This deck was delivered at the SF DevOps meetup on June 6, 2019, to introduce TiDB, TiKV and how to run the various components of the TiDB platform on Kubernetes using the operator pattern.
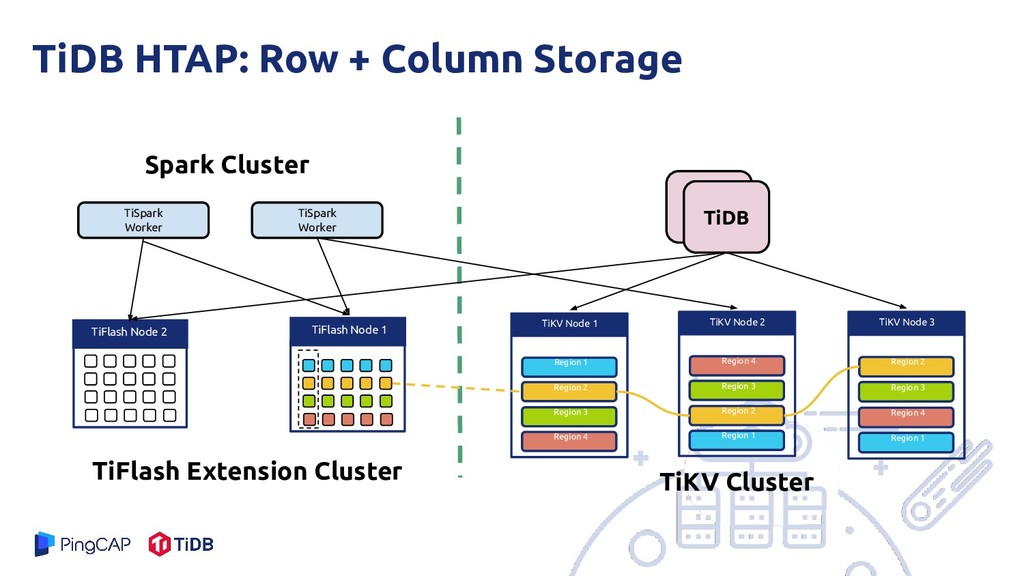
MySQL protocol It is not based on the MySQL source code It is an ACID/strongly consistent database The inspiration is Google Spanner + F1 It separates SQL processing and storage into separate components Both of them are independently scalable The SQL processing layer is stateless It is designed for both Transaction and Analytical Processing (HTAP)
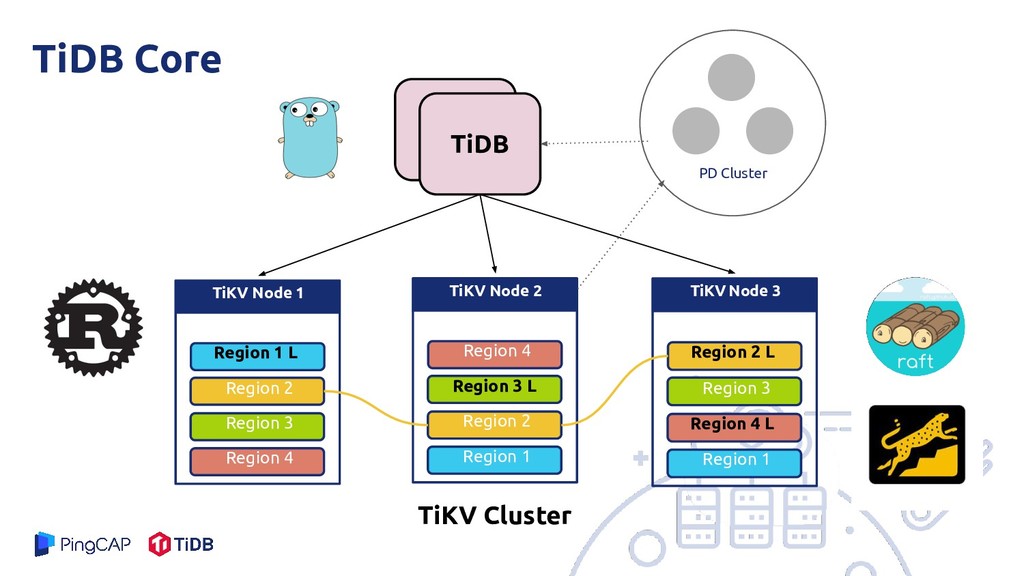
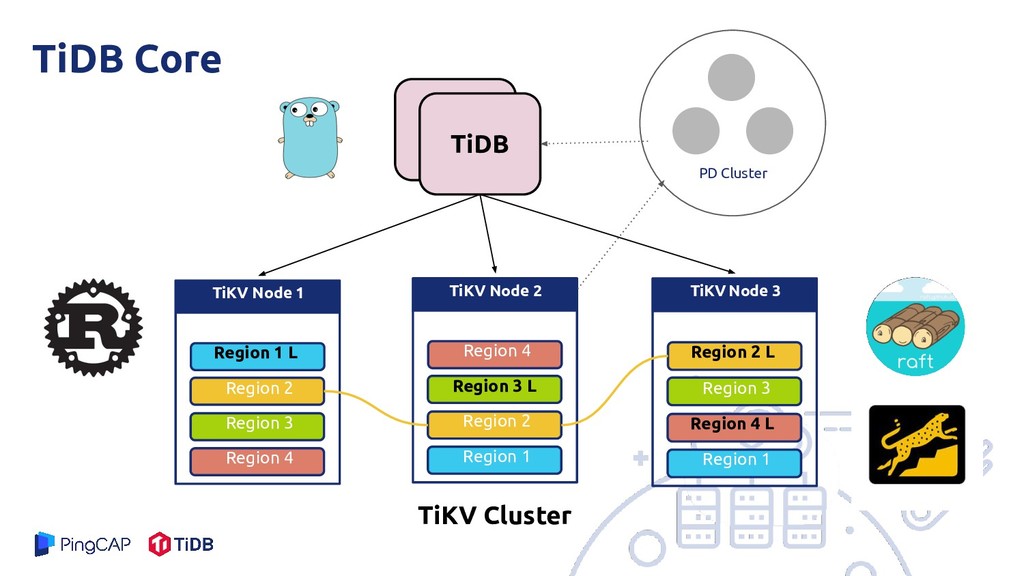
