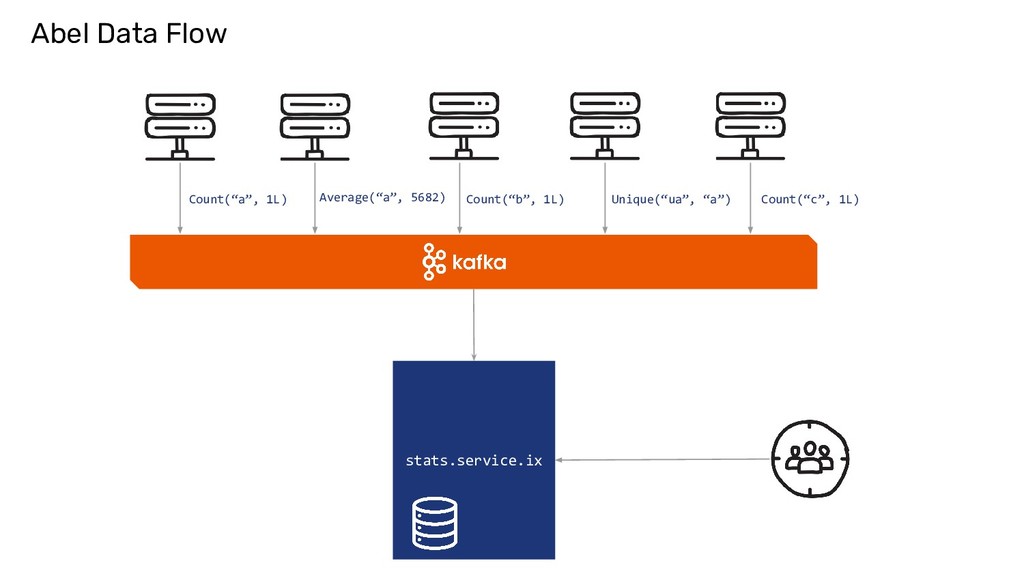
Using Monoids for large scale aggregation - Scala.io, Lyon 2017
In this talk, you will see, how Monoids acts as a powerful abstraction to build distributed stats aggregation system. You will also see a high level architecture of how an in-house system named able was built based on this premise.
