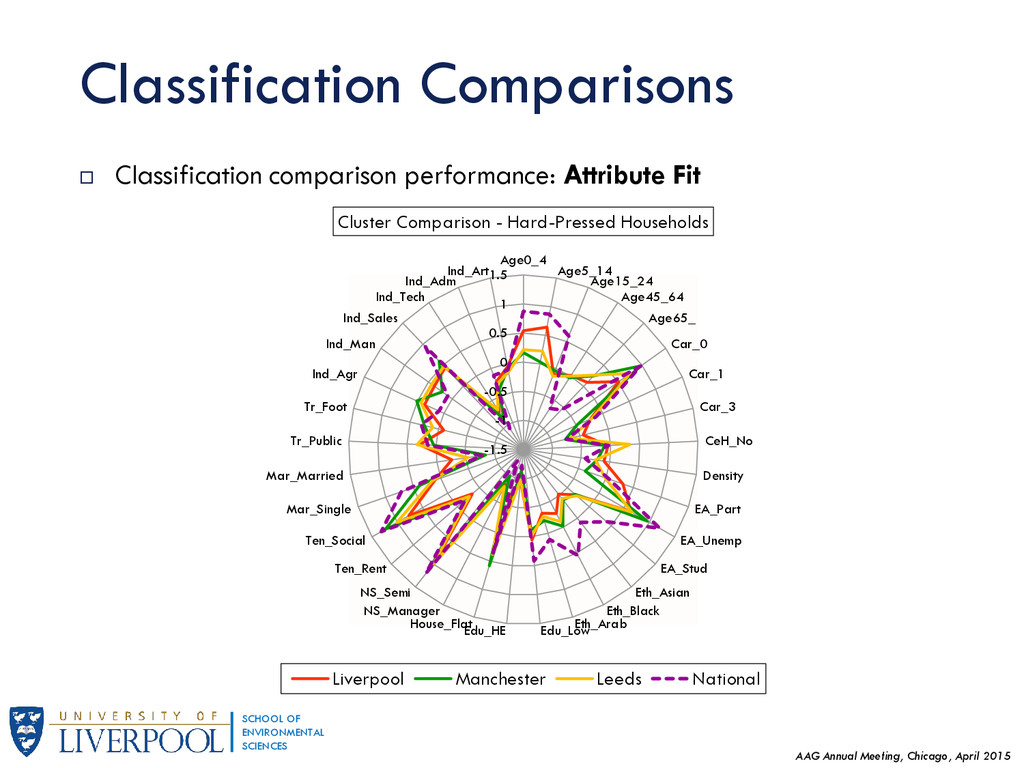
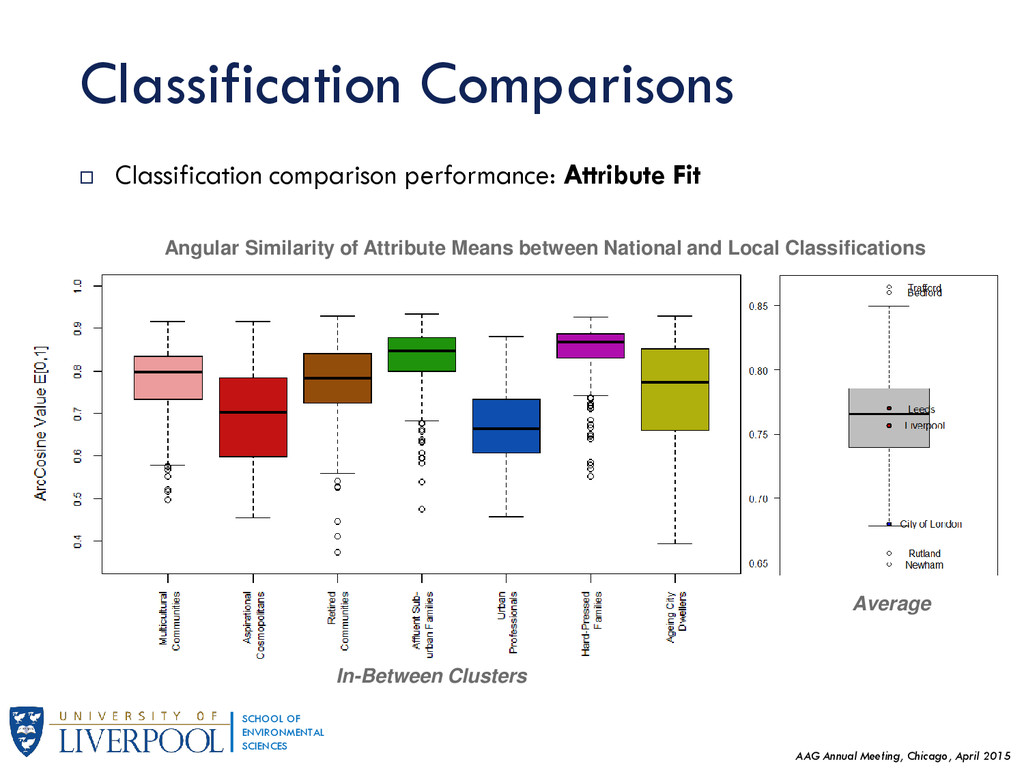
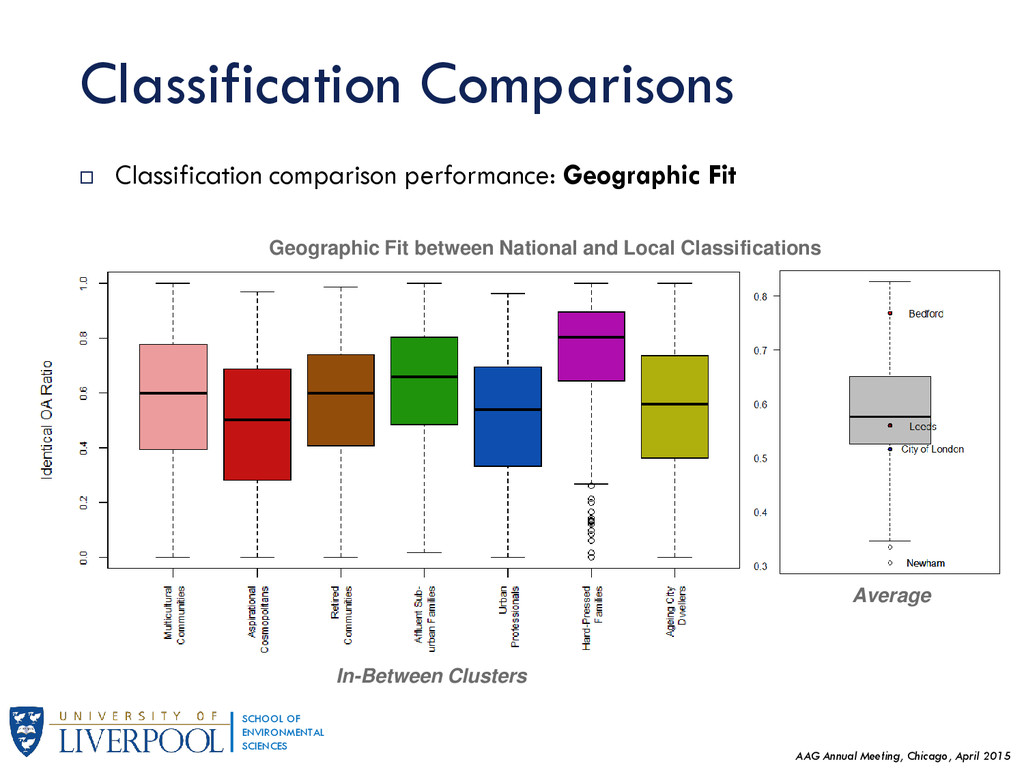
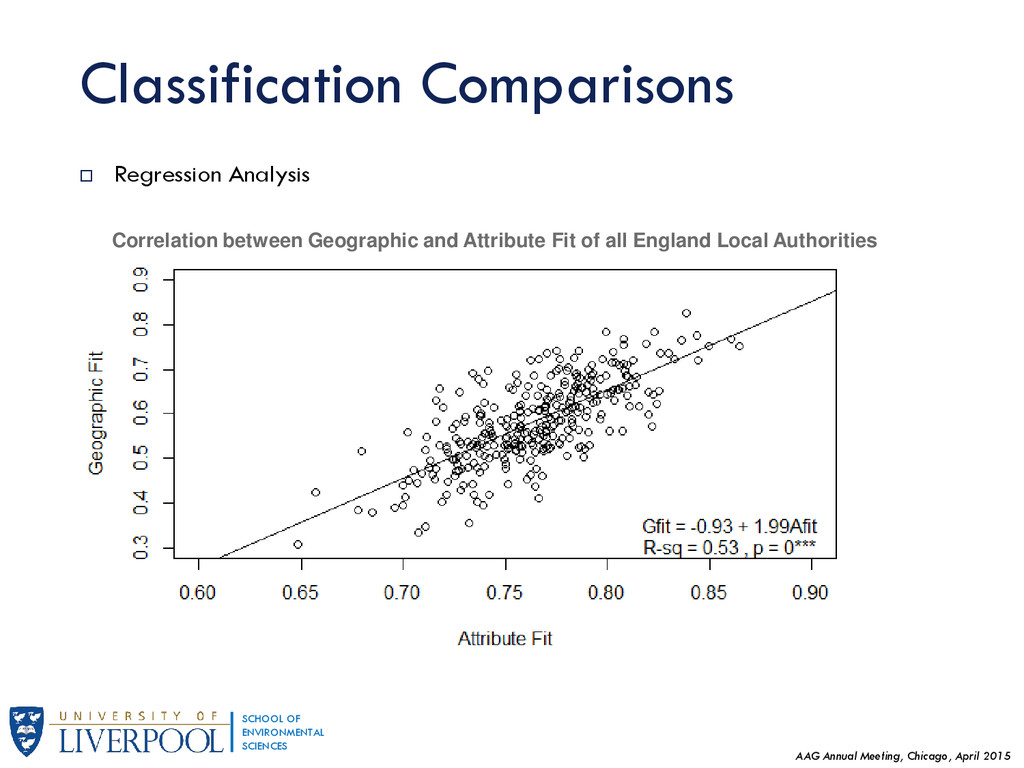
