## AWSとKotlinで作るクローラー
azihsoyn
2019/02/26
scouty Crawler Night 2019
---
## 自己紹介
[](https://twitter.com/azihsoyn)
{:.left-column}
* [ふそやん@azihsoyn](https://twitter.com/azihsoyn)
* 趣味
* 釣り
* アニメ
* 今期はかぐや様は告らせたい
* 上野さんは不器用
* 業務ではサーバーサイドエンジニア
* Go
* Kotlin
* [rehash.fm](http://rehash.fm)っていうポッドキャストやってます
{:.right-column .medium}
---
---
[グノスポ](https://gunosy-sports.com/)もあります!
---
---
テックブログもあるので是非読んでみてください
* [導入編](https://tech.gunosy.io/entry/gunosy-sports1)
* [AppSync編](https://tech.gunosy.io/entry/gunosy-sports2)
* [デザイン編](https://tech.gunosy.io/entry/gunosy-sports3)
* [サーバー編](https://tech.gunosy.io/entry/gunosy-sports4)
* [インフラ編](https://tech.gunosy.io/entry/gunosy-sports5)
---
## 今回話すこと
* グノスポで作ったクローラーのレシピ
* クローラーの知見
---
## 今回話すクローラーの定義
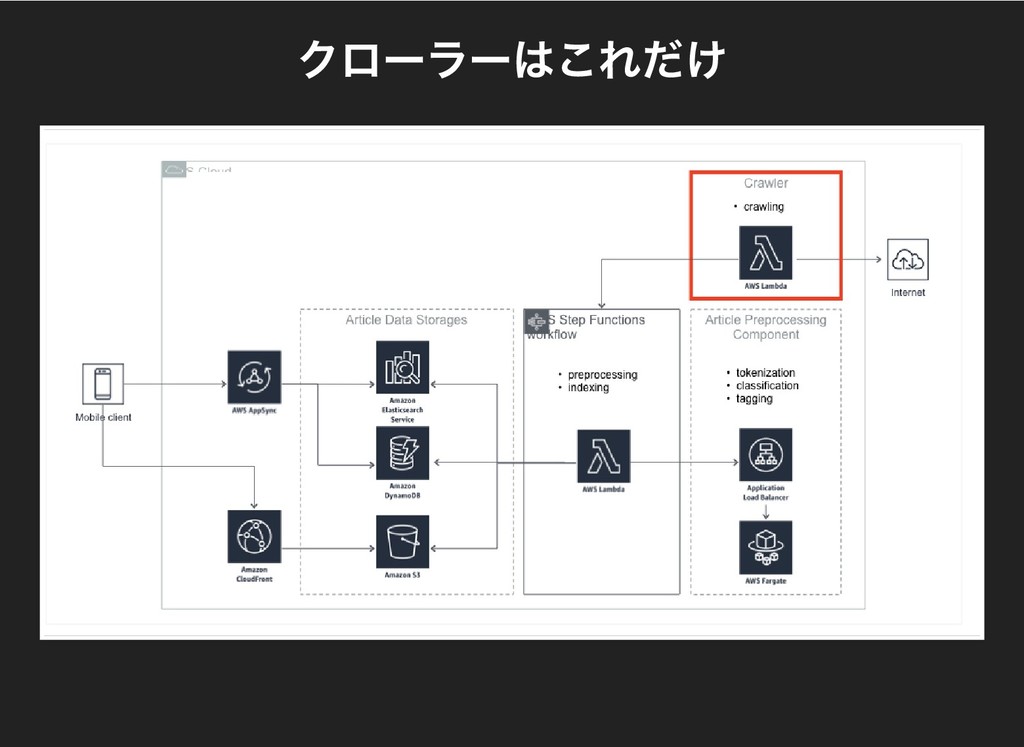
* クローラーは提携メディアのフィードを定期的にクロール
* 提携メディアはグノスポが定めたフォーマット(Atom/RSS2.0)でフィードを作成
(google botみたいに無差別にクロールするわけではない)
---
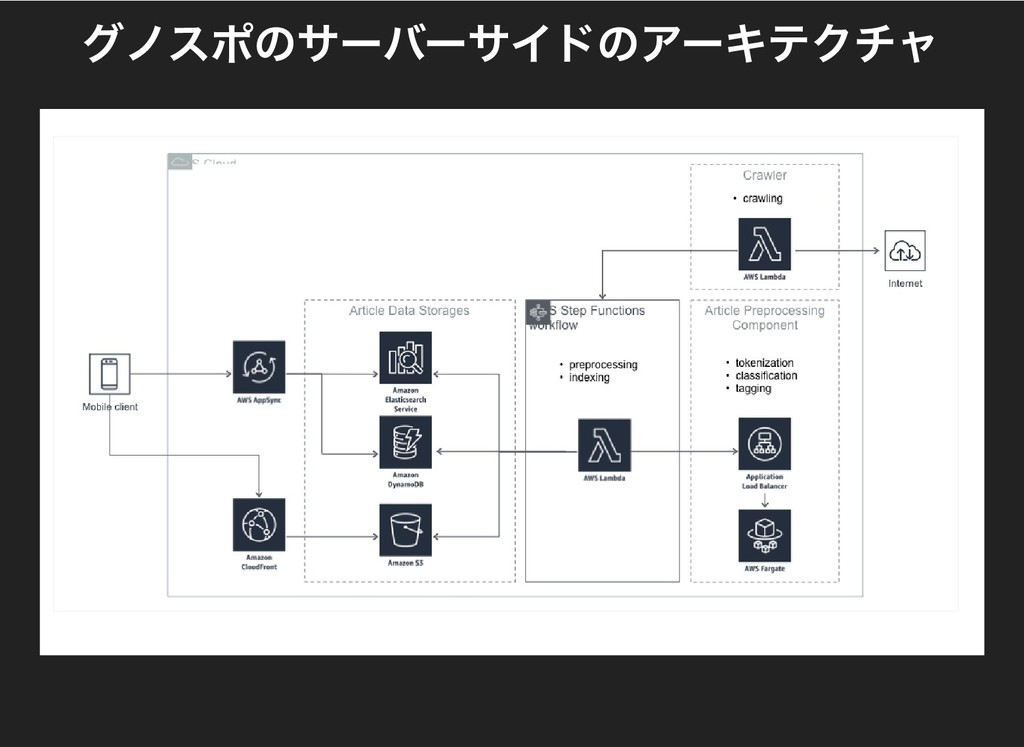
#### グノスポのサーバーサイドのアーキテクチャ

---