Region 3 Region 4 Region 2 L TiKV Node 3 Region 3 Region 4 L Region 1 Region 4 TiKV Node 2 Region 3 L Region 2 Region 1 TiKV Cluster PD Cluster TiDB Core
Region 1 TiKV Node 1 Region 2 Region 3 Region 4 Region 2 TiKV Node 3 Region 3 Region 4 Region 1 Region 4 TiKV Node 2 Region 3 Region 2 Region 1 TiFlash Node 2 TiFlash Extension Cluster TiKV Cluster TiSpark Worker TiSpark Worker TiFlash Node 1
clusters (multi-tenancy) • Safe scaling (up or down, in or out) • Use different types of Network or Local Storage (different performance) • Automatic monitoring • Rolling updates • Automatic failover • *Multi-Cloud* (as long as it has k8s)
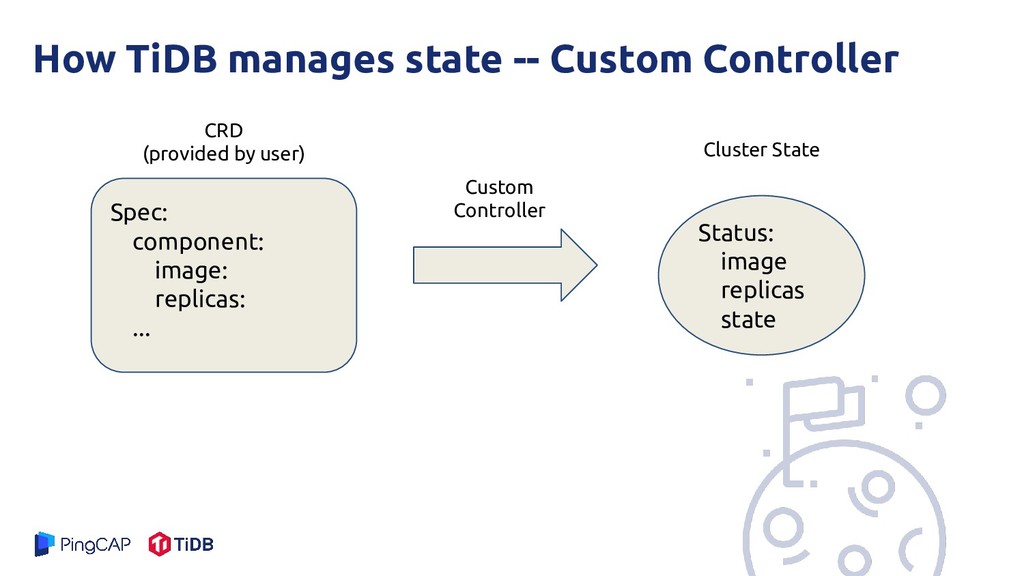
