Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
数式をなるべく使わないベイズ推定入門
Search
Masayuki Isobe
February 03, 2013
Technology
25k
24
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
数式をなるべく使わないベイズ推定入門
第13回 モヤLT発表資料
Masayuki Isobe
February 03, 2013
Other Decks in Technology
See All in Technology
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
5.3k
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
0
300
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.2k
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
110
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3k
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3.9k
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
150
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
110
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.1k
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
140
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
1
2.9k
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
130
Featured
See All Featured
Why Our Code Smells
bkeepers
PRO
340
58k
Site-Speed That Sticks
csswizardry
13
1.3k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Design in an AI World
tapps
1
260
What's in a price? How to price your products and services
michaelherold
247
13k
How STYLIGHT went responsive
nonsquared
100
6.2k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Leo the Paperboy
mayatellez
8
1.9k
The SEO Collaboration Effect
kristinabergwall1
1
500
Ethics towards AI in product and experience design
skipperchong
2
330
Accessibility Awareness
sabderemane
1
150
Writing Fast Ruby
sferik
630
63k
Transcript
数式を なるべく 使わない と言いつつけっこう使ってるけど、かなり分かりやすいと思われる ベイズ推定入門 アドファイブ株式会社 代表 礒部正幸 2013/2/3 モヤLT
発表資料 於) リディラバ事務所
確率変数 (例1) 「明日の天気」という確率変数 天気 = {晴れ90%, 雨7%, 雪3% } (例2)
「30日後の天気」という確率変数 天気 = {晴れ50%, 雨45%, 雪5% } (例3) 「とある女子の女心」 という確率変数 女心 = {好き 20%, 気になる30%, なんとも思わない40%, 嫌い10%} (例4) 「とある女子の飲み会での態度」 という確率変数 態度 = {会話が弾んだ 50%, 終始大爆笑15%, 会話なし20%, 目が合っただけ 15%}
確率変数の推定 ・点推定 確率変数の値を一つに決める → 例えば 「女心=“好き“」 と決め打ってしまう ・ベイジアンな推定 確率変数の各実現値(=好きとか嫌いとか)の それぞれの確率(=確率分布)を一つに決める
→ 例えば {好き=70%, 気になる=15%, なんとも思わない=10%, 嫌い=5%} → 値は決め打ちしないけど、「傾向をハッキリさせる」 のがポイント。 ベイズの定理を使って、傾向の移り変わりを定量的に計算するのがベイズ推定。
(点推定といえば)最尤推定 ・尤度が最も高いパラメータに決め打ちする推定方法 例) 態度=「目が合っただけ」だった場合,尤度= P(態度|女心) は P(目が合った|好き) = 90% P(目が合った
| 嫌い) = 40% P(目が合った | なんとも思わない) = 70% P(目が合った|気になる) = 60% → 尤度が最も高いパラメータ(=女心)の実現値は“好き”なので、 最尤推定では、「目が合っただけ」 という態度から 「女心=好き」 と推定される ⇨ 最尤推定の欠点: オーバーフィッティング(つまり、勘違い) 尤度は、女心(=パラメータ)が 態度(=データ)を生み出す メカニズム を規定するもの 尤度 は メカニズム
ベイズの定理 事後分布 = 事前分布 × 尤度 ÷ データの出現確率 ∝ 事前分布
× 尤度 事後分布=P(パラメータ|データ)=P(女心|態度) 事前分布=P(パラメータ)=P(女心) 尤度=P(パラメータ|データ)=P(態度|女心) データの出現確率=P(データ)=P(態度) 相手の反応を見て女心を推測する 「元々がどんだけ」モテるのか は で決まる、という定理 女心が態度に表れる「メカニズム」 心によらずどんな態度をとりがちか MAP推定(後述)やMCMC (後述)では分母は 関係なくなるため、こちらの比例の式も定番
ベイズ更新 事後分布 = 事前分布 × 尤度 ÷ データの出現確率 ∝ 事前分布
× 尤度 事後分布N ∝ 事前分布N-1 × 尤度N ∝ 事前分布N-2 × 尤度N × 尤度N-1 … ⇨ 新しいデータを得るたびに、事後分布を更新して いける (最初の事前分布については、でっち上げる。)
MAP(最大事後確率) 推定 ・(尤度じゃなくて)事後確率が最大になるようなパラメータを決める ※事後確率の計算は∝の式を使えばオッケー(比例定数=データ出現確率) 例) 態度=「目が合っただけ」だった場合,事後分布= P(女心|態度) なので、 P(好き|目が合っただけ) ∝
P(好き)×P(目が合う|好き) P(嫌い|目が合っただけ) ∝ P(嫌い)×P(目が合う|嫌い) P(なんとも|目が合っただけ) ∝ P(なんとも)×P(目が合う|なんとも) P(気になる|目が合っただけ) ∝ P(気になる)×P(目が合う|気になる) (参考)MAP推定はベイズの定理は使うけど点推定なため、ふつうベイジアンな推定手 法とはみなされない。
予測モデルと周辺化 【問題】 P(予測したい事象 | パラメータ) が分かっている時、 P(予測したい事象) を知りたい。 【解】 ・点推定の場合