#### クローラーはこれだけ

---
## 使っているライブラリ
---
## 使っているライブラリ
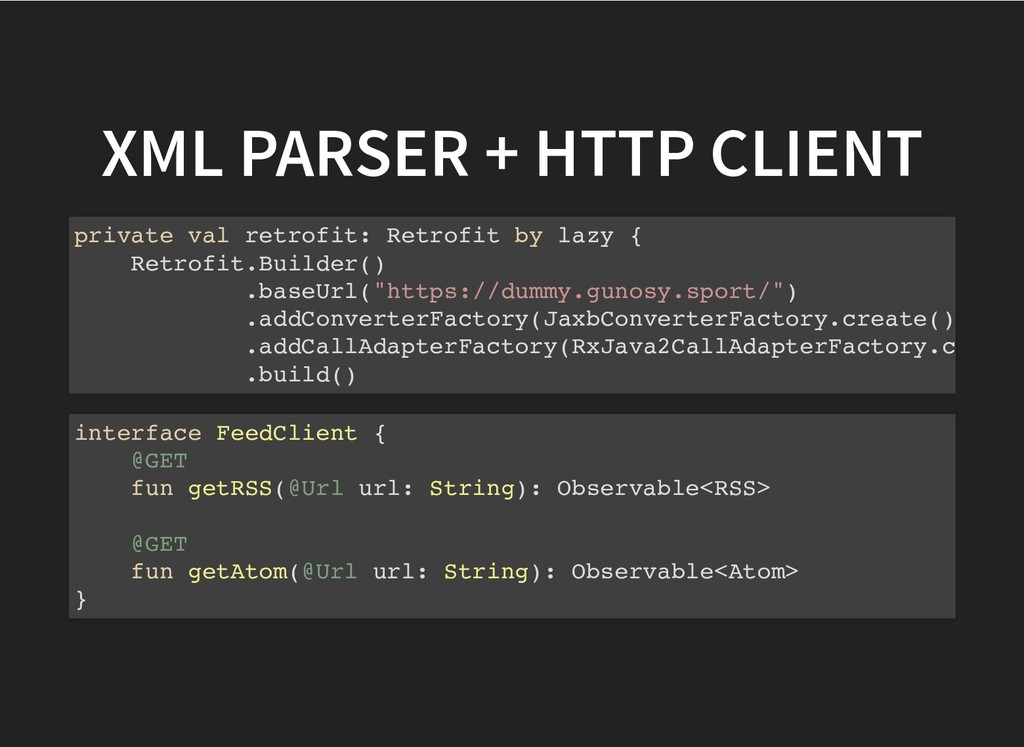
## XML parser + http client
---
## XML parser + http client
## Retrofit + JAXB
---
## XML Parser + http client
retrofit公式のconverterがある
[retrofit-conberers/jaxb](https://github.com/square/retrofit/tree/master/retrofit-converters/jaxb)
---
## XML Parser + http client
```kotlin
private val retrofit: Retrofit by lazy {
Retrofit.Builder()
.baseUrl("https://dummy.gunosy.sport/")
.addConverterFactory(JaxbConverterFactory.create())
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.build()
```
```kotlin
interface FeedClient {
@GET
fun getRSS(@Url url: String): Observable
@GET
fun getAtom(@Url url: String): Observable
}
```
---
## XML Parser + http client
data classでxmlの構造を定義
```kotlin
@XmlAccessorType(XmlAccessType.FIELD)
@XmlRootElement
@JaxbPojo // noarg用annotation
data class RSS(
@XmlAttribute
val version: String,
@JaxbPojo
val channel: Channel
)
```
---
