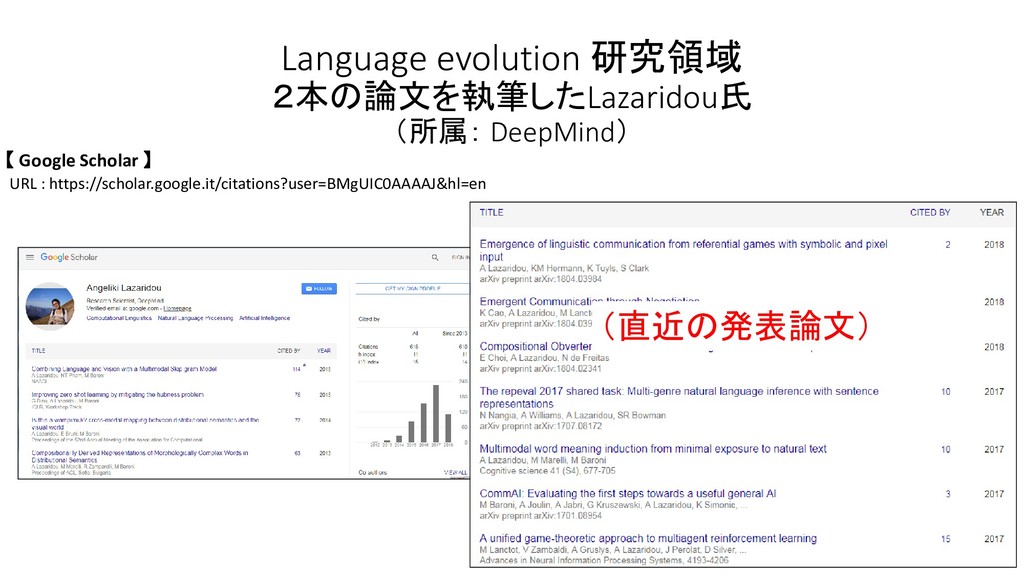
Nando de Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning. In NIPS, pp. 2137–2145, 2016. ・ Angeliki Lazaridou, Alexander Peysakhovich, and Marco Baroni. Multi-agent cooperation and the emergence of (natural) language. In ICLR, 2017.
al. Learning multiagent communication with backpropagation. In NIPS, pp. 2244–2252, 2016. ・ Emilio Jorge, Mikael Kageback, and Emil Gustavsson. Learning to play guess who? and inventing a grounded language as a consequence. arXiv preprint arXiv:1611.03218, 2016.
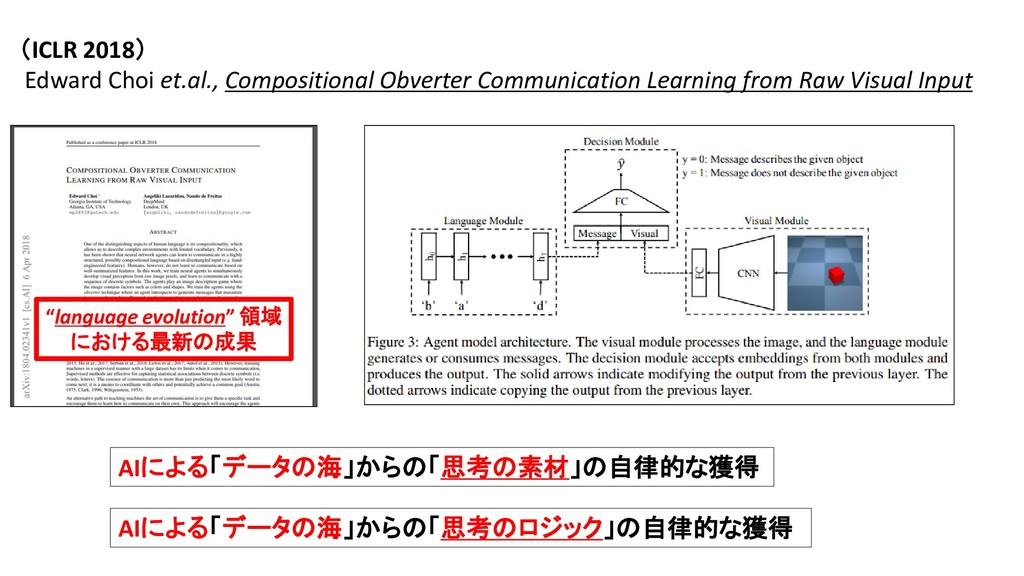
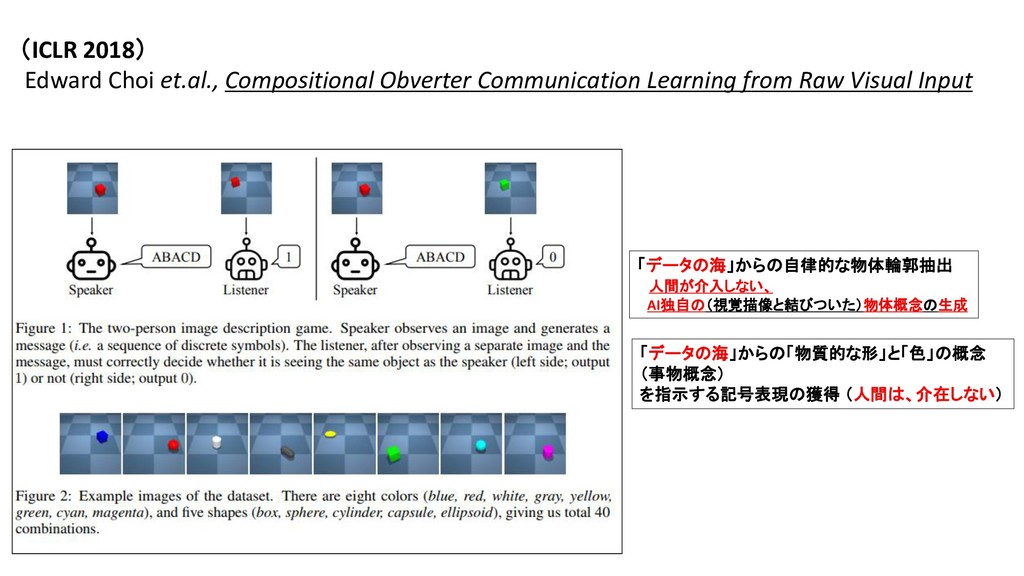
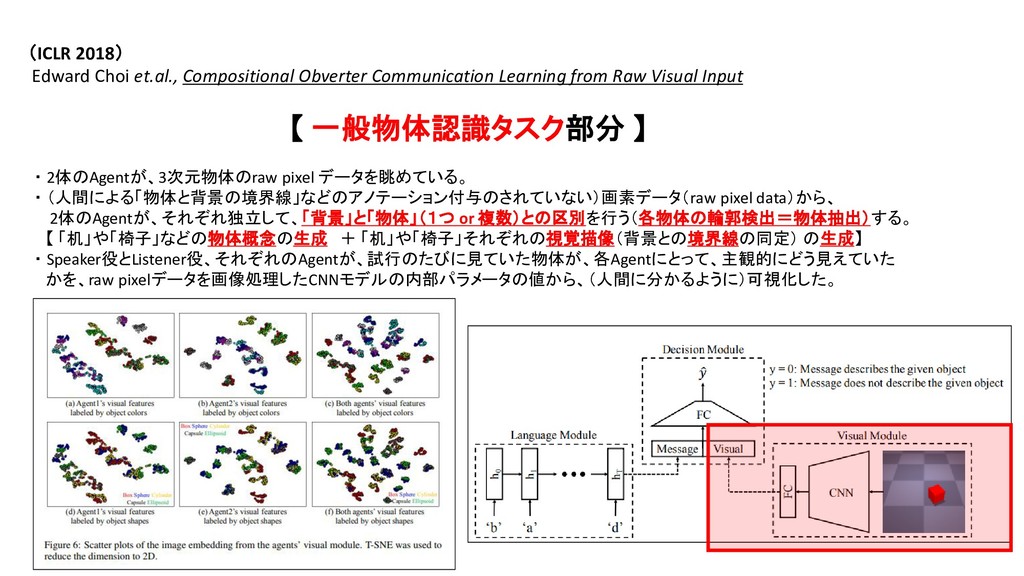
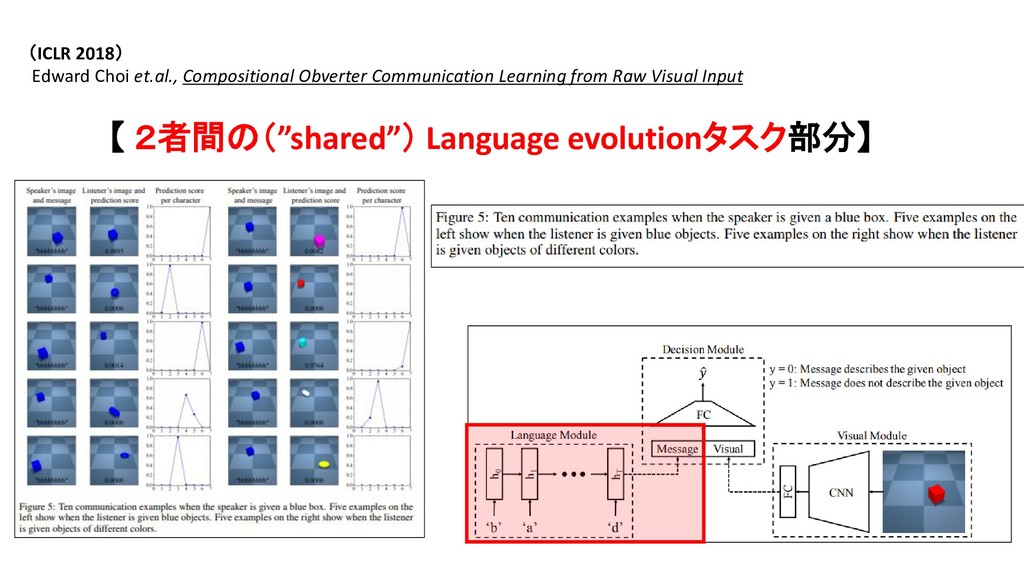
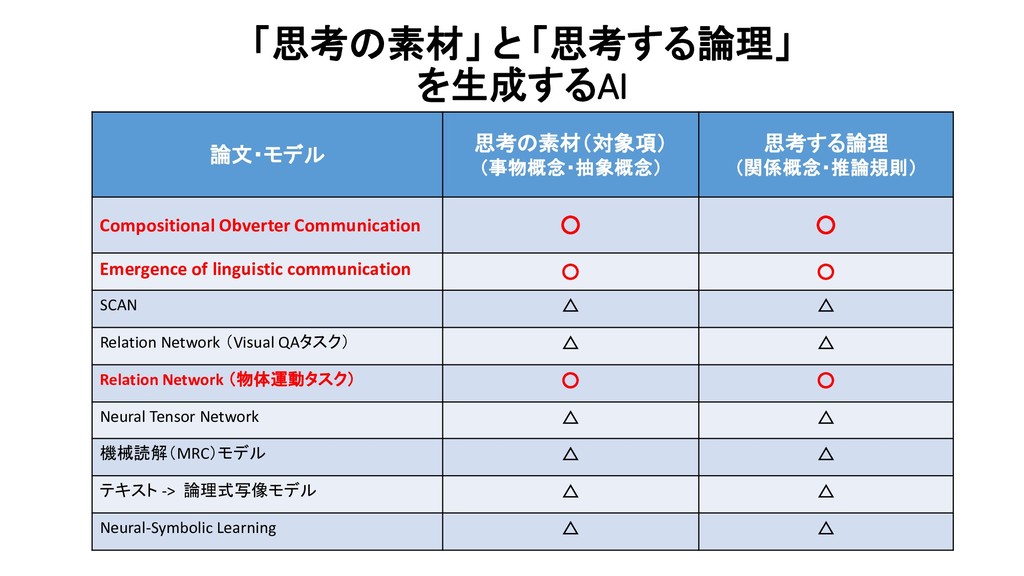
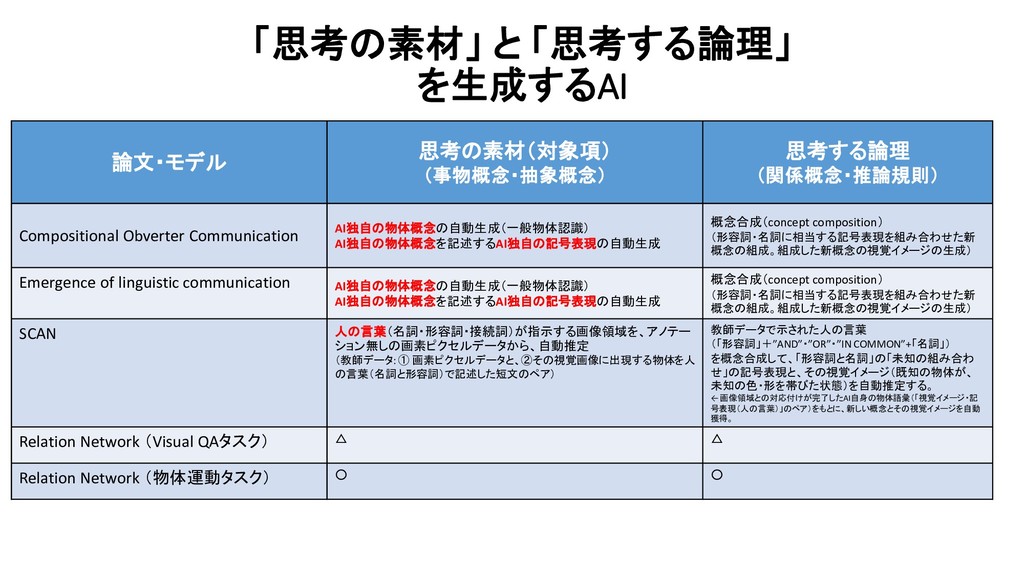
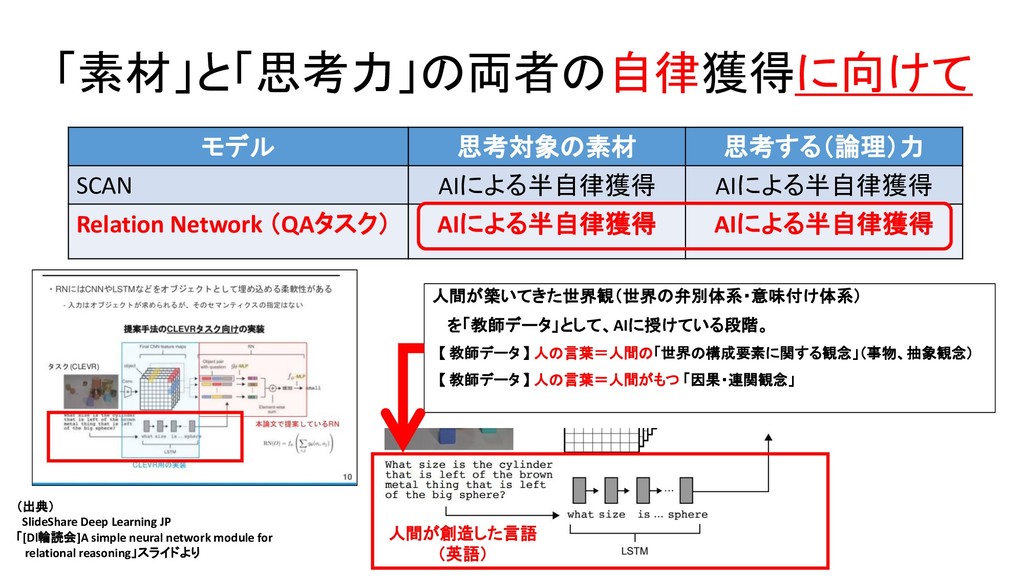
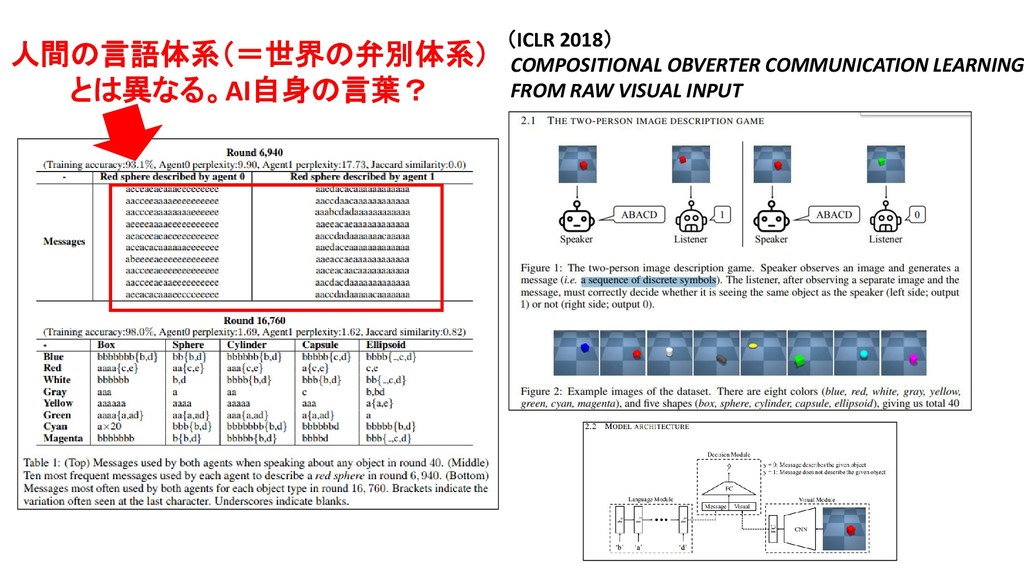
・ AIは、人の手で行われた「画像の意味づけ」=「画像に何(物体概念)が、どの位置に映っているのか」 を、天下り的に与えられるだけの研究にとどまっている。 【 以下、Obverter 論文より抜粋 】 Edward Choi et.al., Compositional Obverter Communication Learning from Raw Visual Input
Emergence of grounded compositional language in multi-agent populations. arXiv preprint arXiv:1703.04908, 2017. ・ Satwik Kottur, Jose MF Moura, Stefan Lee, and Dhruv Batra. Natural language does not emerge ’naturally’ in multi-agent dialog. In EMNLP, 2017.
