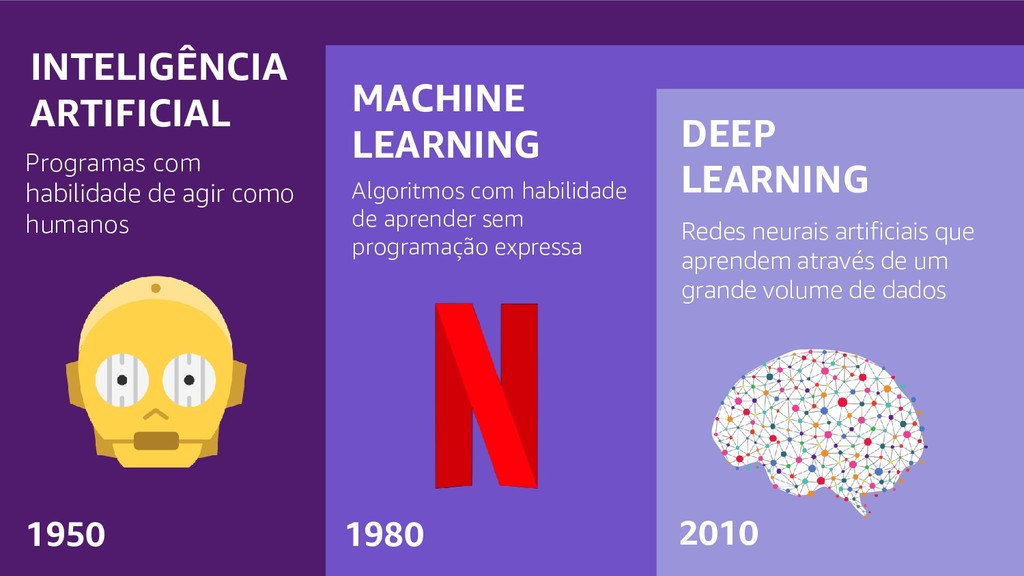
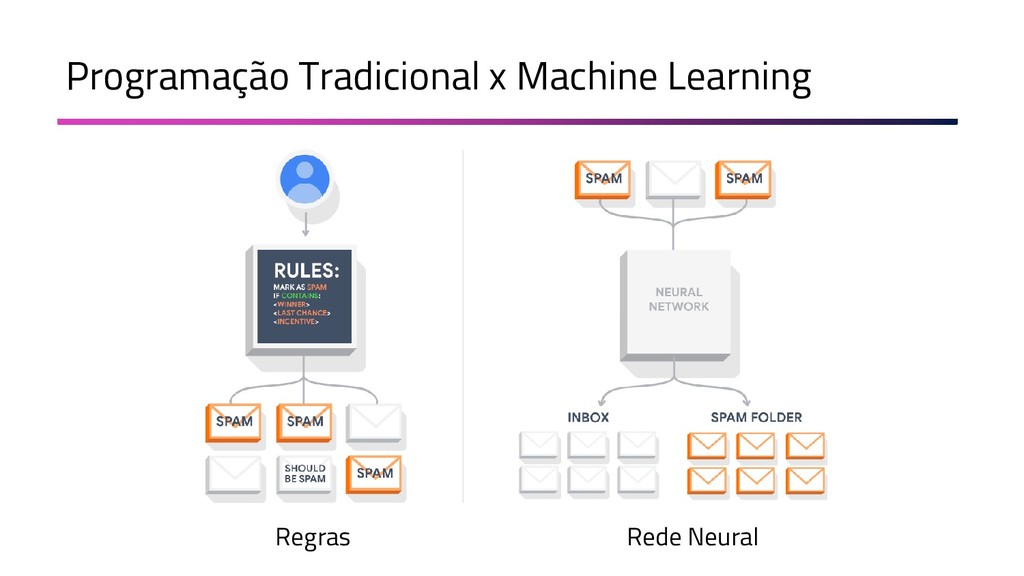
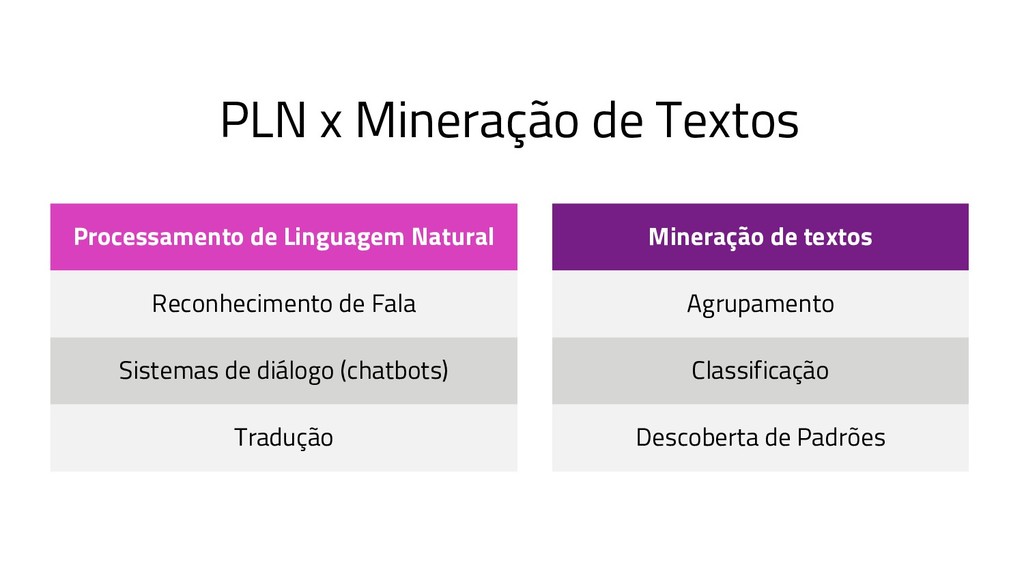
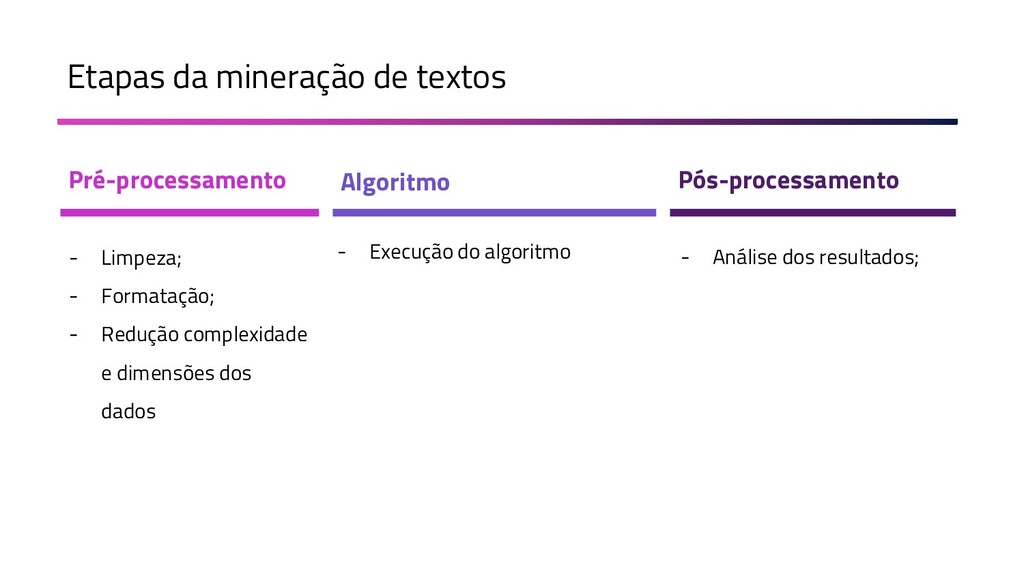
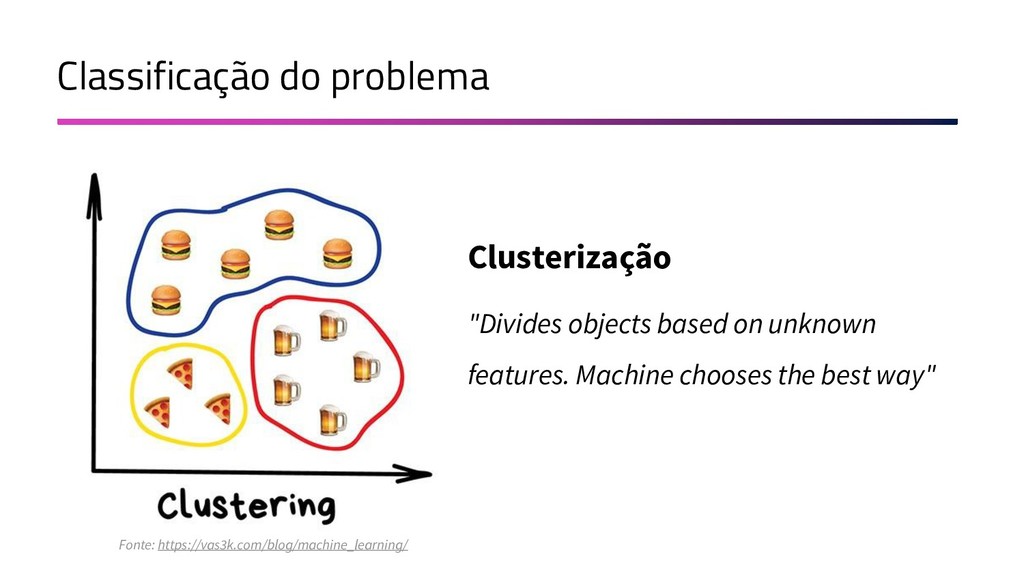
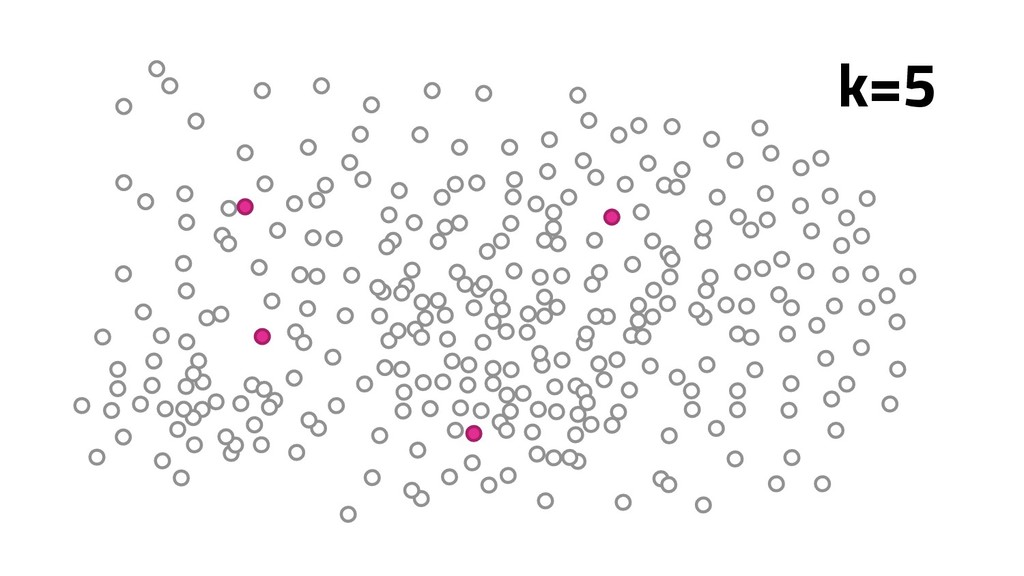
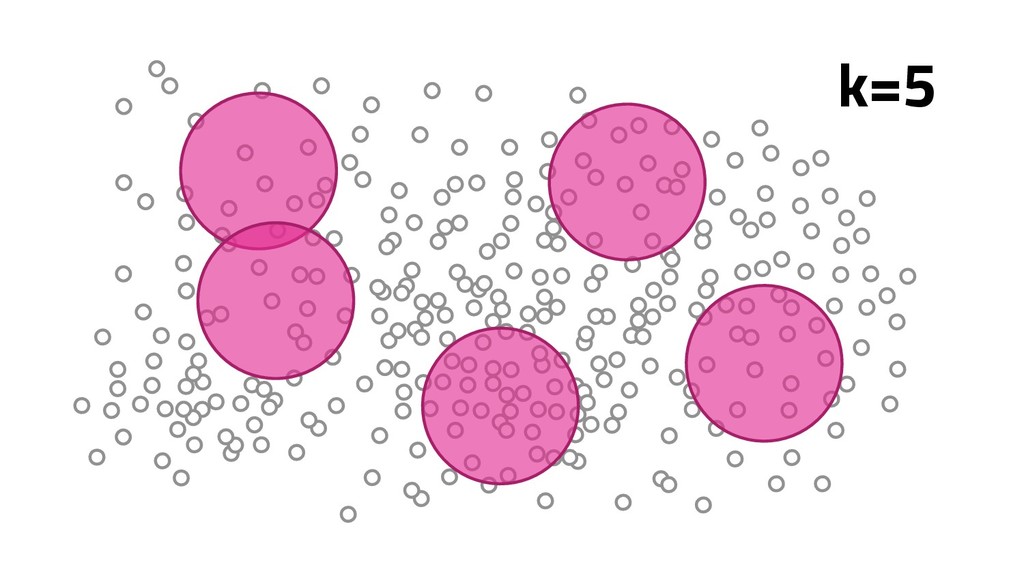
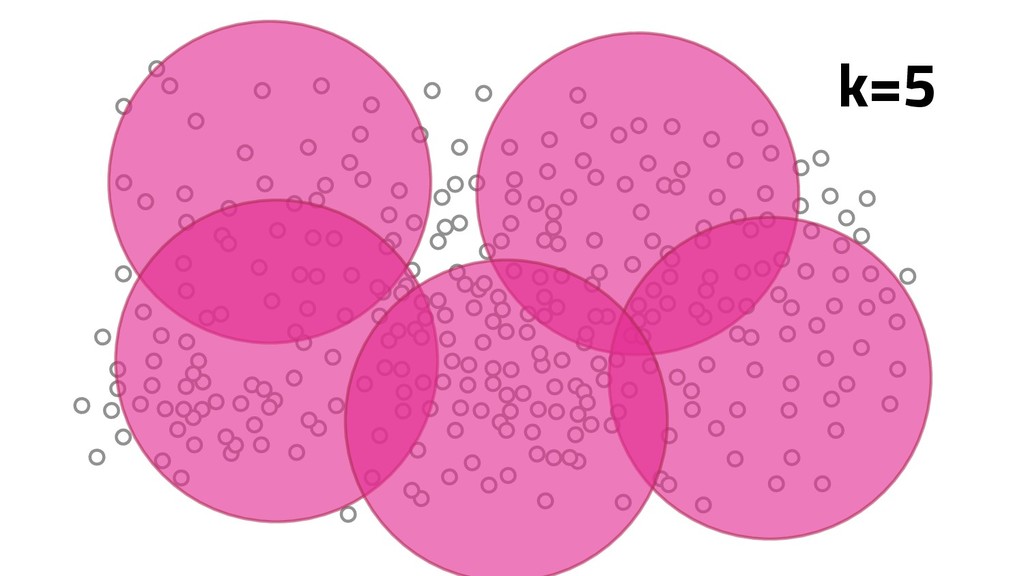
