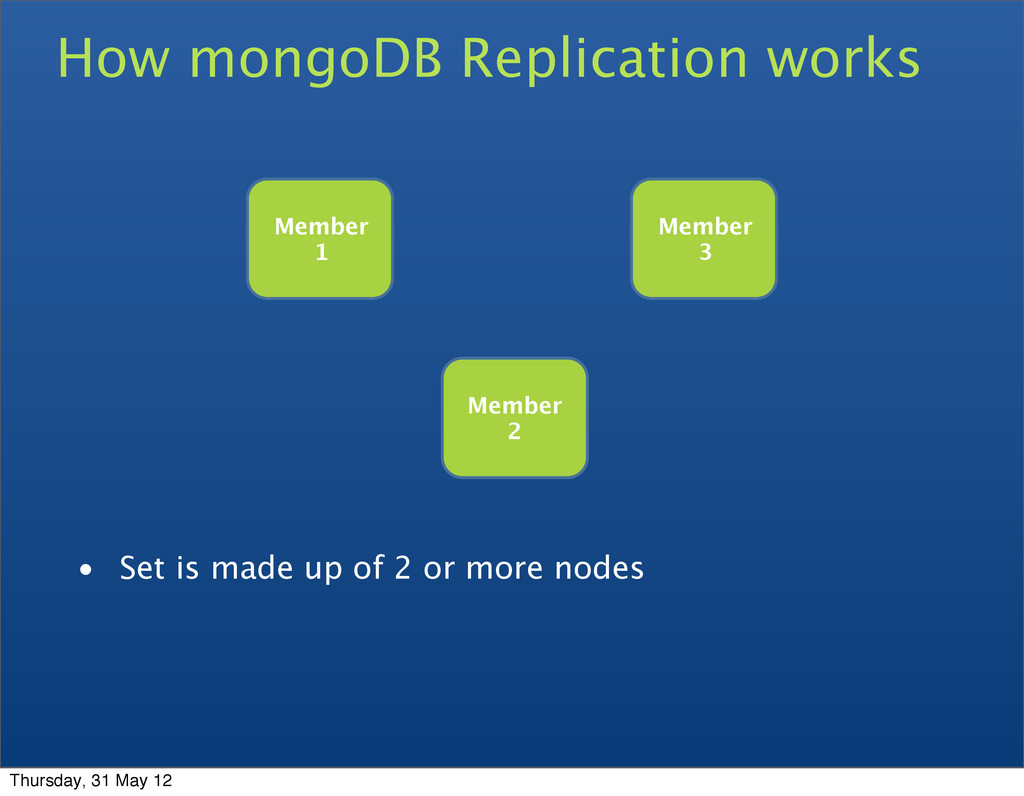
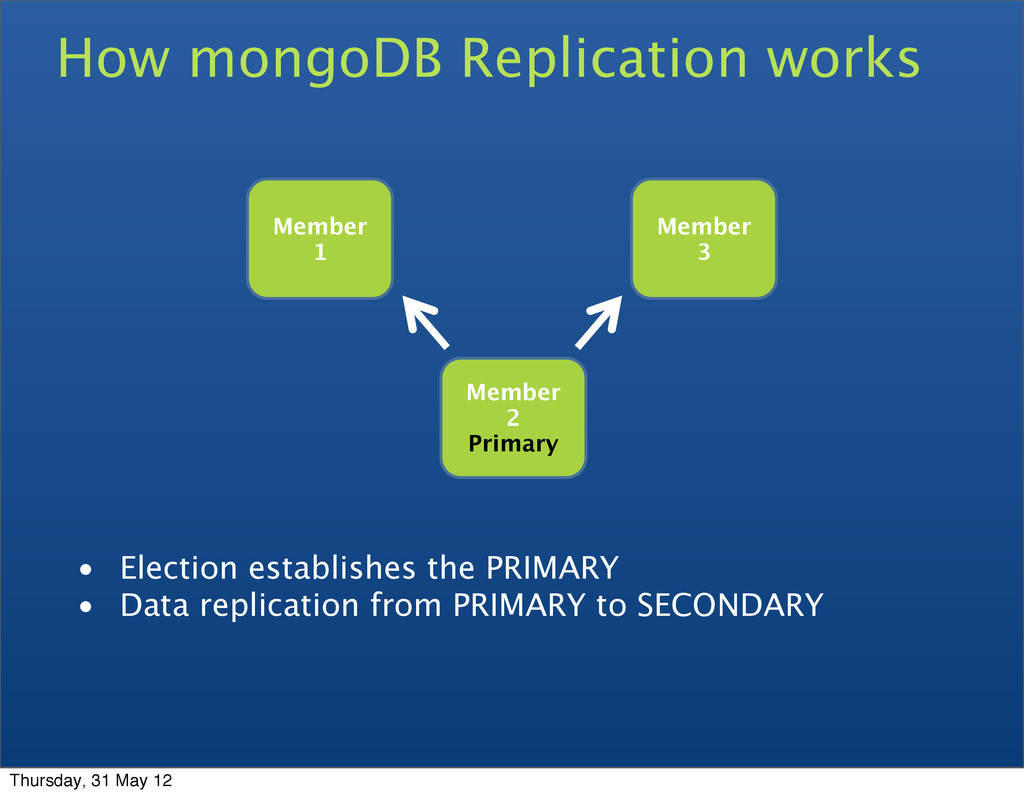
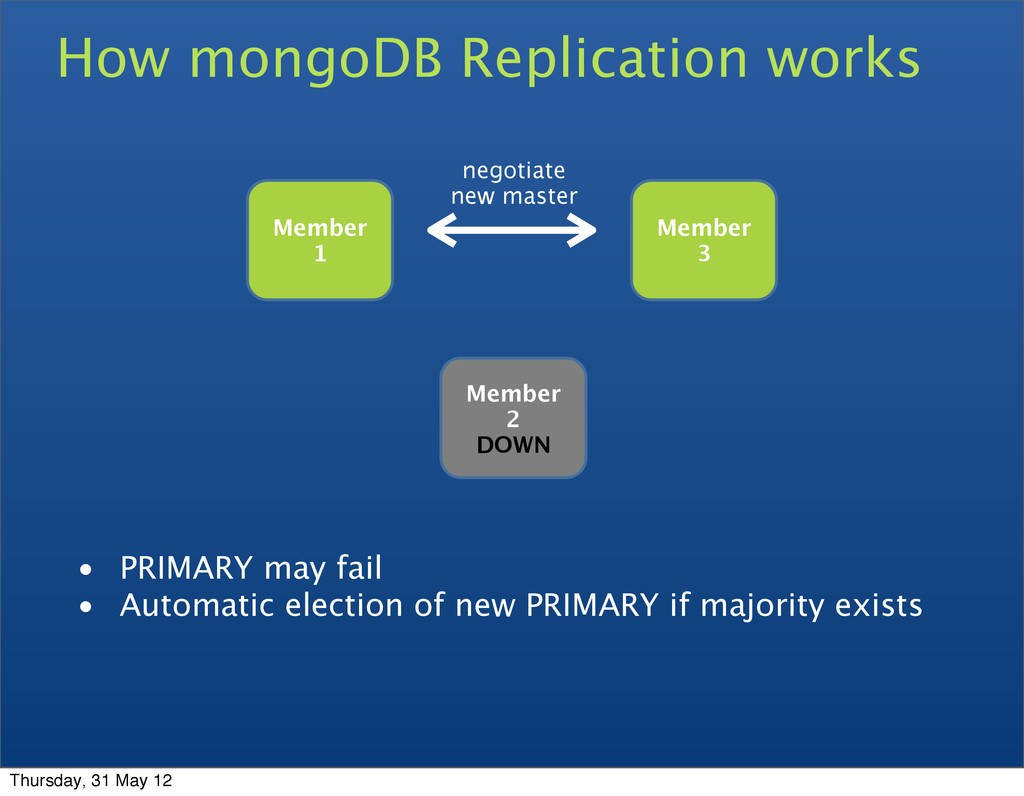
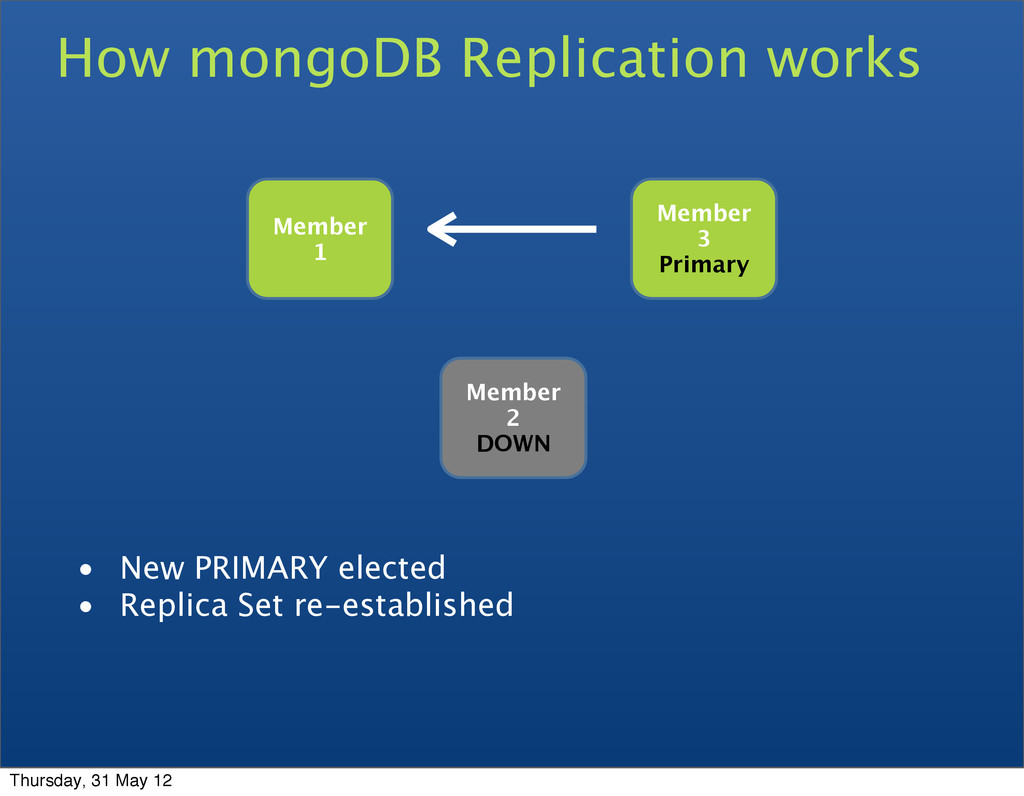
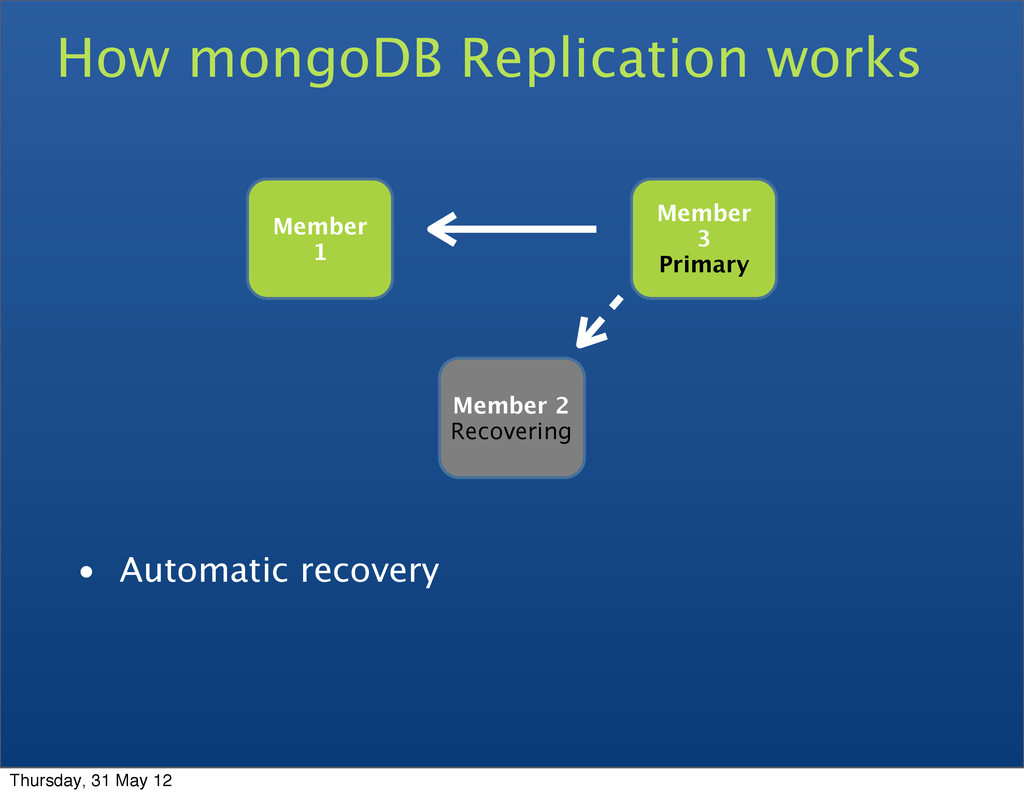
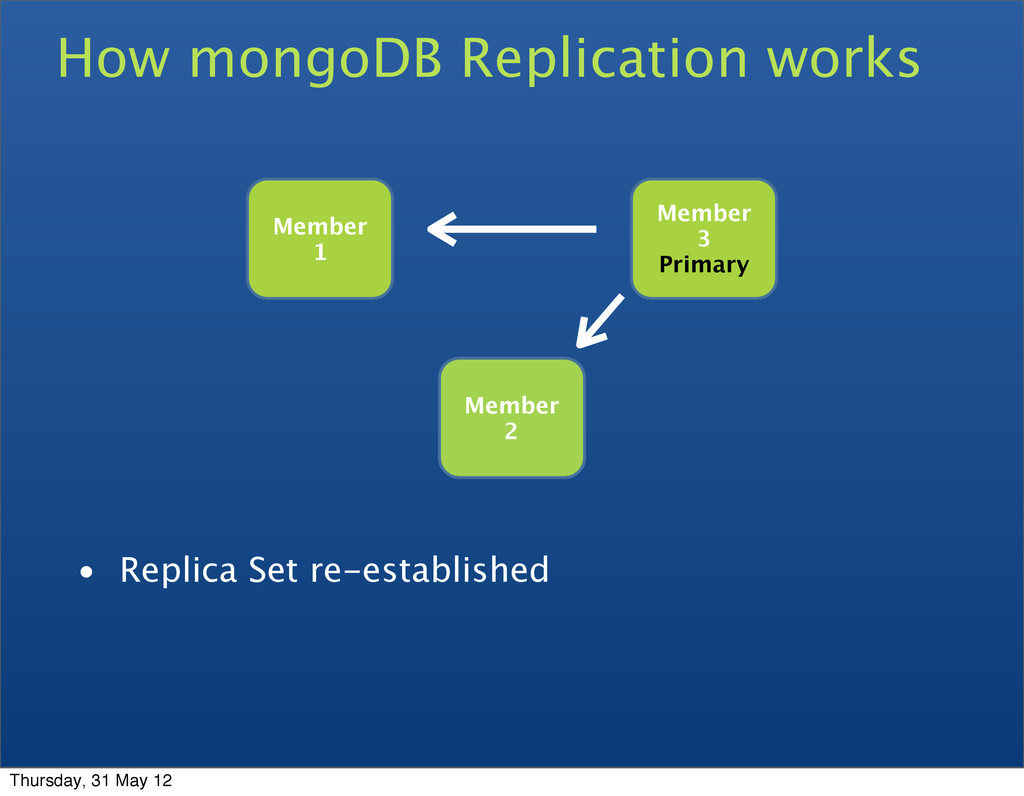
• Replica sets • A cluster of N servers • All writes to primary • Reads can be to primary (default) or a secondary • Any (one) node can be primary • Consensus election of primary • Automatic failover • Automatic recovery Thursday, 31 May 12
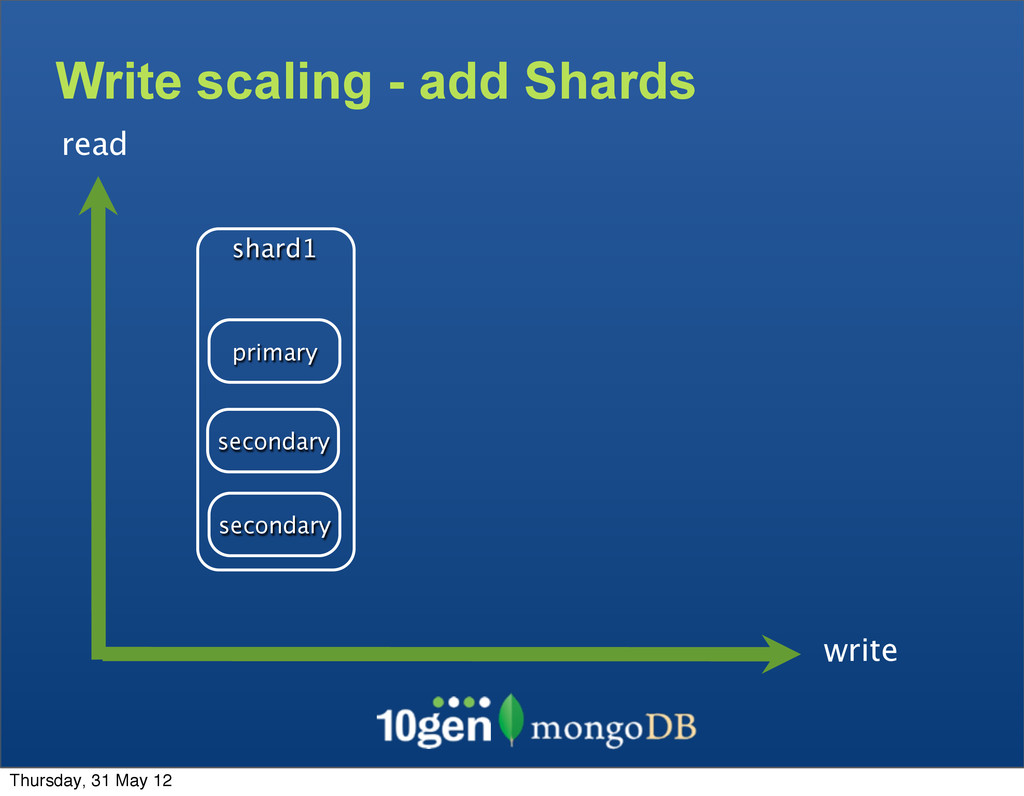
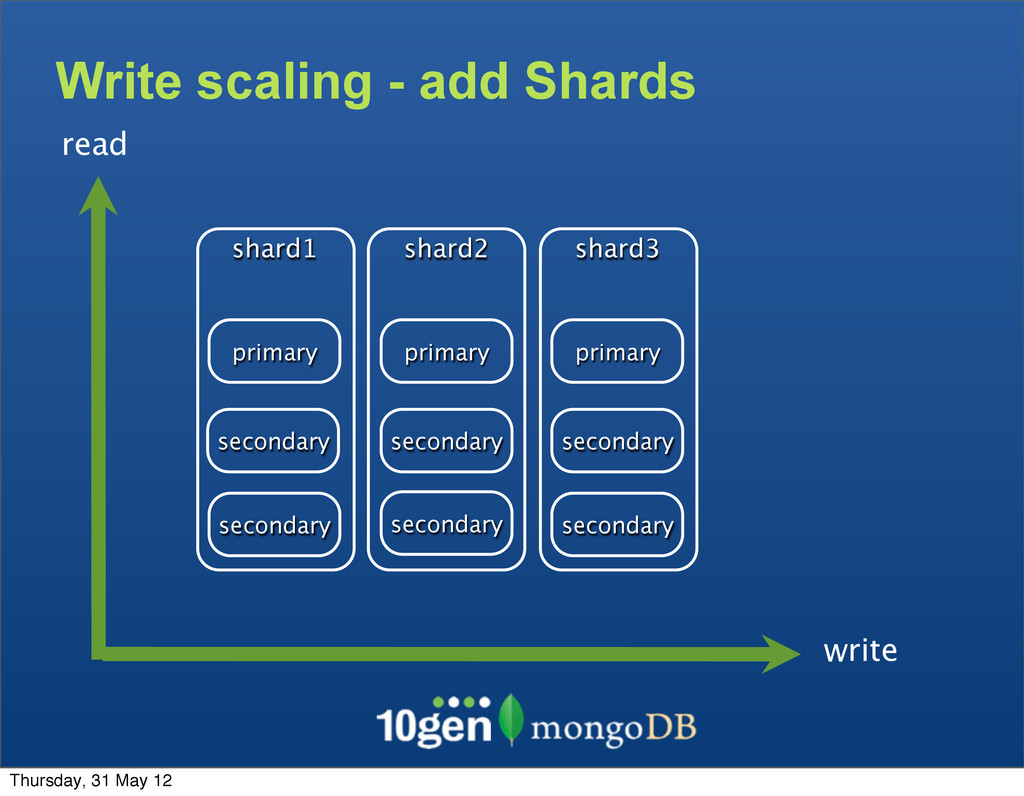
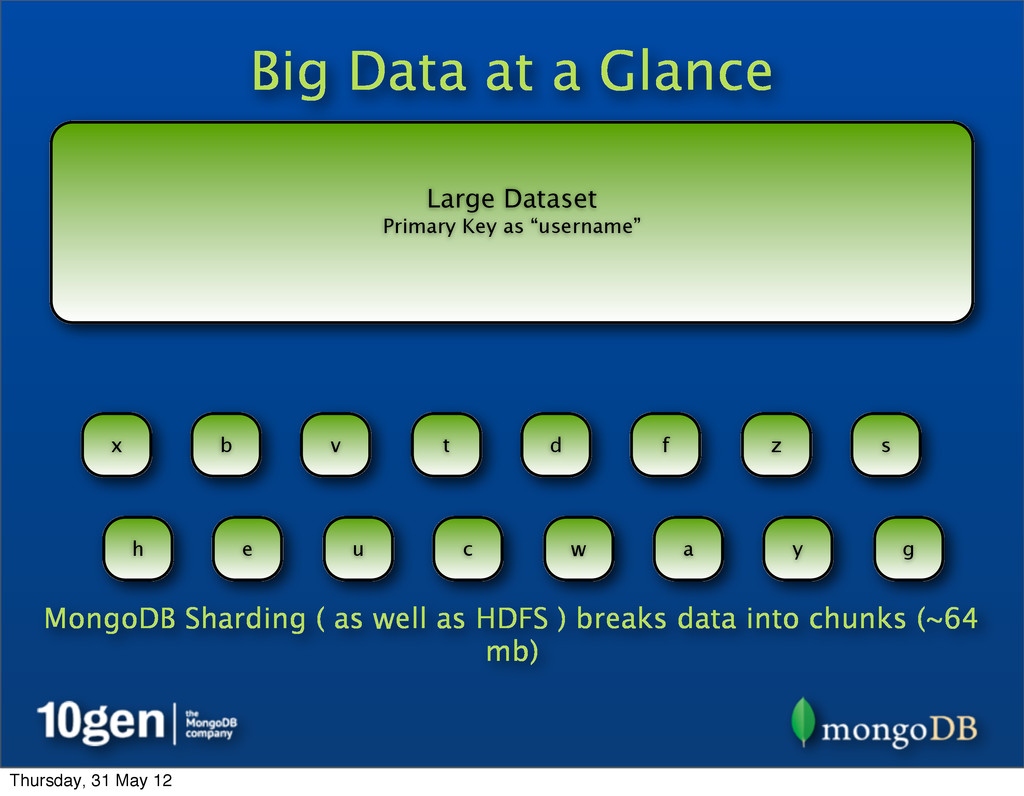
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Thursday, 31 May 12
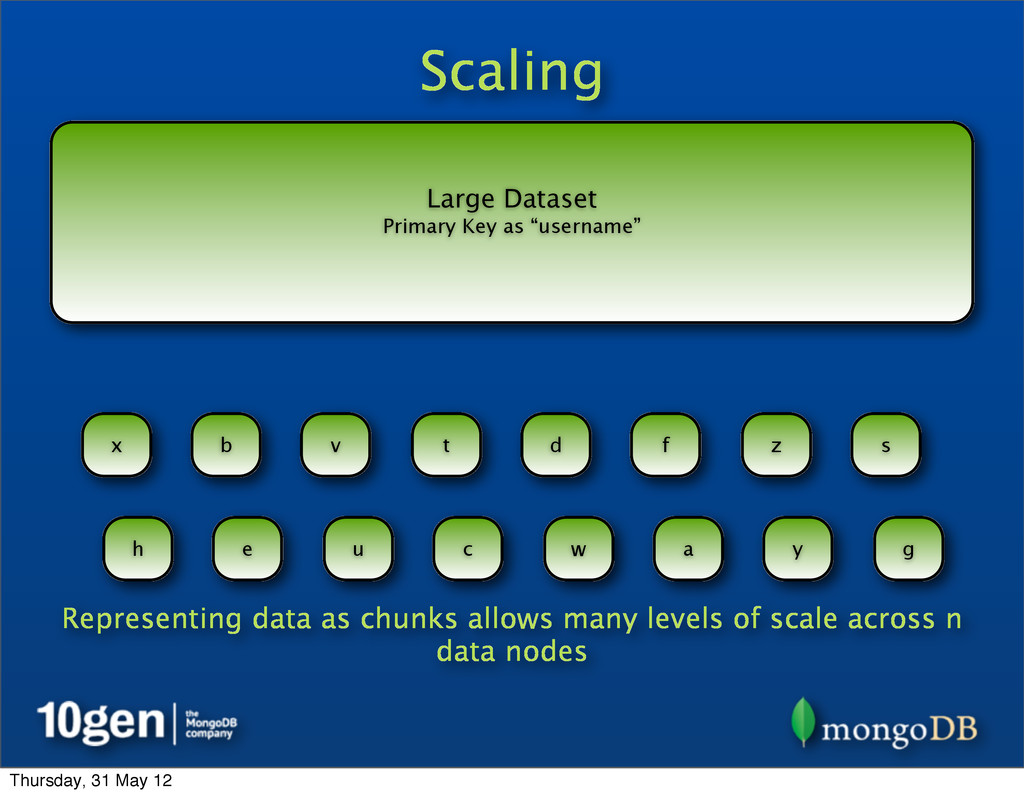
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking • Break up pieces of data into smaller chunks, spread across many data nodes Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Thursday, 31 May 12
