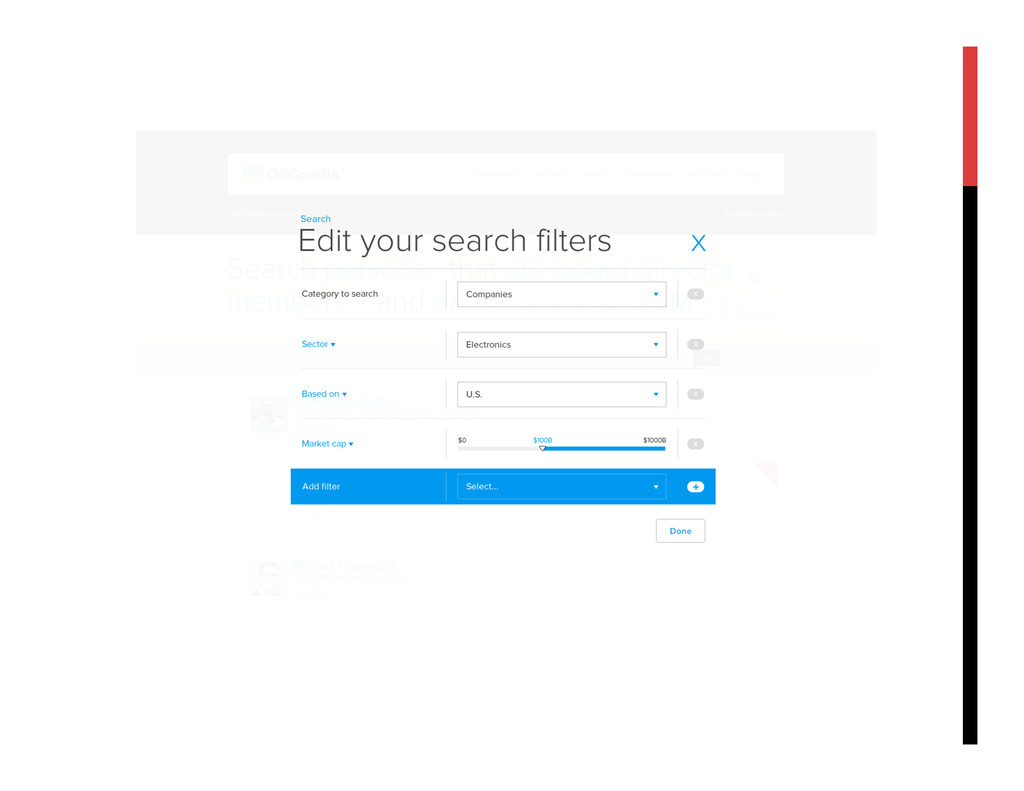
OrgPedia will be a comprehensive, open, public data resource and analytic engine for understanding the corporate world. It will collect data about the world’s corporations – who they are, who owns them, who they own, and how and where they operate. It will provide a website, search engine and analytic tools for regulators, researchers, and many others, including corporations themselves, to use this data both to look up information about individual