Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2026年度新卒技術研修 サイバーエージェントのデータベース 活用事例とパフォーマンス調査入門
Search
CyberAgent
PRO
April 10, 2026
Technology
12k
10
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2026年度新卒技術研修 サイバーエージェントのデータベース 活用事例とパフォーマンス調査入門
CyberAgent
PRO
April 10, 2026
More Decks by CyberAgent
See All by CyberAgent
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
36
Databricks 導入から Genie 活用まで、全部やった話
cyberagentdevelopers
PRO
0
800
専任DEゼロからの データ基盤構築 - Databricks x IaC x AIで 進める「データの民主化」-
cyberagentdevelopers
PRO
0
480
「エンジニア進化論」2028年の開発完全自動化、エンジニアはどう進化するか
cyberagentdevelopers
PRO
9
8.8k
NAB Show 2026 動画技術関連レポート / NAB Show 2026 Report
cyberagentdevelopers
PRO
0
310
Local LLM Meetup #1 Opening
cyberagentdevelopers
PRO
0
430
LocalLLMで機密データを匿名化したい
cyberagentdevelopers
PRO
1
440
Vibe Fine-Tuning Version 2 — RunPod SSH で安く学習してみた
cyberagentdevelopers
PRO
0
430
マッチングアプリにおけるユーザー構成の変化は、事業KPIにどう影響しているのか
cyberagentdevelopers
PRO
1
230
Other Decks in Technology
See All in Technology
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
12
8.7k
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
14
2.1k
DatabricksにおけるMCPソリューション
taka_aki
1
280
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
480
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
250
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
920
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
Kaggleで成長するために意識したこと
prgckwb
2
420
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
110
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
130
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
230
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
320
Featured
See All Featured
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
The agentic SEO stack - context over prompts
schlessera
0
850
How to Ace a Technical Interview
jacobian
281
24k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Navigating Team Friction
lara
192
16k
How to make the Groovebox
asonas
2
2.3k
Writing Fast Ruby
sferik
630
63k
Transcript
2026年度新卒技術研修 サイバーエージェントのデータベース 活用事例とパフォーマンス調査入門 (外部公開版)
はじめに 1. データベース管理システムの種類 2. 社内でよく採用されているデータベースの事例 3. データベース運用で起きやすい問題とその対応事例 4. データベースのパフォーマンス悪化時の初動調査手法
はじめに
鬼海 雄太 Yuta Kikai •メディア統括本部サービスリライアビリティグループ (メディア事業 横断SRE組織) 2012年 サイバーエージェント中途入社 コミュニティサービスやソーシャルゲームの インフラやデータベースを担当
現在は横断SRE組織である現チームで AmebaのDBREとして従事 チームブログであるSRGポータルに毎月記事執筆中 https://ca-srg.dev 2025年~ AWS Community Builders (Category: Data)
昨年のデータベース新卒研修資料を マイナーチェンジ
本日の研修のゴール •データベース管理システム(DBMS)には多くの種類があることを知る •サイバーエージェント内でよく採用されているデータベースを知り、 なぜそれが採用されているかなんとなく理解できている •データベースのパフォーマンス悪化時の初動調査手法がわかる
本日の研修で扱わない部分 •SQLの書き方 •テーブル設計 •OLAP(オンライン分析処理)のデータベース
現時点で完全理解できなくてOK チームに配属後、今日の内容を思い出して資料を活用してください
データベース管理システム(DBMS)の種類
そもそも、なぜデータベースを学ぶのか • データベースはアプリケーションと比較するとライフサイクルが長い あとから変更しにくい。社内でも20年超えのサービスが出てきている 要件に合った適切なデータベースの選定が重要 • データベースはサービスの根幹である データベースが止まると事業が止まる • 重要であるが、普段は意識されづらい
今日からちょっと意識してみましょう
基本用語解説
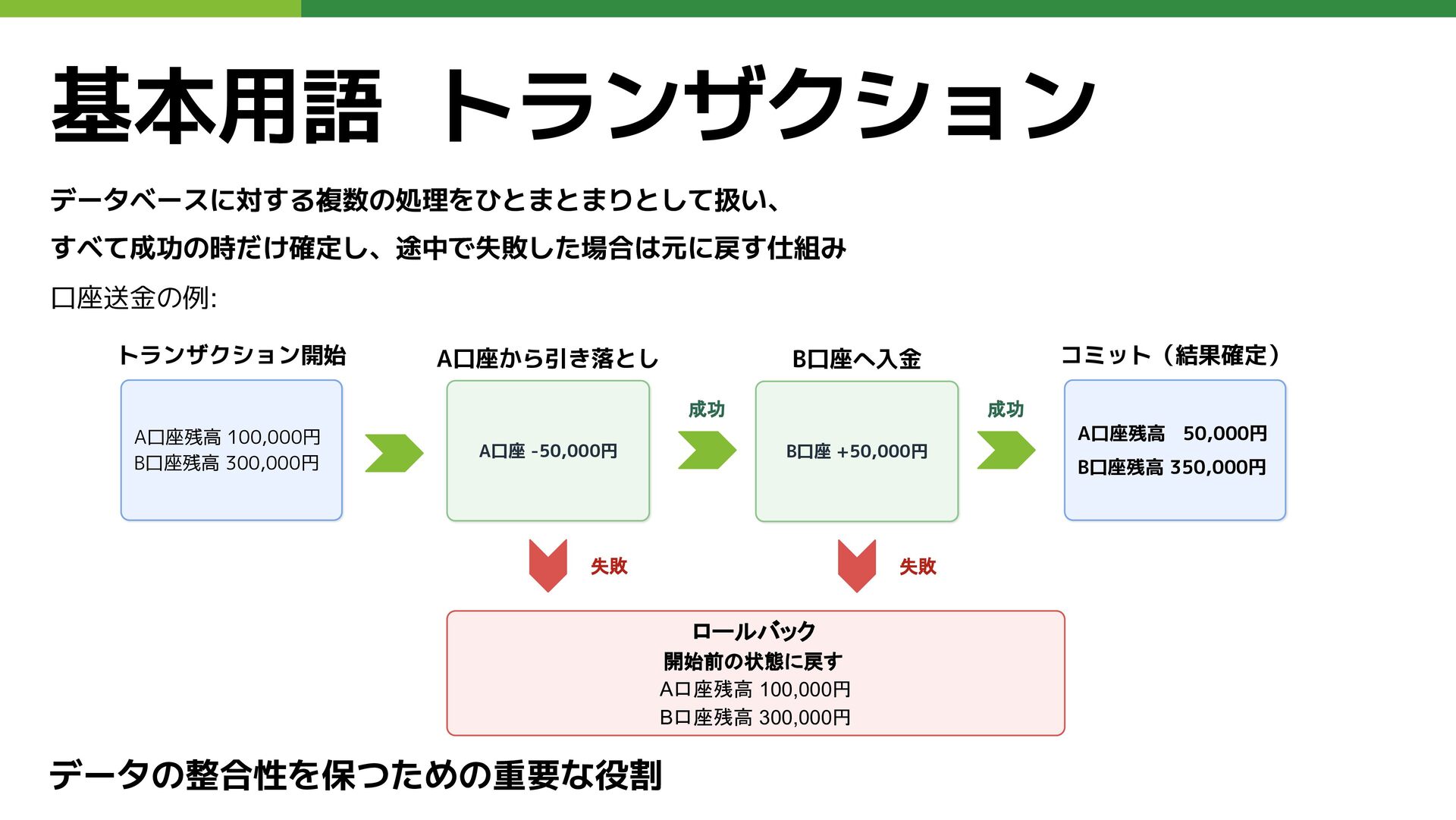
基本用語 トランザクション データベースに対する複数の処理をひとまとまりとして扱い、 すべて成功の時だけ確定し、途中で失敗した場合は元に戻す仕組み データの整合性を保つための重要な役割 口座送金の例: トランザクション開始 A口座残高 100,000円 B口座残高
300,000円 成功 失敗 ロールバック 開始前の状態に戻す A口座残高 100,000円 B口座残高 300,000円 A口座 -50,000円 B口座 +50,000円 成功 A口座残高 50,000円 B口座残高 350,000円 失敗 A口座から引き落とし B口座へ入金 コミット(結果確定)
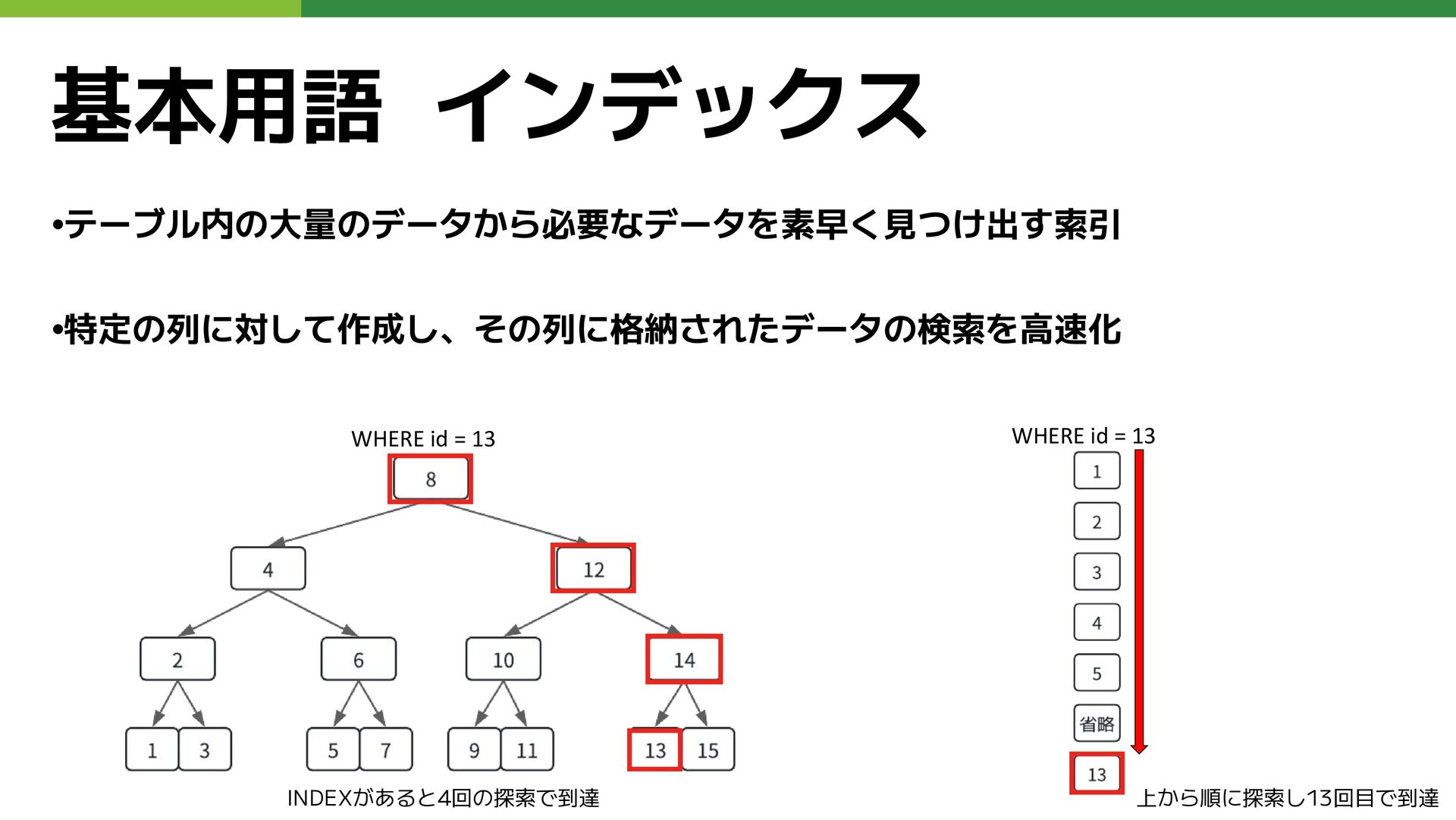
基本用語 インデックス •テーブル内の大量のデータから必要なデータを素早く見つけ出す索引 •特定の列に対して作成し、その列に格納されたデータの検索を高速化 WHERE id = 13 WHERE id
= 13 INDEXがあると4回の探索で到達 上から順に探索し13回目で到達
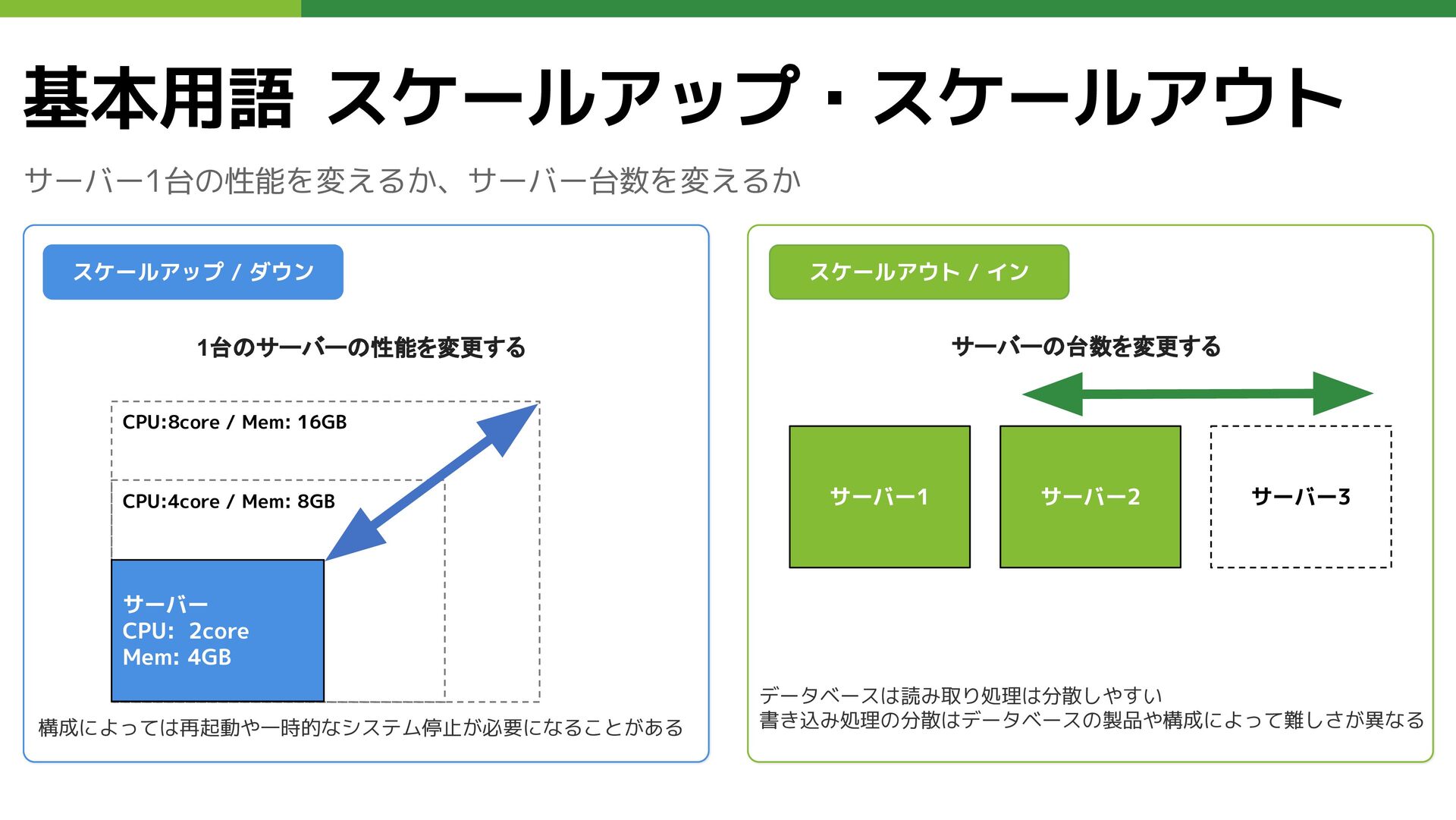