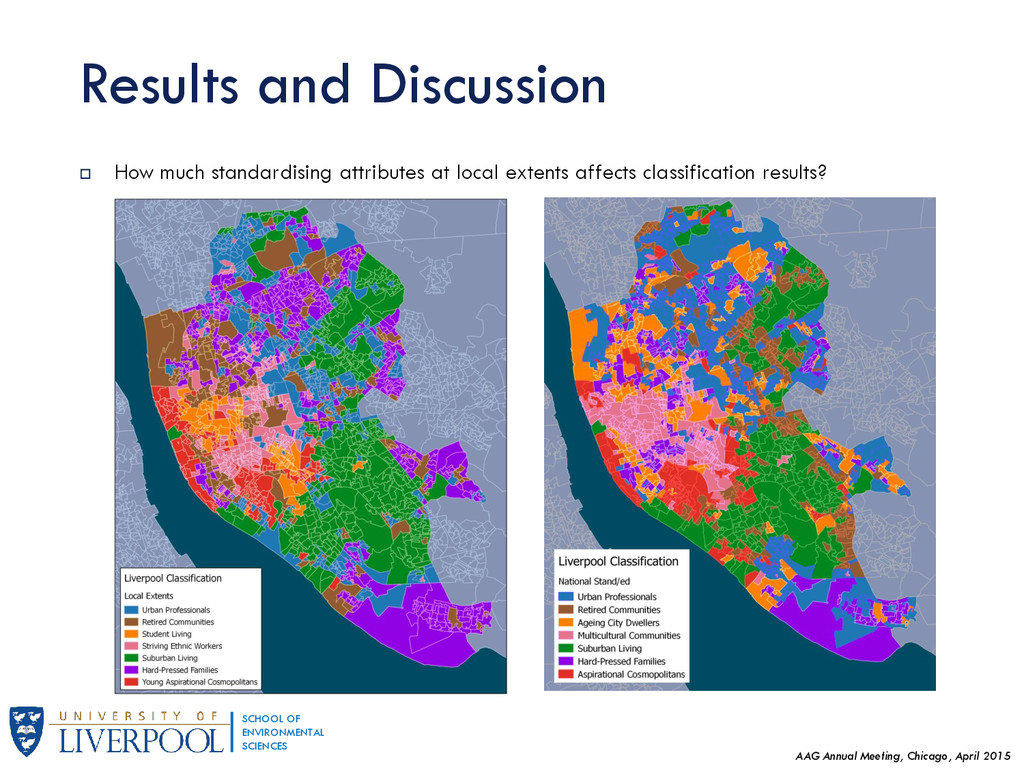
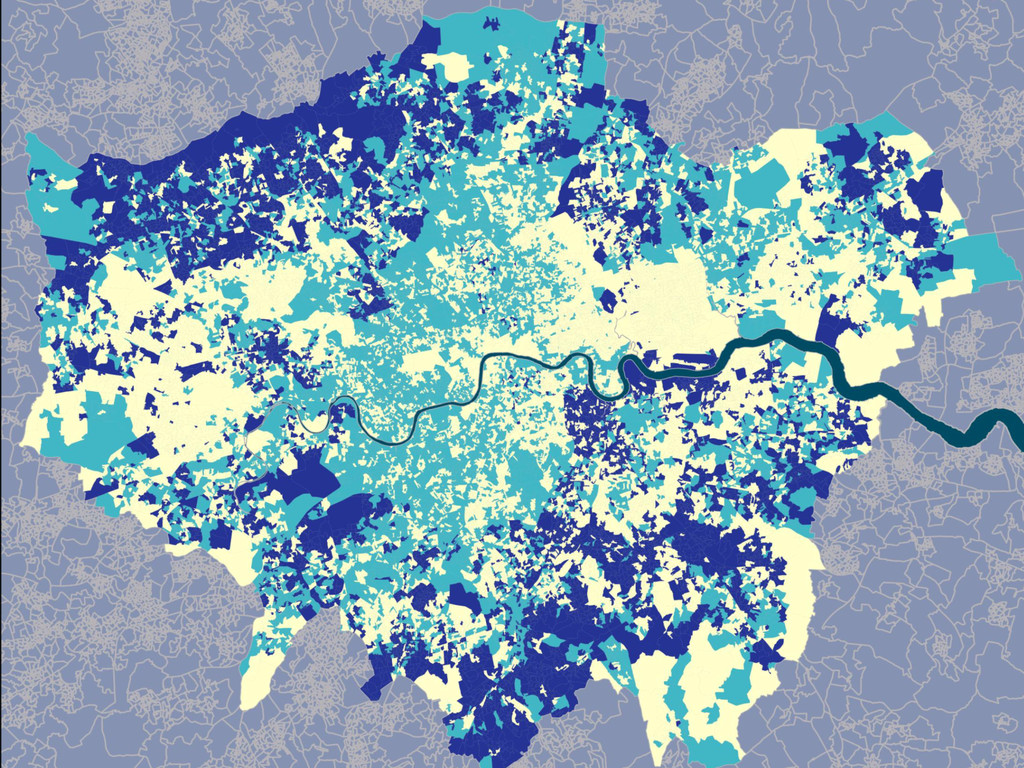
This research generalises results regarding Geographic Sensitivity of socio-spatial patterns (presented earlier in