corporations, and also to research interrelationships between companies and industries.
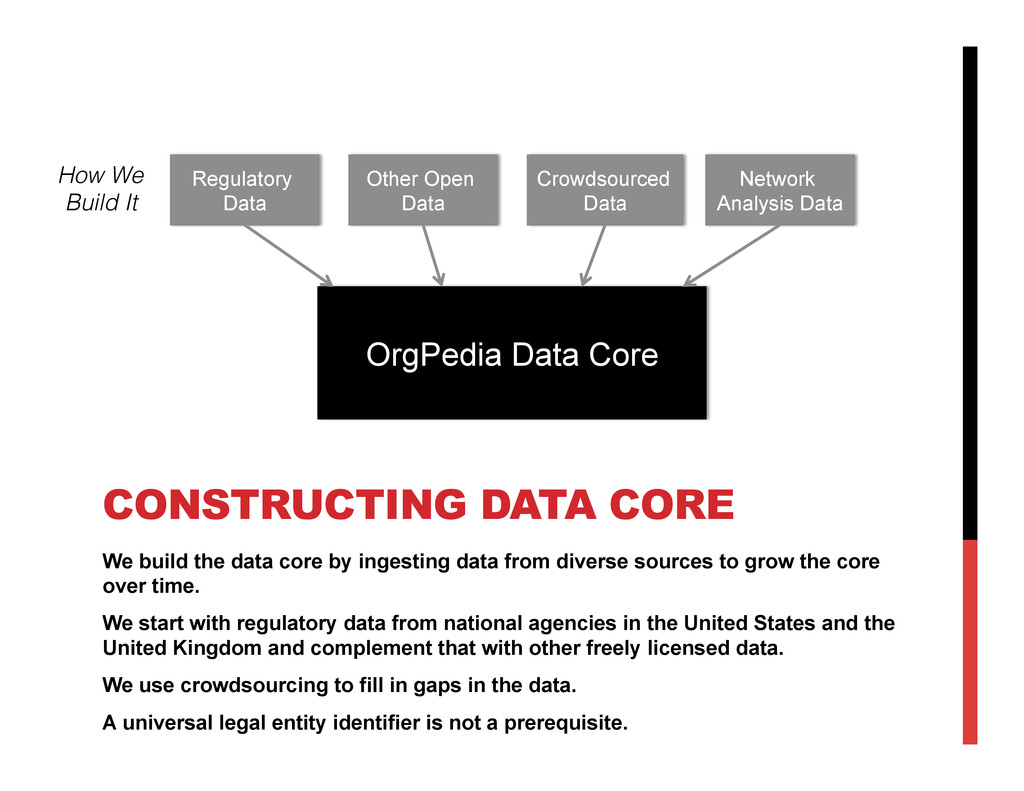
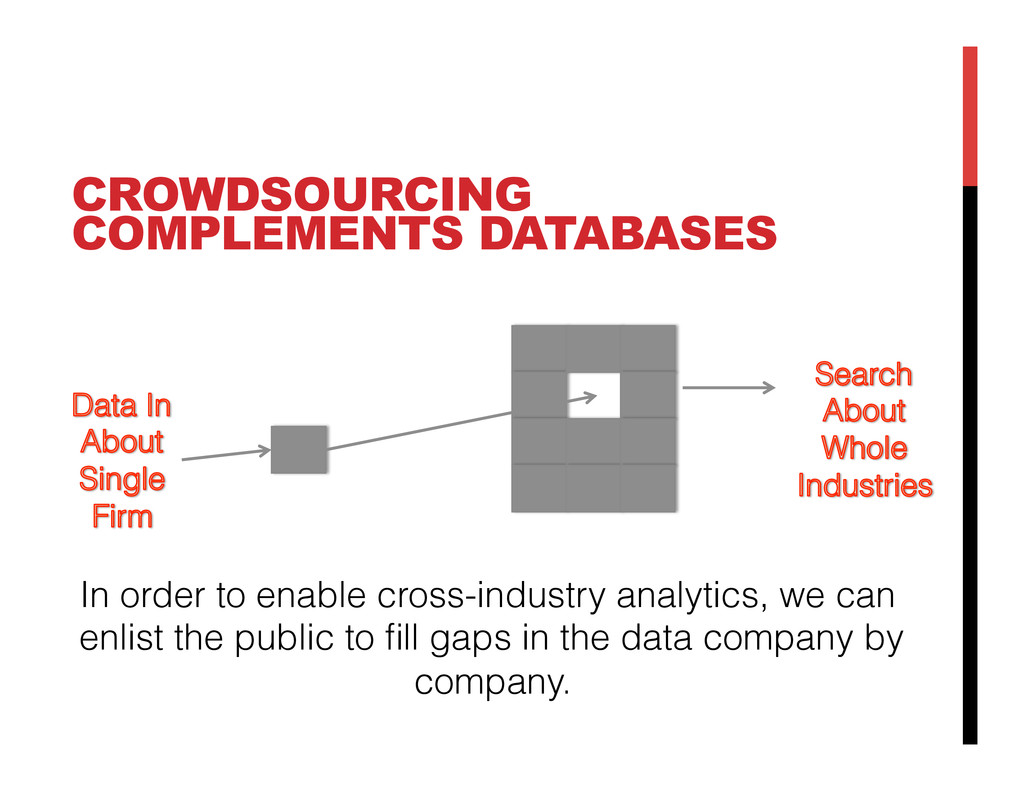
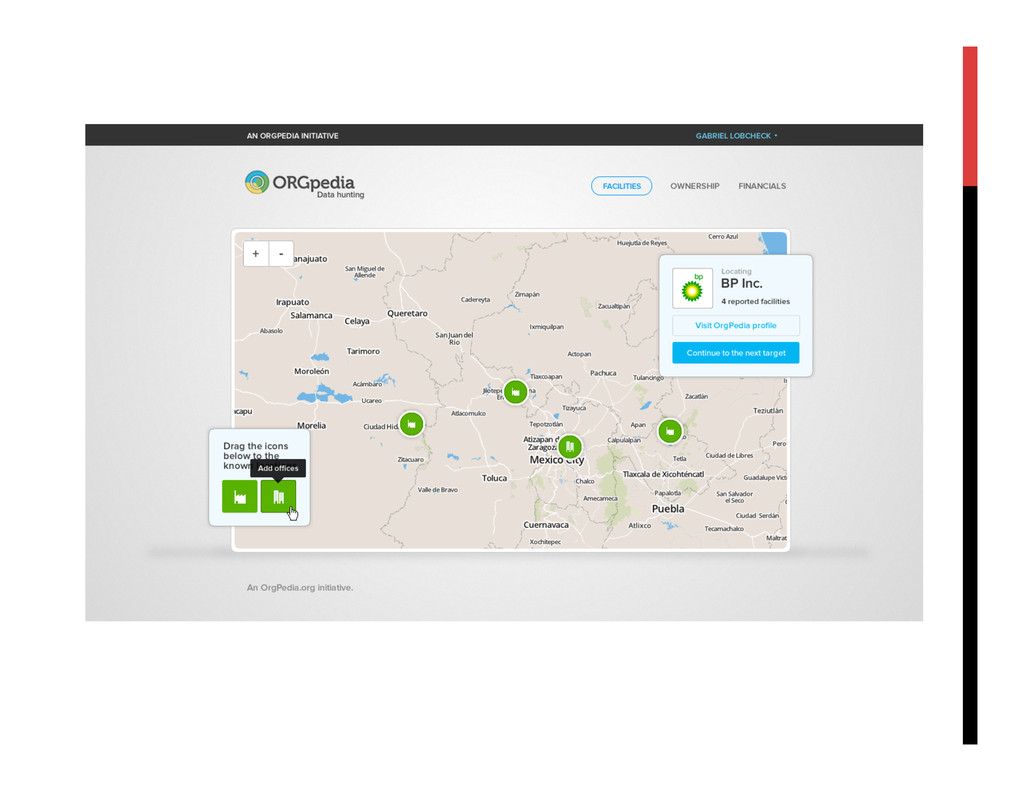
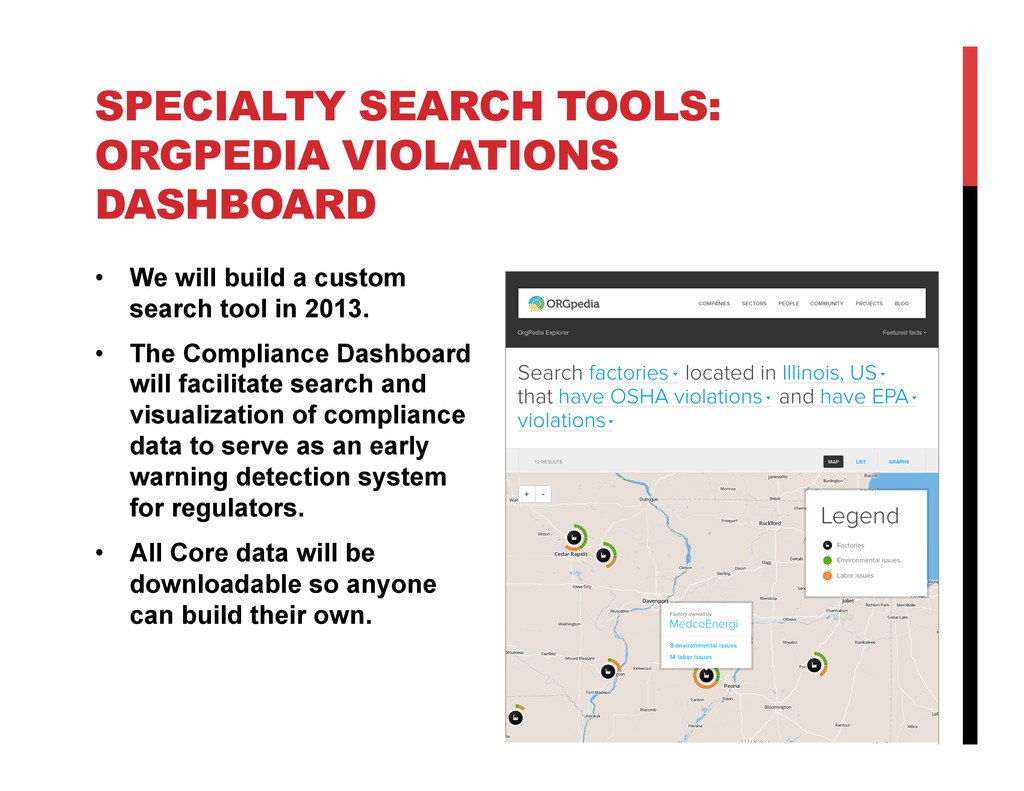
OrgPedia will bring together data from diverse sources while maintaining and displaying data provenance. As a priority, OrgPedia will import data that government agencies (starting with the U.S. and the U.K.) hold about the firms they regulate, such as financial data, environmental, labor, and safety compliance information, and patent filings, most of which have never been integrated. This core data structure will enable OrgPedia to explore adding other information over time, including other data sets that are licensed for re-use, crowdsource data from the public, and data developed through techniques such as social media network analysis. The result will be a “hub” of comprehensive data about corporations worldwide.