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking • Break up pieces of data into smaller chunks, spread across many data nodes • Each data node contains many chunks Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Thursday, 31 May 12
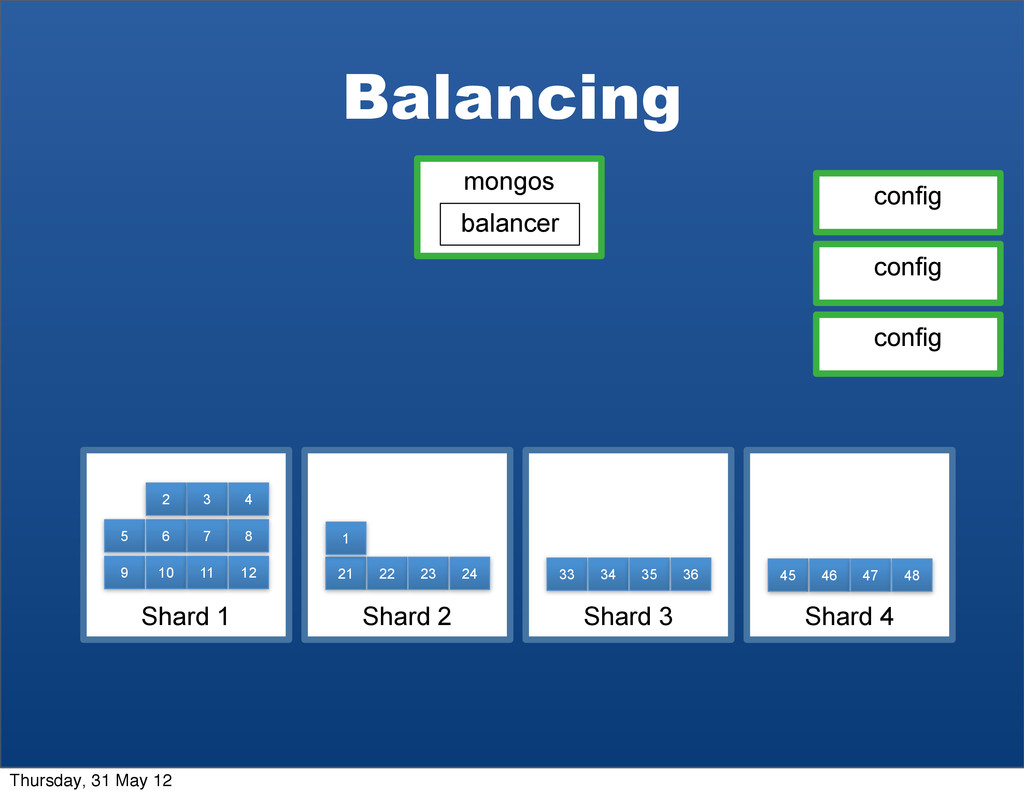
System (which inspired Hadoop’s HDFS) and MongoDB’s Sharding handle the scale problem by chunking • Break up pieces of data into smaller chunks, spread across many data nodes • Each data node contains many chunks • If a chunk gets too large or a node overloaded, data can be rebalanced Large Dataset Primary Key as “username” a b c d e f g h s t u v w x y z ... Thursday, 31 May 12
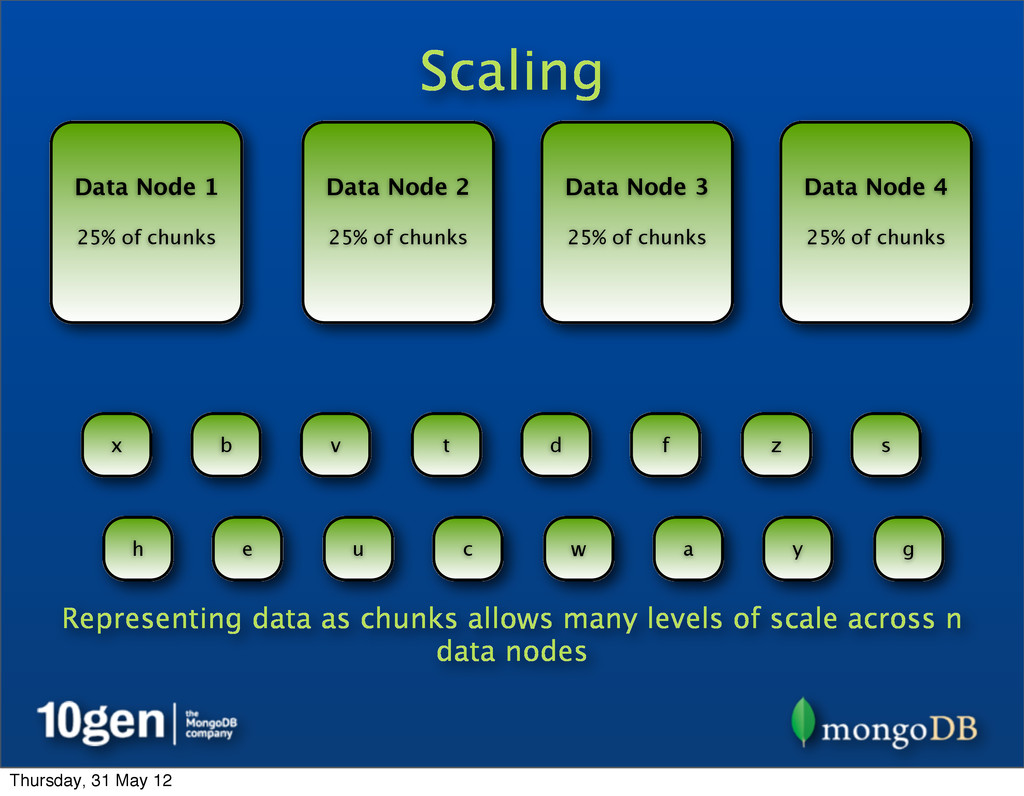
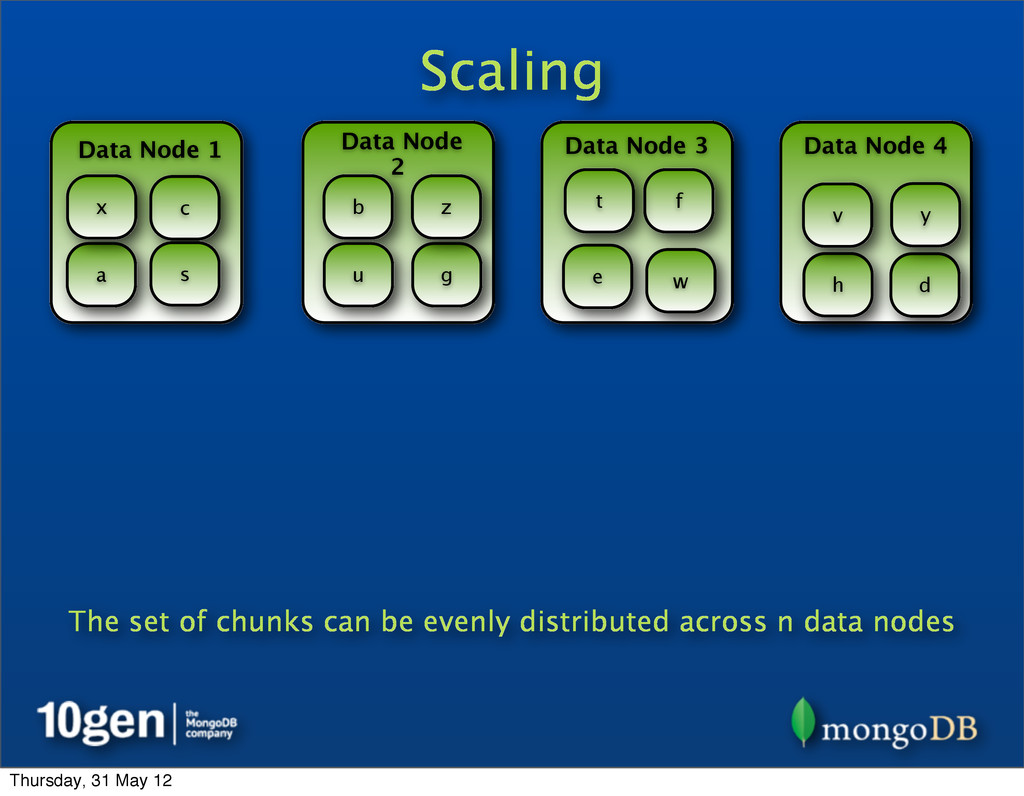
25% of chunks Data Node 2 25% of chunks Data Node 3 25% of chunks Data Node 4 25% of chunks a b c d e f g h s t u v w x y z Representing data as chunks allows many levels of scale across n data nodes Thursday, 31 May 12
