Toy • Be Like Yahoo, Google, FB • Data as Strategy • Free – Just Add Hardware • Open, Standard • Cost-Savings Projects • Bigger and Faster is Better • Fewer Hacks to Survive Scale • Do The Previously Impossible It’s Aspirational It Costs Less We Get More Computing www.avalonconsulting.net/blog/485-thinking-beyond-shiny- and-new www.pianta.co.uk/massive-sale-now-on/ www.google.com/about/careers/locations/mayes-county/
a prototype Hadoop cluster as part of a big data POC • We cut our IT budget by 22% by moving some operations to Hadoop • Our SQL queries are 3 times faster and overnight reports finish in 39 minutes now • We do the same things with data, but do them notably better. • We want to become a real-time product business that reacts to new machine sensor data in seconds, not days • We want to predict which merchants will take out a business loan this month • We want a complete customer profile that “understands” what they want at any time • We think there is a magic wand available?
new • Big Machine Learning is qualitatively different – More data beats algorithm improvement – Scale trumps noise and sample size effects – Can brute-force manual tasks • Feature selection • Hyperparameter tuning • Engineering “Big” is Difficult – Build new scalable data platforms – Re-engineering parallel algorithms
Huge data Online problems Automated Developers, Engineers Statistical environments, BI tools High-level languages Accuracy Medium-sized data Offline work Ad-hoc Statisticians, Analysts vs.
