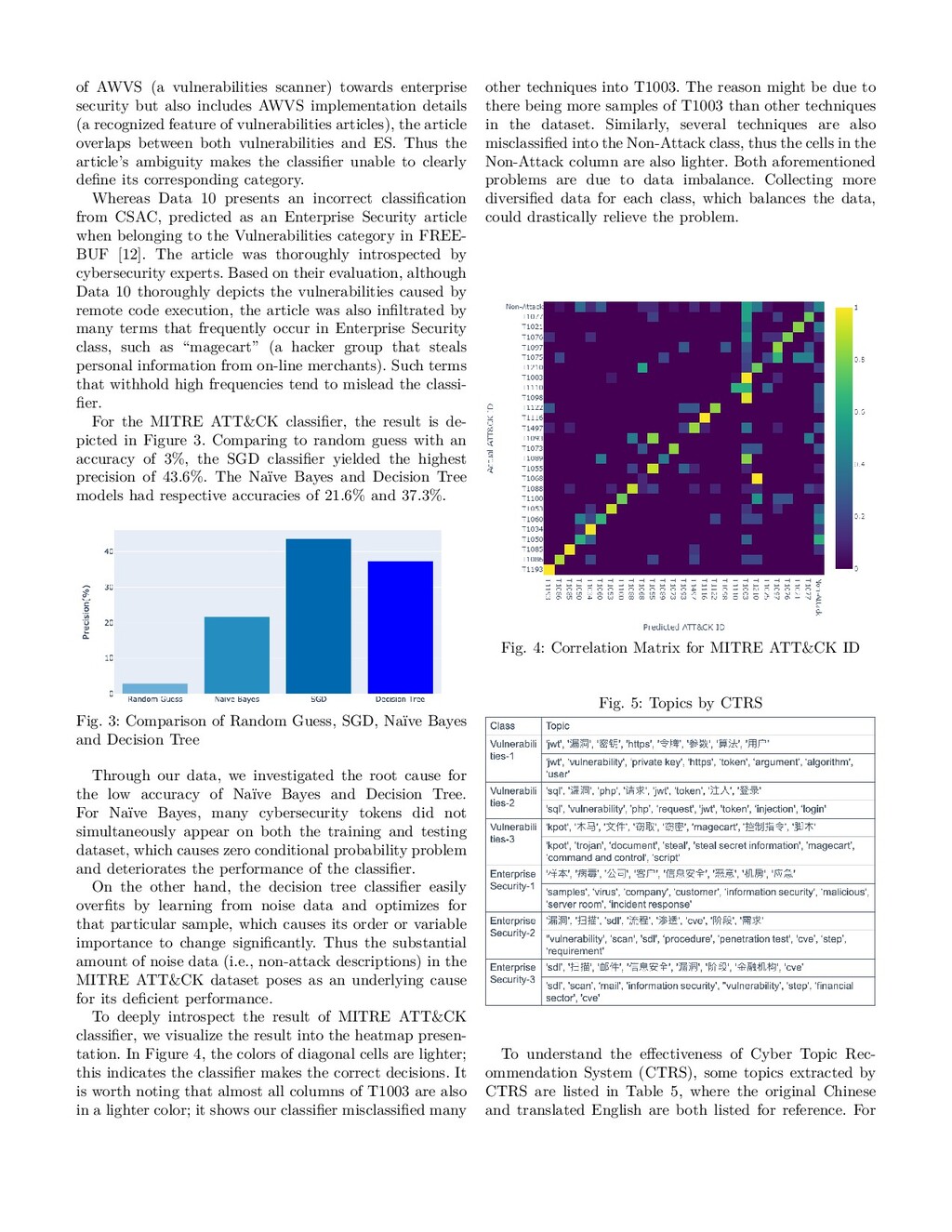
related to cryptography, authen- tication, and network application vulnerability. Therefore, these topics could provide a higher level of meaning for security experts. We could observe from Figure 5 that there are still some too-common keywords (e.g., argument, information security, and step). These keywords only provide rare information. Thus removing these keyword could further improve the effectiveness of CTRS. While there is no ground truth available to evaluate CTRS, the results are manually reviewed by security experts. The evaluation shown in Table II indicates that the ratio of finding related topics is 75% for vulnerability articles and 85% for Enterprise Security articles. This eval- uation demonstrates that CTRS can provide meaningful hints for security experts to quickly capture the topics of the article. TABLE II: Evaluation result of CTRS topic non-relative high medium low Vulnerabilities 5 4 4 7 Enterprise Security 3 6 7 4 V. Conclusion As we mentioned in the introduction, the lack of Chi- nese threat intelligence visibility creates a blind spot for CTI. Additionally, highly-active Chinese security forums provide fertile sources for intelligence. In this paper, CTI ANT, a novel prototype for Chinese CTI analysis is proposed to enlarge the threat intelligence visibility and analysis capability to Chinese data sources. In addition to the quantitative performance measure- ments mentioned in the evaluations section, here we highlight the findings from our study: 1) Cyber Security Article Classifier (CSAC): We have established an automatic classification system that assists security analysts to quickly identify the theme of cyber threat data, a significant step towards Chinese CTI gathering and updating. 2) Cyber Topic Recommendation System (CTRS): It determines the inter-similarity of prevalent security- related keywords and clusters them to distinct cy- bersecurity topics. Not only does the CTRS results assist threat analysts in identifying key threat actors to deploy appropriate security controls, but the results have also revealed intrinsic connections across various keywords. 3) MITRE ATT&CK Detector (MD): We respectively analyzed various classification models to automat- ically recognize MITRE ATT&CK techniques in Chinese APT reports, facilitating the design of bet- ter cyber defense mechanisms for multiple domains. Through the visualization of MITRE ATT&CK detections in heatmap format, we have further un- covered the imbalance of Chinese MITRE ATT&CK data and proposed adjustment strategies to enable higher-efficiency results for future Chinese CTI in- spection. References [1] D. Chismon and M. Ruks, “Threat intelligence: Collecting, analysing, evaluating,” MWR InfoSecurity Ltd, 2015. [2] V. G. Li, M. Dunn, P. Pearce, D. McCoy, G. M. Voelker, and S. Savage, “Reading the tea leaves: A comparative analysis of