25% of chunks Data Node 2 25% of chunks Data Node 3 25% of chunks Data Node 4 25% of chunks a b c d e f g h s t u v w x y z Representing data as chunks allows many levels of scale across n data nodes Thursday, 31 May 12
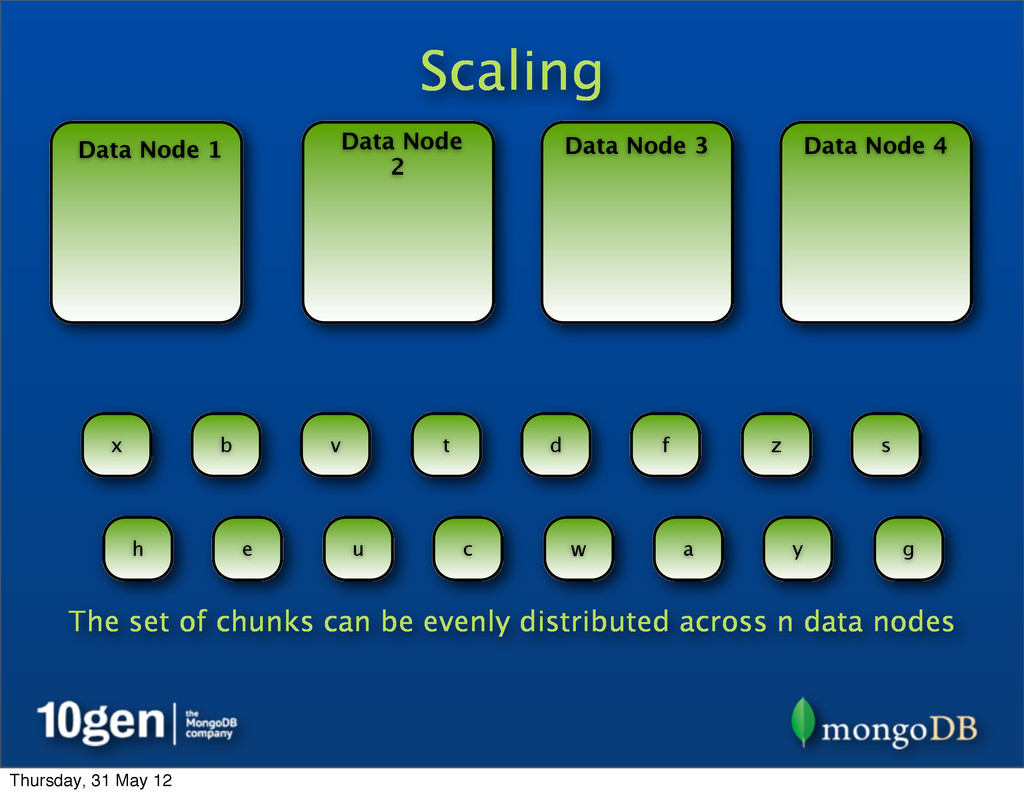
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z The goal is equilibrium - an equal distribution. As nodes are added (or even removed) chunks can be redistributed for balance. Thursday, 31 May 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z The goal is equilibrium - an equal distribution. As nodes are added (or even removed) chunks can be redistributed for balance. Thursday, 31 May 12
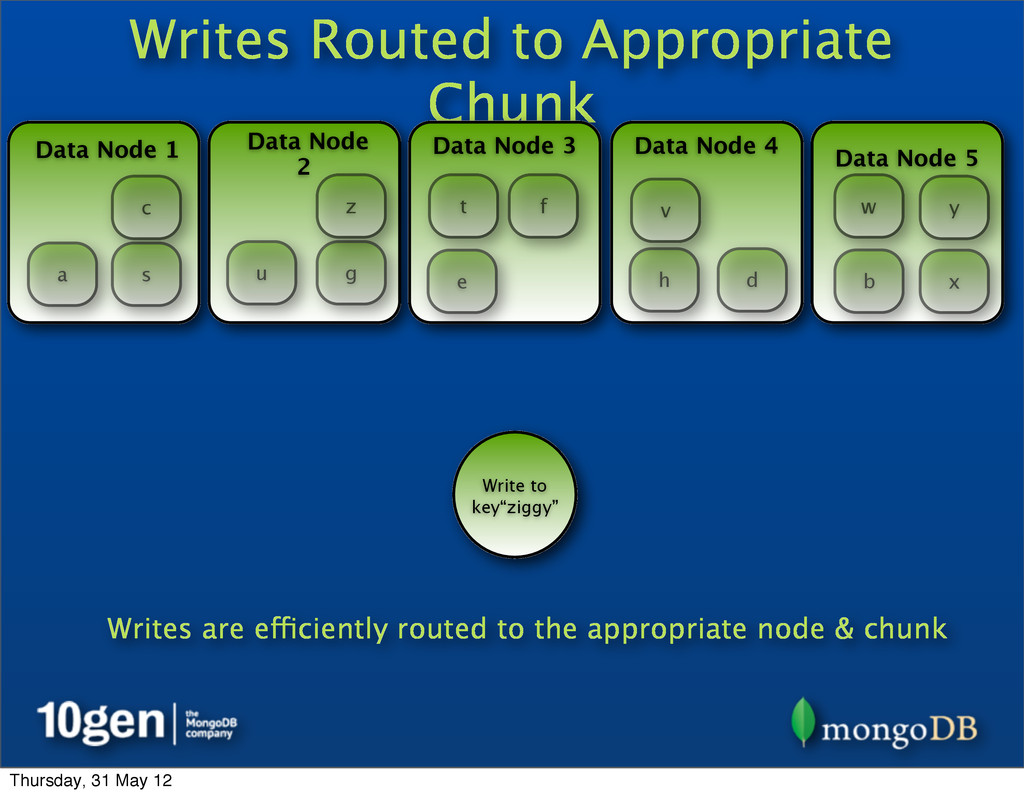
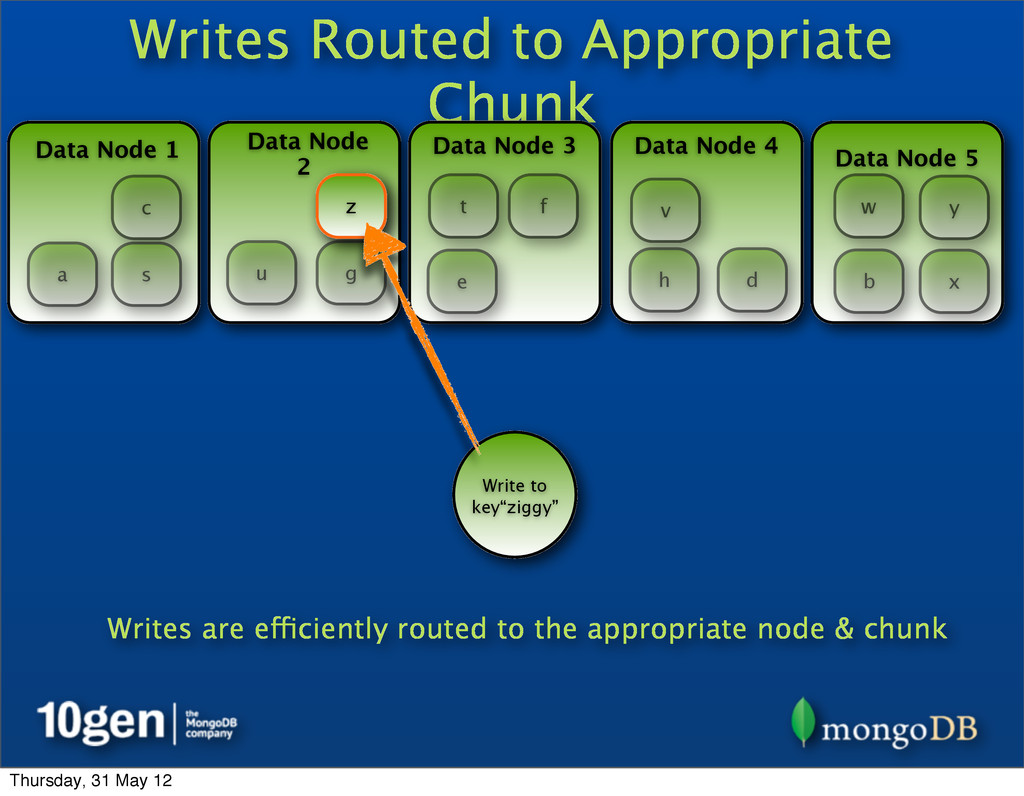
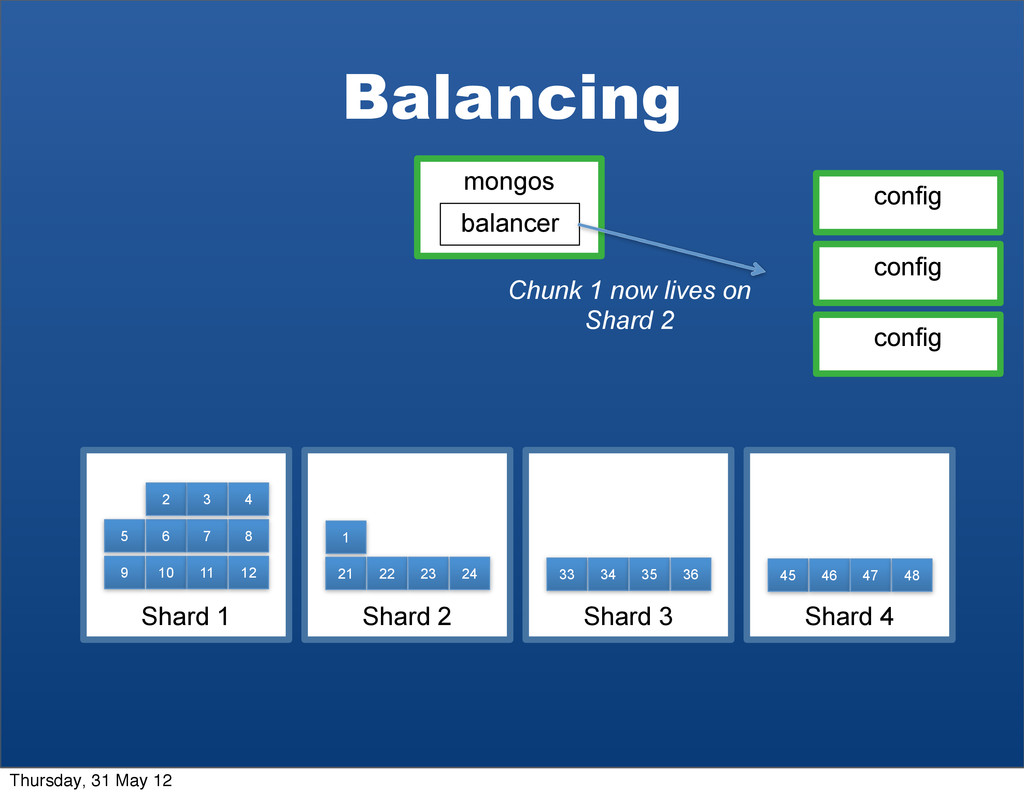
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z Write to key“ziggy” z Writes are efficiently routed to the appropriate node & chunk Thursday, 31 May 12
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z Write to key“ziggy” z Writes are efficiently routed to the appropriate node & chunk Thursday, 31 May 12