Linguistic Communication from Referential Games with Symbolic And Pixel Input 【 この論文が発見した事実 】 AI自身が(人間とは無関係に)生成する言語(communication protocol)が、どれだけ構造化の度合いが高い文法規則をもつかは、 そのAIが、(人間による物体輪郭アノテーション付与なしの) raw pixel data (raw sensorimotor data)を(自分のセンサーで)眺めた結果、 そこに、どれだけ複雑な「物体(事物)間の関係構造」の存在を見出すか(認識(同定)するか)によって、左右される。 the degree of structure found in the input data affects the nature of emerged protocols corroborate the hypothesis that structured compositional language is most likely to emerge when agents perceive the world as being structured.
Linguistic Communication from Referential Games with Symbolic And Pixel Input 【 この論文が発見した事実 】 AI自身が(人間とは無関係に)生成する言語(communication protocol)が、どれだけ構造化の度合いが高い文法規則をもつかは、 そのAIが、(人間による物体輪郭アノテーション付与なしの) raw pixel data (raw sensorimotor data)を(自分のセンサーで)眺めた結果、 そこに、どれだけ複雑な「物体(事物)間の関係構造」の存在を見出すか(認識(同定)するか)によって、左右される。 the degree of structure found in the input data affects the nature of emerged protocols corroborate the hypothesis that structured compositional language is most likely to emerge when agents perceive the world as being structured.
Linguistic Communication from Referential Games with Symbolic And Pixel Input 【 2つの実験を行った 】 【 実験1 】 「人間が作成したVisAデータセット」を、「教師」用データとして、AIに「学ばせる」 【 実験2 】 「人間によるアノテーション付与」なしのraw pixel data(raw sensorimotor data)を、AIに与える。
data)を、AIに与える。 raw pixel dataのなかの、どの領域に、何の物体が映っているのか を、AI自身が自律的に判断する ( -> 物体概念の獲得 + その物体概念の視覚描像が出現している位置(範囲)の同定) 物体概念一般には、いかなる属性の集合が想定でき、画像の中に見出したそれぞれの物体は、 個々の属性のどれに該当するのかを、AI自身が自律的に判断する。 disentangled by AI theirselves (with no human helps & instructions)
agent-invented languages are effective (i.e. achieve near-perfect task rewards), they are decidedly not interpretable or compositional. In essence, we find that natural language does not emerge ‘naturally’, despite the semblance of ease of natural-language-emergence that one may gather from recent literature
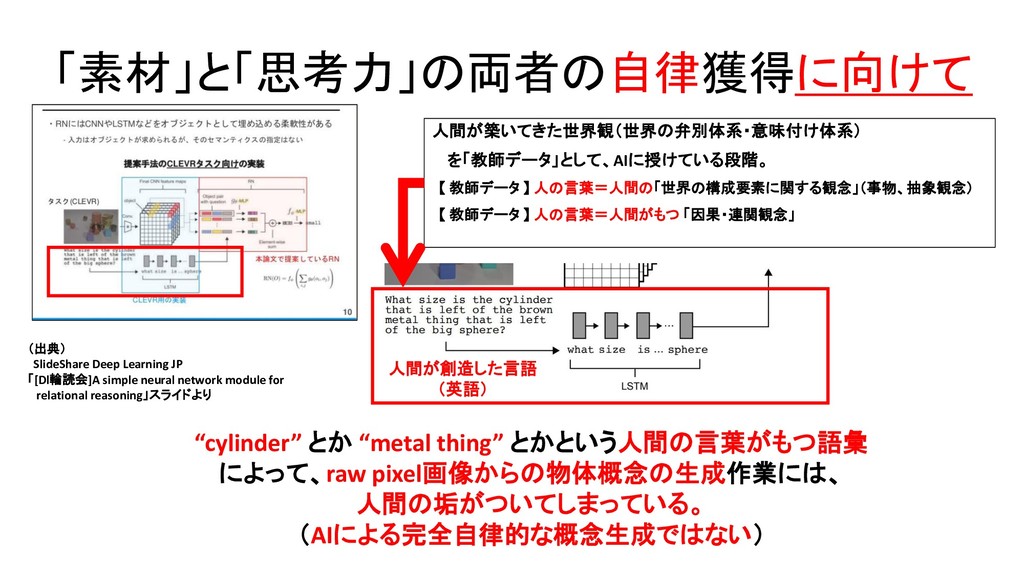
Linguistic Communication from Referential Games with Symbolic And Pixel Input 【 実験1 】 人間が物体輪郭+属性該否の情報をアノテーション付けした Inputデータを受けて、 【 実験2 】 人間によるアノテーションなしの画素データ(raw pixel data)を Inputデータとして受けて、 Encoder-decoderモデルを用いて、 単語(に相当する、人間の言語とは異なる、独自の「記号」) を、「単語(に相当)」単位に、1単語(相当)ずつ、生成する。 Speaker 役のAgent の役割
Linguistic Communication from Referential Games with Symbolic And Pixel Input Speaker 役のAgentのパラメータと、Listener 役のAgentのパラメータを、 ひとつの損失関数式のなかで、同時に学習する。 Speaker 役Agentのパラメータと、 Listener 役Agentのパラメータは、 互いに独立している。 【 報酬関数 】 Speaker 役の発したメッセージを、 Listener 役が理解して、 Speaker役が画像データ中に、何の物体を 見出していたのか、認識共有できたら、 1を返す。認識共有に失敗したら、0を返す。
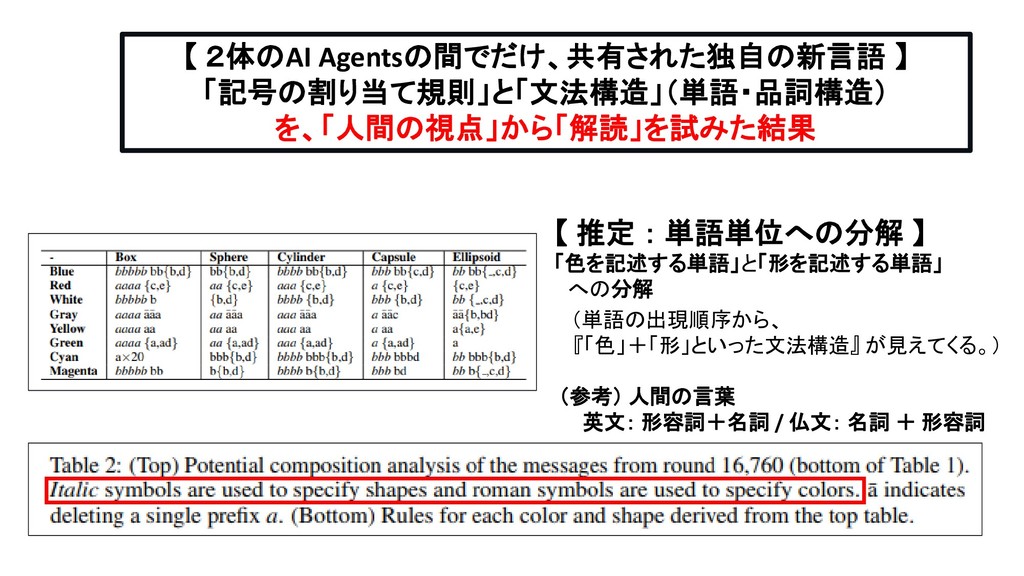
Linguistic Communication from Referential Games with Symbolic And Pixel Input AIが、自身が独自に生成する記号体系(言語体系)を用いて、「1つの物体」を表現する際に、 用いることができる「文字」(Symbol)記号の個数(「文字数」)に上限を設けた。 3パターンの制限を設定し、それぞれの(制約)条件の下で、 生み出される言語体系の特性を、相互に比較した。
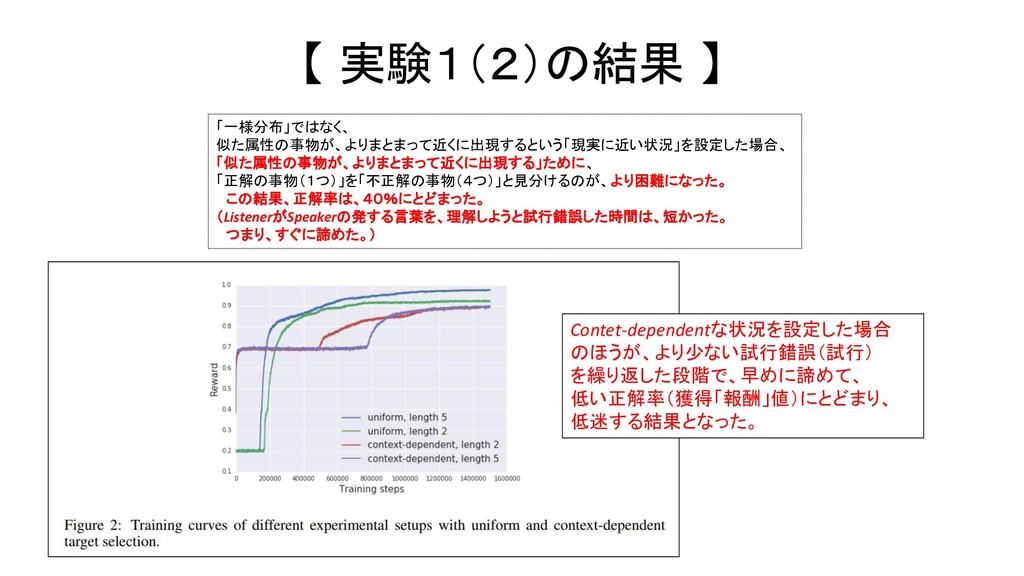
Linguistic Communication from Referential Games with Symbolic And Pixel Input AIに見せる物体郡の配置のパターンを、より現実の世界で遭遇する状況に近い設定にした。 具体的には、種類のことなる事物が、でたらめに、ランダムに並んでいるのではなく、 同じカテゴリに属する事物が、近くに並んで出現する(共起する)状況を再現した。 その上で、事物の配置関係が、完全に「ランダム」な状況であるとき (=先行研究では、事物の並びは、一様分布(uniform distribution)と呼ばれる統計分布に従って、出現する設定) と、似たカテゴリの事物が、近くにまとまって出現する、上記の現実的な状況とで、 このSpeakerがうみだす言語の特性がどう変化し、その言葉を聞いたListenerが、Speakerが見ていた物体 を正しく理解できた割合(正解率)がどう変化したのかを、比較検証した。
Linguistic Communication from Referential Games with Symbolic And Pixel Input Speakerには、ひとつの事物が写っている画像しか見せないが、 Listenerに見せる事物は、「Speakerが見ている事物(1つ)」と、「Speakerが見ていなかった4つの事物」(distractors) の合計5つでる。 今回、後者の4つの事物(不正解の事物)について、 種類のことなる事物が、でたらめに、ランダムに並んでいる状況と、 同じカテゴリに属する事物が、近くに並んで出現する(共起する)状況 (=一様分布ではない、特定の統計分布に従って出現する状況) の2つの状況を用意した。
the semantics of ambiguous or homonym words in the languate. どのような物体を、「親しい意味カテゴリに属する事物概念」に所属する事物として、 その言語は、「同義語」で言い表したり、(曖昧性をもつ)同一の表現で言い表すかの性質 【 実験1(2)の結果 】
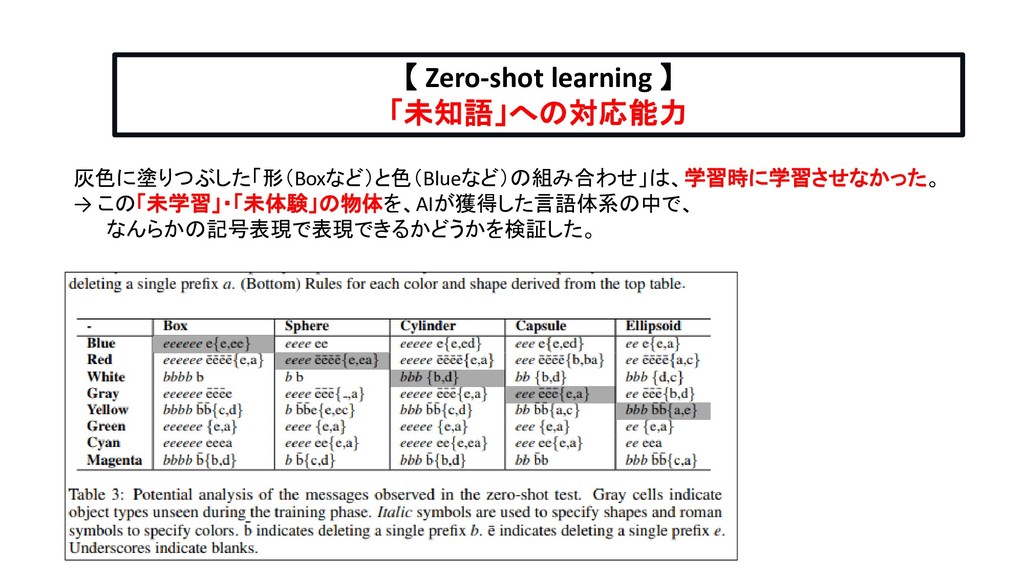
Linguistic Communication from Referential Games with Symbolic And Pixel Input Speakerが、これまで見たことのない「未知の事物」が目の前に出現した(認識した、発見した)ときに、 (未知の物体をみるよりも過去に)、すでに獲得済みの事物概念と(それを指す)言葉(語彙)の範囲内(言語体系内)で、 その「未知の事物」を言語で表現することができるのか、言語のもつ「概念合成力」の大きさを定量評価した。
Linguistic Communication from Referential Games with Symbolic And Pixel Input これまで見たことのない「未知の事物」を構成するために、 Unigram chimeras シナリオとuniform chimeras シナリオの2つの状況設定を用意した。
Linguistic Communication from Referential Games with Symbolic And Pixel Input 加えて、さらに踏み込んで、Speakerに、これまで発したことのない(Listenerが聞いたことのない) 記号列を、発してもらうようにした。(未知の記号列)
Referential Games with Symbolic And Pixel Input Speakerが発したこれまで発したことのない「未知の記号列」は、 過去に発声したことのある「語彙」と、 過去に見られた「接頭辞や接尾語の変化規則」や「語の活用規則」など、過去の言語構造がもっていた言語規則 と一貫性のあるルールで、新たに生み出された表現(新語)だった。 【 実験1(3)の結果 】
B : 「不正解の物体」が 1個しかない状況設定。 Game C : 「不正解の物体」が1個あり、Speaker と Listener は互いに異なる位置から、物体を見ている。 Game D : Cの設定に加えて、物体の色を5種類(Cは8種類)に減らし、3種類の特定の形状をした物体を取り除いた状況設定。 4つの状況設定で、実証実験を行った。
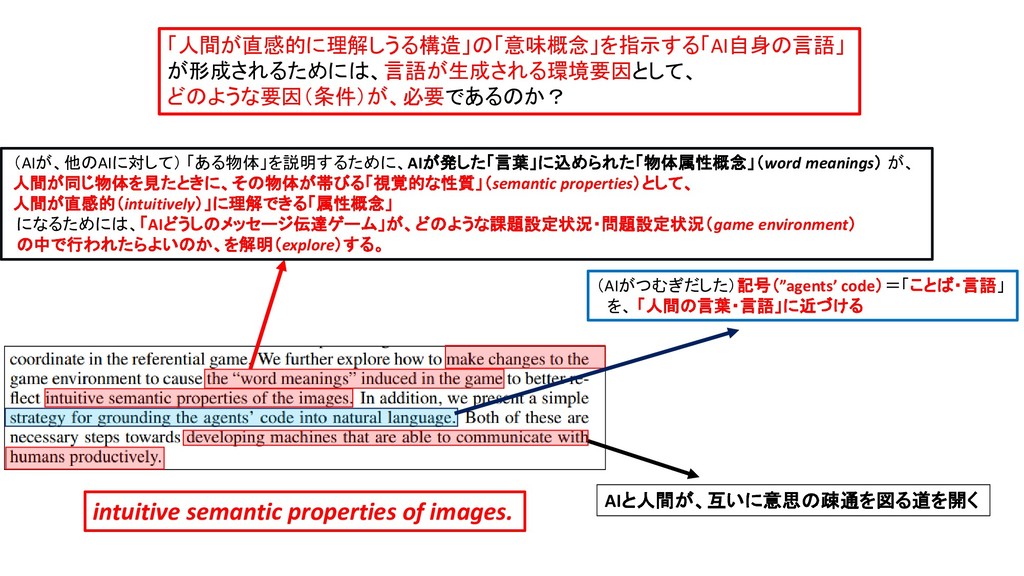
「人間が直感的に理解しうる構造」の「意味概念」を指示する「AI自身の言語」 が形成されるためには、言語が生成される環境要因として、 どのような要因(条件)が、必要であるのか? assigned to meanings that make intuitive sense in terms of our [ human-being’s own ] conceptualization of the world.
