Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ニューラルネット実践
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ayumu
February 21, 2019
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ニューラルネット実践
ニューラルネット、損失関数、勾配法、前回の疑問点
長岡技術科学大学 自然言語処理研究室
学部3年 守谷 歩
Ayumu
February 21, 2019
More Decks by Ayumu
See All by Ayumu
B3ゼミ_03_28_マルチモーダル学習_.pdf
ayumum
0
200
マルチモーダル学習
ayumum
0
190
B3ゼミ 自然言語処理におけるCNN
ayumum
0
140
言語処理年次大会報告
ayumum
0
130
ニューラルネット4
ayumum
0
140
文献紹介「二値符号予測と誤り訂正を用いたニューラル翻訳モデル」
ayumum
0
210
ニューラルネット3 誤差伝搬法,CNN,word2vec
ayumum
0
210
文献紹介[Zero-Shot Dialog Generation with Cross-Domain Latent Action]
ayumum
0
230
パーセプトロンとニューラルネット1
ayumum
0
120
Other Decks in Technology
See All in Technology
どうして今サーバーサイドKotlinを選択したのか
nealle
0
210
AIで政治は変わるのか? — 中高生と考えたAI時代の民主主義(東海高校サタデープログラム)
eitarosuda
0
400
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
0
140
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
12
1.7k
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
1
2.4k
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
740
Baseline対応のDOMの型定義を作った
uhyo
3
720
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
3.4k
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
140
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
1
2.4k
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
400
Featured
See All Featured
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
RailsConf 2023
tenderlove
30
1.5k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