⇨ パラメータの点推定値を予測モデルに代入すれば、予測分布が求まる 例) P(X) = P(X|女心) | 女心=“好き” = P(X|“好き“) P(“OK”) = P(”OK” | “好き”) P(“NG”) = P(”NG” | “好き”) ・ベイズ推定の場合 ⇨ パラメータの確率を使って予測モデルの期待値を計算すると、予測分布が求まる 例) P(X) = Σ 女心 { P(X|女心)× P(女心) } P(”OK”) = P(”OK” | “好き”)×P(”好き”) + P(”OK” | “嫌い”)×P(”嫌い”) + P(”OK” | “なんとも”)×P(”なんとも”) + P(”OK” | “気になる”)×P(”気になる”) ← 予測モデル ← 予測分布 ← こういう実現値の全パターンを総ナメして確率変数を消す計算を 周辺化と呼ぶ。周辺化を行うのがベイジアンな推定の特徴。
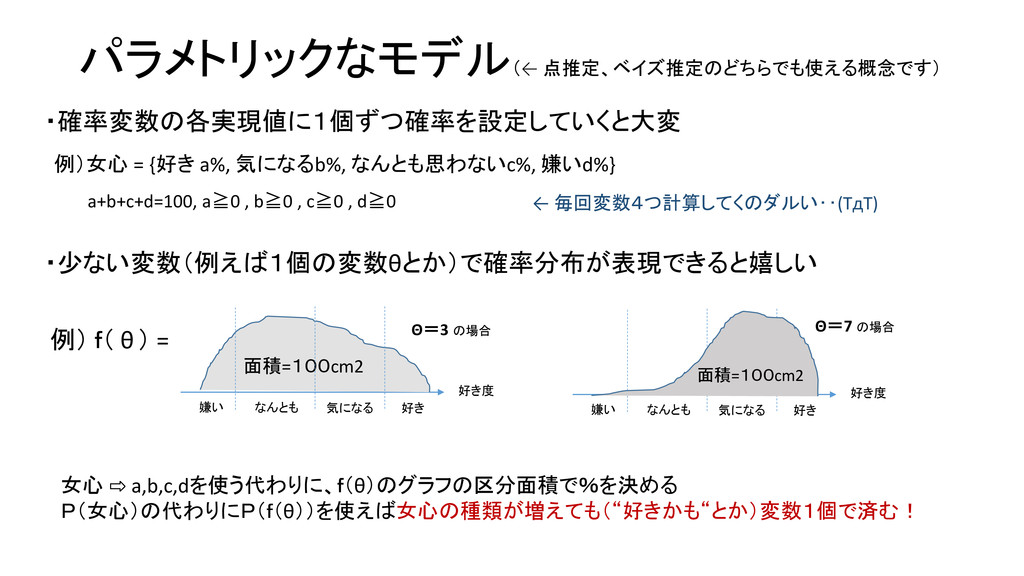
パラメトリックなモデル (← 点推定、ベイズ推定のどちらでも使える概念です) ・確率変数の各実現値に1個ずつ確率を設定していくと大変 例)女心 = {好き a%, 気になるb%, なんとも思わないc%,
嫌いd%} a+b+c+d=100, a≧0 , b≧0 , c≧0 , d≧0 ・少ない変数(例えば1個の変数θとか)で確率分布が表現できると嬉しい 例) f( θ) = ← 毎回変数4つ計算してくのダルい‥(TдT) 好き度 面積=100cm2 好き 気になる なんとも 嫌い Θ=3 の場合 好き度 好き 気になる なんとも 嫌い 女心 ⇨ a,b,c,dを使う代わりに、f(θ)のグラフの区分面積で%を決める P(女心)の代わりにP(f(θ))を使えば女心の種類が増えても(“好きかも“とか)変数1個で済む! Θ=7 の場合 面積=100cm2
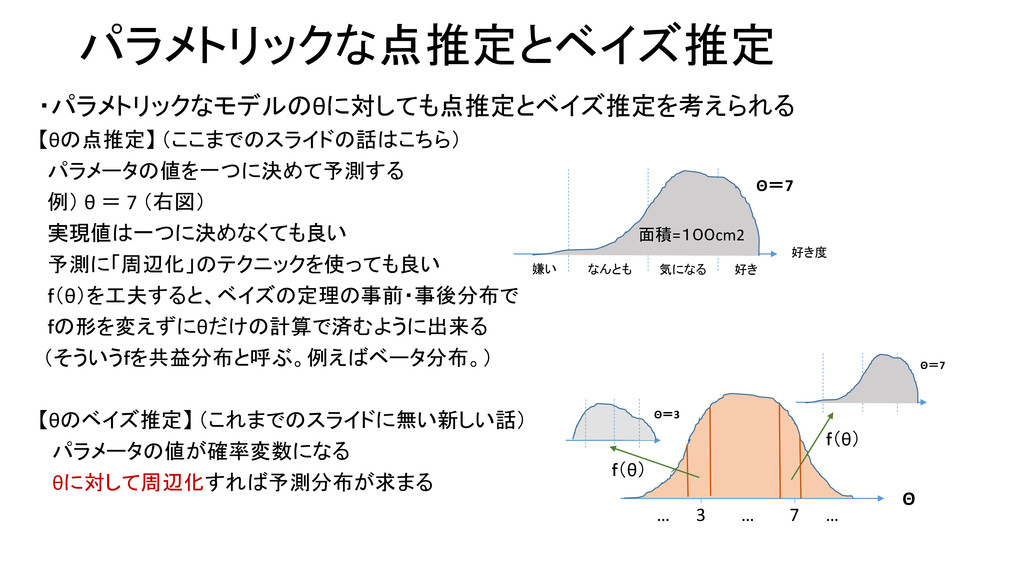
パラメトリックな点推定とベイズ推定 ・パラメトリックなモデルのθに対しても点推定とベイズ推定を考えられる 【θの点推定】 (ここまでのスライドの話はこちら) パラメータの値を一つに決めて予測する 例) θ = 7 (右図)
実現値は一つに決めなくても良い 予測に「周辺化」のテクニックを使っても良い f(θ)を工夫すると、ベイズの定理の事前・事後分布で fの形を変えずにθだけの計算で済むように出来る (そういうfを共益分布と呼ぶ。例えばベータ分布。) 【θのベイズ推定】 (これまでのスライドに無い新しい話) パラメータの値が確率変数になる θに対して周辺化すれば予測分布が求まる 好き度 好き 気になる なんとも 嫌い Θ=7 面積=100cm2 Θ … 3 … 7 … Θ=7 Θ=3 f(θ) f(θ)
サンプリング法 ・ 「θに対して周辺化」って一体どうやるの(;´゚д゚`) ⇨ θの全パターンをリストアップ 【課題】 「パターンの数が多い」 or 「θが連続値で積分も大変」 【対策】
θ は確率変数なので、 「θというサイコロを振って出た目(例えばθ=3.5とか)を使ってf(θ)のグラフを求めて予測分布を計算」 を何度も繰り返すと、 「予測分布というサイコロ」を何度も振って予測値という出目を記録するのと同じことになる ⇨ θの全パターンを計算し尽くさなくても、予測分布というサイコロの傾向が分かる ⇨ つまり予測出来る。 Θ … 3 … 7 … Θ=3.141592.. f(θ) Θが連続値(=実数)だったら 全パターンを総ナメとかムリ… ⇨ 積分を計算する? Θ … 3 … 7 …
• サンプリングのテクニック (ベイズ推定以外にも使える汎用的な手法) 【課題】 Θのグラフが複雑すぎて 「θの出目に似た傾向の乱数ルーチン」を作るのがムズい 【対策】 「Θの出目を直接生成」する乱数ルーチン(☆)は難しくても、 「前の出目が決まってる時に、次の出目を生成」する乱数ルーチン(*)は 割りと作りやすかったりする。