of (Natural) Language (人間の指図を受けずに、) 複数のAI Agentどうしが、互いの認識を伝達しようとする「言語伝達ゲーム」 (multi-agent coordination communication games)という状況文脈の中で、 「言語も概念もなにもない白紙の状態」(start as blank slates)から、互いの認識を伝達し合おうと試行錯誤する過程 を通じて、共有された「物体属性概念」と、それを指示する言葉が、立ち現れてくるプロセスを研究する
of (Natural) Language (人間の指図を受けずに、) 複数のAI Agentどうしが、互いの認識を伝達しようとする「言語伝達ゲーム」 (multi-agent coordination communication games)という状況文脈の中で、 「言語も概念もなにもない白紙の状態」(start as blank slates)から、互いの認識を伝達し合おうと試行錯誤する過程 を通じて、共有された「物体属性概念」と、それを指示する言葉が、立ち現れてくるプロセスを研究する
Nando de Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning. In NIPS, pp. 2137–2145, 2016. ・ Angeliki Lazaridou, Alexander Peysakhovich, and Marco Baroni. Multi-agent cooperation and the emergence of (natural) language. In ICLR, 2017. 再掲
the Emergence of (Natural) Language 要素数 K(個)の記号集合は、以下のいずれかであるかは、論文で明示されていない。 【 可能性1 】 人間によって、天下り的に与えられる。 【 可能性2 】 (複数の)AIどうしがコミュニケーションを行う相互過程の中から、おのずと(内生的に)生成される。
the Emergence of (Natural) Language a message from a fixed, arbitrary vocabulary 以下の “from … arbitrary vocabulary” という記述を見るかぎりでは、【 可能性2 】 だろうか? 【 可能性1 】 人間によって、天下り的に与えられる。 【 可能性2 】 (複数の)AIどうしがコミュニケーションを行う相互過程の中から、おのずと(内生的に)生成される。
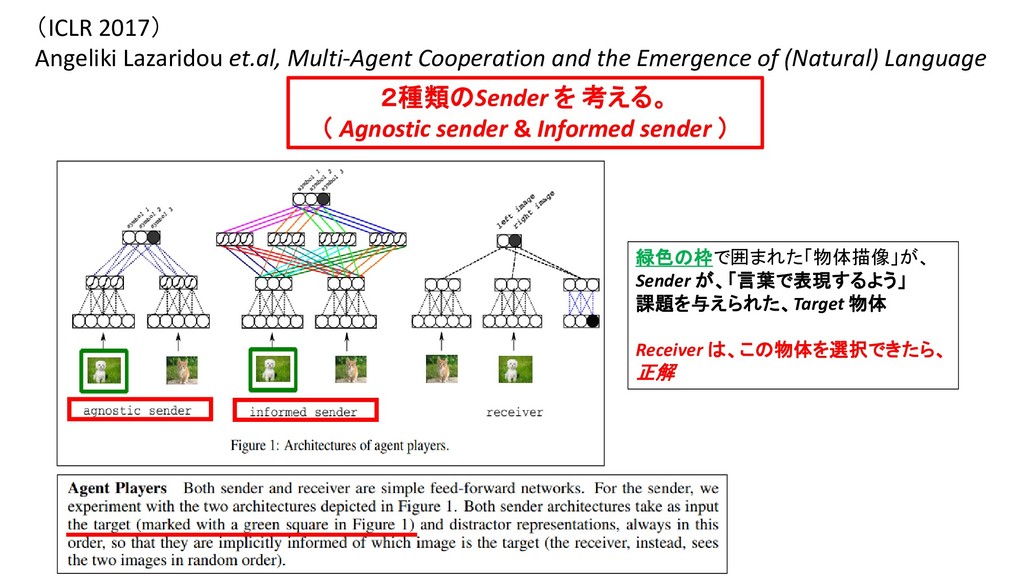
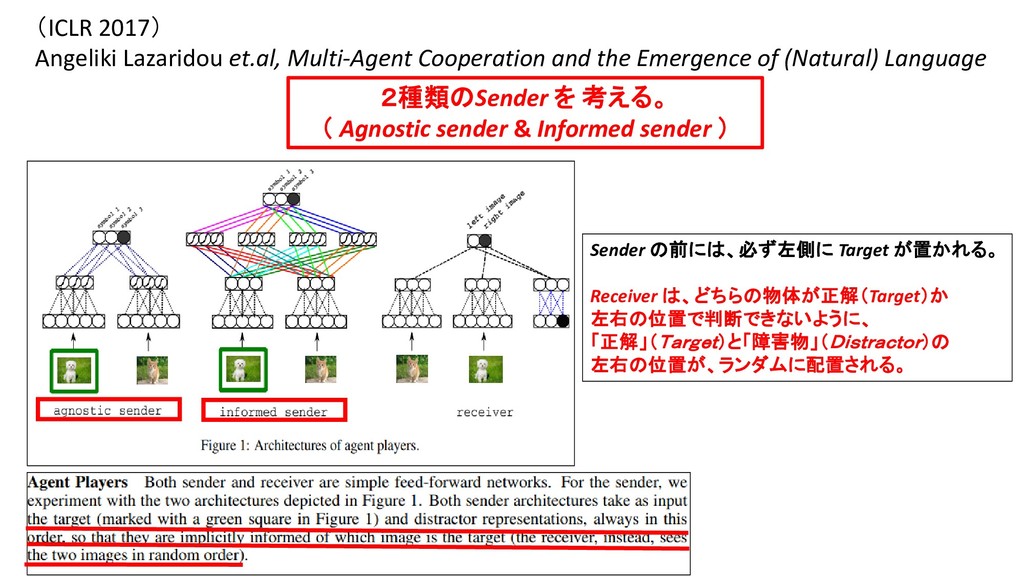
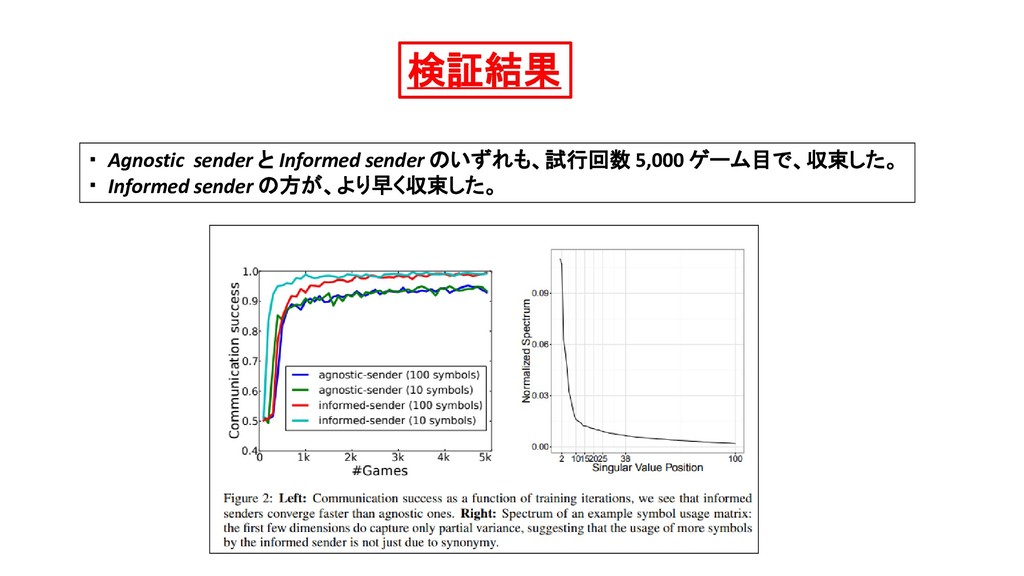
of (Natural) Language 2種類のSender を 考える。 ( Agnostic sender & Informed sender ) Informed sender は、 目の前にある「2つの物体描像」を「総体的に」眺める。 The resulting feature maps are combined through another filter has an inductive bias towards combining the two images dimensionby-dimension
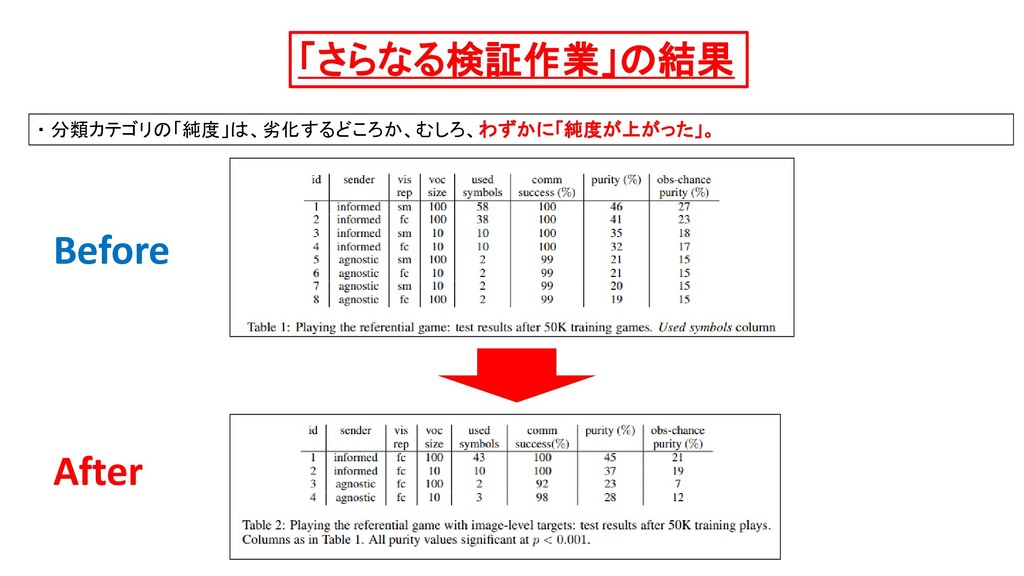
AIが生成する言語」と「人間がもつ物体-名詞ラベル」とを、 「直接的(明示的)に、対応付けた」(thanks to their direct correspondence to labels.)ことで、 「Sender AI がうみだした記号列」の多く(many symbols)は、「直接的に、人間が理解できる」記号になった (many symbols have now become directly interpretable)
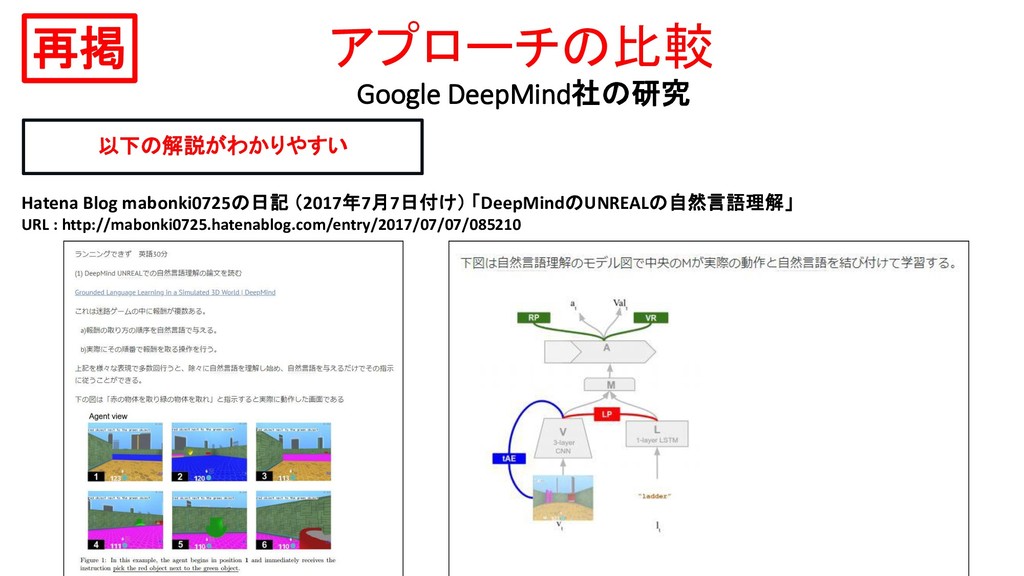
games : learning to communicate with sequences of symbols to ensure that the invented protocol is close enough to a natural language and, thus, potentially interpretable by humans DeepMindのこの論文を引用している (University of Edinburgh所属の研究者による) 後続の論文
games : learning to communicate with sequences of symbols with a language that is understandable by humans. DeepMindのこの論文を引用している (University of Edinburgh所属の研究者による) 後続の論文
emergence of language with multi-agent games : learning to communicate with sequences of symbols Between twa agents … while human interpretability would be ensured
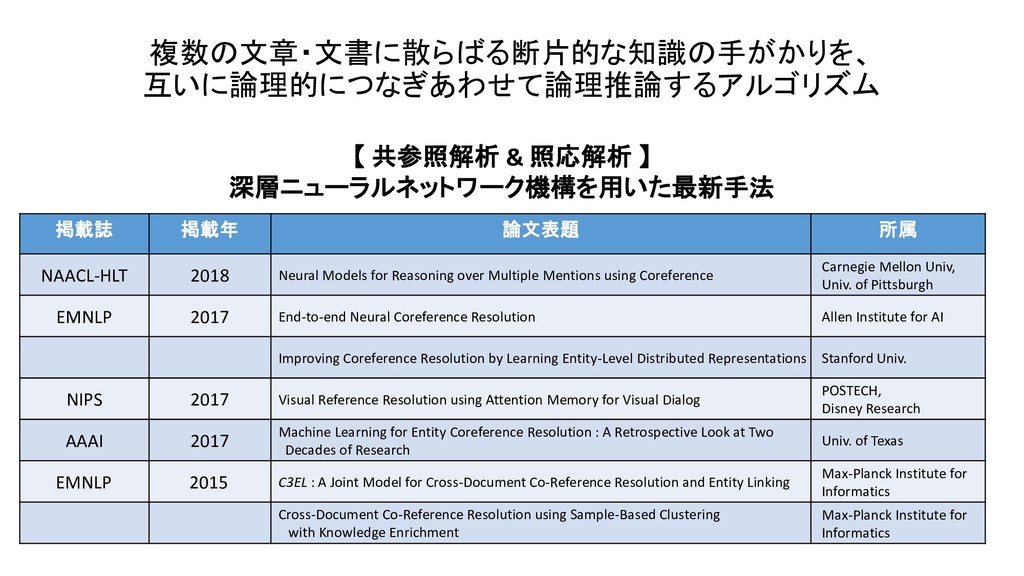
論文表題 所属 NAACL-HLT 2018 Neural Models for Reasoning over Multiple Mentions using Coreference Carnegie Mellon Univ, Univ. of Pittsburgh EMNLP 2017 End-to-end Neural Coreference Resolution Allen Institute for AI Improving Coreference Resolution by Learning Entity-Level Distributed Representations Stanford Univ. NIPS 2017 Visual Reference Resolution using Attention Memory for Visual Dialog POSTECH, Disney Research AAAI 2017 Machine Learning for Entity Coreference Resolution : A Retrospective Look at Two Decades of Research Univ. of Texas EMNLP 2015 C3EL : A Joint Model for Cross-Document Co-Reference Resolution and Entity Linking Max-Planck Institute for Informatics Cross-Document Co-Reference Resolution using Sample-Based Clustering with Knowledge Enrichment Max-Planck Institute for Informatics
Evolution Channels Gradient Descent in Super Neural Networks 【 Icoxfig417氏による論文要約 】 URL : https://github.com/arXivTimes/arXivTimes/issues/191 【 Hatena Blog we are hackaer による論文解説 】 URL: http://miyamotok0105.hatenablog.com/entry/2017/03/23/200000
2017 ] David Raposo et.al., Discovering objects and their relations from entangled scene 『人間の』「言語」を自律的に獲得するAI ・ Karl Moritz Hermann et.al., Grounded Language Learning in a Simulated 3D World 以下のモデルも、Language Evolution研究のモデルと融合させていくことが、 今後の課題となる。
] Vicarious社 ・ Ken Kansky et.al., Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics Imperial College London ・ Marta Garnero et.al., Towards Deep Symbolic Reinforcement Learning
et.al., Schema Networks: Zero-shot Transfer with a Generative Causal Model of Intuitive Physics the Schema Network can learn the dynamics of an environment directly from data. generative physics simulator capable of disentangling multiple causes of events and reasoning backward through causes to achieve goals.
Marta Garnero et.al., Towards Deep Symbolic Reinforcement Learning architecture comprising a neural back end and a symbolic front end learns effectively, and, by acquiring a set of symbolic rules that are easily comprehensible to humans ability to reason on an abstract level, … to implement high-level cognitive functions such as transfer learning, analogical reasoning, and hypothesis-based reasoning.
