This talk will provide an overview over the core concepts, discuss limitations enforced by the underlying distributed storage system, and how the Datastore performs in combination with Google App Engine. A special focus is on the entity group concept, which is important to guarantee good scalability and to keep performance high.
The Datastore is a fully managed schemaless database and part of the Google Cloud Platform. It’s available in many of Google’s cloud services, or can be used as standalone data backend. At the moment Philipp is working on his master’s thesis which includes an extensive analysis of Google App Engine in combination with the Datastore as data storage backend.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
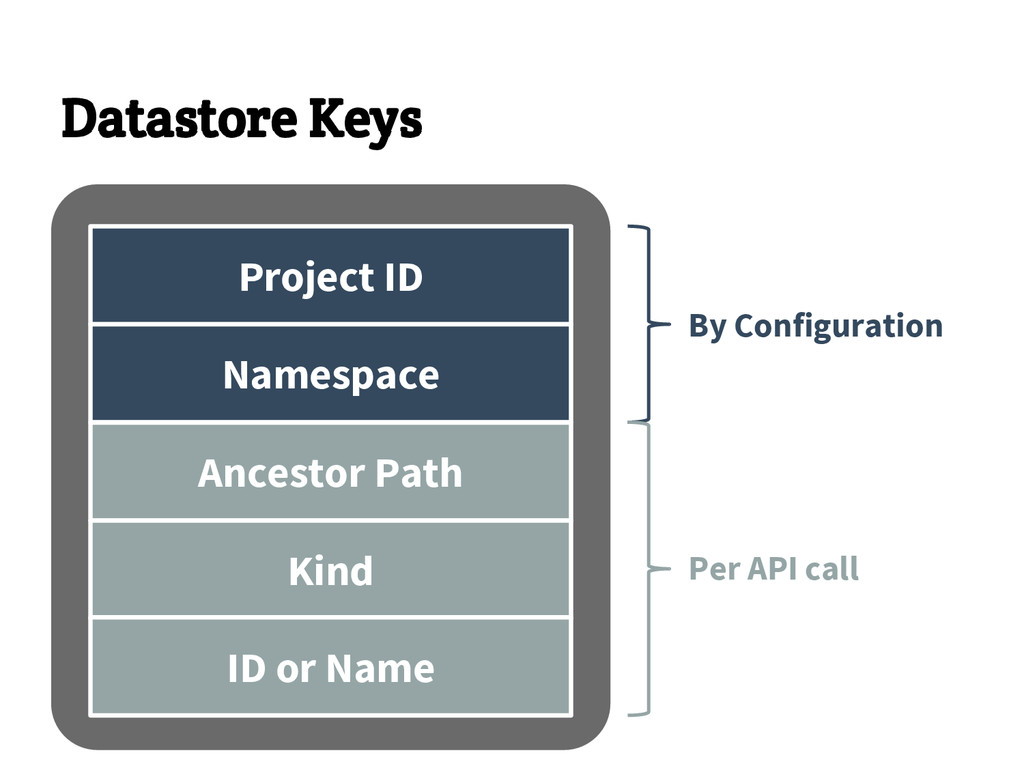{kind=link}
{kind=link}
{kind=link}
{kind=link}
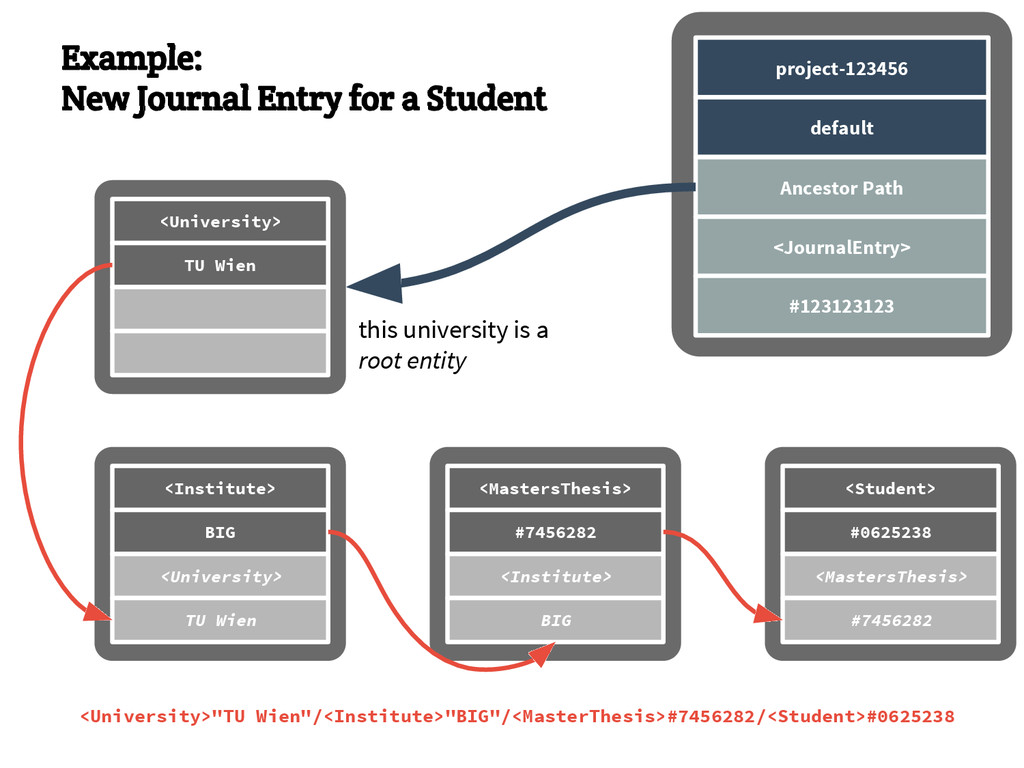{kind=link}
{kind=link}
{kind=link}