その(*)を上手く設計(★)すると、θ=θ0 を出発点として、 θ1 –(*)-> θ2 –(*)-> θ3 –(*)-> という系列が あたかも乱数ルーチン(☆)からの出力であるかのような 乱数を作り出せる。 (ただし前の値との相関が大きいので、N個スキップ毎に採用するとか、バーンインのため初期値θ0~θ1000 までは捨てるとか、色々工夫する。 Θ … 3 … 7 … こういう分布(サイコロ)だったら たぶん簡単にシミュレーションできる しかしこういうのはむずい。 (Θが2次元だし…) ※(★)の(十分条件)は理論的に分かっている マルコフ連鎖モンテカルロ(略してMCMC)
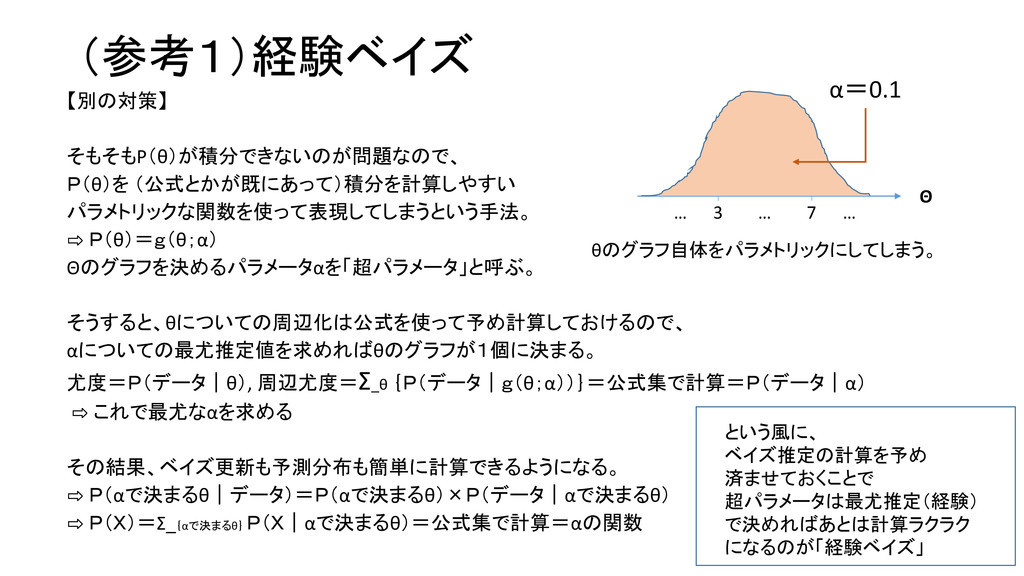
(参考1)経験ベイズ 【別の対策】 そもそもP(θ)が積分できないのが問題なので、 P(θ)を (公式とかが既にあって)積分を計算しやすい パラメトリックな関数を使って表現してしまうという手法。 ⇨ P(θ)=g(θ;α) Θのグラフを決めるパラメータαを「超パラメータ」と呼ぶ。 そうすると、θについての周辺化は公式を使って予め計算しておけるので、
αについての最尤推定値を求めればθのグラフが1個に決まる。 尤度=P(データ|θ), 周辺尤度=Σ_θ {P(データ|g(θ;α))}=公式集で計算=P(データ|α) ⇨ これで最尤なαを求める その結果、ベイズ更新も予測分布も簡単に計算できるようになる。 ⇨ P(αで決まるθ|データ)=P(αで決まるθ)×P(データ|αで決まるθ) ⇨ P(X)=Σ_{αで決まるθ} P(X|αで決まるθ)=公式集で計算=αの関数 Θ … 3 … 7 … α=0.1 θのグラフ自体をパラメトリックにしてしまう。 という風に、 ベイズ推定の計算を予め 済ませておくことで 超パラメータは最尤推定(経験) で決めればあとは計算ラクラク になるのが「経験ベイズ」
(参考2)階層ベイズ ・経験ベイズ(前スライド)のおさらい 【課題】Θの周辺化が大変 【対策】超パラメータαで形が決まる 「公式集で積分計算が簡単(※)」なθの形をわざと選び、 尤度や事後分布や予測分布の式をθについて(公式集を使って)予め周辺化しておいて 超パラメータだけ変数としてくくりだしておく。データからはαを最尤推定する。 ここで、(そもそもの2ページ前の課題から脱線するけど、) 「 αを点推定じゃなくてベイズ推定したらもっとすごくね?」
というアイディアが出てくる。 どうすごいかというと、 「『確率変数によって決まるモデル』によって決まるモデル」という風にモデル(=θのグラフの形)自体を 確率によって作り出せるところが凄い。 (あと、2段階踏んでるにもかかわらず計算式はαのベイズ推定を1回やるだけで済むところも嬉しい。) ⇨ こういう風に、「パラメータのグラフの形を確率で決める」のを2段階(かそれ以上)に階層化して、 周辺化を(公式集で予め計算してもいいし、適宜サンプリングしてもいい)行なって推定や予測を行う という方法を 「階層ベイズ」と呼ぶ。 ※ふつう、教科書では 「公式集を使って 簡単に求める」ではなく 「解析的に求める」 という風に書かれている Θ … 3 … 7 … Θ … 3 … 7 … α α=0.1 α=0.8
(参考3)変分ベイズ ・確率分布を近似する方法は「サンプリング」だけではなく他にもある。 【動機】 そもそも積分が難しいからサンプリングするのであった。 ならば積分を計算しやすい簡単な確率分布を使って近似すれば良いではないか! 【計算方法】 パラメータ(複数のパラメータがあるとする)について周辺化する P(データ)=Σ_{パラメータ}{P(パラメータ, データ)} (*)
