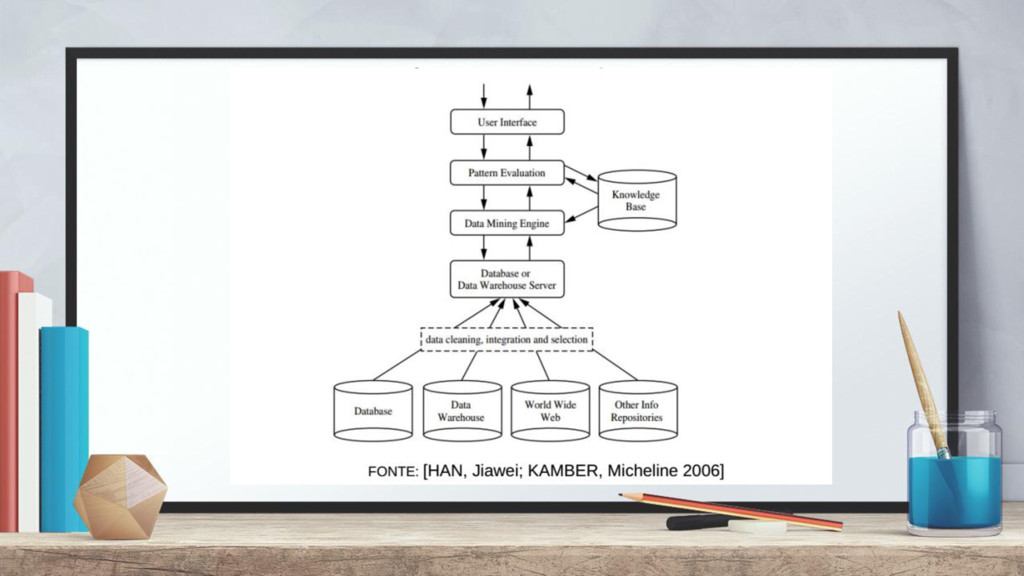
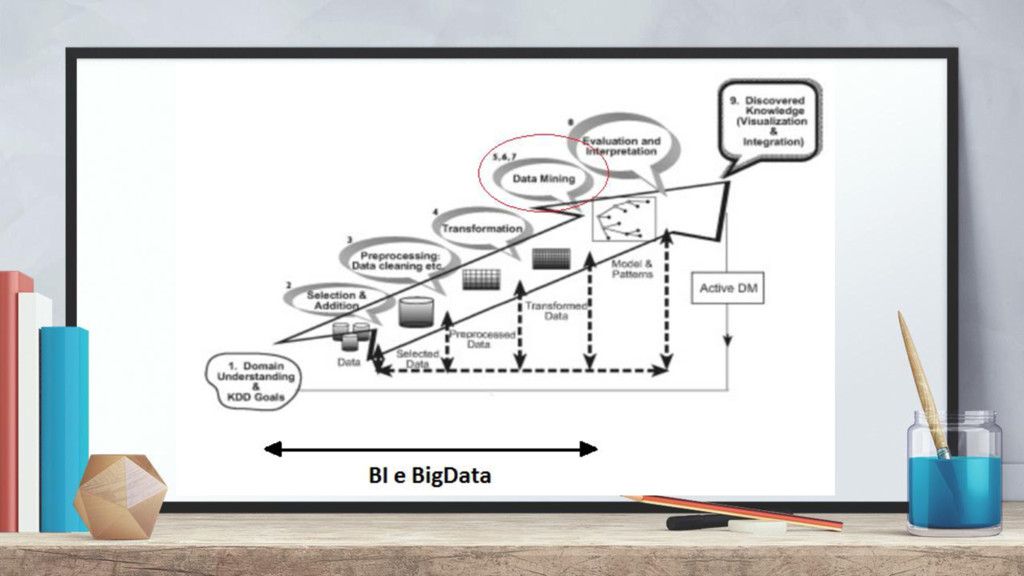
Técnica estatística. + Envolve o aprendizado de máquina. + Etapa do KDD (Knowledge Discovery in Database) O que é Data Mining? Objetivos: + Encontrar padrões entre os dados. + Auxiliar na descoberta de conhecimento. + Auxiliar de maneira ativa na tomada de decisão.