## noargとは
kotlinのdata classにデフォルト引数を書かなくて済むようになるplugin
[no-arg-compiler-plugin](https://kotlinlang.org/docs/reference/compiler-plugins.html#no-arg-compiler-plugin)
---
## XML Parser + http client
呼び出し
```kotlin
retrofit.create(FeedClient::class.java).getRSS(url).subscribe({ rss ->
/* なにか処理 */
}, { error ->
error.printStackTrace()
})
```
---
## その他検討したXML parser
* [retrofit-converter-simplexml](https://github.com/square/retrofit/tree/master/retrofit-converters/simplexml)
* 最近`Deprecated`になった
* [FasterXML/jackson-module-kotlin](https://github.com/FasterXML/jackson-module-kotlin)
* 一部のxmlがパースできなかったため不採用
* javax.xml.parsers
* 一部のxmlがパースできなかったため不採用
---
## HTML parser
---
## HTML parser
## [jsoup](https://mvnrepository.com/artifact/org.jsoup/jsoup)
これはほぼ一択
特にハマることもなく使えた
html内の画像のパスを書き換えたりするのに利用
---
## HTML parser
```kotlin
// 本文内の画像アップロード
val doc = Jsoup.parse(rawArticle.content, "UTF-8")
doc.select("img").map { img ->
try {
val image = uploadImage(img.attr("src").toString())
