Why we built a distributed system - DSConf, Pune 2018
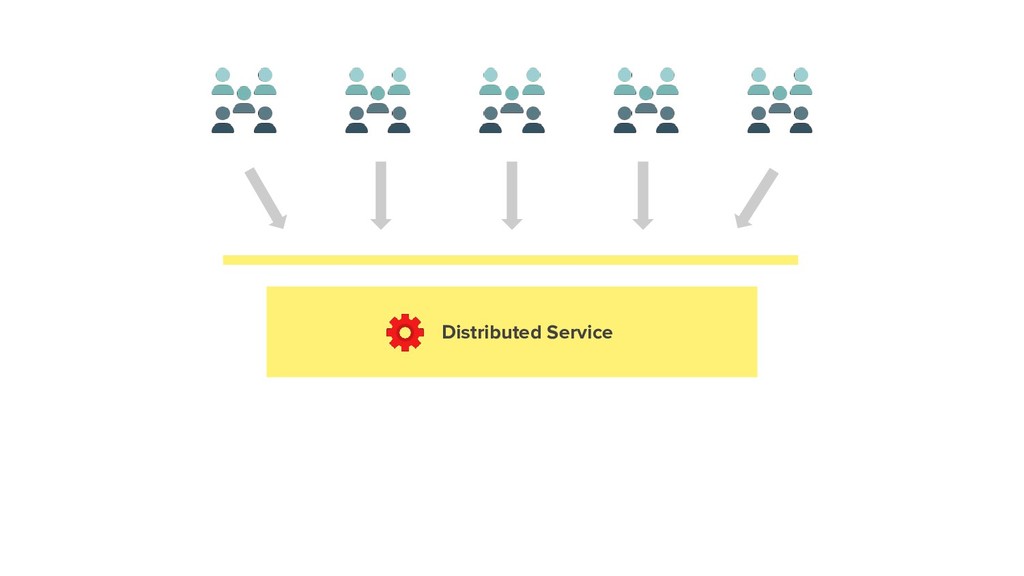
In the first edition of DSConf, we spoke about our reasons for why we built an in-house distributed system and how Suuchi - toolkit to build such systems evolved.
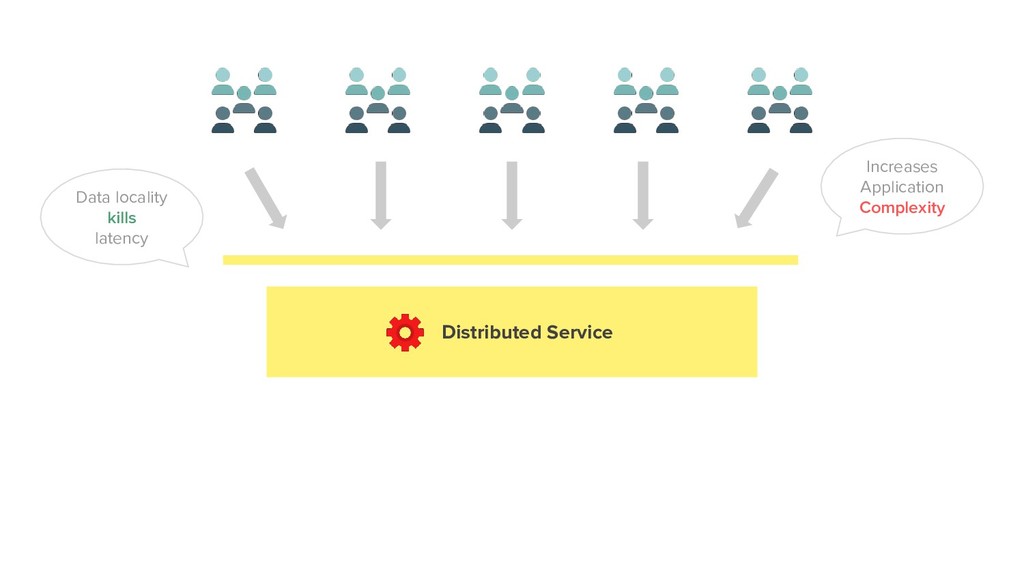
logic upgrade is painful - CoProcessors are not services, more an afterthought - Failure semantics are not well established - More applications means multiple coproc or single bloated coproc - Noisy neighbours / Impedance due to a shared datastore
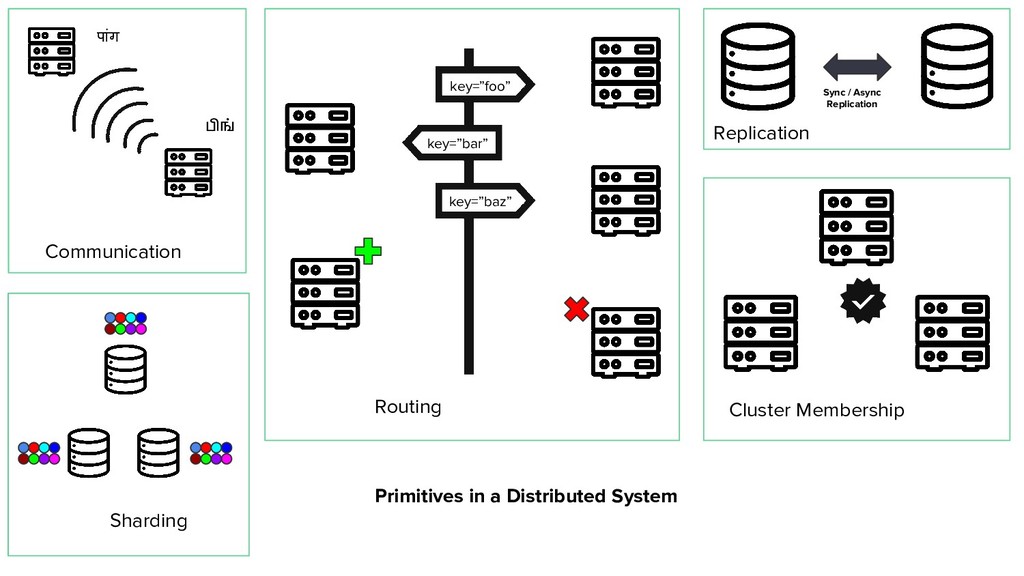
