• Variedad • Volumen • Data tiene un Valor • 2 problemas claves que notar: • Cómo podemos almacenar confiablemente grandes cantidades de data a un precio razonable? • Cómo podemos analizar toda la data que almacenamos?
Hadoop: proyecto open-source • Almacenamiento y procesamiento escalable y económico: • Distribuido y tolerante al error • Aprovecha el poder del hardware estandar de las industrias
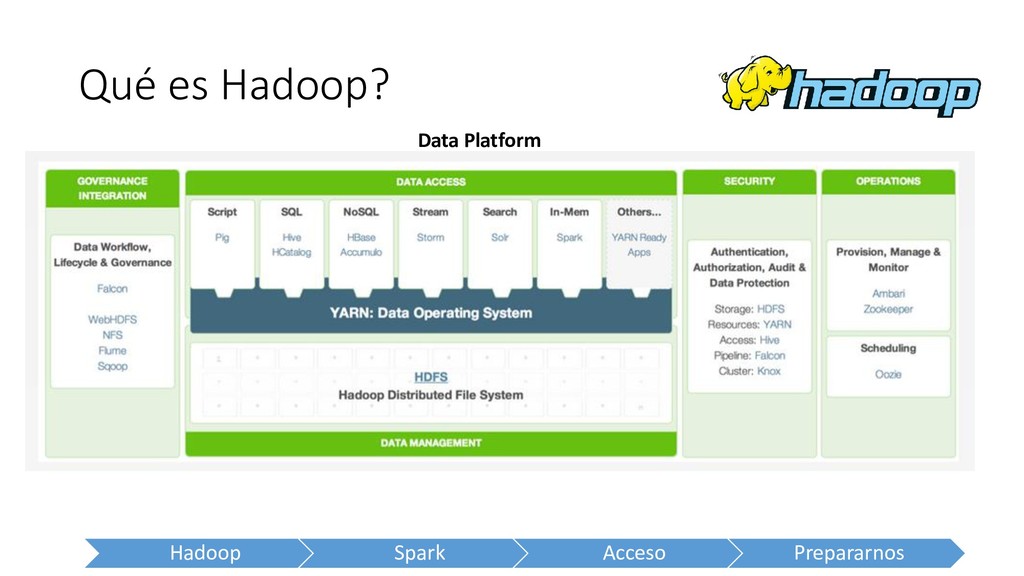
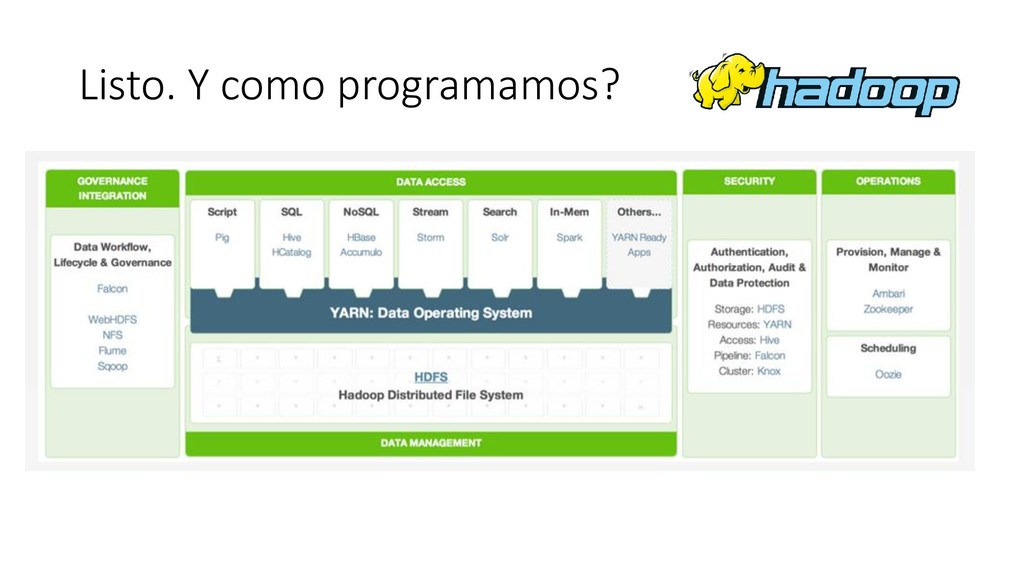
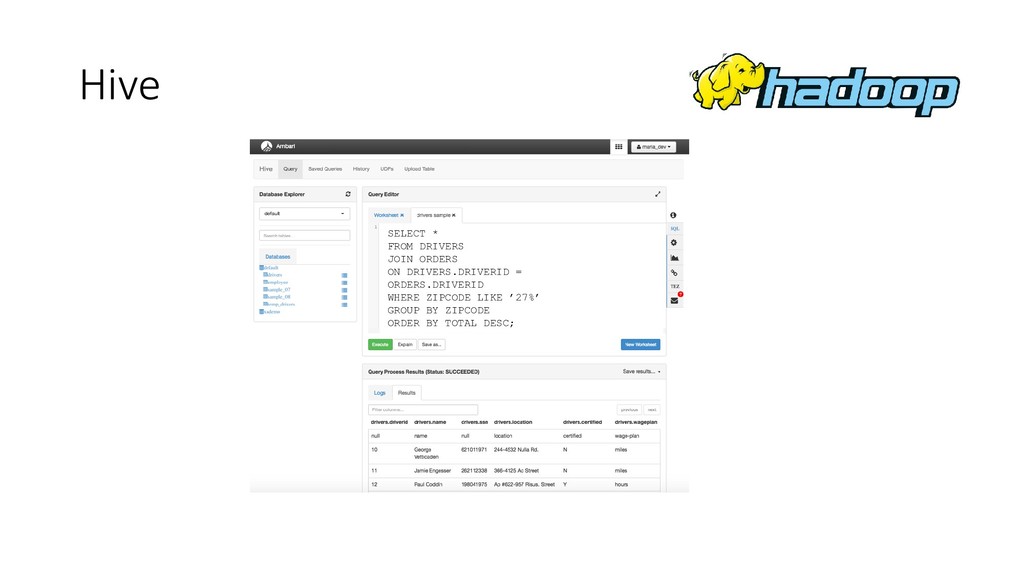
Hadoop consiste en dos componentes principales: 1. Almacenamiento: Hadoop Distributed File System (HDFS) 2. Procesamiento: MapReduce Además de la infraestructura necesaria para hacerlos funcionar: • Sistema de archivos y utilities de administración • Programación de trabajos y monitoreo
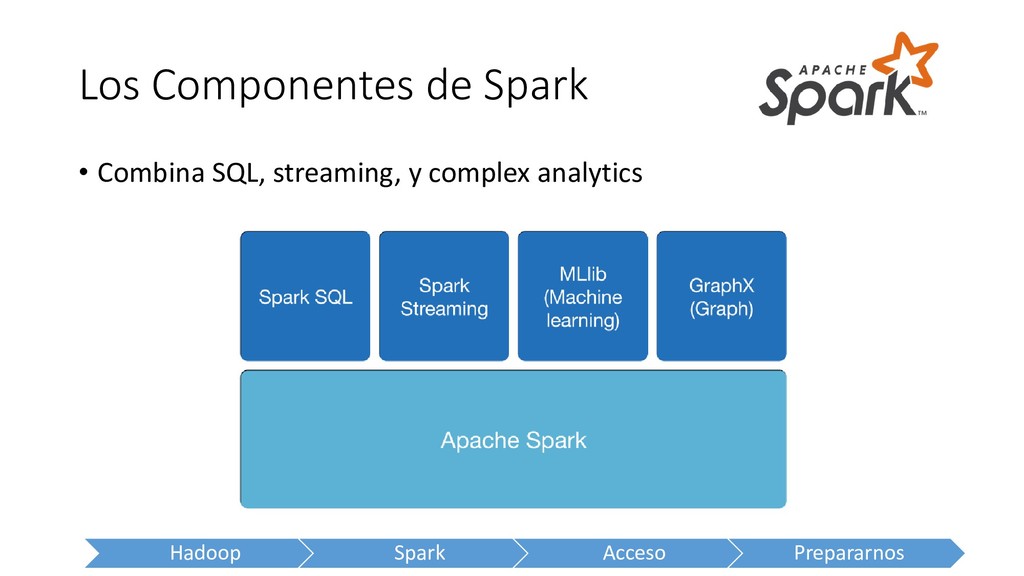
open-source, cluster computing framework • Enfoque en los cálculos interactivos e iterativos: • Utiliza procesamiento in-memory • Lo hace ideal para aplicación de data science • Extensivo soporte API para Java, Scala, R Python
• Spark fue diseñado para facilitar los cálculos iterativos • Fácil de Usar • APIs múltiples disponibles para ambientes de desarrollo familiares • Velocidad • Corre los programas hasta 100x mas rápido que Hadoop MapReduce en memoria, o 10x más rapido en disco • Corre en todos lados • Spark corre en Hadoop, por sí solo, o en la nube. Puede acceder a diversas fuentes de data incluyendo HDFS, Cassandra, HBase, y S3
Hadoop y Apache Spark son big-data frameworks 2. No sirven los mismos propósitos 3. Spark no provee almacenamiento 4. Puedes usar uno sin utilizar el otro. 5. MapReduce y Spark proveen un framework para el procesamiento de data escalable. 6. Uno no reemplaza al otro.