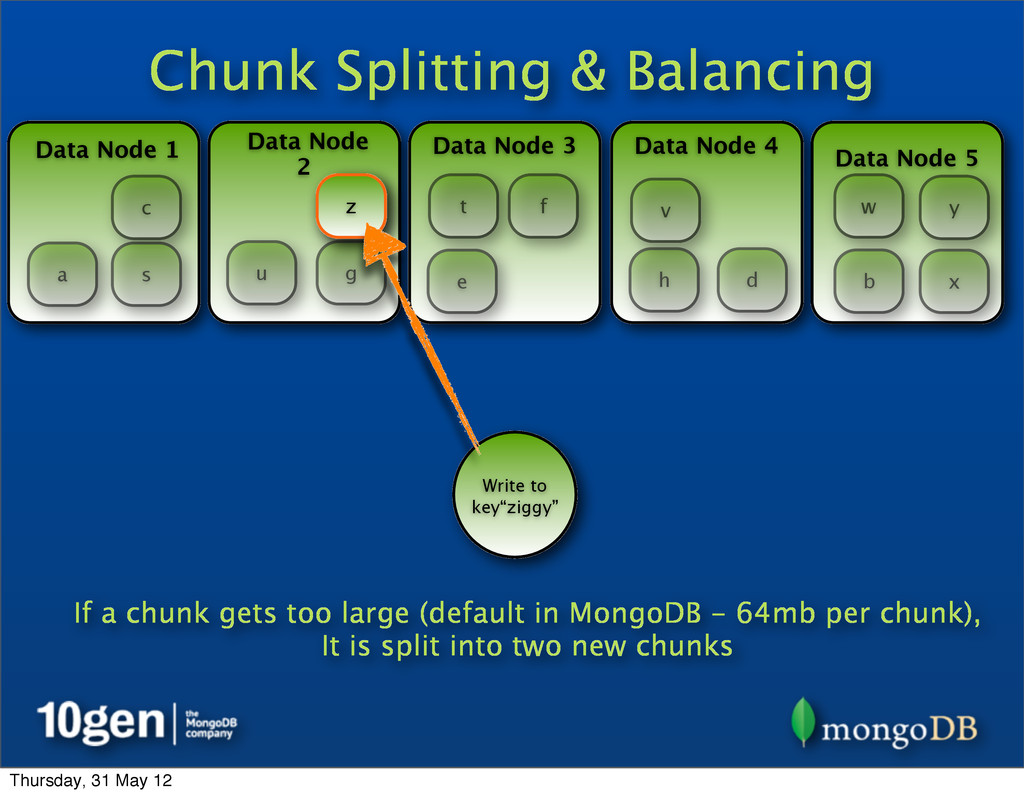
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z Write to key“ziggy” z If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks Thursday, 31 May 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks Thursday, 31 May 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks Thursday, 31 May 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks z1 Thursday, 31 May 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 If a chunk gets too large (default in MongoDB - 64mb per chunk), It is split into two new chunks z1 Thursday, 31 May 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 z1 Each new part of the Z chunk (left & right) now contains half of the keys Thursday, 31 May 12
Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z z2 z1 As chunks continue to grow and split, they can be rebalanced to keep an equal share of data on each server. Thursday, 31 May 12
