pode ajudar você a tomar melhores decisões e saber as explicações por trás das melhores práticas de desenvolvimento. ” Paul Irish, Chrome Developer Relations
web escolhido por você por meio de uma solicitação ao servidor e exibição na janela do navegador. O recurso é especificado pelo usuário por meio de um URI (Identificador Uniforme de Recursos).
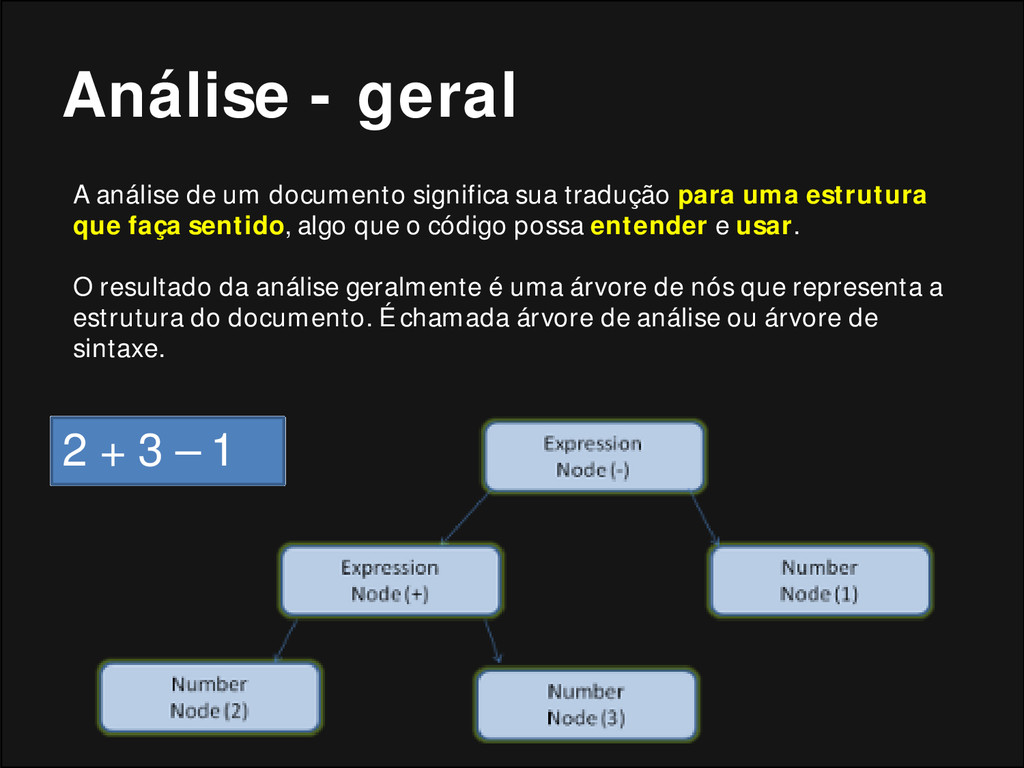
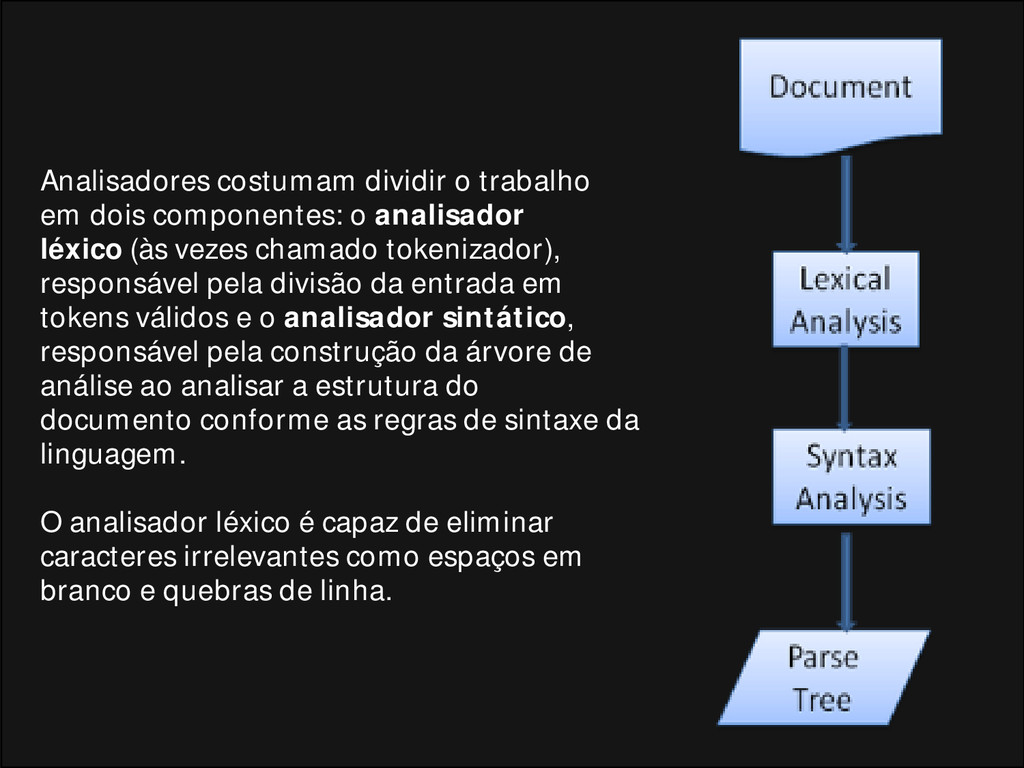
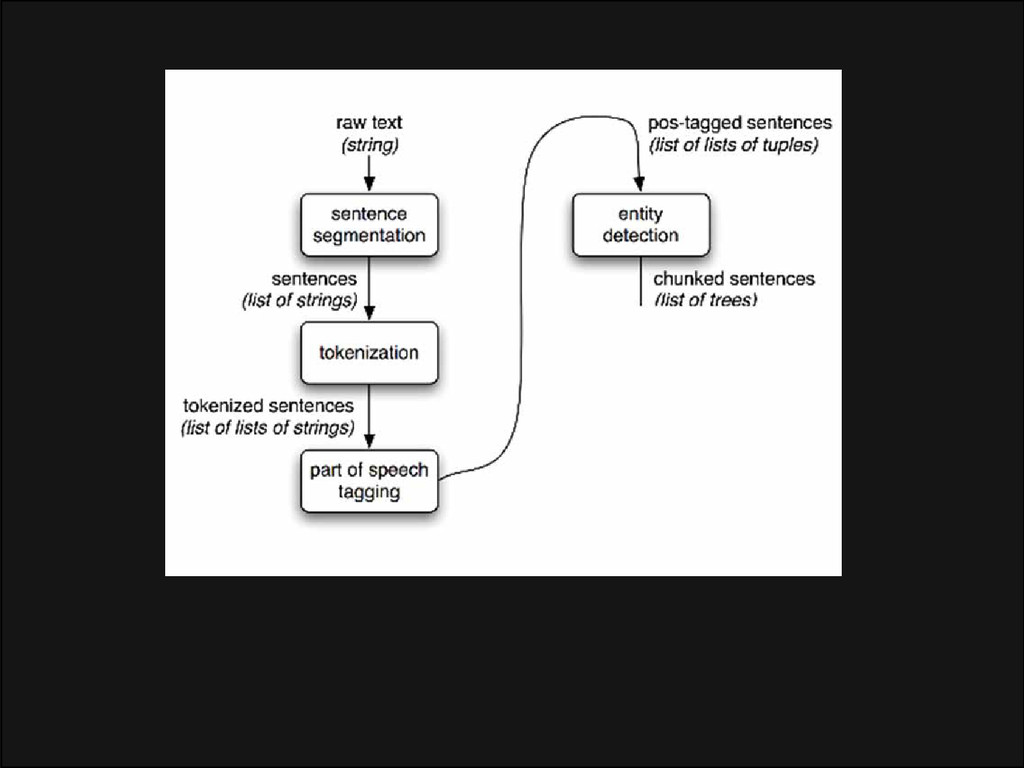
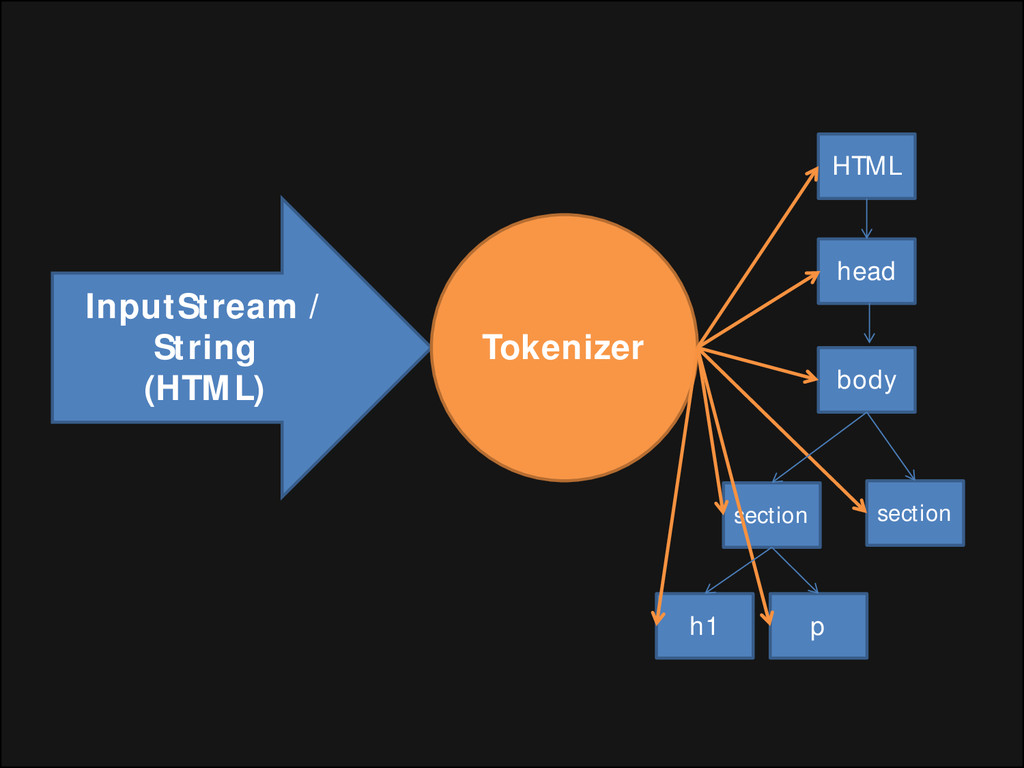
de um documento significa sua tradução para uma estrutura que faça sentido, algo que o código possa entender e usar. O resultado da análise geralmente é uma árvore de nós que representa a estrutura do documento. É chamada árvore de análise ou árvore de sintaxe.
pelo documento - a linguagem ou formato em que foi escrito. Todo formato que pode ser analisado deve possuir gramática determinista composta por regras de vocabulário e sintaxe. Ela é chamada gramática livre de contexto. As linguagens humanas são diferentes desta linguagem e, portanto, não podem ser analisadas por meio de técnicas de análise convencionais.
dois processos - análise léxica e análise sintática. A análise léxica é o processo de divisão das entradas em tokens. Os tokens são o vocabulário de uma linguagem, uma coleção de elementos estruturais válidos. Nas linguagens humanas, isso seria equivalente a todas as palavras que constam no dicionário de determinado idioma. A análise sintática é a aplicação das regras de sintaxe da linguagem.