The Invisible Side of Design
smashingmag
301
52k
Un-Boring Meetings
codingconduct
0
330
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
350
Building an army of robots
kneath
306
46k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.3k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
280
Transcript
ニューラルネット2 2019/02/21 長岡技術科学大学 自然言語処理研究室 学部3年 守谷 歩 ニューラルネット、損失関数、勾配法、前回の 疑問点
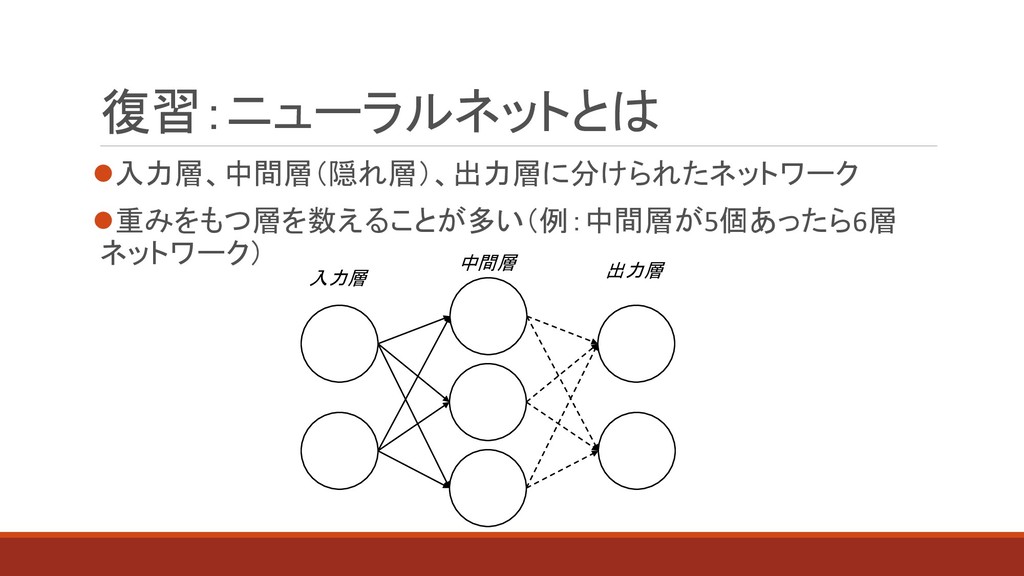
⚫入力層、中間層(隠れ層)、出力層に分けられたネットワーク ⚫重みをもつ層を数えることが多い(例:中間層が5個あったら6層 ネットワーク) 復習:ニューラルネットとは 入力層 中間層 出力層
⚫活性化関数h(x)を与える = ቊ 0 1 ∗ 1 + 2 ∗
2 + ≤ 0 1 1 ∗ 1 + 2 ∗ 2 + > 0 (w1,w2:重み x1,x2:入力 b:バイアス) = h(b+w1∗x1+w2∗x2) 復習:ニューラルネットの式 h(x) x1 x2 w1 w2 1 y b
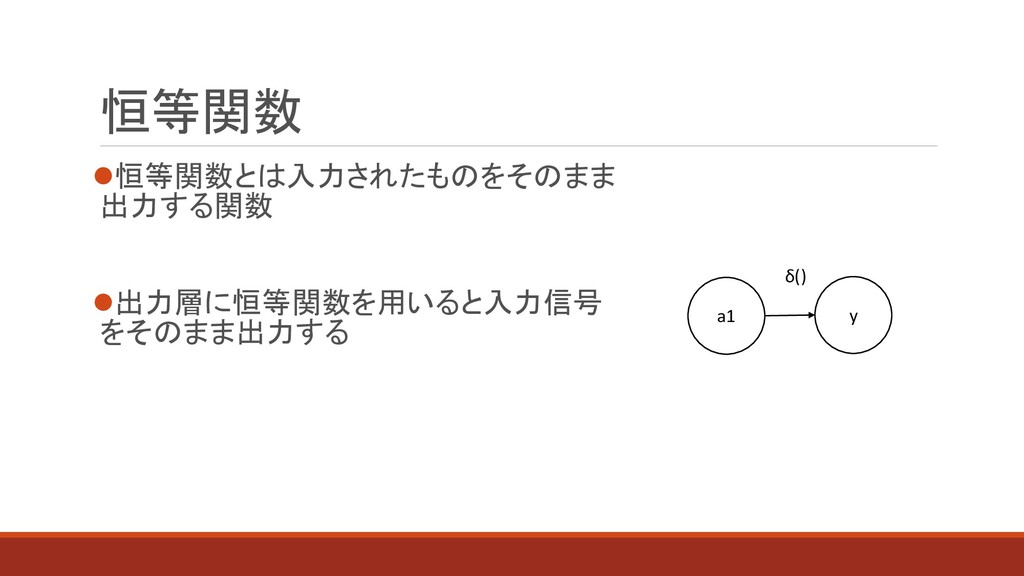
⚫恒等関数とは入力されたものをそのまま 出力する関数 ⚫出力層に恒等関数を用いると入力信号 をそのまま出力する 恒等関数 a1 y δ()