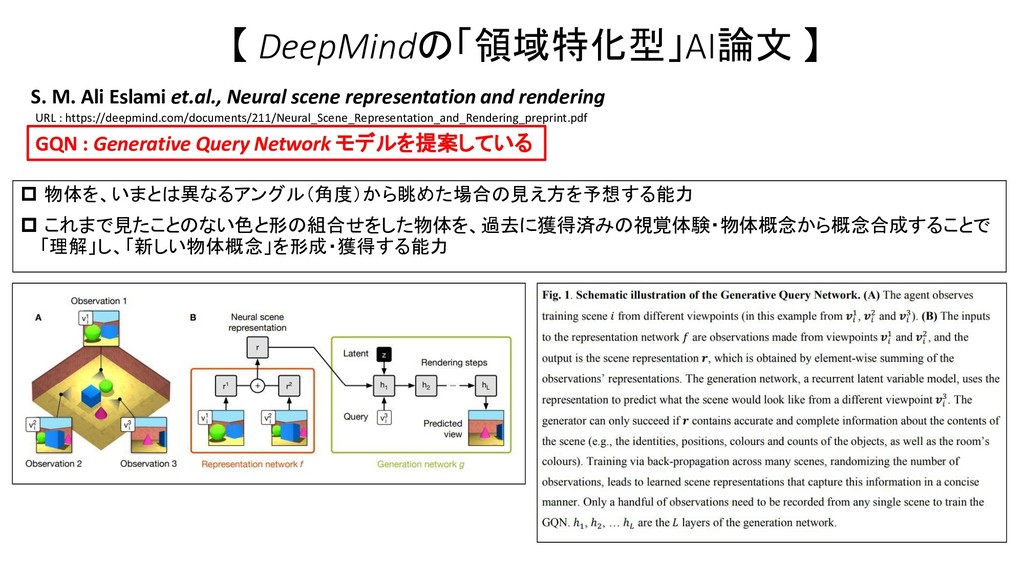
周囲の光景の背景や(光景の中にある)物体について、死角になっている部分の描像を推定する能力 これまで見たことのない色と形の組合せをした物体を、過去に獲得済みの視覚体験・物体概念から概念合成することで 「理解」し、「新しい物体概念」を形成・獲得する能力 上記の領域に取り組んだ、DeepMindから公開済みの論文 (いずれも、Preprint版。研究進行中) ・ (2018/7/4 Work in progress)Ananya Kumar et.al., Consistent Generative Query Networks ・ (2018/7/5 Preprint. Work in progress) Tiago Ramalho et.al., Encoding Spatial Relations from Natural Language ・ (2018/6/15 ) S. M. Ali Eslami et.al., Neural scene representation and rendering ・ (2018/7/4 Preprint. Work in progress ) Dan Rosenbaum et.al., Learning models for visual 3D localization with implicit mapping ・ (2018/7/10 Preprint. Work in progress) Aaron van den Oord et.al., Representation Learning with Contrastive Predictive Coding
representation and rendering DeepMind社 公式ブログ Neural scene representation and rendering URL : https://deepmind.com/blog/neural-scene-representation-and-rendering/
with Contrastive Predictive Coding In neuroscience, predictive coding theories suggest that the brain predicts observations at various levels of abstraction [7, 8]. One of the most common strategies for unsupervised learning has been to predict future, missing or contextual information
with Contrastive Predictive Coding And by casting this as a prediction problem, we automatically infer these features of interest to representation learning. Secondly, we use powerful autoregressive models in this latent space to make predictions many steps in the future.
et.al., Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning 【 解説スライド 】 富田 風大 「論文紹介 Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning」 URL : http://www-waka.ist.osaka-u.ac.jp/brainJournal/lib/exe/fetch.php?media=%E3%83%9A%E3%83%BC%E3%82%B8:2017:170301_f-tomita.pdf
et.al., Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning 【 解説スライド 】 富田 風大 「論文紹介 Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning」 URL : http://www-waka.ist.osaka-u.ac.jp/brainJournal/lib/exe/fetch.php?media=%E3%83%9A%E3%83%BC%E3%82%B8:2017:170301_f-tomita.pdf
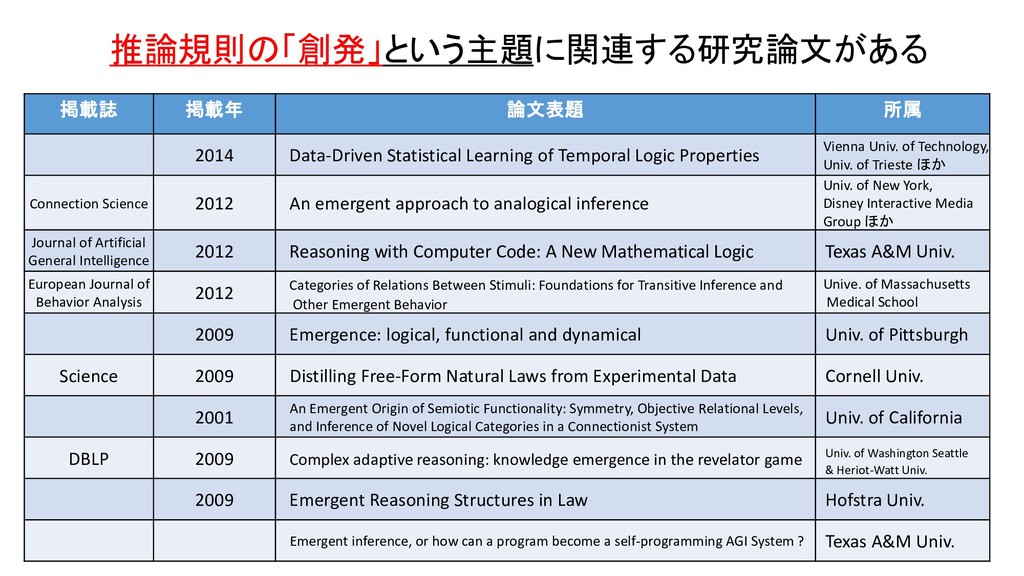
Temporal Logic Properties Vienna Univ. of Technology, Univ. of Trieste ほか Connection Science 2012 An emergent approach to analogical inference Univ. of New York, Disney Interactive Media Group ほか Journal of Artificial General Intelligence 2012 Reasoning with Computer Code: A New Mathematical Logic Texas A&M Univ. European Journal of Behavior Analysis 2012 Categories of Relations Between Stimuli: Foundations for Transitive Inference and Other Emergent Behavior Unive. of Massachusetts Medical School 2009 Emergence: logical, functional and dynamical Univ. of Pittsburgh Science 2009 Distilling Free-Form Natural Laws from Experimental Data Cornell Univ. 2001 An Emergent Origin of Semiotic Functionality: Symmetry, Objective Relational Levels, and Inference of Novel Logical Categories in a Connectionist System Univ. of California DBLP 2009 Complex adaptive reasoning: knowledge emergence in the revelator game Univ. of Washington Seattle & Heriot-Watt Univ. 2009 Emergent Reasoning Structures in Law Hofstra Univ. Emergent inference, or how can a program become a self-programming AGI System ? Texas A&M Univ.