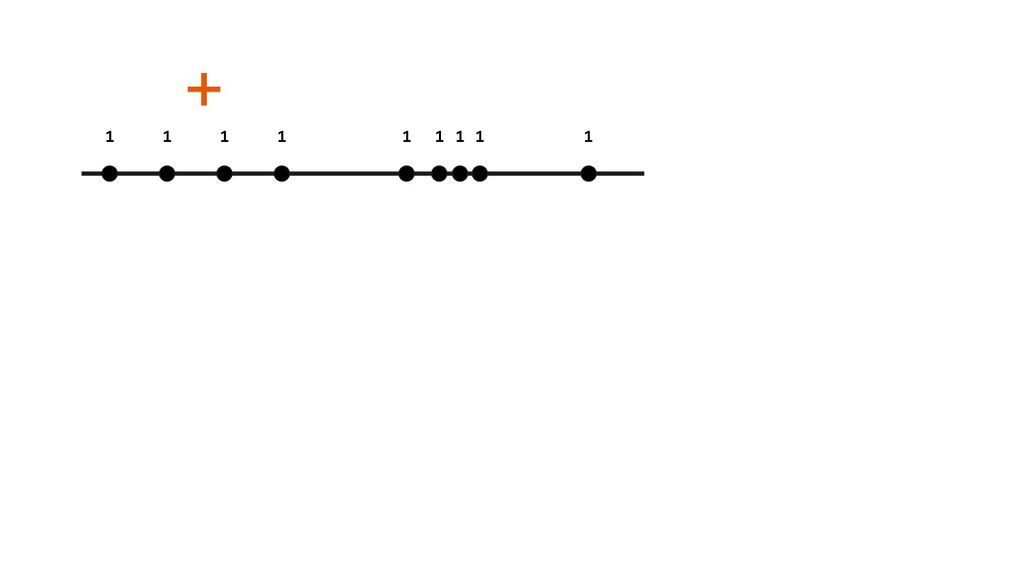
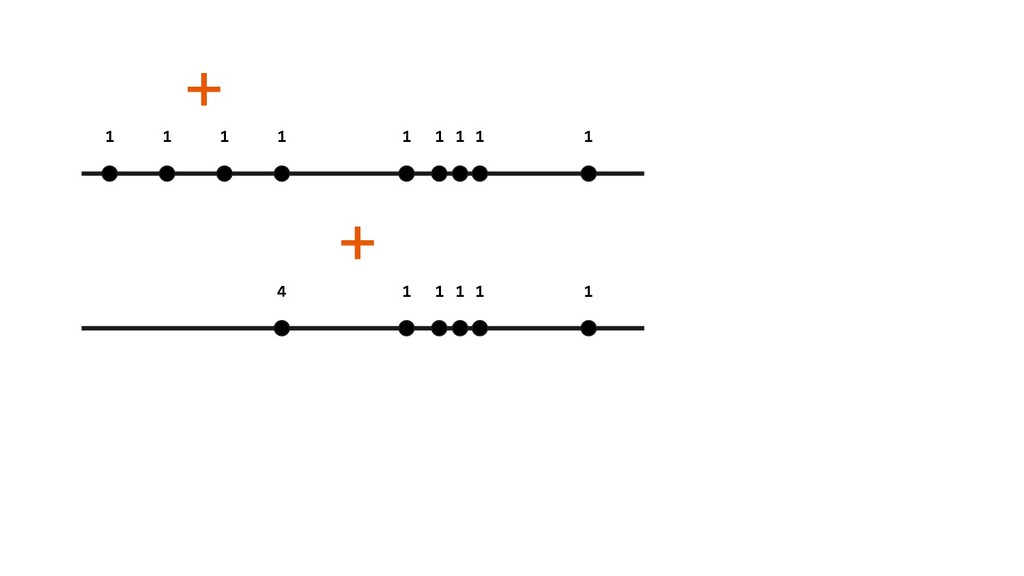
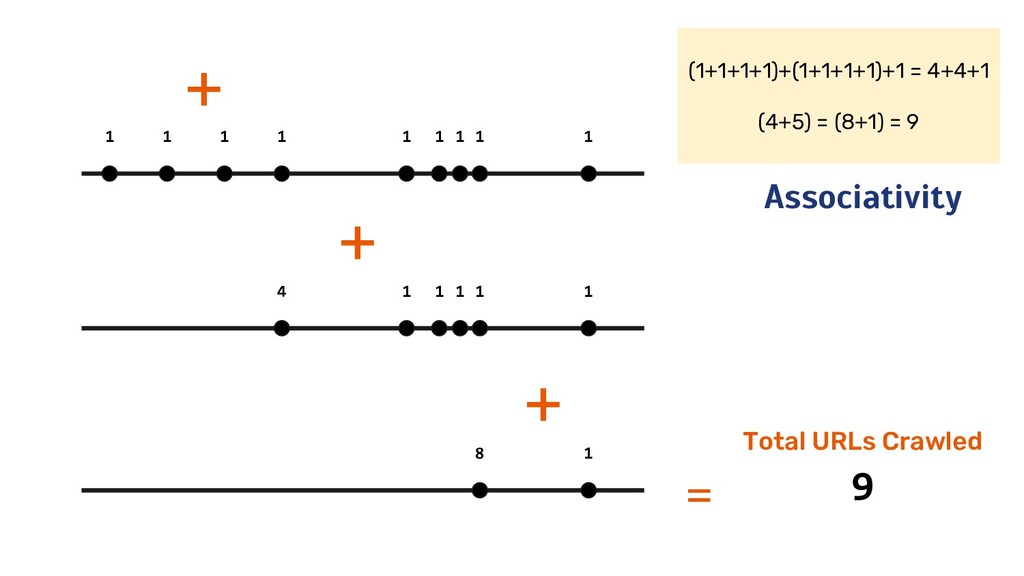
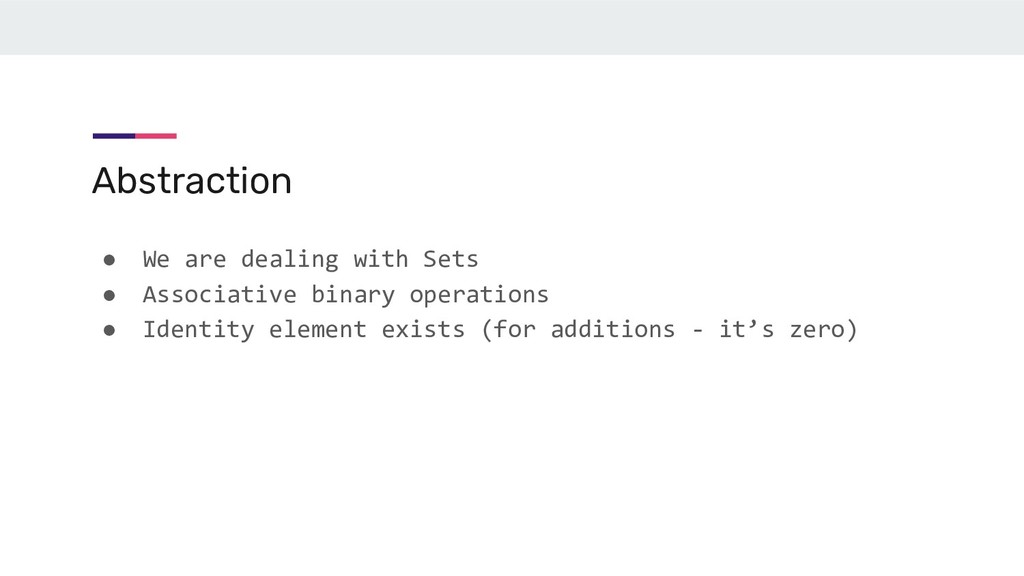
another number (binary operation) - Add: simple add of two numbers - Average: maintain two values - sum and count & “adds” each of them • Ordering of operations