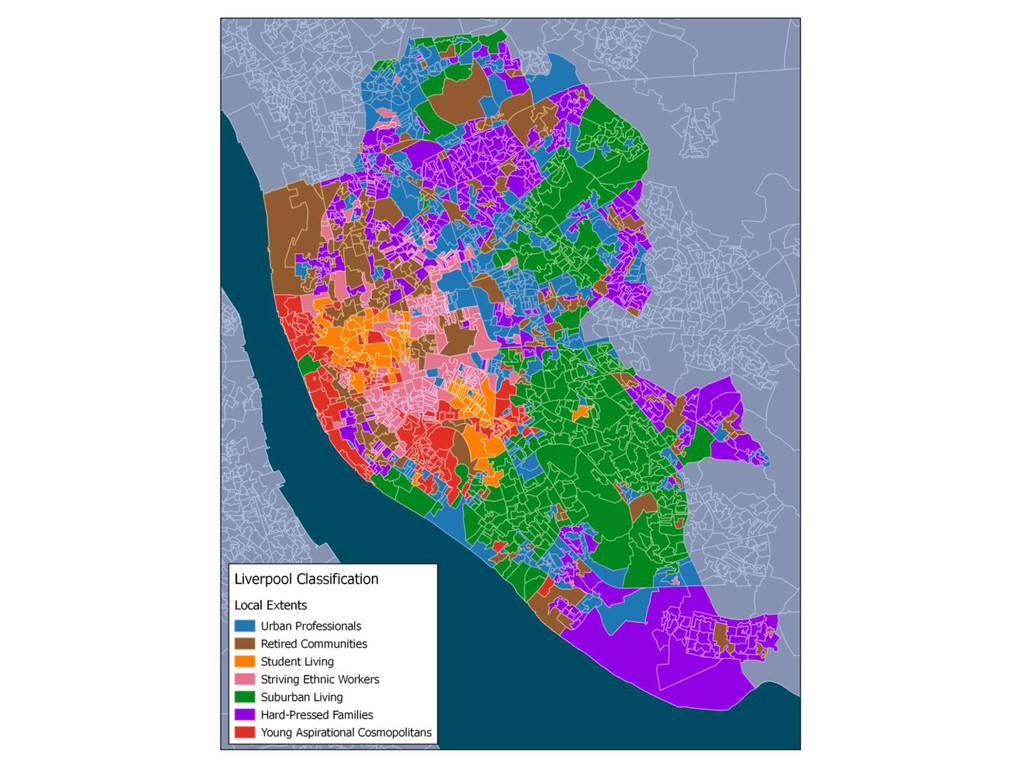
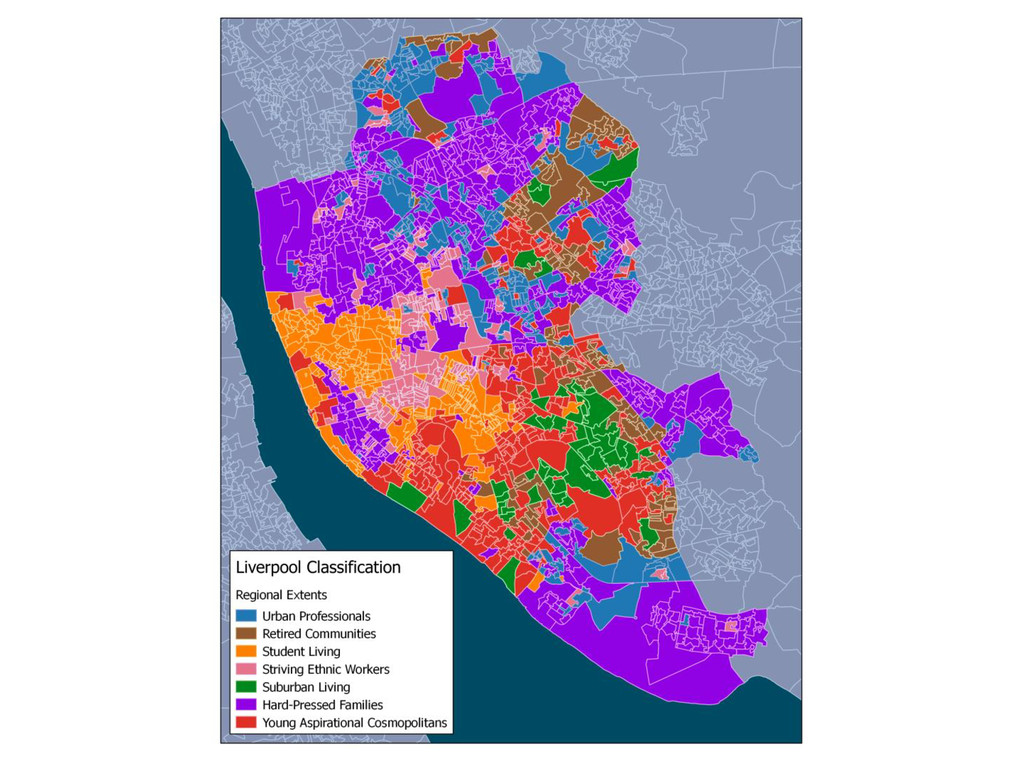
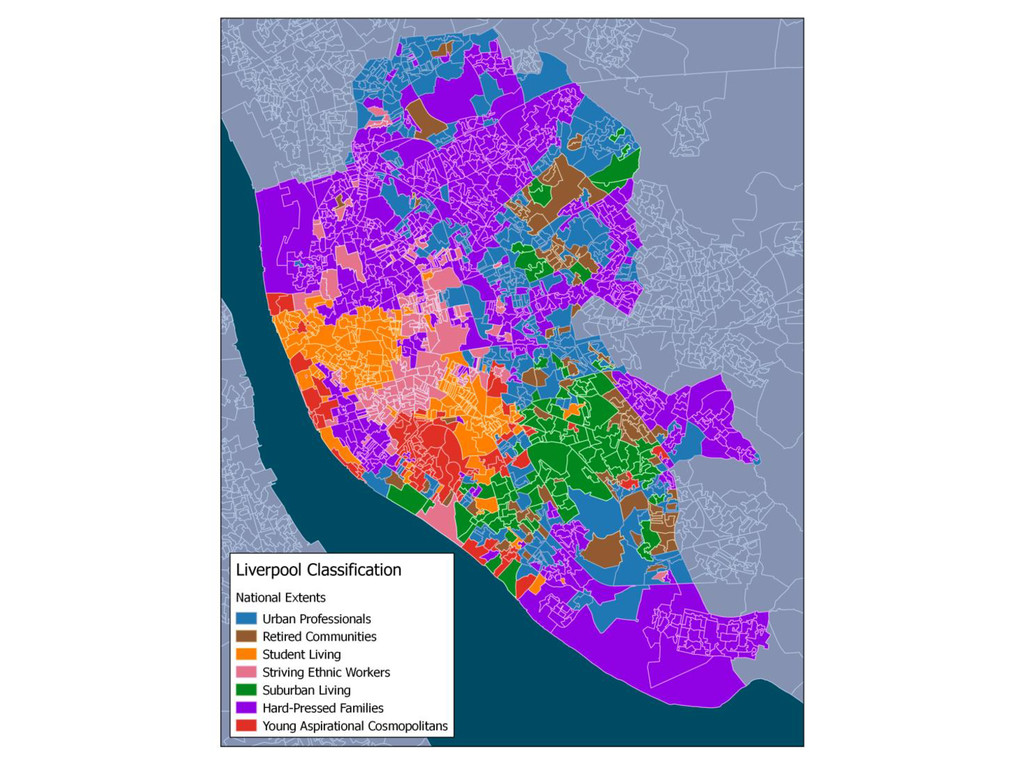
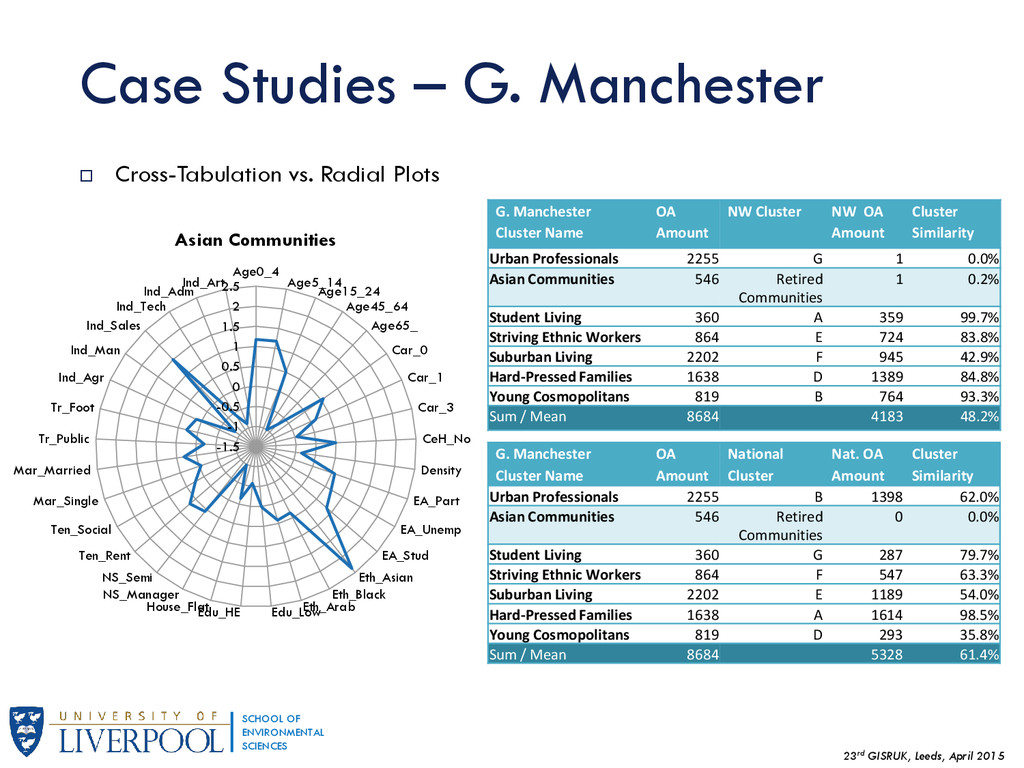
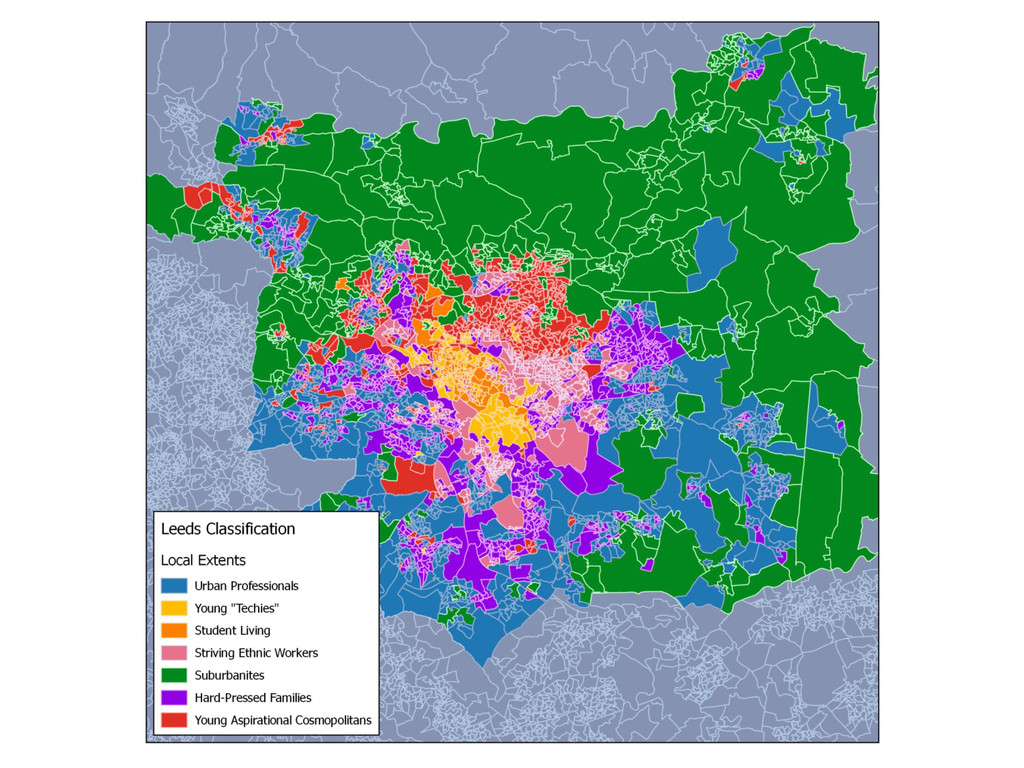