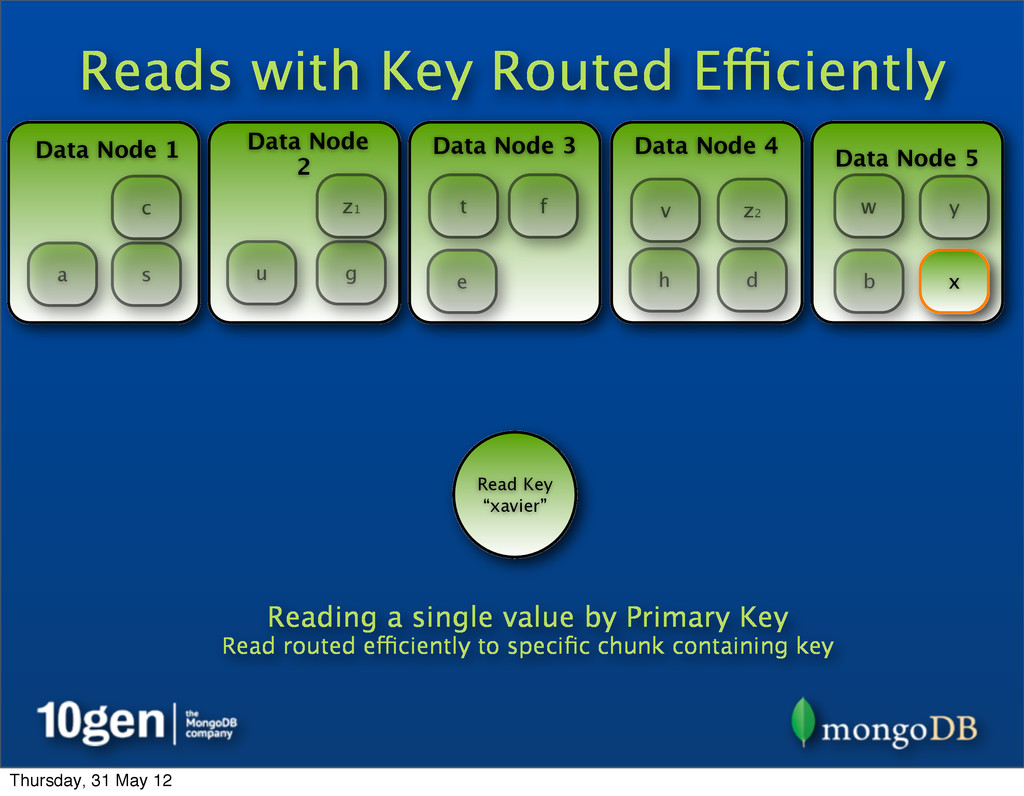
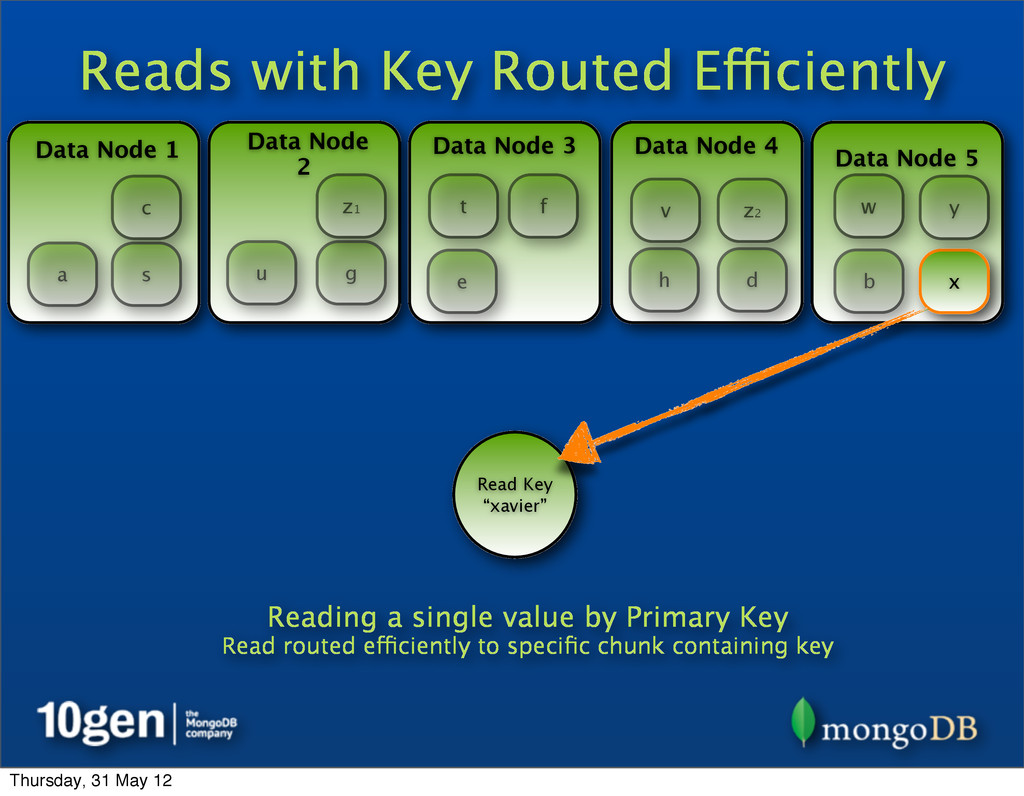
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y z1 Read Key “xavier” Reading a single value by Primary Key Read routed efficiently to specific chunk containing key z2 Thursday, 31 May 12
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Key “xavier” Reading a single value by Primary Key Read routed efficiently to specific chunk containing key z1 z2 Thursday, 31 May 12
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Key “xavier” Reading a single value by Primary Key Read routed efficiently to specific chunk containing key z1 z2 Thursday, 31 May 12
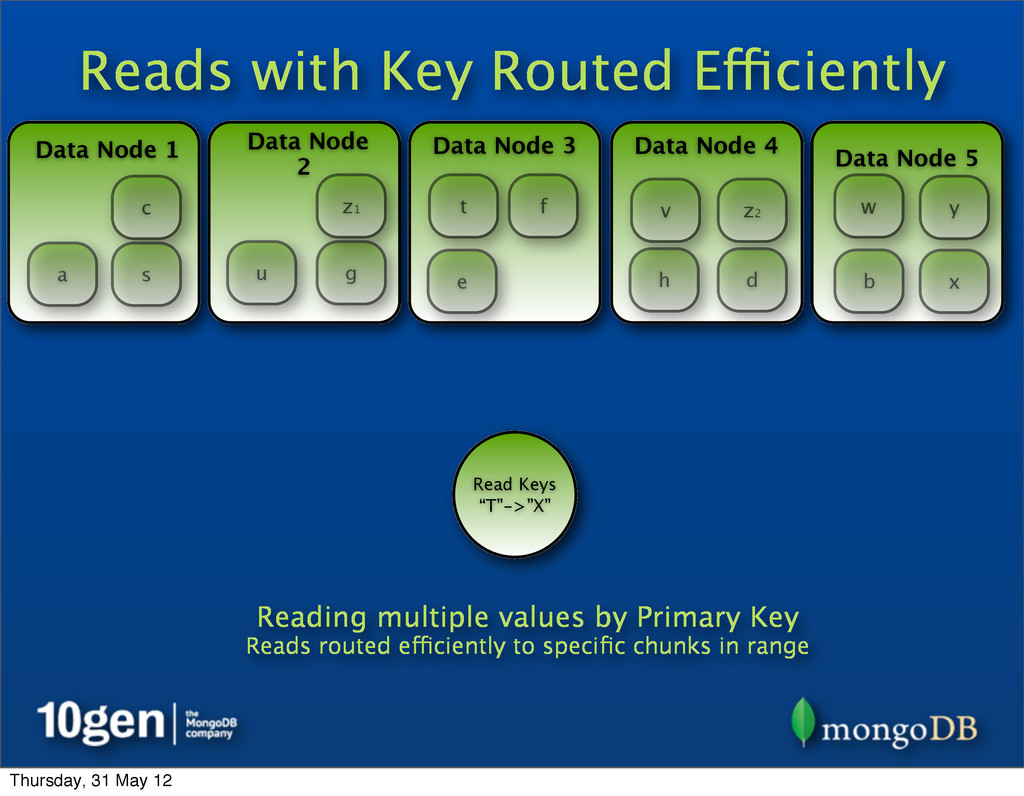
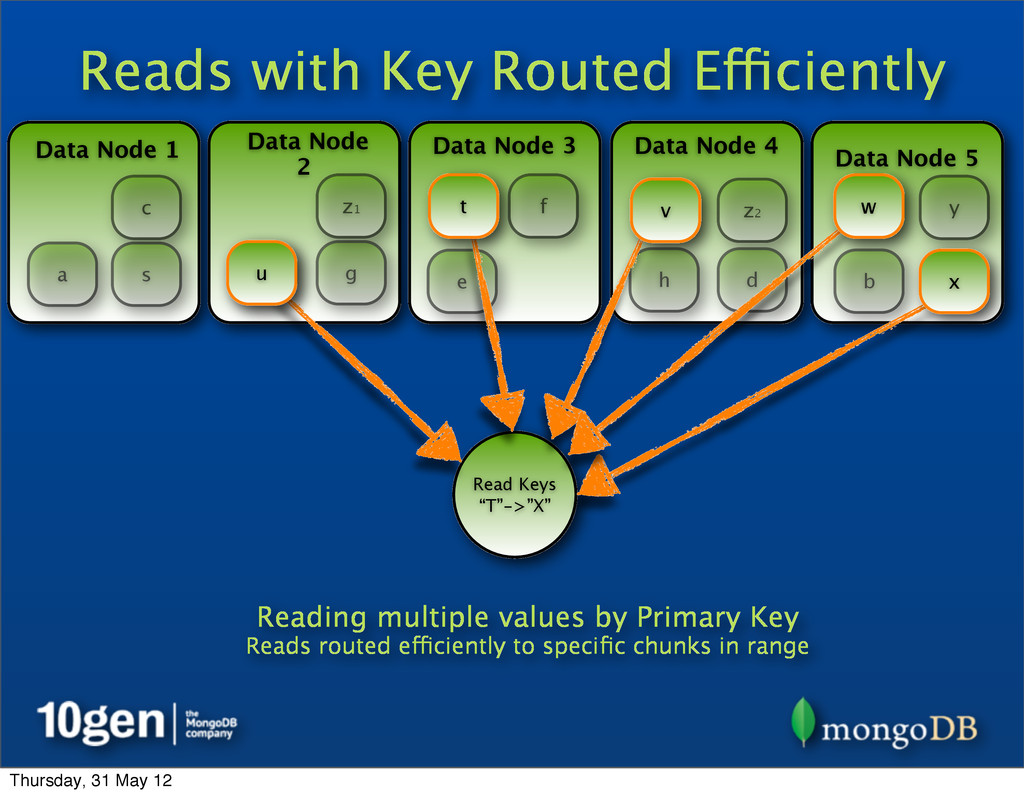
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Keys “T”->”X” Reading multiple values by Primary Key Reads routed efficiently to specific chunks in range t u v w x z1 z2 Thursday, 31 May 12