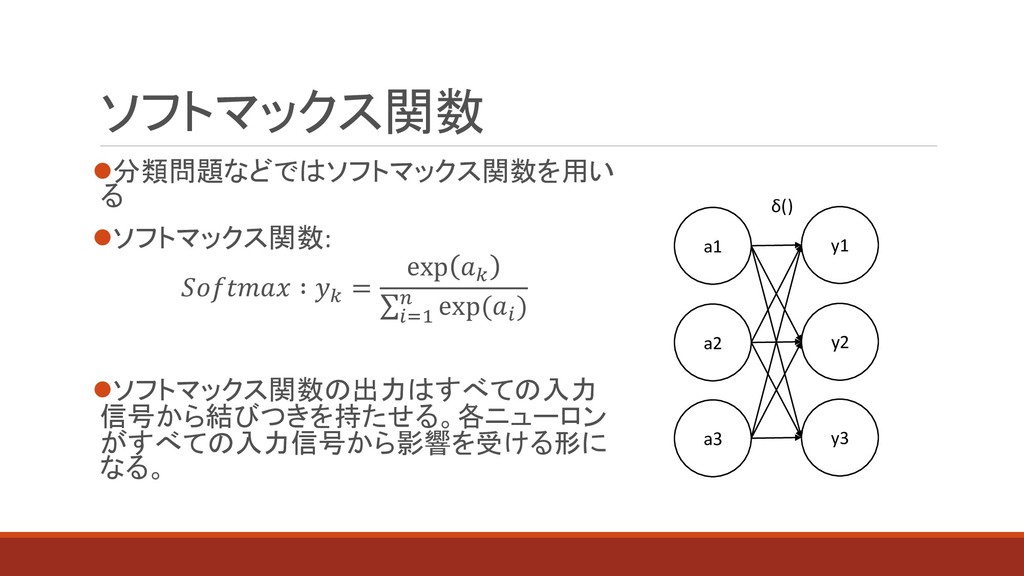
⚫分類問題などではソフトマックス関数を用い る ⚫ソフトマックス関数: ∶ = exp σ =1 exp( )
⚫ソフトマックス関数の出力はすべての入力 信号から結びつきを持たせる。各ニューロン がすべての入力信号から影響を受ける形に なる。 ソフトマックス関数 a1 y1 δ() a2 y2 a3 y3
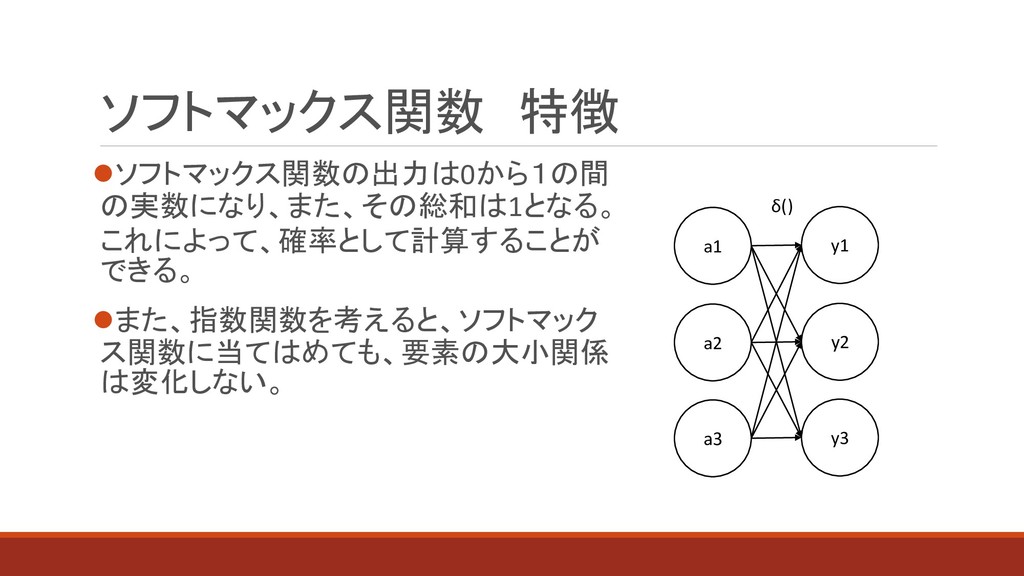
⚫ソフトマックス関数の出力は0から1の間 の実数になり、また、その総和は1となる。 これによって、確率として計算することが できる。 ⚫また、指数関数を考えると、ソフトマック ス関数に当てはめても、要素の大小関係 は変化しない。 ソフトマックス関数 特徴 a1
y1 δ() a2 y2 a3 y3
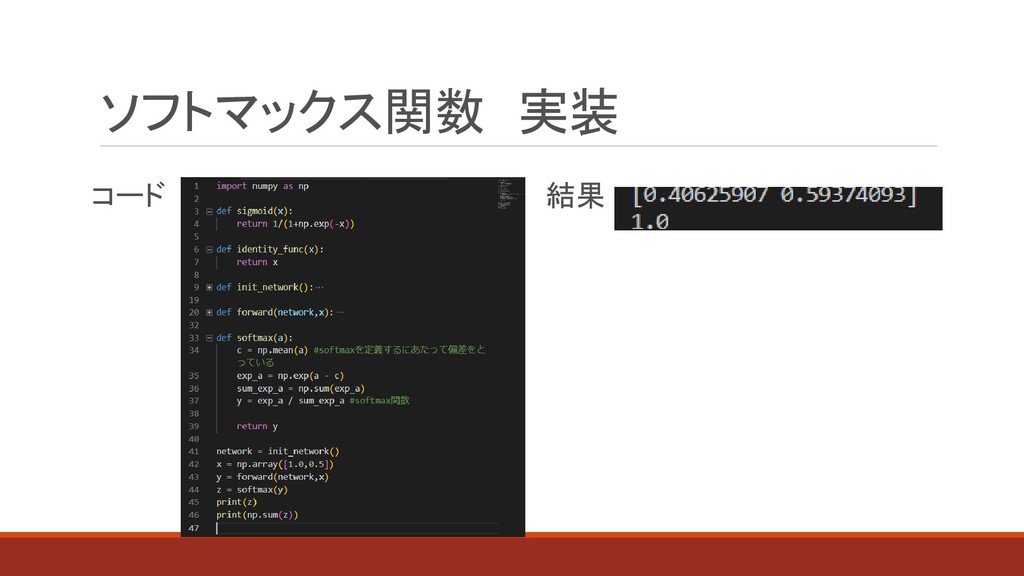
ソフトマックス関数 実装 結果 コード
⚫ニューラルネットの学習とは、訓練データから、重みを更新して、 最適な値にすることである。 ⚫重みを更新するために損失関数といった指標を使う。 ⚫損失関数が最小になるような重みを出すことによって、最適な重 みを求めることができる。 ニューラルネット 学習
⚫損失関数として、二乗和誤差といったものがある。 = 1 2 σ − 2 (y:ニューラルネットの出力,t:教師データ) ⚫教師データを正解のデータには1をそれ以外には0を出力する表 記法をone-hot表現という