don’t matter (commutative) • Grouping of operations don’t matter (associative) • Ignores 0s
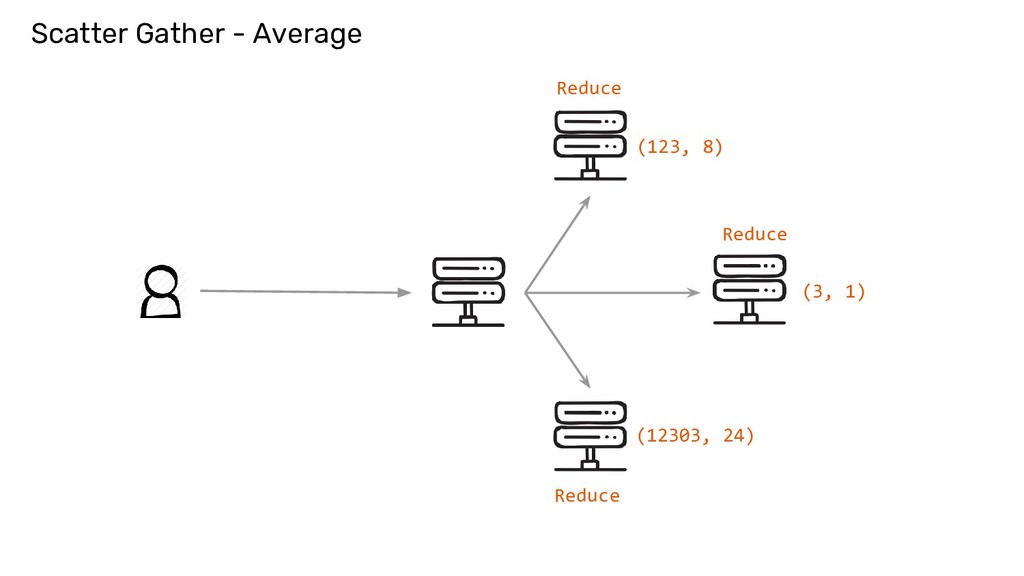
an EMBARRASSINGLY PARALLEL* problem • User Queries are handled via Scatter Gather ◦ Reduce on individual nodes ◦ Re-reduce on the results and return as the response
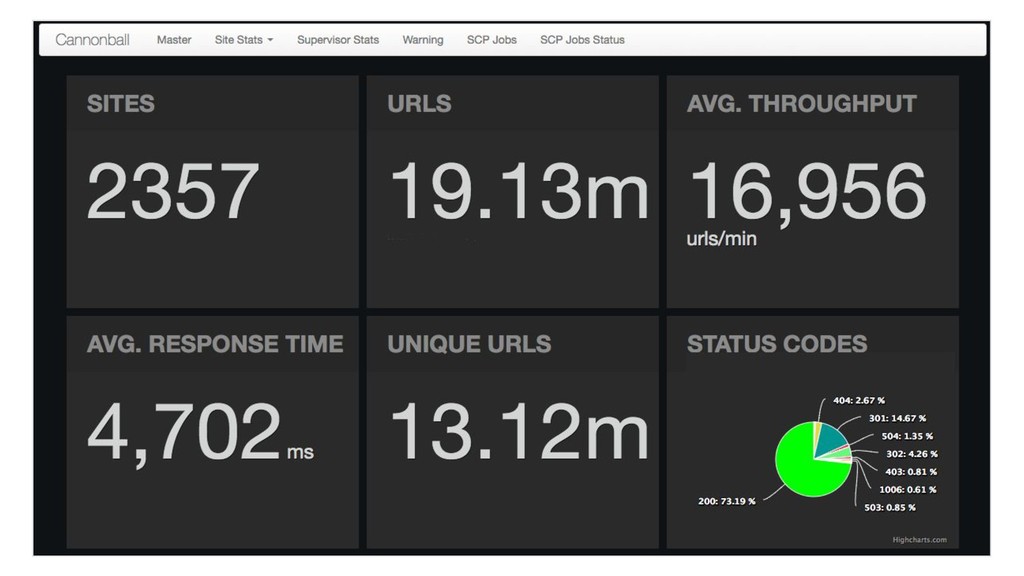