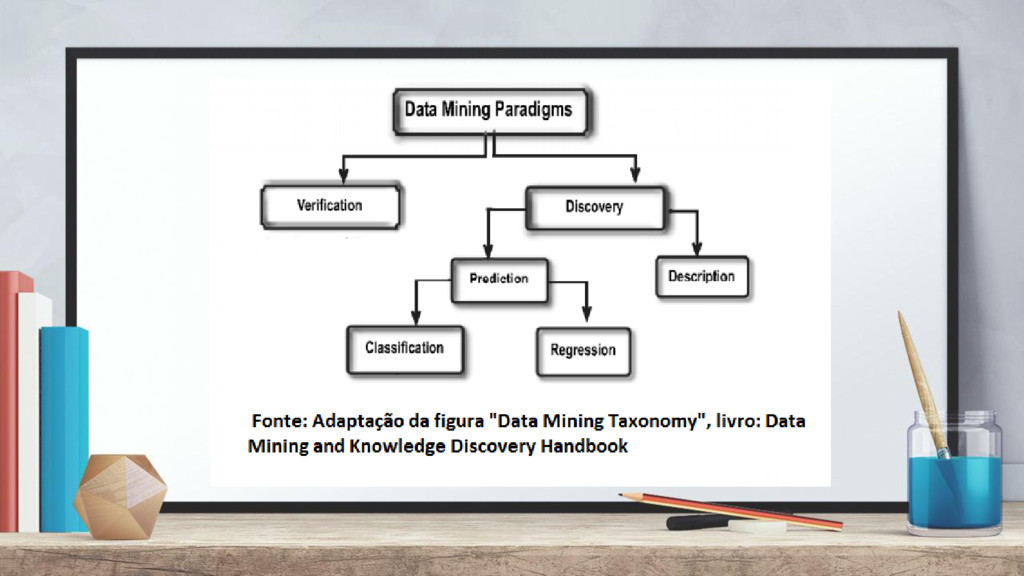
+ Não possuem treinamento. Paradigma Descritivo Exemplos: + Agrupamento (clustering) + Dados são organizados através da interpretação dos próprios dados.
+ Possuem treinamento. + Classes são pré-definidas para cada padrão Paradigma Preditivo Exemplos: + Redes Neurais Artificiais + Conjunto de treino serve de base fornecer conhecimento a rede. + Novos padrões não conhecidos serão preditos.
abordado: reclamações de clientes sobre os serviços prestados pelas empresas brasileiras. + Levantamento feito pela Secretaria do Consumidor, período julho de 2014 a junho de 2015. Análise de Perfis usando Algoritmo de agrupamento
Consumidor, período julho de 2014 a junho de 2015. b) Contexto da base: informações cadastrais de clientes, informações das empresas reclamadas, informações das reclamações dos clientes. c) Base inicial: 23 colunas e 119392 registros. d) Após a limpeza da base: 21 colunas e 77752 registros. e) Adaptações de campos numéricos para categóricos usando fórmula de Sturges, usada para criação de intervalos. Ex: campos faixa etária, tempo de resposta em dias. Análise de Perfis usando Algoritmo de agrupamento