{kind=link}
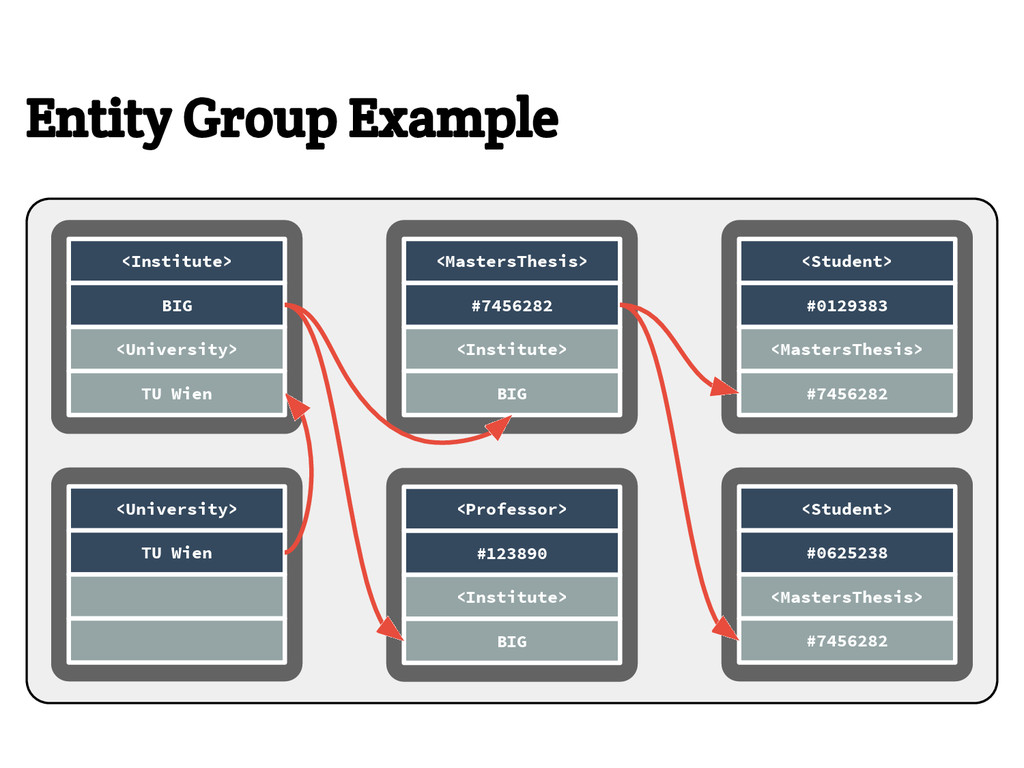{kind=link}
![Entity Group Example Key Data <>/University:"TU Wien" [pbuff] <University:TUWien>/Intitute:"BIG" [pbuff]](https://files.speakerdeck.com/presentations/decc36fc56c941bfb73d24a0b937889c/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