これだと(*)の右辺のΣは複数のパラメータの組み合わせの全パターンを総ナメしなければならない。 ここで、P(パラメータ)の近似関数をQ(パラメータ)とすると、次のAとBは同値になることが分かっている (A) Q(パラメータ)はP(データ)を最大化するような関数である (B) P(パラメータ|データ)とQ(パラメータ)のKLダイバージェンスが最小になるようなQ そこで、Q=Q1(パラメータ分割1)×Q2(パラメータ分割2)×…×Qn (パラメータ分割N)という風に 複数のパラメータに分割して掛け合わせるような近似手法(平均場近似と呼ぶ)を使うと、嬉しいことに (B)を満たすようなQ、すなわち各Q1~Qn は(*)の右辺でパラメータの組み合わせを全パターン調べなくても、 パラメータの分割ごとに部分的に総ナメすれば良くなるってことが「変分理論」によって導かれる!! 組み合わせ爆発! 総ナメは無理! そこで、 パラメータを小分けにして、 「小分けごとに総ナメ」 すれば済むようにしたい。 (余談)ちなみに EMアルゴリズムの 一般形もこれと同じ ノリで導出できる
(参考4)ノンパラベイズ そもそもθとかαとかパラメータを使ってグラフの「形」を決めるのって自由度低くね? 超パラメータを使ってあらかじめ確率分布の形を想定しておくことさえせず、 確率分布を直接作ってくれるような方法はないか? 例) 女心={好きa%, なんともb%, 嫌いc%} (a+b+c =
100%) {好きa%, ちょっと好きb%, なんともc%, 嫌いc%, 大嫌いd%} (a+b+c+d = 100%) {超好きa%, 大好きb%, 好きc%, ちょっと好きd%, なんともe%, 嫌いf%, 大嫌いg%, キモいh% } (a+b+c+d+e+f+g+h = 100%) 以下、無限にパターンを秘めている この例だと、もともとが「好き⇔嫌い」という1次元の数直線で表せるけど、「友達としてどうこう」とか質的に異 なるパラメータがいっぱい考えられるようなケースを全部「想定内」におさめたいというニーズは当然ある。 そんなのできるのか? ⇨ できるんです、そう、ノンパラベイズならね。 この例は「ディリクレ過程」というのを使うとできる。実際に使うと、データ(態度)に応じてa,b,c,d,e,…というパラ メータ(女心)の各確率が計算できるようになる。 (変数がいくつ出てくるか分からないのに足したら100%になるようにパラメータを計算できる。スゲー。)
おわりに ・点推定にも色々な手法があります。 ・特に、データが一部失われてたり、観測出来なかったりしても尤度を計算できるEMアルゴリズム ・ベイズ推定は機械学習の分野でよく使われてます。 ・回帰への応用、とくにパラメトリックなモデルを使いながら使い勝手はノンパラメトリックな「ガウス過程」 ・同時分布の構造を表現する「ベイジアンネットワーク」 ・時系列データに特化した逐次的なベイズ推定である「粒子フィルタ」 などなど ・機械学習はベイズ推定以外にも色んな手法があって面白いです。 ・カーネル法や「サポートベクタマシン」
・線形変換の固有値をを使う手法: 「主成分分析」や「独立成分分析」など ・「決定木」や「強化学習」、「バギング」や「ブースティング」 などなど ・「趣味で機械学習」楽しいのでオススメ!(これからデータマイニングは重要なので実利もあります) アドファイブの製品は機械学習の技術をふんだんに取り入れていきます! (デマンドサイドの入札エンジン、オーディエンスデータ拡張、クリエイティブ最適化、パーソナライズドバナーなどなど) ⇨ 続きは3月の「UUY機械学習セミナー presented by アドファイブ(株)」でやりますので、お楽しみに!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}