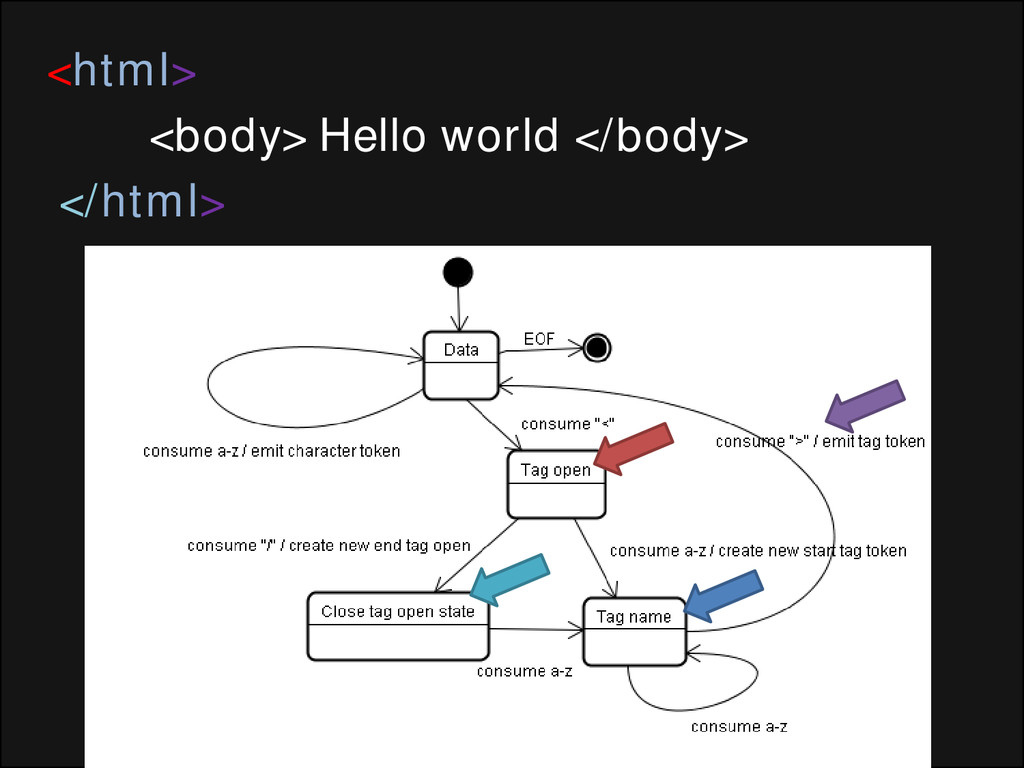
léxico (às vezes chamado tokenizador), responsável pela divisão da entrada em tokens válidos e o analisador sintático, responsável pela construção da árvore de análise ao analisar a estrutura do documento conforme as regras de sintaxe da linguagem. O analisador léxico é capaz de eliminar caracteres irrelevantes como espaços em branco e quebras de linha.