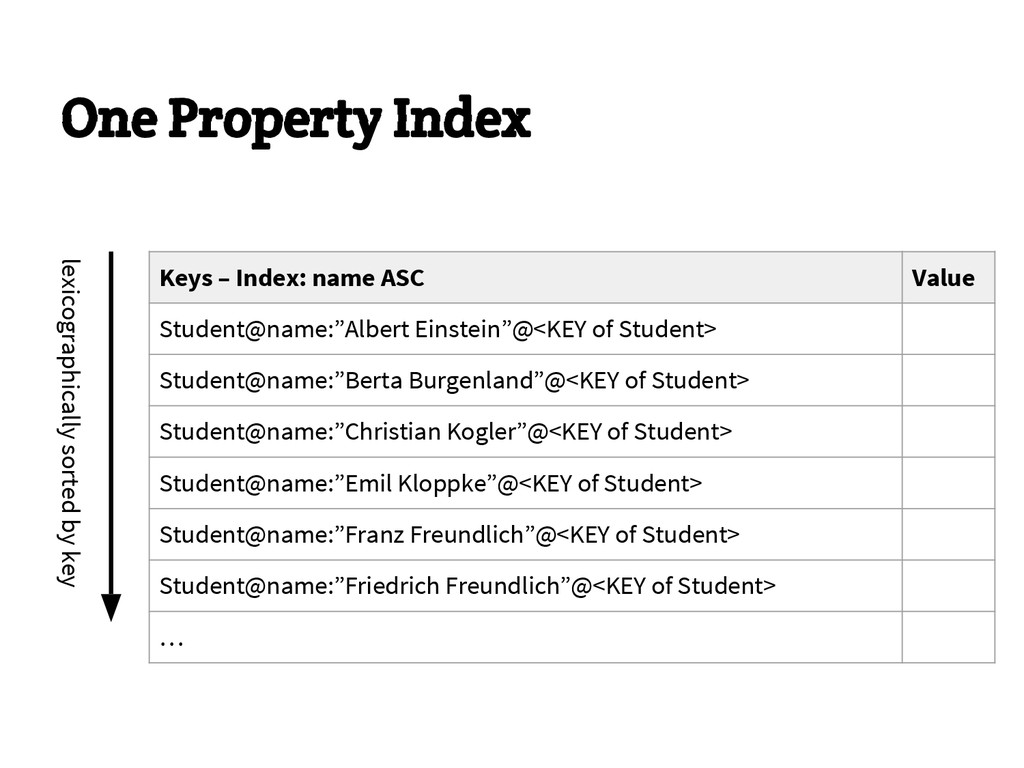{kind=link}
{kind=link}
{kind=link}
{kind=link}
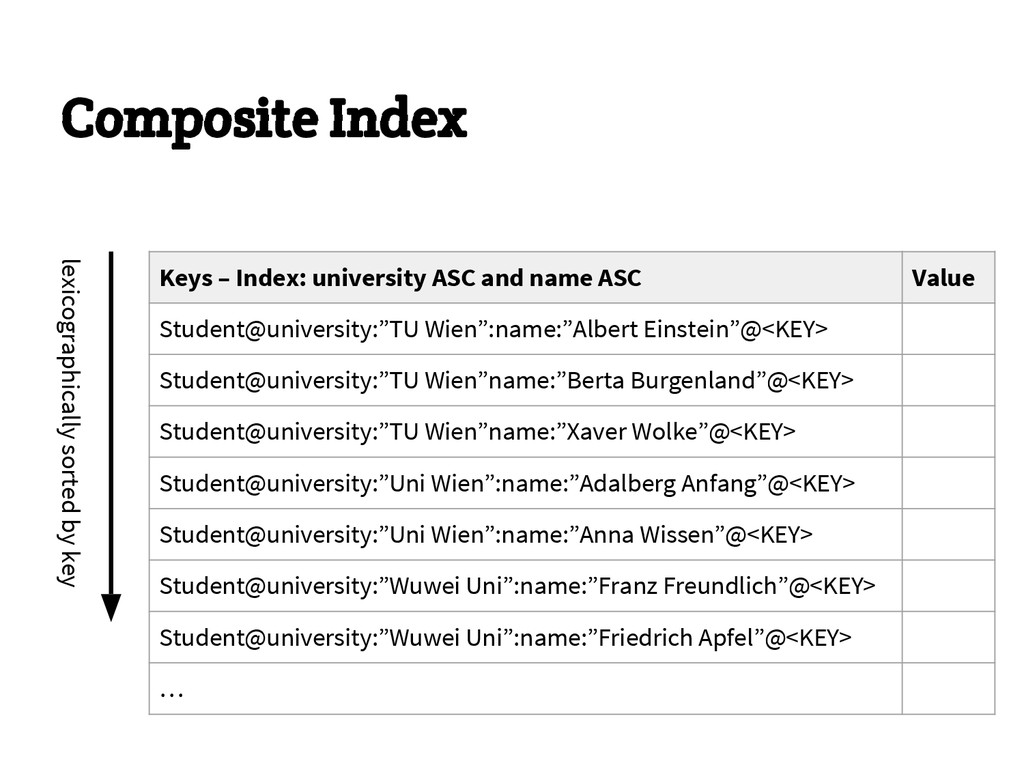{kind=link}
{kind=link}
{kind=link}
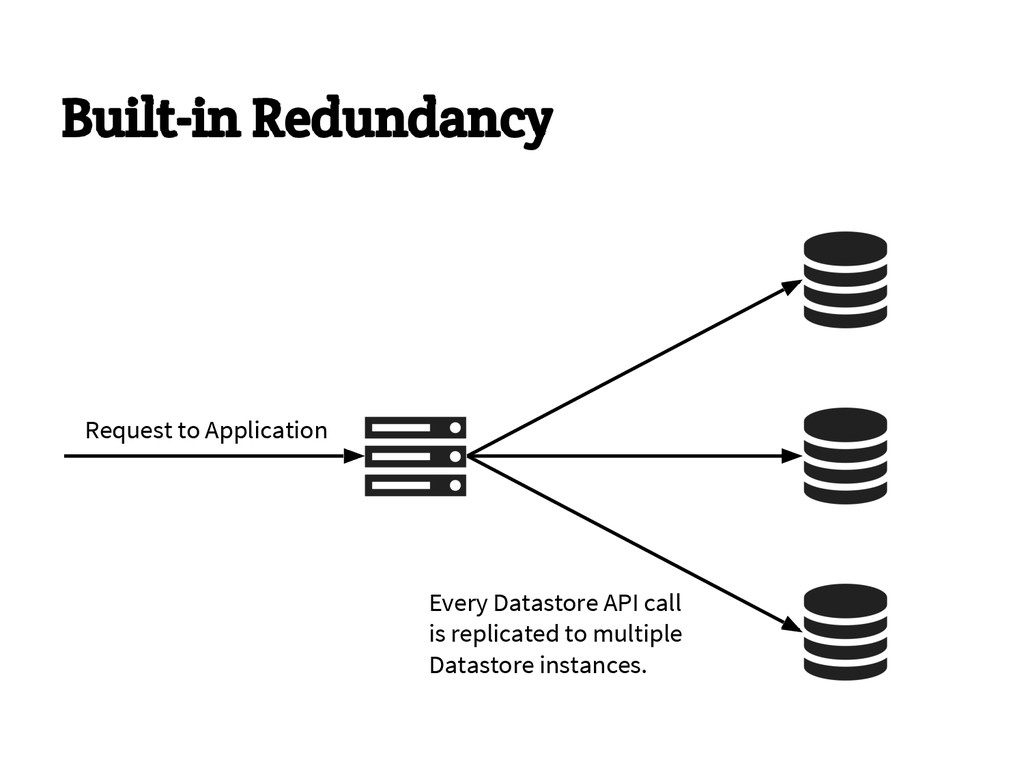{kind=link}
{kind=link}
{kind=link}
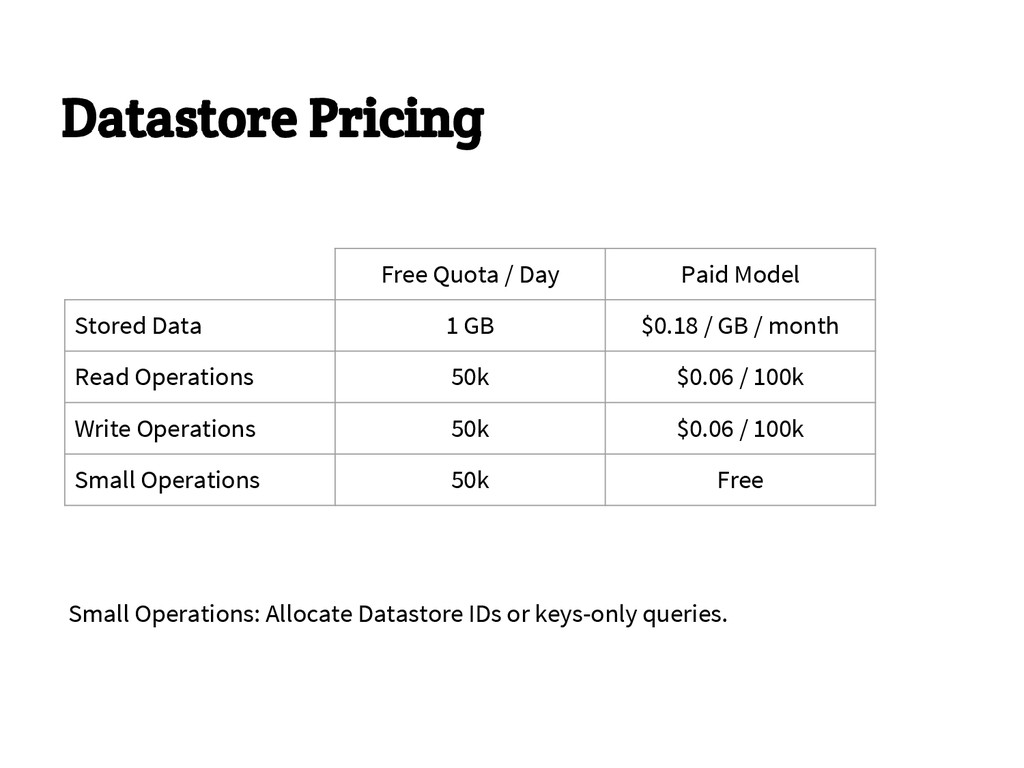{kind=link}
{kind=link}