application-specific YAML file ◦ End user writes the domain operation logic in CRD ◦ Simple to implement and deploy • (There is another way): ◦ API Aggregation: ▪ More control, more powerful but… ▪ Hard to deploy, not well-supported by k8s engines
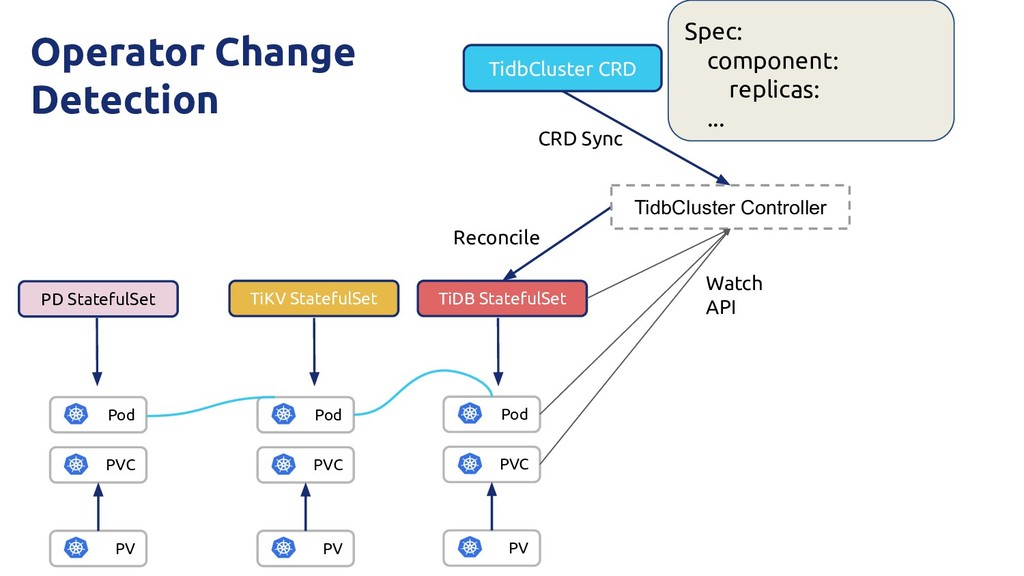
of pods ◦ pd -> tikv -> tidb • Gives “sticky” identity -- network and storage • *No* interchangeable pods ◦ always map the same volume to the same pod • Stable since Kubernetes 1.9
Region 3 Region 4 Region 2 L TiKV Node 3 Region 3 Region 4 L Region 1 Region 4 TiKV Node 2 Region 3 L Region 2 Region 1 TiKV Cluster PD Cluster TiDB Core
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}