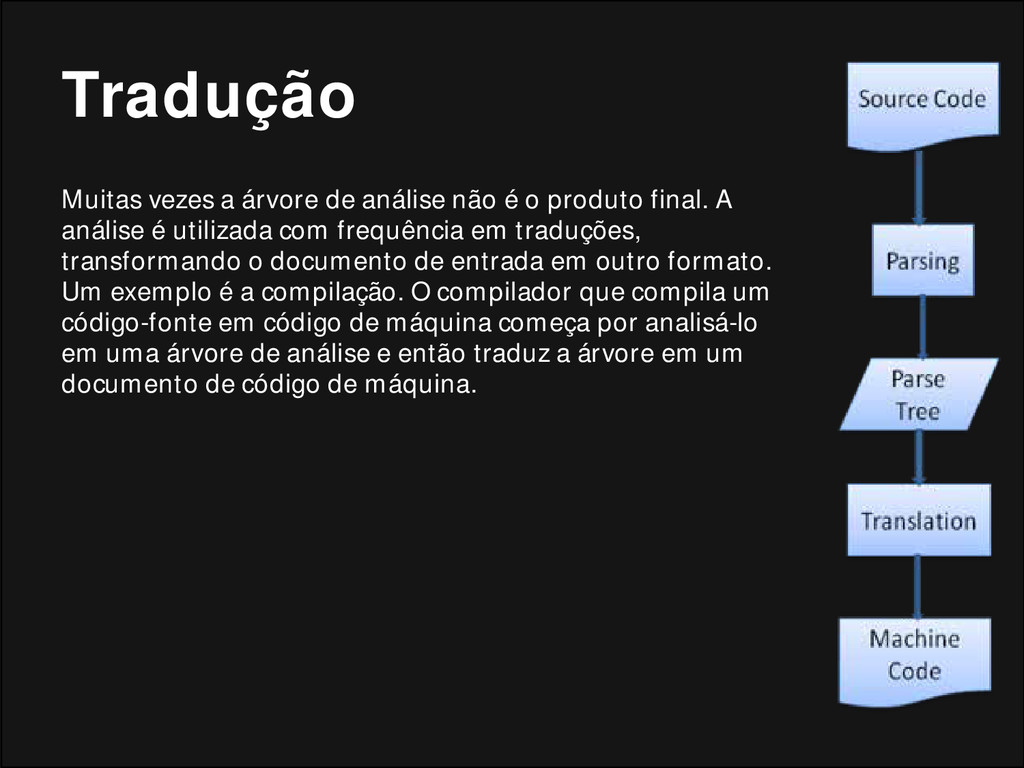
produto final. A análise é utilizada com frequência em traduções, transformando o documento de entrada em outro formato. Um exemplo é a compilação. O compilador que compila um código-fonte em código de máquina começa por analisá-lo em uma árvore de análise e então traduz a árvore em um documento de código de máquina.
formal de definição de HTML — DTD (Definição de Tipo de Documento) —, mas não é uma gramática livre de contexto. Isso pode parecer estranho à primeira vista, mas o HTML é muito semelhante ao XML. Existem diversos analisadores XML. Existe uma variação XML do HTML, chamada XHTML, então qual a diferença? A diferença é que a perspectiva HTML é mais adaptável, pois possibilita a você omitir certas tags adicionadas implicitamente, às vezes omitindo o início ou fim de uma tag, etc. Em geral, é uma sintaxe mais "leve" em oposição à sintaxe rígida e exigente do XML.
um lado, esta é a razão principal para a popularidade do HTML: ele perdoa seus erros e facilita a vida de autores da web. Por outro lado, dificulta a construção de uma gramática formal. Em suma, o HTML não pode ser analisado facilmente, ao menos por analisadores convencionais, já que sua gramática não é livre de contexto, nem por analisadores XML.