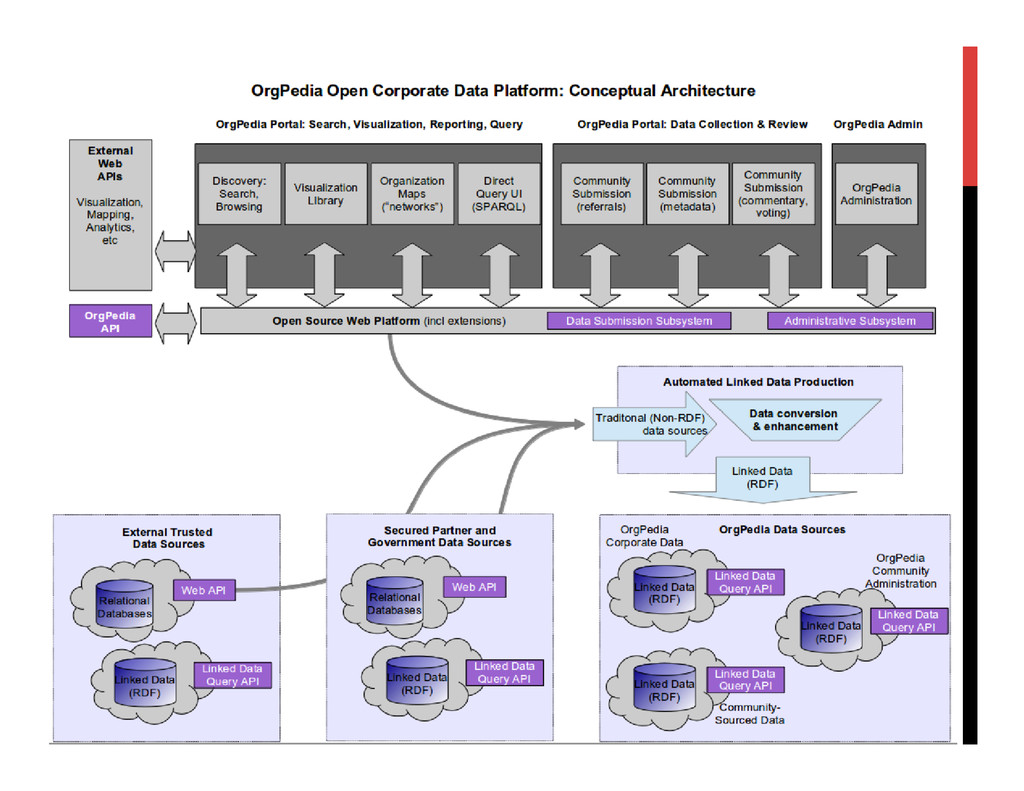
Designed by a consortium of leading technology experts at Rensselaer Polytechnic, MIT, New York Law School and NYU, OrgPedia will be a powerful tool to study the corporate world. It will enable government regulatory agencies to use data about regulated entities more effectively, and will allow researchers in or out of government to import OrgPedia data and analytic tools into their own websites and use OrgPedia to do new analyses and build new applications.
With OrgPedia, researchers will be able to answer questions rapidly that previously would have taken months of work or been impossible to answer. For example, they will use OrgPedia to untangle complex corporate ownership structures or to look across entire industries to see which companies have the best and worst environmental, social, and governance practices. If successful, OrgPedia will spur the release of more data; lead to greater understanding of regulated industry behavior; enable more targeted and effective enforcement and more innovative approaches to regulation; and help researchers gain new insights into regulated markets.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}