GISRUK 2015) by examining the degree of homogeneity of England's neighbourhoods to national standards. Presented at the Association of American Geographers Annual Meeting in Chicago, April 2015.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
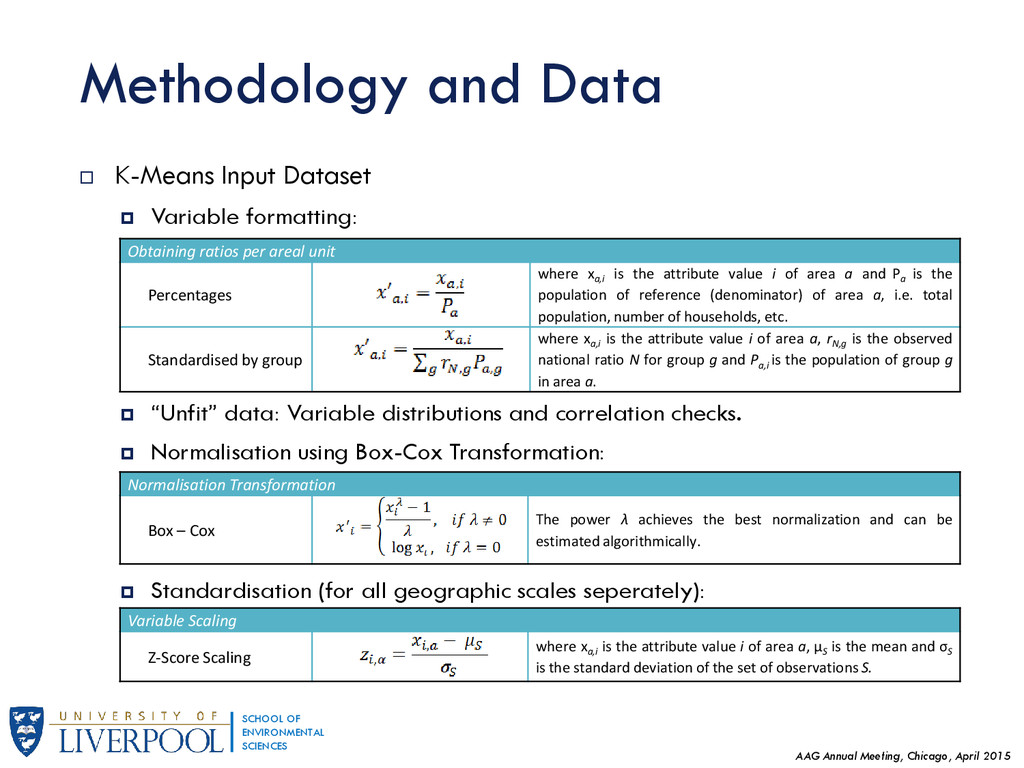{kind=link}
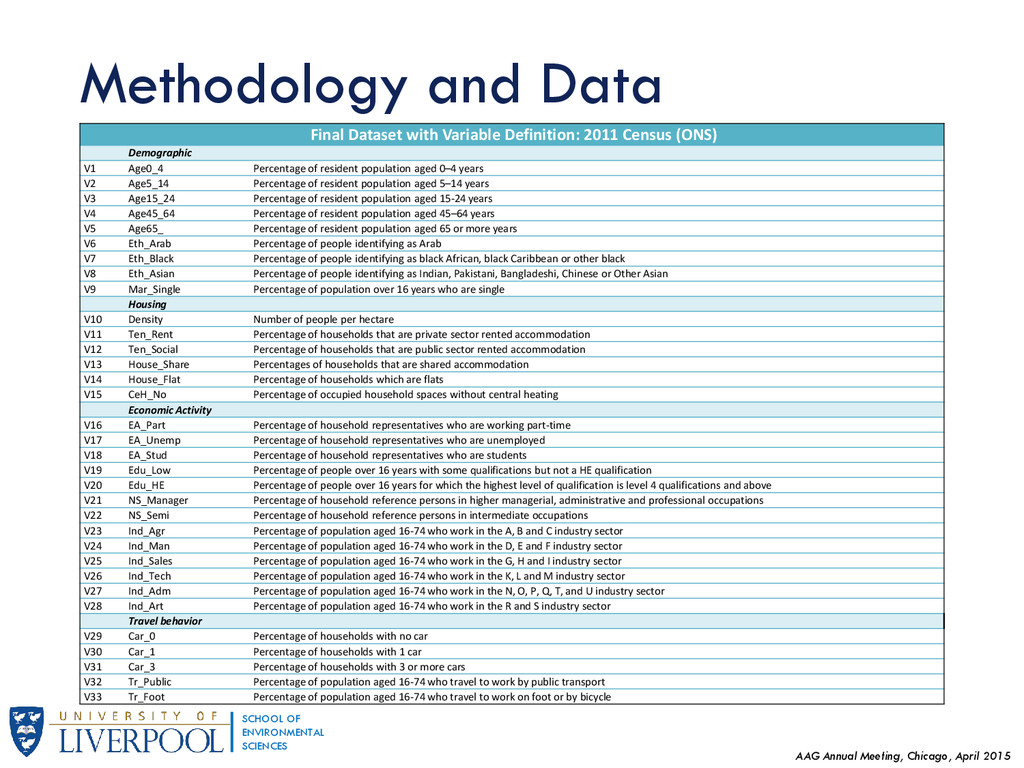{kind=link}
{kind=link}