fracionar grandes quantidades de dados em outras de menor tamanho para que posteriormente e possívelmente sejam encapsulados em objetos como arrays. Para sincronizarmos os termos definiremos “token” como sendo os pedaços dos dados e “delimitadores” como as expressões que separam os tokens. Obs: Os delimitadores são ignorados, por tanto, não são aplicados aos tokens, exemplo: • fonte: a1b2c3d4 • delimitador: \d • saída: a,b,c,d
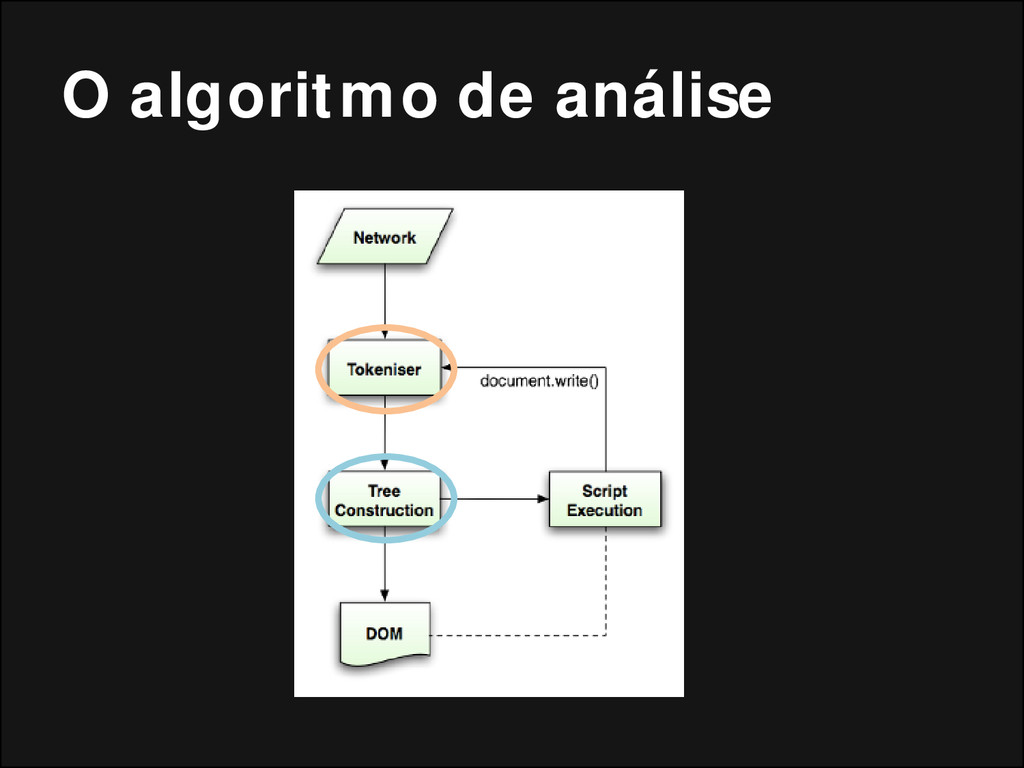
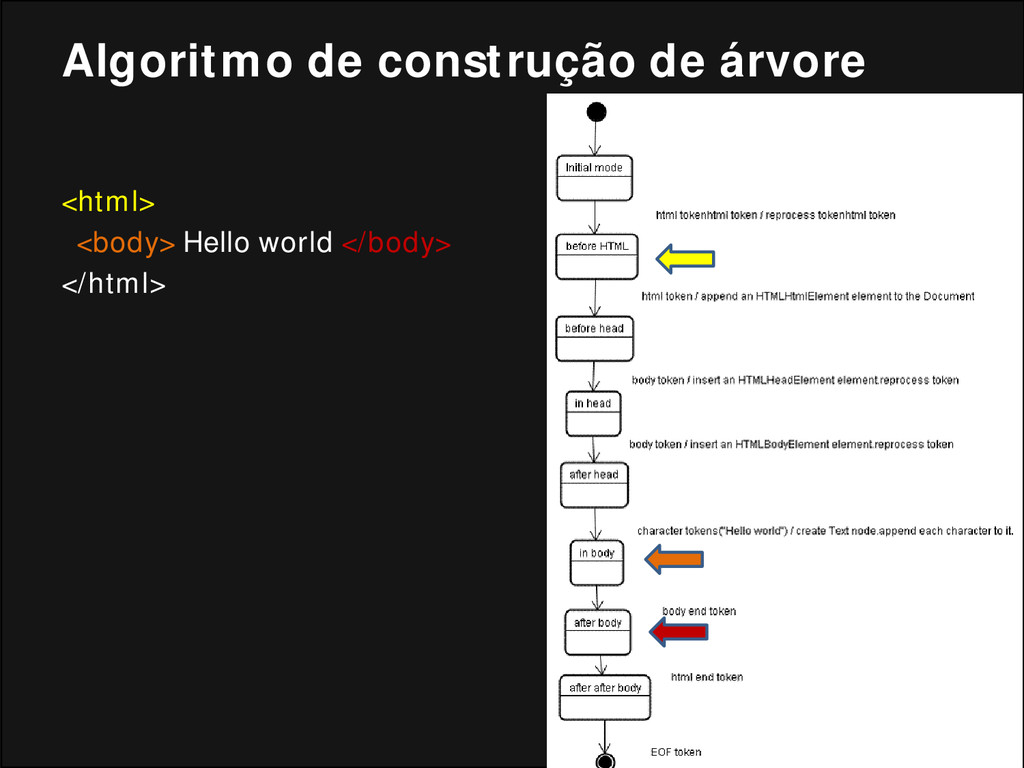
criado, o objeto Document é criado; • Durante a fase de construção da árvore, a árvore DOM com o Documento em sua raiz é modificada e elementos são adicionados