– From UC Berkeley AMPLab – … inspired by MS DryadLINQ • Scala-based – Expressive, efficient – JVM-based • Scala-like abstractions – RDD: Resilient Distributed (immutable) Dataset – Distributed works like local – Like Apache Crunch is Collection-like • Read-Evaluate-Print-Loop – Interactive – No compile/deploy cycle needed • Python API too • Natively Distributed • Hadoop-friendly – Integrate with where data already is – ETL no longer separate • Subprojects: MLlib and more
(4,"winforms") ... (4,3104,1.0) (4,2148819,1.0) ... scala> val postIDTags = postsXML.flatMap { line => val idTagRegex = "Id=\"(\\d+)\".+Tags=\"([^\"]+)\"".r val tagRegex = "<([^&]+)>".r idTagRegex.findFirstMatchIn(line) match { case None => None case Some(m) => { val postID = m.group(1).toInt val tagsString = m.group(2) val tags = tagRegex.findAllMatchIn(tagsString) .map(_.group(1)).toList tags.map((postID,_)) } } }
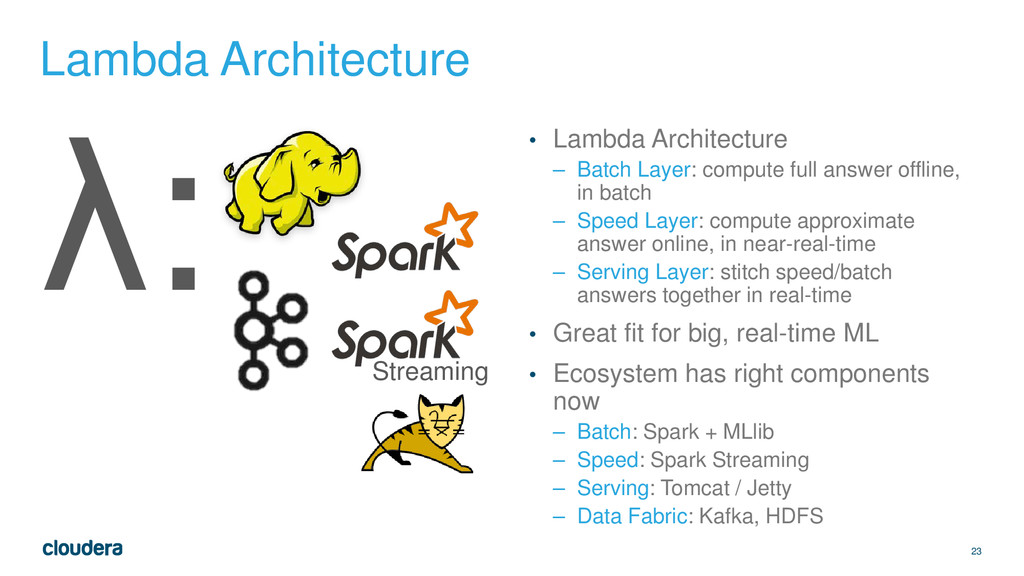
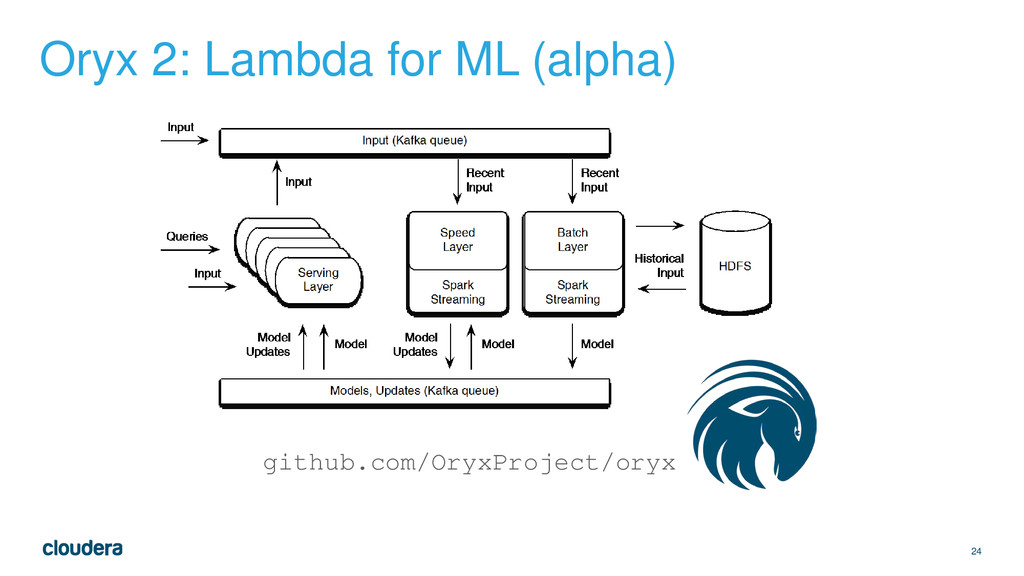
Layer: compute full answer offline, in batch – Speed Layer: compute approximate answer online, in near-real-time – Serving Layer: stitch speed/batch answers together in real-time • Great fit for big, real-time ML • Ecosystem has right components now – Batch: Spark + MLlib – Speed: Spark Streaming – Serving: Tomcat / Jetty – Data Fabric: Kafka, HDFS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
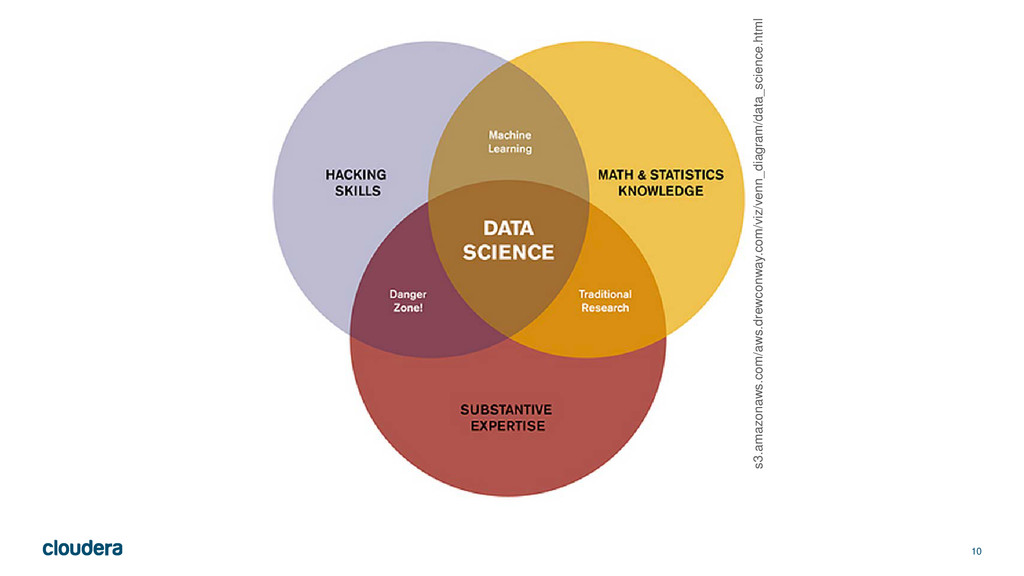{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
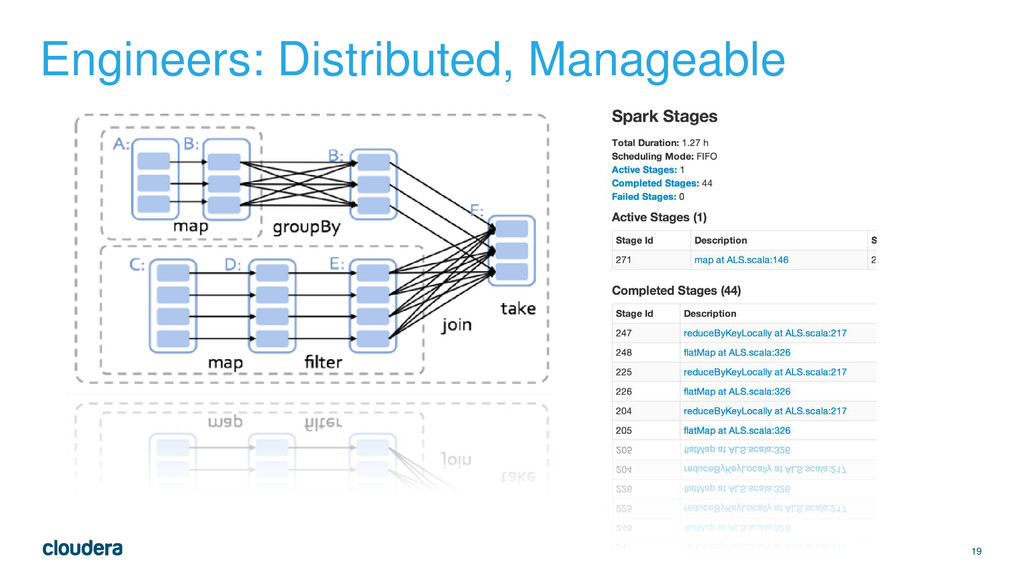{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You [email protected] @sean_r_owen](https://files.speakerdeck.com/presentations/b4630f5056b101323a1376b876f8ed2b/slide_25.jpg){kind=link}
{kind=link}