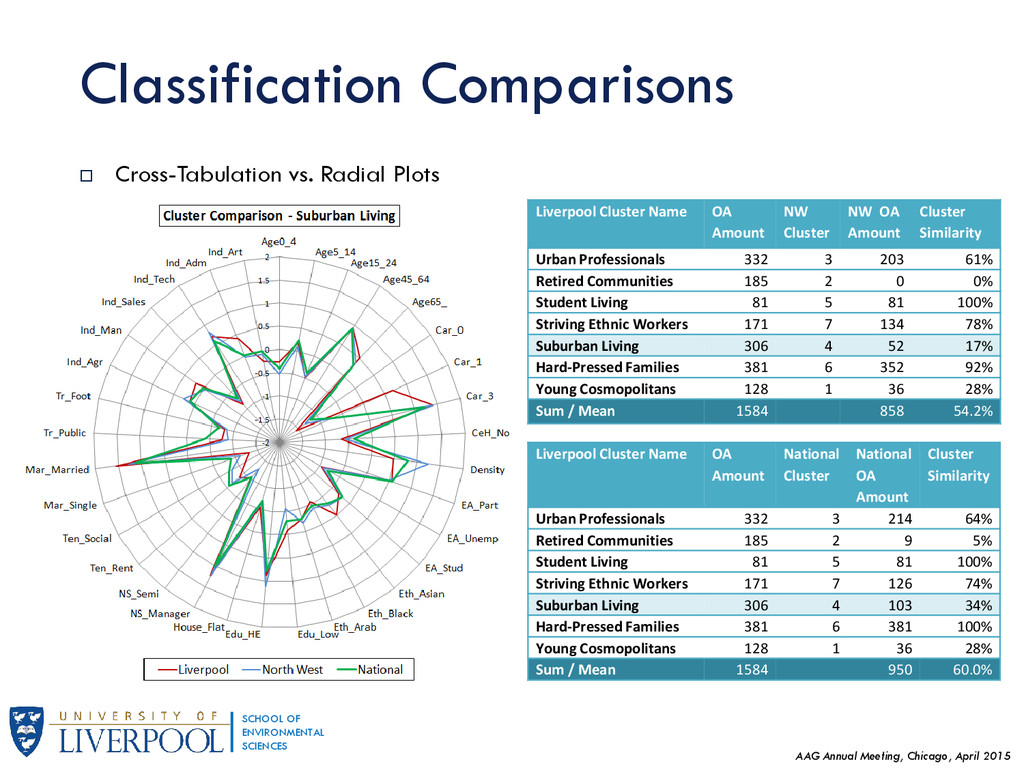{kind=link}
{kind=link}
{kind=link}
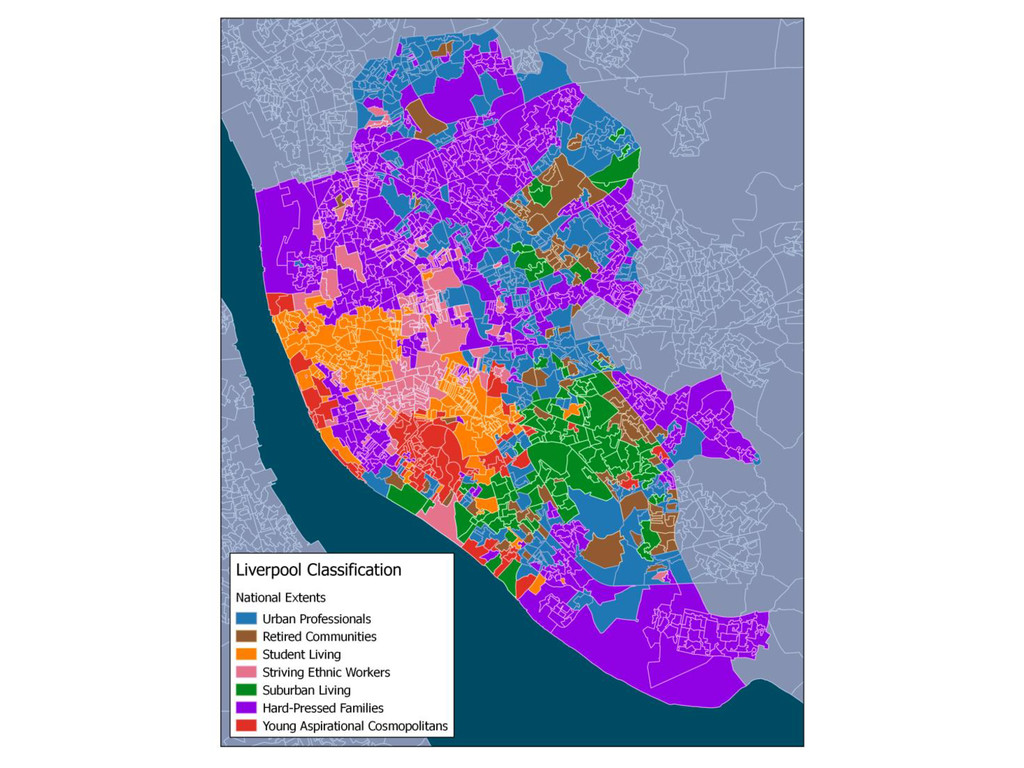{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your time [email protected] https://speakerdeck.com/dblalex Acknowledgements: This work](https://files.speakerdeck.com/presentations/772d0c231d2745069bcf3d196ff610c2/slide_22.jpg){kind=link}