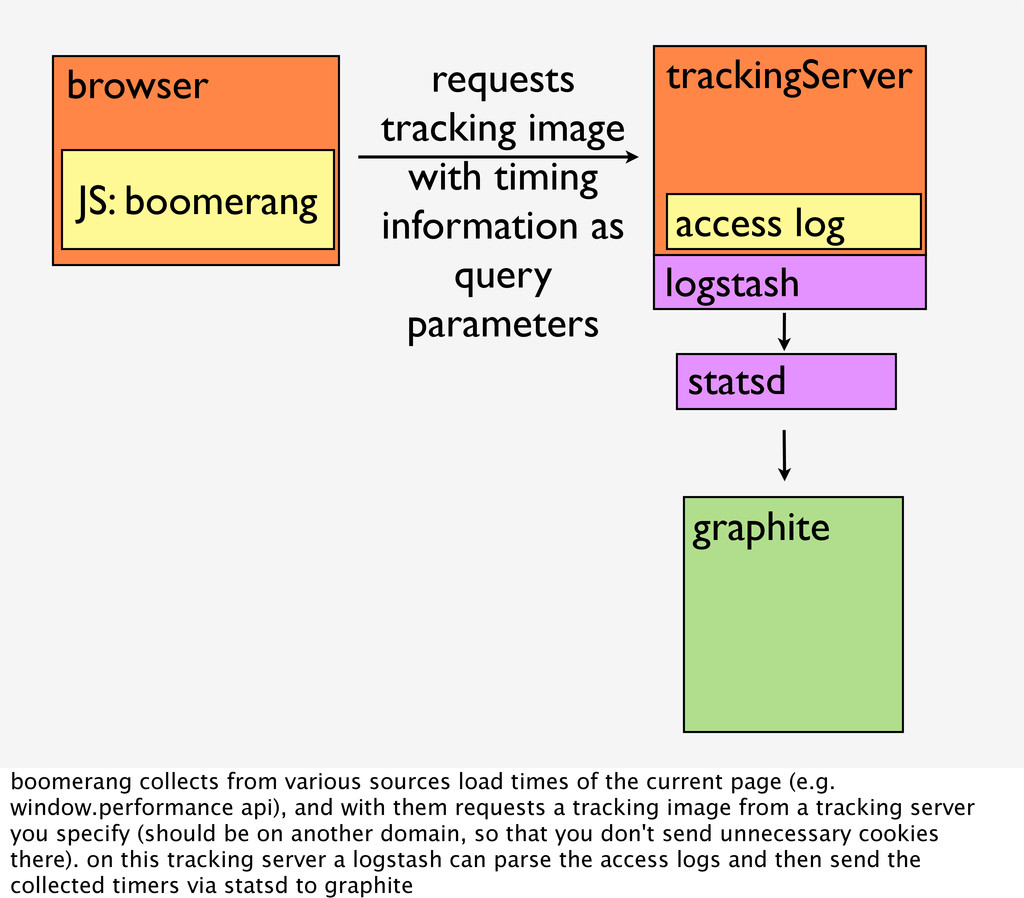
Do you know what is happening in your web application right now, this second, how many requests, logins, exceptions you have, how many and what data your users are generating and what the click through rate of each of your registration step is? Or do you know exactly which exception with which stack trace caused the error your users are seeing? If not, this talk will show how you can easily measure and log everything that happens in your application with the help of open source tools, such as Graphite, StatsD, Graylog2 and Logstash, without influencing your production environment.