基本用語 スケールアップ・スケールアウト サーバー1台の性能を変えるか、サーバー台数を変えるか スケールアップ / ダウン 1台のサーバーの性能を変更する 構成によっては再起動や一時的なシステム停止が必要になることがある スケールアウト サーバーの台数を変更する
サーバー CPU: 2core Mem: 4GB CPU:4core / Mem: 8GB CPU:8core / Mem: 16GB スケールアウト / イン サーバー1 サーバー2 サーバー3 データベースは読み取り処理は分散しやすい 書き込み処理の分散はデータベースの製品や構成によって難しさが異なる
データベースとは
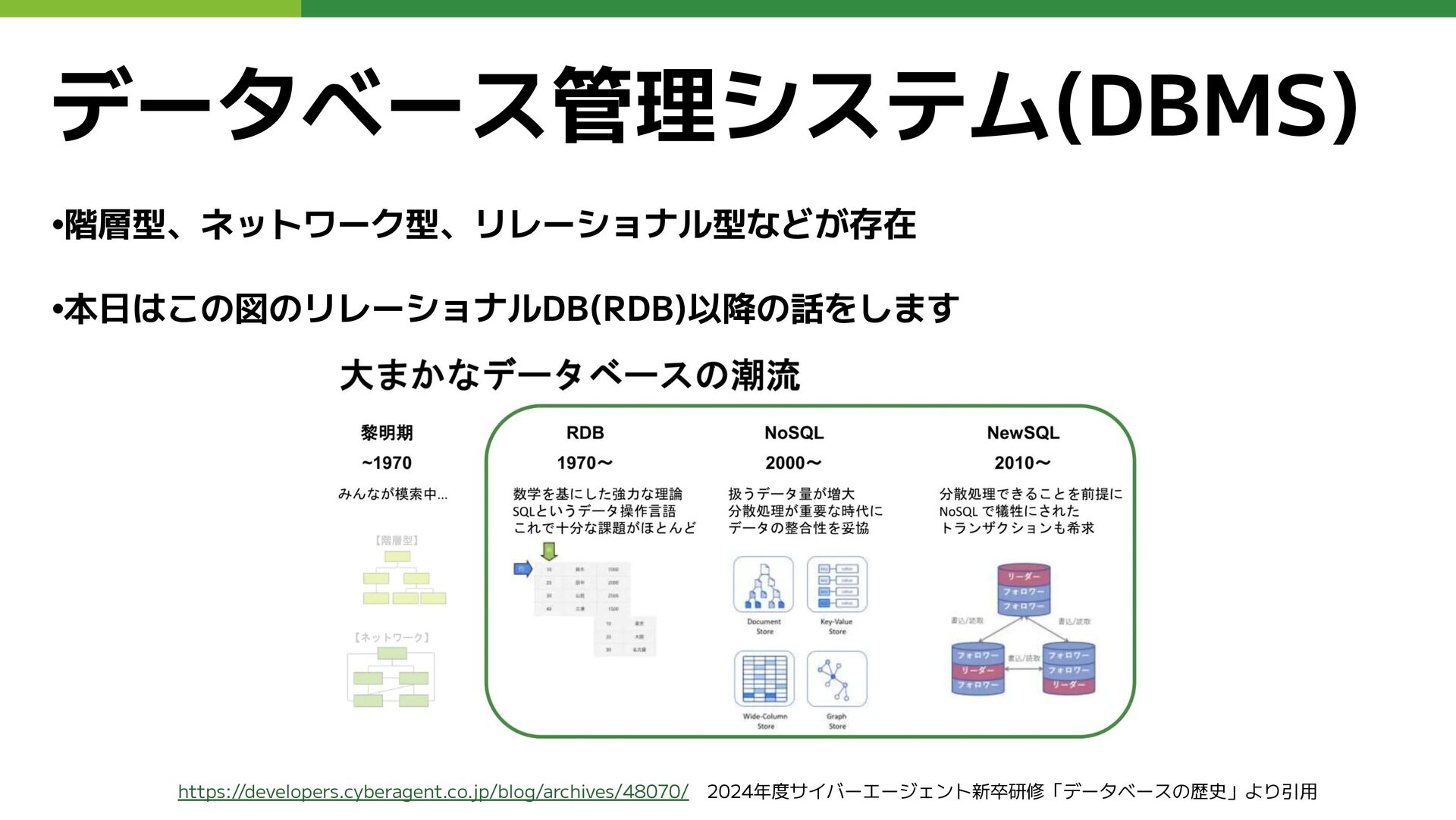
データベース管理システム(DBMS) •階層型、ネットワーク型、リレーショナル型などが存在 •本日はこの図のリレーショナルDB(RDB)以降の話をします https://developers.cyberagent.co.jp/blog/archives/48070/ 2024年度サイバーエージェント新卒研修「データベースの歴史」より引用
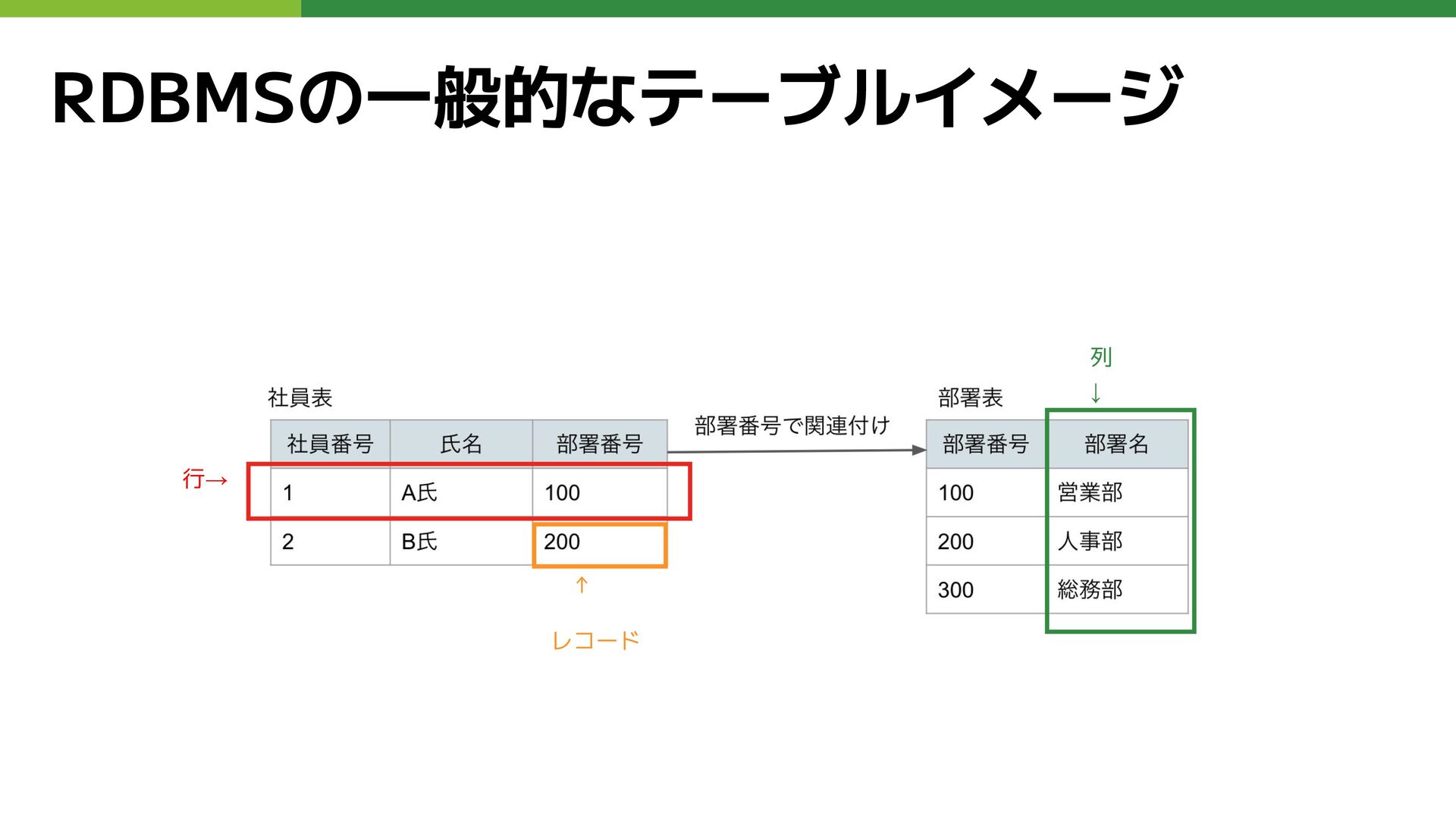
リレーショナルデータベース •表(テーブル)を利用してデータを格納 テーブルは行( row )と列( column )で構成 • テーブル同士が 関係・関連(
リレーション )をもつ • SQL( Structured Query Language )というデータ操作言語でデータを管理 • データの一貫性、整合性を担保するために厳格な制約 • 代表的なリレーショナルデータベース管理システム( RDBMS ) Oracle Database, MySQL , SQL Server , PostgreSQL
RDBMSの一般的なテーブルイメージ 行→ 列 ↓ ↑ レコード
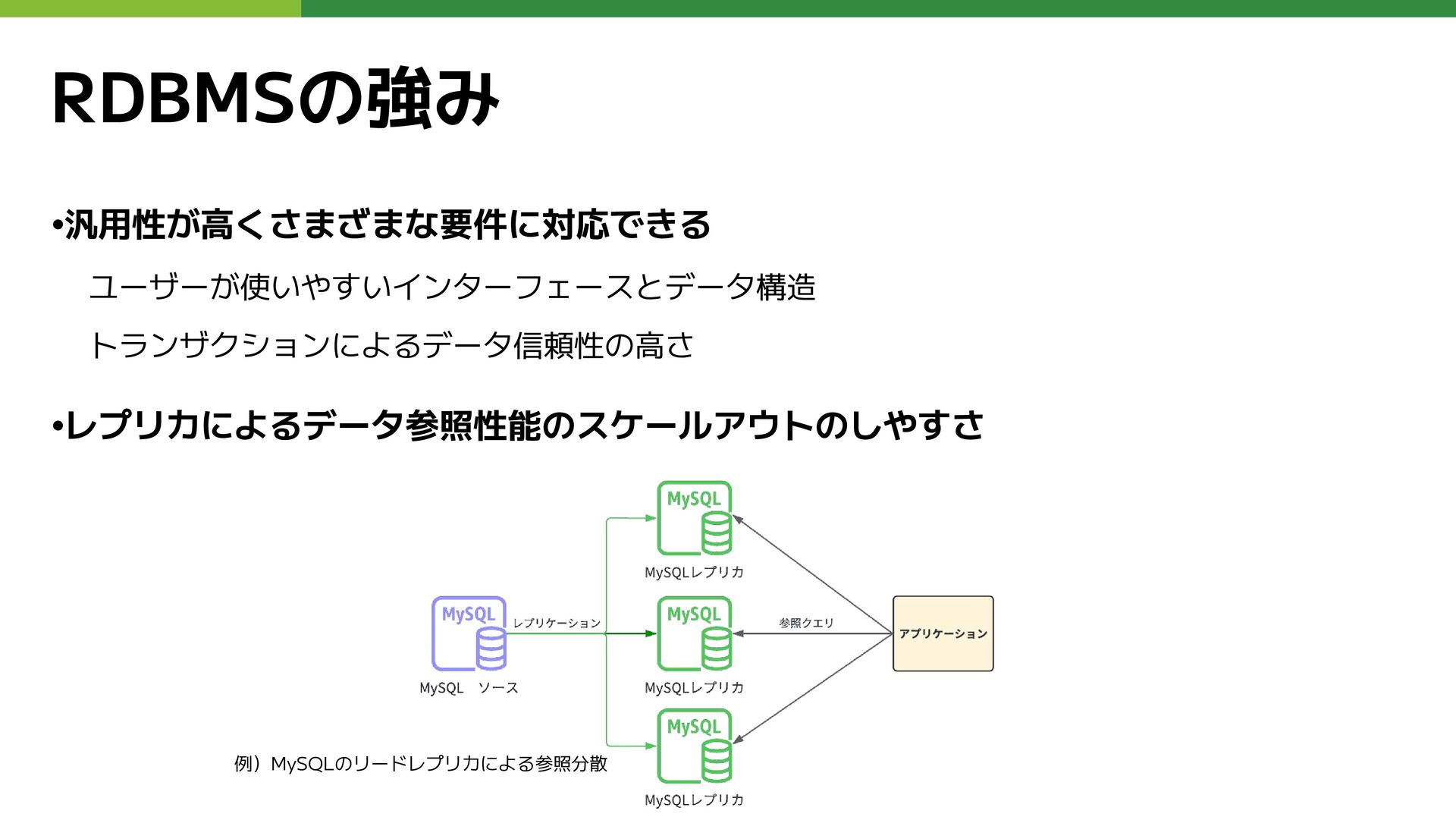
RDBMSの強み •汎用性が高くさまざまな要件に対応できる ユーザーが使いやすいインターフェースとデータ構造 トランザクションによるデータ信頼性の高さ •レプリカによるデータ参照性能のスケールアウトのしやすさ 例)MySQLのリードレプリカによる参照分散
RDBMSの弱み •データの書き込み性能の拡張が難しい 書き込み性能の拡張には水平分割や垂直分割などをアプリケーション側で実装する必要がある ユーザー数やデータ量でシステム規模を伸縮させづらい •要件の変化で求められる性能が変わってきた 単純なデータへの大量アクセス、非構造データ、グラフの取り扱いなど ※近年のRDBMSの進化でこのあたりの強化はされてきている場合もあり
データの書き込み性能の拡張方法 •テーブルの水平分割 •テーブルの垂直分割 id ユーザー名 職業 レベル 1 鈴木 A子
戦士 10 2 佐藤 B太 僧侶 3 3 山田 C助 勇者 7 4 高橋 D次 戦士 22 id ユーザー名 職業 レベル 1 鈴木 A子 戦士 10 3 山田 C助 勇者 7 id ユーザー名 職業 レベル 2 佐藤 B太 僧侶 3 4 高橋 D次 戦士 22 id ユーザー名 職業 レベル 1 鈴木 A子 戦士 10 2 佐藤 B太 僧侶 3 3 山田 C助 勇者 7 4 高橋 D次 戦士 22 id ユーザー名 職業 1 鈴木 A子 戦士 2 佐藤 B太 僧侶 3 山田 C助 勇者 4 高橋 D次 戦士 lv_id uid レベル 1 1 10 2 2 3 3 3 7 4 4 22 同じテーブルをid単位で分割 テーブル単位で分割 頻繁に書き換わりそうなデータを分離
NoSQL •Not Only SQLの略と言われている SQLに囚われない 定義は曖昧だが非リレーショナル・分散型・水平拡張可能などの特徴を持つ製品が多い • NoSQLには様々な種類がある RDBMSで課題になっていた点を独自のアプローチで解決を目指した
NoSQLのデータモデルによる分類の一例 分類 特徴と強み 弱み 製品の一例 キーバリュー型 - key:value単位でデータを格納 - シンプルで高速
- 同時アクセス性能が高い - データの関係性の表現が難しい - トランザクションがないのでデータの信頼 性が低い - Redis ( Valkey含む ) - Memcached - Amazon DynamoDB(※) 列指向型 - 高い書き込み性能 - 大量データを効率的に扱える - ビッグデータの分析 - 複雑なクエリが困難 - ランダムアクセスには向いていない - トランザクションサポートが限定的 - Apache Cassandra - HBase - Google Cloud Bigtable グラフ型 - 関係性の検索(ユーザー同士 の繋がりや地図の経路情報な ど)に強い - 他と比べるとデータ更新が高コスト - Neo4j - Amazon Neptune ドキュメント型 - データ型や定義を決めずに JSONなどの構造をもったドキュ メントデータを格納 - データの関係性の表現が難しい - トランザクションサポートが限定的 - MongoDB - Google Cloud Firestore - ElasticSearch ( OpenSearch含む ) - Amazon DynamoDB(※)
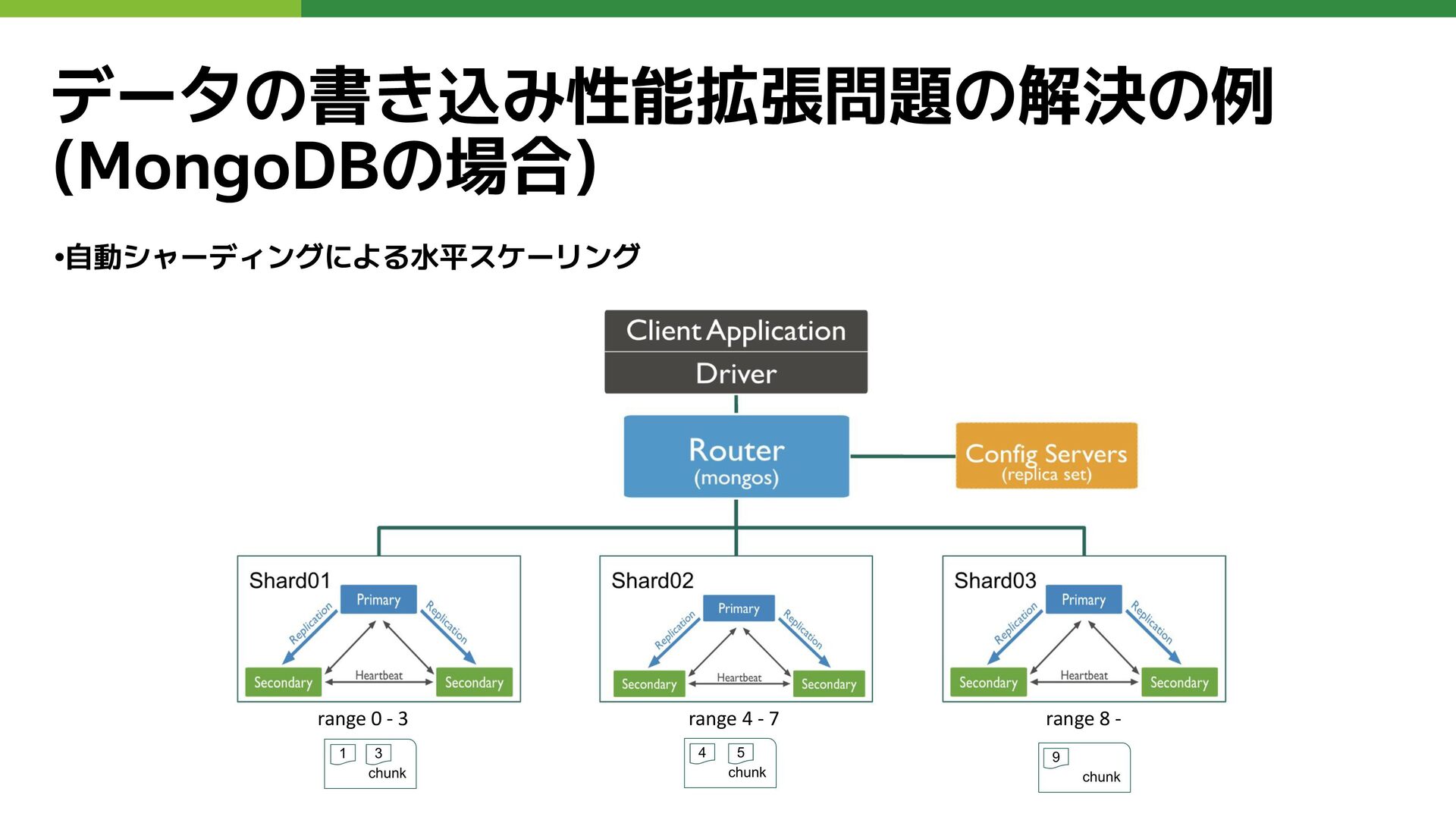
データの書き込み性能拡張問題の解決の例 (MongoDBの場合) •自動シャーディングによる水平スケーリング range 0 - 3 range 4 -
7 range 8 -
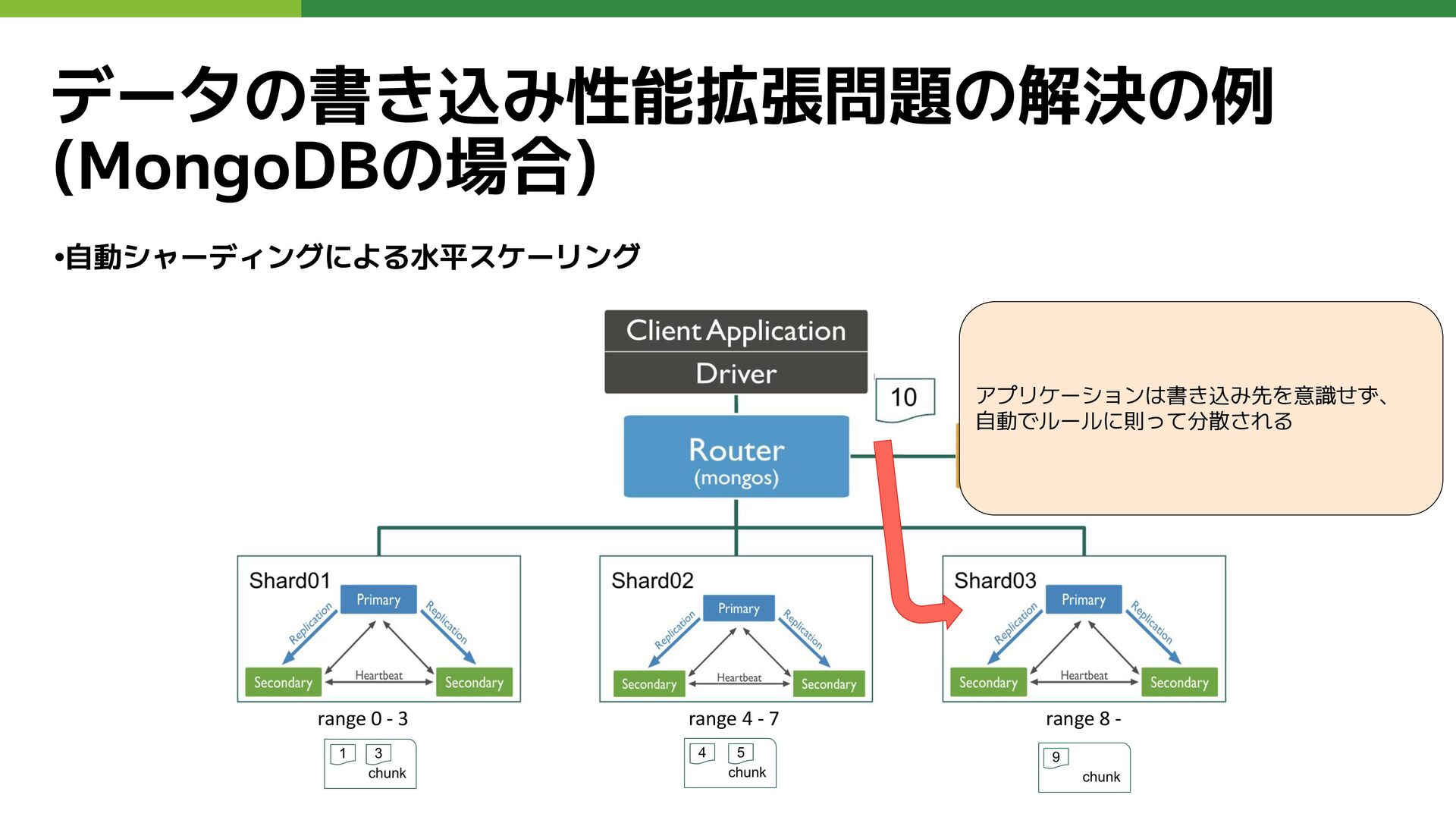
データの書き込み性能拡張問題の解決の例 (MongoDBの場合) •自動シャーディングによる水平スケーリング range 0 - 3 range 4 -
7 range 8 - アプリケーションは書き込み先を意識せず、 自動でルールに則って分散される
要件に最適なデータベースが選択できるように •RDBMSとNoSQLの強み弱みを理解して、要件に最適なデータベースを選択 •NoSQLを利用していくうちに次の要望も出てきた
NoSQLの次に求めたもの •やっぱりSQLで柔軟にデータを取り出せるのは便利だった •トランザクション機能は欲しい
NewSQLの登場 •RDBMSとNoSQLの良いところ取りをした設計 RDBMSのデータの整合性( トランザクション機能 ) NoSQLのスケーラビリティ( 分散アーキテクチャ ) • 代表的な製品
TiDB , CockroachDB , YugabyteDB , Cloud Spanner , Aurora DSQL • NewSQLの弱み 小規模なデータセットや単純なクエリではRDBMSやNoSQLにパフォーマンスで劣る可能性 複雑なアーキテクチャ
1章のまとめ • RDBMSが広く普及 RDBMSは汎用性が高いが苦手な要件もある • 要件をクリアするためのNoSQLが登場 NoSQLには個性的な特性をもった種類がある • NoSQLとRDBMSの特性を併せ持つNewSQLが登場 NewSQLが適さない要件ももちろんある。今後も適材適所は変わらない
社内でよく採用されているデータベースの事例
社内でよく採用されているデータベース 外部に公開されている一部情報 • SRE Technology Map • AI / Data
Technology Map
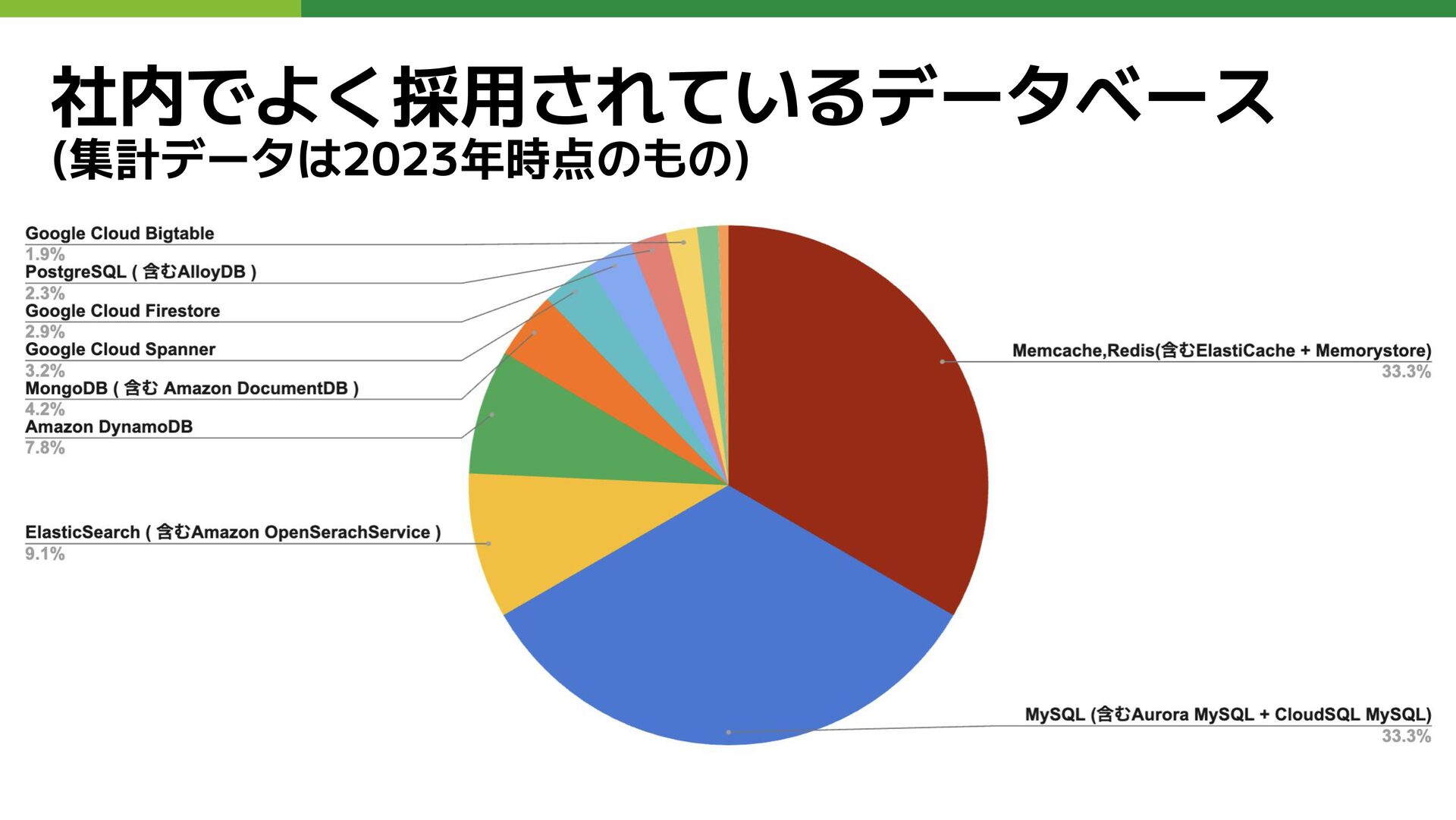
社内でよく採用されているデータベース (集計データは2023年時点のもの)
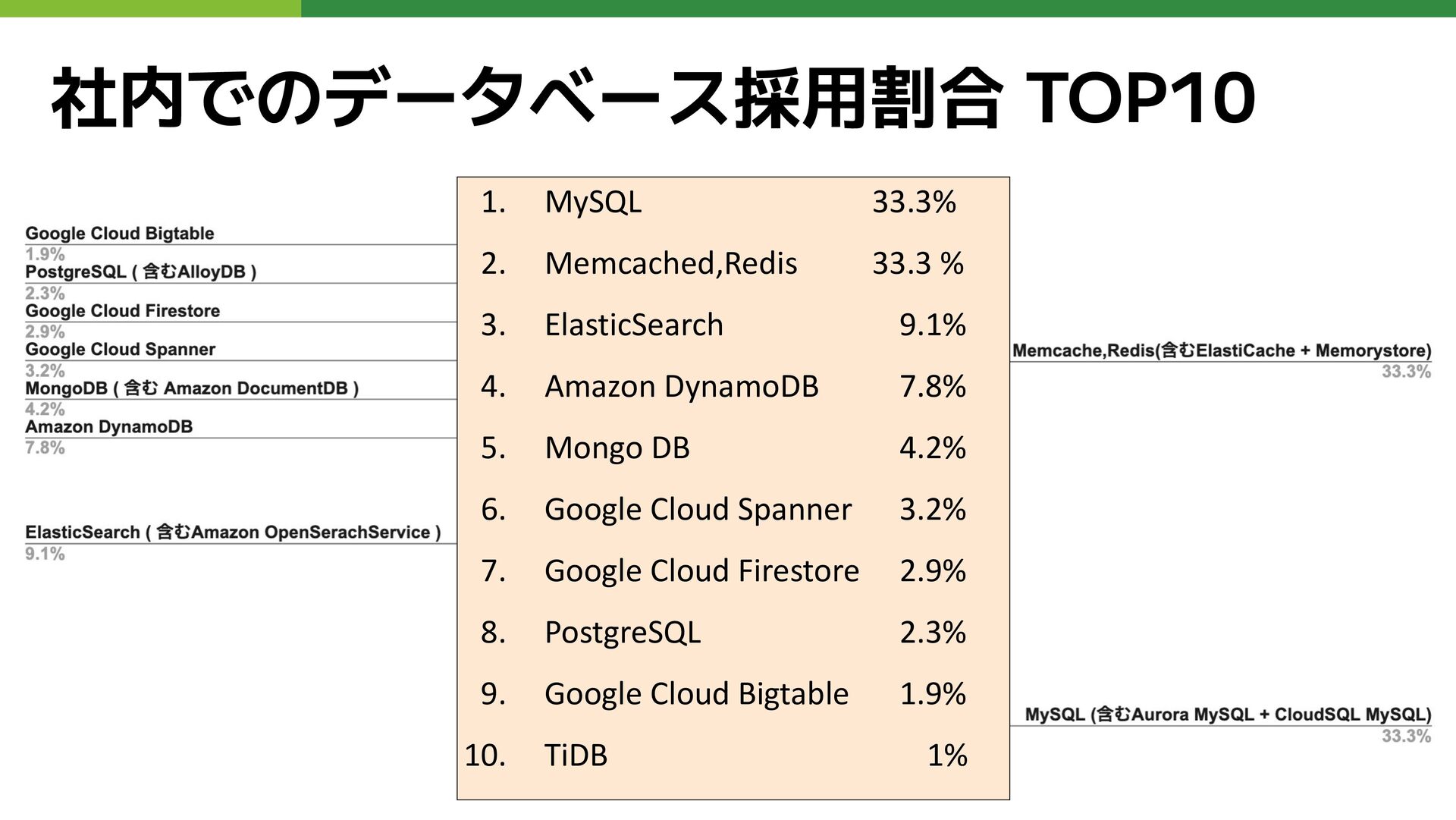
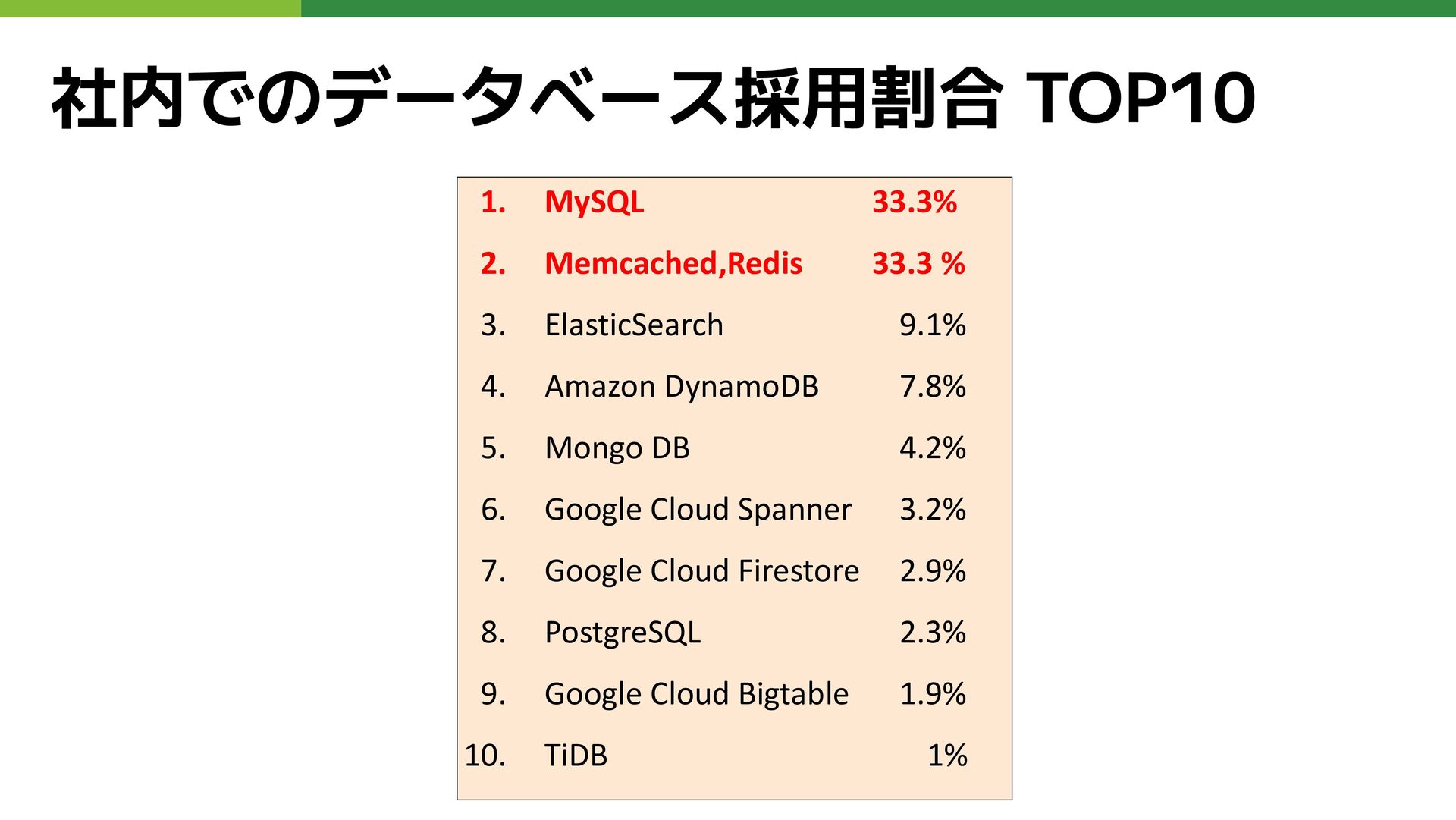
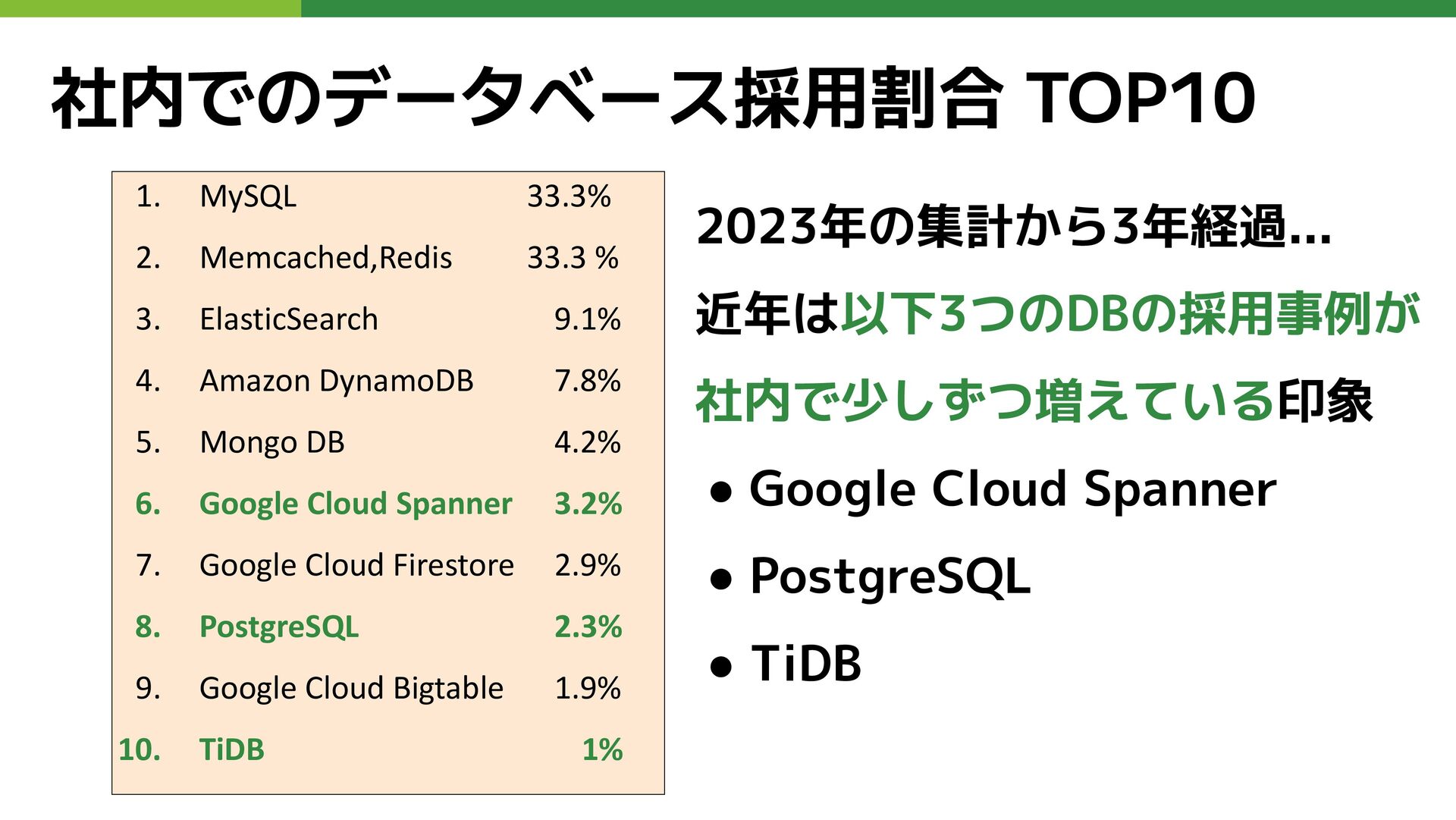
社内でのデータベース採用割合 TOP10 1. MySQL 33.3% 2. Memcached,Redis 33.3 % 3.