A Mineração de Textos é uma das subáreas da Inteligência Artificial que tem como objetivo extrair padrões e conhecimento útil em textos. Para isso, utilizamos uma série de técnicas de Processamento de Linguagem Natural (PLN). O objetivo do PLN é fornecer aos computadores a capacidade de entender esses textos, criar resumos e até aprender conceitos com os textos processados. Nesta palestra, irei apresentar um case em que apliquei técnicas de machine learning e PLN para minerar notícias da BBC utilizando o algoritmo k-means (implementado por mim em Java) e python para o pré-processamento dos dados.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
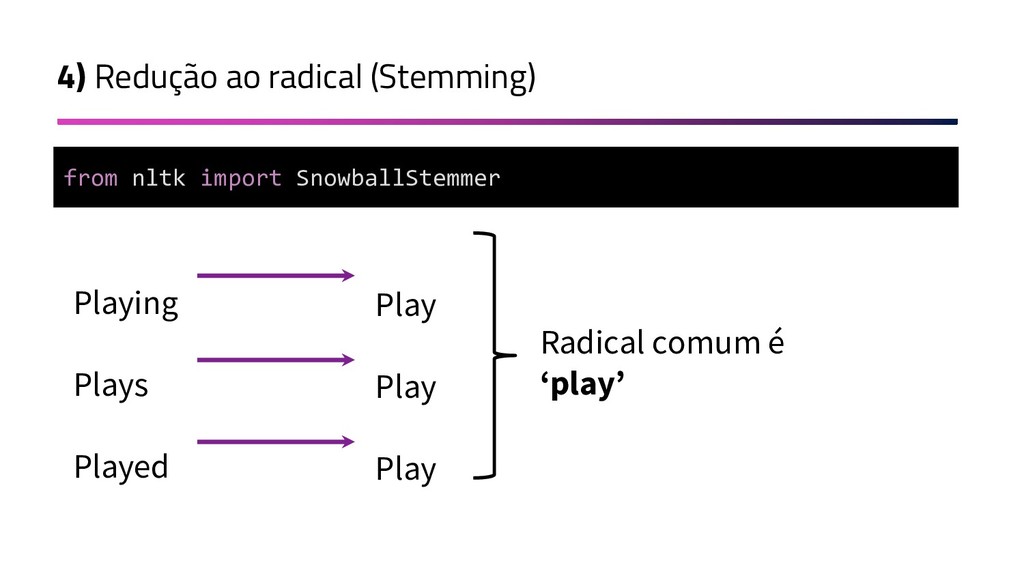{kind=link}
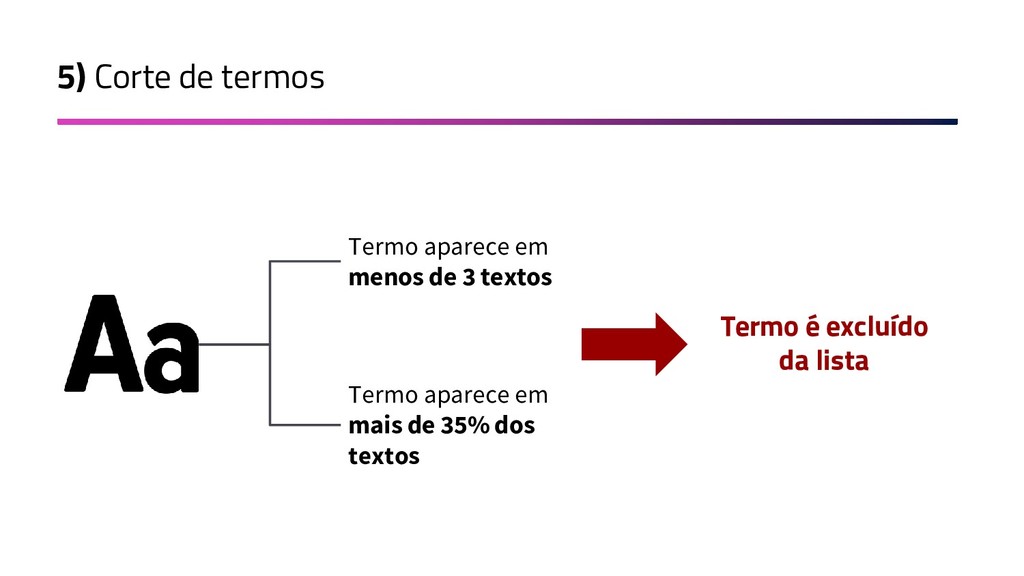{kind=link}
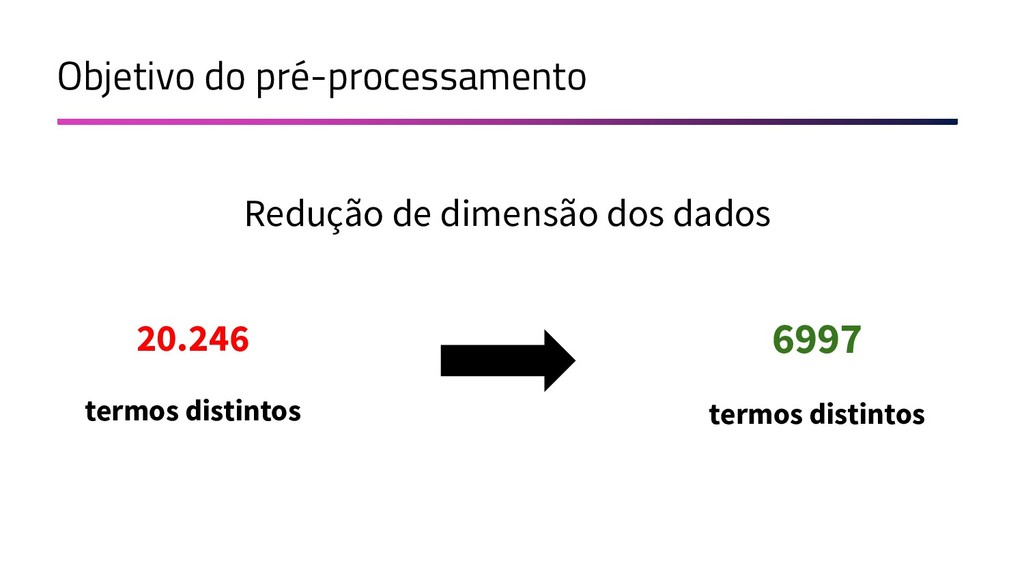{kind=link}
{kind=link}
{kind=link}
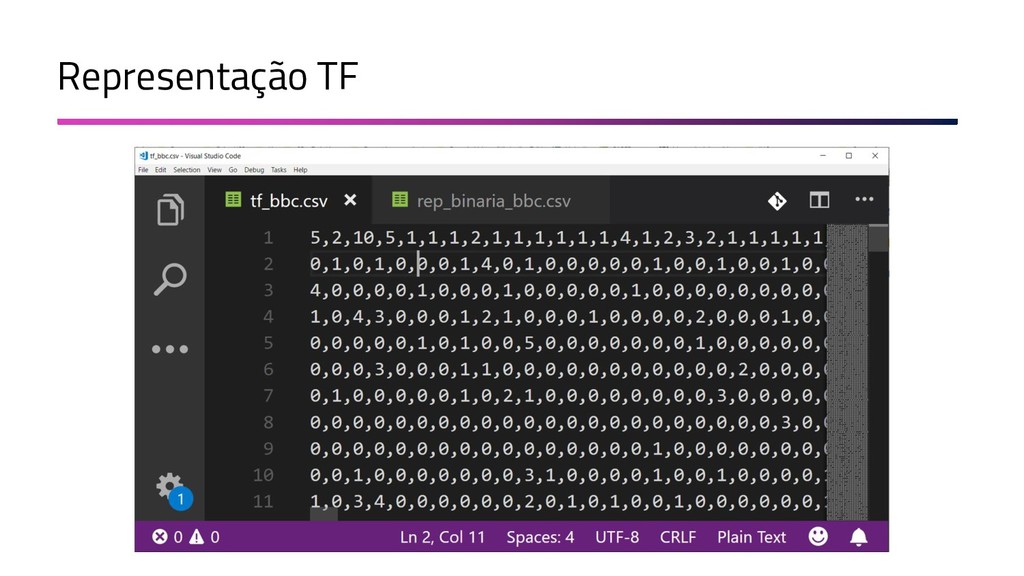{kind=link}
{kind=link}
{kind=link}
{kind=link}
![public void adicionaNoCluster(ArrayList <Coordinate> centroides, ArrayList <Coordinate> pontos, Coordinate [][]](https://files.speakerdeck.com/presentations/fe91372b2354460c9f38f2603bd5d97b/slide_45.jpg){kind=link}
![public ArrayList<Coordinate> novosCentros (ArrayList <Coordinate> centroides, Coordinate [][] grupos, ArrayList](https://files.speakerdeck.com/presentations/fe91372b2354460c9f38f2603bd5d97b/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigada! Carla Vieira [email protected] @carlaprvieira](https://files.speakerdeck.com/presentations/fe91372b2354460c9f38f2603bd5d97b/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}