In this talk will present the PROTEUS project. PROTEUS is an EU H2020 funded research project to evolve massive online machine learning strategies for predictive analytics and real-time interactive visualization methods – in terms of scalability, usability and effectiveness dealing with extremely large data sets and data streams – into ready to use solutions, and to integrate them into enhanced version of Apache Flink, the EU Big Data platform. PROTEUS project is being carried out by an international consortium of 6 partners including Treelogic (creators of Lambdoop), TU Berlin (creators of Apache Flink) and ArcelorMitall (worlds’s leading steel company).
Session presented at Big Data Spain 2015 Conference
16th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract: http://www.bigdataspain.org/program/fri/slot-34.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
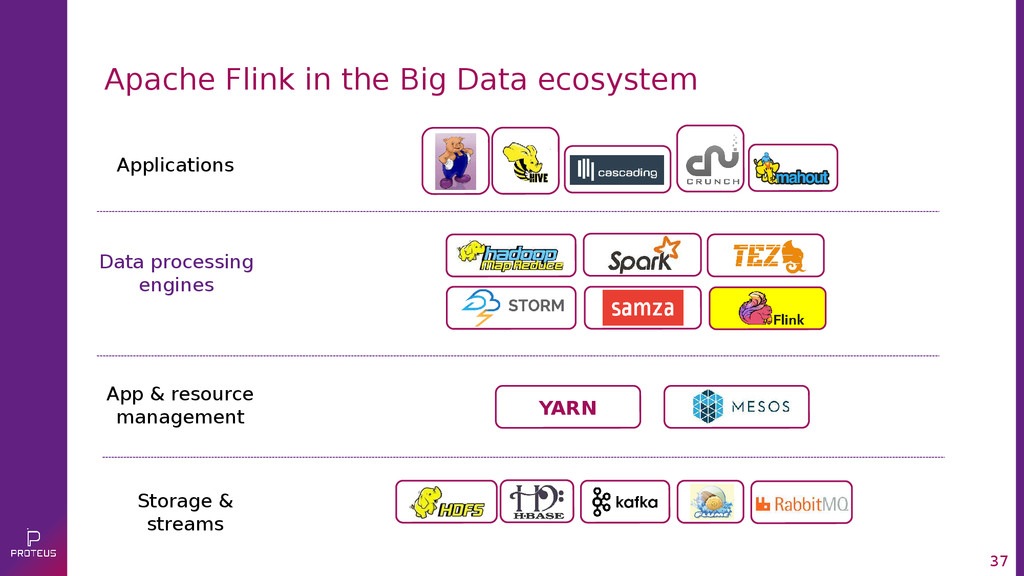{kind=link}
{kind=link}
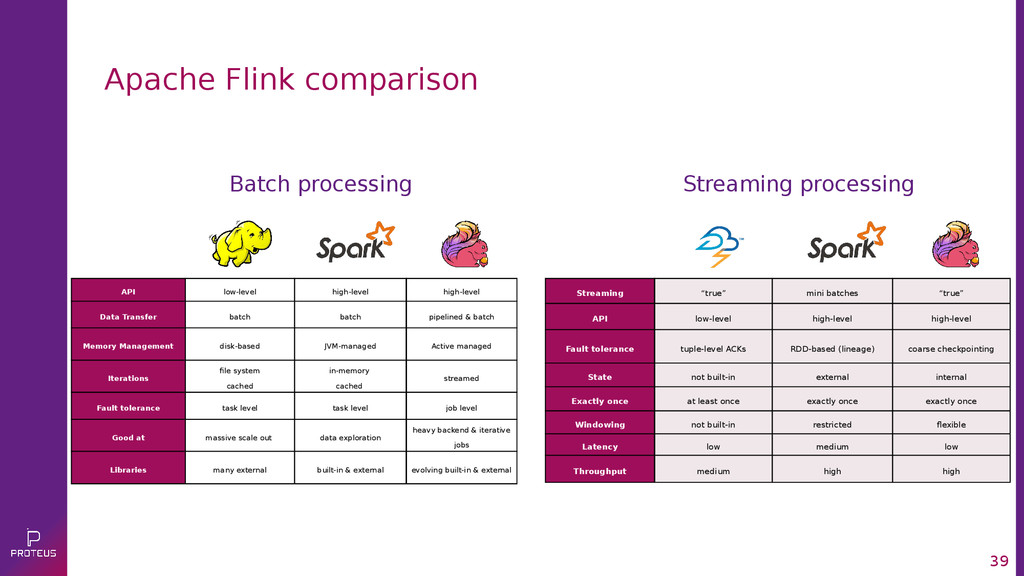{kind=link}
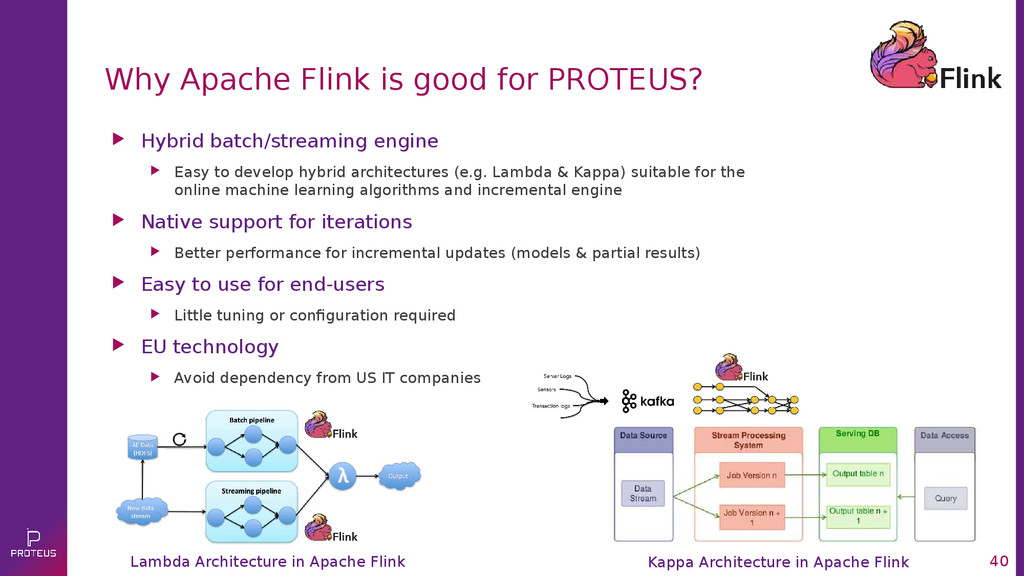{kind=link}
{kind=link}
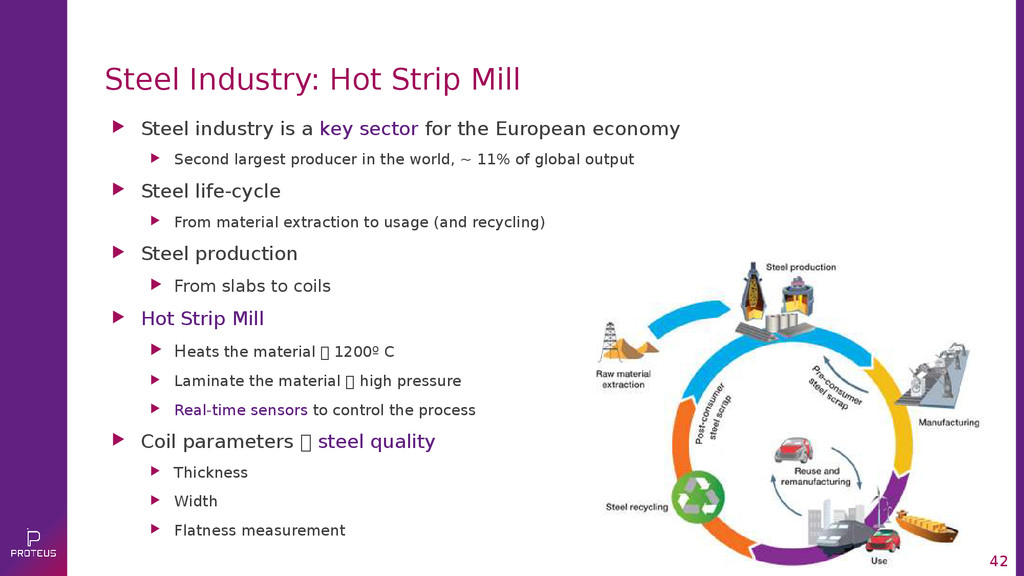{kind=link}
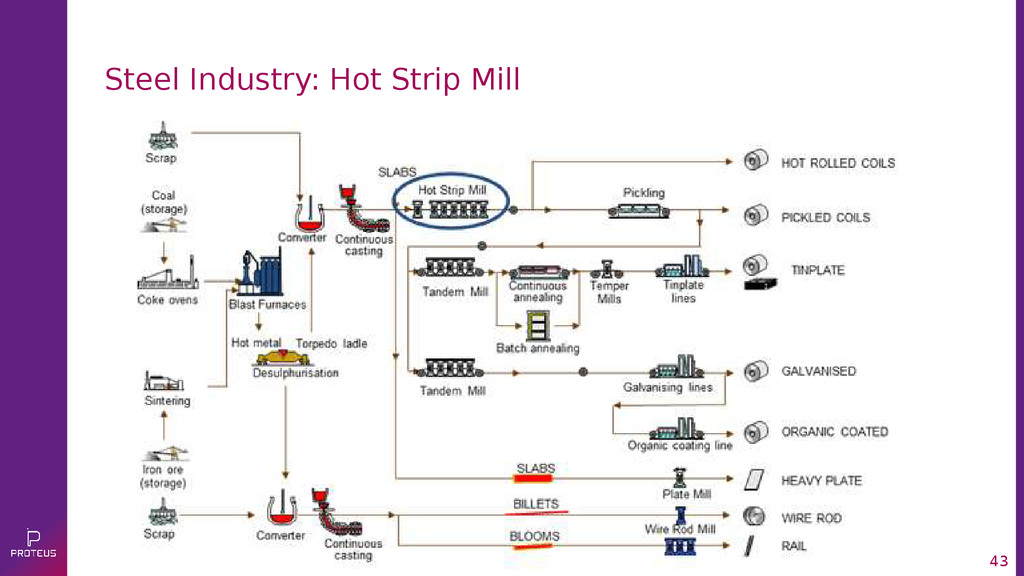{kind=link}
{kind=link}
{kind=link}
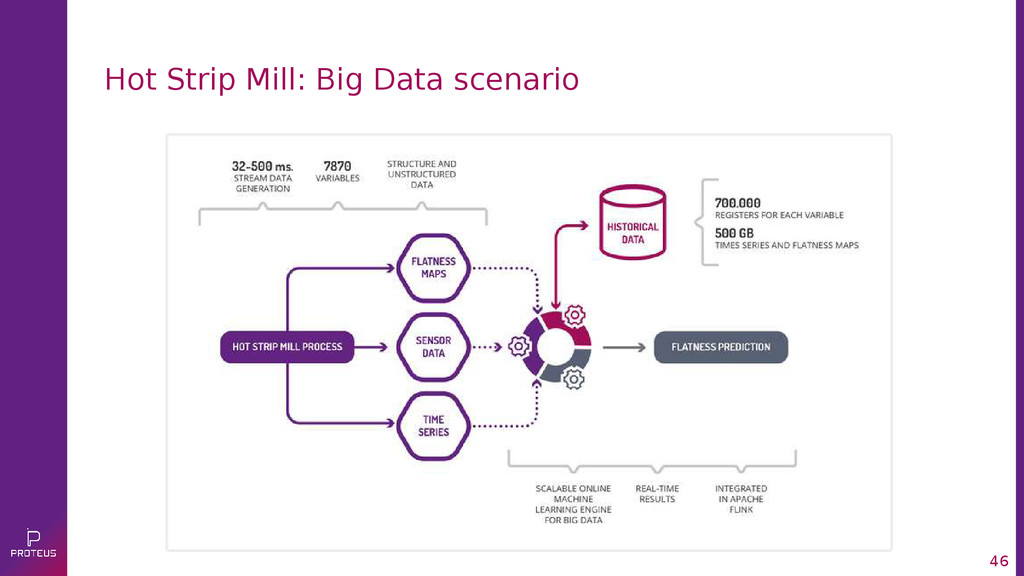{kind=link}
{kind=link}
{kind=link}
{kind=link}