ElasticSearch 9.1% 4. Amazon DynamoDB 7.8% 5. Mongo DB 4.2% 6. Google Cloud Spanner 3.2% 7. Google Cloud Firestore 2.9% 8. PostgreSQL 2.3% 9. Google Cloud Bigtable 1.9% 10. TiDB 1%
社内でのデータベース採用割合 TOP10 1. MySQL 33.3% 2. Memcached,Redis 33.3 % 3.
ElasticSearch 9.1% 4. Amazon DynamoDB 7.8% 5. Mongo DB 4.2% 6. Google Cloud Spanner 3.2% 7. Google Cloud Firestore 2.9% 8. PostgreSQL 2.3% 9. Google Cloud Bigtable 1.9% 10. TiDB 1%
社内でのデータベース採用割合 TOP10 1. MySQL 33.3% 2. Memcached,Redis 33.3 % 3.
ElasticSearch 9.1% 4. Amazon DynamoDB 7.8% 5. Mongo DB 4.2% 6. Google Cloud Spanner 3.2% 7. Google Cloud Firestore 2.9% 8. PostgreSQL 2.3% 9. Google Cloud Bigtable 1.9% 10. TiDB 1% 2023年の集計から3年経過... 近年は以下3つのDBの採用事例が 社内で少しずつ増えている印象 • Google Cloud Spanner • PostgreSQL • TiDB
MySQLについて •MySQLはオープンソースのRDBMS •リリースから30年を超えた歴史ある製品 •ライセンスには無料のCommunity Editionと商用ライセンスがある 主に運用や監視に役立つ機能の有無やサポートの違い
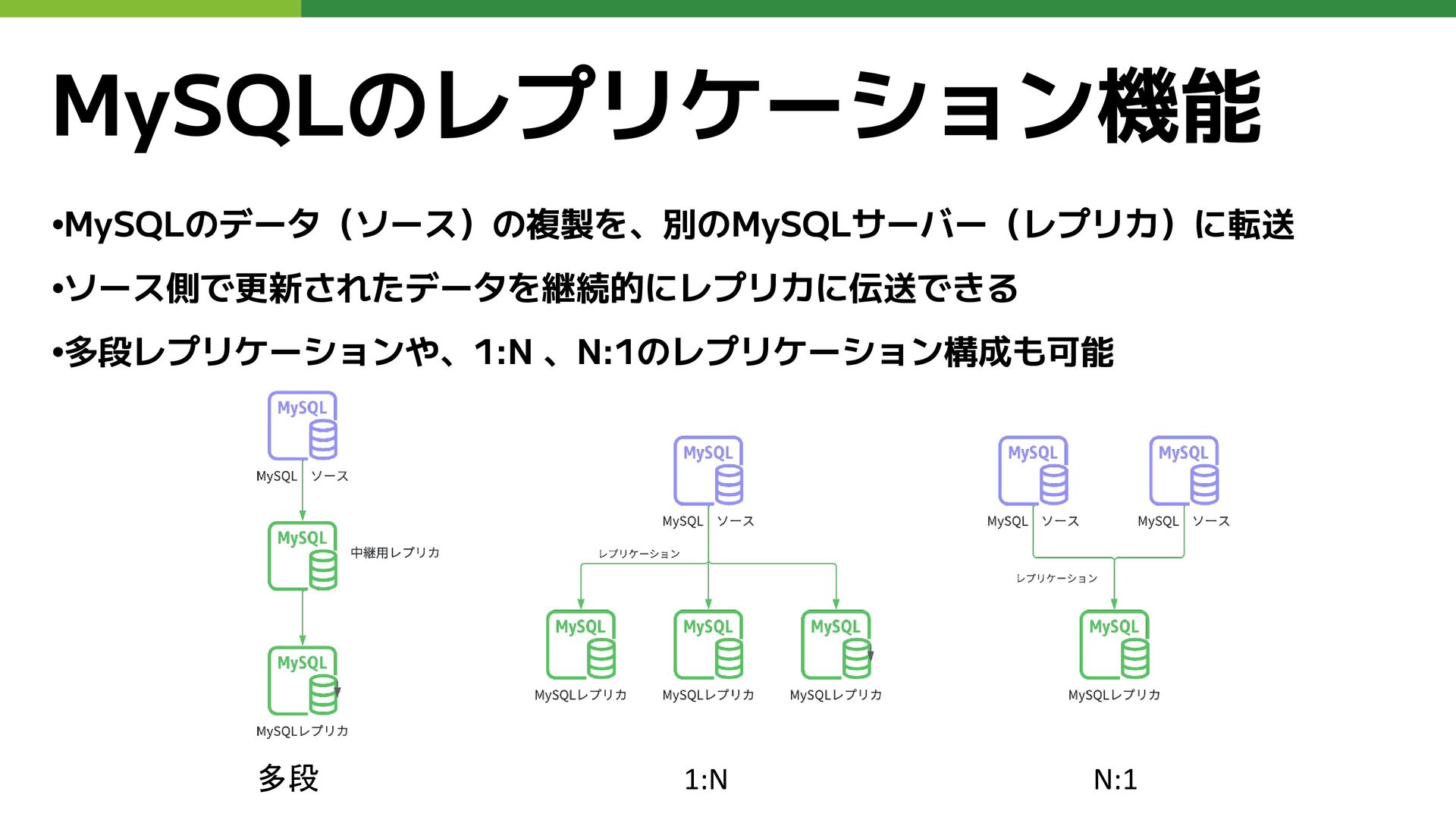
MySQLのレプリケーション機能 •MySQLのデータ(ソース)の複製を、別のMySQLサーバー(レプリカ)に転送 •ソース側で更新されたデータを継続的にレプリカに伝送できる •多段レプリケーションや、1:N 、N:1のレプリケーション構成も可能 多段 1:N N:1
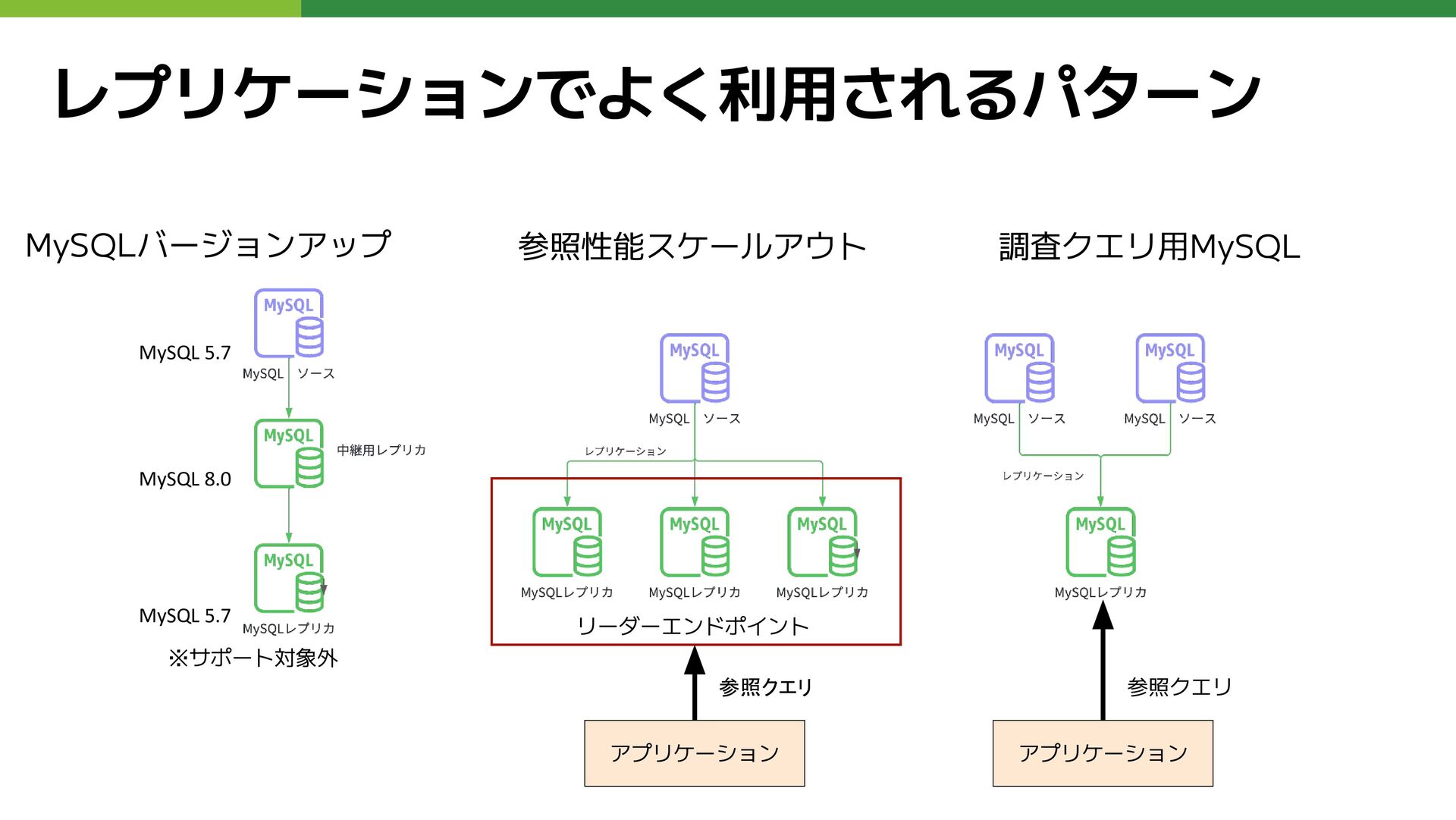
レプリケーションでよく利用されるパターン MySQLバージョンアップ 参照性能スケールアウト 調査クエリ用MySQL MySQL 5.7 MySQL 8.0 MySQL 5.7
リーダーエンドポイント アプリケーション 参照クエリ アプリケーション 参照クエリ ※サポート対象外
NoSQL分類表から社内で採用されているもの再確認 分類 特徴と強み 弱み 製品の一例 キーバリュー型 - key:value単位でデータを格納 - シンプルで高速
- 同時アクセス性能が高い - データの関係性の表現が難しい - トランザクションがないのでデータの信頼 性が低い - Redis ( Valkey含む ) - Memcached - Amazon DynamoDB(※) 列指向型 - 高い書き込み性能 - 大量データを効率的に扱える - ビッグデータの分析 - 複雑なクエリが困難 - ランダムアクセスには向いていない - トランザクションサポートが限定的 - Apache Cassandra - Hbase - Google Cloud Bigtable グラフ型 - 関係性の検索(ユーザー同士 の繋がりや地図の経路情報な ど)に強い - 他と比べるとデータ更新が高コスト - Neo4j - Amazon Neptune ドキュメント型 - データ型や定義を決めずに JSONなどの構造をもったドキュ メントデータを格納 - データの関係性の表現が難しい - トランザクションサポートが限定的 - MongoDB - Google Cloud Firestore - ElasticSearch ( OpenSearch含む ) - Amazon DynamoDB(※)
Memcached 特徴 • 高パフォーマンスなインメモリKVS( Key-Value-Store ) • ディスクアクセスが無いので高速 • 容量が溢れると最終アクセス日時が古い順にデータを削除
• データの永続性はない 主なユースケース • キャッシュ、セッションデータの保存
Redis 特徴 • 高パフォーマンスなインメモリKVS( Key-Value-Store ) • 多様なデータ型が存在 String ,
List , Set , Hash , Sorted Set • データの永続化も可能 • レプリケーションやRedis Clusterを用いたスケーラビリティと高可用性 主なユースケース • キャッシュ、セッションデータ、キュー、メッセージング、リアルタイムランキング
特徴 • フルマネージドでサーバレスなNoSQLデータベース • 応答1桁ミリ秒でのパフォーマンスとスケーラビリティが高い • Key-Value-Storeとドキュメントデータの両方に対応 • データの永続性あり 主なユースケース
• キャッシュ、低遅延が必要な処理、ユーザー行動履歴、IoTデータなどの大量データ Amazon DynamoDB
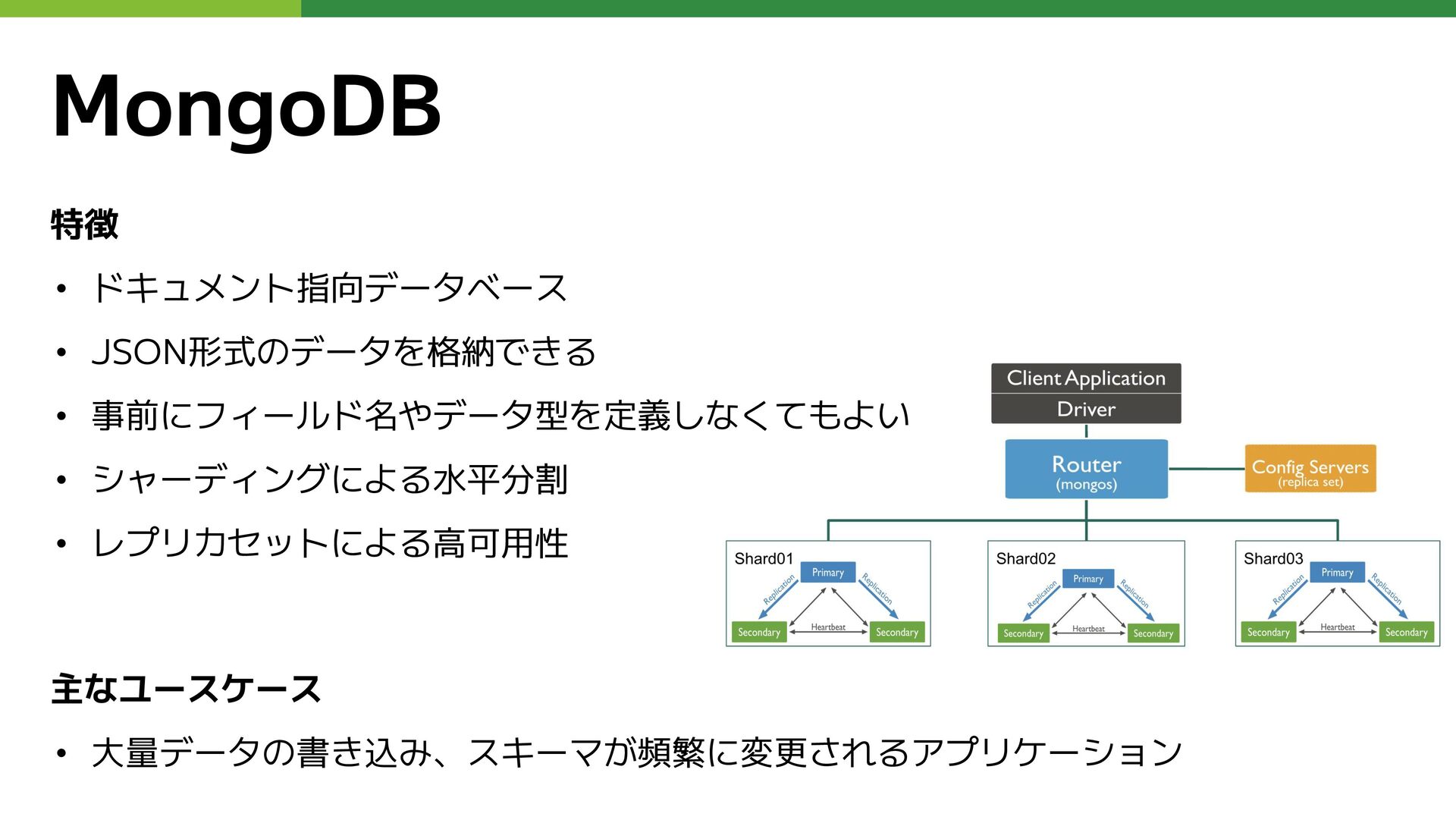
特徴 • ドキュメント指向データベース • JSON形式のデータを格納できる • 事前にフィールド名やデータ型を定義しなくてもよい • シャーディングによる水平分割 •
レプリカセットによる高可用性 主なユースケース • 大量データの書き込み、スキーマが頻繁に変更されるアプリケーション MongoDB
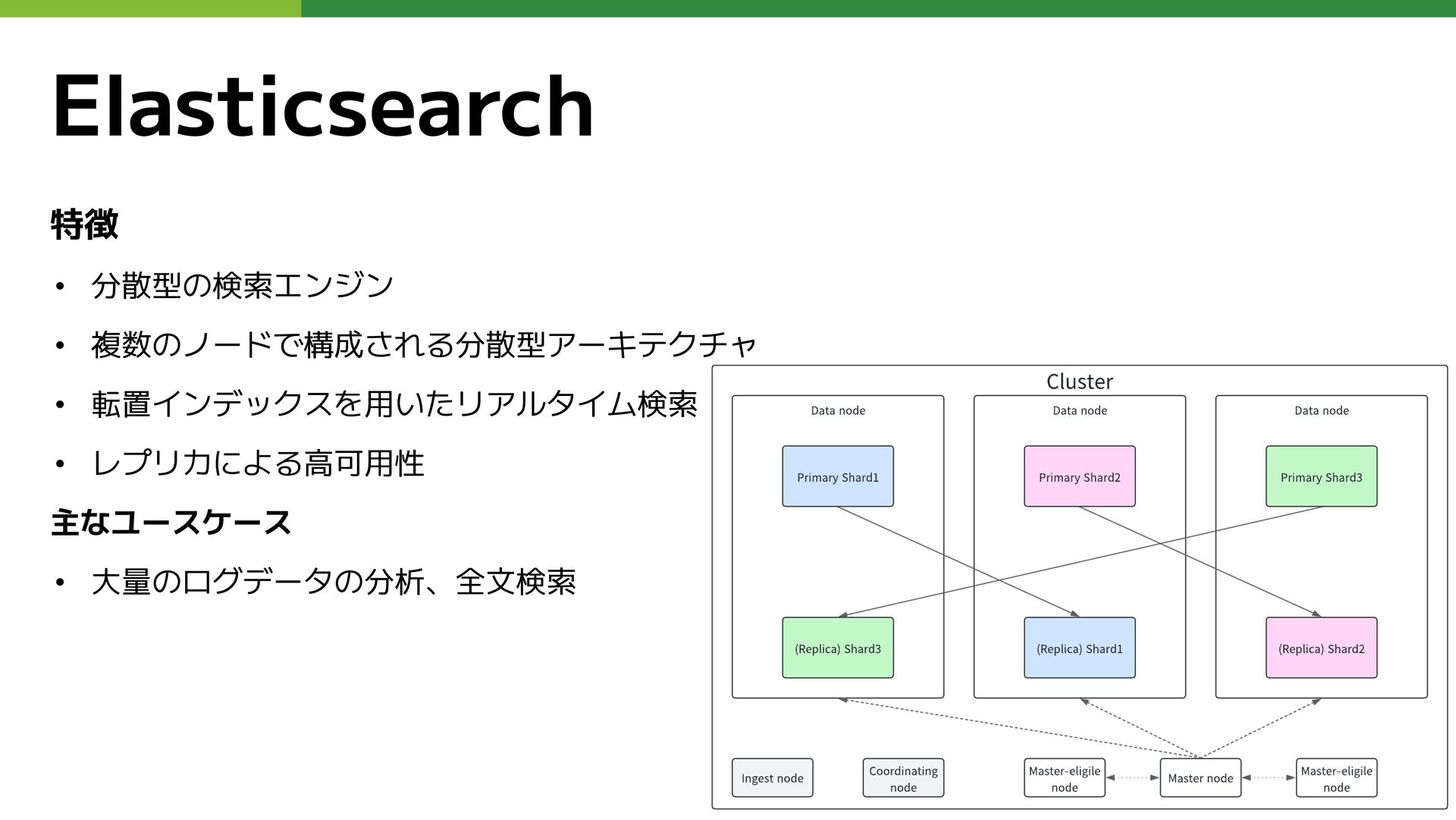
特徴 • 分散型の検索エンジン • 複数のノードで構成される分散型アーキテクチャ • 転置インデックスを用いたリアルタイム検索 • レプリカによる高可用性 主なユースケース
• 大量のログデータの分析、全文検索 Elasticsearch
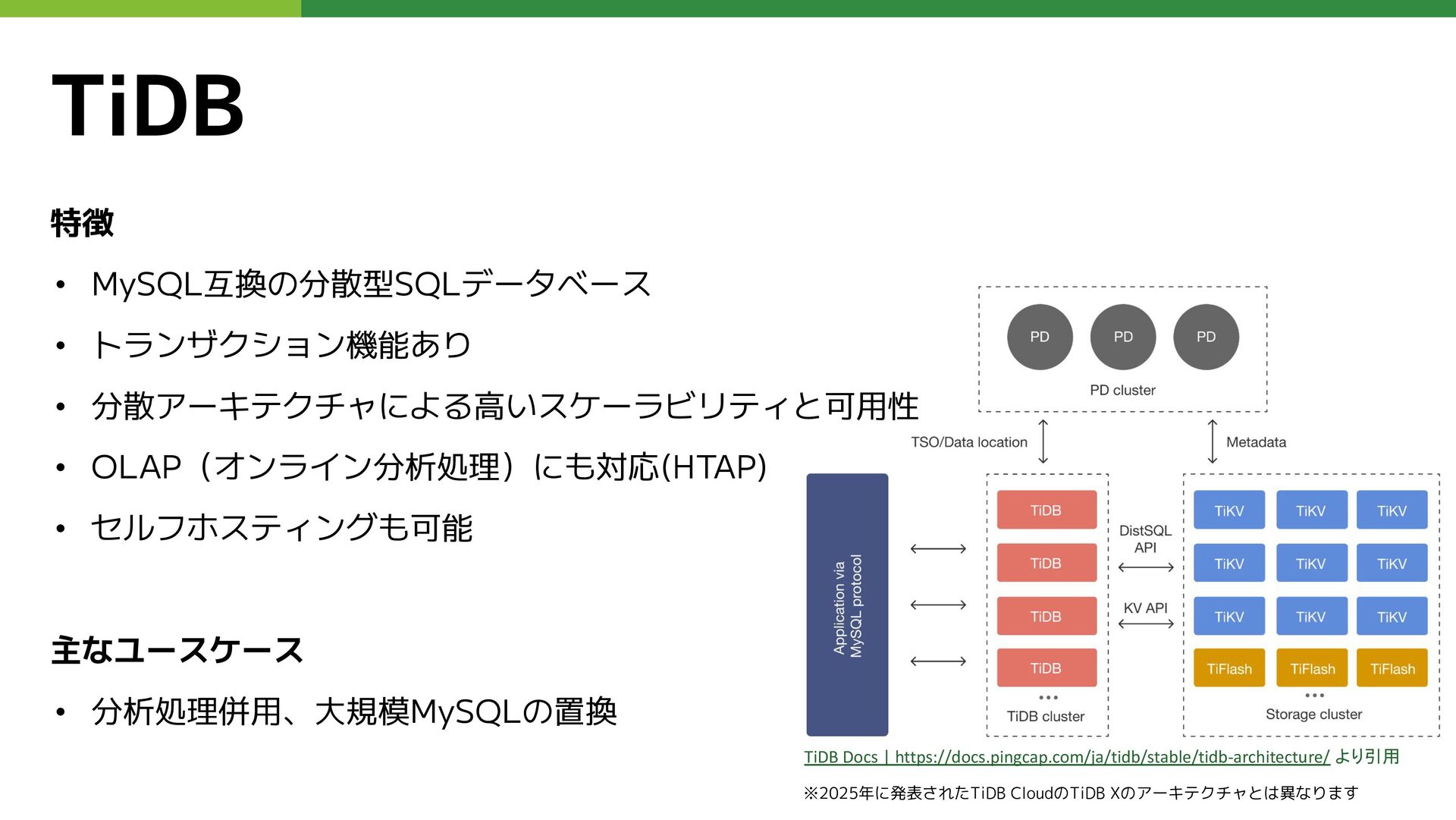
特徴 • MySQL互換の分散型SQLデータベース • トランザクション機能あり • 分散アーキテクチャによる高いスケーラビリティと可用性 • OLAP(オンライン分析処理)にも対応(HTAP) •
セルフホスティングも可能 主なユースケース • 分析処理併用、大規模MySQLの置換 TiDB TiDB Docs | https://docs.pingcap.com/ja/tidb/stable/tidb-architecture/ より引用 ※2025年に発表されたTiDB CloudのTiDB Xのアーキテクチャとは異なります
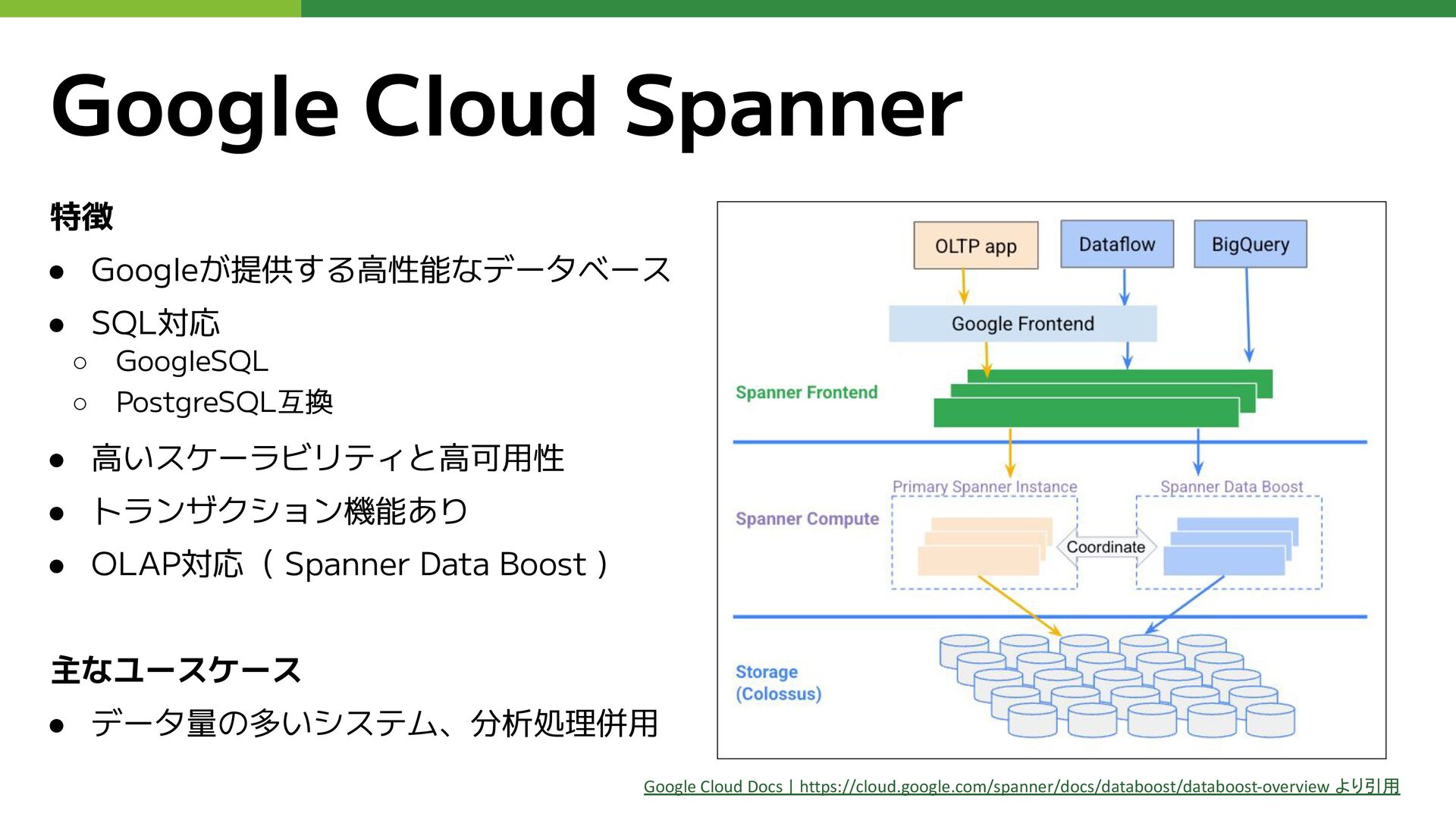
特徴 • Googleが提供する高性能なデータベース • SQL対応 ◦ GoogleSQL ◦ PostgreSQL互換 •
高いスケーラビリティと高可用性 • トランザクション機能あり • OLAP対応( Spanner Data Boost ) 主なユースケース • データ量の多いシステム、分析処理併用 Google Cloud Spanner Google Cloud Docs | https://cloud.google.com/spanner/docs/databoost/databoost-overview より引用
社内で開発しているサービスのデータベース活用事例 • サービスごとのデータベースの使い分けを紹介 • どのデータベースに、どんなデータを格納しているかの参考に 各サービスの開発チームにヒアリングを実施 開発チームからOK出たものは外部公開用資料にも掲載します
データベース活用事例の紹介1 会社名 : 株式会社サイバーエージェント サービス名 : Amebaブログ データベース 用途・入れているデータの一例 Amazon
Aurora MySQL - ユーザー情報 - ブログ記事データ - 下記以外のデータすべて Amazon ElasticCache ( Redis ) - ブログ記事情報のキャッシュ - いいね機能のキャッシュ Amazon ElastiCache ( Memcache ) - ユーザープロフィールのキャッシュ - ブログ設定情報のキャッシュ Amazon OpenSearch Service ( 旧名 Elasticsearch Service ) - 広告商品検索用データ Amazon DynamoDB - アクセス解析機能のデータ
データベース活用事例の紹介2 データベース 用途・入れているデータの一例 MongoDB - マスターデータ - ユーザーデータ - 下記以外のデータすべて
Redis - ランキングデータ - 一時的な購入情報、エリア情報など永続化不要なデー タ 会社名 : 株式会社サイバーエージェント サービス名 : ピグパーティ
データベース活用事例の紹介3 データベース 用途・入れているデータの一例 Google Cloud Spanner - ユーザーデータ - ユニオン(ギルド)データ
- 下記以外のデータすべて Google CloudSQL ( MySQL ) - マスターデータ - 運営用の管理データ Google Cloud Memorystore - ランキングデータ - その他一時キャッシュ 会社名 : 株式会社QualiArts サービス名 : IDOLY PRIDE
データベース活用事例の紹介4 データベース 用途・入れているデータの一例 Google Cloud Spanner (Tokyo-Osakaマルチリージョン ) - サービスに関わるすべてのデータ
OpenSearch Service - Agentic Searchで利用する社内ドキュメントの 全文検索用途 S3 Vectors ※データベースではないが、ベクトルストアとして利用 - Agentic Searchで利用する社内ドキュメントの ベクトルデータを格納 会社名 : 株式会社WinTicket サービス名 : WINTICKET 可用性とパフォーマンスを追求するWINTICKETサーバーのインフラリアーキテクチャ 色んなデータソースに対応した RAG システム「RAGent」の紹介
データベース活用事例の紹介5
データベース活用事例の紹介6 会社名 : 株式会社タップル サービス名: tapple CyberAgent Developers Blog |
75億ドキュメント以上のデータを保持するMongoDBを、Amazon EC2からMongoDB Atlasへ約3ヶ月で移設した方法 CyberAgent Developers Blog | タップルにおける約4年越しのキャッシュストア大幅アップデートの軌跡 データベース 用途・入れているデータの一例 MongoDB - ユーザーデータ - マスターデータ - 下記以外のデータすべて Amazon ElasticCache ( Redis ) - MongoDBの前段キャッシュ - 排他制御ロックデータ Amazon OpenSearch Service - 恋愛対象の候補検索用データ Amazon DynamoDB - メイン機能ではないシステムデータ等
データベース活用事例の紹介7 会社名 : AWA株式会社 サービス名: AWA データベース 用途・入れているデータの一例 DocumentDB(MongoDB) -
アーティスト情報、プレイリスト、ログイン情報 - 下記以外のデータすべて Amazon ElasticCache For Redis - キャッシュ全般 Amazon OpenSearch Service - 検索機能 MemoryDB for Redis - ラウンジ機能関連、お知らせ情報 AWS Blog | AWA 株式会社、MongoDB on EC2 から Amazon DocumentDB への移行でデータベースコストを約 50% 削減(Part 1/2) AWS Blog | AWA 株式会社、MongoDB on EC2 から Amazon DocumentDB への移行でデータベースコストを約 50% 削減(Part 2/2)
データベース活用事例の紹介8 会社名 : 株式会社サイバーエージェント サービス名 : Dynalyst データベース 用途・入れているデータの一例 Aurora
MySQL ( MySQL併用 ) - 広告主情報 - 予算情報 - ホワイトリスト情報 - その他マスターデータ Amazon ElasticCache ( Redis ) - フリークエンシーキャップ (短期間で同一ユーザーに複数回広告を当てるのを防ぐ機構) - その他キャッシュ Amazon ElastiCache ( Memcache ) - MySQLに載せているデータのキャッシュ Amazon DynamoDB - リターゲティング対象ユーザのデータ - 広告動画視聴履歴の一時保存 - クリック履歴の一時保存 SpeakerDeck | 月間数千億リクエストをさばく技術 CyberAgent Way | ハイブリッドクラウドを駆使したコスト最適化:SREと連携したDynalystの移設 より引⽤(右図)
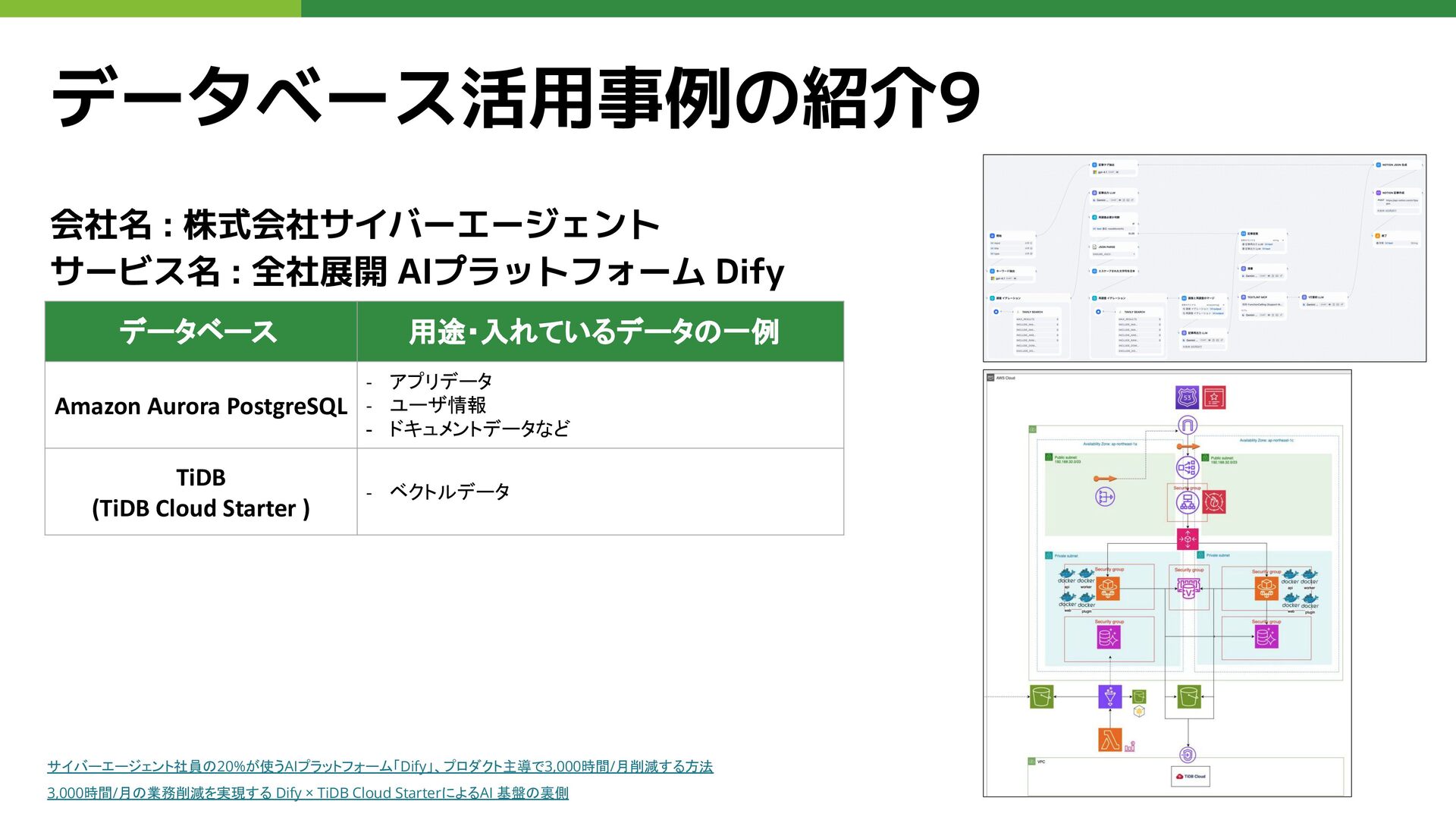
データベース活用事例の紹介9 会社名 : 株式会社サイバーエージェント サービス名 : 全社展開 AIプラットフォーム Dify データベース
用途・入れているデータの一例 Amazon Aurora PostgreSQL - アプリデータ - ユーザ情報 - ドキュメントデータなど TiDB (TiDB Cloud Starter ) - ベクトルデータ 3,000時間/月の業務削減を実現する Dify × TiDB Cloud StarterによるAI 基盤の裏側 サイバーエージェント社員の20%が使うAIプラットフォーム「Dify」、プロダクト主導で3,000時間/月削減する方法
