it takes - Our mission is to protect, provide for, and progress the software and systems behind all of Google’s public services with an ever-watchful eye on their availability, latency, performance, and capacity. - in a “software engineering” way - more scalable, more reliable, more efficient - - … almost same as DevOps
or more precisely, people who have been hired via the standard procedure for Google Software Engineers. - The others are candidates who were very close to the Google Software Engineering qualifications, and who in addition had a set of technical skills that is useful to SRE but is rare for most software engineers. By far, UNIX system internals and networking (Layer 1 to Layer 3) expertise are the two most common types of alternate technical skills we seek. - Team of people who (a) will quickly become bored by performing tasks by hand, and (b) have the skill set necessary to write software to replace their previously manual work - Google places a 50% cap on the aggregate "ops" work for all SREs - We want systems that are automatic, not just automated.
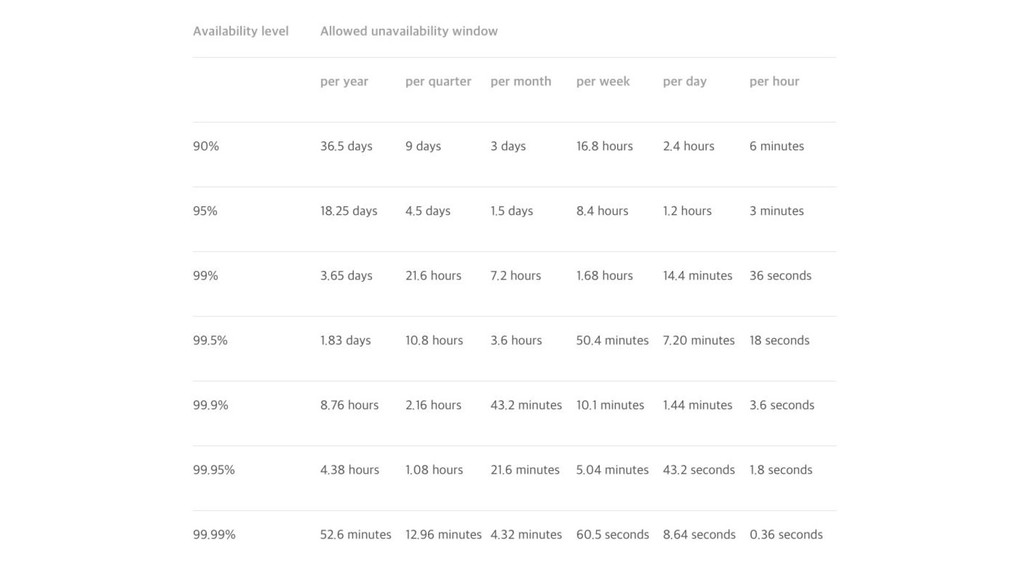
system - Naive approach: Availability = uptime / total time - Better approach: Availability = normal interactions / total interactions - In case of web service: successful requests / totla requests
accept while releasing new software that could have bugs - Error budget = 100% - Target level of availability - Actually a “budget” we can spend every month - Benefit - Risk management by dev team. - Aligns incentives and emphasizes joint ownership between SRE and product development. - Make it easier to decide the rate of releases and to effectively discuss about it.
Boring - “Unlike a detective story, the lack of excitement, suspense, and puzzles is actually a desirable property of source code.” - Remove unnecessary code - every new line of code written is a liability. - The "Negative Lines of Code" Metric - "software bloat" - A smaller project is easier to understand, easier to test, and frequently has fewer defects. - Minimal APIs - "perfection is finally attained not when there is no longer more to add, but when there is no longer anything to take away" by Antoine de Saint Exupery - Modularity (in terms of the design of distributed systems) - Release Simplicity
disaster and emergency testing - SREs break our systems, watch how they fail, and make changes to improve reliability and prevent the failures from recurring - To identify some weaknesses or hidden dependencies and document follow-up actions to rectify the flaws we uncover
documented - all contributing root cause(s) are well understood - effective preventive actions are put in place to reduce the likelihood and/or impact of recurrence Should be a “blameless” postmortem
or degradation beyond a certain threshold - Data loss of any kind - On-call engineer intervention (release rollback, rerouting of traffic, etc.) - A resolution time above some threshold - A monitoring failure (which usually implies manual incident discovery)
Google+ postmortem group - Postmortem reading clubs - Wheel of Misfortune - Disaster Role Playing Game - The formula is straightforward and bears some resemblance to a tabletop RPG (Role Playing Game): the "game master" (GM) picks two team members to be primary and secondary on-call; these two SREs join the GM at the front of the room. An incoming page is announced, and the on-call team responds with what they would do to mitigate and investigate the outage.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}