Causal Mathematical Logic as a guiding framework for the prediction of “Intelligence Signals” in brain simulations Open Univ. & Univ. of Houston Journal of Artificial General Intelligence 2013 Black-box Brain Experiments, Causal Mathematical Logic, and the Thermodynamics of Intelligence Univ. of Houston & Open Univ. Causal Logic Models Carnegie Mellon Univ. & Univ. of Pittsburgh Bounded Seed-AGI The Swiss AI Lab IDSIA ほか International Journal of Mathematics and Computational Sciences 2010 Coupled dynamics in host-guest comples systems duplicates emergent behavior in the brain Engineering and Technokogy 2009 A New Universal Model of Computation and its Contribution to Learning, Intelligence, Parallelism, Ontologies, Refactoring, and the Sharing of Resources Member of IEEE, AAAI, APS Conceptual Blending and Quest for the Holy Creative Process Univ. of Coimbra AISB Journal 2003 Optimality Principles for Conceptual Blending: A First Computational Approach Univ. de Coimbra (CISUC) Argument and Computation 2012 Rational argument, rational inference Cardiff Univ & University College London INTERDISCIPLINARIA 2004 Information and Inference as Combined Cognitive Processes Consejo Nacional de Investigacions Cientificas y Tecnicas 推論規則の「創発」という主題に関連する研究論文がある
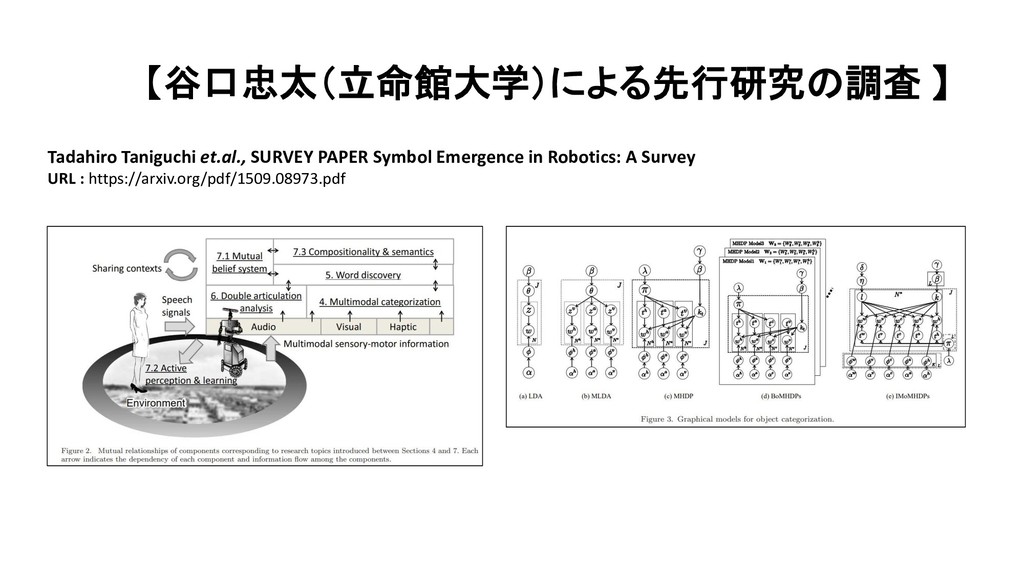
Robotics: A Survey URL : https://arxiv.org/pdf/1509.08973.pdf we introduce a field of research called symbol emergence in robotics (SER). SER is a constructive approach towards an emergent symbol system.
Robotics: A Survey URL : https://arxiv.org/pdf/1509.08973.pdf we introduce a field of research called symbol emergence in robotics (SER). SER is a constructive approach towards an emergent symbol system.
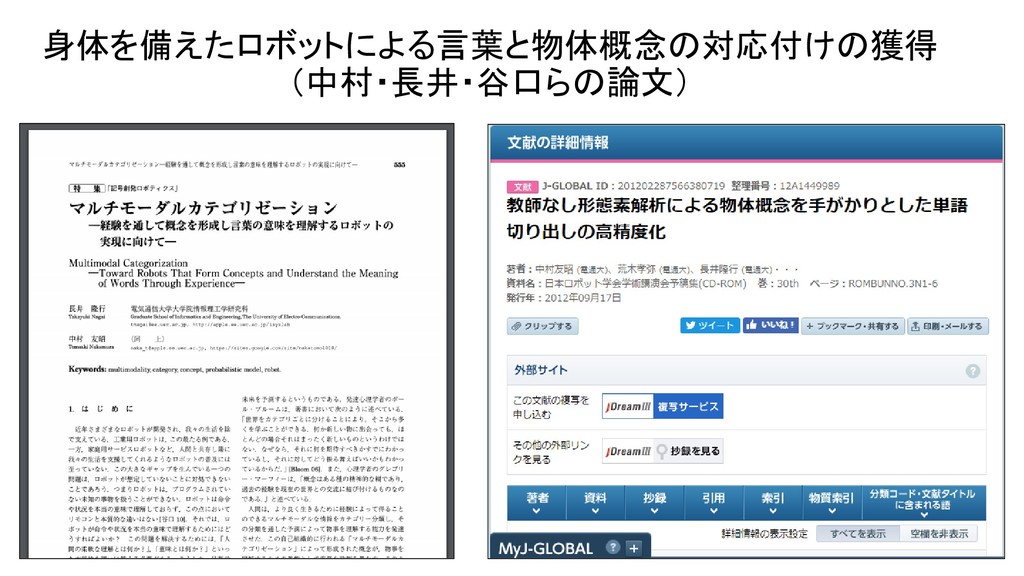
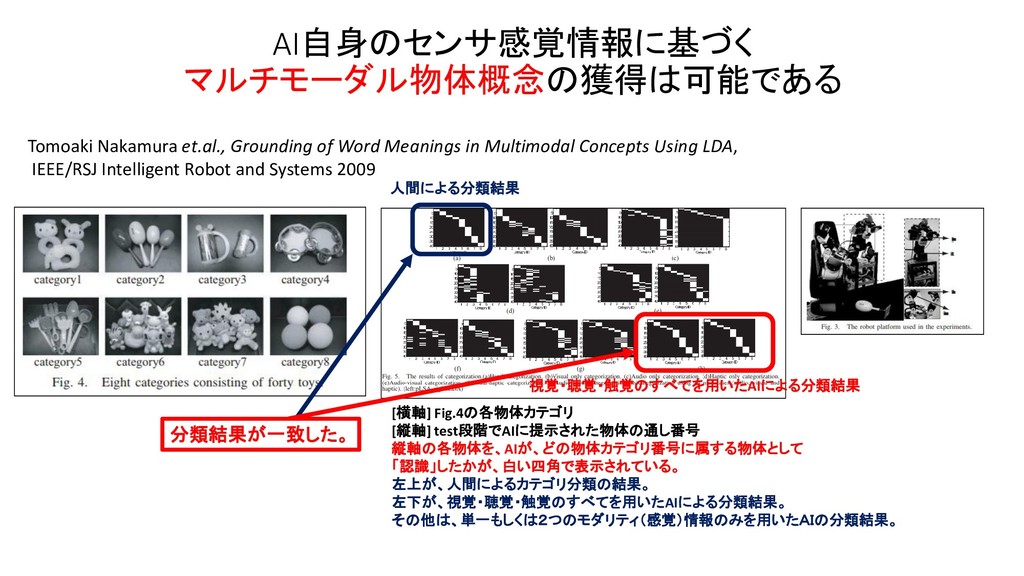
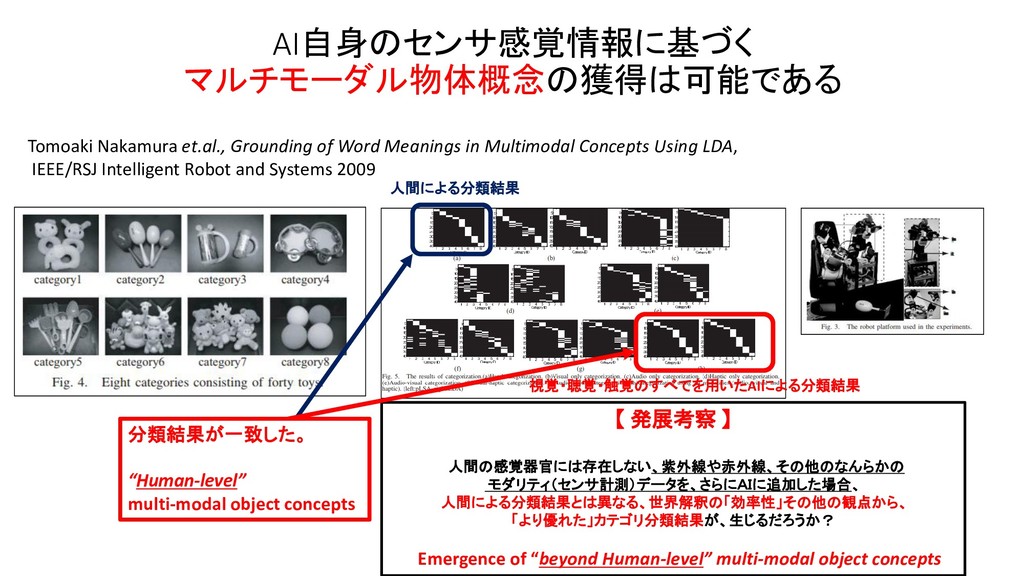
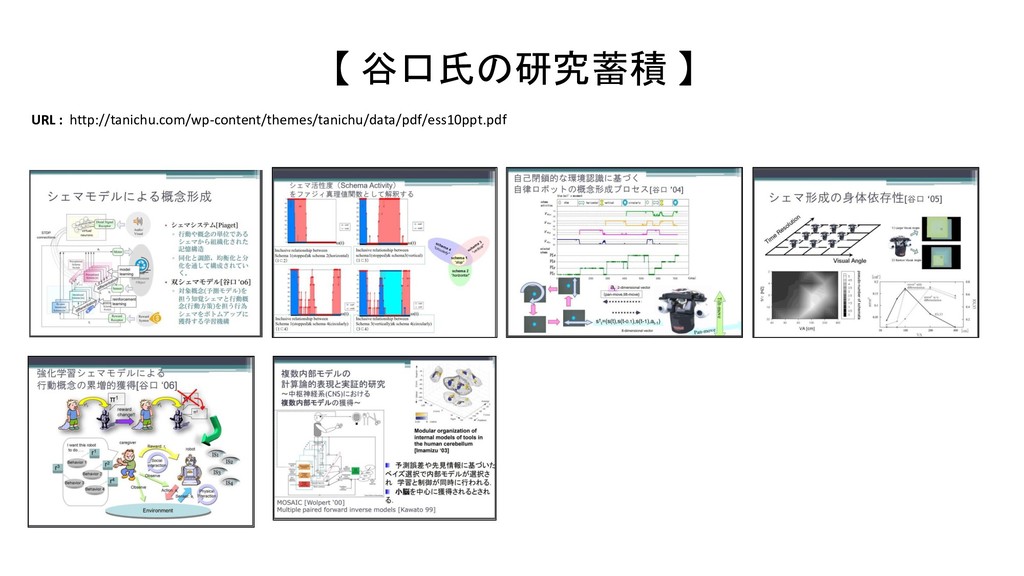
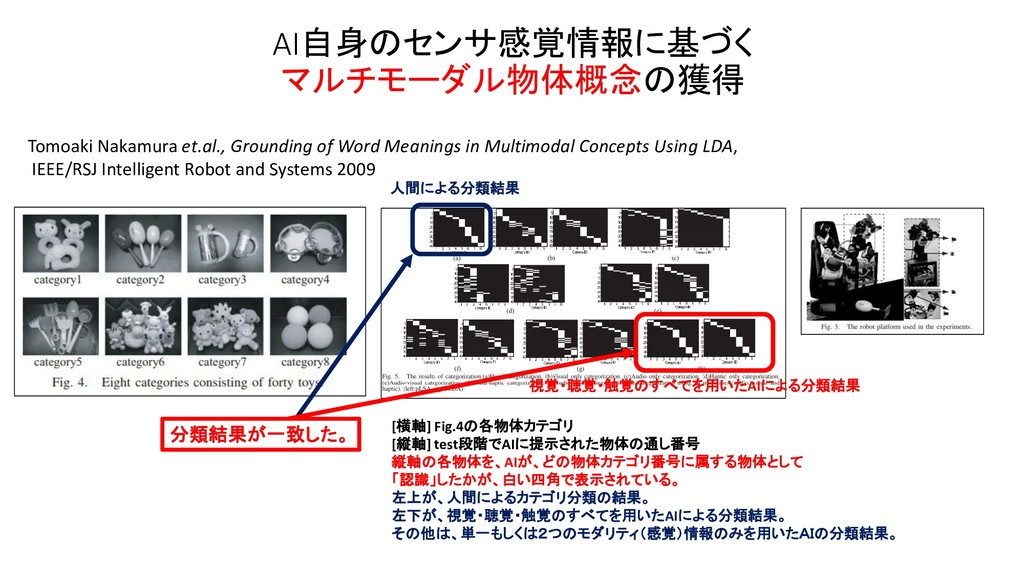
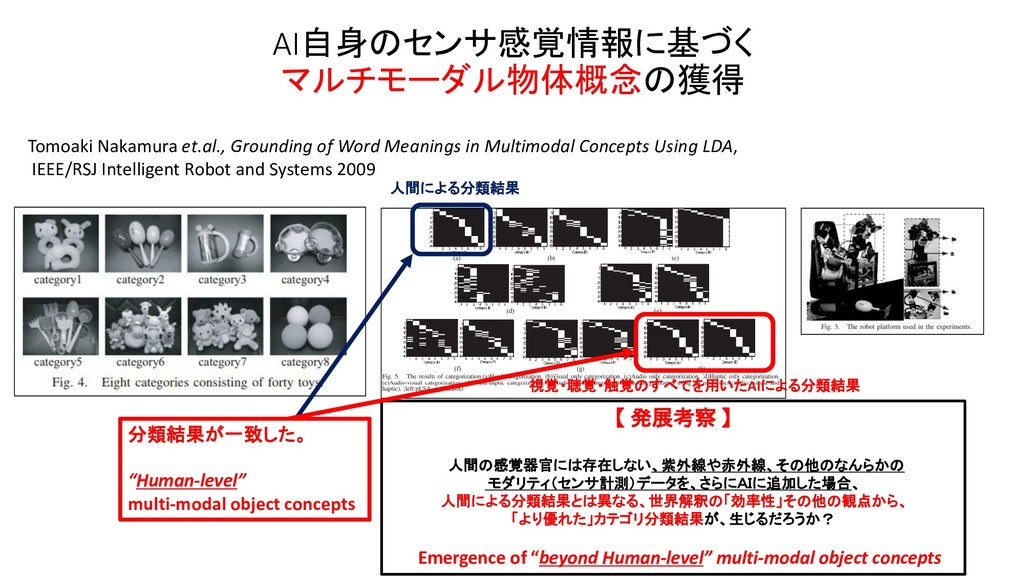
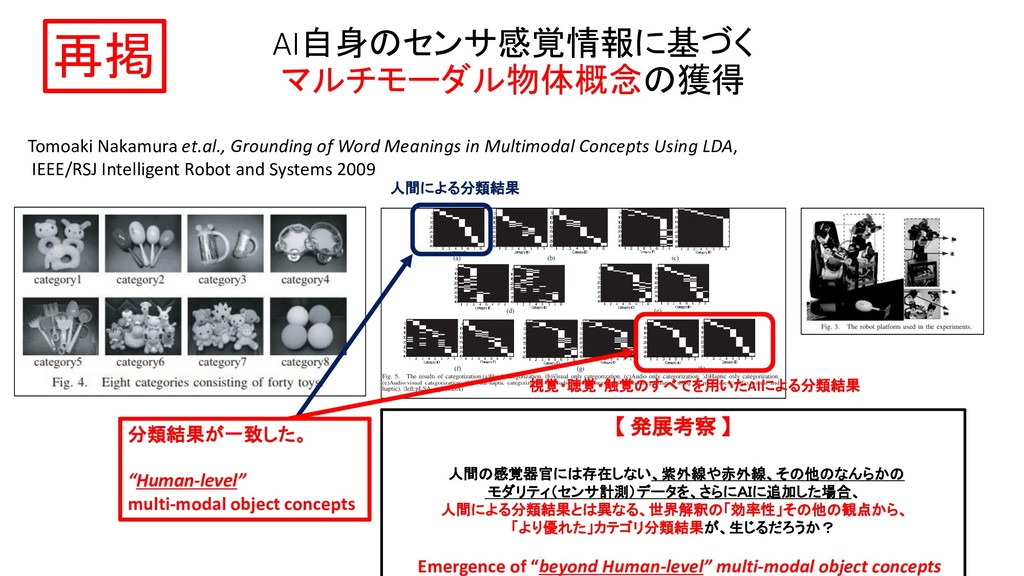
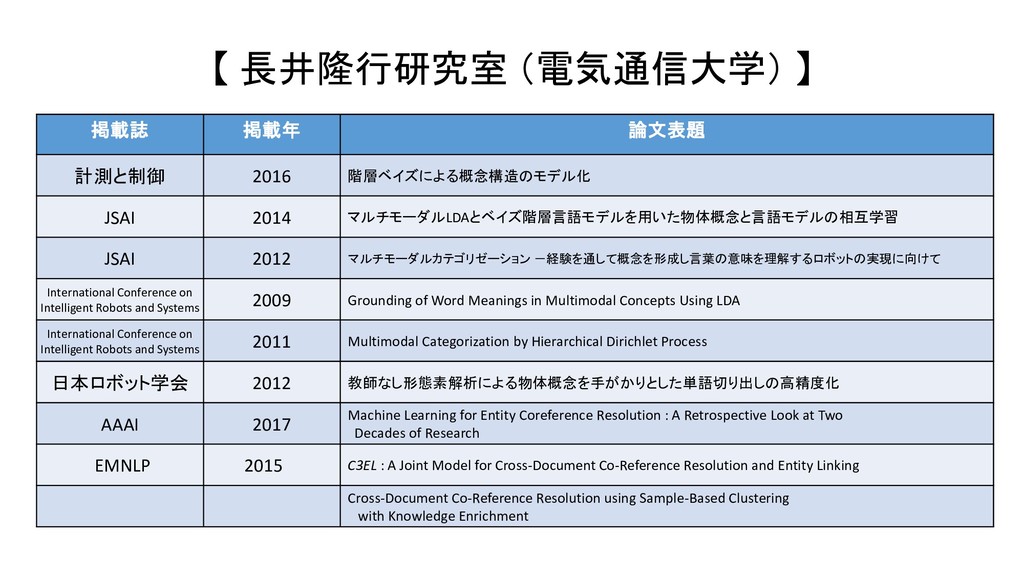
JSAI 2014 マルチモーダルLDAとベイズ階層言語モデルを用いた物体概念と言語モデルの相互学習 JSAI 2012 マルチモーダルカテゴリゼーション -経験を通して概念を形成し言葉の意味を理解するロボットの実現に向けて International Conference on Intelligent Robots and Systems 2009 Grounding of Word Meanings in Multimodal Concepts Using LDA International Conference on Intelligent Robots and Systems 2011 Multimodal Categorization by Hierarchical Dirichlet Process 日本ロボット学会 2012 教師なし形態素解析による物体概念を手がかりとした単語切り出しの高精度化 AAAI 2017 Machine Learning for Entity Coreference Resolution : A Retrospective Look at Two Decades of Research EMNLP 2015 C3EL : A Joint Model for Cross-Document Co-Reference Resolution and Entity Linking Cross-Document Co-Reference Resolution using Sample-Based Clustering with Knowledge Enrichment
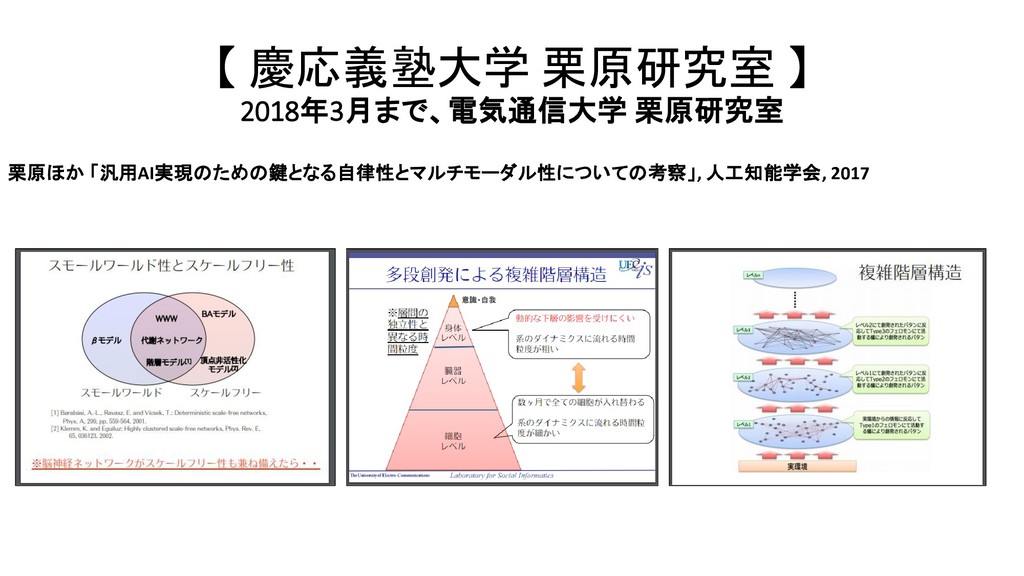
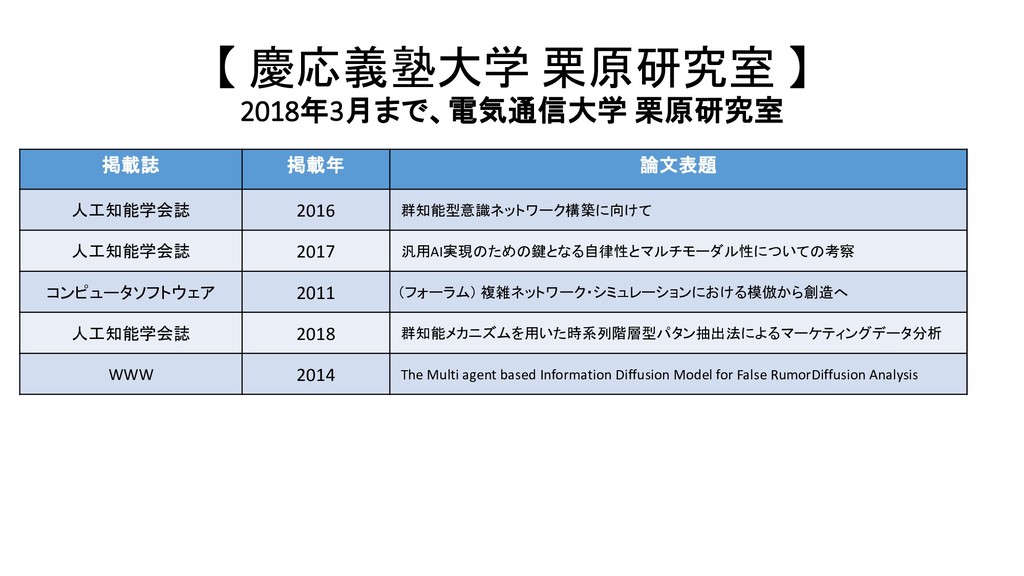
2016 群知能型意識ネットワーク構築に向けて 人工知能学会誌 2017 汎用AI実現のための鍵となる自律性とマルチモーダル性についての考察 コンピュータソフトウェア 2011 (フォーラム) 複雑ネットワーク・シミュレーションにおける模倣から創造へ 人工知能学会誌 2018 群知能メカニズムを用いた時系列階層型パタン抽出法によるマーケティングデータ分析 WWW 2014 The Multi agent based Information Diffusion Model for False RumorDiffusion Analysis
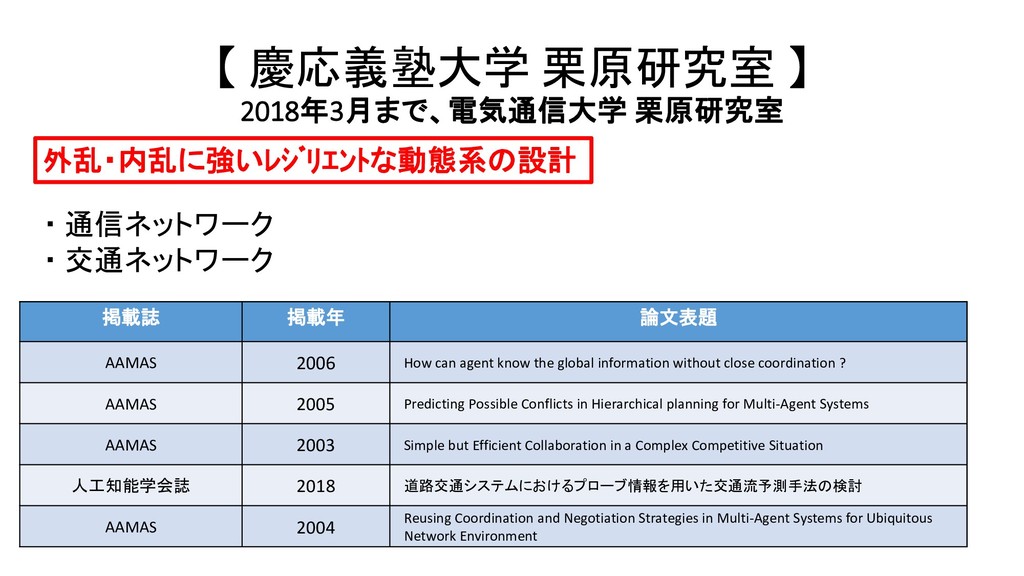
栗原研究室 掲載誌 掲載年 論文表題 AAMAS 2006 How can agent know the global information without close coordination ? AAMAS 2005 Predicting Possible Conflicts in Hierarchical planning for Multi-Agent Systems AAMAS 2003 Simple but Efficient Collaboration in a Complex Competitive Situation 人工知能学会誌 2018 道路交通システムにおけるプローブ情報を用いた交通流予測手法の検討 AAMAS 2004 Reusing Coordination and Negotiation Strategies in Multi-Agent Systems for Ubiquitous Network Environment
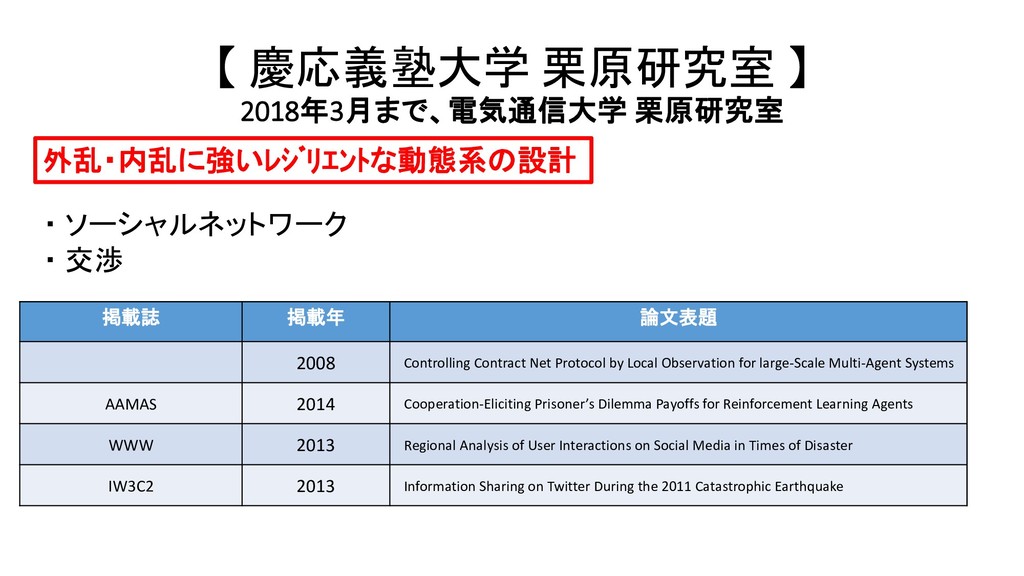