データベース選定の理由 MySQL MySQLを利用しているサービス: Amebaブログ AmebaはAmebaブログを中心としたサービス 2004年からスタートし、今年21周年を迎える歴史あるサービス MySQL選定理由 ➢ 運営初期の頃、2006年頃にMySQL4系の時代から利用。( 当時はOracle RACと併用
) ➢ Amebaブログは参照ヘビーなサービスで、当時利用できるOSSのデータベースでは参照性能の スケールアウトが比較的容易だったMySQLが選ばれた。 ➢ 何度かシステム刷新を経て、現在はMySQL 8.0(Aurora MySQL)を使用 CyberAgent Developers Blog | アメブロ2016:インフラ編 〜大規模リニューアルの裏側〜 CyberAgent Developer Conference 2022 | 事業と歩むAmebaシステム刷新の道 日経クロステック|100億PVにも耐えられる、アメブロがOracle RACで性能向上
データベース選定の理由 MongoDB MongoDBを利用しているサービス:ピグパーティ 仮想空間内でアバター( ピグ )を使って着せ替えや部屋の模様替えを楽しむアバターSNS MongoDB 選定理由 ➢ サーバサイドにNode.jsを採用していて、JSONをそのまま格納できるMongoDBと相性が良い ➢
柔軟なスキーマ設計により仕様変更が多いゲーム開発にマッチ ➢ 自動シャーディングによる負荷分散とレプリケーションによる高可用性 ➢ ピグパーティより前に運営開始したピグライフでもMongoDBを採用しており知見があった Slideshare | MongoDB + node.js で作るソーシャルゲーム Speakerdeck | ピグパーティにおけるMongoDB CommunityバージョンからAtlasへの移行事例
データベース選定の理由 Elasticsearch Elasticsearchを利用しているサービス:tapple tappleは2014年にサービス開始したマッチングサービス 共通の趣味を通して異性との交流や出会いのきっかけを提供 Elasticsearch選定理由 ➢ リリース当初はユーザー検索機能もメインDBであるMongoDBを利用してきた ➢ MongoDBは検索に強いわけではないので、ユーザー数の増加により性能が悪化してきた ➢
ユーザー検索機能を大規模データの検索に強みのあるElasticsearchに切り替えた Speakerdeck | タップル誕生における、事業成長に合わせた継続的なシステム改善について ※サービス名称が変更されたAmazon OpenSearch Service 利用中。名称変更については下記記事を参照 Publickey | 「Amazon Elasticsearch Service」の名称が「Amazon OpenSearch Service」に変更。ElasticsearchからフォークしたOpenSearchも採 用
データベース選定の理由 Cloud Spanner Cloud Spannerを利用しているサービス:IDOLY PRIDE IDOLY PRIDEはアイドルマネジメントRPGのゲーム 2021年リリース ゲーム開発と運営はSGEのQualiArtsが担当 Cloud Spanner選定理由
➢ 過去の別ゲームではMySQLやMongoDBを採用してきた ➢ MySQLでは高負荷なゲームの書き込みの分散で苦労していた ➢ MongoDBは当時トランザクションがなかったり、MongoDBクラスタの運用に苦労していた ➢ Cloud Spannerはフルマネージドで、自動水平分割機能やトランザクション機能をもっていた speakerdeck | ゲーム「IDOLY PRIDE」を構成するGCPアーキテクチャの全貌 「IDOLY PRIDE」におけるGoogle Cloud Spannerの活用
データベース選定の理由 TiDB TiDBを利用しているサービス:大規模データ処理基盤 サイバーエージェント内で横断的に利用される大規模データ処理基盤 以前は基盤全体がHadoopエコシステムに依存していて、データストアにHBaseを利用していた TiDB選定理由 ➢ HBaseの利用と運用の面から複数の課題があった ▪ 簡単な集計、検索にもJavaでコードを書く必要がある ▪
HBaseはプライベートクラウドのVM上で運用していて手間が多かった ➢ TiDBはMySQL互換であるため利用者が使いやすく、複雑なクエリの実行も可能 ➢ TiDB OperatorによってKubernetes上でTiDBを運用可能 speakerdeck |TiUG #1 HBaseからTiDBへの移行を選んだ理由
データベース選定の理由 TiDB Cloud TiDB Cloudを利用しているサービス:全社展開 AIプラットフォーム Dify サイバーエージェント内で横断的に利用されるノーコードAIプラットフォームDify ベクトルデータベースとしてTiDB Cloud Starterプランを採用
TiDB Cloud選定理由 ➢ 全社展開で利用者もデータ量も急激に増加 ▪ マネージドで動的なスケールが可能でパフォーマンスが安定している ➢ 他のベクトルデータベースと比べて低コストで運用可能 ▪ OpenSearch Serviceをベクトルデータベースとして利用する場合、最小構成で月額数万円 ▪ TiDB Cloud Starterの場合従量課金かつ無料枠も存在する為、月額数百円 ~ 数千円 3,000時間/月の業務削減を実現する Dify × TiDB Cloud StarterによるAI 基盤の裏側
2章のまとめ • 社内でのデータベース採用率のトップはMySQL RedisやElasticsearch,MongoDBなどのNoSQLに加え、SpannerなどのNewSQLも使われている • サービスはそれぞれ要件に適したデータベースを選択している サービスが成長すると求める要件が変わってくることもある
データベース運用で起きやすい 問題とその対応事例
ガールフレンド(仮)での事例 データベース: MySQL
ガールフレンド(仮)とは PC/スマートフォン ブラウザで遊べるソーシャルゲーム 2012年リリースでサービス開始から14年目 アーキテクチャなど詳細は下記の発表資料を参照 12年目を迎えた『ガールフレンド(仮)』におけるデータベースの負債解消への道のり
ガールフレンド(仮): ギフトボックスの仕様による性能悪化と データサイズの肥大化 概要 1. サービスリリース当初から「ギフトボックス」という機能があった • ログインボーナスやイベント報酬などのアイテムがここに送られる • ユーザーは任意のタイミングで自身のボックスに受取り可能
2. ギフトの受取日時の期限の設定がなかった • ユーザー側のボックスがいっぱいでギフトボックスに溜め込むユーザーが多発 3. 溜め込んだユーザーがギフトボックスを開くだけでMySQLの負荷増大 • 1ユーザーで100万件以上溜め込むユーザーもいた 4. 一時対応後、テーブルのデータサイズの肥大化が問題に
原因の特定方法 ▪ MySQLのスロークエリログの調査 ▪ 大量にギフトボックス関連のクエリが記録されていた ▪ 発生したユーザーIDに偏りがあることが判明 ▪ ユーザーIDに紐づくギフトボックスのレコードを調査すると1ユーザーで100万件を超えていた ガールフレンド(仮):
ギフトボックスの仕様による性能悪化と データサイズの肥大化
一次対応 • ギフトボックスを表示するクエリに最適化した複合インデックス作成で窮地を脱した パフォーマンスは向上したが、複合インデックスによってデータサイズが倍近くまで膨張 ガールフレンド(仮): ギフトボックスの仕様による性能悪化と データサイズの肥大化
根本対応 1. ギフトボックスの仕様変更によるレコード件数の大幅削減 ギフトボックスの一部アイテムをポイント(数値)に変換する仕様を追加 1アイテム = 1レコードだったので集約できる ユーザーの不利にならないような一定ルールで一括変換 2. 複合インデックスの削除
レコード件数が減ったことで複合インデックスを削除しても影響が出なくなった レコード件数削減と複合インデックス削除によりテーブルのデータサイズは半減した ガールフレンド(仮): ギフトボックスの仕様による性能悪化と データサイズの肥大化
参考:ゲームの仕様を変えるような対応をおこなうための社内フローの一例 【議題】 ギフトボックスのデータサイズ肥大化問題の対応をどうするか 【実現方法のパターン】 ・全アイテムに受取期限を設定し、古いアイテムは一括削除 ・一定ルールのアイテムをすべて数値に変換し、変換した レコードを削除 ・サーバースペック増強で対応 1. 開発チームのエンジニアや開発リーダーと実現方法の協議
開発チーム
【要件】 ギフトボックスのデータサイズ肥大化問題の対応をどうするか 【実現方法のパターン】 ・全アイテムに受取期限を設定し、古いアイテムは一括削除 ・一定ルールのアイテムをすべて数値に変換し、変換した レコードを削除 ・サーバースペック増強で対応 1. 開発チームのエンジニアや開発リーダーと実現方法の協議 「一番効果的に件数を
減らせるのはこの方法ですね。」 「デメリットはユーザーの 不利益になってしまう 可能性が高いことですね。」 開発チーム 参考:ゲームの仕様を変えるような対応をおこなうための社内フローの一例
【要件】 ギフトボックスのデータサイズ肥大化問題の対応をどうするか 【実現方法のパターン】 ・全アイテムに受取期限を設定し、古いアイテムは一括削除 ・一定ルールのアイテムをすべて数値に変換し、変換した レコードを削除 ・サーバースペック増強で対応 1. 開発チームのエンジニアや開発リーダーと実現方法の協議 開発チーム
参考:ゲームの仕様を変えるような対応をおこなうための社内フローの一例 「次に件数を 減らせるのはこの方法ですね。」 「どういうルールでアイテムを 数値化するかが重要そう。」
【要件】 ギフトボックスのデータサイズ肥大化問題の対応をどうするか 【実現方法のパターン】 ・全アイテムに受取期限を設定し、古いアイテムは一括削除 ・一定ルールのアイテムをすべて数値に変換し、変換した レコードを削除 ・サーバースペック増強で対応 1. 開発チームのエンジニアや開発リーダーと実現方法の協議 開発チーム
参考:ゲームの仕様を変えるような対応をおこなうための社内フローの一例 「開発の工数はほぼかけずに 対応できますね。」 「その代わり毎月のサーバー 費用がかなり高額になります。」 「今後さらにデータが増えたら 対応できなくなりそう。 この方法は今回無しで」 ✗
【要件】 ギフトボックスのデータサイズ肥大化問題に対応させる 【実現方法のパターン】 ・全アイテムに受取期限を設定し、古いアイテムは一括削除 ・一定ルールのアイテムをすべて数値に変換し、変換した レコードを削除 ・サーバースペック増強で対応 2. サービスの責任者(プロダクトマネージャー等)も交えて、対応の結論を出す サービス責任者
開発チーム 「全アイテムに受取期限設定 はユーザーへの不利益が大きい のでやめましょう」 「一定のレアリティ以下の アイテムなら、数値変換しても 不利益にならない設計にできそうです。」 参考:ゲームの仕様を変えるような対応をおこなうための社内フローの一例 ✗ ✗
改善結果 • データサイズの肥大化によって顕在化していた負債を取り除けた この課題の解決によってハードウェアの制約で実現できなかったデータセンター移設が 行えるようになり、毎月のサーバーコストが半減 反省 • データ数の増大を見越した仕様とテーブル設計が望ましかった あとから仕様を変更するのは調整を含めて大変 ガールフレンド(仮):
ギフトボックスの仕様による性能悪化と データサイズの肥大化
新作スマホ向けゲームでの事例 データベース: Google Cloud Spanner
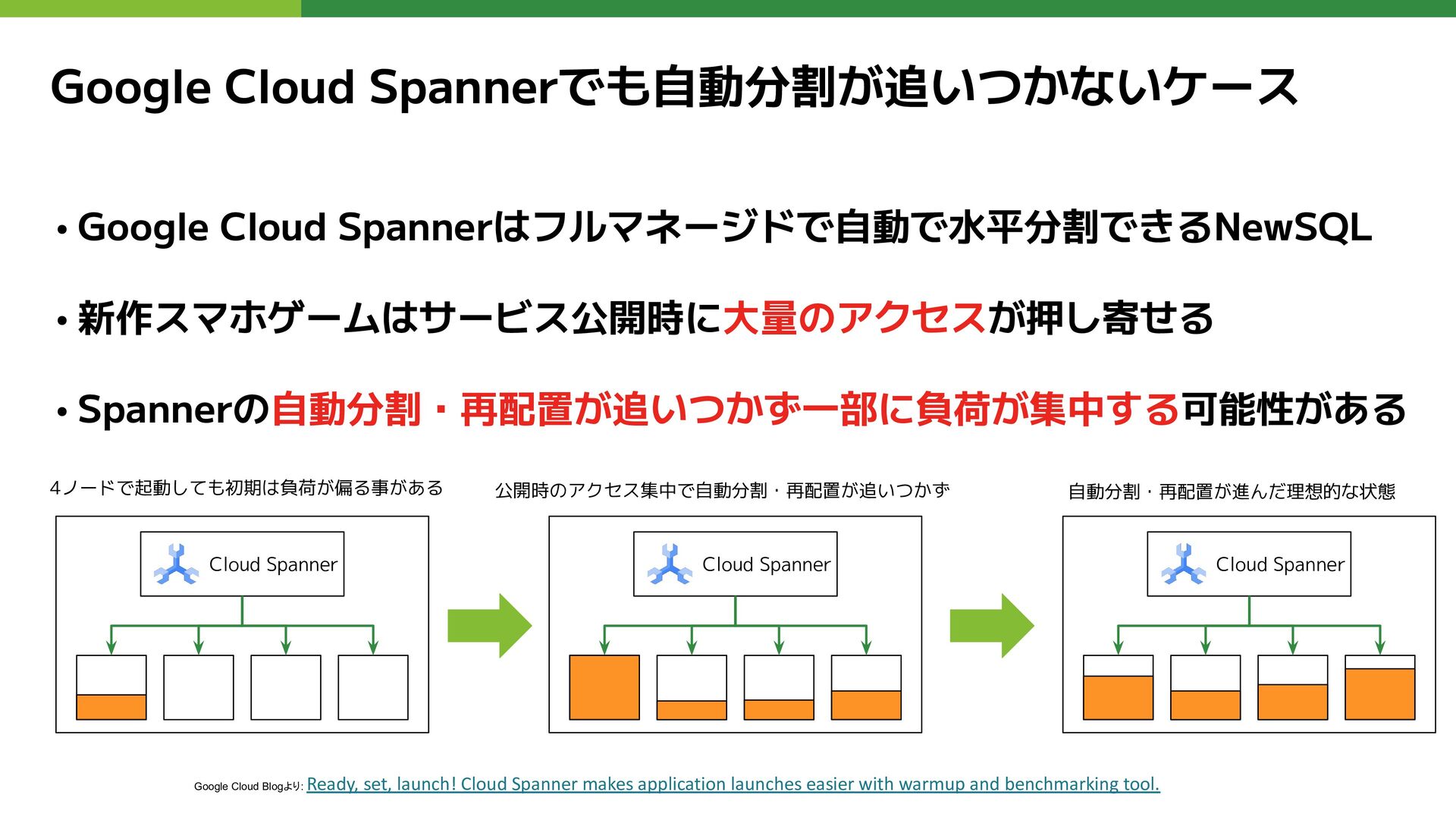
Google Cloud Spannerでも自動分割が追いつかないケース • Google Cloud Spannerはフルマネージドで自動で水平分割できるNewSQL • 新作スマホゲームはサービス公開時に大量のアクセスが押し寄せる •
Spannerの自動分割・再配置が追いつかず一部に負荷が集中する可能性がある Google Cloud Blogより: Ready, set, launch! Cloud Spanner makes application launches easier with warmup and benchmarking tool. 4ノードで起動しても初期は負荷が偏る事がある Cloud Spanner Cloud Spanner Cloud Spanner 公開時のアクセス集中で自動分割・再配置が追いつかず 自動分割・再配置が進んだ理想的な状態
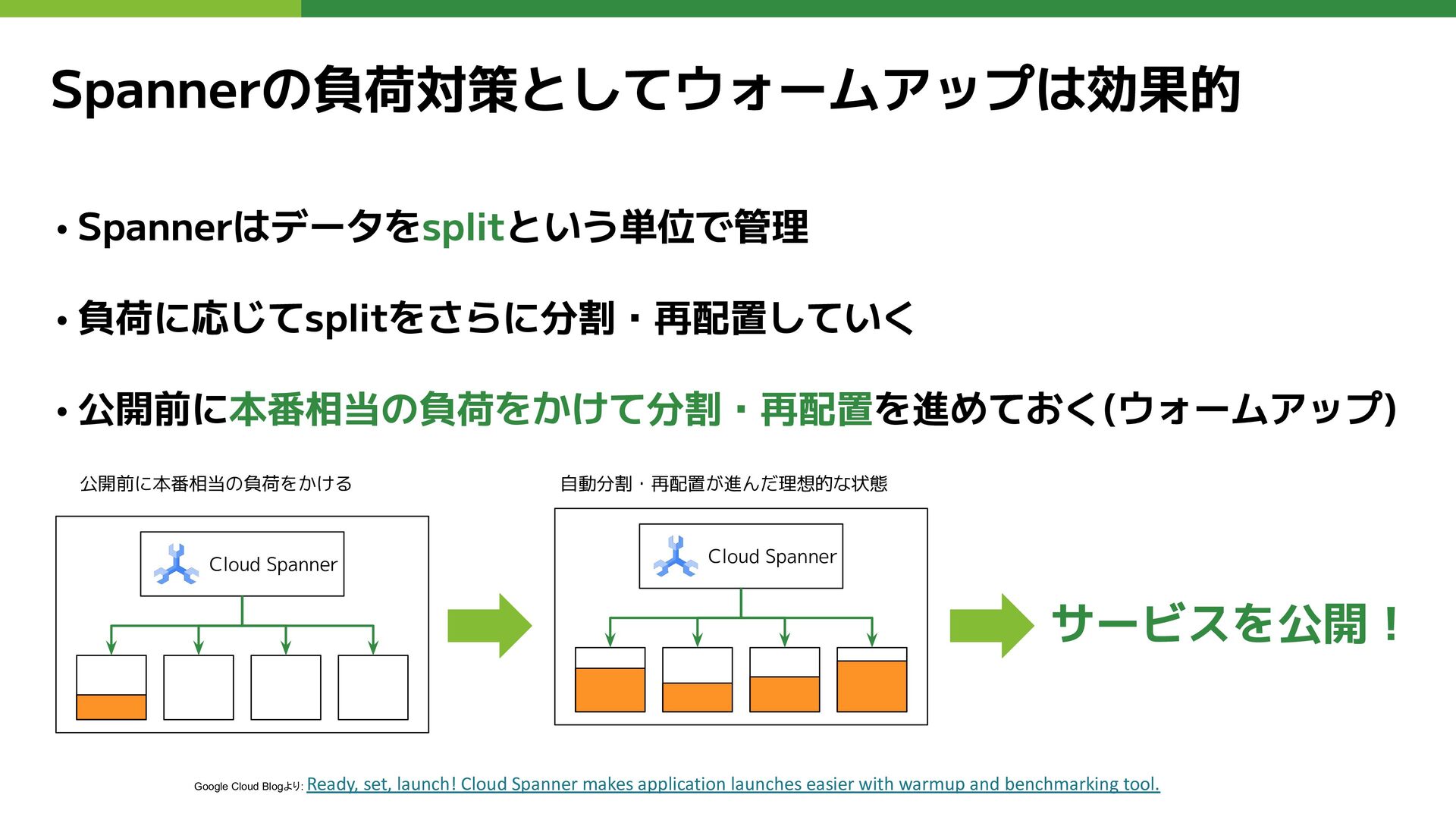
Spannerの負荷対策としてウォームアップは効果的 • Spannerはデータをsplitという単位で管理 • 負荷に応じてsplitをさらに分割・再配置していく • 公開前に本番相当の負荷をかけて分割・再配置を進めておく(ウォームアップ) Google Cloud Blogより:
Ready, set, launch! Cloud Spanner makes application launches easier with warmup and benchmarking tool. 公開前に本番相当の負荷をかける Cloud Spanner Cloud Spanner 自動分割・再配置が進んだ理想的な状態 サービスを公開!
