 0 > 0 ≤ 0
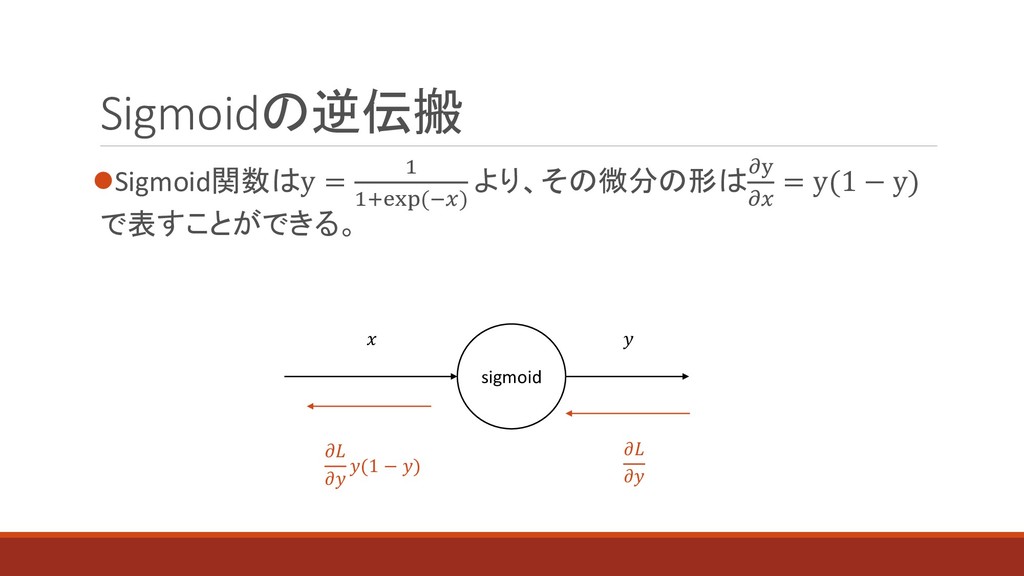
Sigmoidの逆伝搬 ⚫Sigmoid関数はy = 1 1+exp(−) より、その微分の形はy = y(1 − y)
で表すことができる。 sigmoid (1 − )
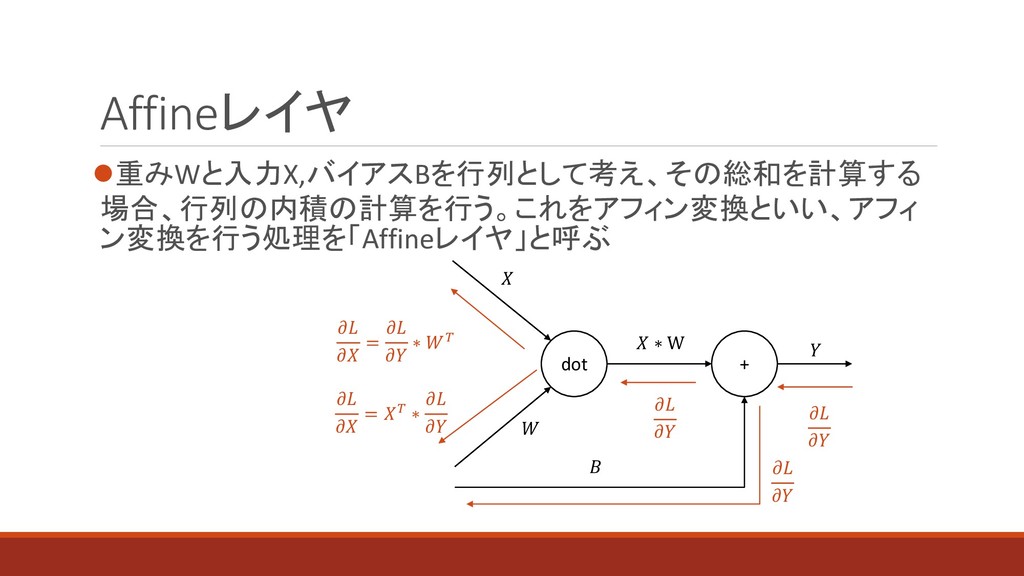
Affineレイヤ ⚫重みWと入力X,バイアスBを行列として考え、その総和を計算する 場合、行列の内積の計算を行う。これをアフィン変換といい、アフィ ン変換を行う処理を「Affineレイヤ」と呼ぶ dot + ∗ W = ∗
= ∗
各レイヤ実装
重みの更新 ⚫SGD(確率的勾配降下法):現状の重みを勾配の方向へある一定の距 離更新する。 ← − η ⚫Momentum:モーメンタムは運動量という意味であり、勾配方向への距 離の更新に速度を追加する。 ← −
← + ⚫AdaGrad:パラメータの各要素に学習係数を調整しながら学習を行う(更 新のステップを調整する) ℎ ← ℎ + ۨ ← − η 1 ℎ ⚫Adam:MomentumとAdaGradの利点を組み合わせ、効率的にパラメータ 空間を探索する
CNN(畳み込みニューラルネット) ⚫Convolutionレイヤ、Poolingレイヤを全結合層に追加したネット ワーク。 ⚫畳み込み層といった、入力データを受け取った次元Nと同じ次元N のデータとして出力する。この時の入出力のデータを特徴マップと 呼ぶ。 ⚫入力データの周囲に固定のデータを埋めることをパディングと呼 ぶ。パディングを行うことで出力サイズを調整することができる。 ⚫フィルターを適用する位置の間隔をストライドという。
CNN(畳み込みニューラルネット) ⚫Poolingレイヤ:プーリングとは縦、横咆哮の空間を小さくする演算 である。例として2*2のMAXプーリングを行うと2*2の行列で最大値 を取る要素を取り出す。一般的に、プーリングのサイズとストライド は同じ値とする。プーリングによって、入力データのずれを吸収でき る ⚫情報をスライドさせながら生成された情報が畳み込まれたレイヤ をConvolutionレイヤと呼ぶ Conv Affine
Pooli ng ReLU ReLU Affine Softm ax