栗原研究室 掲載誌 掲載年 論文表題 2008 Controlling Contract Net Protocol by Local Observation for large-Scale Multi-Agent Systems AAMAS 2014 Cooperation-Eliciting Prisoner’s Dilemma Payoffs for Reinforcement Learning Agents WWW 2013 Regional Analysis of User Interactions on Social Media in Times of Disaster IW3C2 2013 Information Sharing on Twitter During the 2011 Catastrophic Earthquake
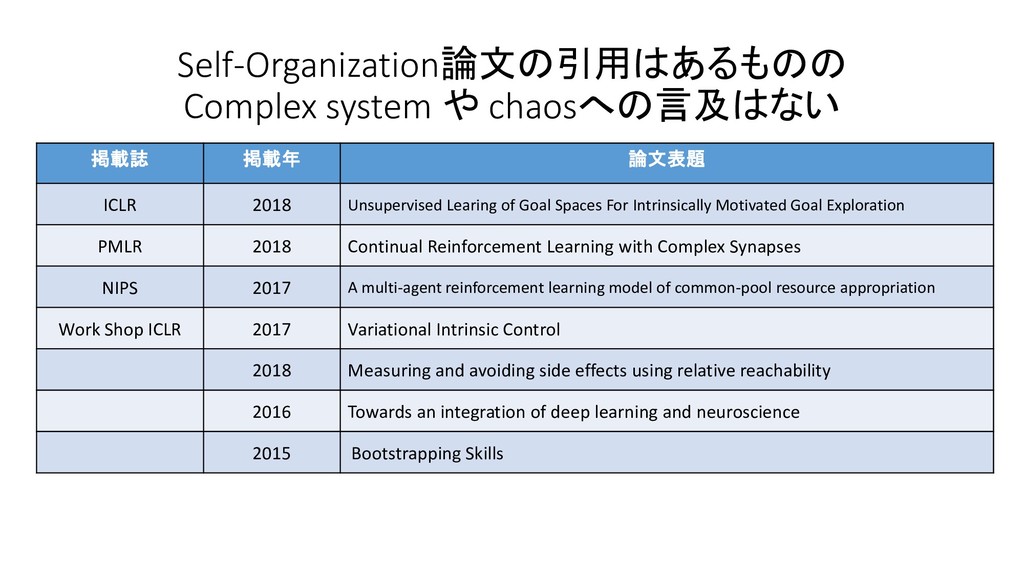
For Intrinsically Motivated Goal Exploration PMLR 2018 Continual Reinforcement Learning with Complex Synapses NIPS 2017 A multi-agent reinforcement learning model of common-pool resource appropriation Work Shop ICLR 2017 Variational Intrinsic Control 2018 Measuring and avoiding side effects using relative reachability 2016 Towards an integration of deep learning and neuroscience 2015 Bootstrapping Skills Self-Organization論文の引用はあるものの Complex system や chaosへの言及はない
of visualluy grounded imagination Georgia Tech., Google Inc. (ICLR Workshop) 2018 Concept Learning via Meta-Optimization with Energy Models OpenAI (NIPS Workshop) 2017 Feature-matching auto-encoders Columbia Univ., OpenAI Arxiv 2018 Learning disentangled Jjoint continuous and discrete representations Schlumberger Software Technology I nnovation Center 2017 Conceptual-linguistic superintelligence eCortex.Inc. (修士論文) Learning transferable data representations using deep generative models Arizona State Univ. 2017 Measuring the tendency of cnns to learn surface statistical regularities Univ. de Montreal
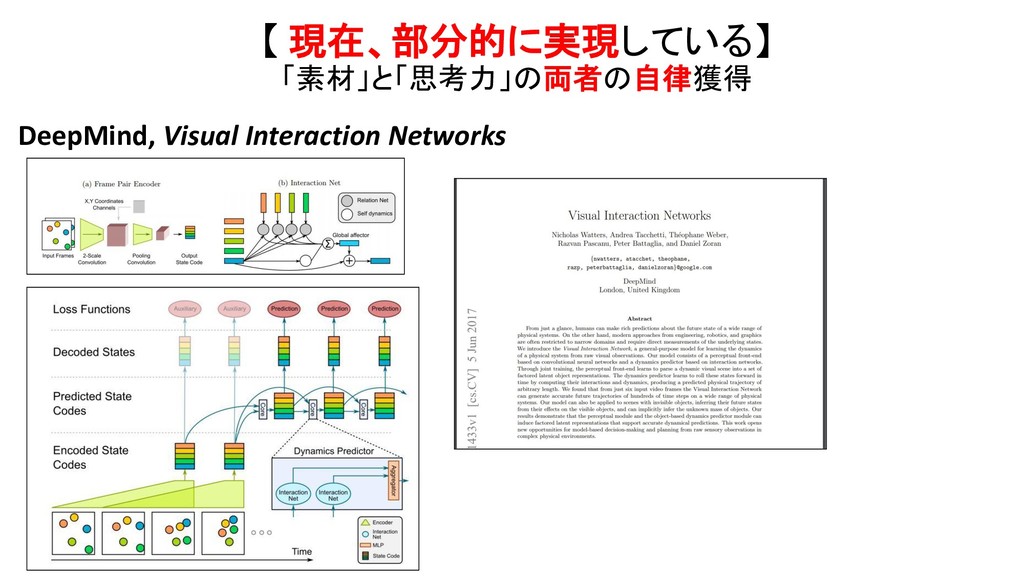
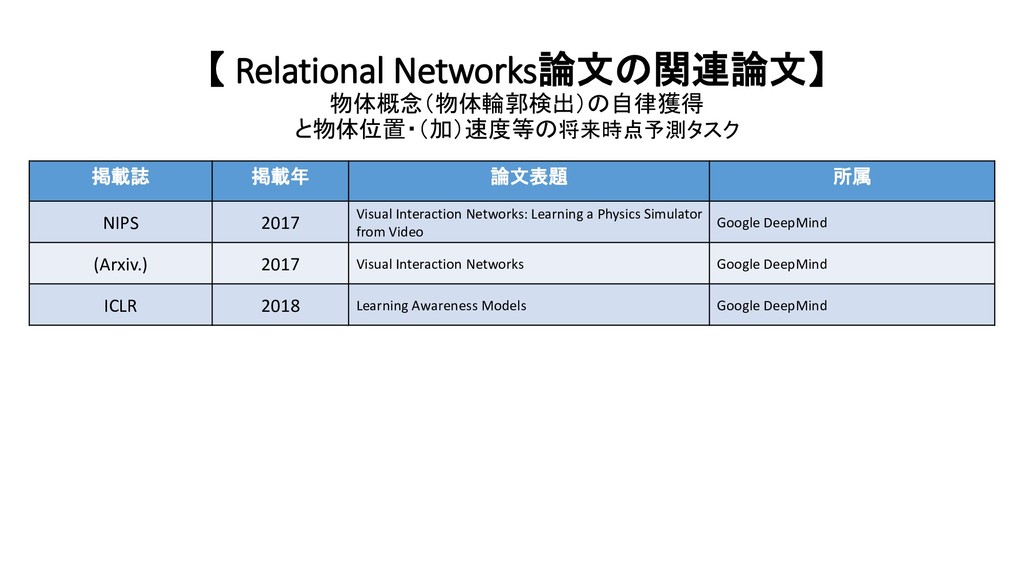
2017 Visual Interaction Networks: Learning a Physics Simulator from Video Google DeepMind (Arxiv.) 2017 Visual Interaction Networks Google DeepMind ICLR 2018 Learning Awareness Models Google DeepMind
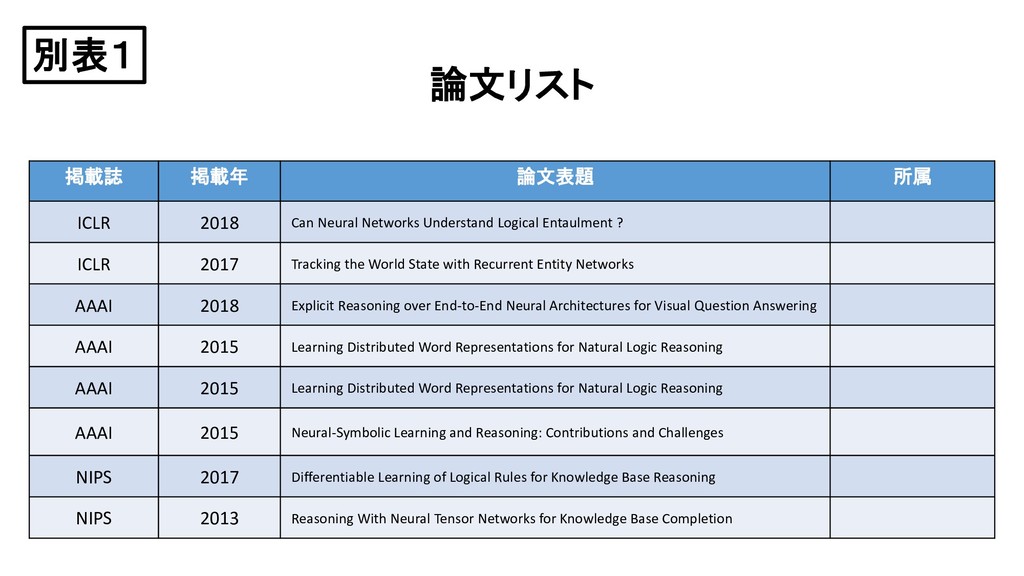
Understand Logical Entaulment ? ICLR 2017 Tracking the World State with Recurrent Entity Networks AAAI 2018 Explicit Reasoning over End-to-End Neural Architectures for Visual Question Answering AAAI 2015 Learning Distributed Word Representations for Natural Logic Reasoning AAAI 2015 Learning Distributed Word Representations for Natural Logic Reasoning AAAI 2015 Neural-Symbolic Learning and Reasoning: Contributions and Challenges NIPS 2017 Differentiable Learning of Logical Rules for Knowledge Base Reasoning NIPS 2013 Reasoning With Neural Tensor Networks for Knowledge Base Completion 別表1
for Semantic Image Interpretation IJCAI 2017 Logic Tensor Networks for Semantic Image Interpretation IJCAI 2016 Learning First-Order Logic Embeddings via Matrix Factorization IJCAI 2011 A Neural-Symbolic Cognitive Agent for Online Learning and Reasoning ACL 2016 Language to Logical Form with Neural Attention CoCoNIPS 2015 Relational knowledge extraction from neural networks COLING 2018 An Interpretable Reasoning Network for Multi-Relation Question Answering Nature 2017 Quantum Enhanced Inference in Markov Logic Networks 別表1
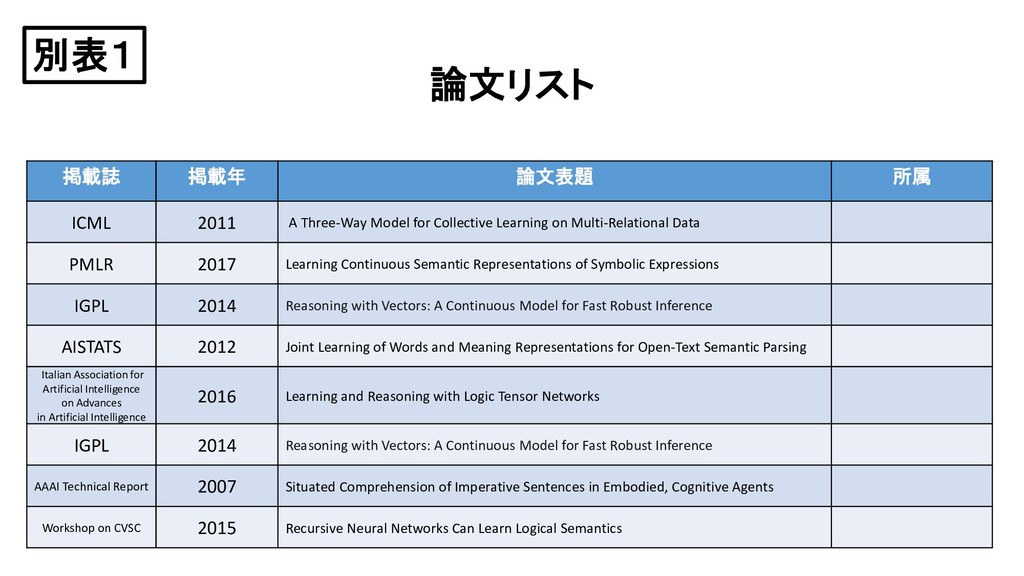
for Collective Learning on Multi-Relational Data PMLR 2017 Learning Continuous Semantic Representations of Symbolic Expressions IGPL 2014 Reasoning with Vectors: A Continuous Model for Fast Robust Inference AISTATS 2012 Joint Learning of Words and Meaning Representations for Open-Text Semantic Parsing Italian Association for Artificial Intelligence on Advances in Artificial Intelligence 2016 Learning and Reasoning with Logic Tensor Networks IGPL 2014 Reasoning with Vectors: A Continuous Model for Fast Robust Inference AAAI Technical Report 2007 Situated Comprehension of Imperative Sentences in Embodied, Cognitive Agents Workshop on CVSC 2015 Recursive Neural Networks Can Learn Logical Semantics 別表1