threat intelligence,” in 28th {USENIX} Security Symposium ({USENIX} Security 19), 2019, pp. 851–867. [3] S. Samtani, M. Abate, V. Benjamin, and W. Li, “Cybersecurity as an industry: A cyber threat intelligence perspective,” The Palgrave Handbook of International Cybercrime and Cyberde- viance, pp. 135–154, 2020. [4] J. Zhao, Q. Yan, J. Li, M. Shao, Z. He, and B. Li, “Timiner: Au- tomatically extracting and analyzing categorized cyber threat intelligence from social data,” Computers & Security, p. 101867, 2020. [5] T. Wang and K. P. Chow, “Automatic tagging of cyber threat intelligence unstructured data using semantics extraction,” in 2019 IEEE International Conference on Intelligence and Secu- rity Informatics (ISI). IEEE, 2019, pp. 197–199. [6] H. Wu, X. Li, and Y. Gao, “An effective approach of named entity recognition for cyber threat intelligence,” in 2020 IEEE 4th Information Technology, Networking, Electronic and Au- tomation Control Conference (ITNEC), vol. 1. IEEE, 2020, pp. 1370–1374. [7] S. Mittal, A. Joshi, and T. Finin, “Cyber-all-intel: An ai for security related threat intelligence,” arXiv preprint arXiv:1905.02895, 2019. [8] L. Perry, B. Shapira, and R. Puzis, “No-doubt: Attack attri- bution based on threat intelligence reports,” in 2019 IEEE In- ternational Conference on Intelligence and Security Informatics (ISI). IEEE, 2019, pp. 80–85. [9] MITRE, Threat Report ATT&CK® Mapping (TRAM), 2019 (accessed October 4, 2020). [Online]. Available: https: //github.com/mitre-attack/tram [10] V. Legoy, “rcatt: Retrieving att&ck tactics and techniques in cyber threat reports,” FIRST Cyber Threat Intelligence Symposium, 2020. [11] G. Husari, E. Al-Shaer, B. Chu, and R. F. Rahman, “Learning apt chains from cyber threat intelligence,” in Proceedings of the 6th Annual Symposium on Hot Topics in the Science of Security, 2019, pp. 1–2. [12] FreeBuf, 2012 (accessed October 15, 2020), https://www. freebuf.com/. [13] VULHUB, 2012 (accessed October 15, 2020), http://vulhub. org.cn/attack. [14] Simplified Chinese Stop Word list, 2019 (accessed Octo- ber 15, 2020), https://github.com/goto456/stopwords/blob/ master/cn_stopwords.txt. [15] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Ma- chine learning in Python,” Journal of Machine Learning Re- search, vol. 12, pp. 2825–2830, 2011. [16] C. Sumiyoshi, H. Fujino, T. Sumiyoshi, Y. Yasuda, H. Ya- mamori, M. Fujimoto, and R. Hashimoto, “Semantic memory organization in japanese patients with schizophrenia examined with category fluency,” Frontiers in Psychiatry, vol. 9, p. 87, 2018. [17] X. Liao, K. Yuan, X. Wang, Z. Li, L. Xing, and R. Beyah, “Acing the ioc game: Toward automatic discovery and analysis of open- source cyber threat intelligence,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’16. New York, NY, USA: Association for Computing Machinery, 2016, p. 755–766.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}