Dutch PHP Conference 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![192.168.56.1 - - [09/Jul/2012:19:18:19 +0200] "GET /rg_trunk/webroot/c/af10c/ images/template/rg_logo_default.png HTTP/ 1.1"](https://files.speakerdeck.com/presentations/c182c960b26f013023443eee7fd6b067/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
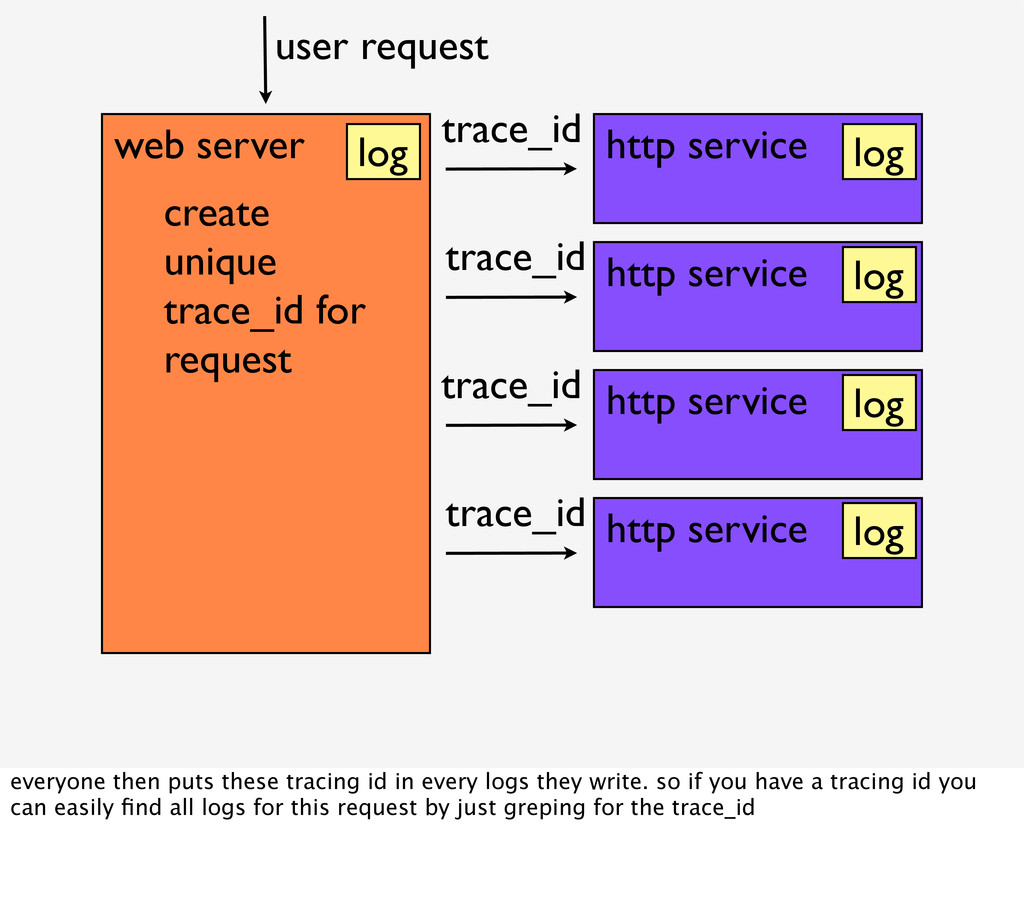{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
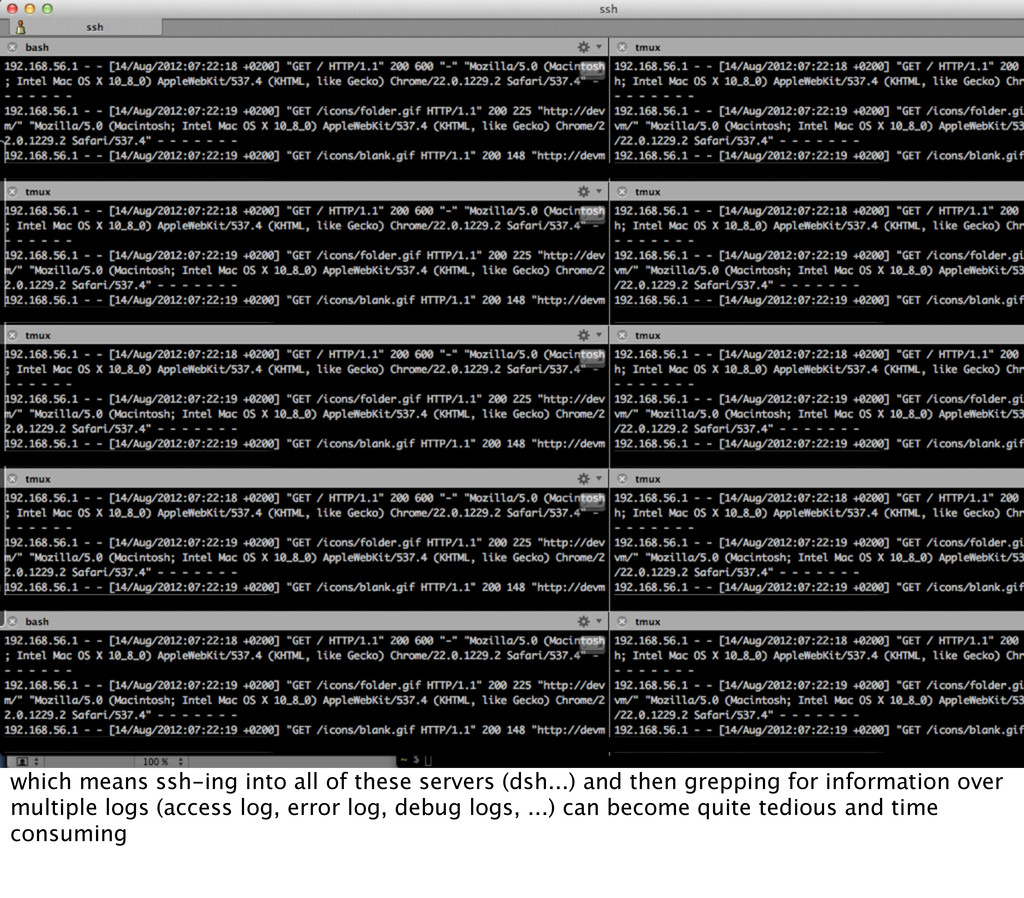
{kind=link}
{kind=link}
{kind=link}
{kind=link}