2 Data Node 3 Data Node 4 Data Node 5 a b c d e f g h s t u v w x y Read Keys “T”->”X” Reading multiple values by Primary Key Reads routed efficiently to specific chunks in range t u v w x z1 z2 Thursday, 31 May 12
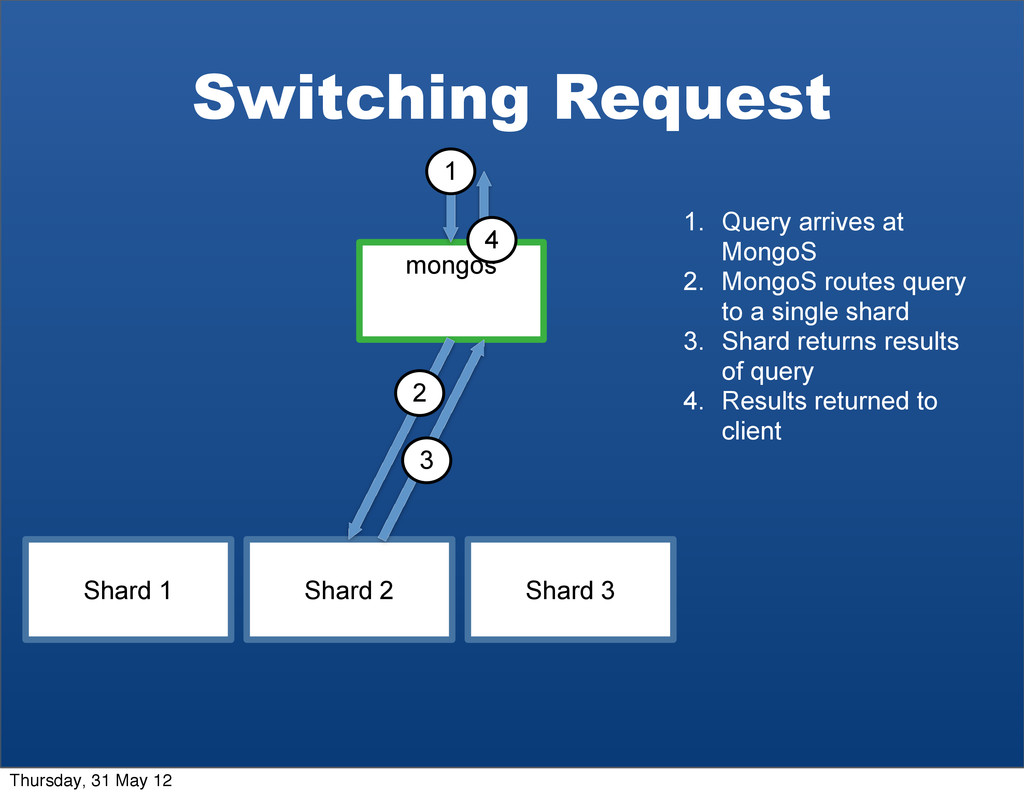
2 3 4 1. Query arrives at MongoS 2. MongoS routes query to a single shard 3. Shard returns results of query 4. Results returned to client Thursday, 31 May 12
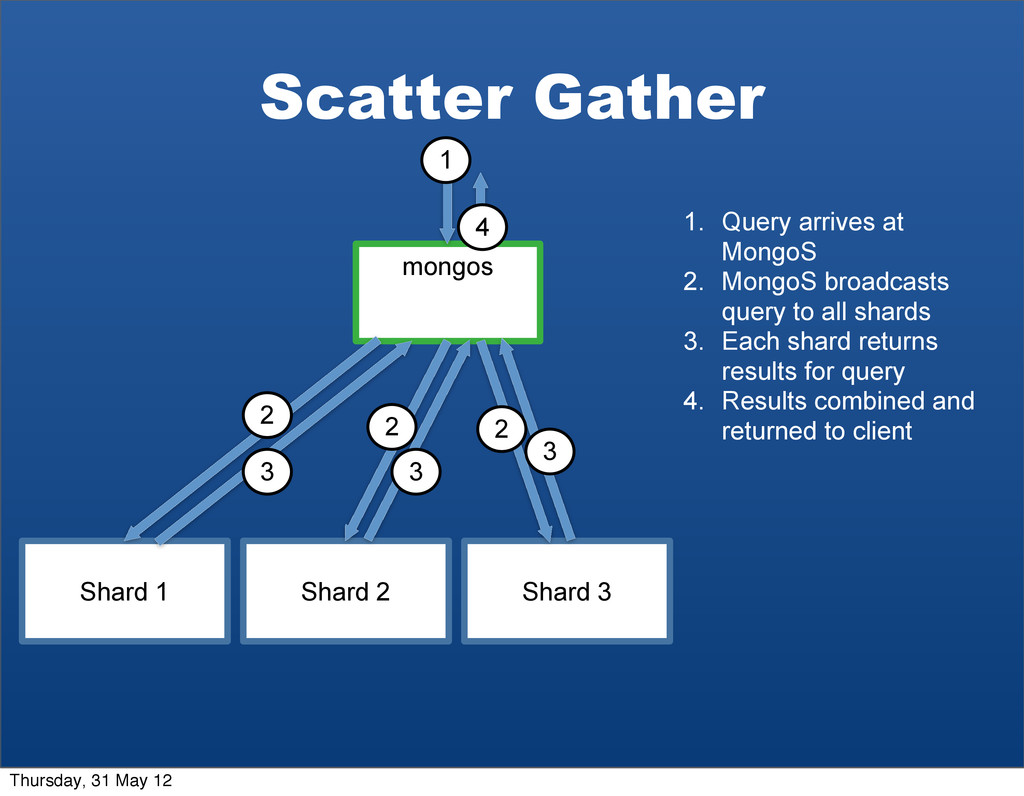
4 1. Query arrives at MongoS 2. MongoS broadcasts query to all shards 3. Each shard returns results for query 4. Results combined and returned to client 2 2 3 3 2 3 Thursday, 31 May 12
shard key Routed in order db.users.find().sort({email:-1}) Find by non shard key Scatter Gather db.users.find({state:”CA”}) Sorted by non shard key Distributed merge sort db.users.find().sort({state:1}) Thursday, 31 May 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
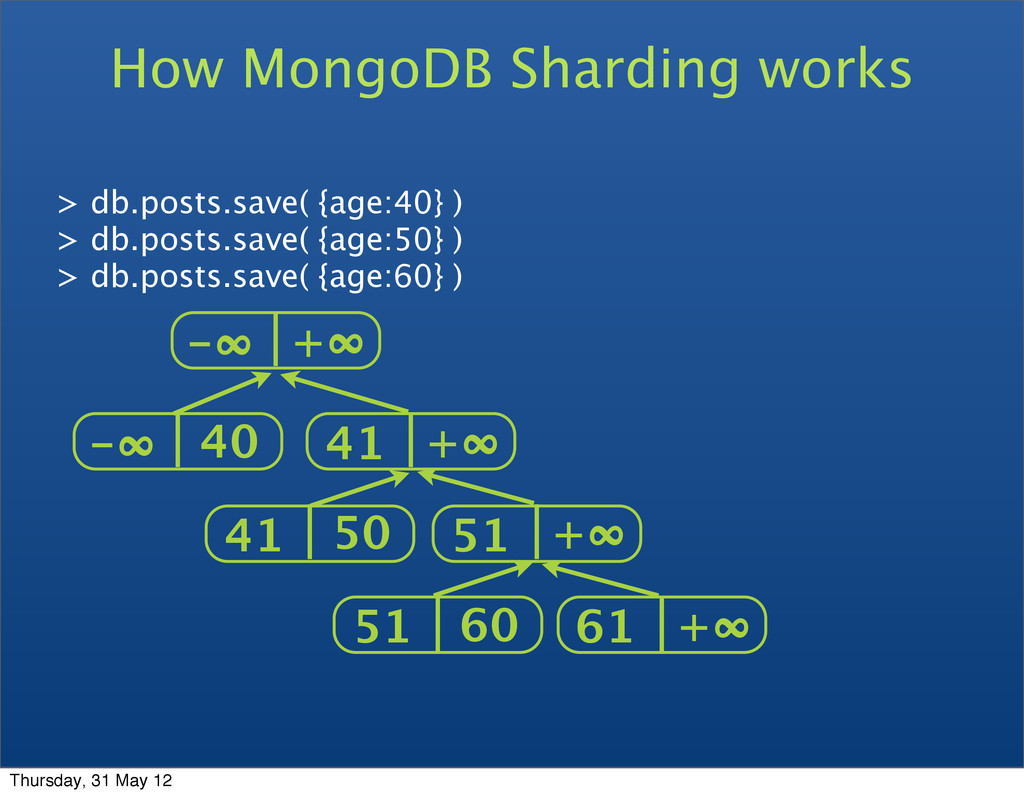{kind=link}
{kind=link}
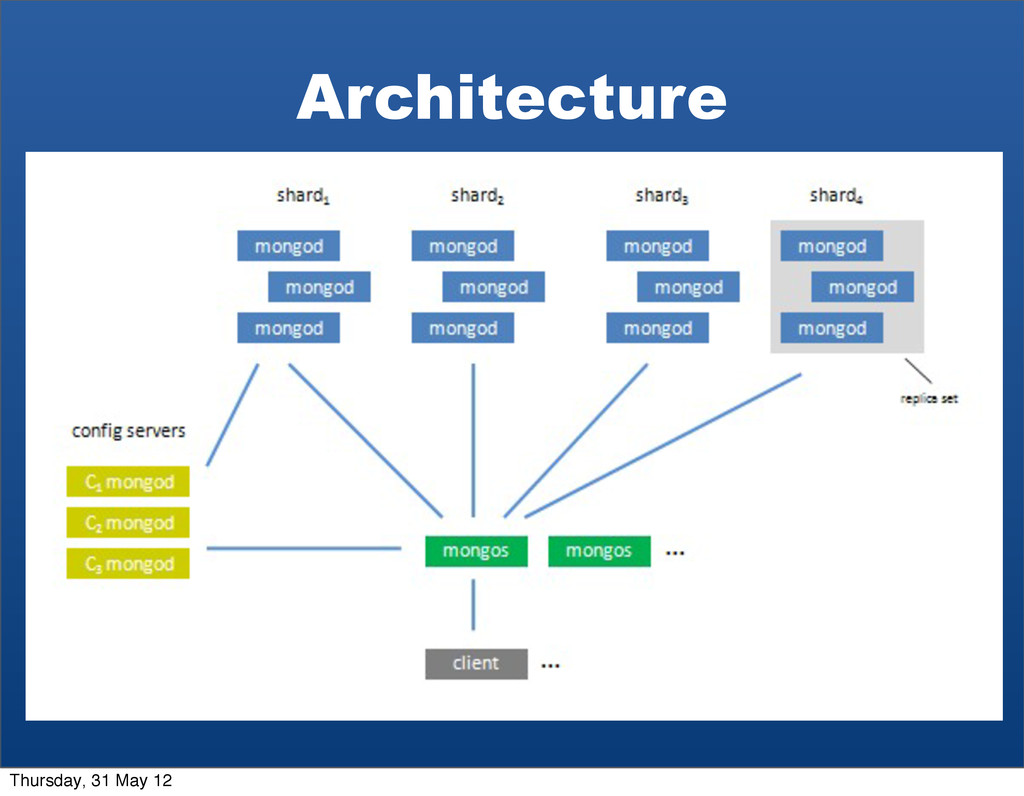{kind=link}
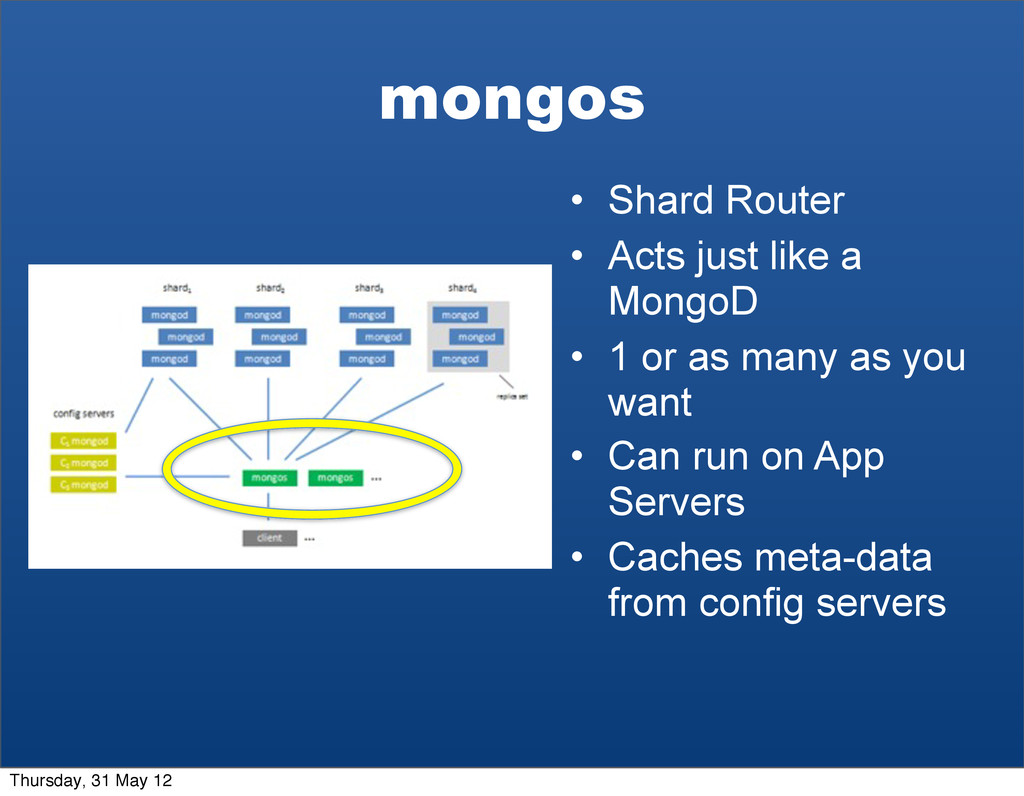{kind=link}