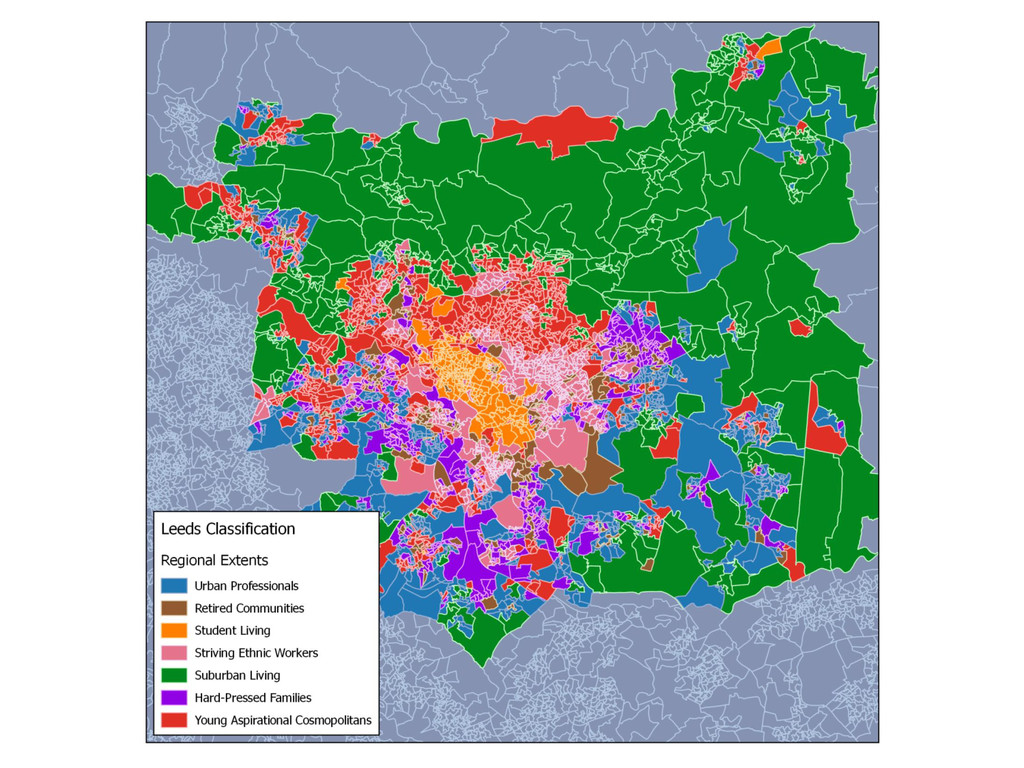
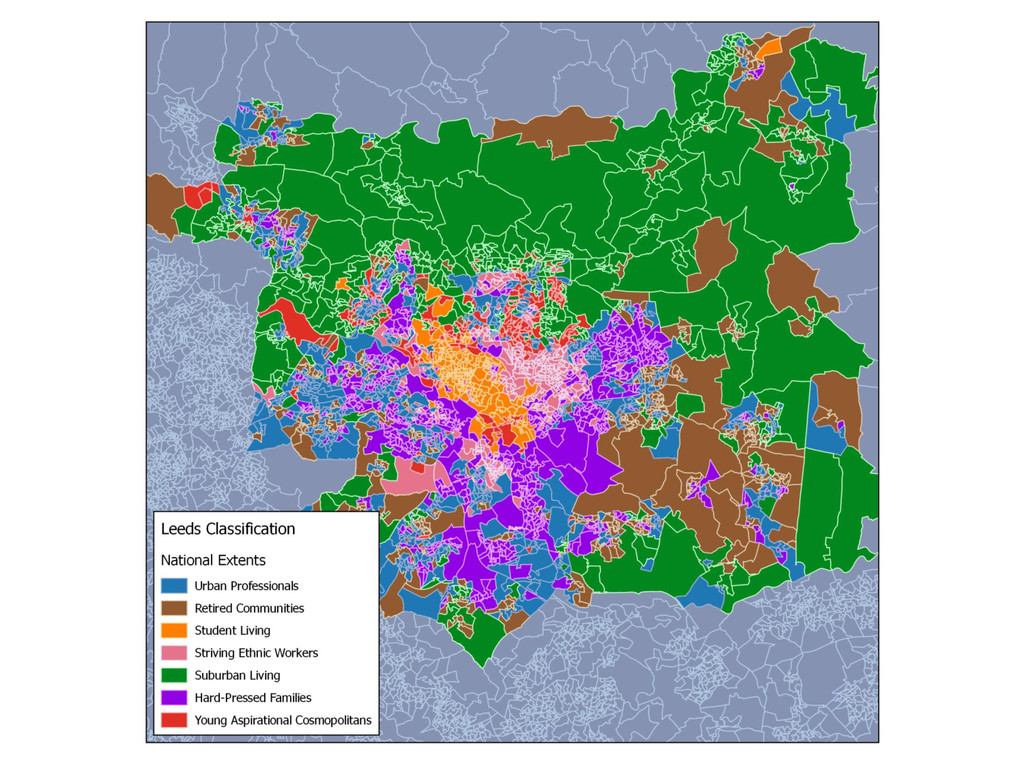
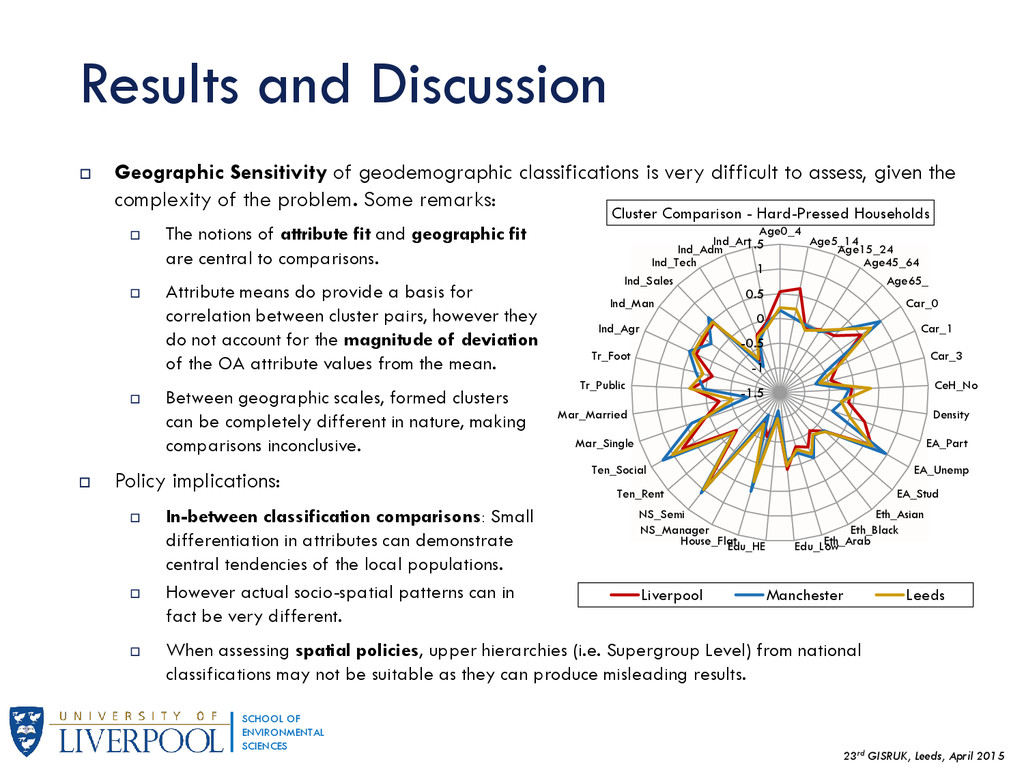
This is the first part of a wider research regarding