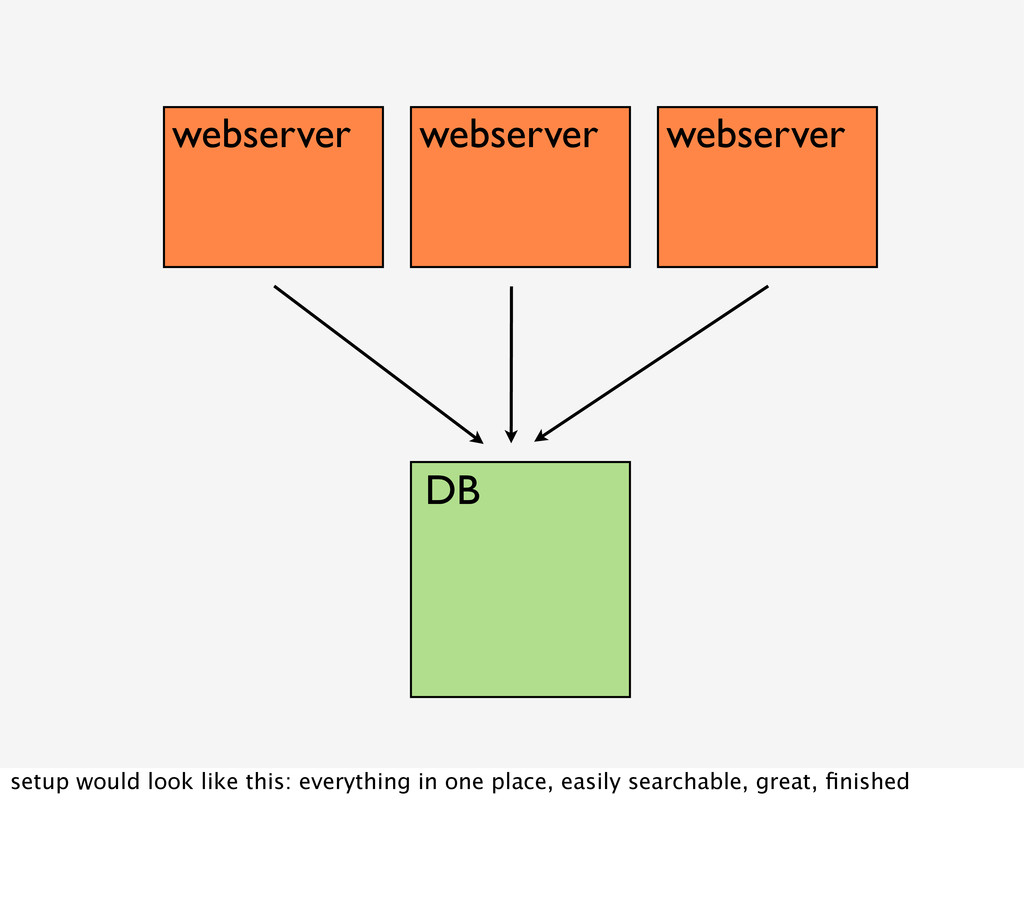{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
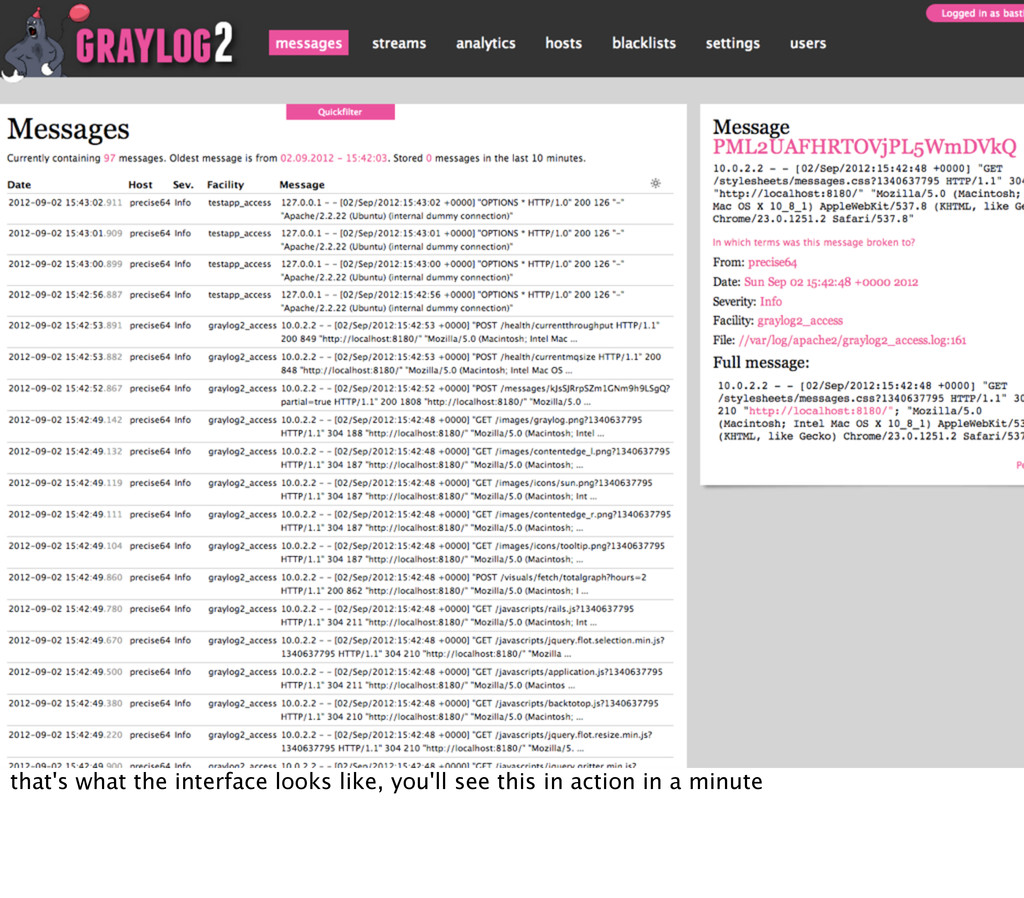{kind=link}
{kind=link}
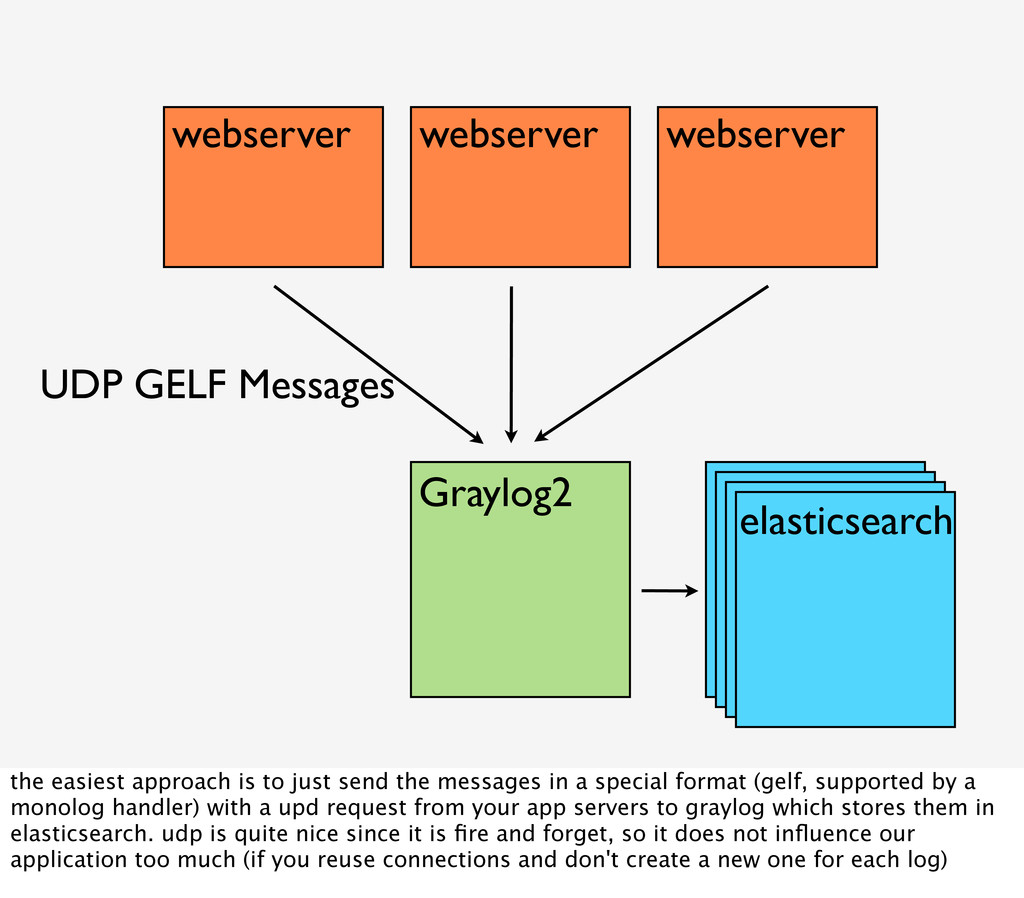{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
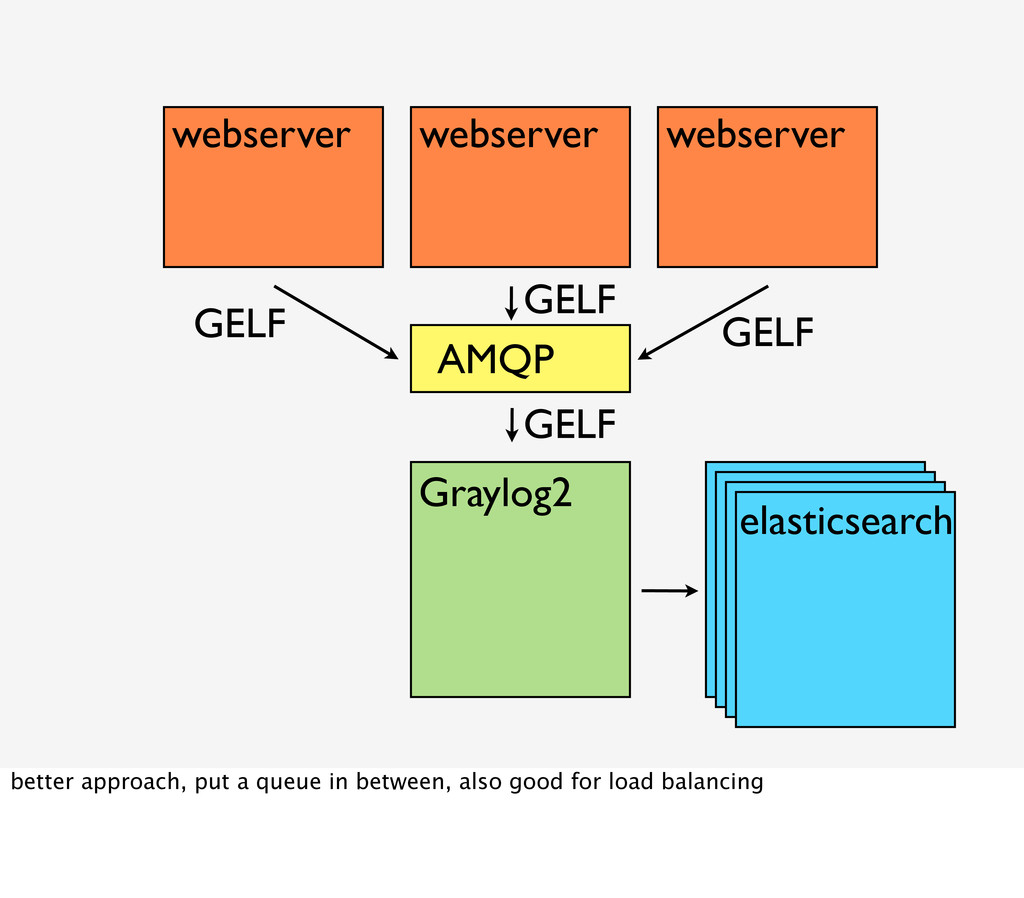{