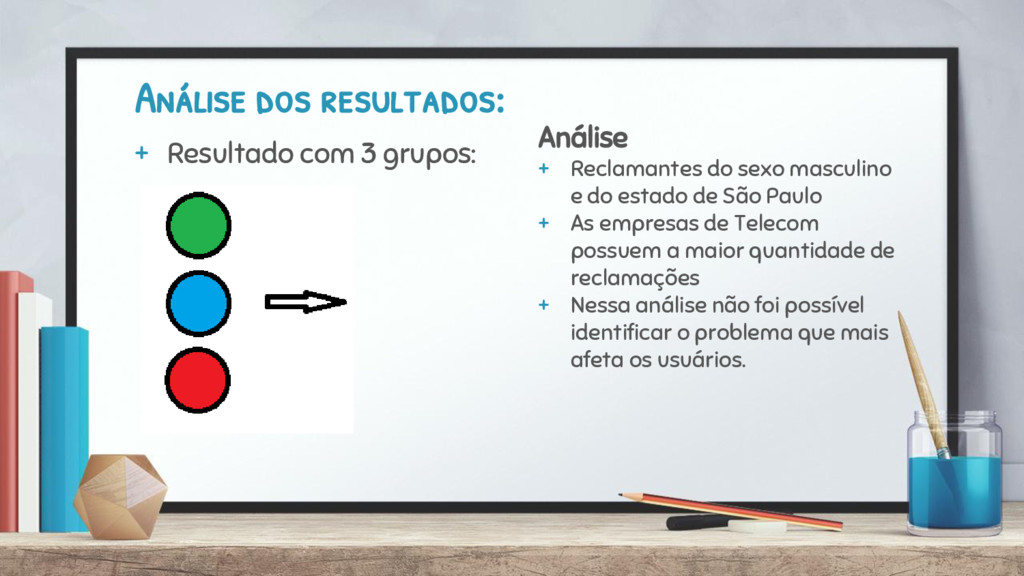
ferramenta open source WEKA. b) Simple K-Means é derivado do K-Means. c) Interpreta dados categóricos e dados numéricos. d) Simple K-Means é um algoritmo de particionamento, e por isso necessita do número de clusters finais para sua execução. + Testes realizados: a) Primeiro: teste realizado para saber o limite do algoritmo. Até que ponto os clusters seriam diferentes? b) Escolha da quanitdade de grupos (clusters) baseada no limite do algoritmo. c) Análise dos grupos (clusters) encontrados. Análise de Perfis usando Algoritmo de agrupamento
Reclamantes do sexo masculino e do estado de São Paulo + As empresas de Telecom possuem a maior quantidade de reclamações + Nessa análise não foi possível identificar o problema que mais afeta os usuários.
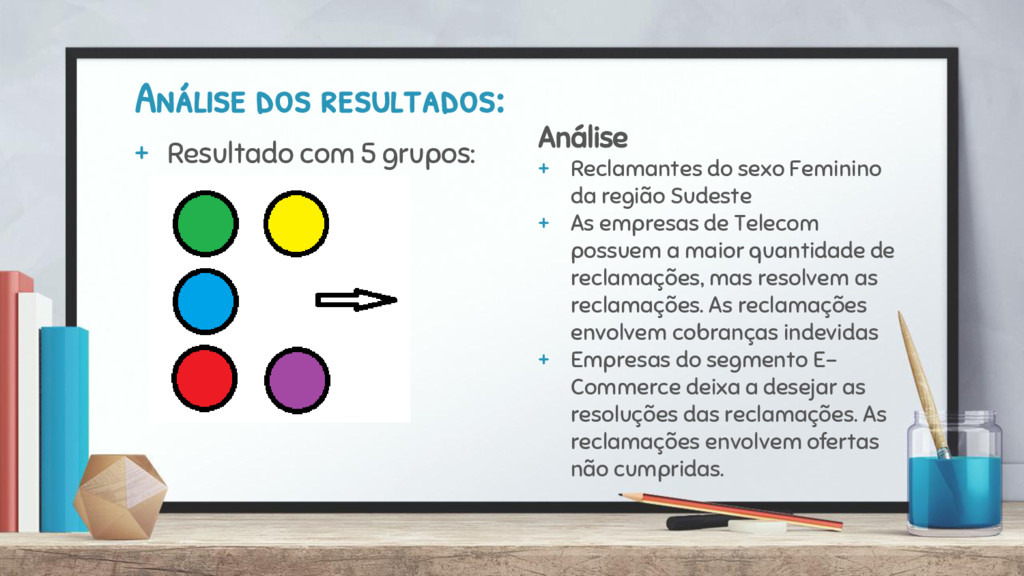
Reclamantes do sexo Feminino da região Sudeste + As empresas de Telecom possuem a maior quantidade de reclamações, mas resolvem as reclamações. As reclamações envolvem cobranças indevidas + Empresas do segmento E- Commerce deixa a desejar as resoluções das reclamações. As reclamações envolvem ofertas não cumpridas.