the Geographic Sensitivity of socio-spatial patterns, by examining the case studies of Liverpool, Manchester and Leeds, along with some preliminary findings of a more generalised approach of socio-spatial pattern homogeneity. The aim of this wider research is to produce geographic extents that maximize local socio-spatial variation - essentially a MAUP approach.
Presented at the GIS Research UK Conference in Leeds, April 2015 and awarded by CASA-UCL as the best paper in Spatial Analysis.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
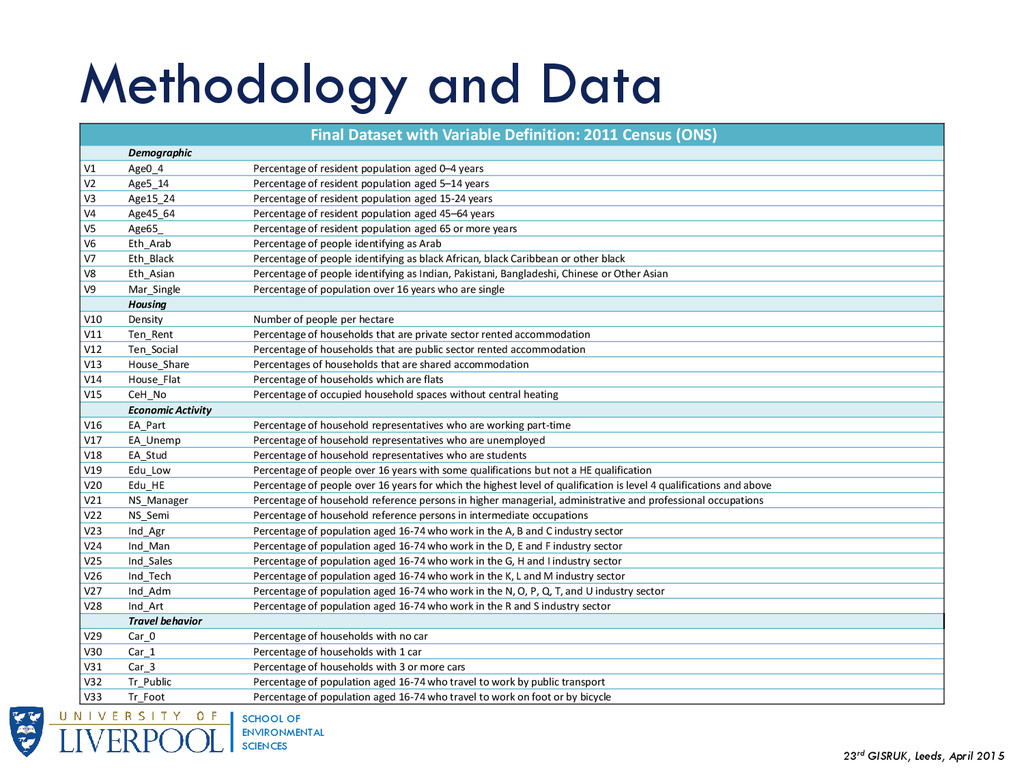{kind=link}
{kind=link}
{kind=link}
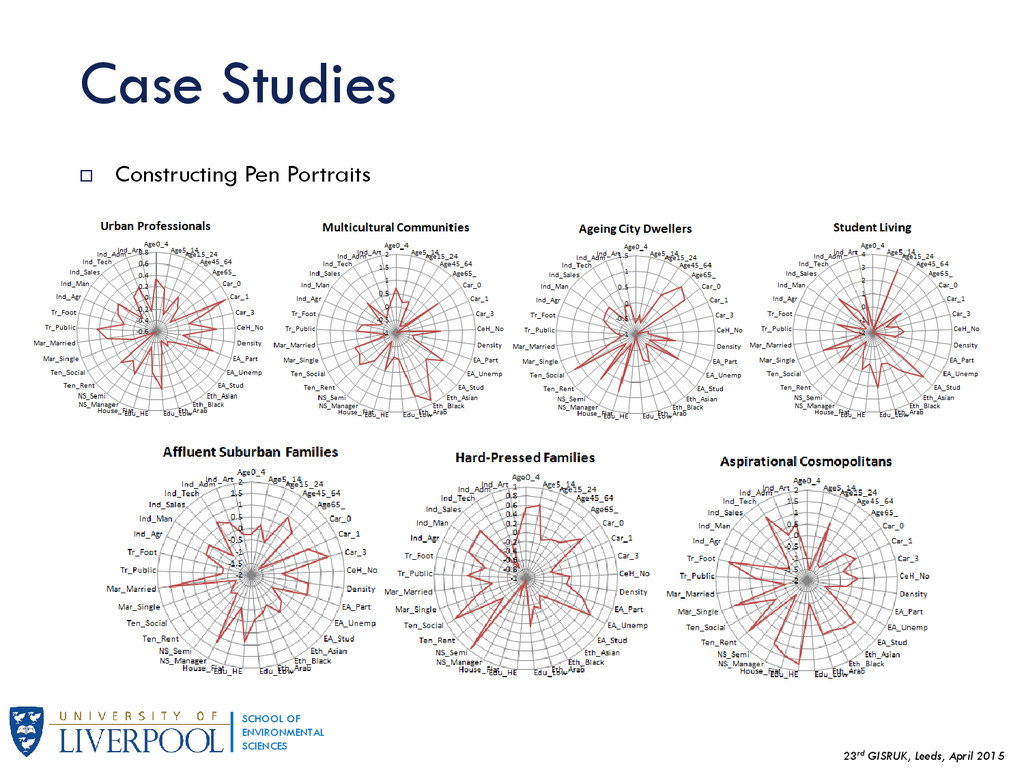{kind=link}
{kind=link}
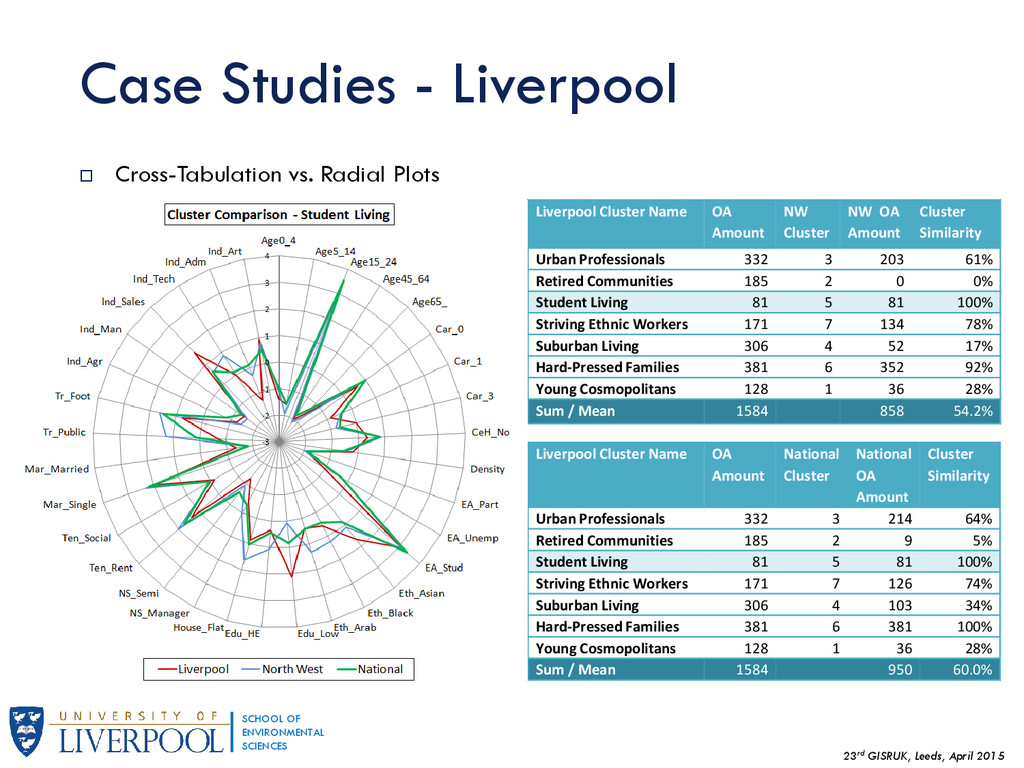{kind=link}