routing queries to appropriate member - detecting your cluster members - replicating your data based on your strategy - local state via embedded KV store per node (optionally) github.com/ashwanthkumar/suuchi
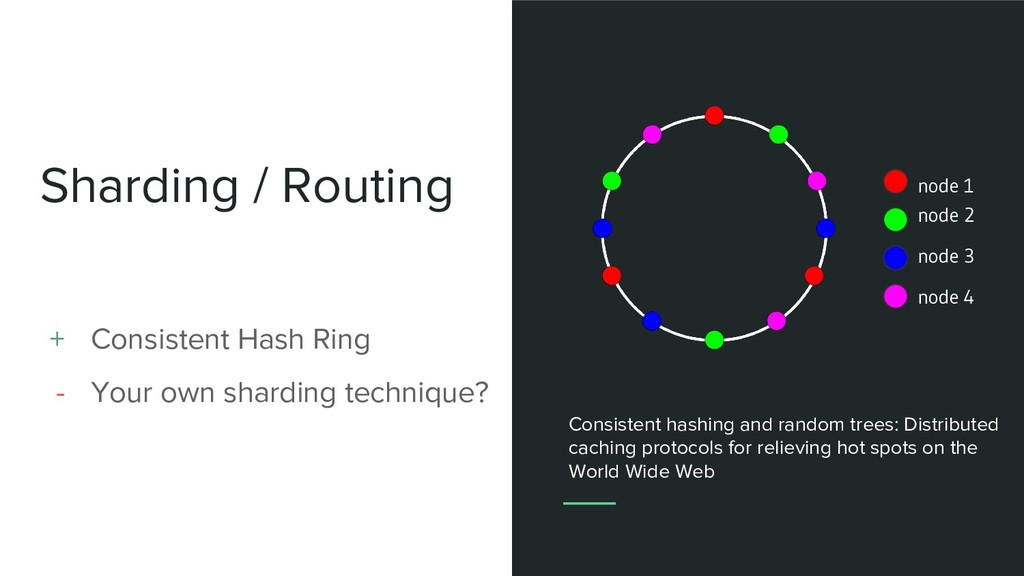
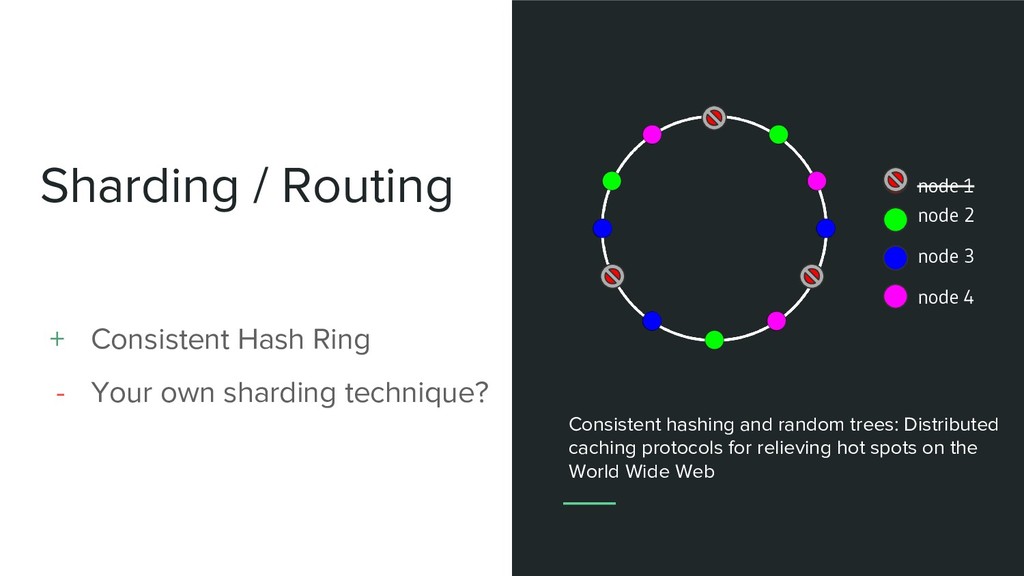
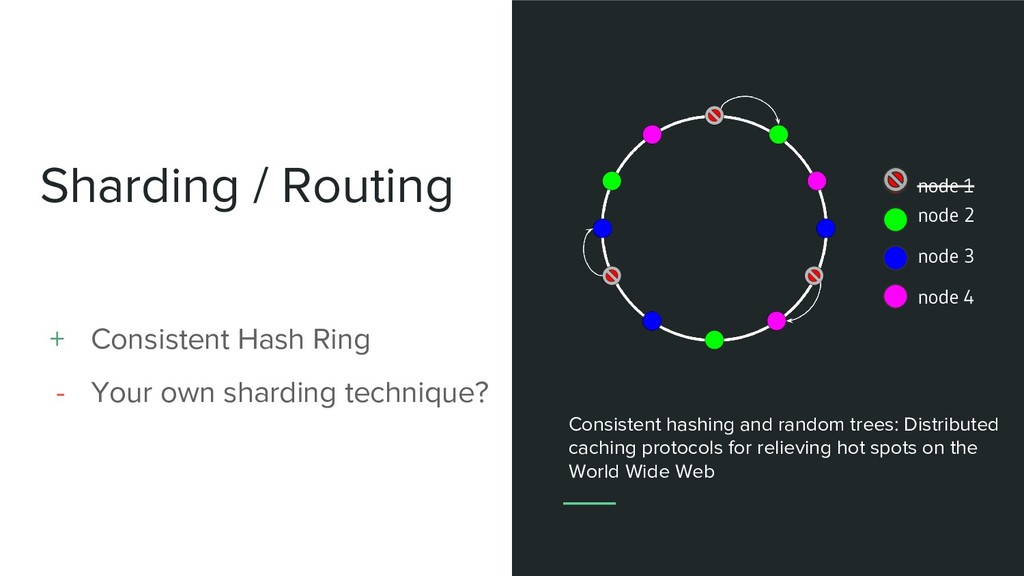
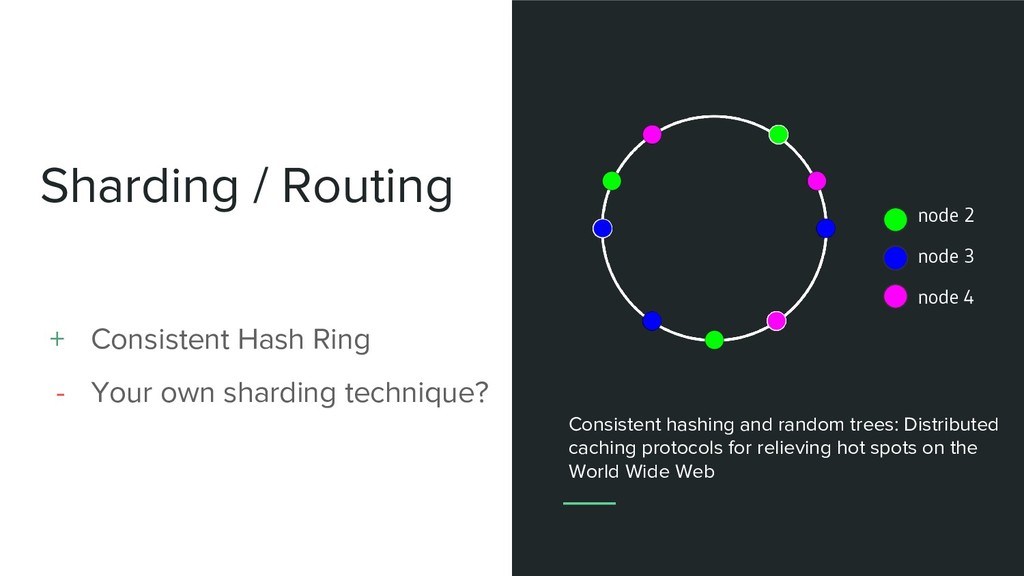
sharding technique? node 2 node 1 node 3 node 4 Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web
sharding technique? node 2 node 1 node 3 node 4 Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web
sharding technique? node 2 node 1 node 3 node 4 Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web
sharding technique? Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web node 2 node 3 node 4
- write heavy system ◦ Stores 120 TB of url & timestamp indexed HTML pages • Stats (as Monoids) Aggregation System ◦ Approximate real-time aggregates ◦ Timeline & windowed queries • Real time scheduler for our Crawlers ◦ Prioritising which next batch of urls to crawl ◦ Helps crawl 20+ million urls per day
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}