y = [0.1,0.05,0.6,0.0,0.05,0.1,0.0,0.1,0.0,0.0] t = [0,0,1,0,0,0,0,0,0,0] One-hot表現と二乗和誤差
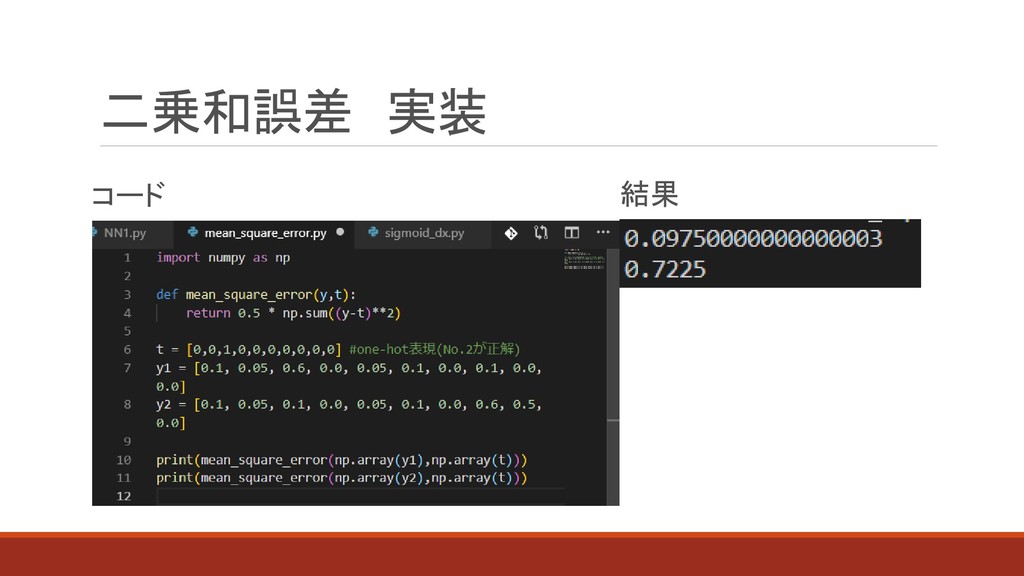
二乗和誤差 実装 結果 コード
⚫損失関数として、交差エントロピー誤差といったものがある。 = − σ log (y:ニューラルネットの出力,t:教師データ) ⚫さっき考えたone-hot表現で考える y = [0.1,0.05,0.6,0.0,0.05,0.1,0.0,0.1,0.0,0.0]
t = [0,0,1,0,0,0,0,0,0,0] ニューラルネットの出力が0.6の場合、交差エントロピー誤差は -log0.6=0.51となって、出力が正しく考えられる場合小さい値になる。 交差エントロピー誤差
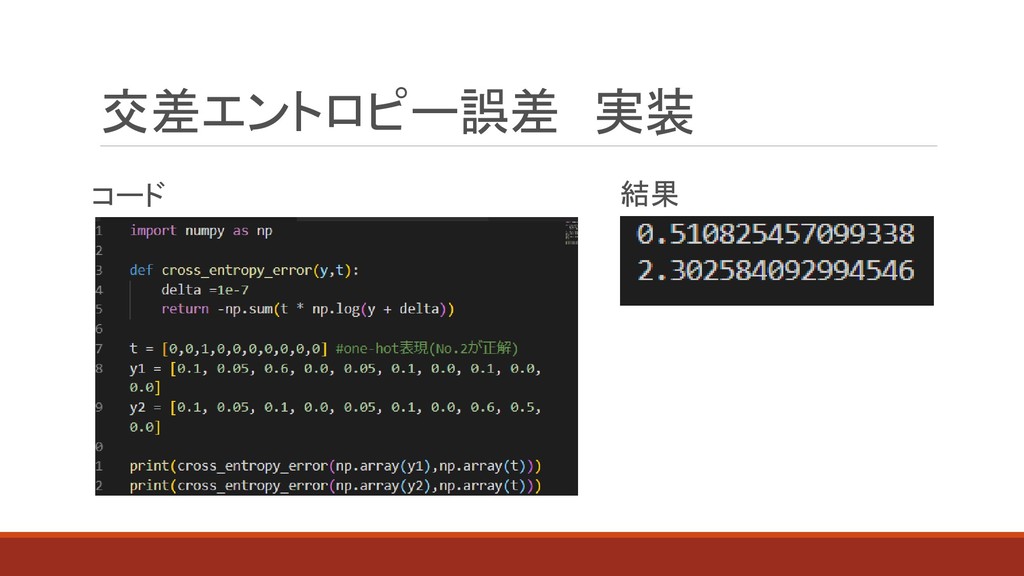
交差エントロピー誤差 実装 結果 コード
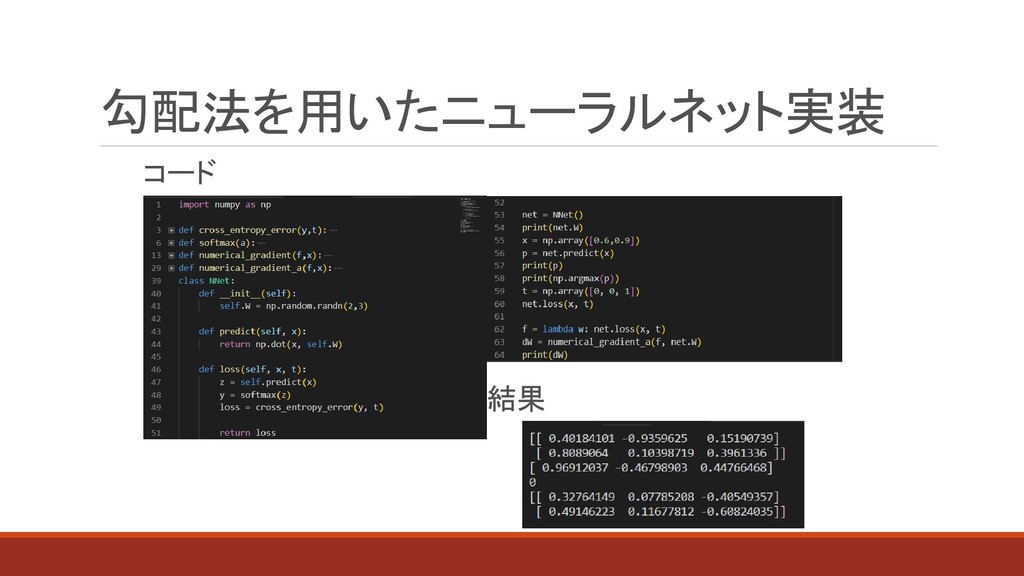
⚫損失関数が最小になる値をとるパラメータを学習時に見つけるの は難しいため、勾配を用いてできるだけ小さな値を使う。 ⚫勾配法は、現在地から勾配の方向に進み続け、関数の値を徐々 に減らしていく方法。 = − η この時のηをニューラルネットの学習率という 勾配法
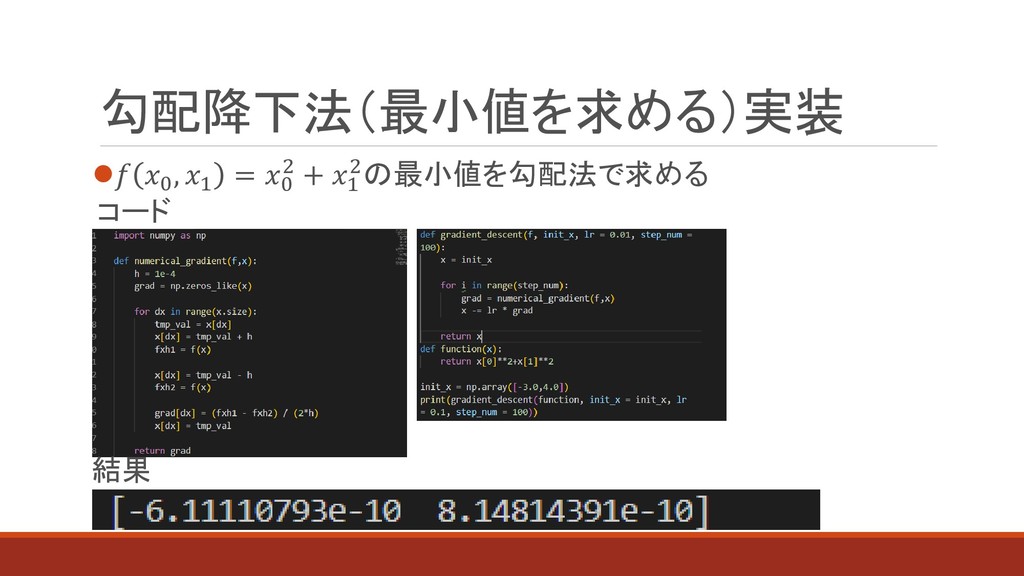
⚫ 0 , 1 = 0 2 + 1 2の最小値を勾配法で求める
勾配降下法(最小値を求める)実装 コード 結果