a ela; • Cada nó emitido pelo tokenizador é processado pelo construtor da árvore. Para cada token, a especificação define qual elemento DOM é relevante e deve ser criado para o token. Além da adição do elemento à arvore DOM, ele também é adicionado a uma pilha de elementos abertos. Essa pilha é utilizada para corrigir incompatibilidade em aninhamentos e tag que não foram fechadas.
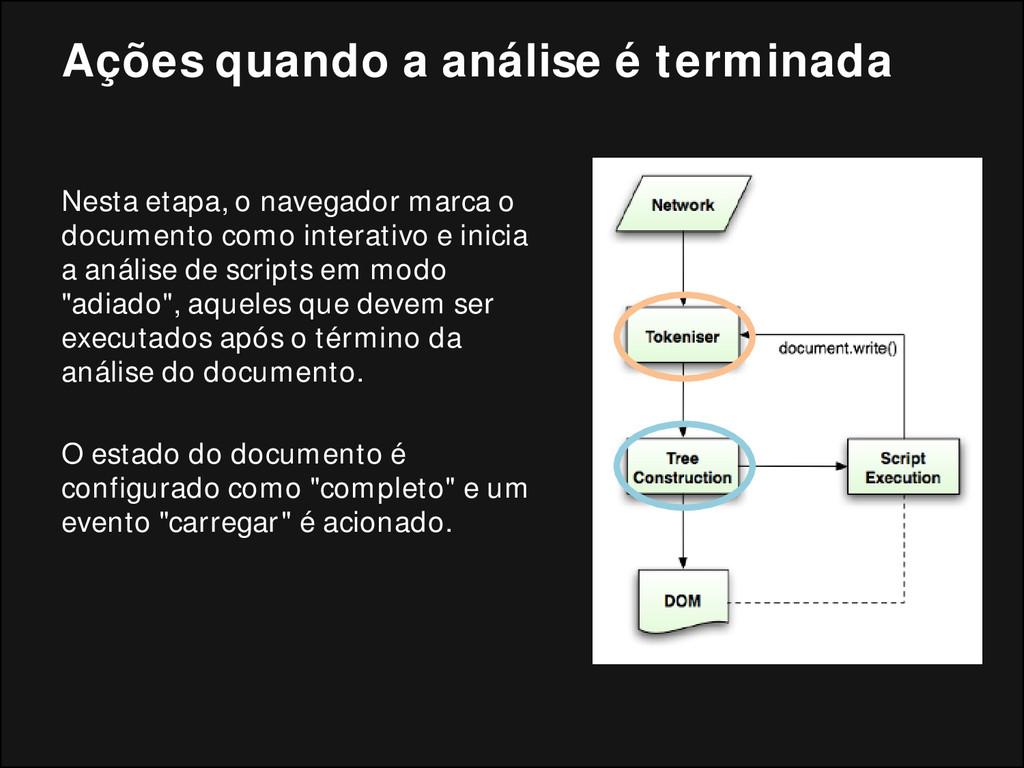
marca o documento como interativo e inicia a análise de scripts em modo "adiado", aqueles que devem ser executados após o término da análise do documento. O estado do documento é configurado como "completo" e um evento "carregar" é acionado.