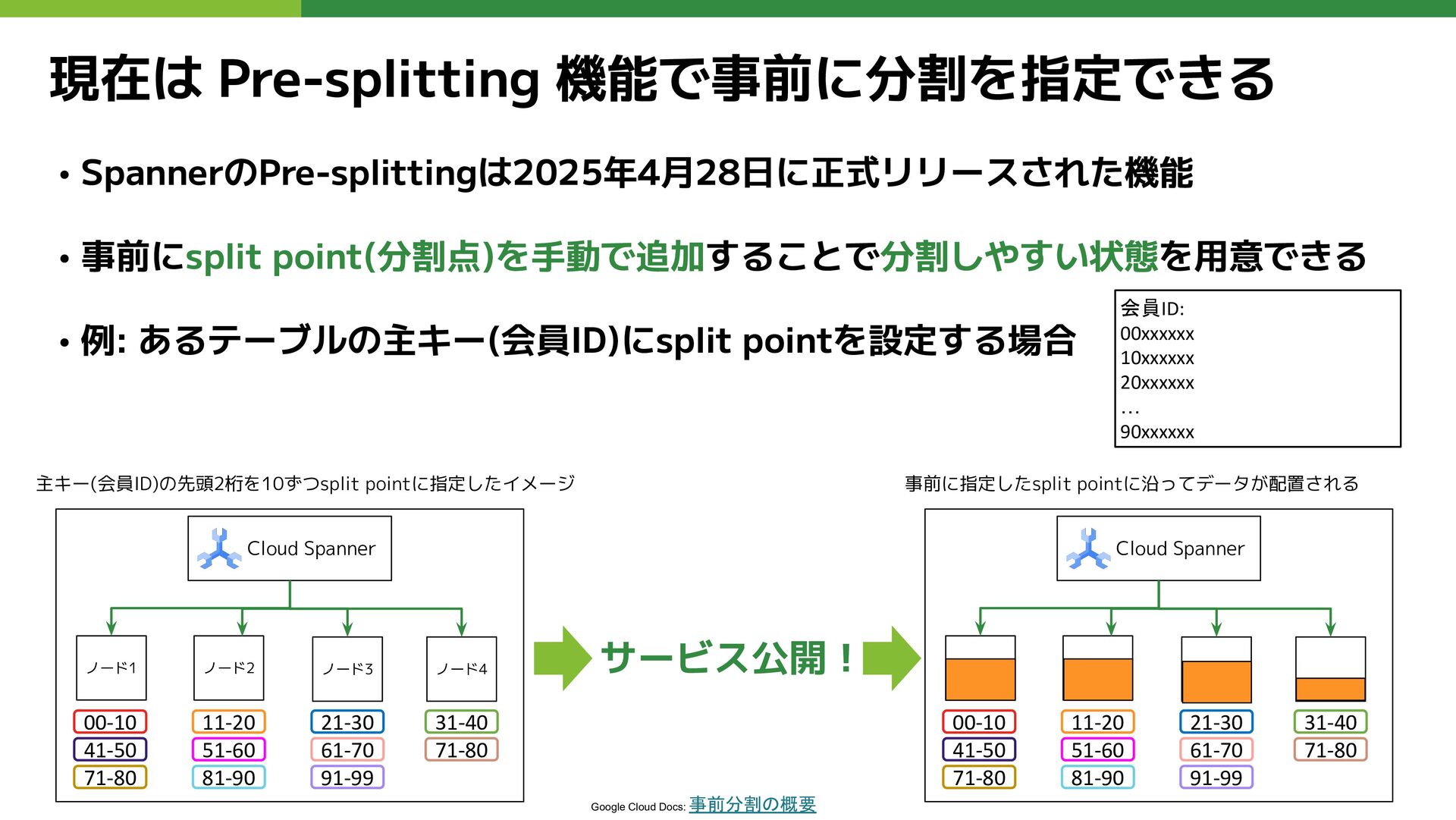
現在は Pre-splitting 機能で事前に分割を指定できる • SpannerのPre-splittingは2025年4月28日に正式リリースされた機能 • 事前にsplit point(分割点)を手動で追加することで分割しやすい状態を用意できる • 例:
あるテーブルの主キー(会員ID)にsplit pointを設定する場合 Google Cloud Docs: 事前分割の概要 主キー(会員ID)の先頭2桁を10ずつsplit pointに指定したイメージ Cloud Spanner ノード1 ノード2 ノード3 ノード4 サービス公開! 会員ID: 00xxxxxx 10xxxxxx 20xxxxxx … 90xxxxxx 00-10 11-20 21-30 31-40 41-50 51-60 61-70 71-80 71-80 81-90 91-99 事前に指定したsplit pointに沿ってデータが配置される Cloud Spanner 00-10 11-20 21-30 31-40 41-50 51-60 61-70 71-80 71-80 81-90 91-99
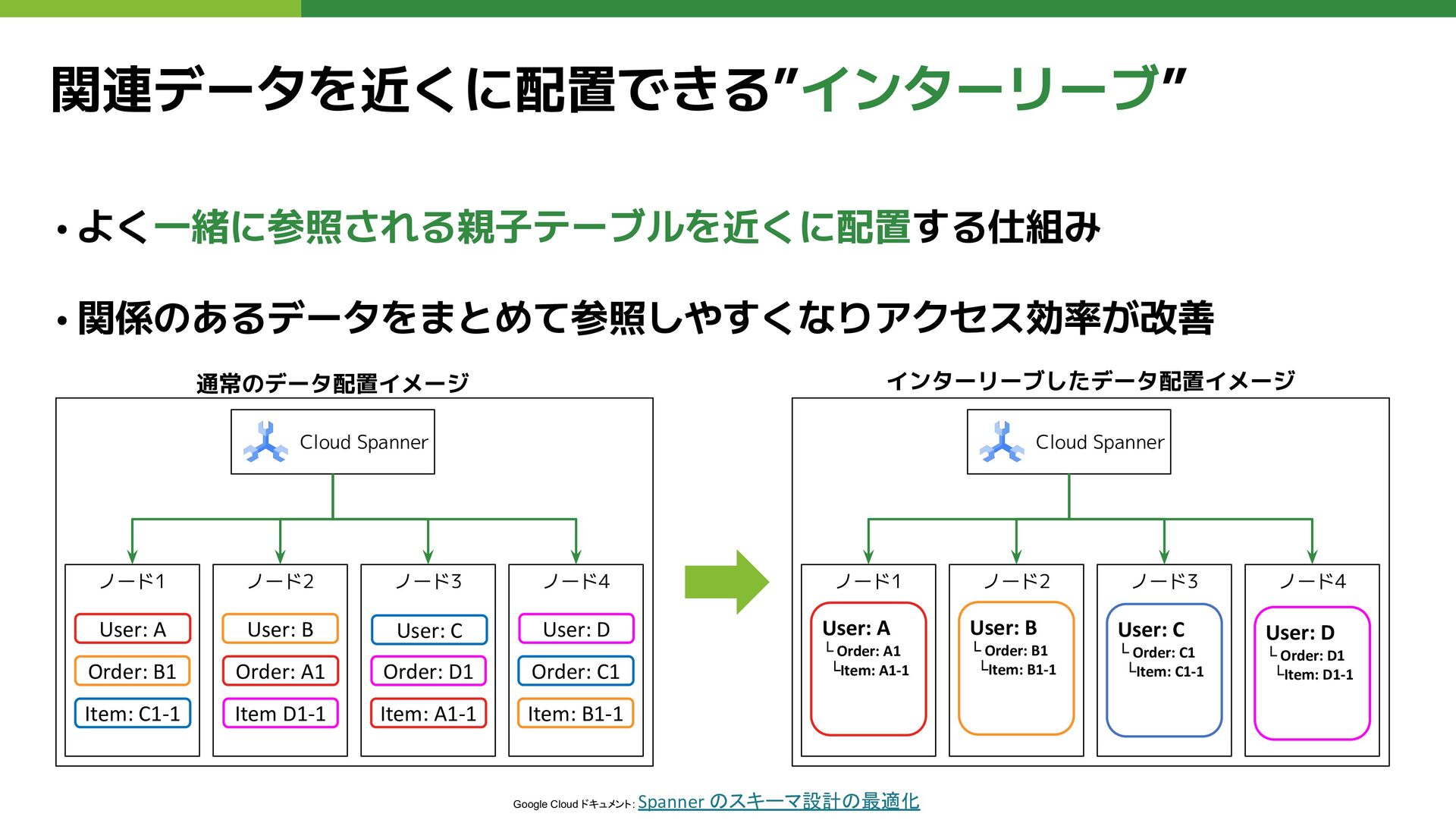
関連データを近くに配置できる”インターリーブ” • よく一緒に参照される親子テーブルを近くに配置する仕組み • 関係のあるデータをまとめて参照しやすくなりアクセス効率が改善 Google Cloud ドキュメント: Spanner のスキーマ設計の最適化
通常のデータ配置イメージ Cloud Spanner ノード1 ノード2 ノード3 ノード4 User: A Order: A1 インターリーブしたデータ配置イメージ Cloud Spanner ノード1 ノード2 ノード3 ノード4 User: A └ Order: A1 └Item: A1-1 Order: B1 User: B User: C User: D Order: C1 Item: C1-1 Order: D1 Item D1-1 Item: A1-1 Item: B1-1 User: B └ Order: B1 └Item: B1-1 User: C └ Order: C1 └Item: C1-1 User: D └ Order: D1 └Item: D1-1
3章のまとめ • ガールフレンド(仮)ではゲーム仕様とテーブル設計で苦労した 複合インデックスで窮地を脱したが、次はデータ肥大化問題に苦労した データの増大を見越した仕様決めやテーブル設計が重要 • 新作ゲームのような公開と同時に大量アクセスが来る環境では事前準備が必要 勝手にスケールしてくれるNewSQLのSpannerでも事前準備なしではインシデントにつながる ウォームアップやPre-splittingをつかって負荷集中に備えることが重要 関連データ同士を物理的に近くに配置できるインターリーブをつかった設計も重要
データベースのパフォーマンス 悪化時の初動調査手法
Amazon CloudWatch Database Insightsによる調査
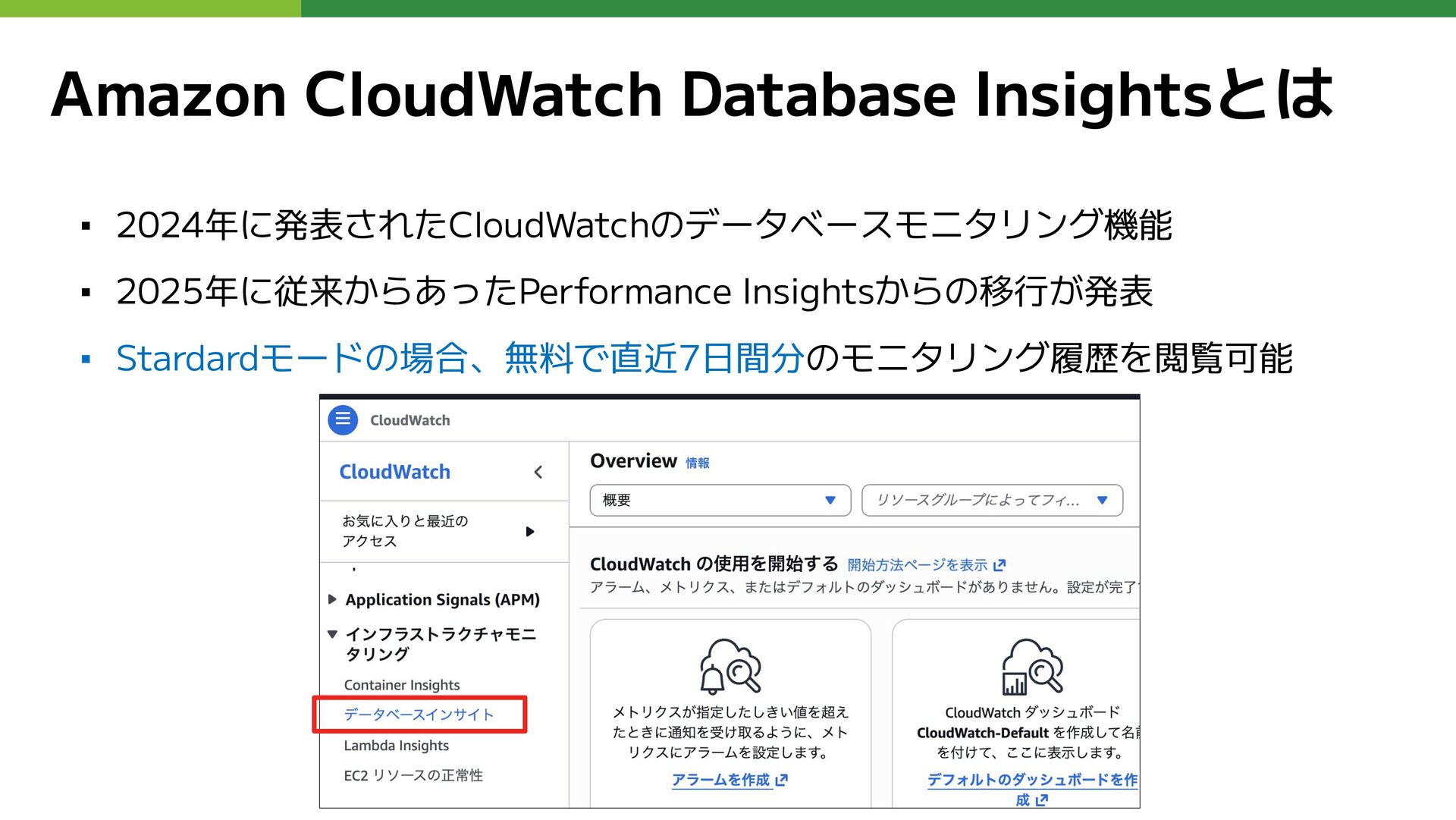
Amazon CloudWatch Database Insightsとは ▪ 2024年に発表されたCloudWatchのデータベースモニタリング機能 ▪ 2025年に従来からあったPerformance Insightsからの移行が発表 ▪
Stardardモードの場合、無料で直近7日間分のモニタリング履歴を閲覧可能
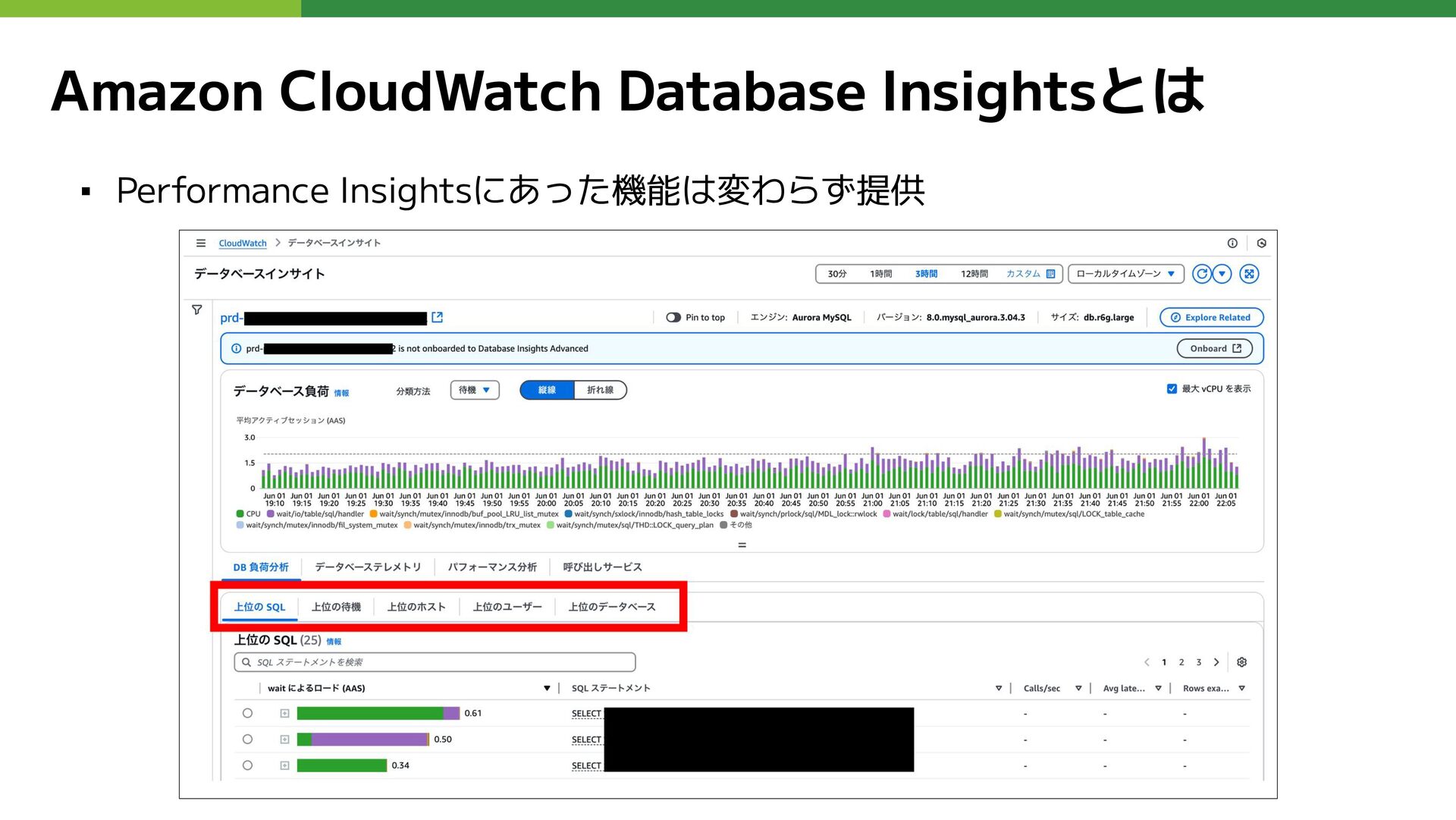
Amazon CloudWatch Database Insightsとは ▪ Performance Insightsにあった機能は変わらず提供
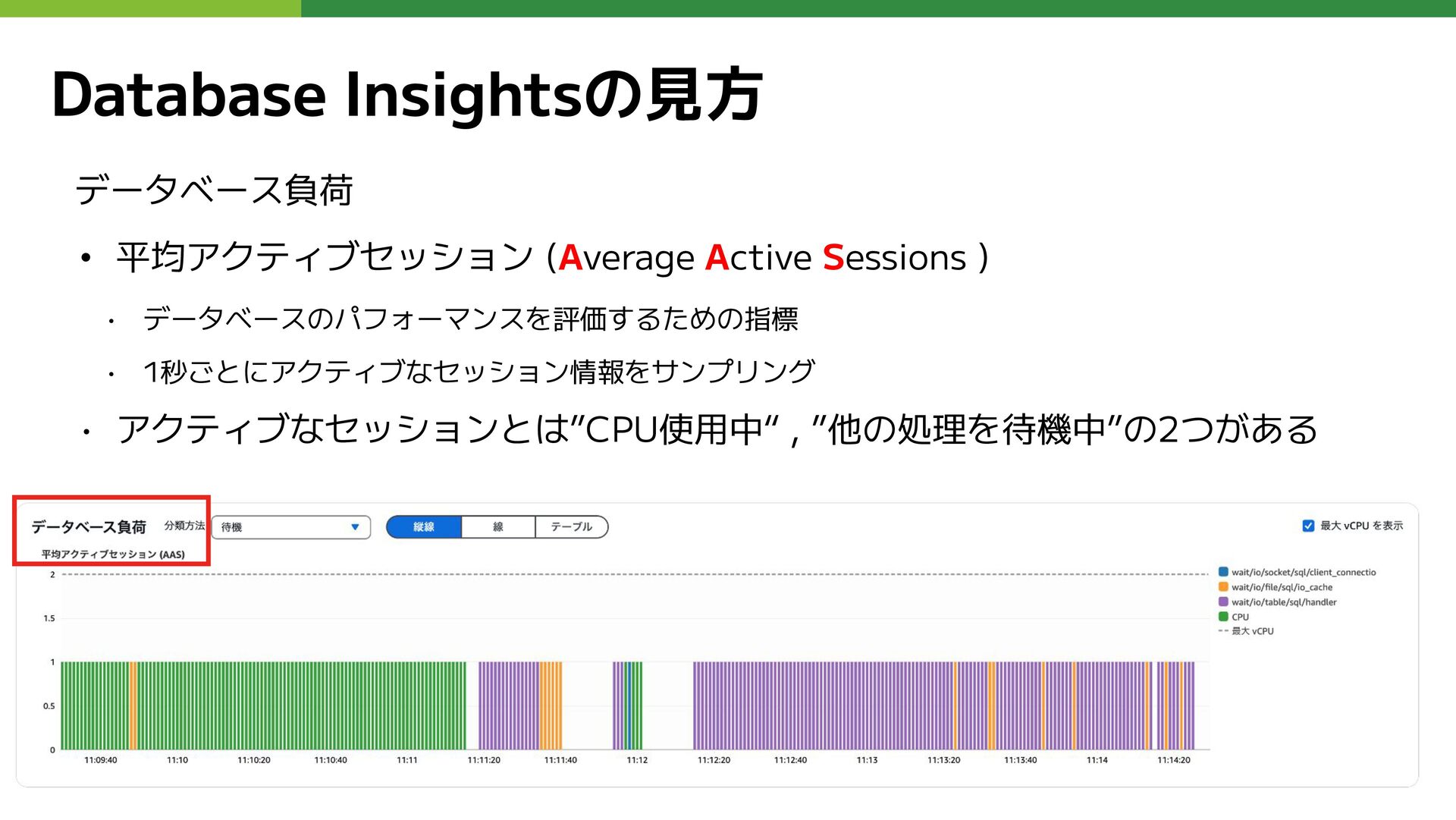
Database Insightsの見方 データベース負荷 • 平均アクティブセッション (Average Active Sessions ) •
データベースのパフォーマンスを評価するための指標 • 1秒ごとにアクティブなセッション情報をサンプリング • アクティブなセッションとは”CPU使用中“ , ”他の処理を待機中”の2つがある
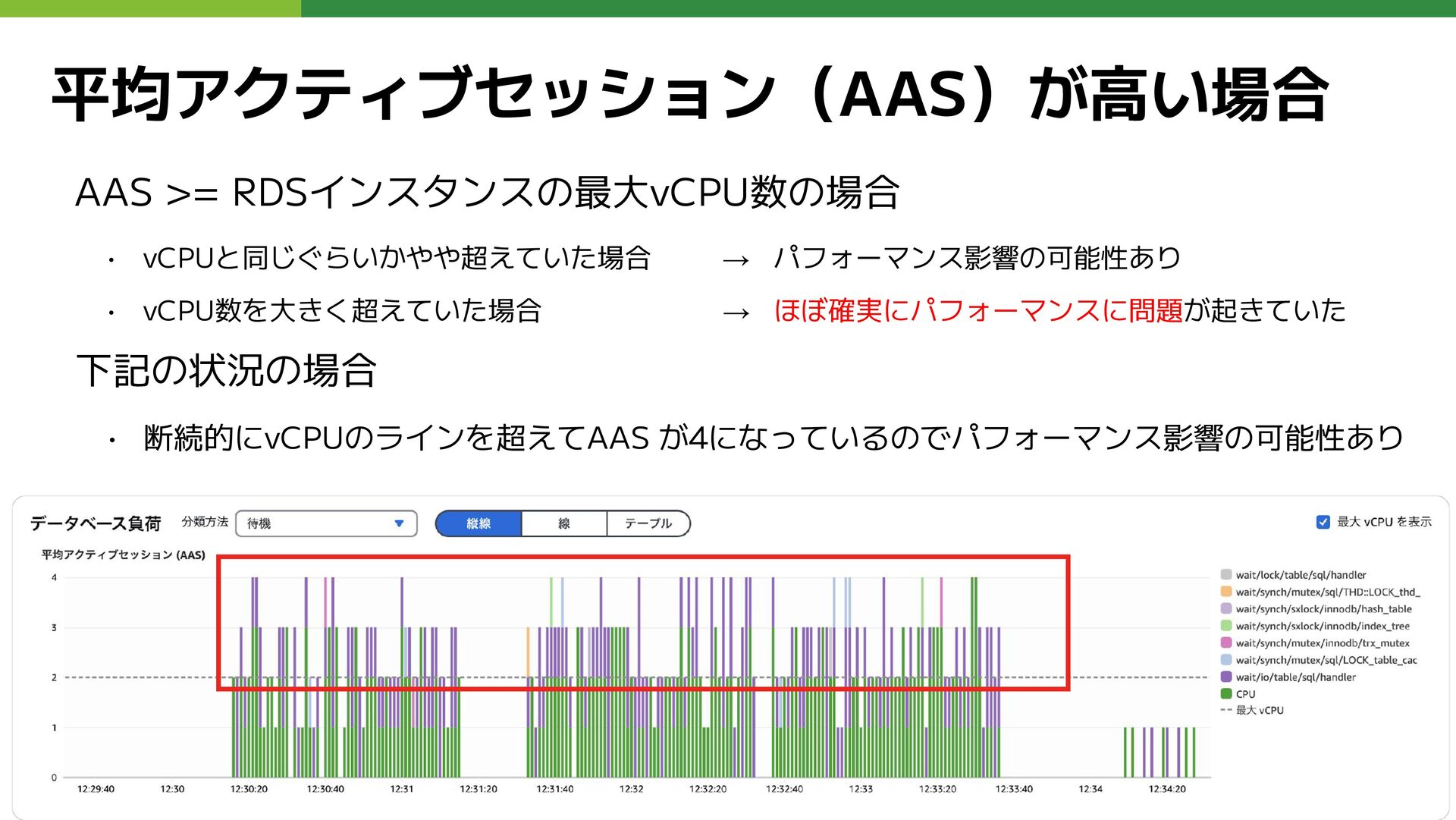