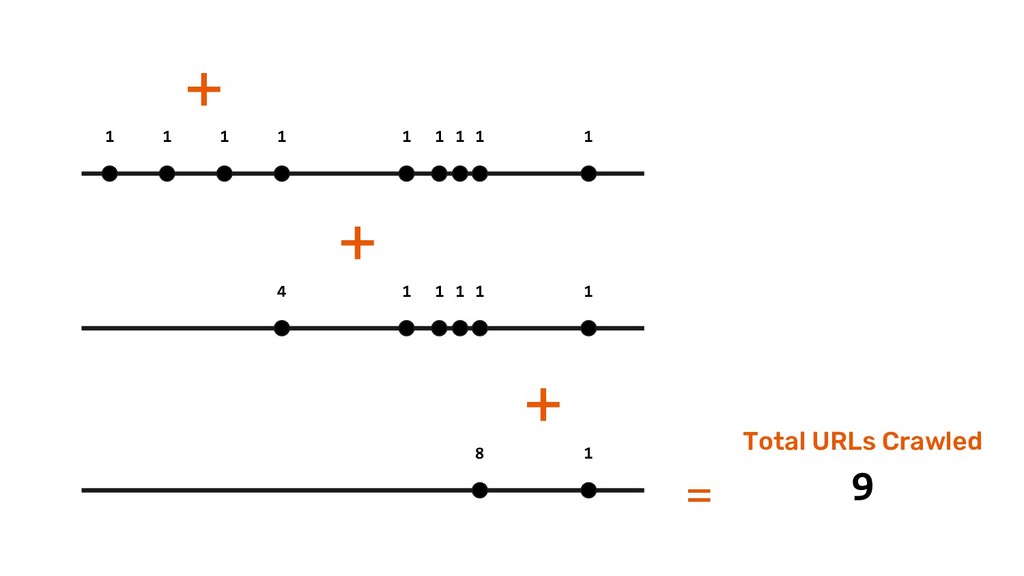
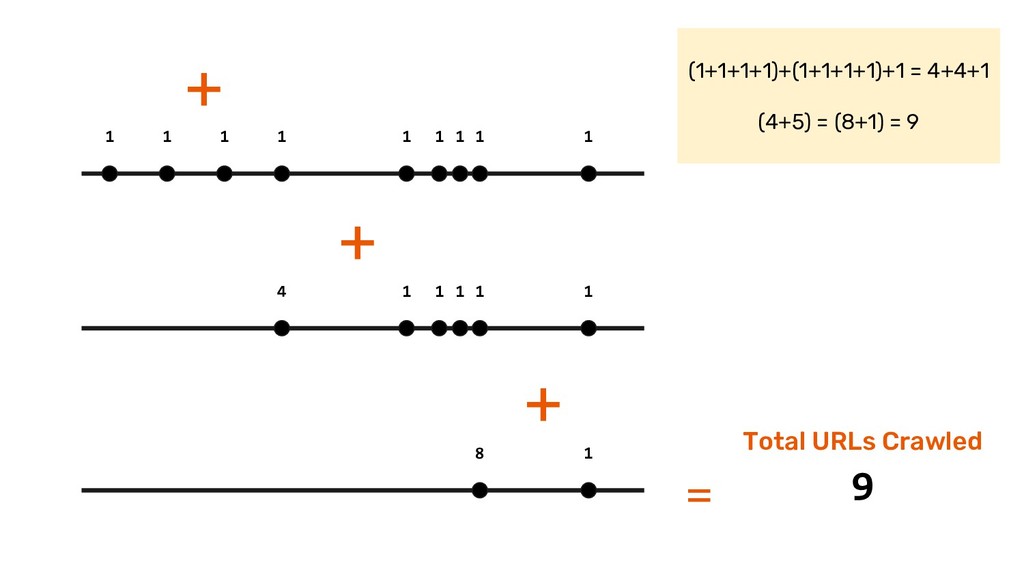
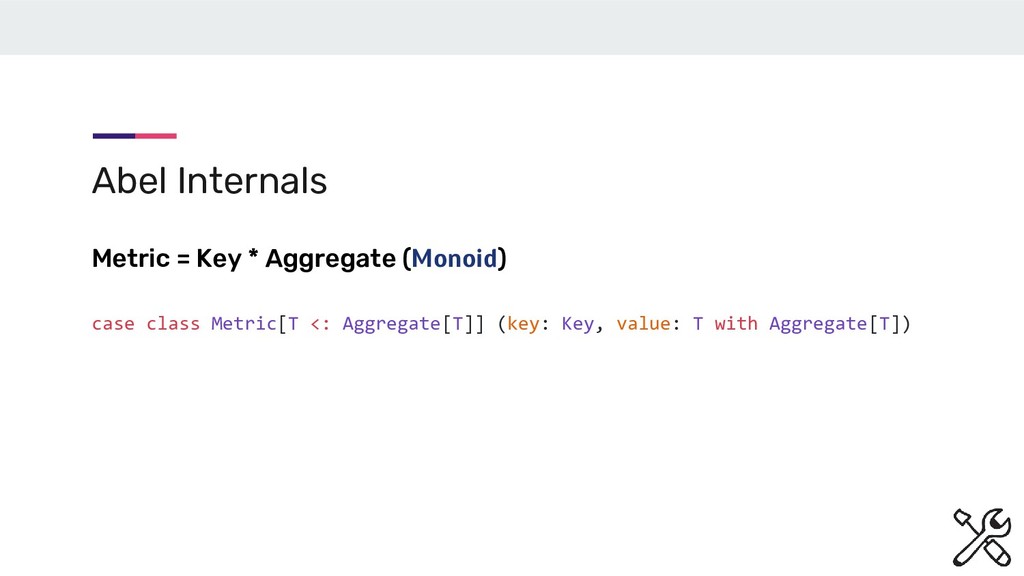
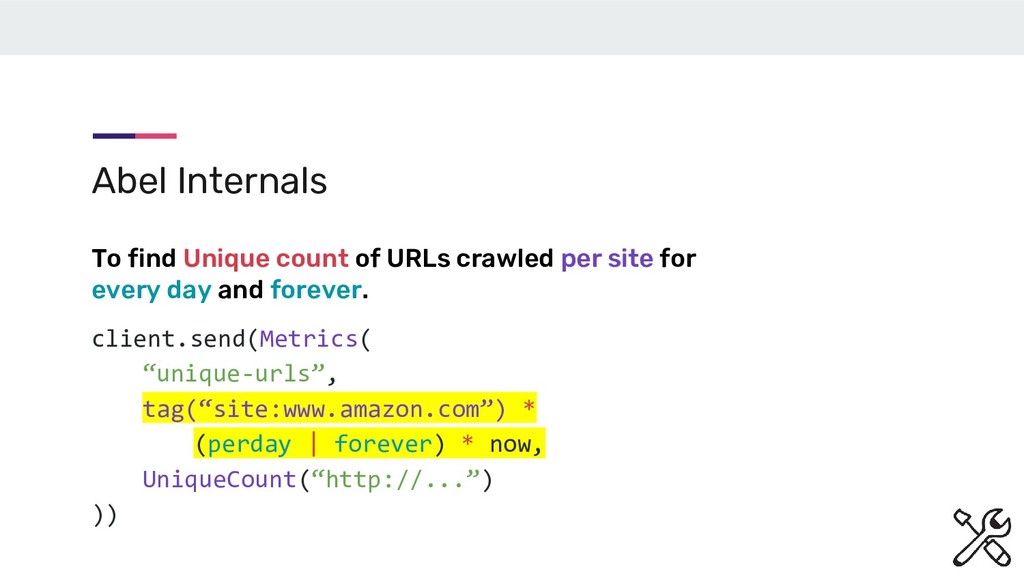
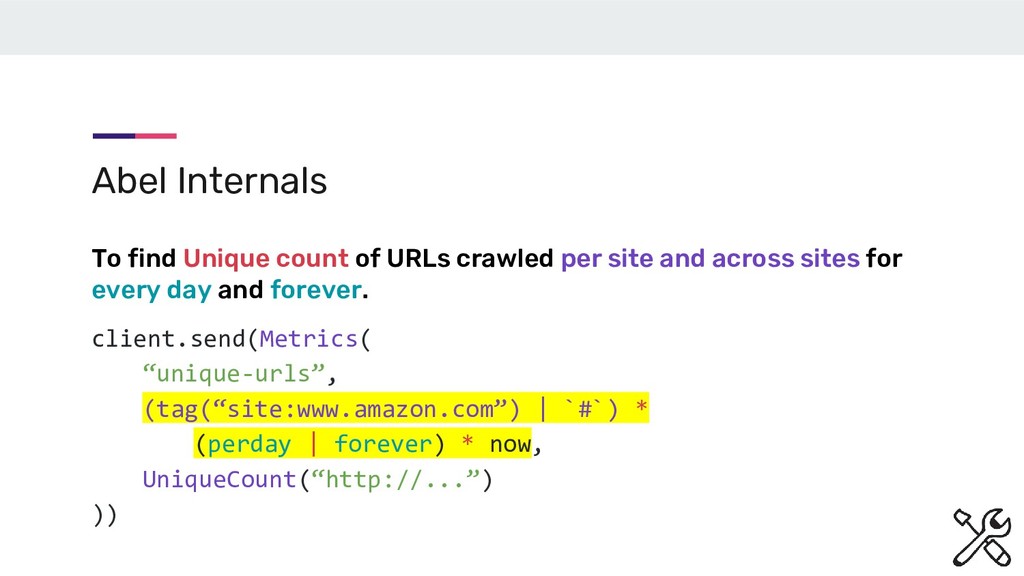
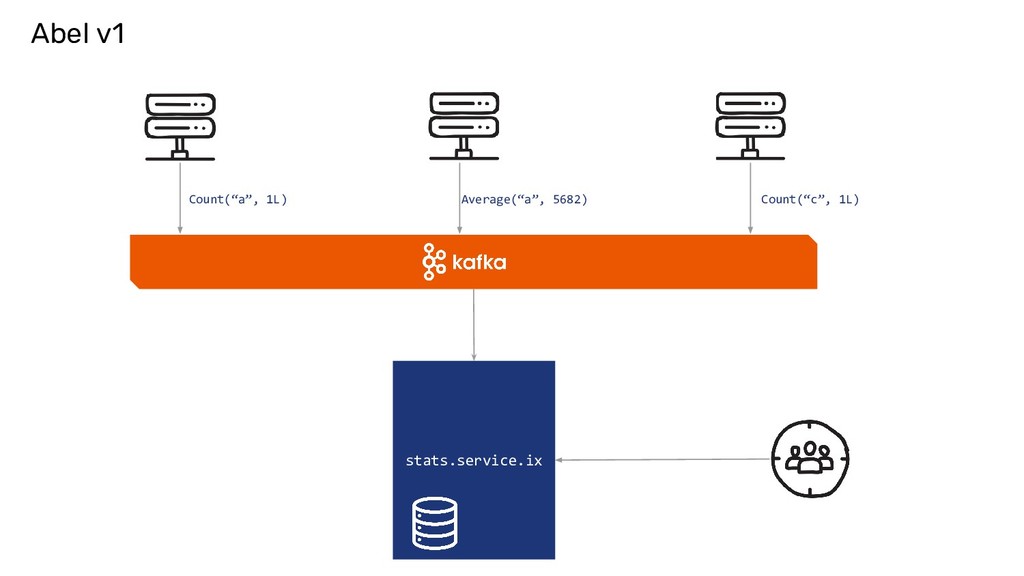
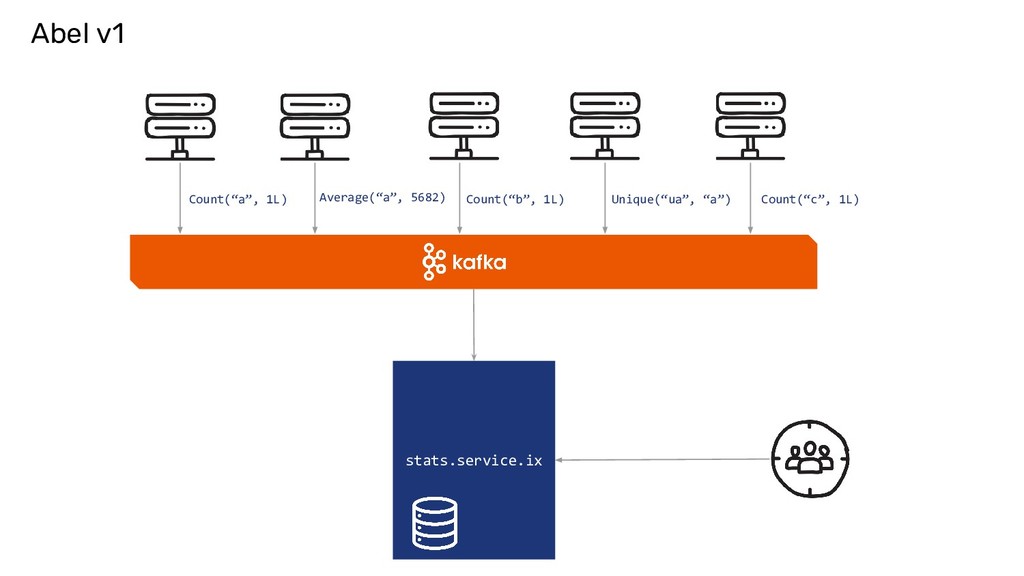
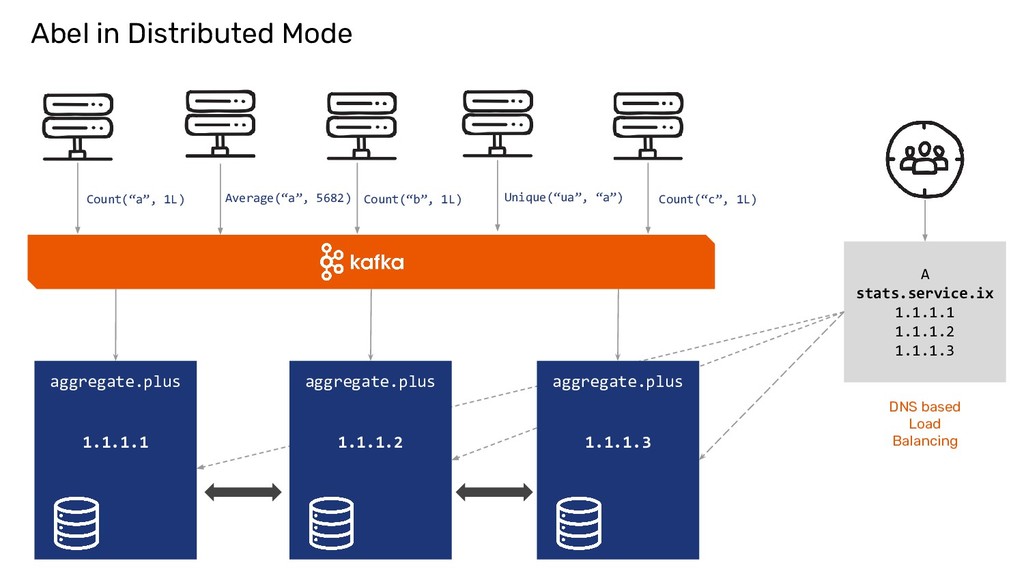