img.attr("src", image.url)
img.attr("data-gs-width", image.width.toString())
img.attr("data-gs-height", image.height.toString())
} catch (e: Exception) {
e.printStackTrace()
}
}
```
---
## ファイル形式検出
---
## ファイル形式検出
## [mime-util](https://mvnrepository.com/artifact/eu.medsea.mimeutil/mime-util)
* 画像のファイル識別に利用
* アプリが対応している画像だけをサーバーに保存
* メディアが間違えておかしなファイルを指定してしまったときに弾く
---
## 使ってるAWSサービス
---
## クローリング編
---
## lambda
* クロールする処理をlambda関数として実行
* java 8 ランタイム
* メトリクスも自動で取れるので監視などが楽
---
## rekognition
* 画像をアプリのリストに表示する際に選手の顔がちゃんと表示されるようにする
* 認識に1秒もかからないぐらい早い
---
## DynamoDB
* クロールした各種情報の保存
* 提携メディアのfeedテーブル
* クロールした記事のarticleテーブル
* 試合情報
* チーム情報
* ...etc
---
## DynamoDB
* 現在lambdaから気軽に使えるデータ永続化サービスは実質DynamoDBしか選択肢がない
* Data API for Aurora Serverless が東京リージョンにきたら一部乗り換える予定🙏
参考: https://dev.classmethod.jp/cloud/aws/amazon-aurora-serverless-avaible-http-endpoint/
---
## DynamoDB
* DynamoDBを使う上で問題になるのはどうやってユニークなIDを発番するか
* articleごとに一意なキーが必要