分散表現 カウントベース手法 ⚫自然言語処理をするにあたってコーパスを用いる。コーパスを使う ために元のテキストデータを辞書型にし、単語のリストを単語IDのリ ストに変換する。 ⚫単語の分散表現は、単語を固定長のベクトルで表現する。 ⚫また、そのために、単語の意味は、周囲の単語によって形成され るといった分布仮説を用いる。
分散表現 コサイン類似度 ⚫ex) You sey goodbye, and I say hello→7*7の単語の頻度のテーブ
ルができる。 ⚫このテーブルを共起行列とし、各単語のベクトルが求まる、 ⚫単語ベクトル表現の類似度を計算する場合、2つのベクトルのコサ イン類似度を見る。 Similarity x, y = x ∗ y | |
分散表現 相互情報量PMI ⚫単語の頻度では、意味的に近い要素の関連性が少なくなる。 ⚫Xが起こる確率とyが起こる確率を使い相互情報量といった指標を 使う P x, y = log2
P x, y ()
Word2vec 推論ベース ⚫推論ベースは、周囲の単語が与えられたときに、その間にどのよ うな単語が出現するかを推測する手法 ⚫Ex)you ? Goodbye, and I say
hello ⚫One-Hotベクトルでベクトルを生成、CBOWモデルを用いる。 ⚫CBOWモデルはコンテキストからターゲット推論を行うニューラル ネット ⚫またほかにもSkip-gramモデルといったターゲットからコンテキスト 推論を行うニューラルネットも使用することができる。
CBOWモデル ⚫CBOWモデルの入力はコンテキストで表される。入 力層がコンテキストの数あり、中間層を経て出力層 へたどり着く。出力層のニューロンは各単語のスコ アであり、値が高いと対応する単語の出現確率も 高くなる。 ⚫スコアにSoftmax関数を適用すると確率が得られ る。 ⚫CBOWモデルの損失関数 =
−( |−1 , +1 )
Skip-gram ⚫Skip-gramモデルはCBOWと逆で、ターゲットか らコンテキストを予測するモデルである。 ⚫Ex)you ? Goodbye ? I say hello
⚫それぞれの出力層で、個別に損失を求め、そ れらを足し合わせら物を最終的な損失とする。 ⚫Skip-gramモデルの損失関数 = 1 =1 ( −1 + (+1 | )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}