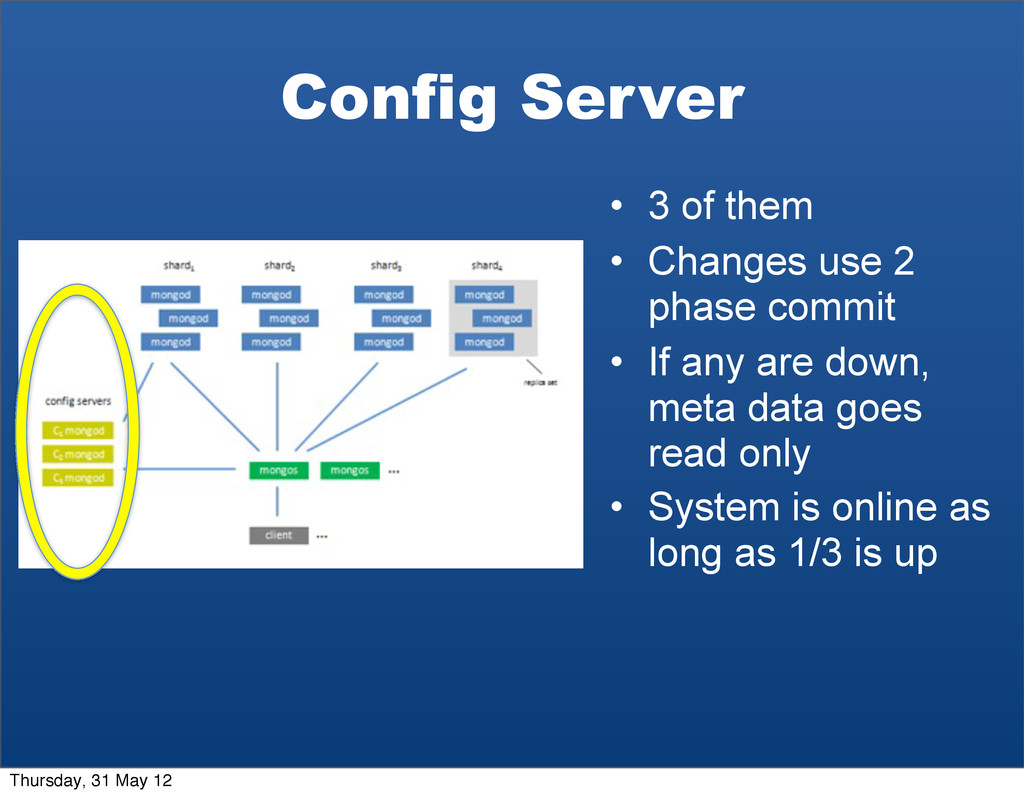{kind=link}
{kind=link}
![Keys { name: “Jared”, email: “[email protected]”, } { name: “Scott”,](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_51.jpg){kind=link}
{kind=link}
![Chunks -∞ +∞ [email protected] [email protected] [email protected] Thursday, 31 May 12](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_53.jpg){kind=link}
![Chunks -∞ +∞ [email protected] [email protected] [email protected] Split! Thursday, 31 May](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_54.jpg){kind=link}
![Chunks -∞ +∞ [email protected] [email protected] [email protected] Split! This is a](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_55.jpg){kind=link}
![Chunks -∞ +∞ [email protected] [email protected] [email protected] Thursday, 31 May 12](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_56.jpg){kind=link}
![Chunks -∞ +∞ [email protected] [email protected] [email protected] Thursday, 31 May 12](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_57.jpg){kind=link}