今回は[snowflake](https://www.slideshare.net/moaikids/20130901-snowflake)をカスタマイズして利用
---
## snowflakeとは
* twitterが採用している(いた?) id生成ロジック
* グノスポではtimestamp部 + feed_id部 + incr部から生成
* lambdaは必ずfeed_id毎に実行
* 同じfeed_idでlambdaが同時に走らないことが前提
---
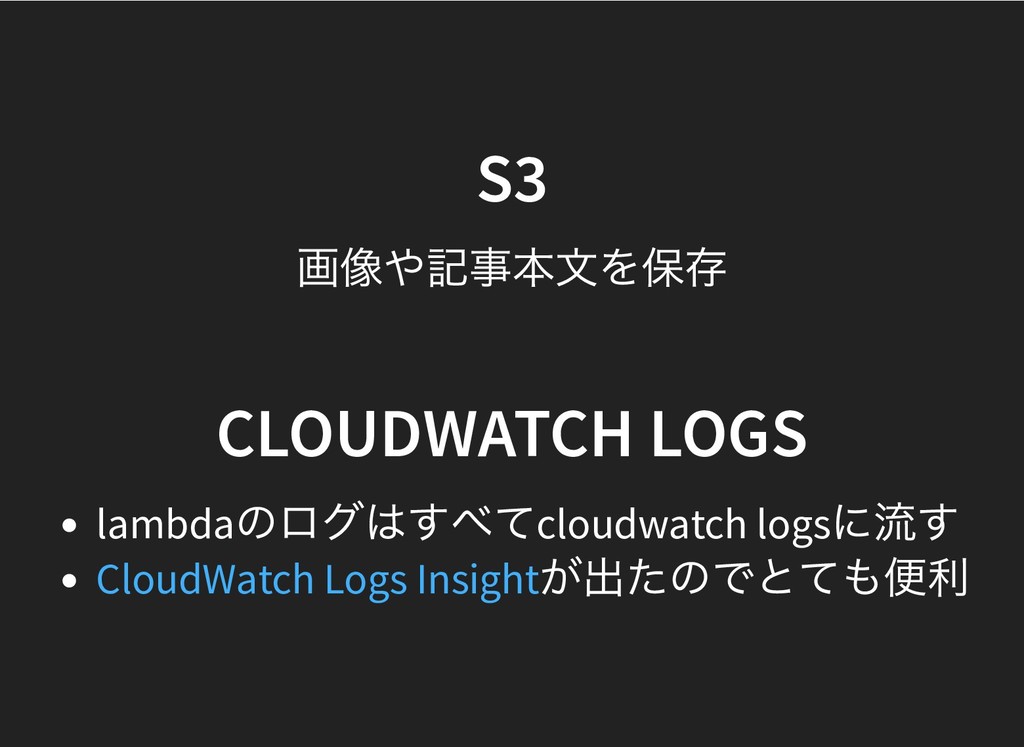
## S3
画像や記事本文を保存
## CloudWatch Logs
* lambdaのログはすべてcloudwatch logsに流す
* [CloudWatch Logs Insight](https://aws.amazon.com/jp/blogs/news/new-amazon-cloudwatch-logs-insights-fast-interactive-log-analytics/)が出たのでとても便利
---
## スケジューリング編
---
## CloudWatch Events
* クローラー毎に異なるスケジュールを設定
* コンテンツの特性に合わせる
* 試合中の情報は1分(最短)間隔
* 試合のスケジュールは1時間
* 記事の更新は10分
とか
---
## SQS
* 同じlambdaを異なるパラメータで同時に実行したいときに利用
* feed毎の記事の収集
* 試合中のデータの更新
* cludwatch events → lambda(ジョブをキューイング) → SQS → lambda(クロール)
* [Amazon SQS FIFO](https://aws.amazon.com/jp/blogs/news/amazon-sqs-fifo-tokyo/)を使うと[メッセージ重複排除](https://docs.aws.amazon.com/ja_jp/AWSSimpleQueueService/latest/SQSDeveloperGuide/using-messagededuplicationid-property.html)ができる