平均アクティブセッション(AAS)が高い場合 AAS >= RDSインスタンスの最大vCPU数の場合 • vCPUと同じぐらいかやや超えていた場合 → パフォーマンス影響の可能性あり • vCPU数を大きく超えていた場合
→ ほぼ確実にパフォーマンスに問題が起きていた 下記の状況の場合 • 断続的にvCPUのラインを超えてAAS が4になっているのでパフォーマンス影響の可能性あり
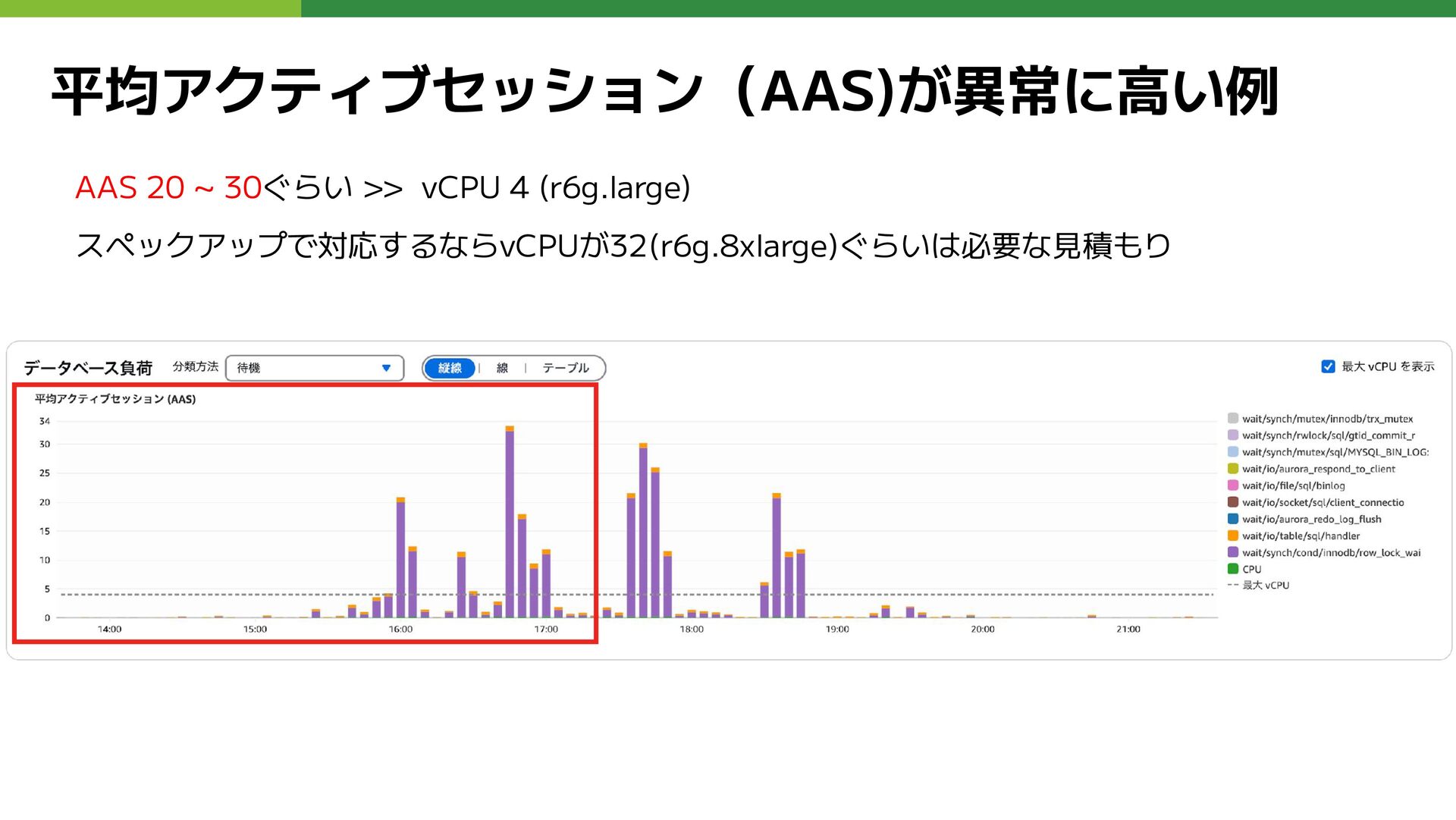
平均アクティブセッション(AAS)が異常に高い例 AAS 20 ~ 30ぐらい >> vCPU 4 (r6g.large) スペックアップで対応するならvCPUが32(r6g.8xlarge)ぐらいは必要な見積もり
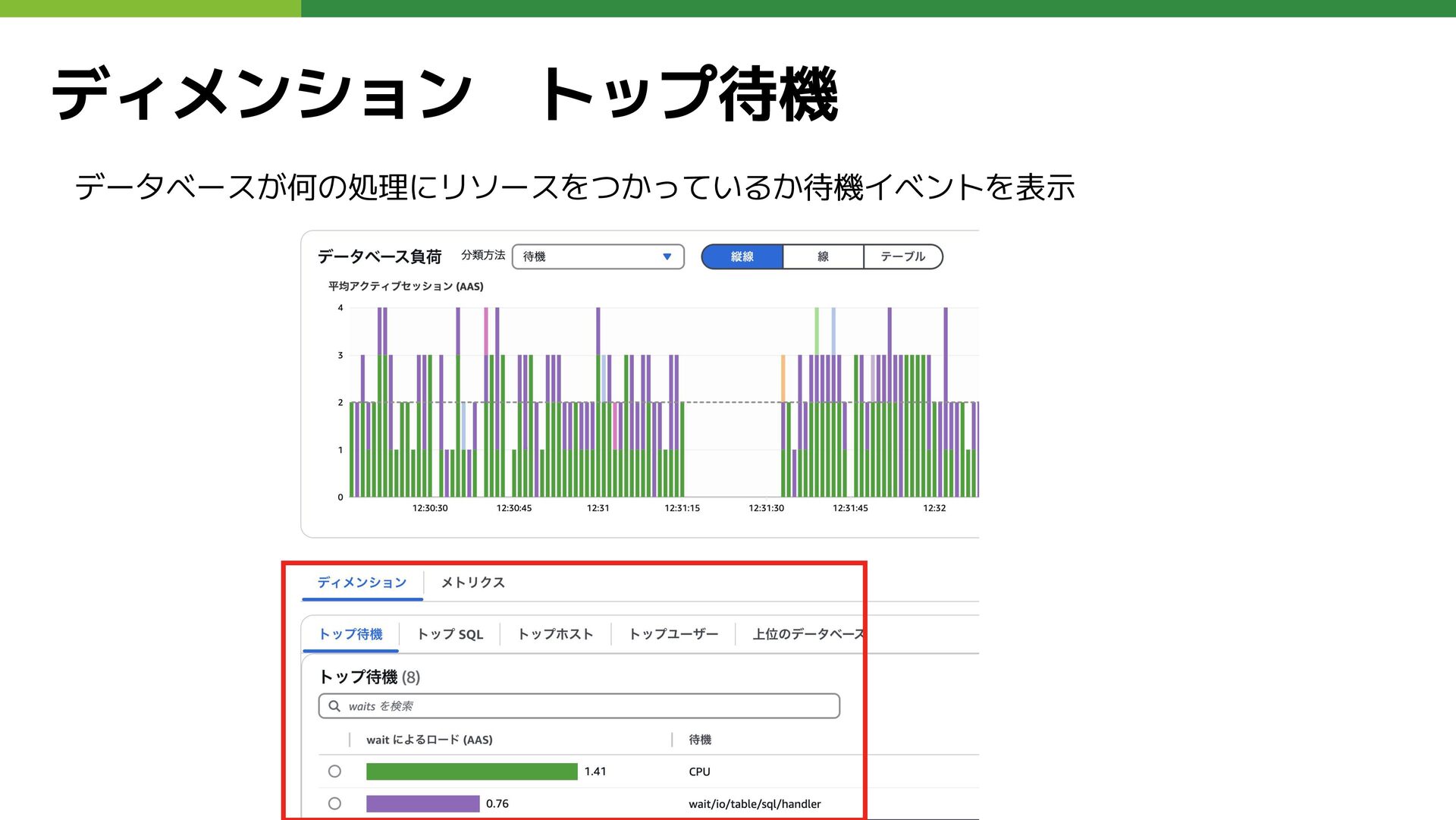
ディメンション トップ待機 データベースが何の処理にリソースをつかっているか待機イベントを表示
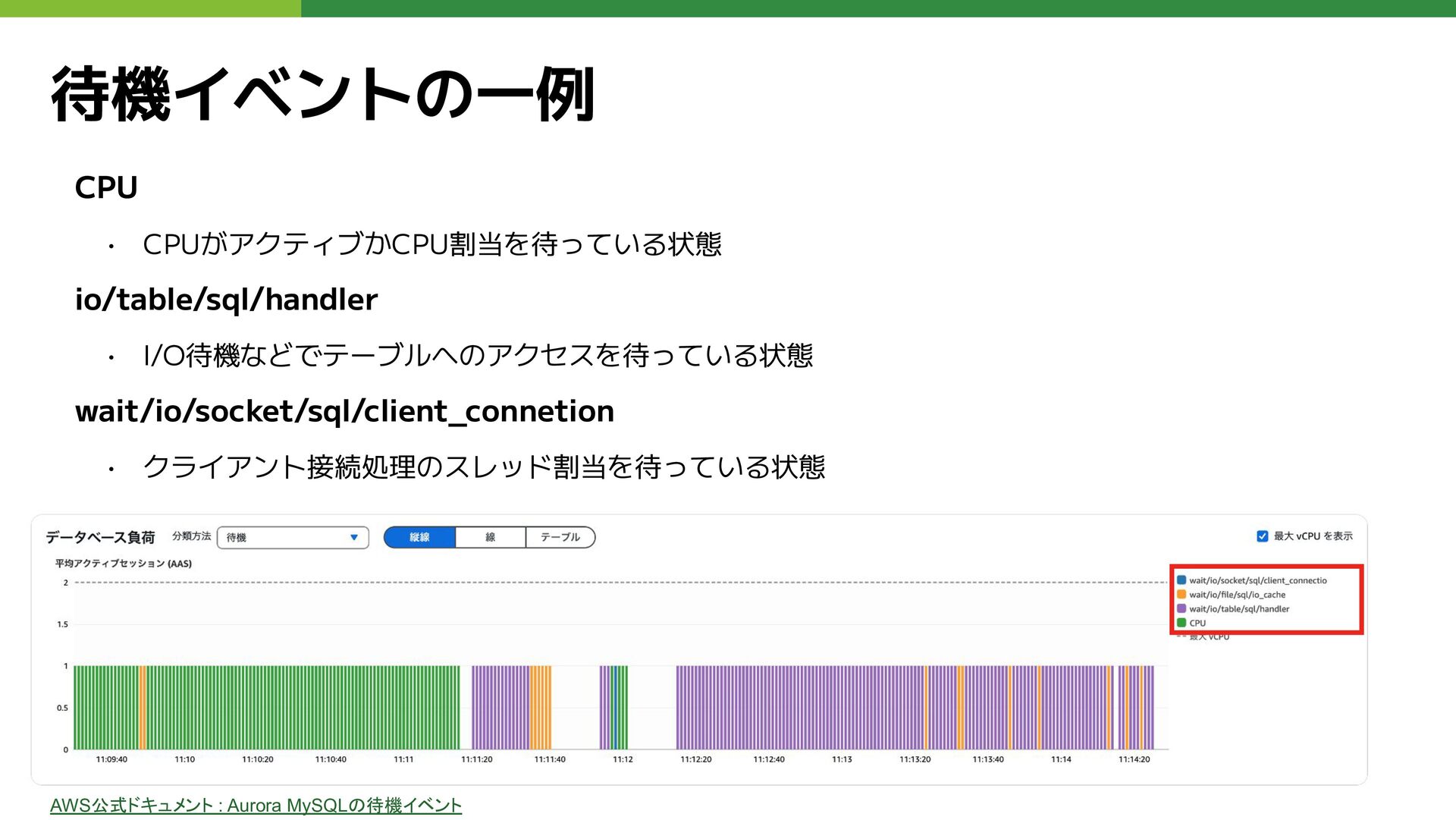
待機イベントの一例 CPU • CPUがアクティブかCPU割当を待っている状態 io/table/sql/handler • I/O待機などでテーブルへのアクセスを待っている状態 wait/io/socket/sql/client_connetion • クライアント接続処理のスレッド割当を待っている状態
AWS公式ドキュメント : Aurora MySQLの待機イベント
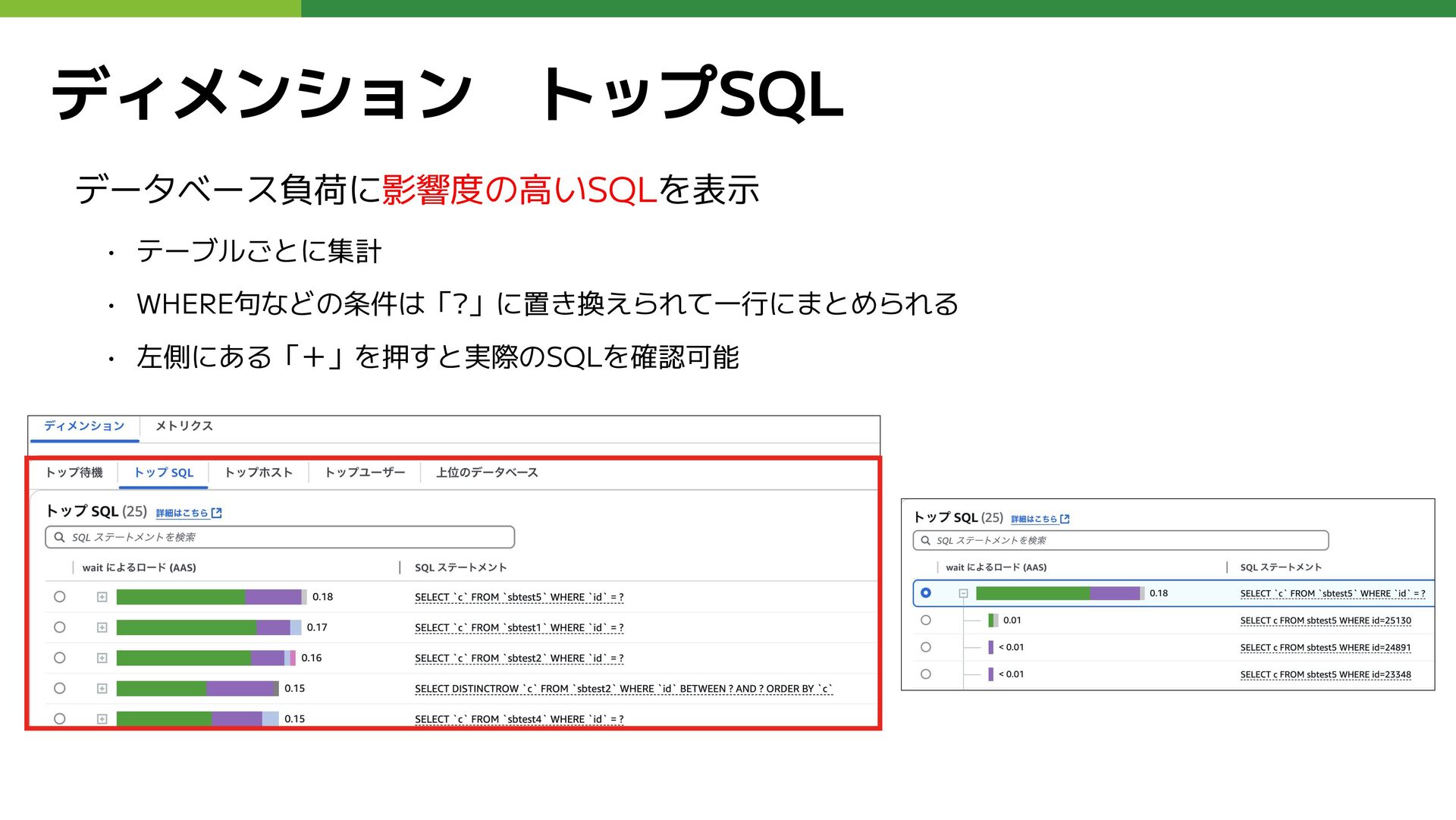
ディメンション トップSQL データベース負荷に影響度の高いSQLを表示 • テーブルごとに集計 • WHERE句などの条件は「?」に置き換えられて一行にまとめられる • 左側にある「+」を押すと実際のSQLを確認可能
Database Insightsをつかった調査の流れ 1. 問題があった時間帯の「平均アクティブセッション(AAS)」がいくつだったか確認 2. 「トップSQL」で影響度の高かったクエリを確認 3. そのクエリの待機イベントを見て、何で時間かかっているかを確認 4. クエリの改善やDBインスタンスの増強などの解決策を検討する
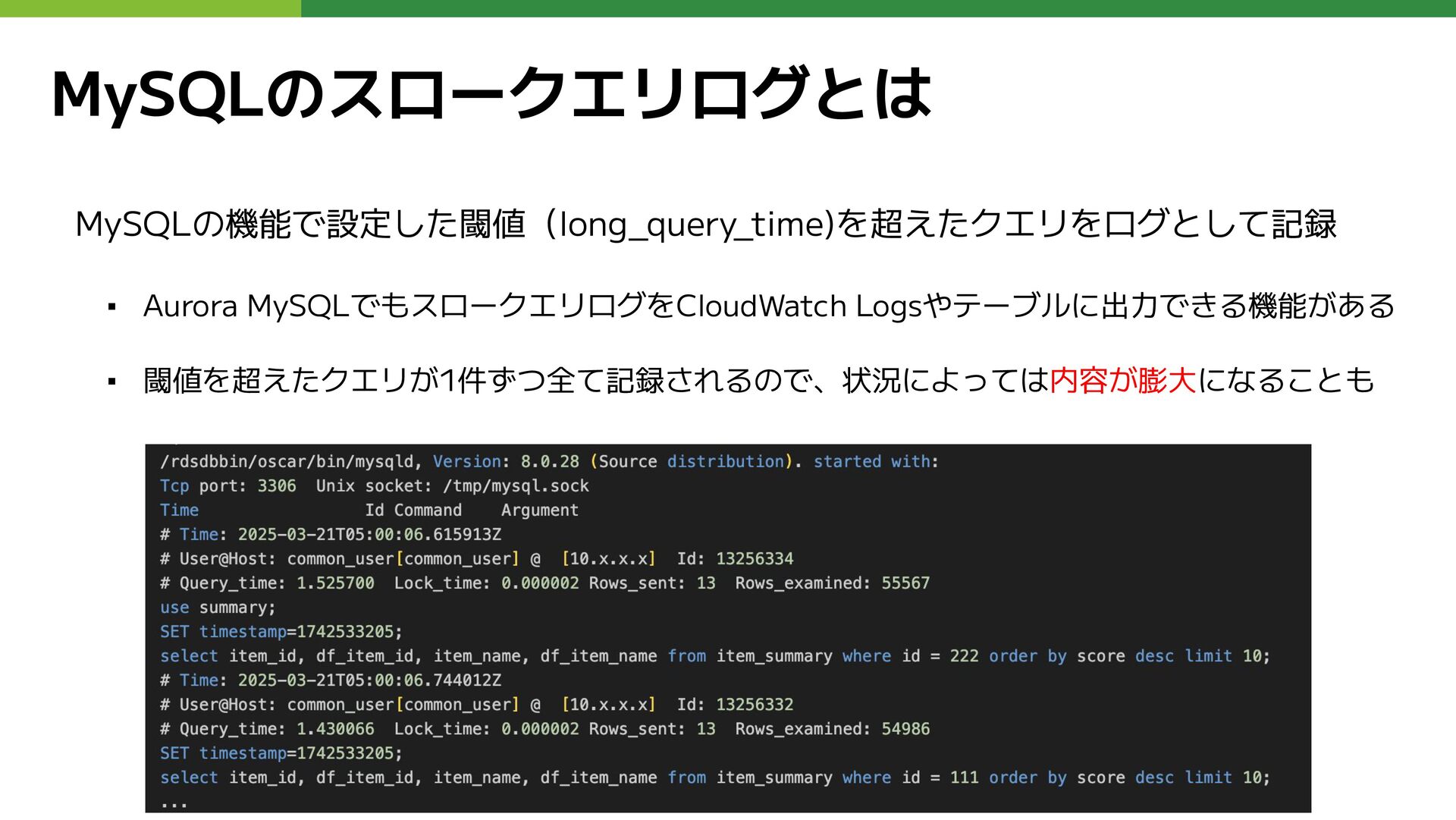
MySQLスロークエリログの調査
MySQLのスロークエリログとは MySQLの機能で設定した閾値(long_query_time)を超えたクエリをログとして記録 ▪ Aurora MySQLでもスロークエリログをCloudWatch Logsやテーブルに出力できる機能がある ▪ 閾値を超えたクエリが1件ずつ全て記録されるので、状況によっては内容が膨大になることも
Database Insightsをつかった調査の流れ 1. 問題があった時間帯の「平均アクティブセッション(AAS)」がいくつだったか確認 2. 「トップSQL」で影響度の高かったクエリを確認 3. そのクエリの待機イベントを見て、何で時間かかっているかを確認 4. クエリの改善やシステムの増強などの解決策を検討する
「クエリの改善ってどうするんだ?」
EXPLAINによるクエリの実行計画調査
EXPLAINとは MySQLがクエリをどのように実行するのかを可視化する機能 • どのテーブルから読み取るか • どのような順序でテーブル結合するか • どのインデックスを使用するか • 一時テーブルやソートが必要か
というようなクエリの実行計画を確認できる
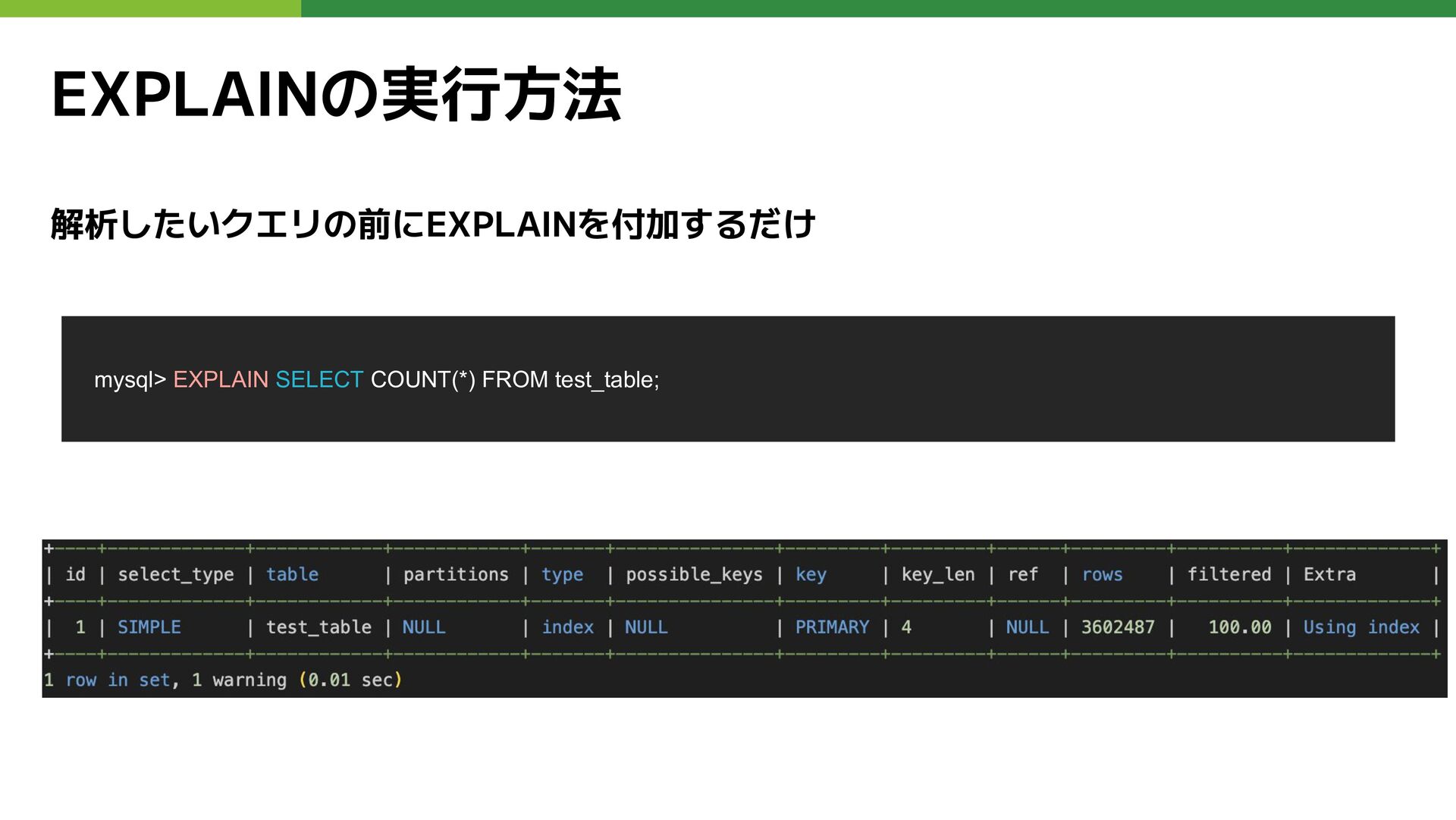
EXPLAINの実行方法 解析したいクエリの前にEXPLAINを付加するだけ mysql> EXPLAIN SELECT COUNT(*) FROM test_table;
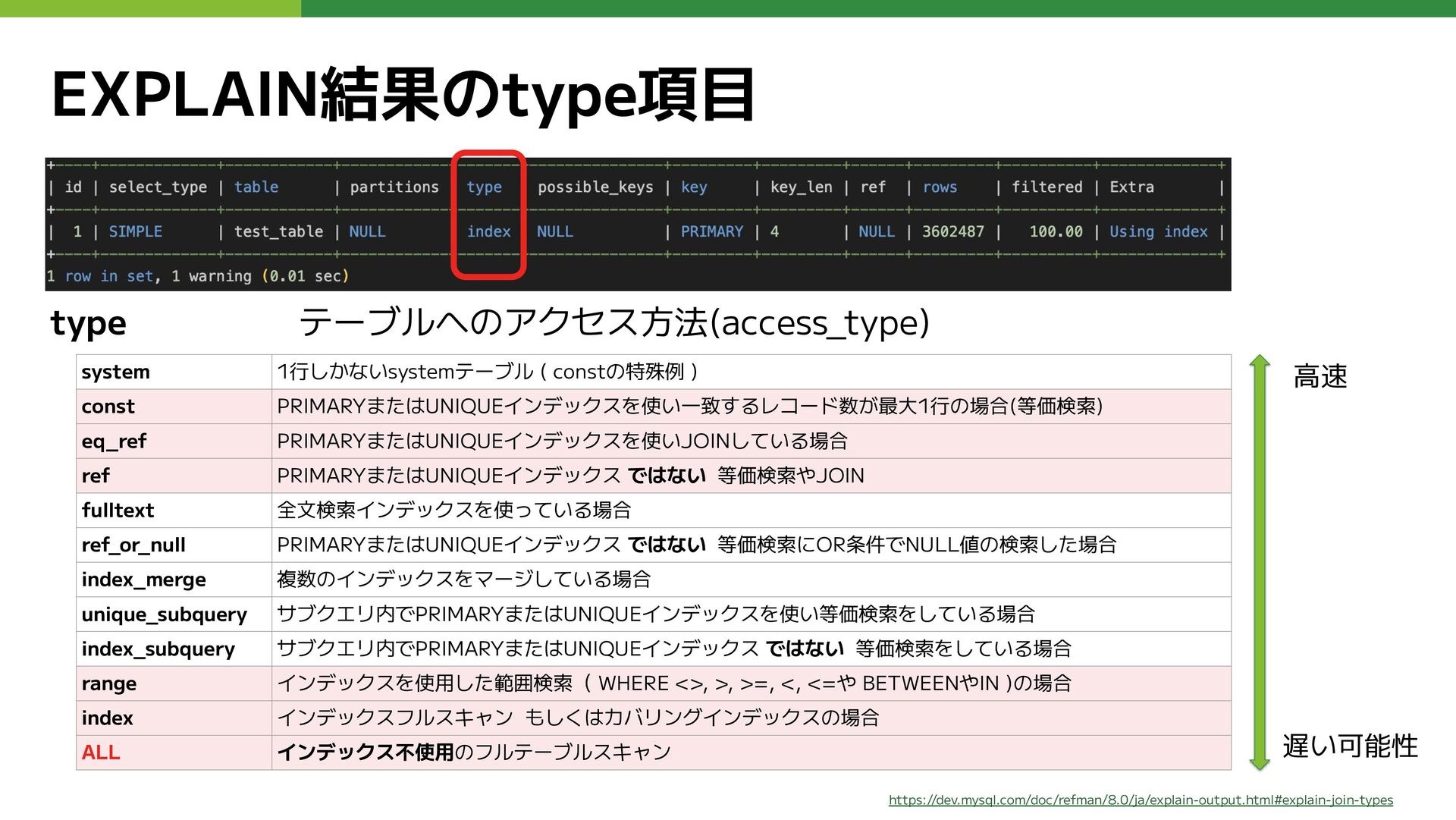
EXPLAIN結果のtype項目 type テーブルへのアクセス方法(access_type) system 1行しかないsystemテーブル ( constの特殊例 )