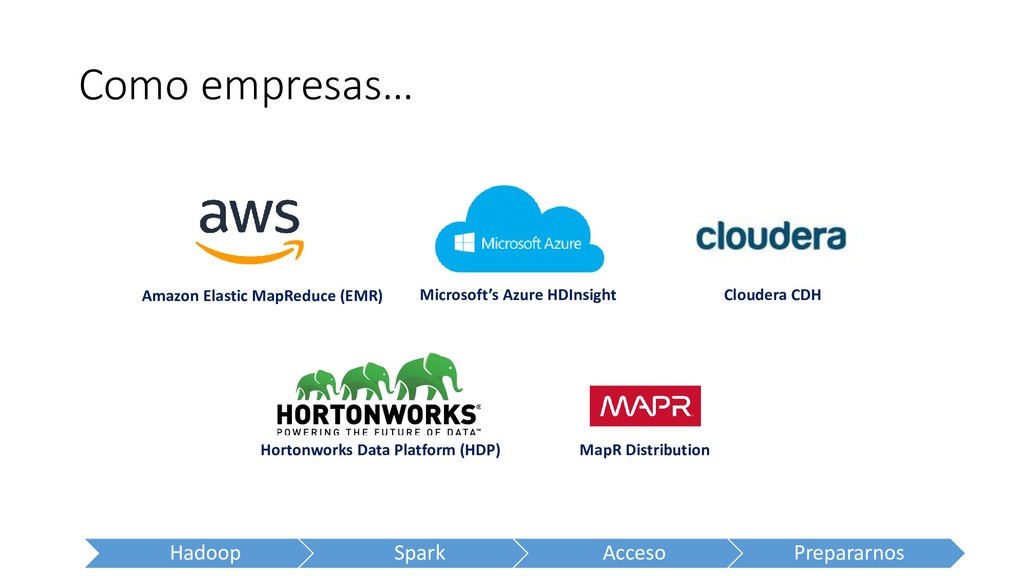
colaboración entre personas, comunidades y proyectos las necesidades de las empresas no son necesariamente prioridad de la comunidad open source Lo que necesitamos: un vendedor de software que provea un paquete de soluciones integradas para brindar a las empresas una solución integral
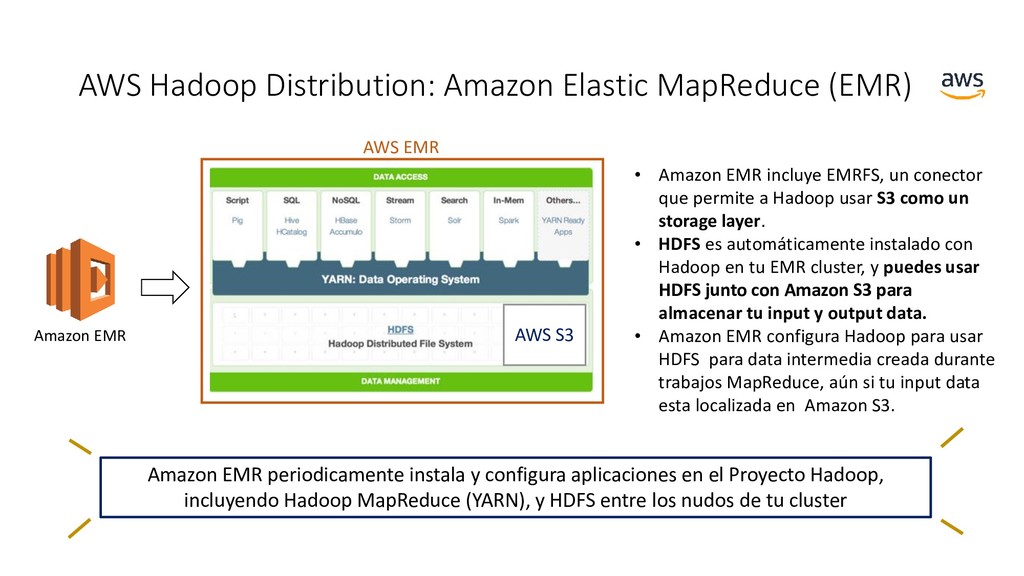
instala y configura aplicaciones en el Proyecto Hadoop, incluyendo Hadoop MapReduce (YARN), y HDFS entre los nudos de tu cluster AWS S3 AWS EMR Amazon EMR • Amazon EMR incluye EMRFS, un conector que permite a Hadoop usar S3 como un storage layer. • HDFS es automáticamente instalado con Hadoop en tu EMR cluster, y puedes usar HDFS junto con Amazon S3 para almacenar tu input y output data. • Amazon EMR configura Hadoop para usar HDFS para data intermedia creada durante trabajos MapReduce, aún si tu input data esta localizada en Amazon S3.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}