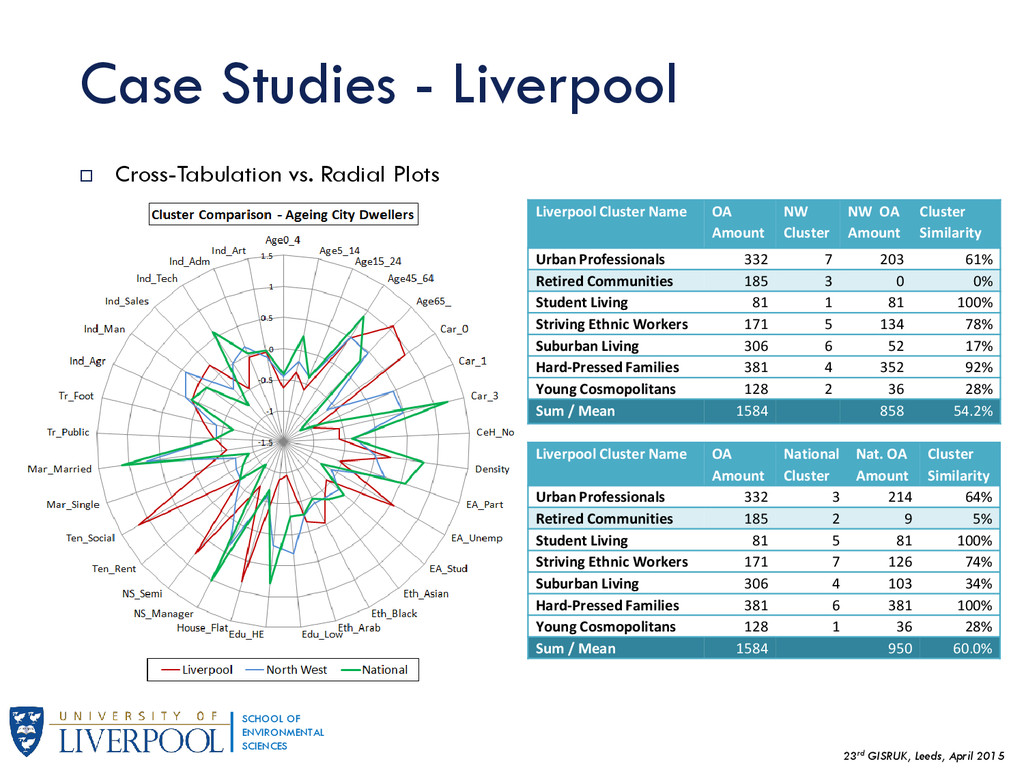{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
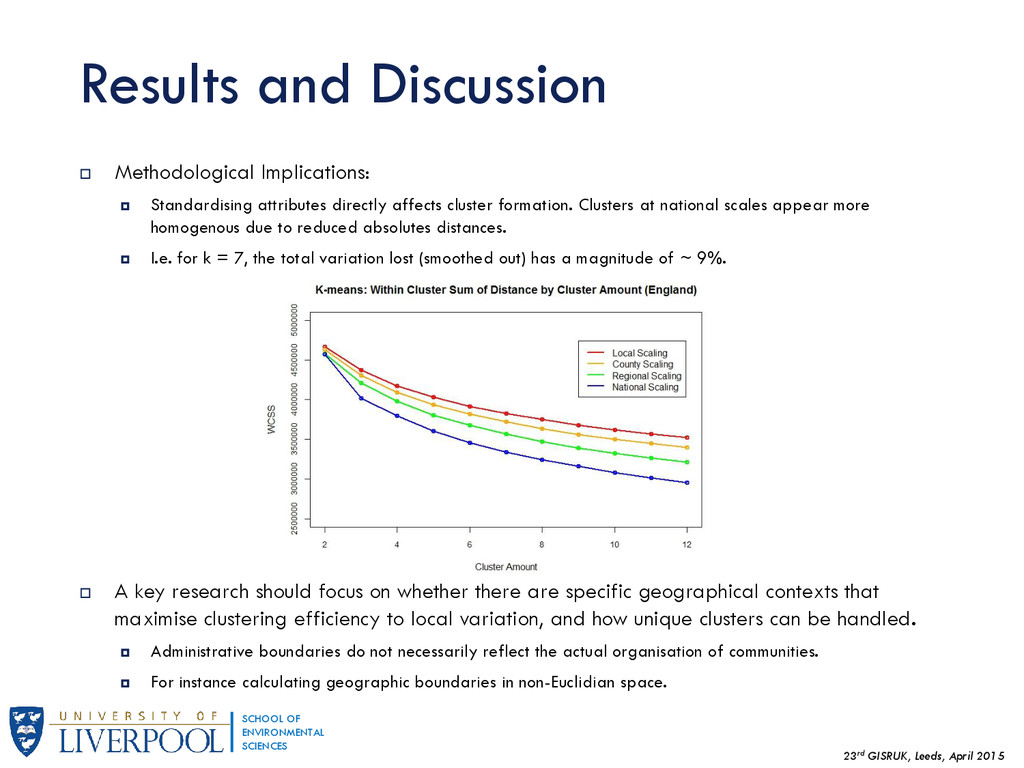{kind=link}
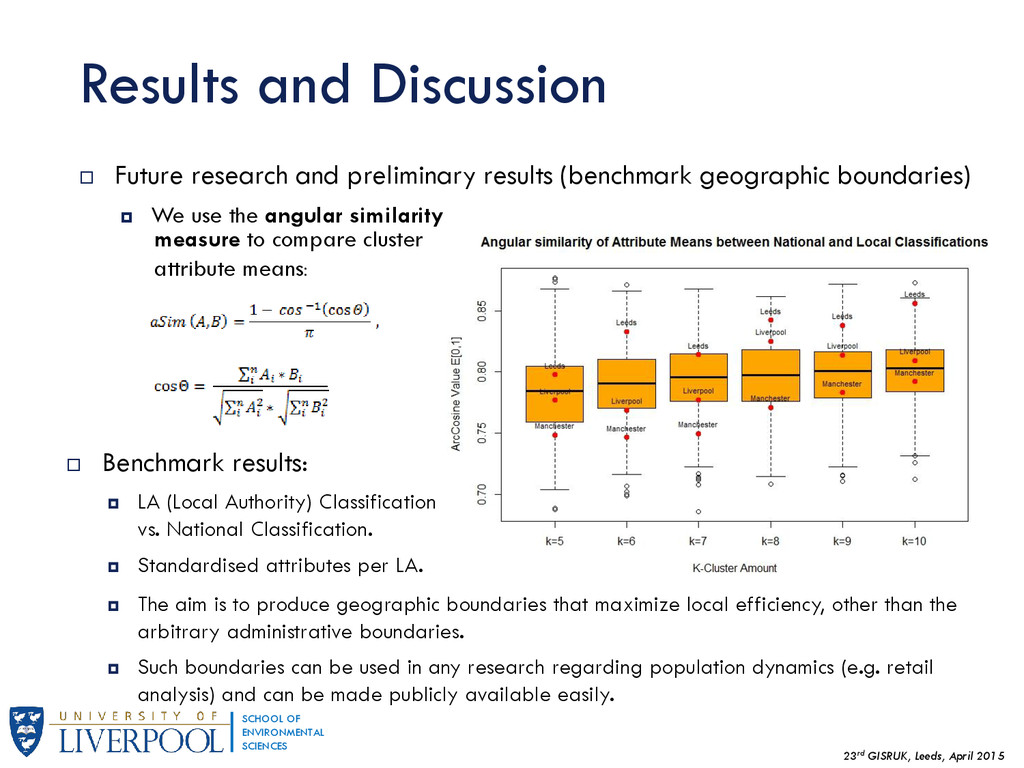{kind=link}
![Thank you for your time [email protected] https://speakerdeck.com/dblalex Acknowledgements: This work](https://files.speakerdeck.com/presentations/4cbeaa9241664567af64f756d1415b37/slide_28.jpg){kind=link}