const PRIMARYまたはUNIQUEインデックスを使い一致するレコード数が最大1行の場合(等価検索) eq_ref PRIMARYまたはUNIQUEインデックスを使いJOINしている場合 ref PRIMARYまたはUNIQUEインデックス ではない 等価検索やJOIN fulltext 全文検索インデックスを使っている場合 ref_or_null PRIMARYまたはUNIQUEインデックス ではない 等価検索にOR条件でNULL値の検索した場合 index_merge 複数のインデックスをマージしている場合 unique_subquery サブクエリ内でPRIMARYまたはUNIQUEインデックスを使い等価検索をしている場合 index_subquery サブクエリ内でPRIMARYまたはUNIQUEインデックス ではない 等価検索をしている場合 range インデックスを使用した範囲検索( WHERE <>, >, >=, <, <=や BETWEENやIN )の場合 index インデックスフルスキャン もしくはカバリングインデックスの場合 ALL インデックス不使用のフルテーブルスキャン https://dev.mysql.com/doc/refman/8.0/ja/explain-output.html#explain-join-types 遅い可能性 高速
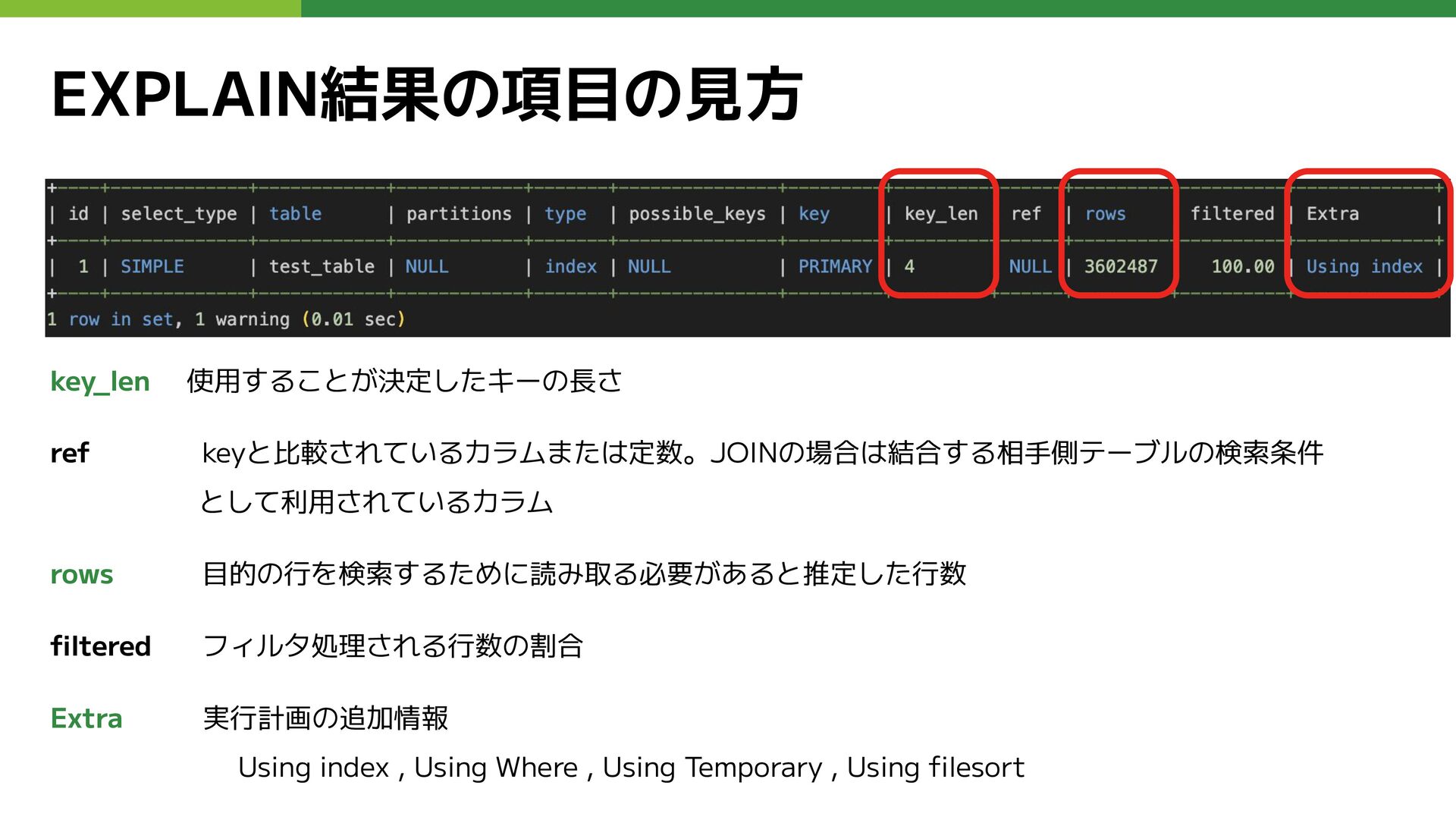
EXPLAIN結果の項目の見方 key_len 使用することが決定したキーの長さ ref keyと比較されているカラムまたは定数。JOINの場合は結合する相手側テーブルの検索条件 として利用されているカラム rows 目的の行を検索するために読み取る必要があると推定した行数 filtered フィルタ処理される行数の割合
Extra 実行計画の追加情報 Using index , Using Where , Using Temporary , Using filesort
EXPLAINを見たらまずこの3つに注意 (※今日はこれだけでOK) • type が ALL インデックスが使われていないフルテーブルスキャンで重い事が多い • rowsが数十万件~数百万件 読み取り対象が多すぎる。インデックスが効いていないか、条件が広すぎる
• Extraに Using temporary や Using filesort 一時テーブル作成やソート処理が発生。データ量が多いと急激に重くなる
EXPLAINをつかったクエリ解析の簡単な例
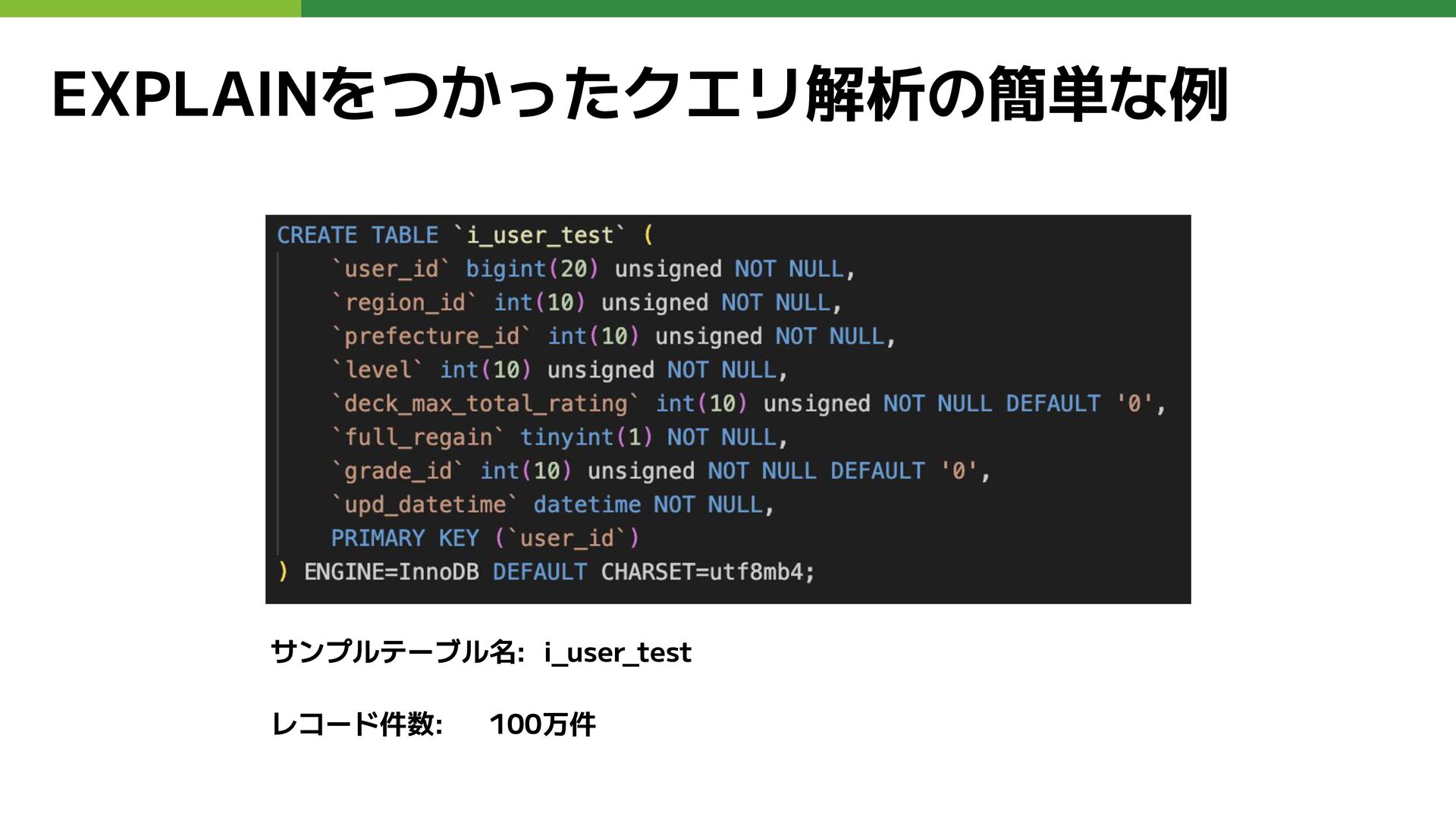
EXPLAINをつかったクエリ解析の簡単な例 サンプルテーブル名: i_user_test レコード件数: 100万件
インデックスが全く設定されていない場合 type ALL rows 90万件 Extra Using Where WHERE句はつかっているが、全件フルスキャンとなっている EXPLAIN結果
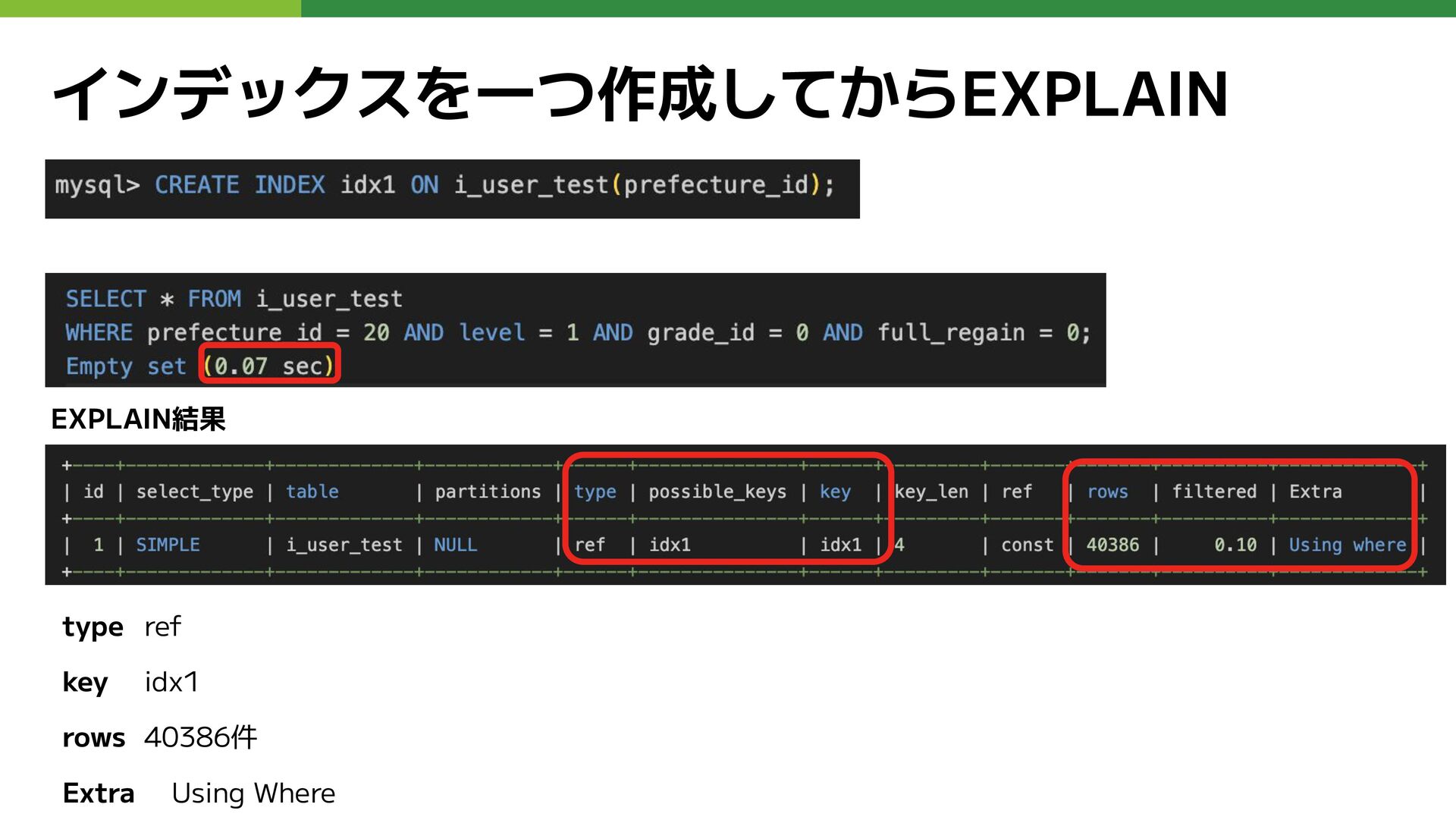
インデックスを一つ作成してからEXPLAIN type ref key idx1 rows 40386件 Extra Using Where
EXPLAIN結果
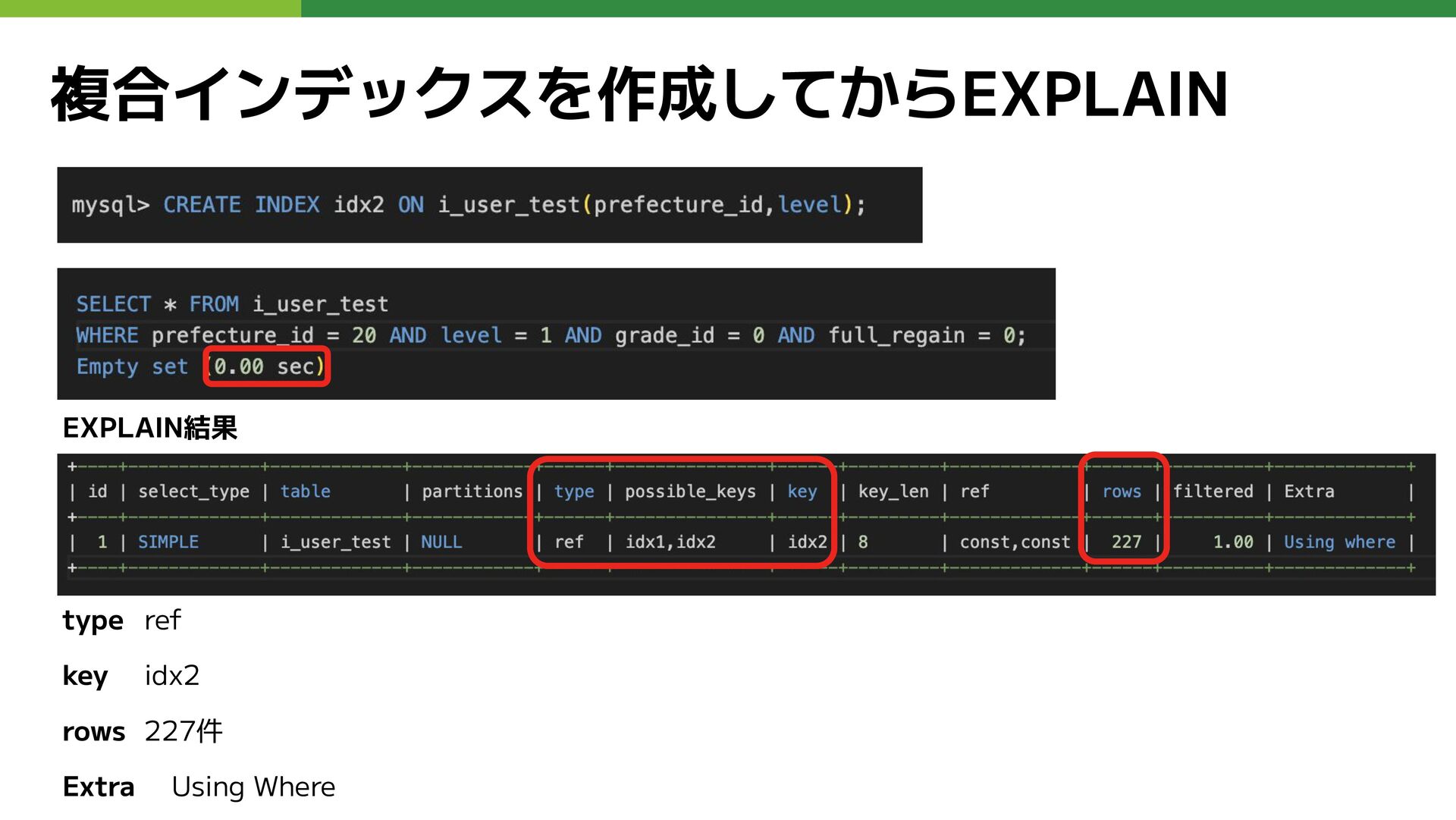
複合インデックスを作成してからEXPLAIN type ref key idx2 rows 227件 Extra Using Where
EXPLAIN結果
さらに詳しいEXPLAINの解説や、MySQLのクエリ調査 の方法は2025年の新卒研修資料をチェック! 【2025年度新卒技術研修】100分で学ぶ サイバーエージェントのデータベース 活用事例とMySQLパフォーマンス調査
Google Cloud Spanner環境での調査
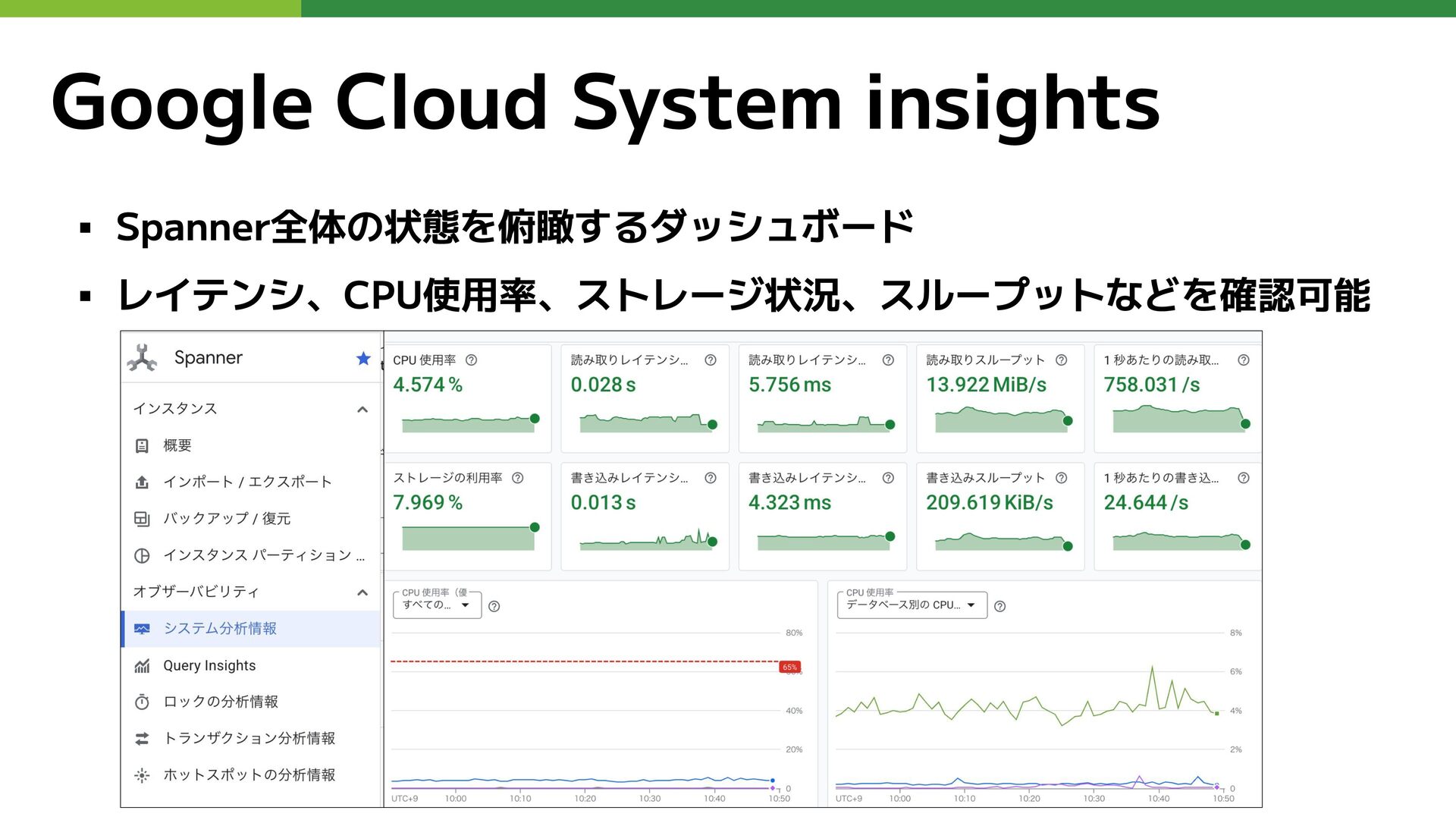
Google Cloud System insights ▪ Spanner全体の状態を俯瞰するダッシュボード ▪ レイテンシ、CPU使用率、ストレージ状況、スループットなどを確認可能
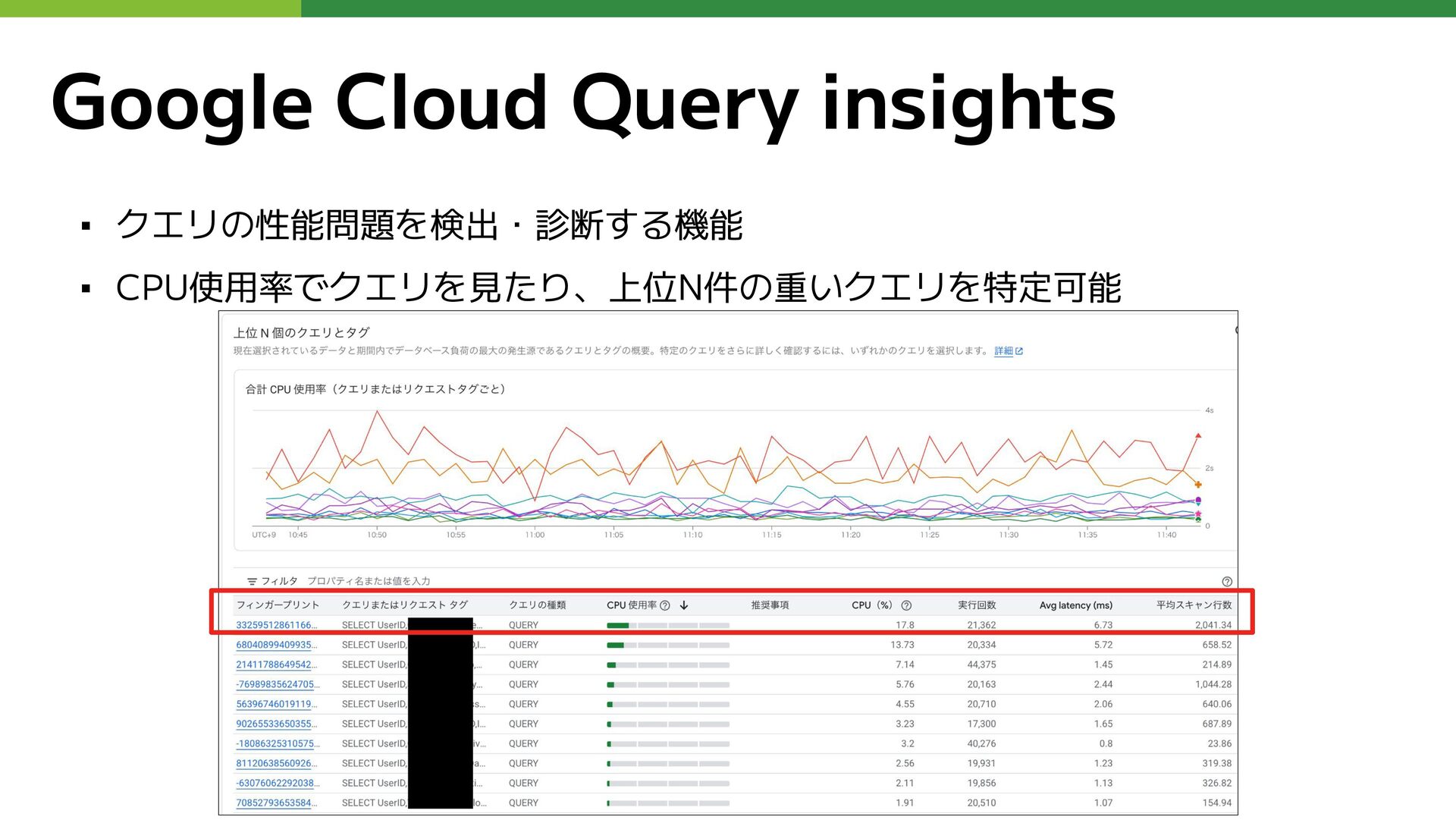
Google Cloud Query insights ▪ クエリの性能問題を検出・診断する機能 ▪ CPU使用率でクエリを見たり、上位N件の重いクエリを特定可能
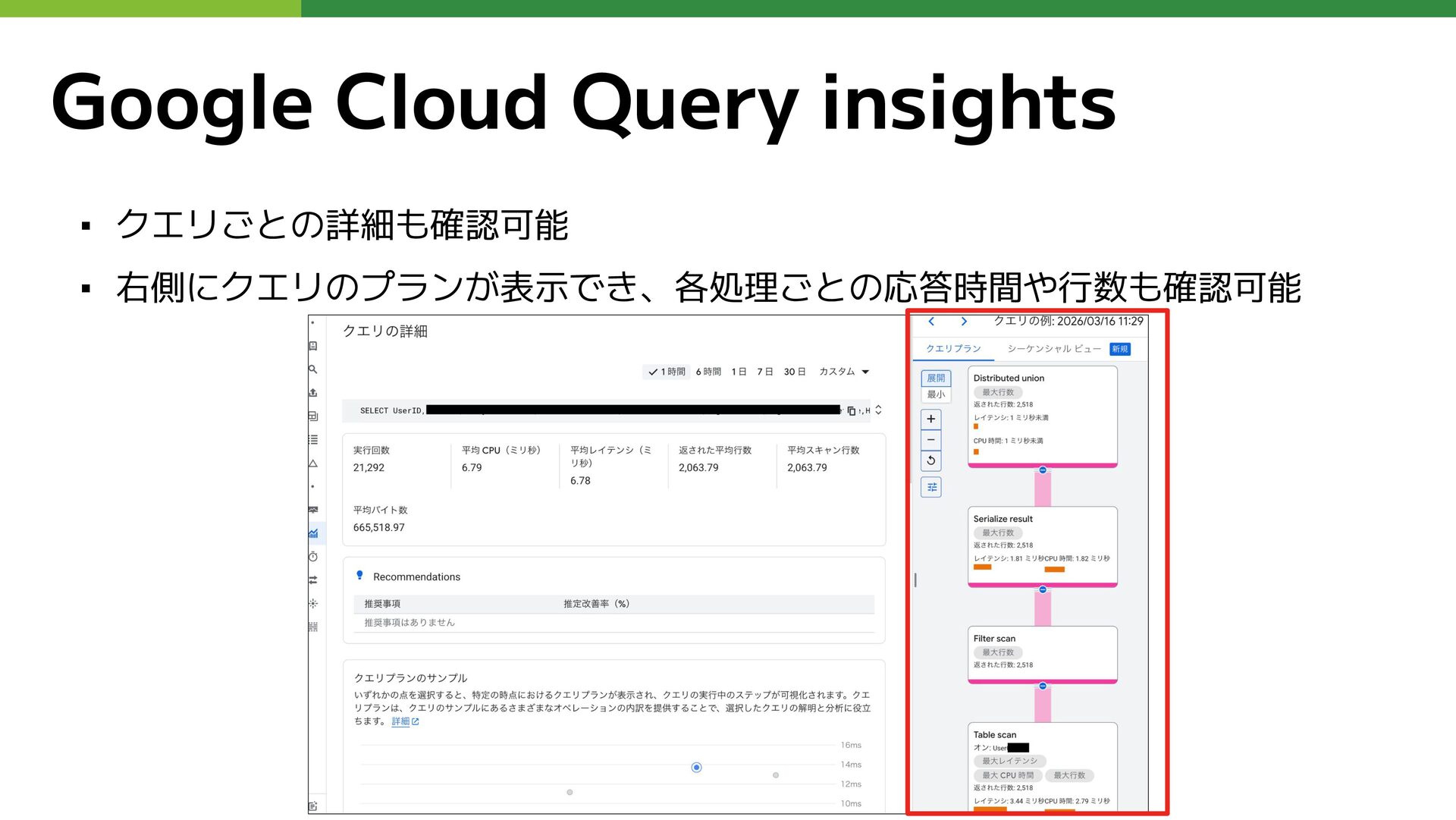
Google Cloud Query insights ▪ クエリごとの詳細も確認可能 ▪ 右側にクエリのプランが表示でき、各処理ごとの応答時間や行数も確認可能
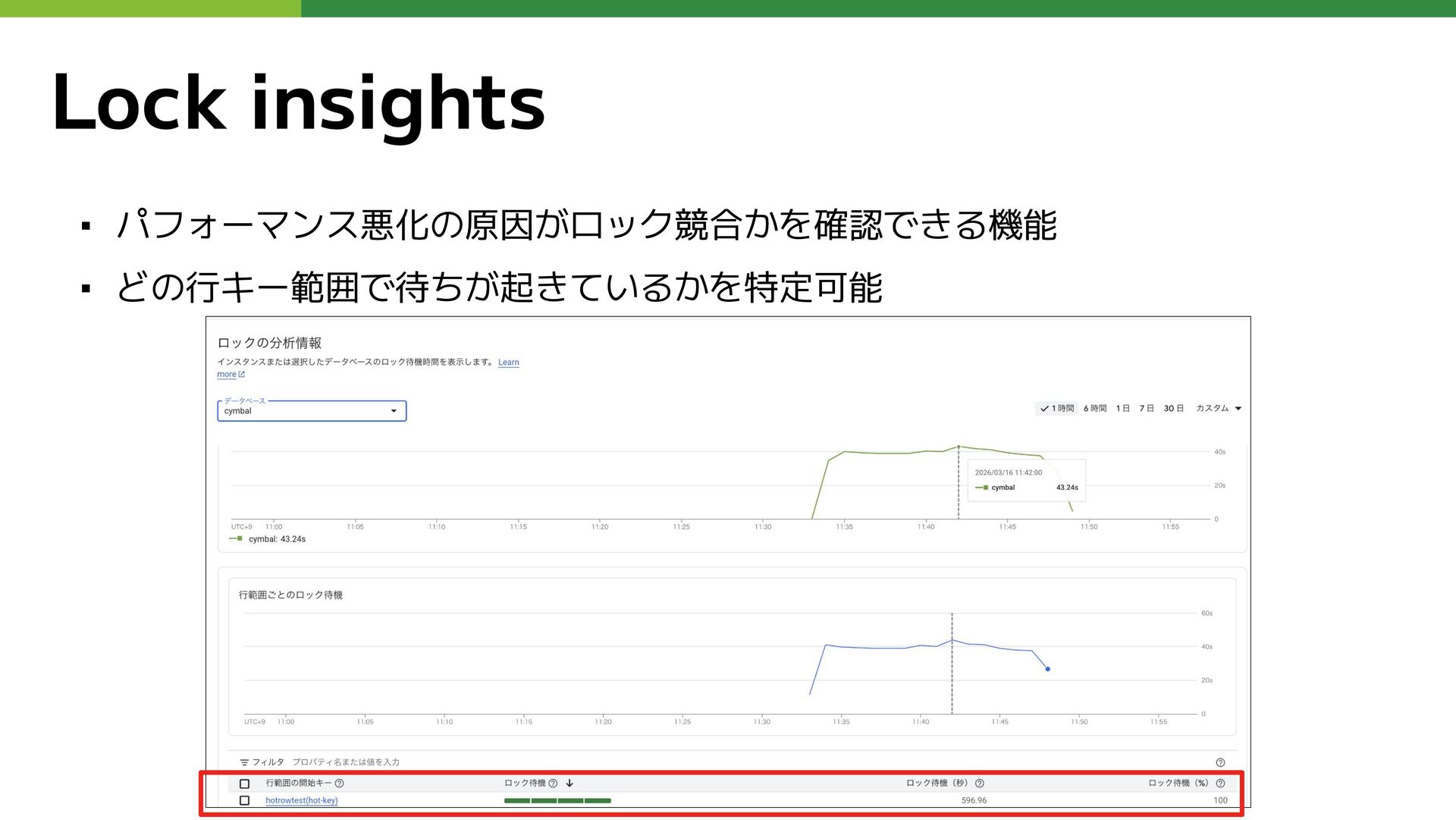
Lock insights ▪ パフォーマンス悪化の原因がロック競合かを確認できる機能 ▪ どの行キー範囲で待ちが起きているかを特定可能