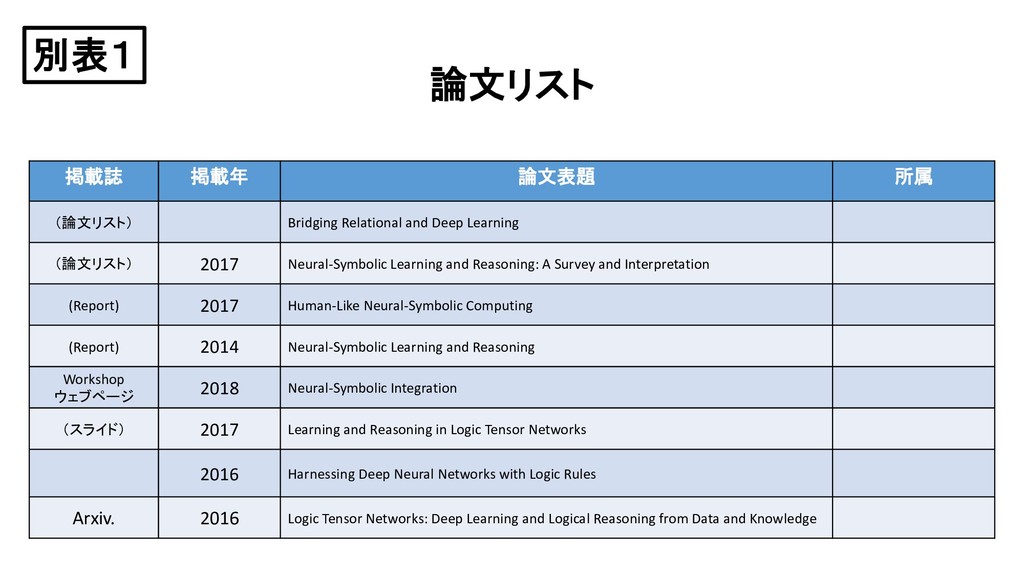
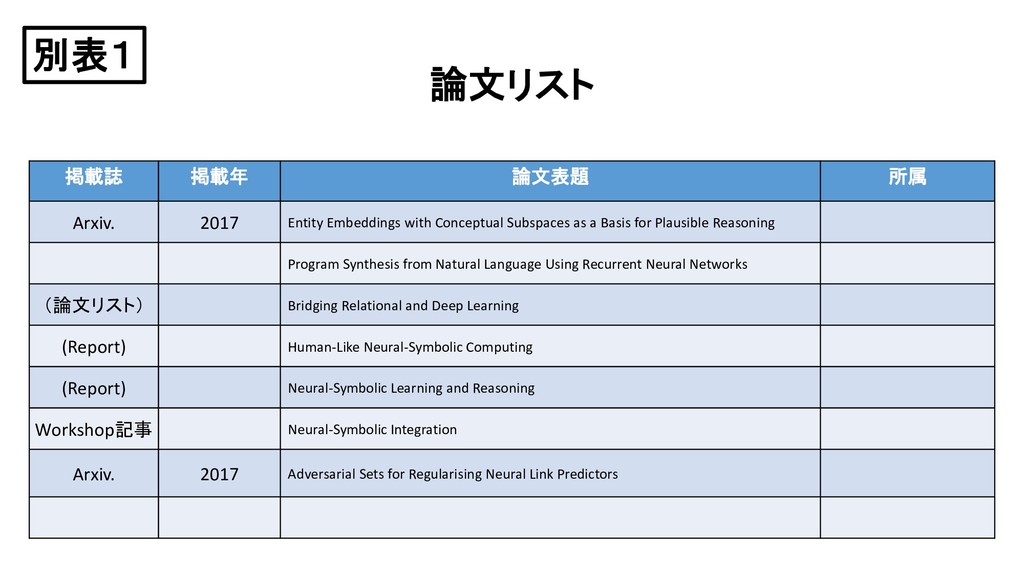
Learning (論文リスト) 2017 Neural-Symbolic Learning and Reasoning: A Survey and Interpretation (Report) 2017 Human-Like Neural-Symbolic Computing (Report) 2014 Neural-Symbolic Learning and Reasoning Workshop ウェブページ 2018 Neural-Symbolic Integration (スライド) 2017 Learning and Reasoning in Logic Tensor Networks 2016 Harnessing Deep Neural Networks with Logic Rules Arxiv. 2016 Logic Tensor Networks: Deep Learning and Logical Reasoning from Data and Knowledge 別表1
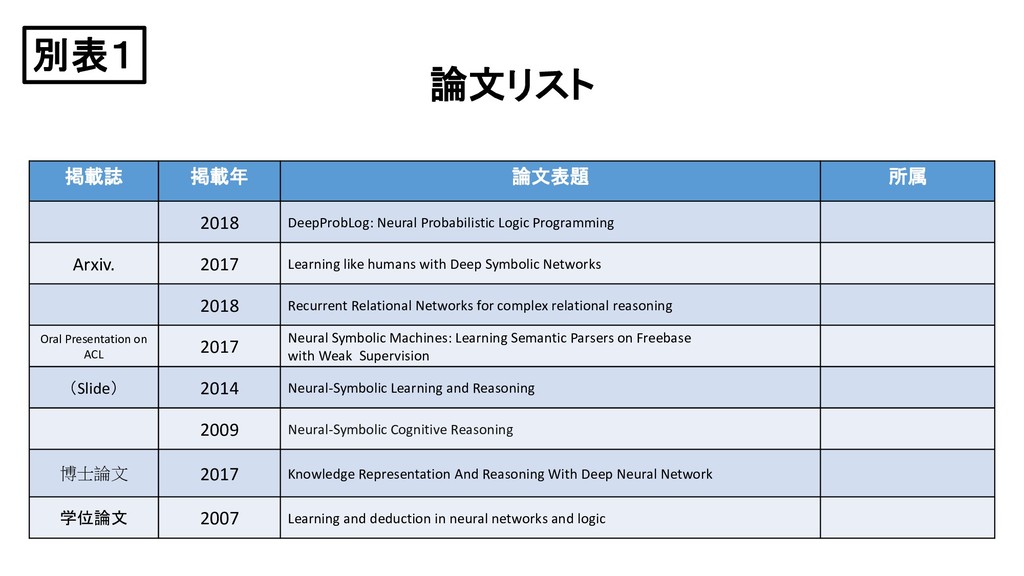
Programming Arxiv. 2017 Learning like humans with Deep Symbolic Networks 2018 Recurrent Relational Networks for complex relational reasoning Oral Presentation on ACL 2017 Neural Symbolic Machines: Learning Semantic Parsers on Freebase with Weak Supervision (Slide) 2014 Neural-Symbolic Learning and Reasoning 2009 Neural-Symbolic Cognitive Reasoning 博士論文 2017 Knowledge Representation And Reasoning With Deep Neural Network 学位論文 2007 Learning and deduction in neural networks and logic 別表1
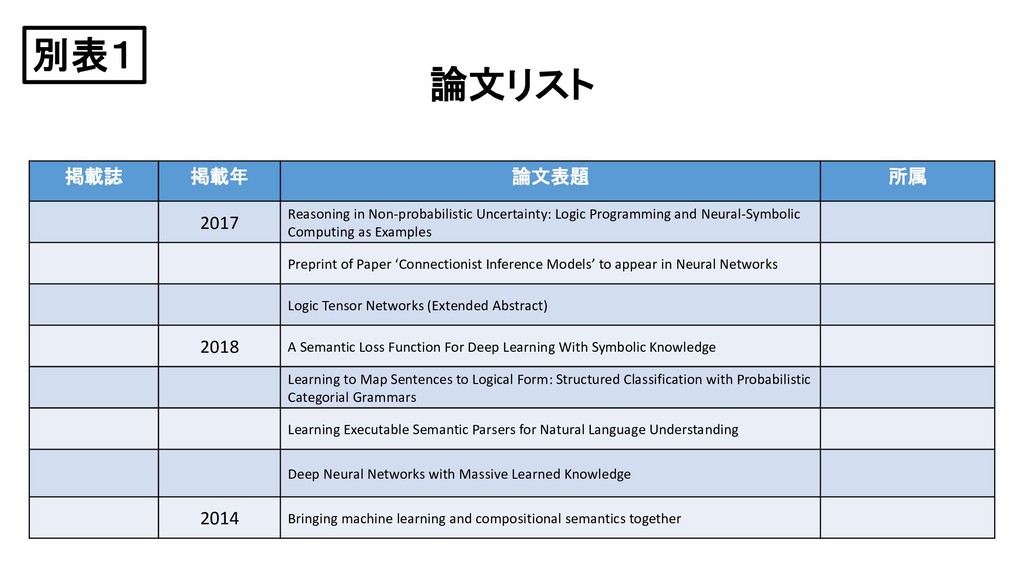
Logic Programming and Neural-Symbolic Computing as Examples Preprint of Paper ‘Connectionist Inference Models’ to appear in Neural Networks Logic Tensor Networks (Extended Abstract) 2018 A Semantic Loss Function For Deep Learning With Symbolic Knowledge Learning to Map Sentences to Logical Form: Structured Classification with Probabilistic Categorial Grammars Learning Executable Semantic Parsers for Natural Language Understanding Deep Neural Networks with Massive Learned Knowledge 2014 Bringing machine learning and compositional semantics together 別表1
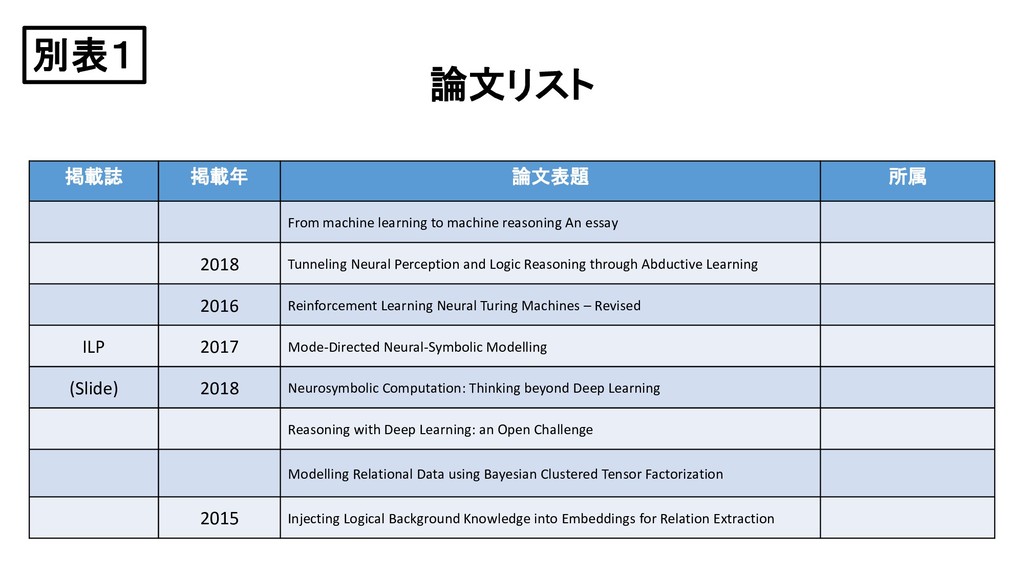
reasoning An essay 2018 Tunneling Neural Perception and Logic Reasoning through Abductive Learning 2016 Reinforcement Learning Neural Turing Machines – Revised ILP 2017 Mode-Directed Neural-Symbolic Modelling (Slide) 2018 Neurosymbolic Computation: Thinking beyond Deep Learning Reasoning with Deep Learning: an Open Challenge Modelling Relational Data using Bayesian Clustered Tensor Factorization 2015 Injecting Logical Background Knowledge into Embeddings for Relation Extraction 別表1
Conceptual Subspaces as a Basis for Plausible Reasoning Program Synthesis from Natural Language Using Recurrent Neural Networks (論文リスト) Bridging Relational and Deep Learning (Report) Human-Like Neural-Symbolic Computing (Report) Neural-Symbolic Learning and Reasoning Workshop記事 Neural-Symbolic Integration Arxiv. 2017 Adversarial Sets for Regularising Neural Link Predictors 別表1
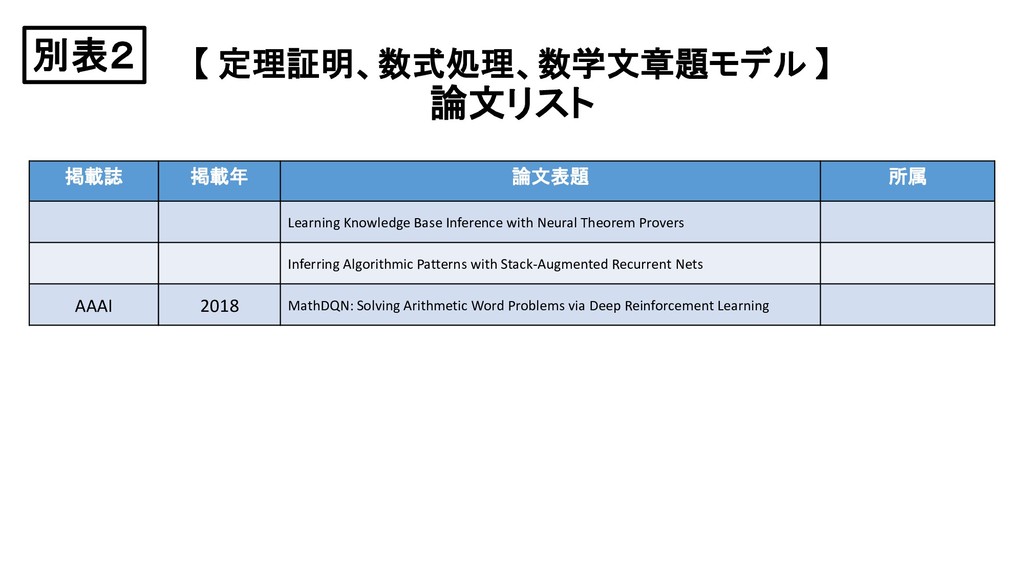
Base Inference with Neural Theorem Provers Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets AAAI 2018 MathDQN: Solving Arithmetic Word Problems via Deep Reinforcement Learning 別表2
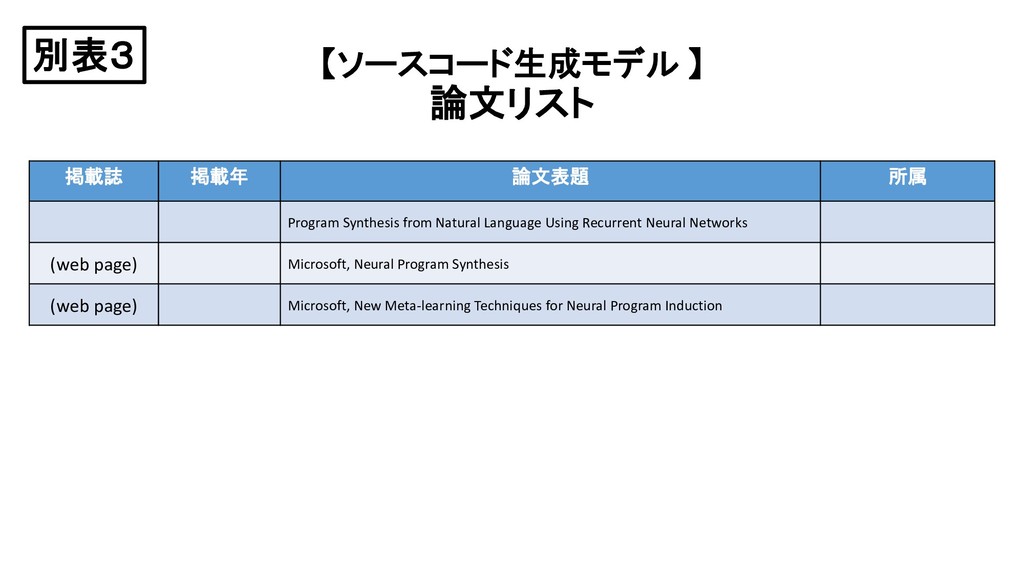
Programmer-Interpreters ICLR 2017 DEEPCODER: Learning To Write Programs ICLR 2018 Neural Sketch Learning For Conditional Program Generation NIPS 2017 Neural Program Meta-Induction AAAI 2016 Convolutional neural networks over tree structures for programming language processing JMLR 2017 RobustFill: Neural Program Learning under Noisy I/O 2017 Inferring and Executing Programs for Visual Reasoning 別表3