![Chunks -∞ +∞ [email protected] [email protected] [email protected] Split! Thursday, 31 May](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_58.jpg){kind=link}
![Chunks Min Key Max Key Shard -∞ [email protected] 1 [email protected]](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_59.jpg){kind=link}
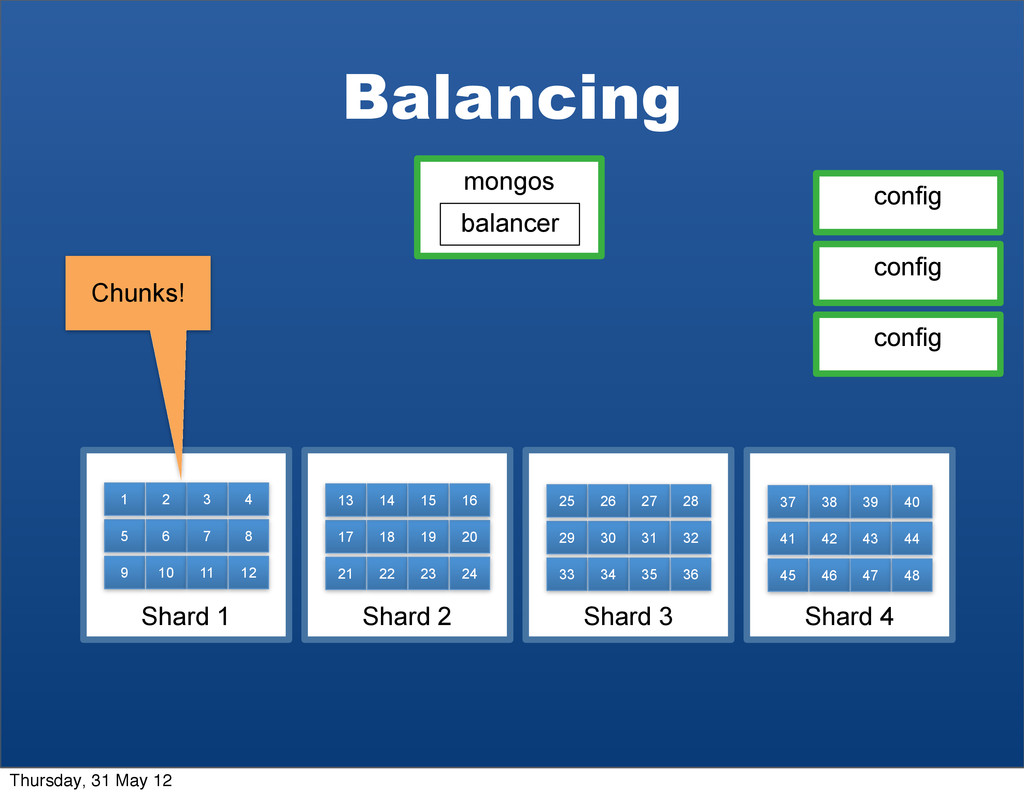{kind=link}
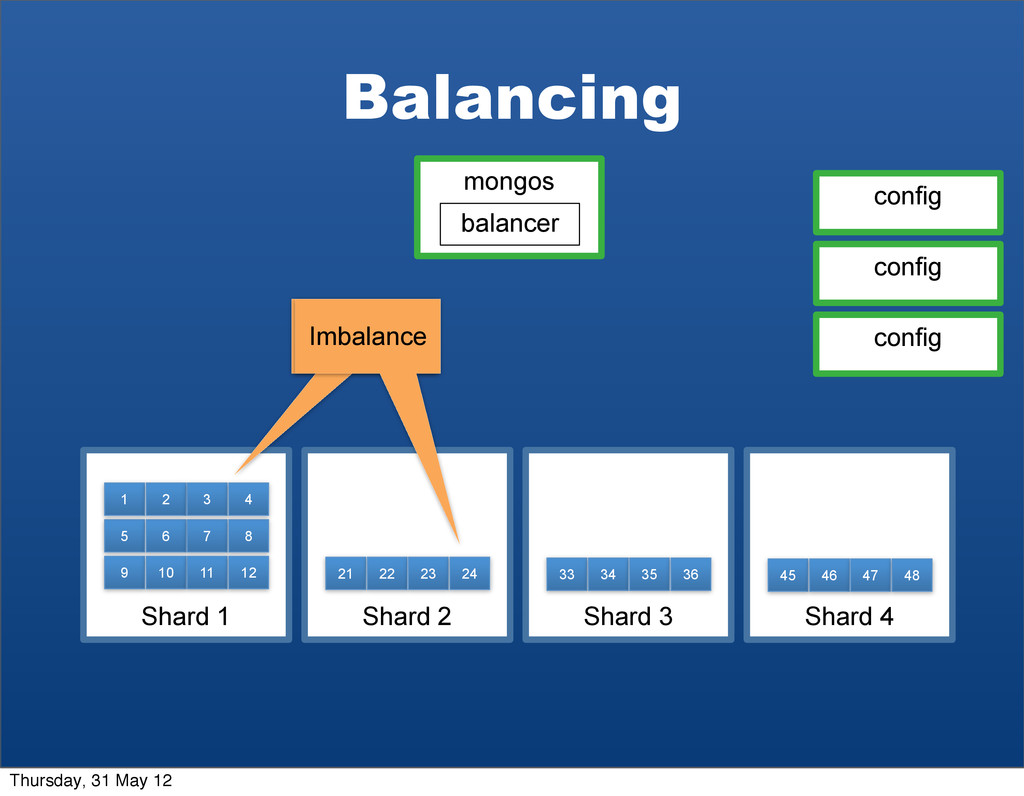{kind=link}
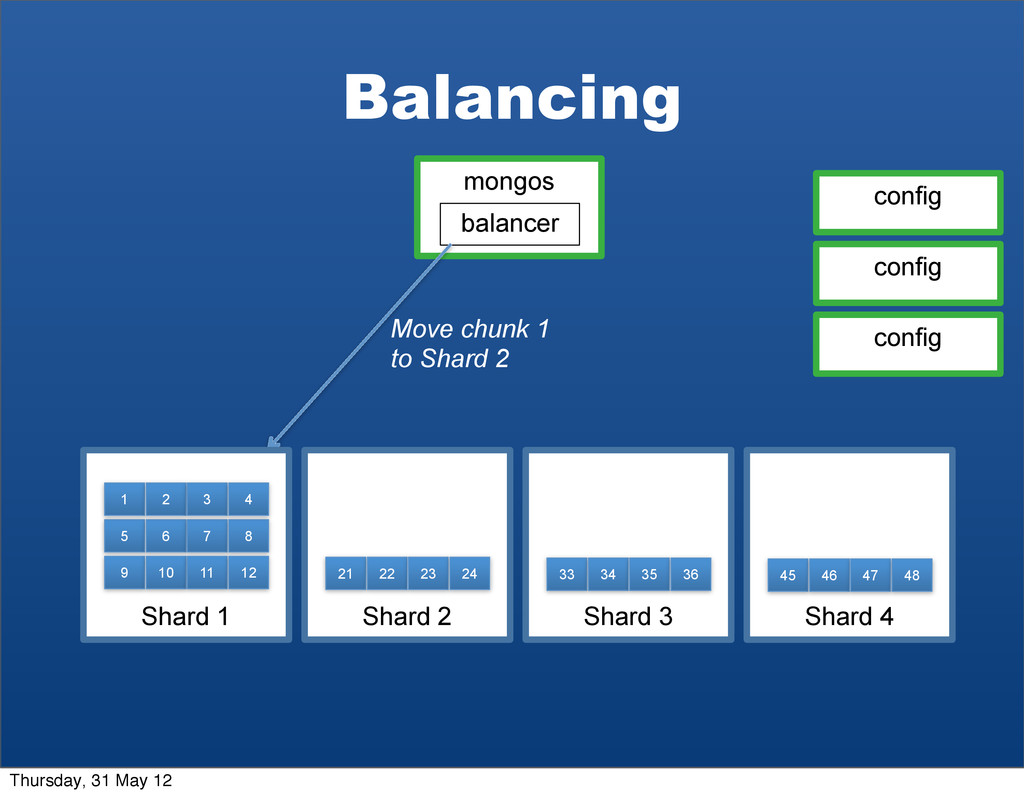{kind=link}
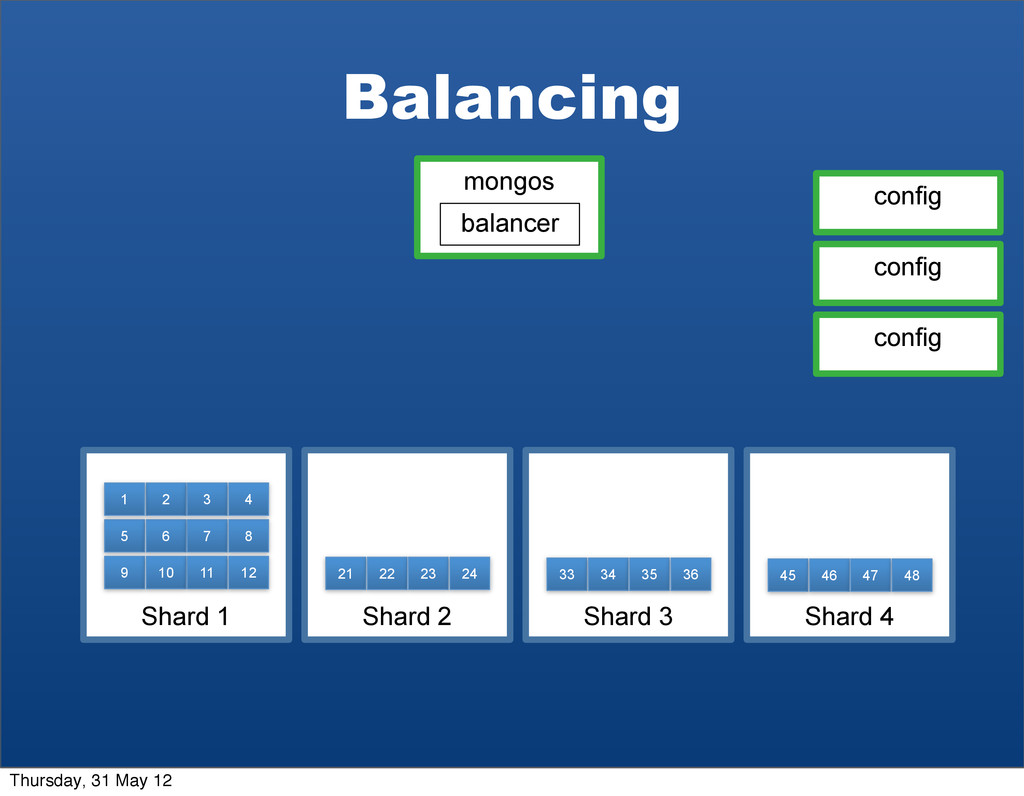{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Writes Inserts Requires shard key db.users.insert({ name: “Jared”, email: “[email protected]”})](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_69.jpg){kind=link}
![Queries By Shard Key Routed db.users.find( {email: “[email protected]”}) Sorted by](https://files.speakerdeck.com/presentations/4fc75102ed0e1d0125003bac/slide_70.jpg){kind=link}
{kind=link}