---
### 作り方終わり
---
### 知見の話
---
### クローラー、肥大化してませんか?
---
### サービスに新しい機能やコンテンツを追加するためにクローラーは改修が多くなりがち
---
* 増えるif文
* 増えるフラグ
* 増えるエンティティ
* 増える依存関係
* 増えるデータベース
* ...etc
---
### 管理できていれば問題ない
---
今流行りのクリーンアーキテクチャ

---
### いい本なので読みましょう
(クリーンアーキテクチャでクローラーを作りましょうという話じゃないです)
---
## 責務を分ける
---
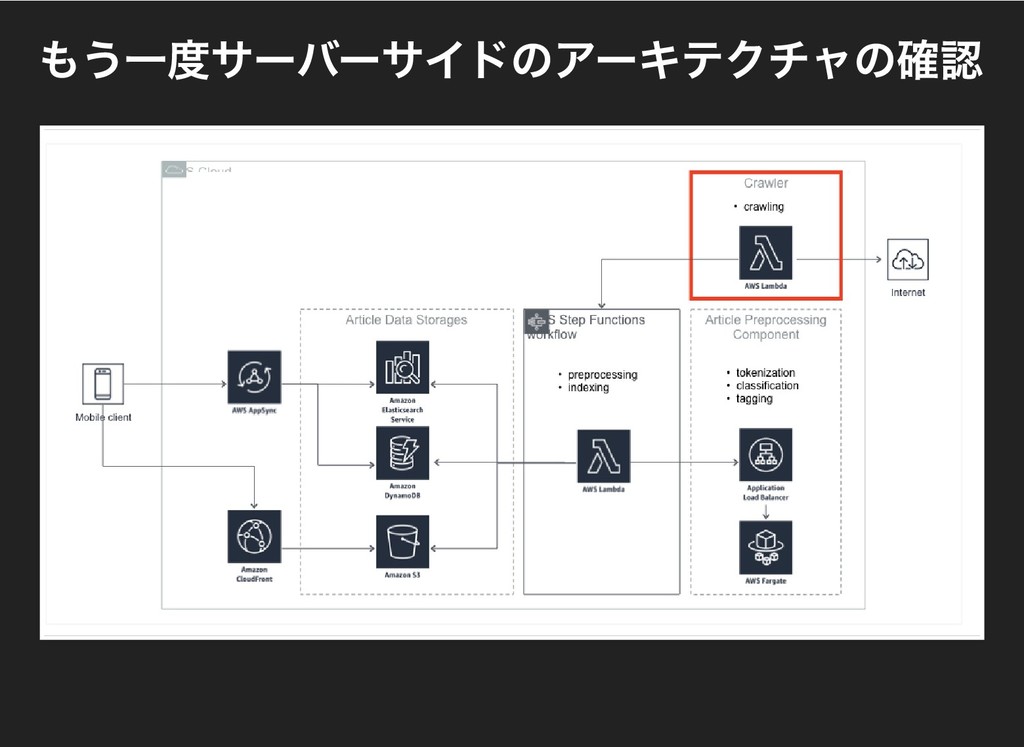
#### もう一度サーバーサイドのアーキテクチャの確認

---
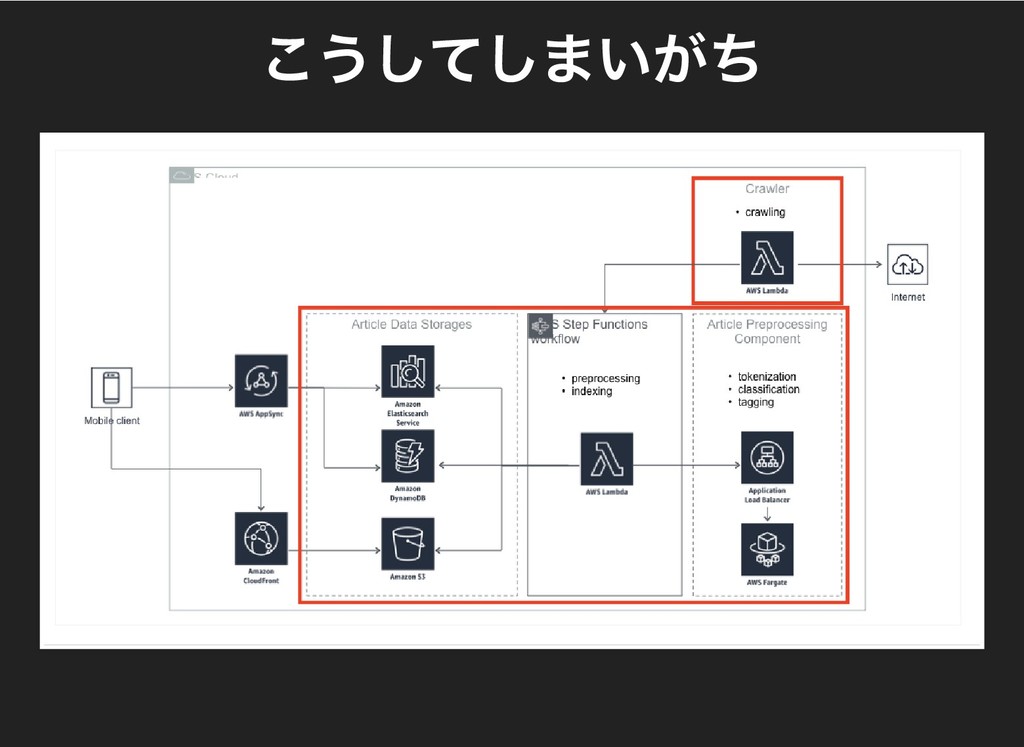
### こうしてしまいがち

---
### 全部クローラー!!
---
* 今回設計の段階でクロールした生データとアプリケーションから参照されるデータは別にしようというルールにした
(深く考えていたわけではないがAppSyncを使う上でこうなった)
* アプリケーションから参照されるデータはpre processというフローで生成する
* クローラーはxmlをパースして画像をS3にアップロードしてDynamoDBにデータを保存することに専念する
---
### クローラーはxmlをパースして画像をS3にアップロードしてDynamoDBにデータを保存することに専念する
---
# シンプル!!
---
# まとめ
---
## 使ってるライブラリ
* Retrofit + JAXB
* Jsoup
* mime-util
* noarg
---
## 使ってるAWSサービス
* lambda
* SQS
* CloudWatch Events
* CloudWatch Logs
* S3
* DynamoDB
* rekognition
---
## 責務を分ける
---
## Thanks!
---
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}