now, UniqueCount(“http://...”) )) Abel Internals To find Unique count of URLs crawled per site and across sites for every day and forever. It is implemented as a Ring.
Sum Average Response Time Sum with Count & Total Unique count of urls crawled HyperLogLog HTTP Response Code Distribution Count-Min Sketch Top K Websites with poor response time Heap with K elements Website response times percentiles QTree (loosely based on q-digest) Histogram of response times Array(to model bins) and slotwise Sum
◦ Identity ◦ Inverse • Monoid under multiplication ◦ Associative ◦ Multiplicative Identity • Multiplication is distributive with respect to addition ◦ (a + b) . c = (ac + bc) Right Distributivity ◦ a . (b + c) = (ab + ac) Left Distributivity
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1200 3600 4800 [1200,1] [3600,1] [4800,1] +](https://files.speakerdeck.com/presentations/90bfaa54ed464bf79be8f332890e6bfb/slide_12.jpg){kind=link}
![1200 3600 4800 [1200,1] [3600,1] [4800,1] [4800,2] [4800,1] + +](https://files.speakerdeck.com/presentations/90bfaa54ed464bf79be8f332890e6bfb/slide_13.jpg){kind=link}
![1200 3600 4800 [1200,1] [3600,1] [4800,1] [4800,2] [4800,1] = 3200](https://files.speakerdeck.com/presentations/90bfaa54ed464bf79be8f332890e6bfb/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}