⚫ニューラルネットの勾配とは、重みパラメータに関する損失関数の 勾配である。とある重みWに対する損失関数Lがあった場合、その 勾配は とあらわすことができる。 ⚫重みのパラメータWの勾配dWが負の値であった場合、その値を 重みに更新してあげ、正の値であった場合、重みからその値を引け ば、損失関数を減らすことができる。 ニューラルネットの勾配
コード 勾配法を用いたニューラルネット実装 結果
宿題:活性化関数 線形関数であった 場合 ⚫活性化関数が線形関数であった場合 ℎ = これが3層のニューラルネットだった場合 ℎ ℎ ℎ
= 3 = 3 となるaが存在してしまう。⇒単層パーセプトロンと一緒
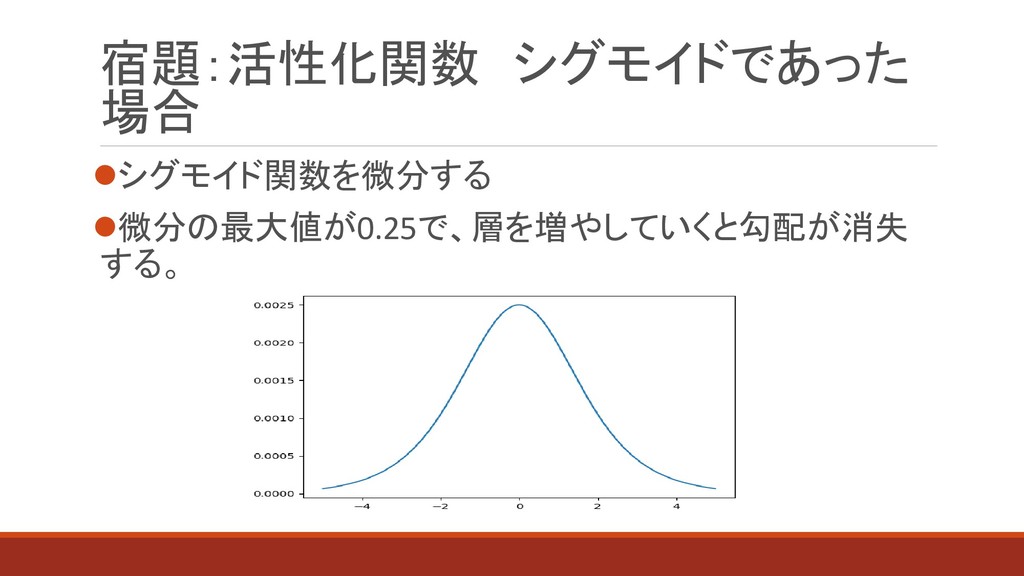
宿題:活性化関数 シグモイドであった 場合 ⚫シグモイド関数を微分する ⚫微分の最大値が0.25で、層を増やしていくと勾配が消失 する。
宿題:活性化関数 ReLUであった場合 ⚫微分されても活性化関数は ℎ′ = ቊ 1 ( > 0)
0 ( < 0) そのため、勾配消失が防げるため、ReLU関数が使われるこ とが多い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![⚫損失関数として、交差エントロピー誤差といったものがある。 = − σ log (y:ニューラルネットの出力,t:教師データ) ⚫さっき考えたone-hot表現で考える y = [0.1,0.05,0.6,0.0,0.05,0.1,0.0,0.1,0.0,0.0]](https://files.speakerdeck.com/presentations/dd70d19d311c414697a57684abb359a7/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}