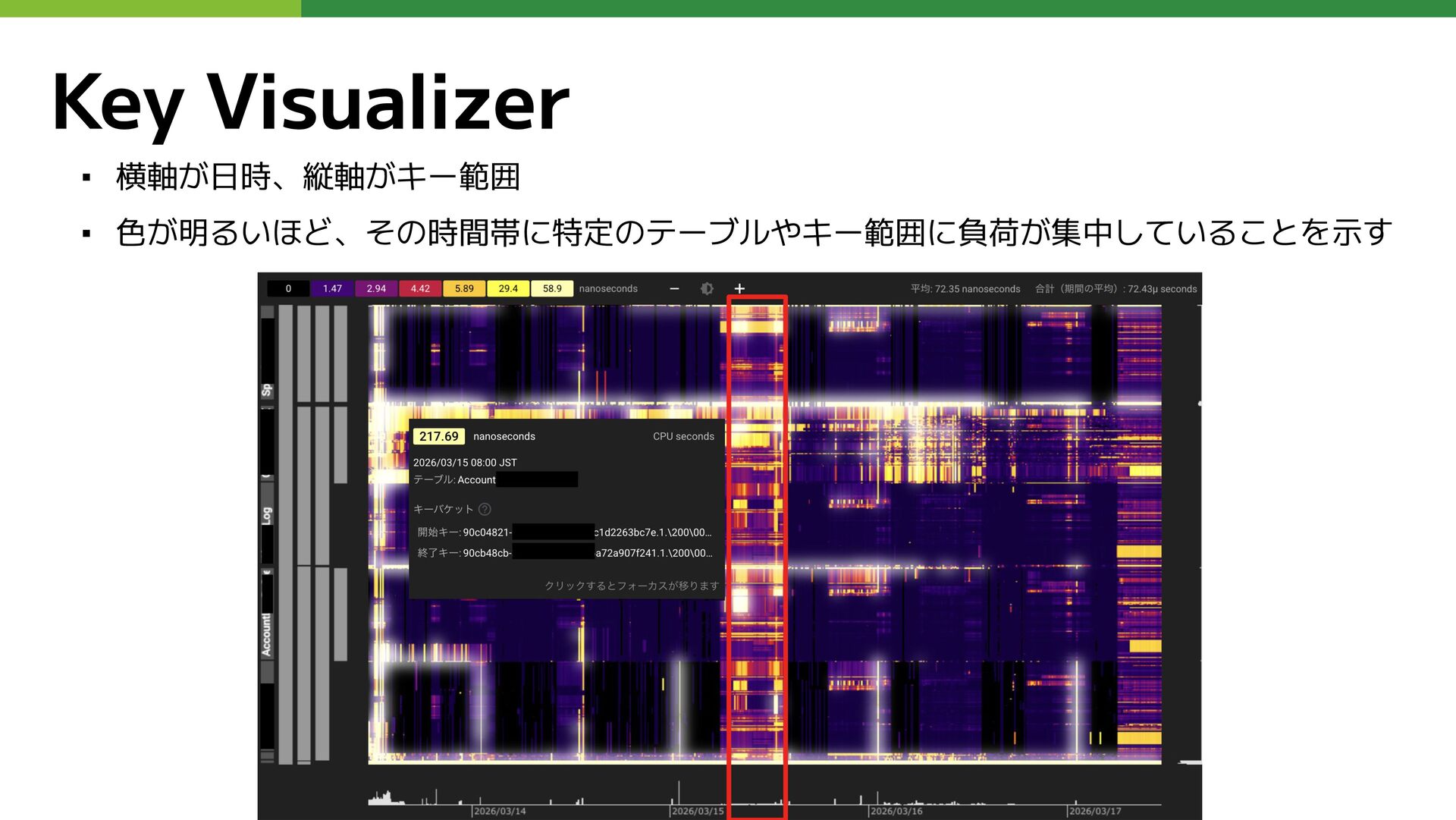
Key Visualizer ▪ データアクセスパターンを可視化する機能 ▪ 偏ったアクセスを発見し、スキーマ設計やキー設計の改善につなげる
Key Visualizer ▪ 横軸が日時、縦軸がキー範囲 ▪ 色が明るいほど、その時間帯に特定のテーブルやキー範囲に負荷が集中していることを示す
Google Cloud Spannerでの調査の流れ 1. System insightsでCPU使用率などSpanner全体の状況を俯瞰して確認する 2. Query insightsで重いクエリの上位を確認し、重いクエリを特定し調査する 3.
Lock insightsでロック競合がおきていなかったか確認する 4. Key Visualizerで問題のある偏ったデータアクセスが発生していなかったか確認する
AIエージェントを活用したデータベースの調査
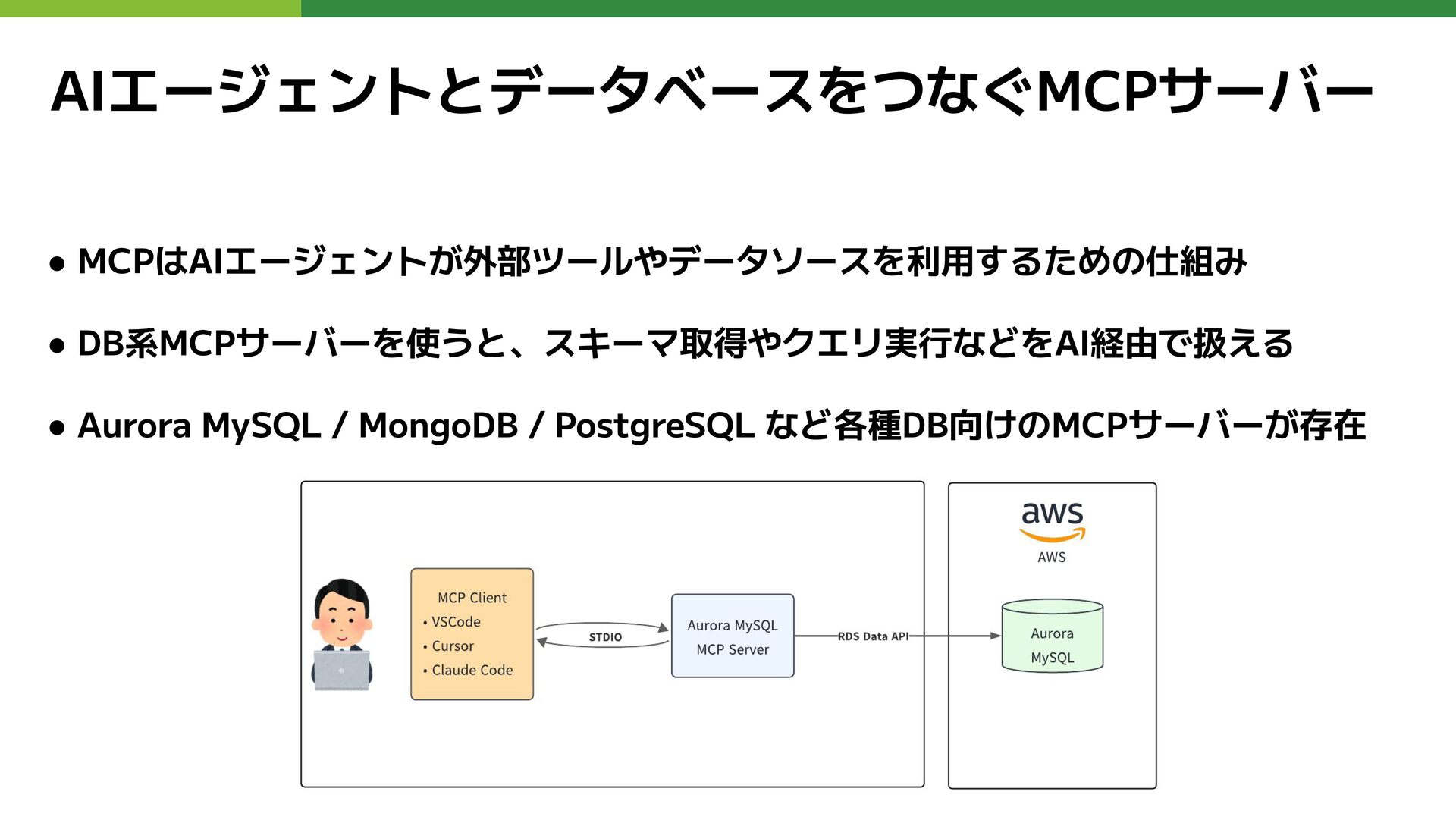
AIエージェントとデータベースをつなぐMCPサーバー • MCPはAIエージェントが外部ツールやデータソースを利用するための仕組み • DB系MCPサーバーを使うと、スキーマ取得やクエリ実行などをAI経由で扱える • Aurora MySQL / MongoDB
/ PostgreSQL など各種DB向けのMCPサーバーが存在
Aurora MySQL MCPサーバーを使った調査のイメージ • Aurora MySQLに対して自然言語から SQL を作ってクエリを実行できる(※次ページに注意事項有) • Database
Insights などで遅いクエリを特定したあとの調査を補助 Usersテーブルの◯◯クエリが遅いから調べて Claude Code Usersテーブルの構成とデータ状況を調べます Aurora MySQL MCPサーバー (AIエージェント) Aurora MySQL クラスタ
• 本番環境に接続する場合は読み取り専用にする ◦ 書き込み可能だと、意図しない破壊的な更新クエリが実行される可能性がある ただし、読み取り専用でもシステムに悪影響が出る高負荷なクエリが実行される可能性はある (本番環境と同じデータをもつ隔離環境で使えれば理想的) • ベンダーなど公式から提供されているMCPサーバーの利用を推奨 ◦ 個人作成などの非公式なMCPサーバーは、安全性を自身で確認する
• AIからのアドバイスを鵜呑みにしない ◦ 対応の最終判断は人間が行うこと。判断できる技術力を身につけましょう (AIエージェント) データベース系MCPサーバーの注意点 クエリ実行が遅いのはデータ件数が多いせいなので全件消します (AIエージェント) 調査のために全スキーマの全テーブルをSELECTします
4章のまとめ • AWS環境ならDatabase Insightsという機能で便利に調査が可能 • 遅いクエリが特定できたらEXPLAIN でクエリの実行計画を調査 • Google CloudにもQuery
InsightsやKey Visualizerなどの便利な調査機能がある • データベース系のMCPサーバーをつかうと、AIが調査の補助をしてくれる - 便利だが利用には注意が必要
本日の研修のまとめ
研修のまとめ • サイバーエージェントではRDBMS,NoSQL含め複数のデータベースが活用されている サービスごとの要件にあったデータベースを採用 特に社内で採用率が高いのがRDBMSのMySQL • データベースで起きやすい問題とその対応事例 設計の変更やクエリの改善によって、パフォーマンス改善やサーバコスト削減につながる NewSQLでも新作ゲームリリースのような大量アクセスが来る場合は事前準備が重要 •
データベースのパフォーマンス調査には便利な手法がある Database Insights、MySQLスロークエリログ、EXPLAIN Google Cloud System insights、Query Insights、Lock insigts、Key Visualizer、MCP • AIからの提案も判断できる技術力を身につけましょう
現時点で完全理解できなくてOK チームに配属後、今日の内容を思い出して資料を活用してください もう一度...
本日の内容をちゃんと理解したい人におすすめの書籍
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}