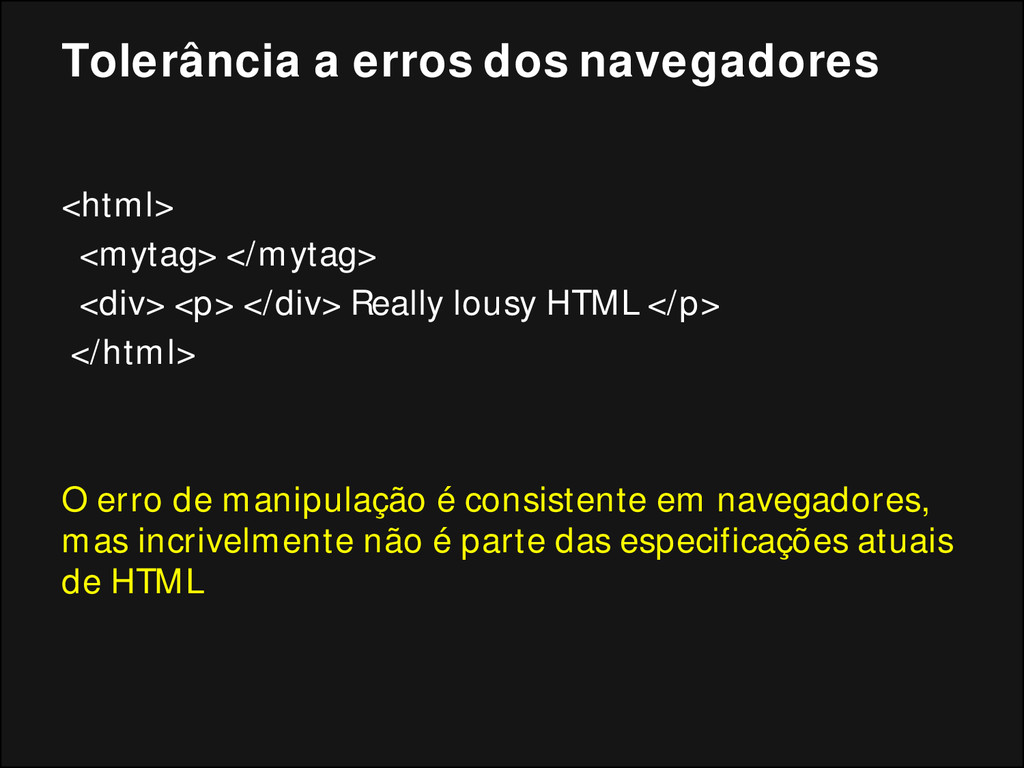
</div> Really lousy HTML </p> </html> O erro de manipulação é consistente em navegadores, mas incrivelmente não é parte das especificações atuais de HTML
árvore do documento. Se o documento tiver uma boa formação, a análise é simples. • Infelizmente, temos que lidar com muitos documentos HTML que não têm boa formação, então o analisador deve ser tolerante com os erros. • Temos que tratar, no mínimo, das seguintes condições de erro: • O elemento adicionado é expressamente proibido caso esteja dentro de uma tag externa. Neste caso, devemos fechar todas as tag até aquela que proíbe o elemento e adicioná-lo em seguida. • Não é permitido adicionar o elemento diretamente. É possível que o autor do documento tenha esquecido de alguma tag no meio (ou que a tag no meio seja opcional). Este pode ser o caso das tags a seguir: HTML HEAD BODY TBODY TR TD LI (esqueci alguma?). • Queremos adicionar um elemento de bloco no interior de um elemento in- line. Feche todos os elementos in-line até o segundo maior elemento de bloco. • Se isso não funcionar, feche os elementos até que possamos adicionar o elemento ou ignorar a tag.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}