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![filter{ grok { match => ["@source", "\/%{USERNAME:facility}\.log$"] } grok {](https://files.speakerdeck.com/presentations/c182c960b26f013023443eee7fd6b067/slide_92.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
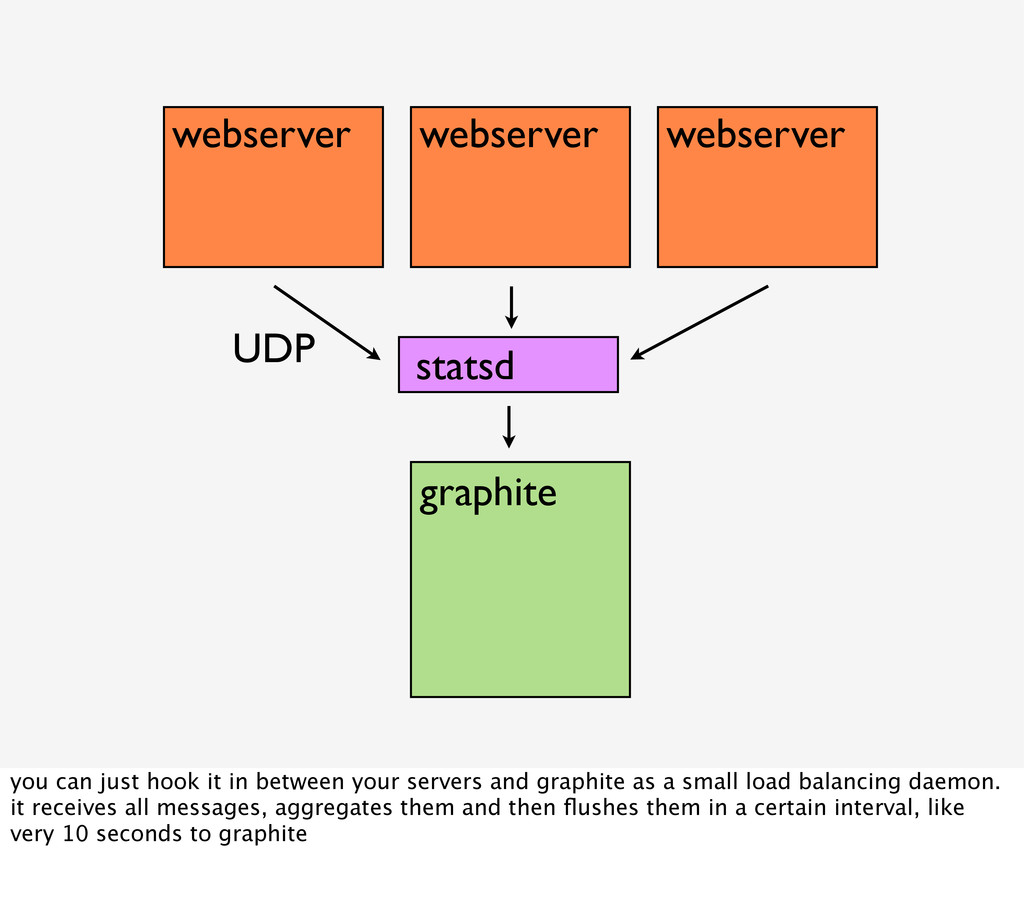{kind=link}
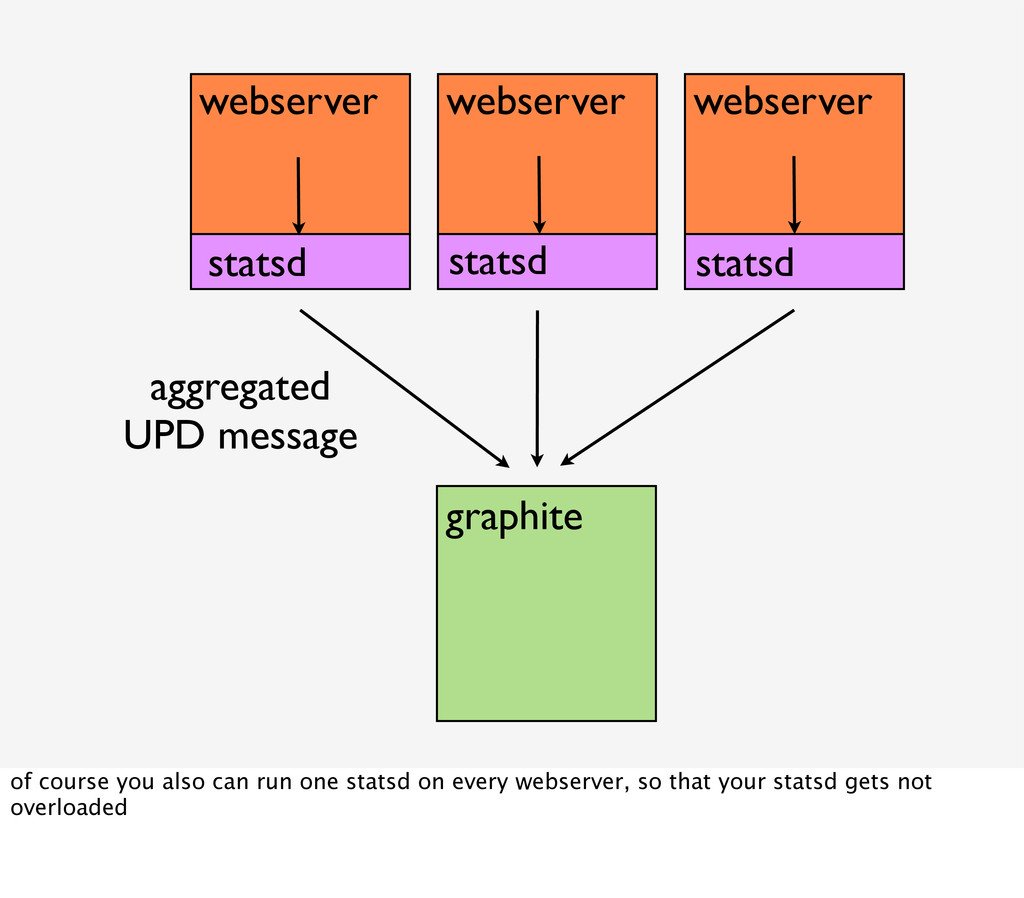{kind=link}
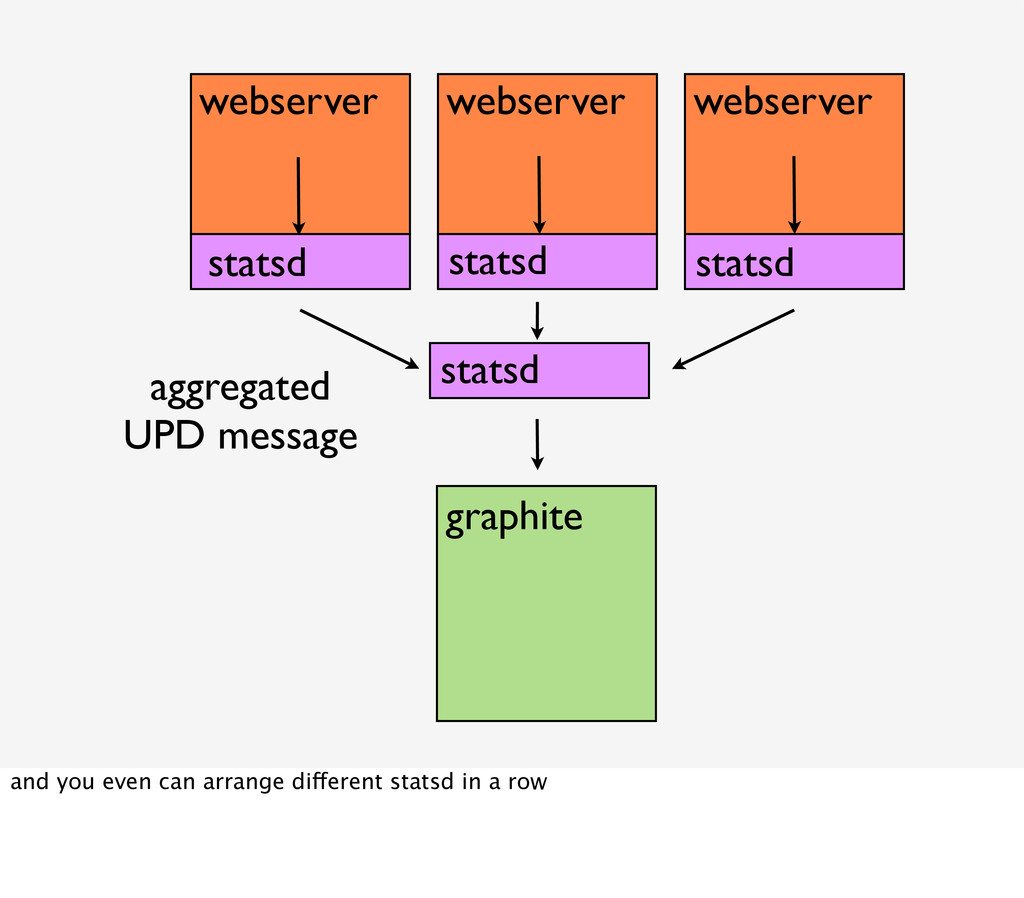{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![192.168.56.1 - - [09/Jul/2012:19:18:19 +0200] "GET /rg_trunk/webroot/c/af10c/ images/template/rg_logo_default.png HTTP/ 1.1"](https://files.speakerdeck.com/presentations/c182c960b26f013023443eee7fd6b067/slide_114.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![http://twitter.com/BastianHofmann http://profiles.google.com/bashofmann http://lanyrd.com/people/BastianHofmann http://speakerdeck.com/u/bastianhofmann https://github.com/bashofmann https://www.researchgate.net/profile/Bastian_Hofmann/ [email protected] thanks, you can](https://files.speakerdeck.com/presentations/c182c960b26f013023443eee7fd6b067/slide_120.jpg){kind=link}