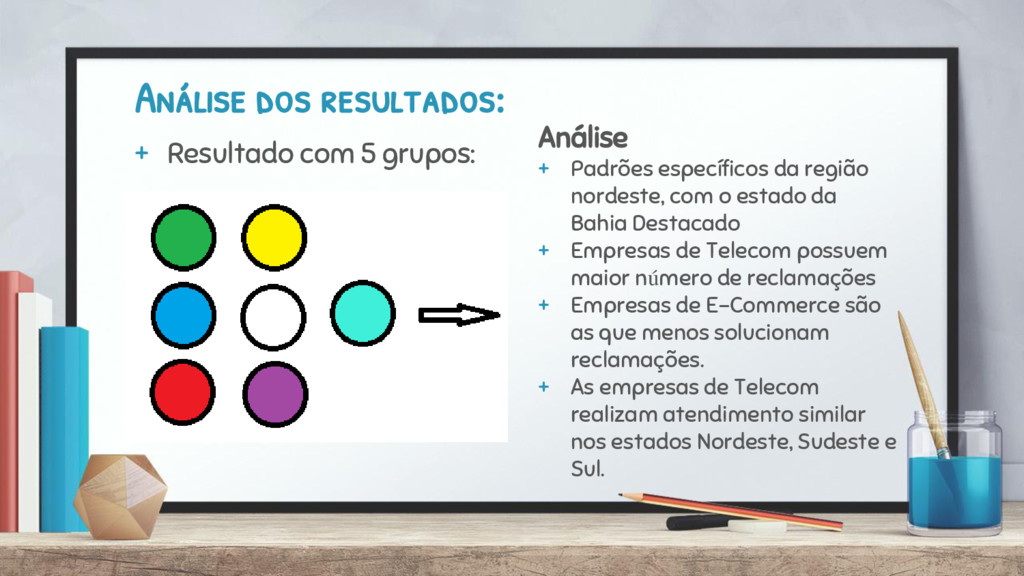
Padrões específicos da região nordeste, com o estado da Bahia Destacado + Empresas de Telecom possuem maior número de reclamações + Empresas de E-Commerce são as que menos solucionam reclamações. + As empresas de Telecom realizam atendimento similar nos estados Nordeste, Sudeste e Sul.
reclamações. 2. As empresas de Telecom, resolvem as reclamações 3. As empresas de E-Commerce NÃO resolvem as reclamações abertas. 4. As empresas de Telecom atendem de forma semelhante, Nordeste, Sudeste e Sul. Conclusões Sobre perfil de clientes: 1. Clientes do sexo masculino e feminino da região Sudeste e Nordeste do país.
especialista de domínio, um especialista da área de análise de consumidores. + A base de dados continham mais informações sobre as empresas do que informações dos clientes. + Dessa maneira, as conclusões e resultados, foram voltados na maioria para as empresas. Comentários
abordado: setor Jurídico de um banco deseja antecipar o resultado de processos jurídicos envolvendo seus produtos, empréstimo e cartão de crédito. + Base de Dados: processos jurídicos que envolvem os dois tipos de produtos, empréstimo e cartão de crédito. Período, 5 anos de dados. + Tratamento na base: seleção de variáveis relevantes para o contexto dos dois produtos. Predição de Processos Jurídicos usando Redes Neurais.
ou NÃO apenas. A Regressão Logística diz 70% de ser SIM e 30% de ser NÃO. c) Criação de dois modelos: 1. Modelo Preditivo para Empréstimo: + Base balanceada amostral para treinamento: 628 registros, 50% de processos com causa perdida e 50% de processos com causa ganha. 2. Modelo Preditivo para Cartão: + Base balanceada amostral para treinamento: 1648 registros, 50% de processos com causa perdida e 50% de processos com causa ganha. Predição de Processos Jurídicos usando Redes Neurais
processos envolvendo o produto Empréstimo. 2. Modelo Preditivo para Cartão: + Base para simulação: 3299 processos envolvendo o produto Cartão. + OBS: a) as bases de testes e simulação, possuem as mesmas variáveis; b) o setor jurídico deseja saber o % Perda dos processos. Predição de Processos Jurídicos usando Redes Neurais.
jurídico. 2. O processo de carga da base e entrada das variáveis já está sendo automatizado. 3. O modelo será melhorado para aumentar a sua acertividade. 4. A base de conhecimento do modelo será incrementada de tempos em tempos. 5. Ao fim da automação do processo de carga, o setor jurídico irá utilizar os modelos como ferramenta de trabalho na predição de processos. Comentários
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigado! Contatos: + [email protected] + https://br.linkedin.com/in/tiago- rodrigues-l-santos-99112339](https://files.speakerdeck.com/presentations/e804e42c4f264a7aab6b9b3ad1d36a9c/slide_35.jpg){kind=link}