Natural Language Using Recurrent Neural Networks (web page) Microsoft, Neural Program Synthesis (web page) Microsoft, New Meta-learning Techniques for Neural Program Induction 別表3
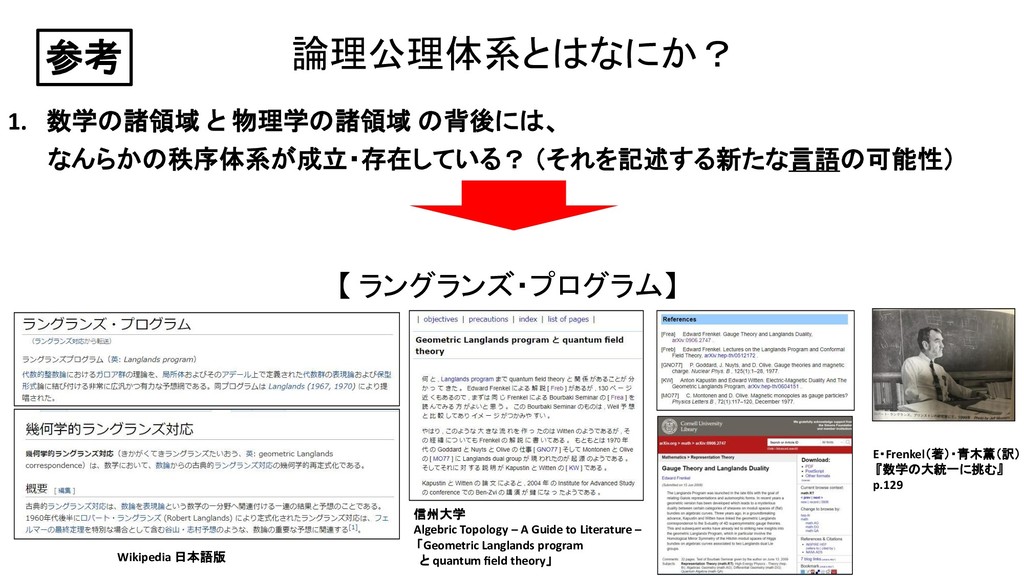
参考 信州大学 Algebric Topology – A Guide to Literature – 「Geometric Langlands program と quantum field theory」 Wikipedia 日本語版 E・Frenkel(著)・青木薫(訳) 『数学の大統一に挑む』 p.129
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![複数の文章・文書に散らばる断片的な知識の手がかりを、 互いに論理的につなぎあわせて論理推論する精度を競う 技術コンテスト 及び 研究用データセット [ACL 2018] Johannes Welbl et.al.,](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_186.jpg){kind=link}
![複数の文章・文書に散らばる断片的な知識の手がかりを、 互いに論理的につなぎあわせて論理推論する精度を競う 技術コンテスト 及び 研究用データセット [EMNLP 2005] Xiaoqiang Luo, On](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_187.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Graph Network による物体や事物間の連関関係 の特徴表現獲得(学習)と転移学習の実現 [Arxiv. 2018] Peter W. Battaglia et.al,](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_193.jpg){kind=link}
![[Arxiv. 2018] Peter W. Battaglia et.al, Relational inductive biases, deep](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_194.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Predictive Coding とは? 【 参考 】 [ ICLR 2017 ]](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_224.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DeepMind 社がとる進路の『予想』 アプローチ A. を取るのではないか? [ 「予想」の根拠 ] [ 根拠1]](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_241.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![中村研究室 [JSAI 2013] Muhammad Fadlilほか 「多層マルチモーダルLDAを用いた人の動きと物体の統合的概念の形成」 人工知能学会, 2013](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_319.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
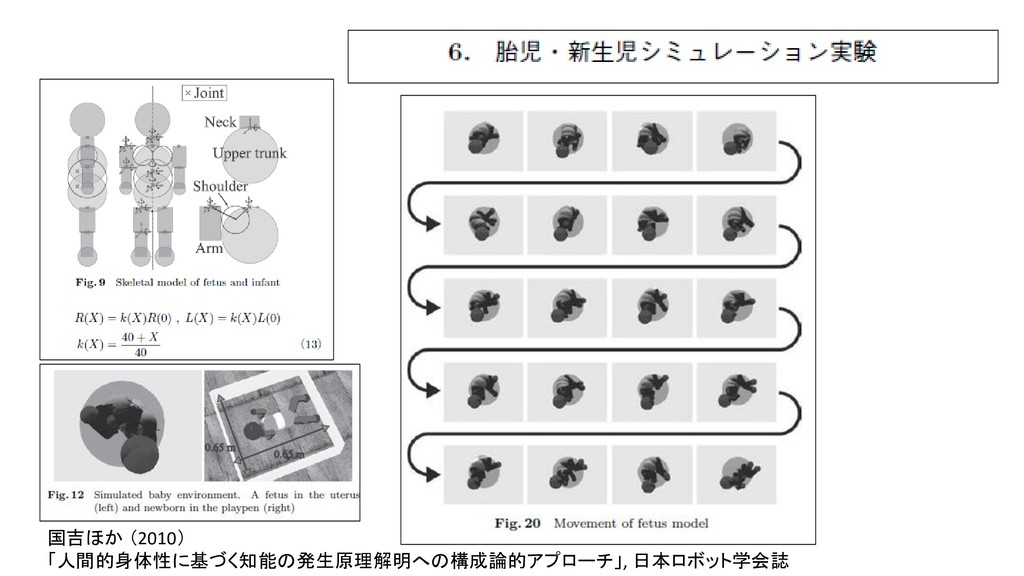{kind=link}
{kind=link}
{kind=link}
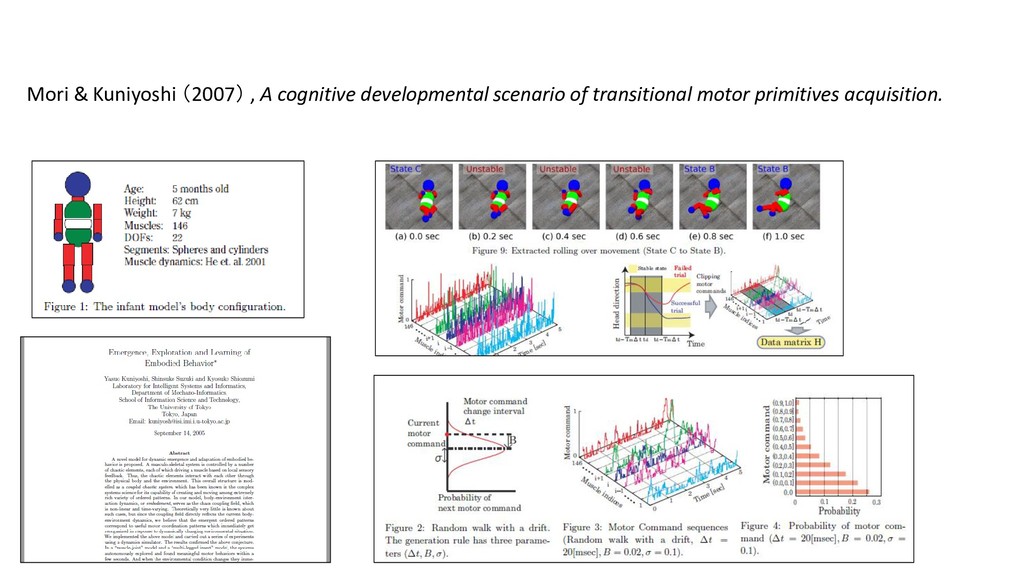{kind=link}
{kind=link}
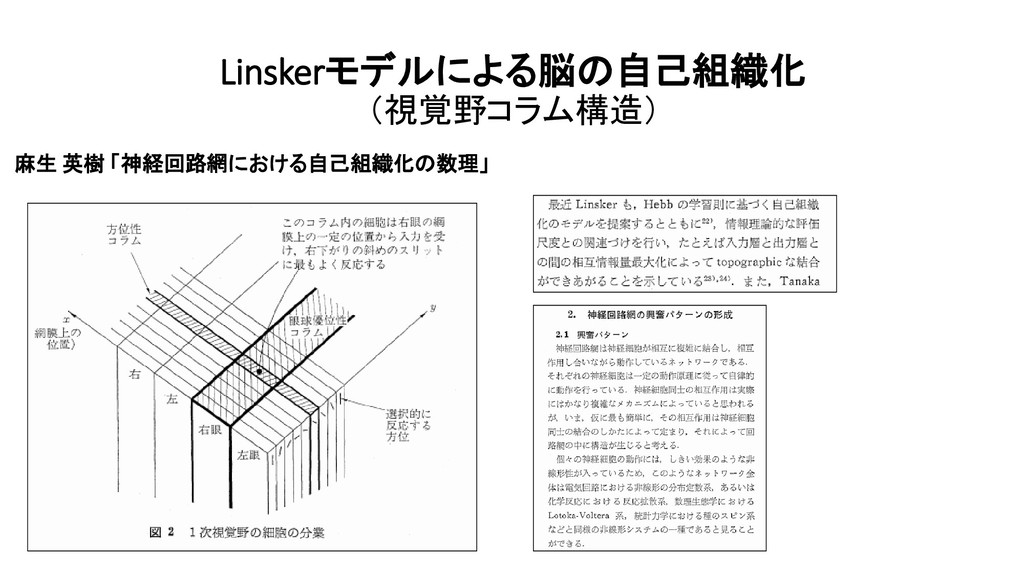
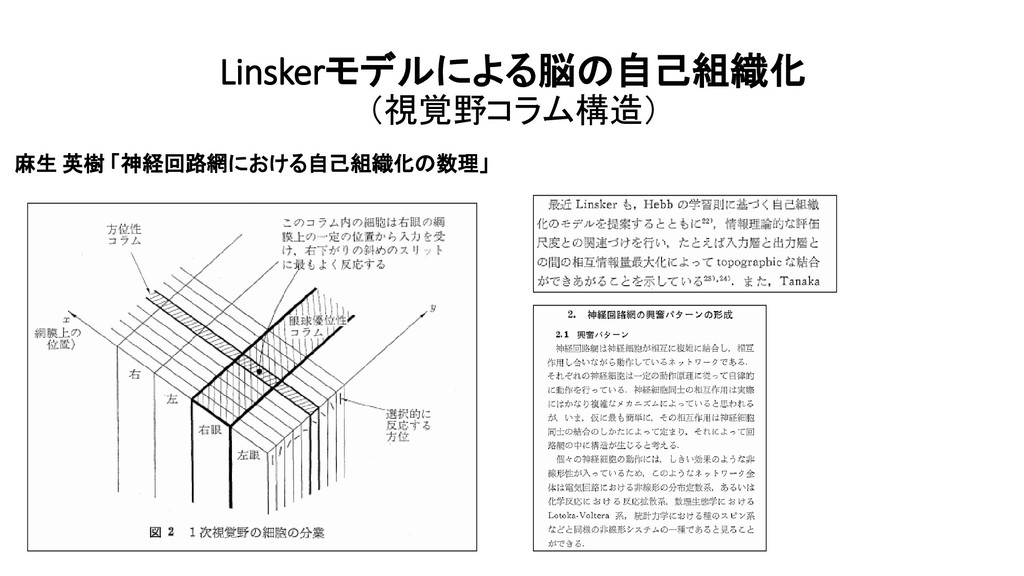
![Linskerモデルによる脳の自己組織化 (視覚野コラム構造) Ralph Linsker [1998] 【 解説 】 浅川 伸一](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_370.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
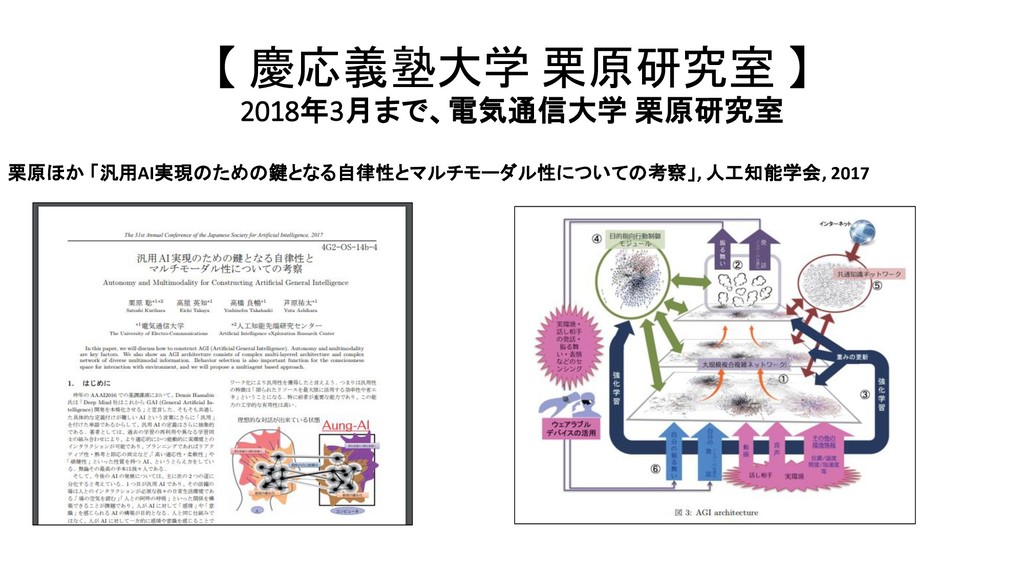{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
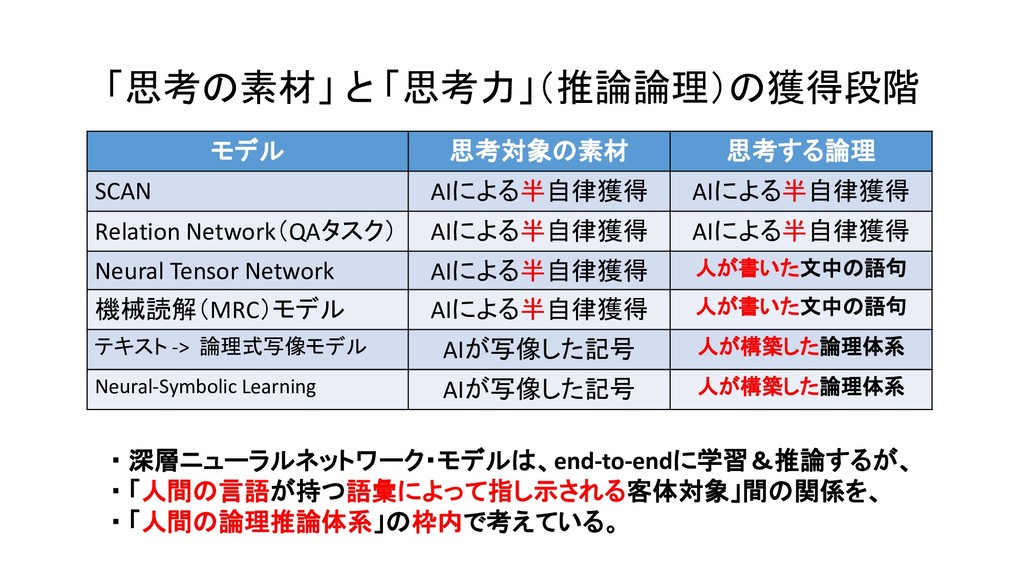
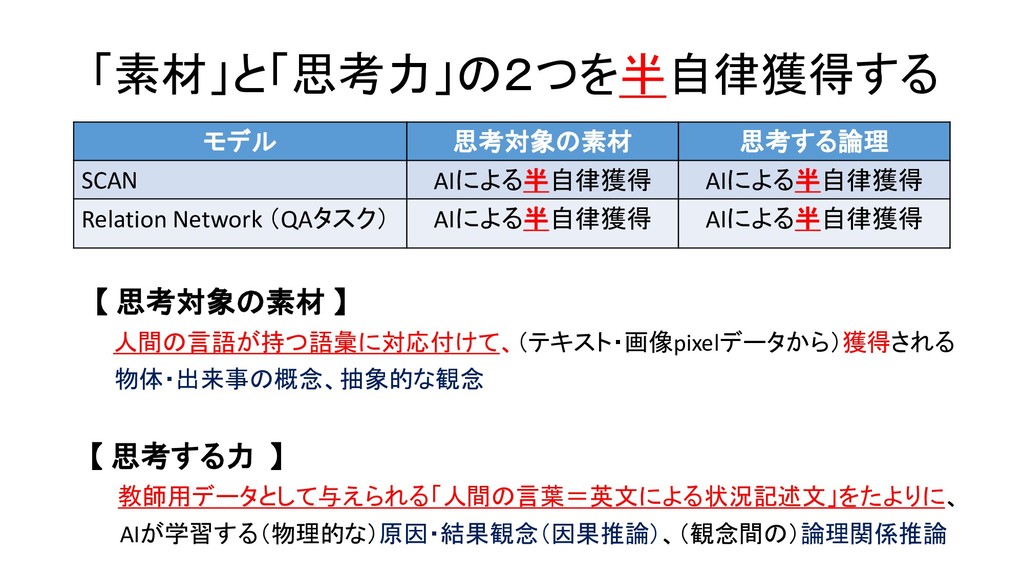
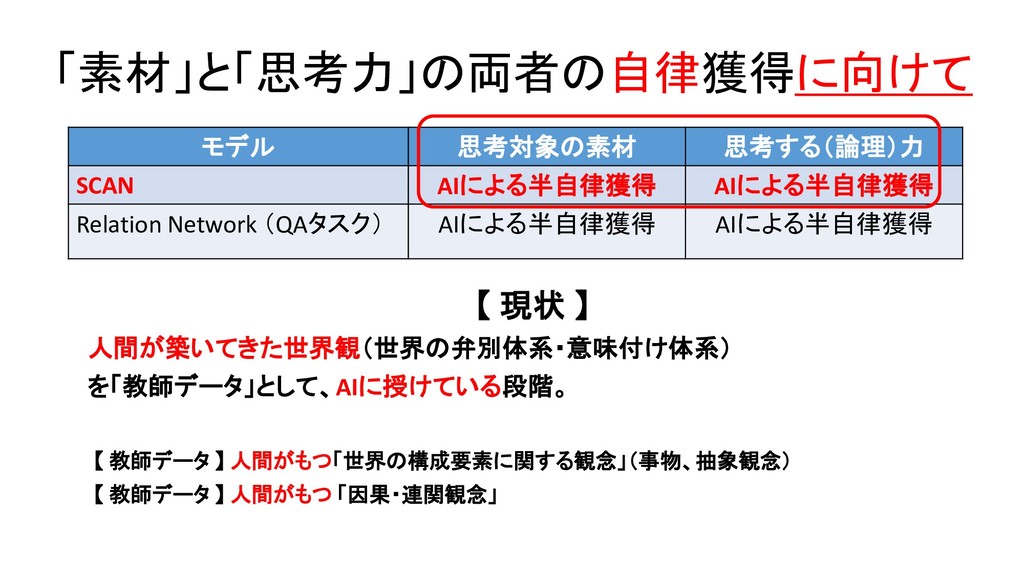
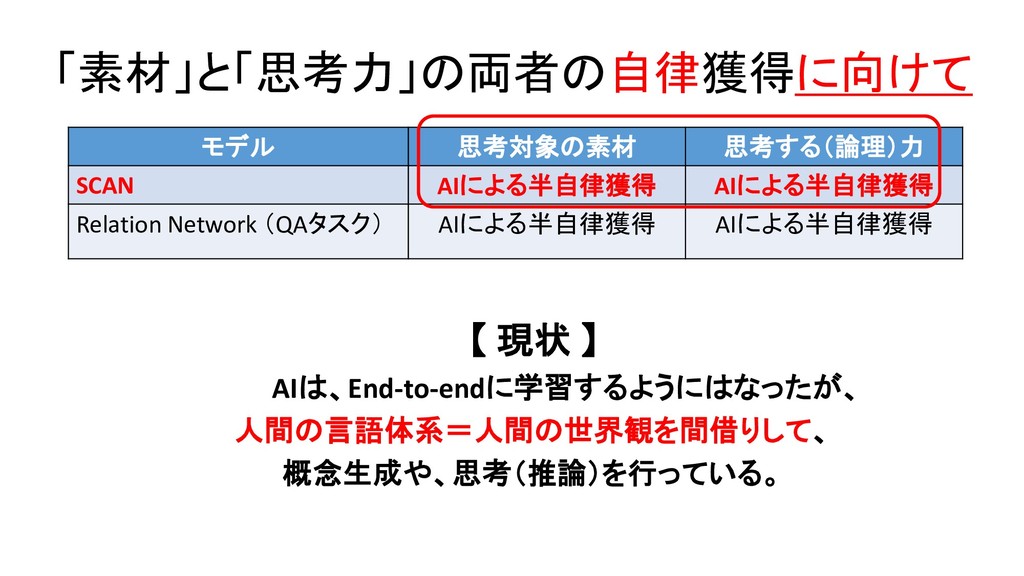
![論文・モデル 思考の素材(対象項) (事物概念・抽象概念) 思考する論理 (関係概念・推論規則) Neural Tensor Network 人が定義した[主語(S)、述語(P)、目的語・補語(O)]のTriple知識 データを学習し、新しいデータを記述するS-P-O記号表現(人の言](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_412.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(出典) SlideShare Deep Learning JP 「[Dl輪読会]A simple neural network module](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_432.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Linskerモデルによる脳の自己組織化 (視覚野コラム構造) Ralph Linsker [1998] 【 解説 】 浅川 伸一](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_443.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
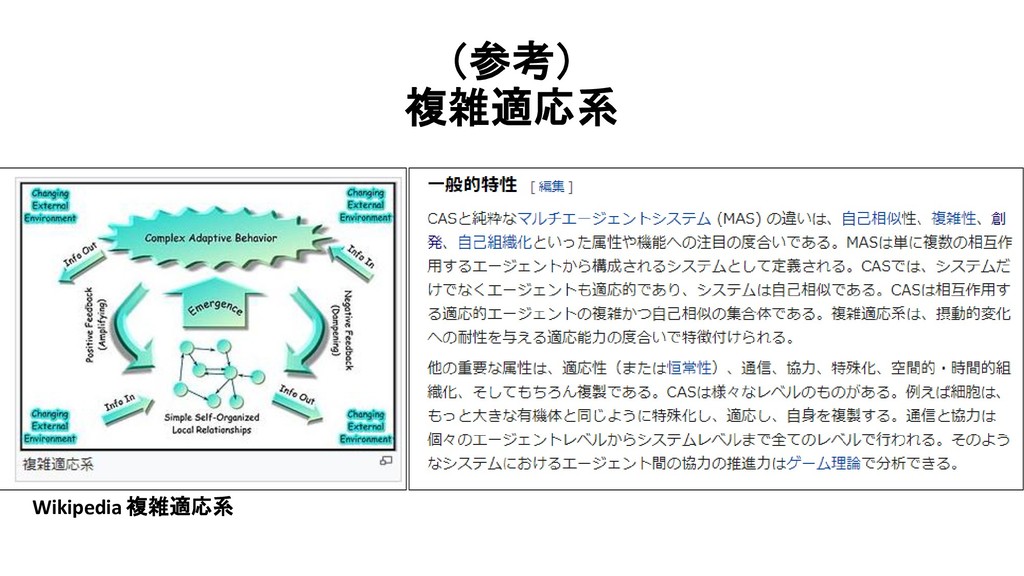
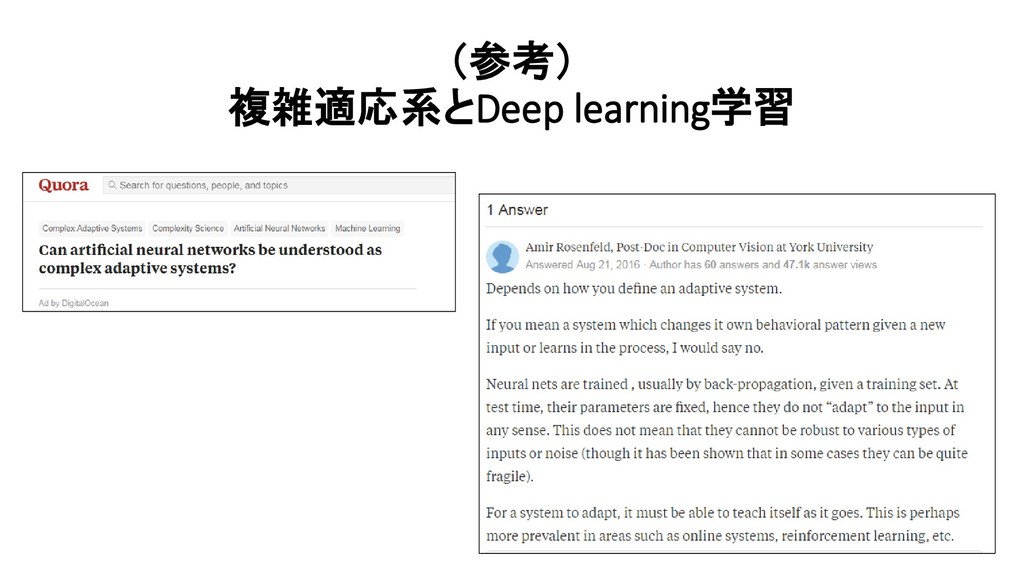
![北村[1995]による定義 北村 新三 「創発的機能形成のシステム理論に向けて」, 計測と制御, Vol.37, 1995 「自律的にふるまう個体(要素)間および環境との間の局所的な相互作用 が大域的な秩序をボトムアップ的に発現し、他方、そのように生じた 秩序が個体のふるまいをトップダウン的に拘束するという双方向の動的](https://files.speakerdeck.com/presentations/29161b9fdca94e099d52bdf2e6609746/slide_453.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}